
- 1饥荒更新后服务器不显示,饥荒更新完服务器启动时遇到一些麻烦 | 手游网游页游攻略大全...
- 2内网服务器批量挂载本地iso镜像的yum源_内网挂载yum
- 3谱聚类(spectral clustering)原理总结_adaptive kernel spectral clustering
- 4Python 第二代非支配排序遗传算法(NSGA-II)求解多目标高次函数的帕累托前沿_第二代遗传算法
- 530分钟从零玩转部署docker+k8s集群_k8s集群和docker swarm集群可以一起安装在一个节点吗
- 6python学习--Django4、数据库的增删改查、django后台管理系统、动态获取orm的name_django 添加数据
- 7关于Deepin23下的CUDA安装_deepin23 nvidia
- 8TCP的连接和断开_tcp连接和断开的序列号有关系吗
- 9Pycharm连接云算力远程服务器(AutoDL)训练深度学习模型全过程_autodl的pytorch能直接用嘛
- 10【转】工作站和服务器的区别
kubernetes容器网络_容器网络解决方案
赞
踩
K8S架构
Kubernetes最初源于谷歌内部的Borg,提供了面向应用的容器集群部署和管理系统。 Kubernetes 具备完善的集群管理能力,包括多层次的安全防护和准入机制、多租户应用支撑能力、透明的服务注册和服务发现机制、内建负载均衡器、故障发现和自我修复能力、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多粒度的资源配额管理能力。 Kubernetes 还提供完善的管理工具,涵盖开发、部署测试、运维监控等各个环节。
分层架构
Kubernetes设计理念和功能其实就是一个类似Linux的分层架构,如下图所示。
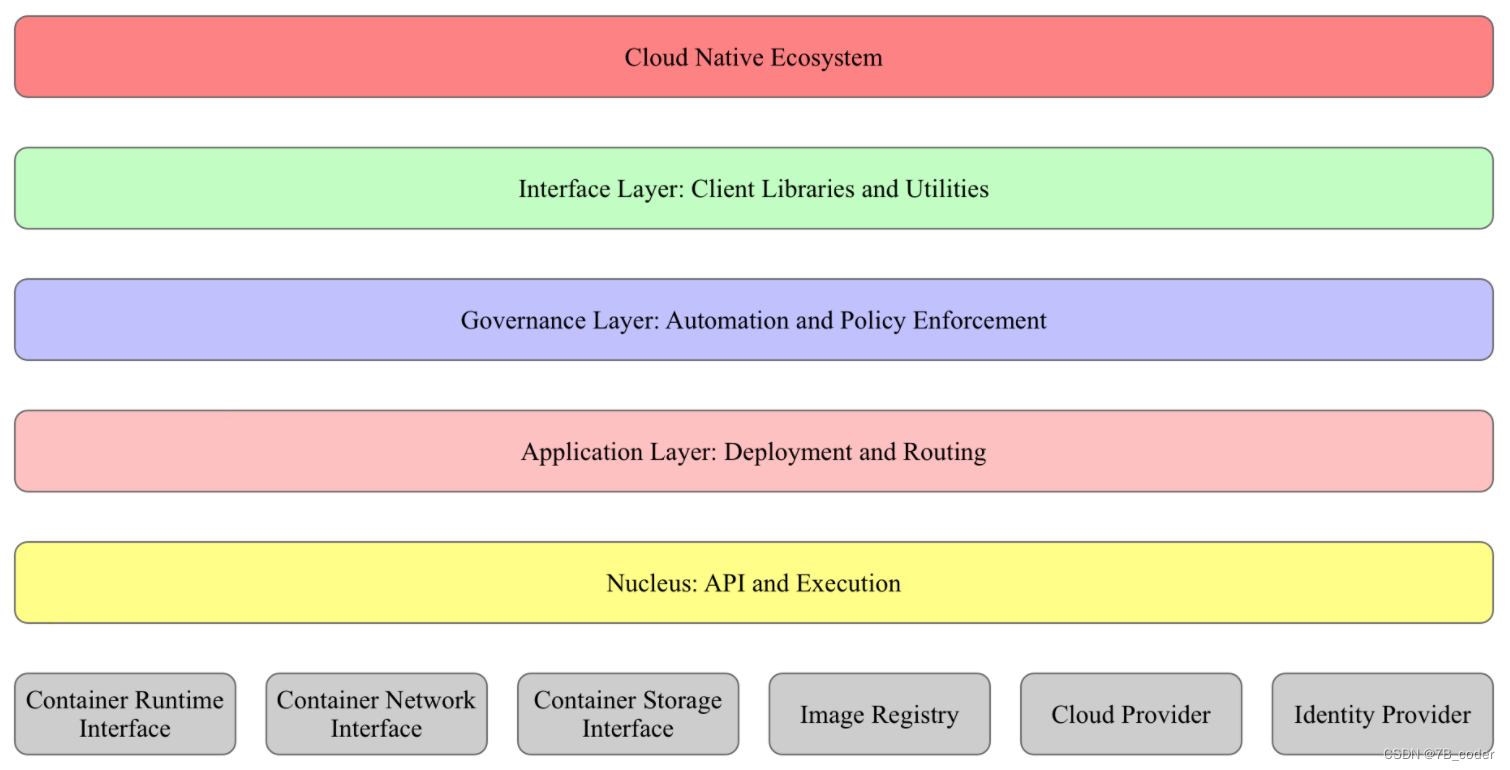
架构主要自底向上分为:
-
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
-
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)、Service Mesh(部分位于应用层)
-
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)、Service Mesh(部分位于管理层)
-
接口层:kubectl命令行工具、客户端SDK以及集群联邦
-
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
-
Kubernetes外部:日志、监控、配置管理、CI/CD、Workflow、FaaS、OTS应用、ChatOps、GitOps、SecOps等
-
Kubernetes内部:CRI、CNI、CSI、镜像仓库、Cloud Provider、集群自身的配置和管理等
-
总体架构
Kubernetes借鉴了Borg的设计理念,比如Pod、Service、Label和单Pod单IP等。Kubernetes的整体架构跟Borg非常像,如下图所示。
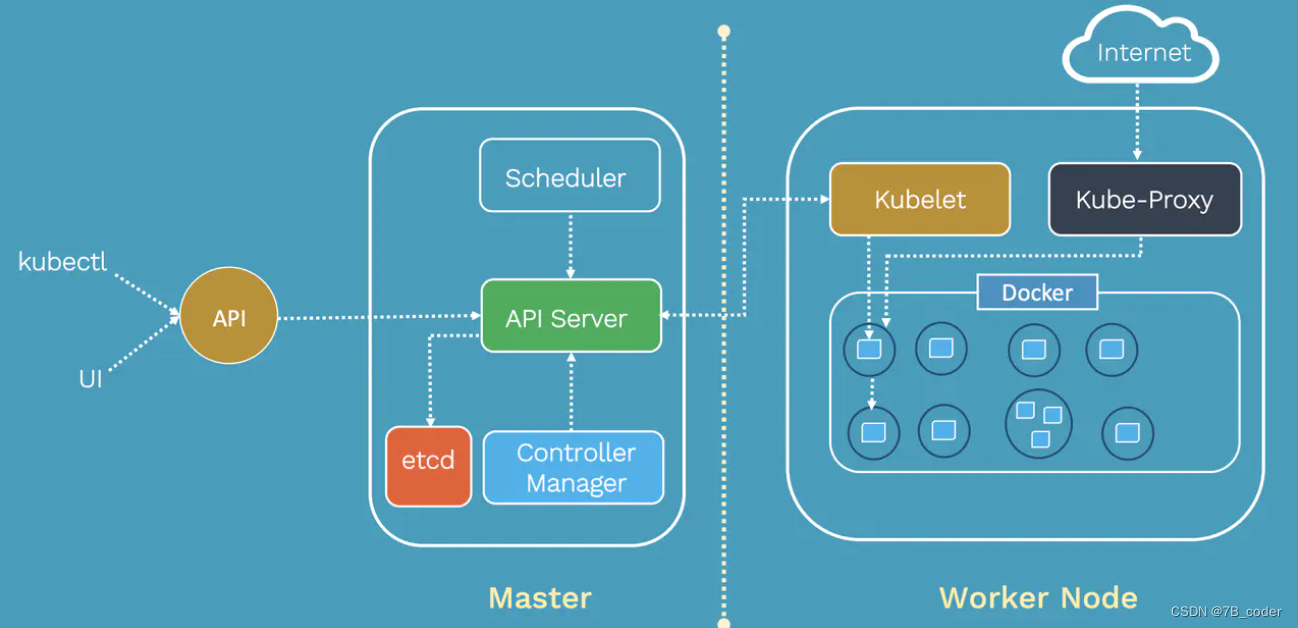
Kubernetes主要由以下几个核心组件组成:
-
etcd保存了整个集群的状态;
-
apiserver提供了资源操作的唯一入口,并提供认证、授权、访问控制、API注册和发现等机制;
-
controller manager负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
-
scheduler负责资源的调度,按照预定的调度策略将Pod调度到相应的机器上;
-
kubelet负责维护容器的生命周期,同时也负责Volume(CSI)和网络(CNI)的管理;
-
container runtime负责镜像管理以及Pod和容器的真正运行(CRI);
-
kube-proxy负责为Service提供cluster内部的服务发现和负载均衡;
除了核心组件,还有一些推荐的插件,其中有的已经成为CNCF中的托管项目:
-
CoreDNS负责为整个集群提供DNS服务
-
Ingress Controller为服务提供外网入口
-
Prometheus提供资源监控
-
Dashboard提供GUI
-
Federation提供跨可用区的集群
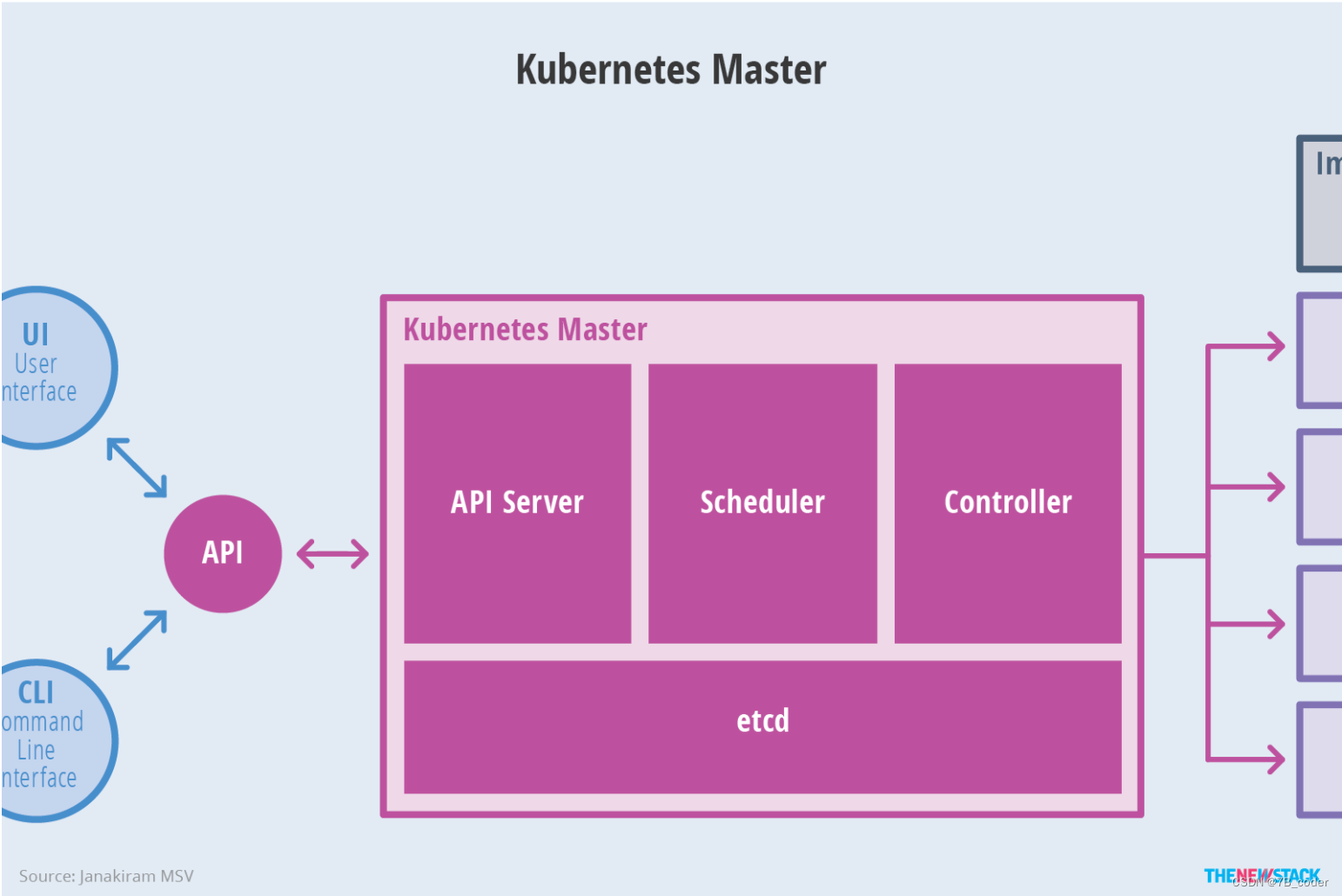
Master架构
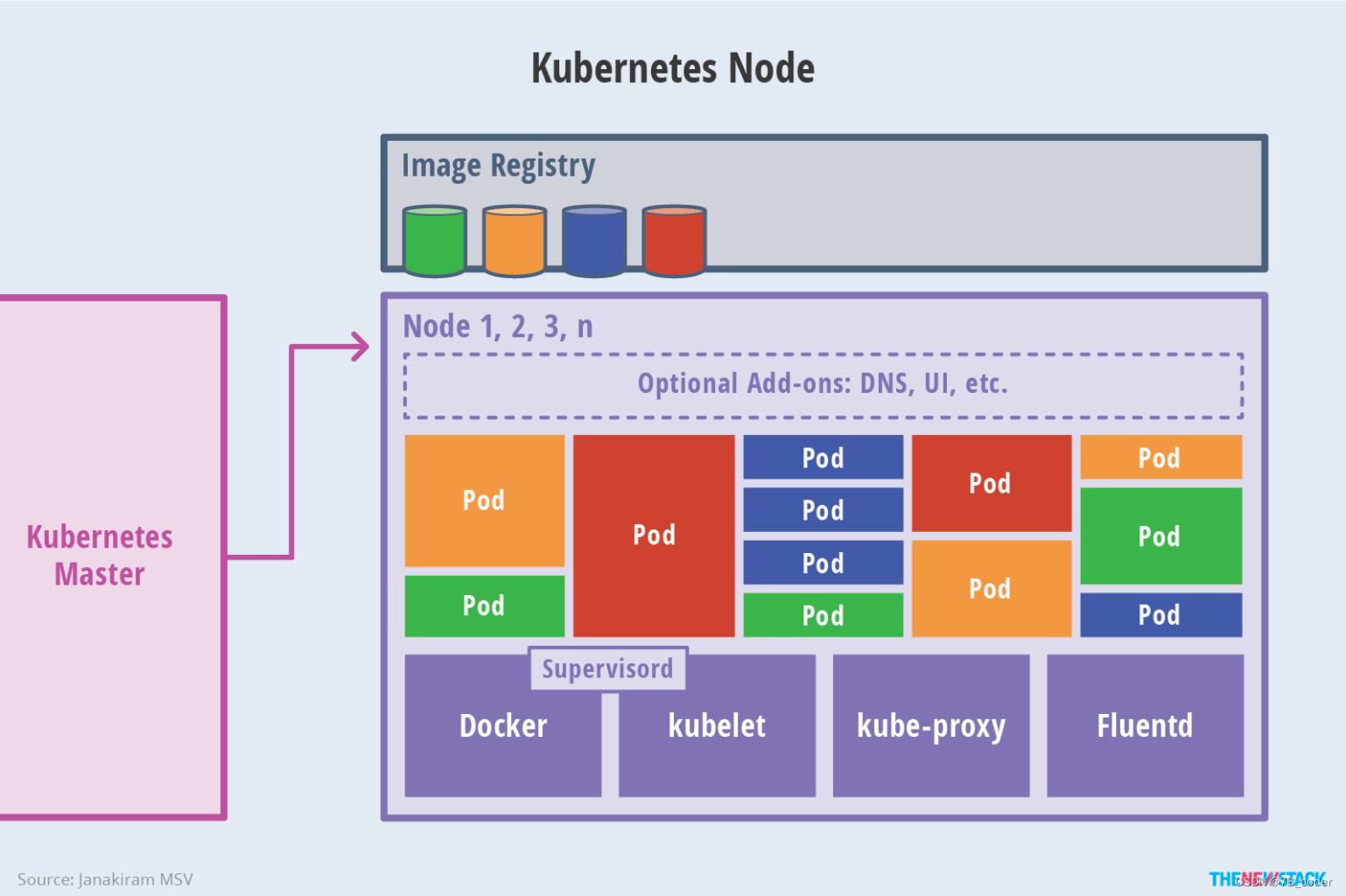
Node架构
核心概念
Node:Kubernetes 集群中的计算能力由 Node 提供,可以是物理机也可以是虚拟机。不论是物理机还是虚拟机,工作主机的统一特征是上面要运行 kubelet 管理节点上运行的容器。
Pod:Pod 是在 Kubernetes 集群中运行部署应用或服务的最小单元,它是可以支持多容器的。Pod 的设计理念是支持多个容器在一个 Pod 中共享网络地址和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。根据业务场景的不同,Pod可以分为:长期伺服型(long-running)、批处理型(batch)、节点后台支撑型(node-daemon)和有状态应用型(stateful application),分别对应的控制器为 Deployment、Job、DaemonSet 和 StatefulSet。
Service:Deployment等控制器只能控制服务的Pod数量,不能解决服务访问的问题。在 K8 集群中,客户端需要访问的服务就是 Service 对象。每个 Service 会对应一个集群内部有效的虚拟 IP,集群内部通过虚拟 IP 访问一个服务。
Labels and Selectors:用于标识Pod的KV对
Namespace:命名空间为 Kubernetes 集群提供虚拟的隔离作用,Kubernetes 集群初始有两个命名空间,分别是默认命名空间 default 和系统命名空间 kube-system,除此以外,管理员可以可以创建新的命名空间满足需要。
Secret:Secret 是用来保存和传递密码、密钥、认证凭证这些敏感信息的对象。使用 Secret 的好处是可以避免把敏感信息明文写在配置文件里,比如数据库访问账户和密码等。
Annotation:注解可以为对象附加任意的非标识的KV形式的元数据。
K8S容器网络
Kubernetes为每个Pod分配一个IP,即“IP-Per-Pod”,Pod内所有容器共享一个网络命名空间,Pod间无需NAT即可直接通信。
Kubernetes网络通信主要分为如下几部分:
-
Pod内部容器间通信
-
Pod间通信
-
同一个Node内的Pod之间
-
不同Node上的Pod之间
-
-
Pod与Service之间的网络通信
-
外界与Service之间的网络通信
具体可以将容器网络通信细分为:
-
Pod访问
-
Pod访问其他Node的Pod
-
Pod访问同Node的Pod
-
Node访问其他Node的Pod
-
Node访问本Node的Pod
-
-
Service访问
-
Client Pod访问Service在其他Node上的BackEnd Pod
-
Client Pod访问Service在本Node上的BackEnd Pod
-
Node访问Service在其他Node上的BackEnd Pod
-
Node访问Service在本Node上的BackEnd Pod
-
External访问Service
-
容器网络基础
Pod使用了Linux中的Cgroup和Namespace技术,其中Cgroup用于资源限制,Namespace用于资源隔离。每个Namespace都会拥有自己的协议栈,包括接口、路由表、Socket和iptables规则,一个接口只会属于一个network namespace。为了支持多个Pod有多种方法,一种是使用多个硬件接口,一种是生成软件模拟的接口。下面是几种软件接口实现方式:
Virtual bridge
创建一个虚拟接口对veth pair,一端放在Pod中作为eth0,一端放在root ns中插在linux bridge或者是ovs bridge上,实现接口的连通。这种方式下网桥可能会带来一些额外的性能开销。
Multiplexing
多路复用是将一个中间网络设备暴露出多个虚拟接口,并支持通过转发规则控制报文转发至哪个接口。MACVLAN为每个虚拟接口分配独立的MAC地址,出向报文带上这个MAC地址,入向报文通过目的MAC地址进行多路复用转发。IPVLAN也是类似的,但是在单个MAC地址上使用多个IP地址进行多路复用,对VM更友好一些。Linux Kernel从3.9开始支持MACVLAN,从3.19 开始支持 IPVLAN。
Hardware switching
当前大部分的网卡都支持SRIOV(Single Root I/O Virtualization),可以将一个物理网卡分拆成多个虚拟网卡,每个虚拟网卡都是一个独立的PCI设备,可以拥有独立的VLAN和硬件QoS能力,可以提供与原始硬件网卡一致的性能,但是由于无法灵活实现VPC网络的各种功能,因此在公有云上使用并不多。
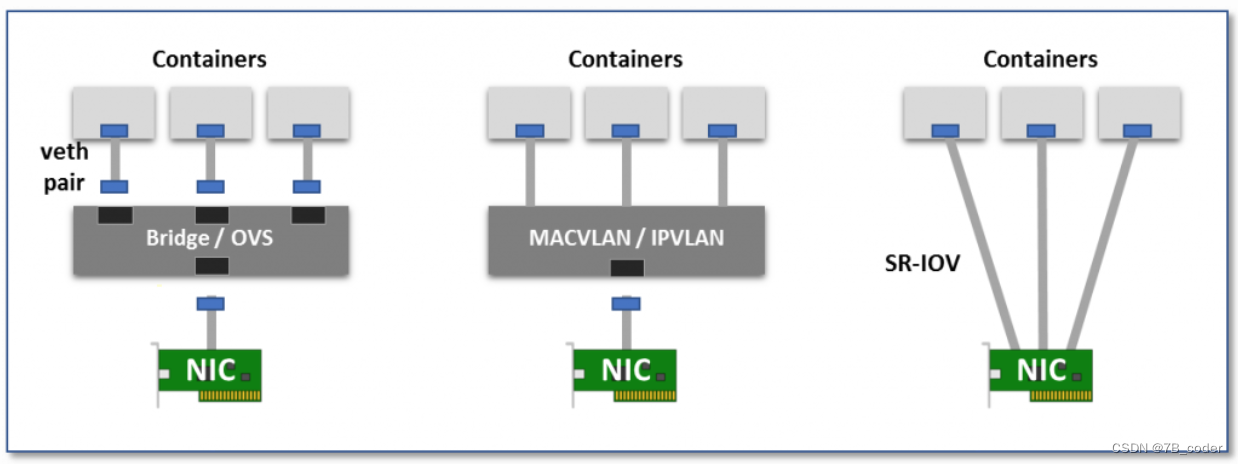 在不考虑性能的情况下业界通常使用virtual bridge的方式实现单机容器网络拓扑,如果考虑性能和安全策略可以考虑使用MACVLAN/IPVLAN(SRIOV方案的安全策略隔离需要依赖交换机上配置VLAN和ACL,不够灵活)。
在不考虑性能的情况下业界通常使用virtual bridge的方式实现单机容器网络拓扑,如果考虑性能和安全策略可以考虑使用MACVLAN/IPVLAN(SRIOV方案的安全策略隔离需要依赖交换机上配置VLAN和ACL,不够灵活)。
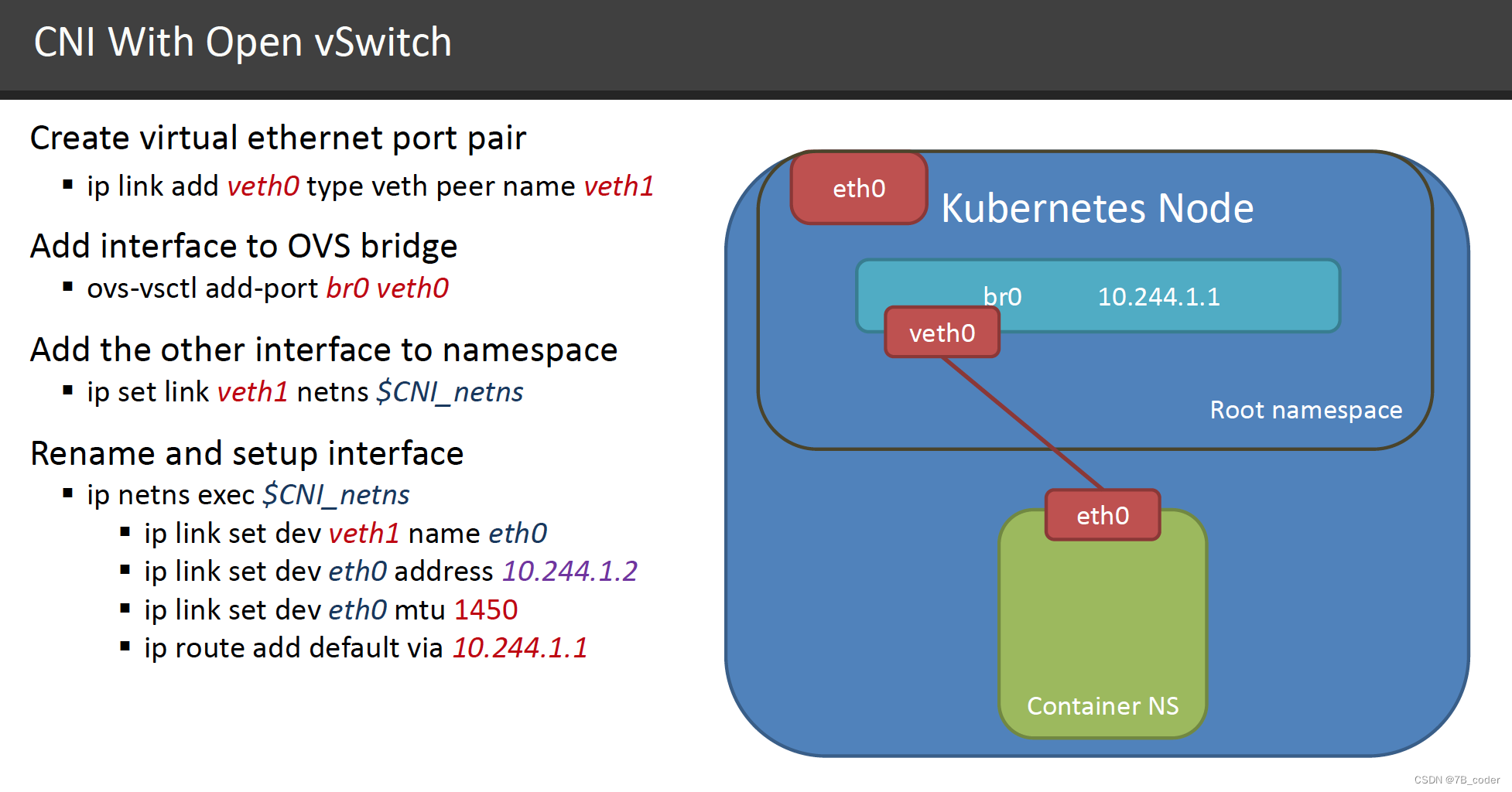
CNI
Container Network Interface (CNI) 最早是由CoreOS发起的容器网络规范,是Kubernetes网络插件的基础。其基本思想为:Container Runtime在创建容器时,先创建好network namespace,然后调用CNI插件为这个netns配置网络,其后再启动容器内的进程。
CNI插件包括两部分:
-
CNI Plugin负责给容器配置网络,它包括两个基本的接口
-
配置网络: AddNetwork(net NetworkConfig, rt RuntimeConf) (types.Result, error)
-
清理网络: DelNetwork(net NetworkConfig, rt RuntimeConf) error
-
-
IPAM Plugin负责给容器分配IP地址、网关和DNS,主要实现包括host-local和dhcp
CNI插件是一个二进制程序,其输入和输出遵守 appc/CNI 规约。当创建Pod的时候,kubelet通过apiserver watch到之后,在本地执行创建操作,其中创建网络步骤会执行CNI配置文件中指定的CNI插件二进制文件,由CNI插件配置Pod的网络。
IPAM插件也是一个二进制程序,默认使用host-local方式,使用本地文件维护一个“本地数据库”,为每个Node配置一个容器网络网段,比如/24这样的C段。当Pod创建时从"本地数据库"中分配一个IP地址。当没有较多剩余IP地址无法为每个Node分配/24网段,或者是有状态Pod漂移时想保留IP地址,这个时候就需要使用集中式地址管理,比如dhcp方案(可以借助neutron中的nn/vn来实现dhcp),社区中也有一些基于redis、consul、etcd等共享存储的集中式IPAM方案。(Pod被分配到一个Node上运行之后,就不会离开这个Node,直到被删除。当某个Pod失败,首先会被Kubernetes清理掉,之后ReplicationController将会重建Pod,重建之后Pod的ID会变化,即一个新的Pod。所以Kubernetes中Pod的迁移,实际指的是在新Node上重建Pod。)
Pod间通信
社区容器网络方案主要有两种:
-
隧道方案:隧道方案在IaaS层的网络中应用也比较多,将pod分布在一个大二层的网络规模下。网络拓扑简单,但随着节点规模的增长复杂度会提升。
-
Weave:UDP广播,本机建立新的BR,通过PCAP互通
-
Open vSwitch(OVS):基于VxLan和GRE协议,但是性能方面损失比较严重
-
Flannel:UDP广播,VxLan
-
Racher:IPsec
-
-
路由方案:路由方案一般是从3层或者2层实现隔离和跨主机容器互通的,出了问题也很容易排查。
-
Calico:基于BGP协议的路由方案,支持很细致的ACL控制,对混合云亲和度比较高。
-
Macvlan:从逻辑和Kernel层来看隔离性和性能最优的方案,基于二层隔离,所以需要二层路由器支持,大多数云服务商不支持,所以混合云上比较难以实现。
-
下面重点介绍一些常用的Flannel和Calico方案。
Flannel
Flannel是kubernetes默认提供网络插件,由CoreOs团队开发社交的网络工具,采用L3 Overlay模式。同宿主机下各个Pod属于同一个子网,不同宿主机下的Pod属于不同的子网。Flannel会在每一个宿主机上运行名为flanneld代理,其负责为宿主机预先分配一个子网,并为Pod分配IP地址。Flannel使用Kubernetes或etcd来存储网络配置、分配的子网和主机公共IP等信息。数据包则通过VXLAN、UDP或host-gw这些类型的后端机制进行转发。
Flannel的主要组件:
-
docker0:网桥设备,每创建一个pod都会创建一对 veth pair。其中一端是pod中的eth0,另一端是Cni0网桥中的端口(网卡)。Pod中从网卡eth0发出的流量都会发送到Cni0网桥设备的端口(网卡)上。
-
flannel.1: overlay网络的设备,用来进行 vxlan 报文的处理(封包和解包)。不同node之间的pod数据流量都从overlay设备以隧道的形式发送到对端。
-
flanneld:flannel在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac、ip等网络数据信息。
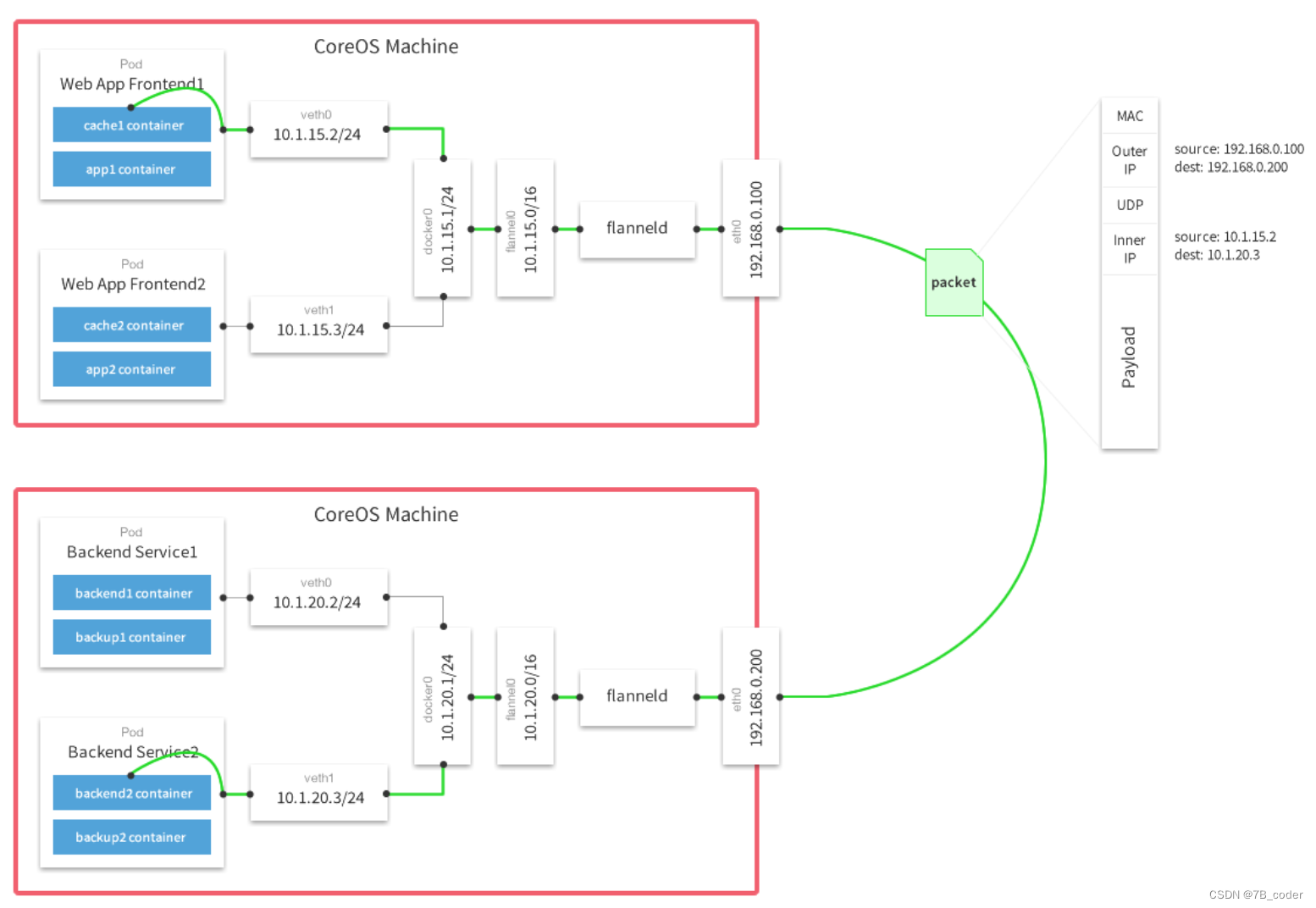 不同node上的pod的通信流程:
不同node上的pod的通信流程:
-
pod中产生数据,根据pod的路由信息,将数据发送到docker0
-
docker0 根据节点的路由表,将数据发送到隧道设备flannel.1
-
flannel.1查看数据包的目的ip,从flanneld获得对端隧道设备的必要信息,封装数据包。
-
flannel.1将数据包发送到对端设备。对端节点的网卡接收到数据包,发现数据包为overlay数据包,解开外层封装,并发送内层封装到flannel.1设备。
-
flannel.1设备查看数据包,根据路由表匹配,将数据发送给docker0设备。
-
docker0匹配路由表,发送数据给网桥上对应的端口。
flannel默认使用vxlan后端,如果内核版本较老使用udp后端。udp后端的封包格式如下:
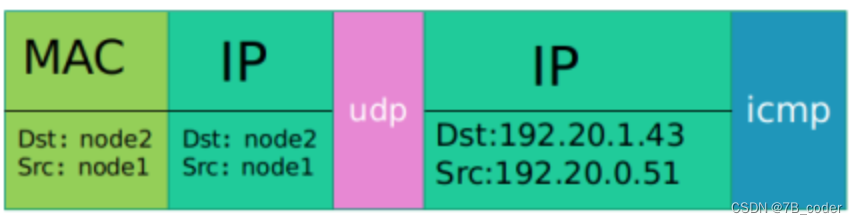
使用udp后端时,flanneld创建flannel.1 tun设备,当数据包到达flannel.1虚拟网卡的时候,由flanneld进行读取并进行udp封装,查找路由表发送出去。
vxlan和上文提到的udp backend的封包结构是非常类似,不同之处是多了一个vxlan header,以及原始报文中多了个二层的报头。
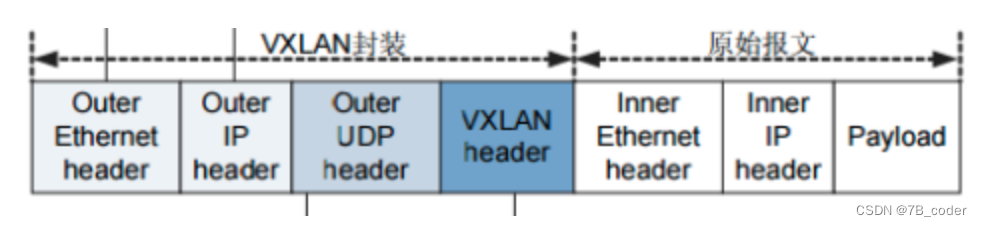
VXLAN网络数据包转发的核心是 RIB 路由表、FDB 转发表、ARP 路由表,即VXLAN要解决二层 Guest MAC 地址寻址、跨三层 Guest IP 地址寻址的问题,并实现全网高效路由分发和同步。早期的Flannel版本实现,借助于Linux 3.8内核开始引入的Distributed Overlay Virtual Ethernet(DOVE)机制,当数据包无法在 FDB 转发表中找到对应的 MAC 地址转发目的地时 kernel 发出 l2miss 通知事件,当在 ARP 表中找不到对应 IP-MAC 记录时 kernel 发出 l3miss 通知事件。flanneld通过NETLINK监听L2 Miss和L3Miss消息,查询从etcd中watch到的元信息进行响应。l2miss 和 l3miss 方案缺陷:
-
每一台 Host 需要配置所有需要互通 Guest 路由,路由记录会膨胀,不适合大型组网
-
通过 netlink 通知学习路由的效率不高
-
Flannel Daemon 异常后无法持续维护 ARP 和 FDB 表,从而导致网络不通
为了弥补 l2miss 和 l3miss 的缺陷,新版Flannel 改用了三层路由的实现方案,给每个Node上的Pod子网网段添加远端 Host 路由,同时为 vtep 和 bridge 各自分配三层 IP 地址,当数据包到达目的 Host 后,在内部进行三层转发。这样的好处就是 Host 不需要配置所有的 Guest 二层 MAC 地址,从一个二层寻址转换成三层寻址,路由数目与 Host 机器数呈线性相关。
新的Node A加入flannel网络时,它会将自己的三个信息写入etcd中,分别是:subnet 10.1.16.0/24、Public IP 192.168.0.101、vtep设备flannel.1的mac地址 MAC A。其他Node会得到EventAdded事件,并从中获取Node A添加至etcd的各种信息,并在本机上添加三条信息:
-
路由信息:所有通往目的地址10.1.16.0/24的封包都通过vtep设备flannel.1设备发出,发往的网关地址为10.1.16.0,即Node A中的flannel.1设备。
-
FDB信息:MAC地址为MAC A的封包,都将通过vxlan发往目的地址192.168.0.101,即Node A。
-
ARP信息:网关地址10.1.16.0的地址为MAC A。
udp后端和vxlan后端工作方式本质上是一样的,vxlan后端中将VNI设置为1,将udp的proxy换成了内核中的vxlan处理模块。
Calico
K8S默认的Flannel容器网络方案主要关注Pod间互通,并不支持Network Policy,如果想要Network Policy安全隔离策略就需要使用Calico。Calico 不使用隧道或 NAT 来实现转发,而是巧妙的把所有二三层流量转换成三层流量,并通过 Host 上路由配置完成跨 Host 转发。Calico规避了二层网络通通信的广播开销、VLAN 4096规则限制和VXLAN隧道技术的开销。
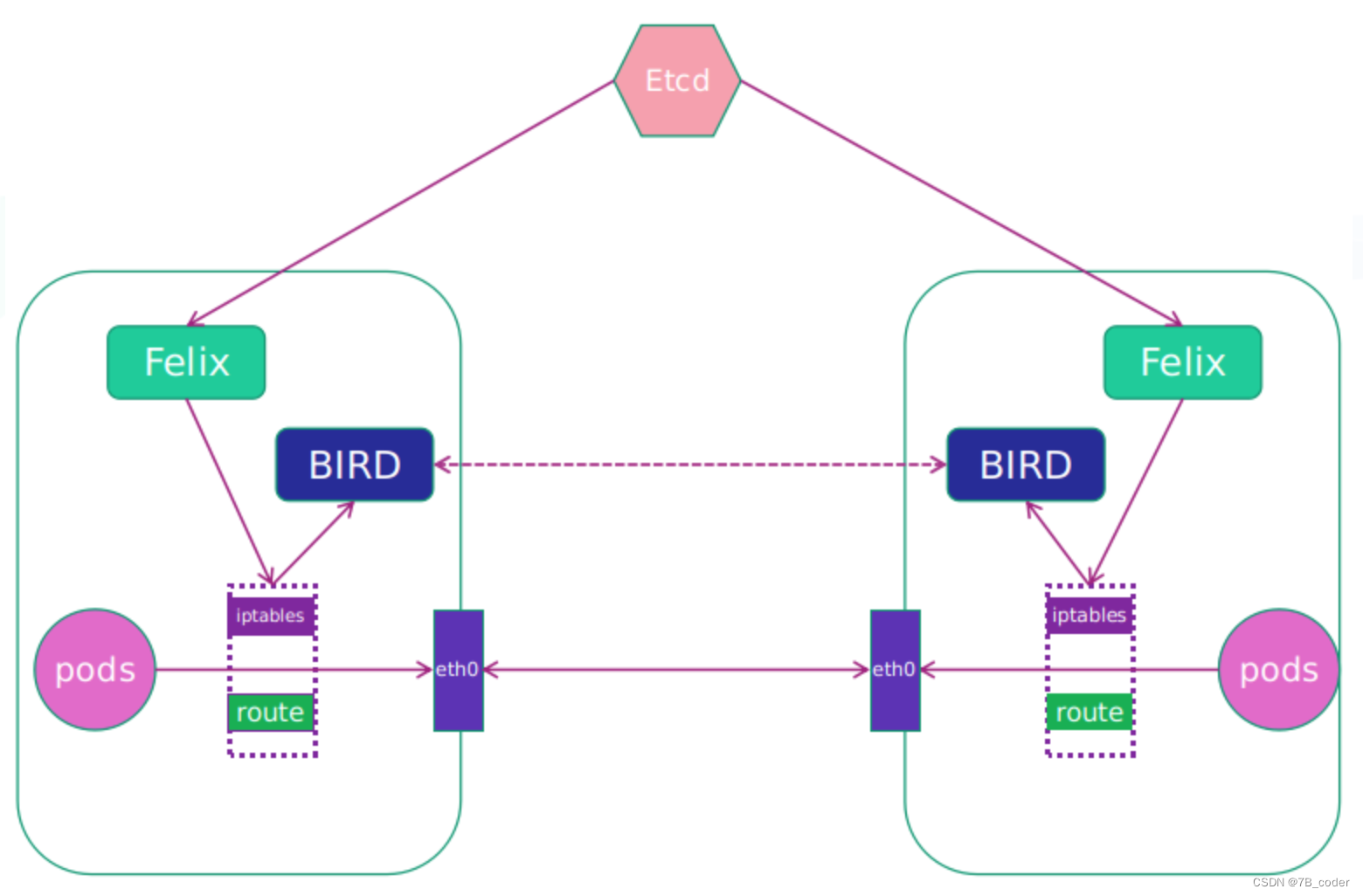
Calico网络模型主要工作组件:
-
Felix:运行在每一台 Host 的 agent 进程,主要负责网络接口管理和监听、路由、ARP 管理、ACL 管理和同步、状态上报等。
-
etcd:分布式键值存储,主要负责网络元数据一致性,确保Calico网络状态的准确性,可以与kubernetes共用;
-
BGP Client(BIRD):Calico 为每一台 Host 部署一个 BGP Client,使用 BIRD 实现,BIRD 是一个单独的持续发展的项目,实现了众多动态路由协议比如 BGP、OSPF、RIP 等。在 Calico 的角色是监听 Host 上由 Felix 注入的路由信息,然后通过 BGP 协议广播告诉剩余 Host 节点,从而实现网络互通。
-
BGP Route Reflector:在大型网络规模中,如果仅仅使用 BGP client 形成 mesh 全网互联的方案就会导致规模限制,因为所有节点之间俩俩互联,需要 N^2 个连接,为了解决这个规模问题,可以采用 BGP 的 Router Reflector 的方法,使所有 BGP Client 仅与特定 RR 节点互联并做路由同步,从而大大减少连接数。
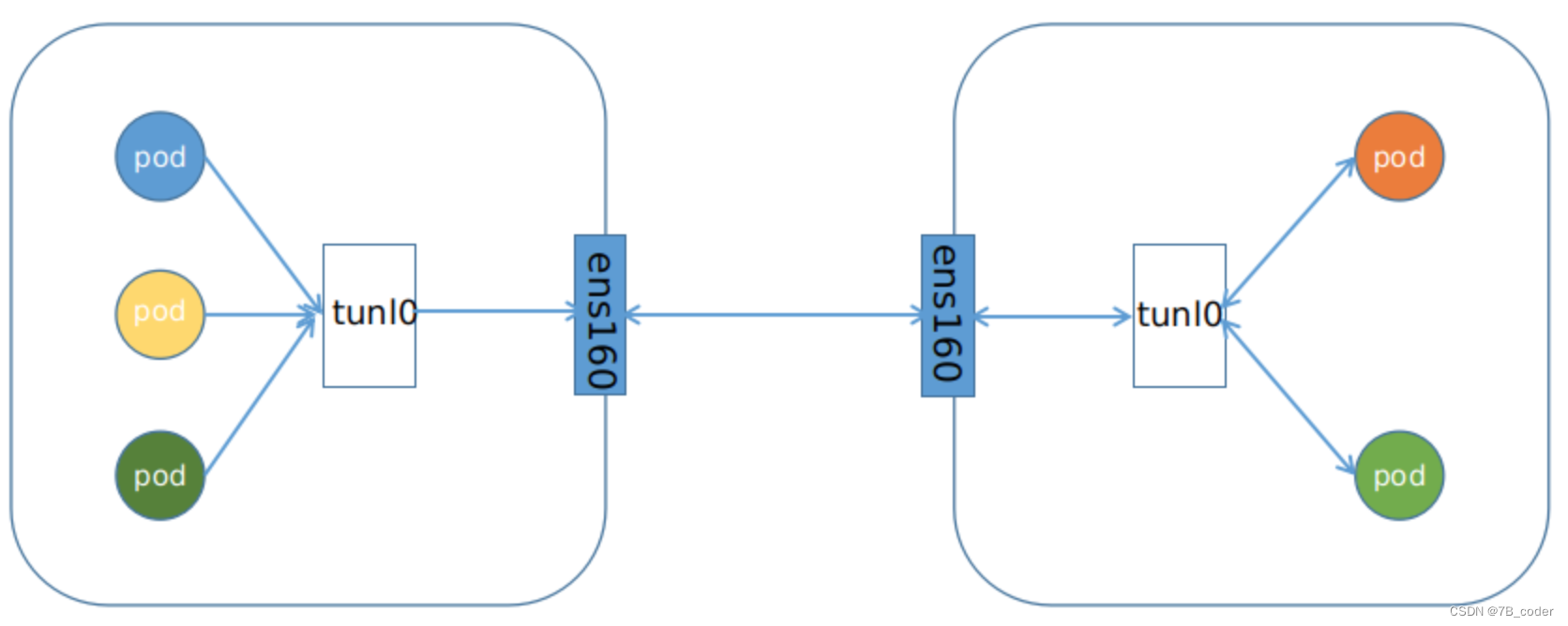
Calico网络节点间有两种:IPIP和BGP,默认选择IPIP网络。IPIP网络与BGP网络原理一样,都是在Host配置Pod访问的路由到Node。
IPIP网络:
-
流量:tunlo设备封装数据,形成隧道,承载流量
-
适用网络类型:适用于互相访问的pod不在同一个网段中,跨网段访问的场景。外层封装的ip能够解决跨网段的路由问题
-
效率:流量需要tunl0设备封装,效率略低
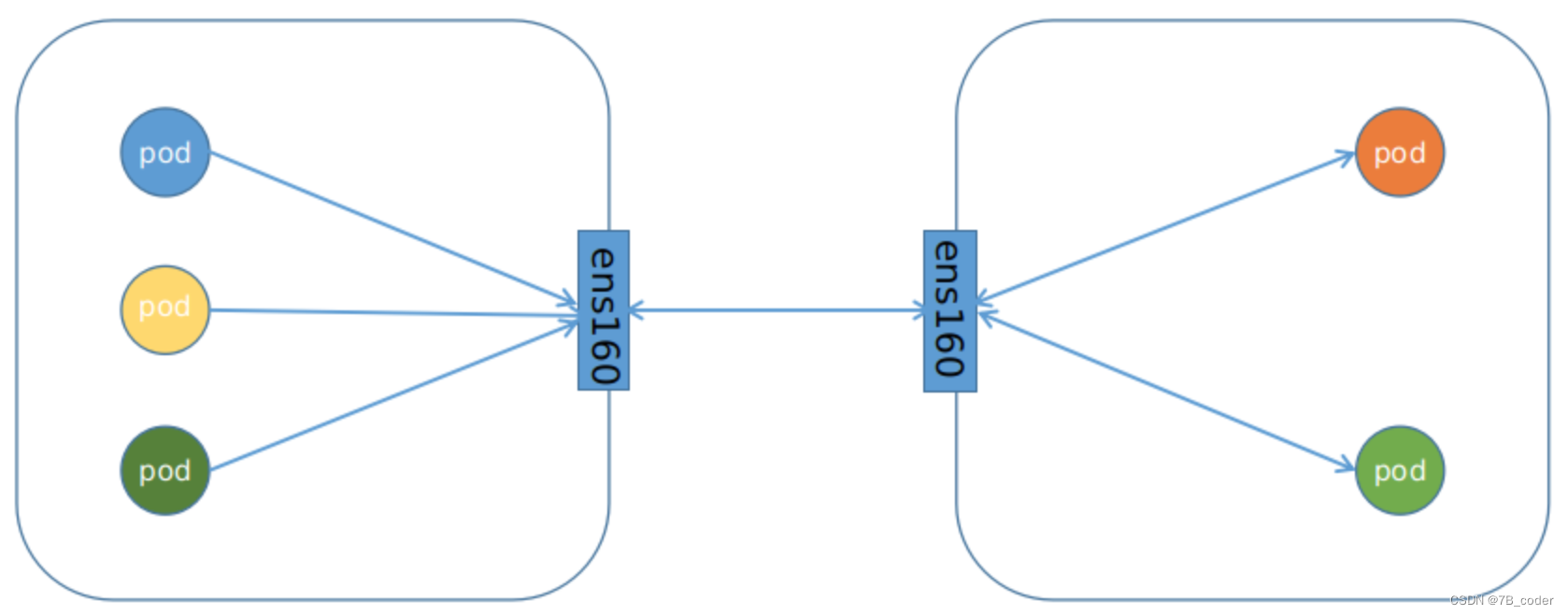
BGP网络:
-
流量:使用路由信息导向流量
-
适用网络类型:适用于互相访问的Pod在同一个网段,适用于大型网络
-
效率:原生HostGW,效率高
Calico由于在Host设置三层路由,无法解决多租户场景中网络地址冲突的问题,同时BGP网络需要物理网络工程师配合配置交换机来建立BGP邻居,大规模网络会在Host设置较多的路由和Iptables规则导致调试困难。
DNS
Kubernetes DNS 在群集上调度 DNS Pod 和服务,并配置 kubelet 以告知各个容器使用 DNS 服务的 IP 来解析 DNS 名称。
Kube-dns 会作为 Deployment 运行并将冗余 kube-dns Pod 调度到集群中的各节点。kube-dns Pod 位于 kube-system 命名空间中。kube-dns 部署通过相应的 Service 访问,该 Service 会对 kube-dns Pod 进行分组并为其提供单一 IP 地址。默认情况下,集群中的所有 Pod 均使用此服务来解析 DNS 查询。
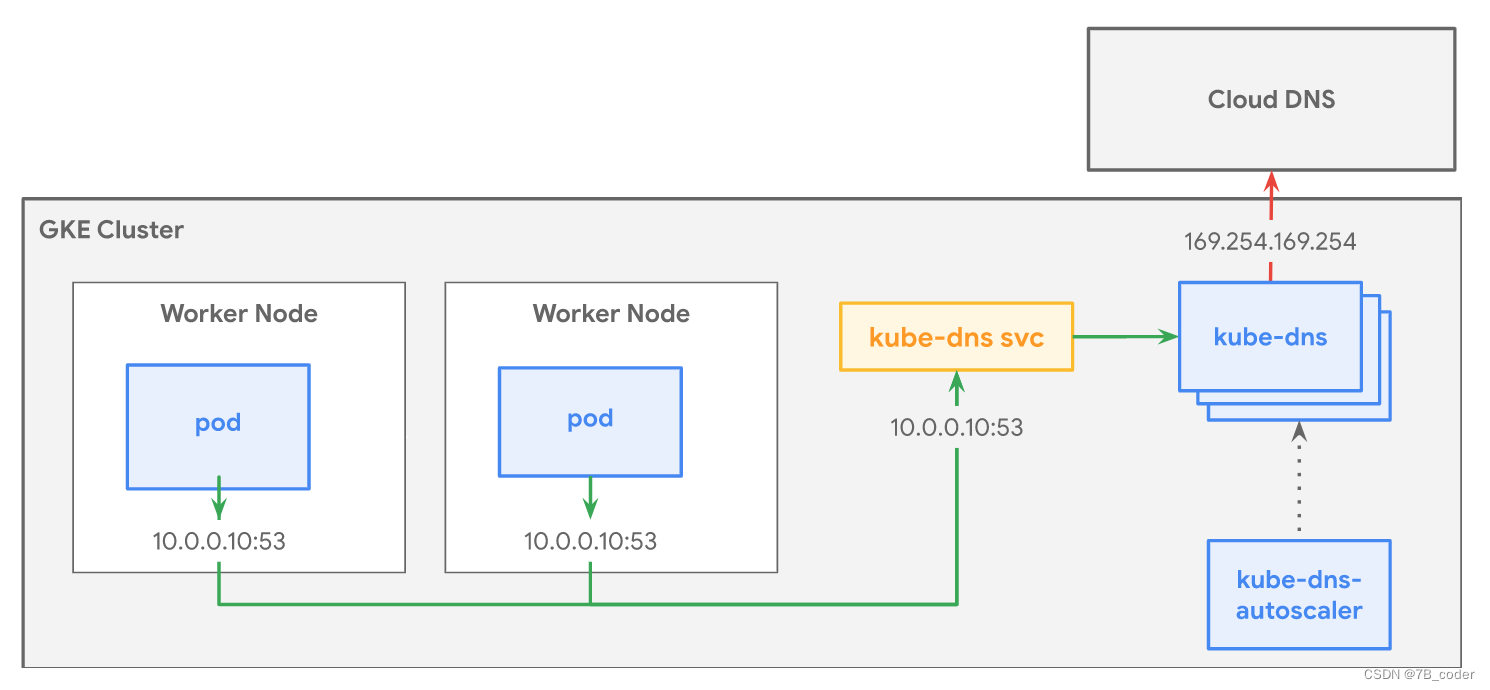
Kube-dns 会从容扩缩以满足集群的 DNS 需求。此扩缩过程由 kube-dns-autoscaler 控制,kube-dns-autoscaler 会根据集群中的节点数和核心数调整 kube-dns 部署中副本的数量。
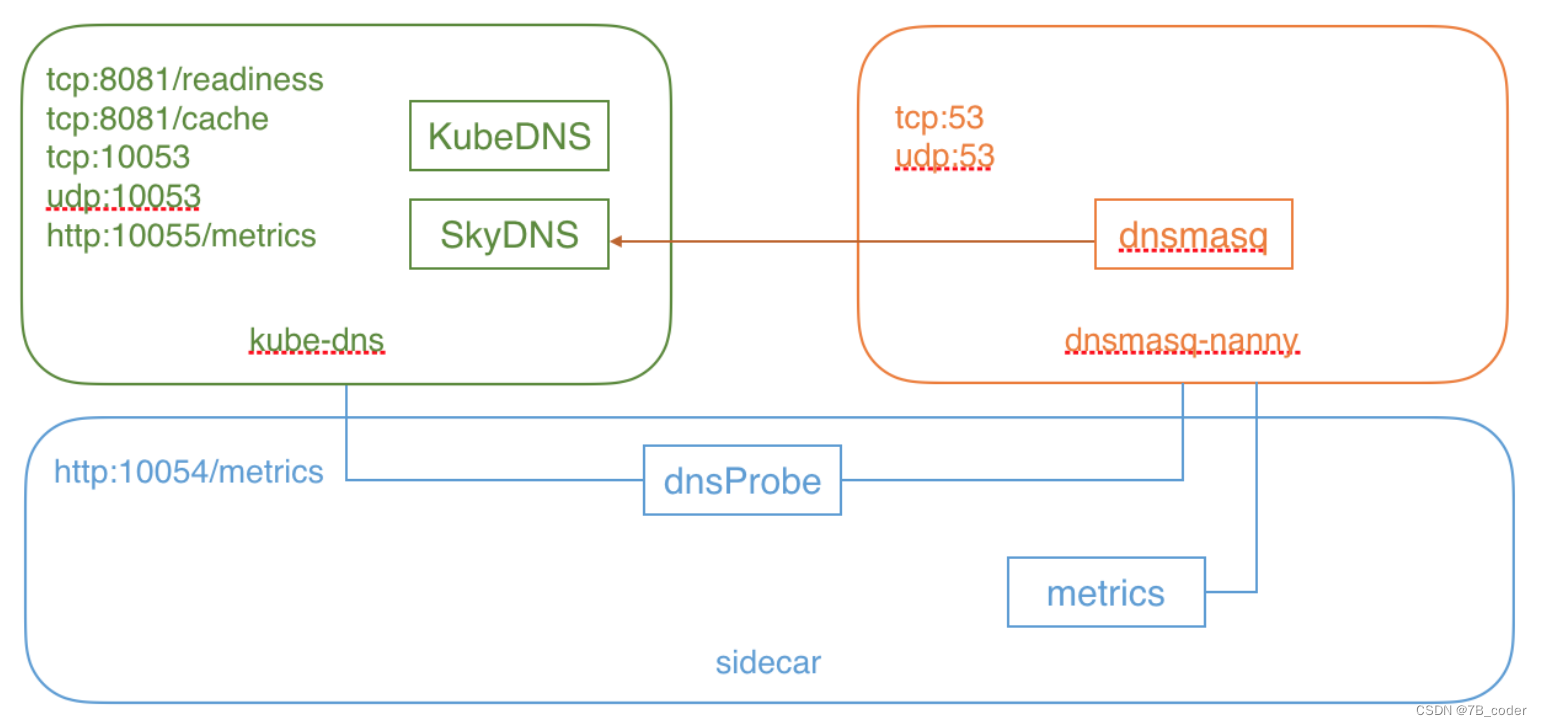
kube-dns Pod由三个容器组成:
-
kube-dns:DNS 服务的核心组件,主要由 KubeDNS 和 SkyDNS 组成
-
KubeDNS 负责监听 Service 和 Endpoint 的变化情况,并将相关的信息更新到 SkyDNS 中
-
SkyDNS 负责 DNS 解析,监听在 10053 端口 (tcp/udp),同时也监听在 10055 端口提供 metrics
-
kube-dns 还监听了 8081 端口,以供健康检查使用
-
-
dnsmasq-nanny:负责启动 dnsmasq,并在配置发生变化时重启 dnsmasq
-
dnsmasq 的 upstream 为 SkyDNS,即集群内部的 DNS 解析由 SkyDNS 负责
-
-
sidecar:负责健康检查和提供 DNS metrics(监听在 10054 端口)
Service
Service是将运行在一组 Pods上的应用程序抽象为网络服务,Kubernetes为Pods提供自己的IP地址和一组Pod的单个DNS名称,并且可以在它们之间进行负载平衡,应用程序无需修改即可使用Service这套服务发现机制。
在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式。从Kubernetes v1.0开始,可以使用 用户空间代理模式;Kubernetes v1.1添加了 iptables 模式代理,并从Kubernetes v1.2 开始 kube-proxy 的 iptables 模式成为默认设置;Kubernetes v1.8添加了 ipvs 代理模式。
常规的Service都有ClusterIP,还有一种Headless Service。顾名思义这种Service没有Cluster IP,只有一个EndPoint列表(默认是PodIP:Port列表,yaml中显式指定nodeport之后也会有NodeIP:Port列表,不过只对外提供访问入口),没有负载均衡功能,通常用于与其他外部服务发现机制对接。
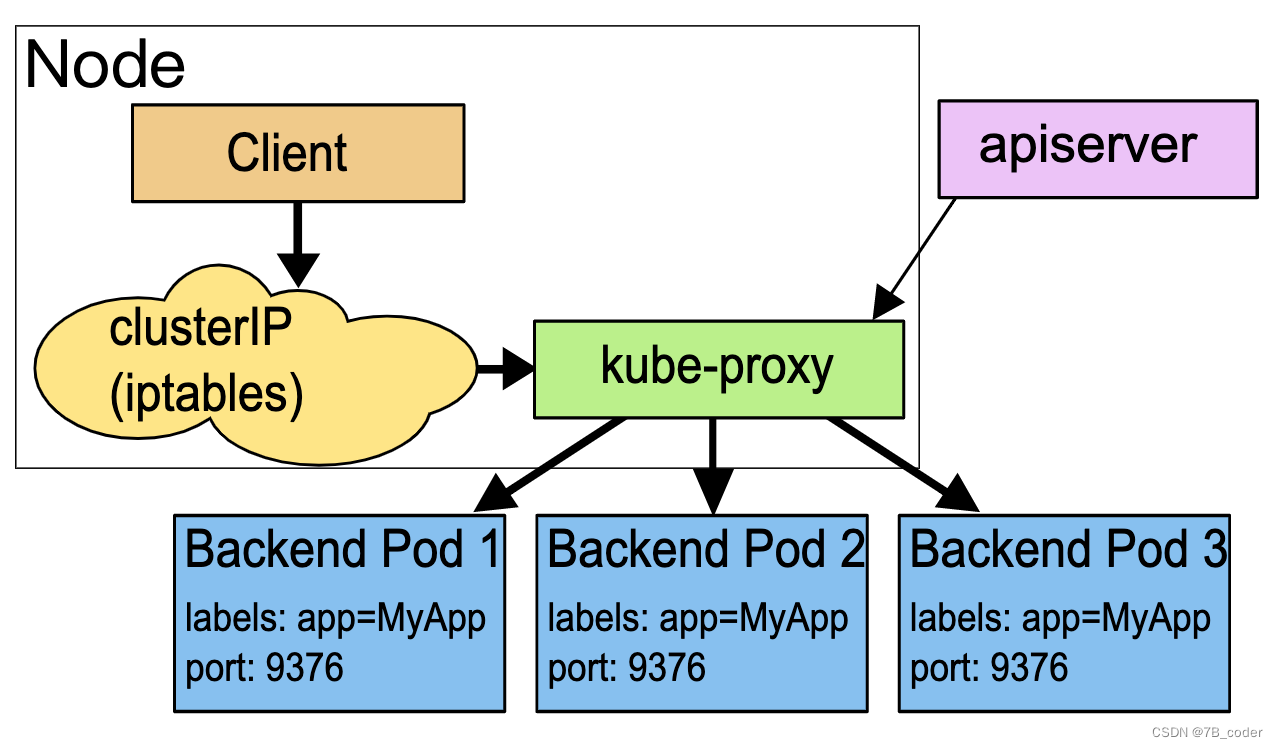
Userspace代理模式
这种模式下kube-proxy 会监视 Kubernetes master 对 Service 对象和 Endpoints 对象的添加和移除。 对每个 Service,它会在本地 Node 上打开一个代理端口(随机选择)。 任何连接到“代理端口”的请求,都会被代理到 Service 的backend Pods 中的某个上面。 使用哪个 backend Pod,是 kube-proxy 基于 SessionAffinity 来确定的。最后,kube-proxy通过配置 iptables 规则,将到达该 Service 的 clusterIP(虚拟 IP)和 Port 的请求重定向到代理端口,代理端口再代理请求到 backend Pod。
当有多个后端Pod的时候,选择Pod的算法有两种:一种是Round-Robin,如果一个Pod没有响应就试下一个;一种是选择与请求来源IP地址更接近的Pod。默认Pod选择算法是round-robin。
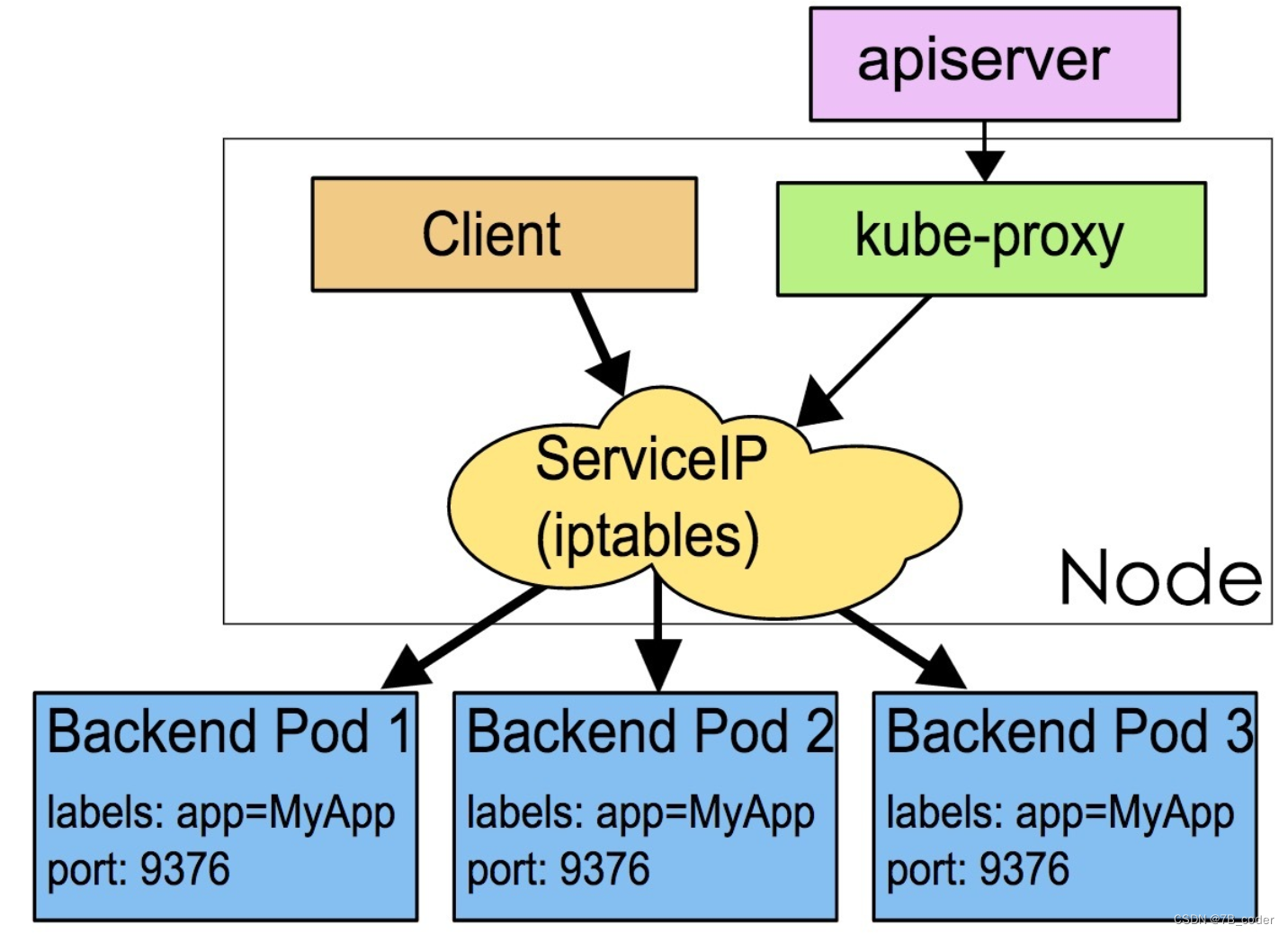
Iptables代理模式
在iptables模式下,创建Service时Node节点上的kube-proxy会创建两个iptables规则。一个为Service服务,将<ClusterIP, Port>的流量转给后端。另一个为EndPoints创建,用于选择Pod。默认情况下后端的选择是随机的。具体iptables规则示例如下:
-A KUBE-SVC-NWV5X2332I4OT4T3 -m comment --comment "default/hostnames:" -m statistic --mode random --probability 0.33332999982 -j KUBE-SEP-WNBA2IHDGP2BOBGZ -A KUBE-SEP-WNBA2IHDGP2BOBGZ -p tcp -m comment --comment "default/hostnames:" -m tcp -j DNAT --to-destination 10.244.1.7:9376
iptables模式下的kube-proxy不执行真正的数据转发,不需要在内核空间和用户空间进行切换,会比userspace模式下运行的更快更可靠。但是iptables模式下,如果选择的Pod没有响应,无法自动重试选择其他Pod,这个时候需要运行readiness probes(准备情况探测器)。kubelet使用readiness probes来探测容器还是可以开始接流量,将准备就绪的容器加入Service的EndPoints,将Pod未就绪的容器从EndPoints中删除,从而实现对Service的Endpoints的控制。
IPVS代理模式
IPVS模式跟iptables模式底层原理一致,都是基于netfilter hook函数。但是不同的是iptables规则是顺序匹配,当规则数较多时匹配时间较长;而IPVS模式是采用散列表作为存储数据结构,相比之下匹配时间会较短,能够更快的重定向流量。此外,ipvs还提供了多种负载均衡算法,比如rr(round-robin,轮询调度算法)、lc(least connection,最小连接数调度算法)、dh(destination hashing,目的地址散列调度算法)、sh(source hashing,源地址散列调度算法)、sed(shortest expected delay,最短期望延迟调度算法)、nq(never queue,永不排队调度算法)。需要注意的是IPVS模式需要在Node上预先安装ipvs内核模块,当kube-proxy配置为ipvs模式时,会先检测Node上是否安装了ipvs模块,如果未安装将使用iptables模式。Node上创建一个kube-ipvs0的虚拟网卡,将Service的VIP都绑定上去。
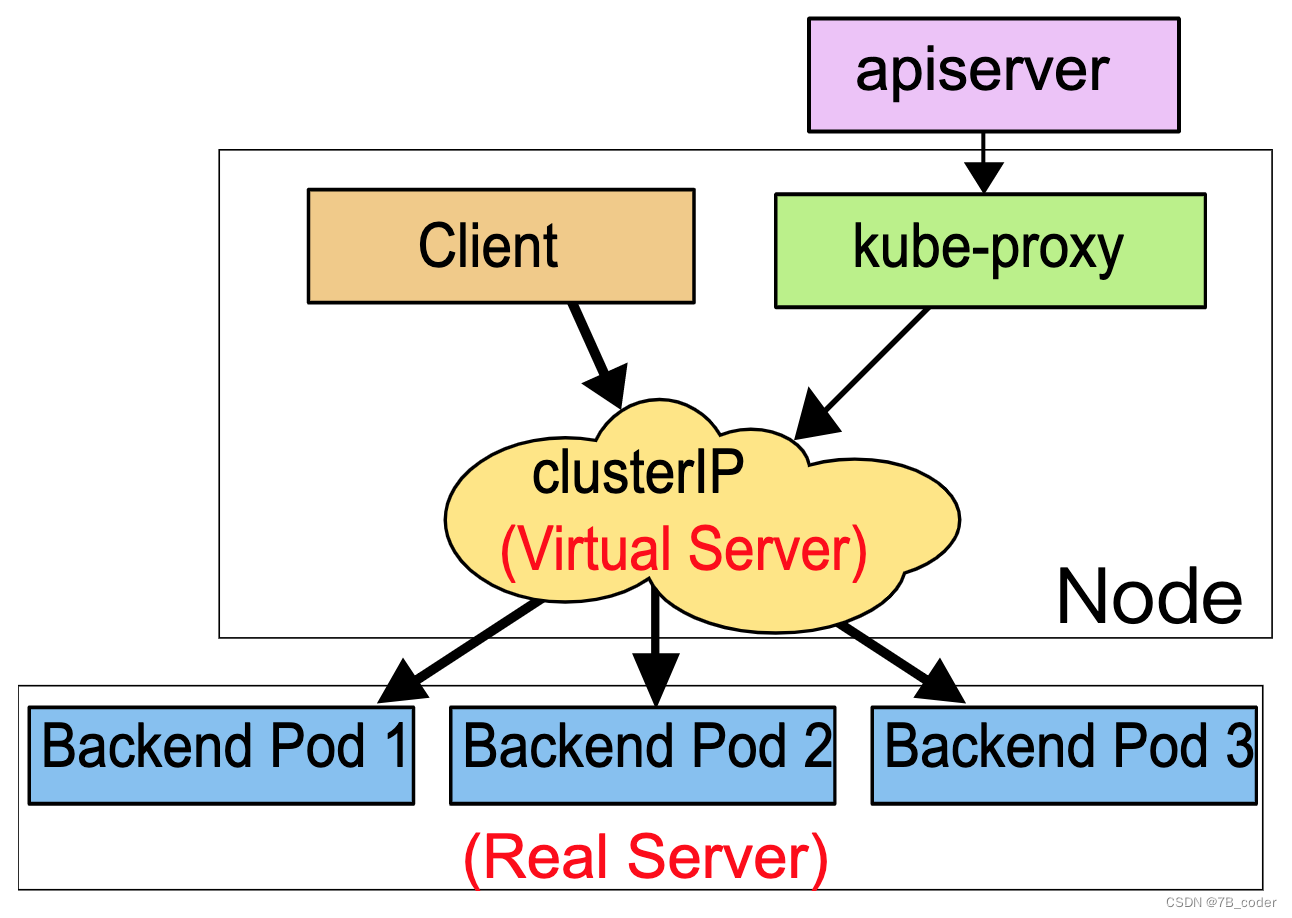
OVS方案
标准社区中是没有OVS模式的,只在一些OVS和Kubernetes整合的方案中存在。在OVS支持容器网络的方案中有如下四种方案,其中linux bridge和tun方案比较常用,算是iptables代理模式在适配OVS时的折中。linux bridge方案可以支持多租户场景下地址重叠(不同VPC的规则使用不同的linux bridge),同理ovs流表也可以支持多租户网络隔离,但是tun方案不行(tun上无法做service地址隔离)。
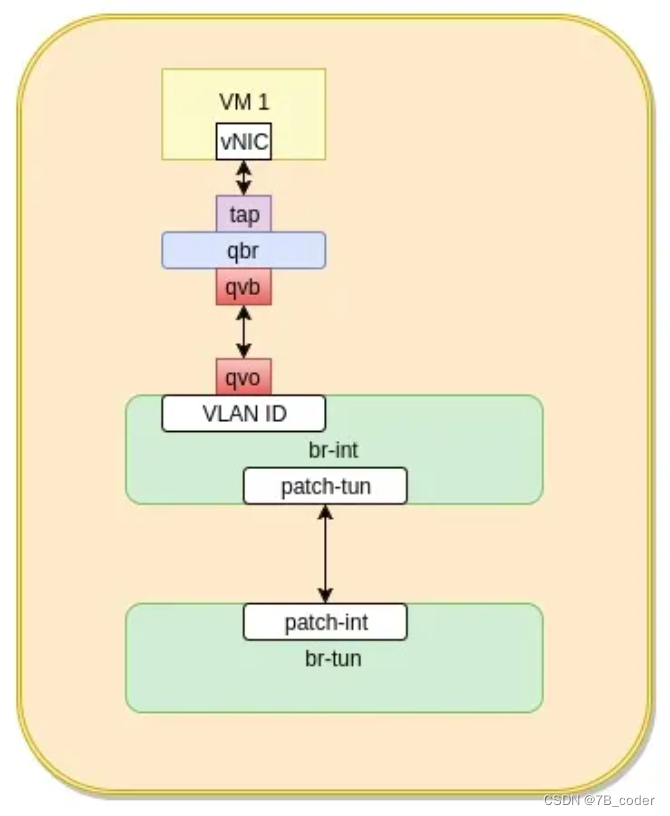
linux bridge+iptables方案
Openstack在ComputeNode上的网络拓扑是将虚机的TAP设备插在一个linux网桥qbr上,然后qbr再与ovs网桥br-int连接,具体如下左图。为什么不将虚机的网卡直接连接到 OVS 桥 br-int,官方说法是:“理想地,TAP 设备最好能直接挂在 br-int 上。由于OpenStack 使用 TAP 设备上的 iptables 规则来实现 Security Group,而 open vswitch 不支持在直接连到其网桥上的 TAP 设备上使用 iptables。因此,不得不增加 Linux bridge qbr 来将 TAP 设备连到 OVS bridge 上。”。简单地说,OpenStack 需要在 qbr 桥上使用 iptables 过滤进出虚机的数据包,而 br-int 上无法做到这一点。
容器网络也可以参考Neutron的OVS拓扑,在在容器虚拟网卡跟ovs bridge之间再添加一个linux网桥docker0,并在上面设置iptables的nat规则来实现Service,类似之前百度云虚拟网络BLB的TTM跑在qbr上。
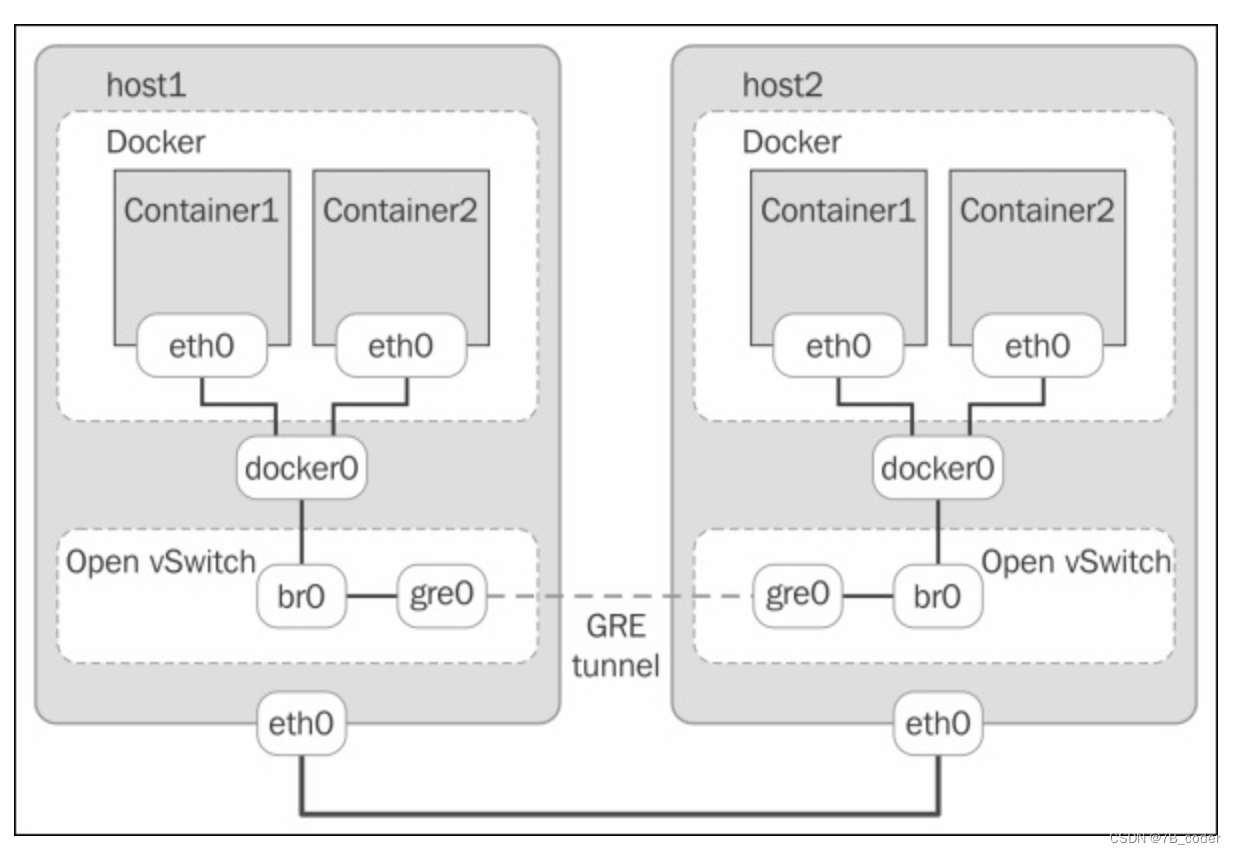
tun+iptables方案
Openshift的SDN采用这种方案,我们之前做的分布式Metadata也是采用这种方案。在OVS网桥br0上添加tun0设备,tun0是OVS 内部端口,它会被分配本机的 pod 子网的网关IP 地址,用于OpenShift pod 以及Docker 容器与集群外部的通信。通过OVS上流表配置规则,将Service的VIP流量导流到tun0设备上。针对tun0设备,可以在root ns中配置iptables nat规则来实现service。整个转发流程中不仅需要DNAT将目的地址VIP修改为后端pod的ip,还需要SNAT将源地址修改为tun0的ip,这样可以是的Service的回包依然能够回到tun0上,并再次走iptables实现De-SNAT,并再回到br0上最终送到对应的Pod。这种方案不仅可以解决宿主机访问Service,也可以解决Pod内访问Service。
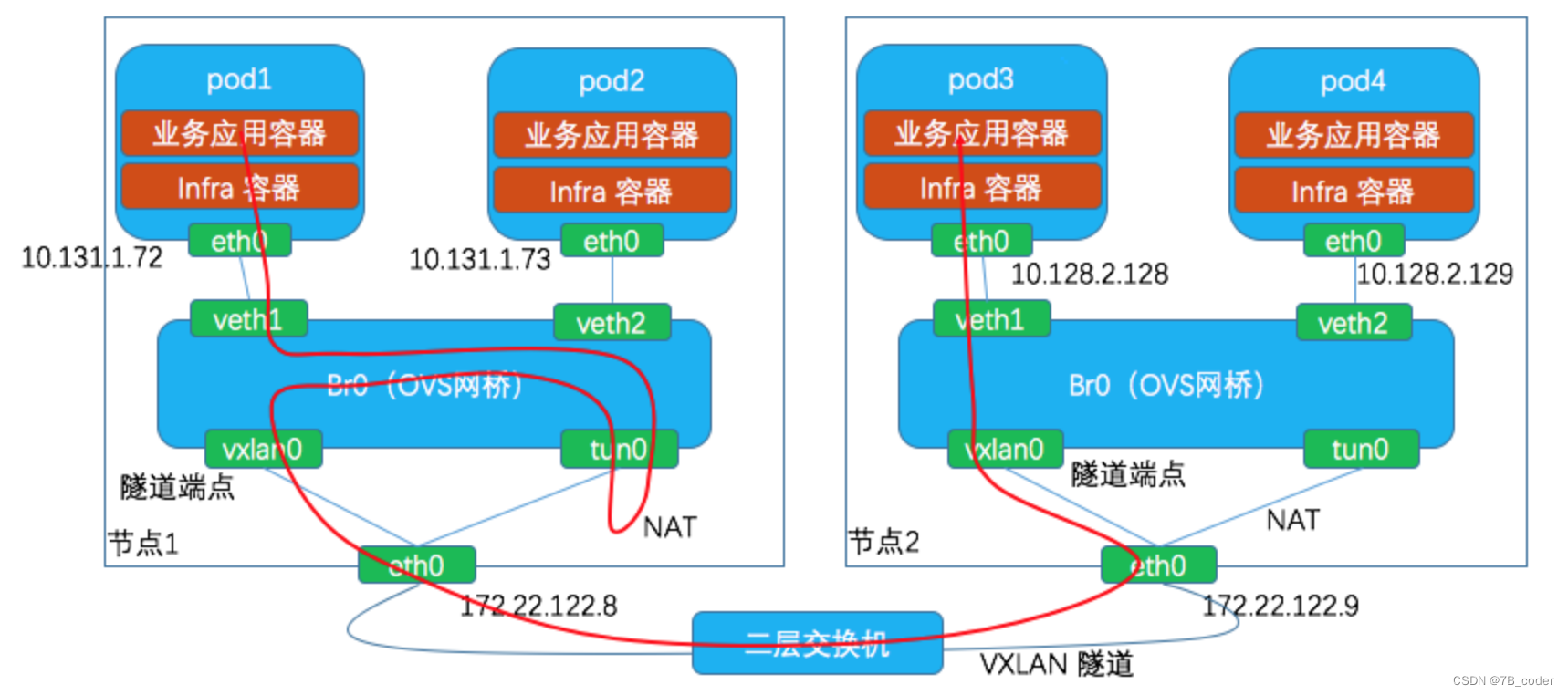
OVS上具体的流表Pipeline结构如下所示:
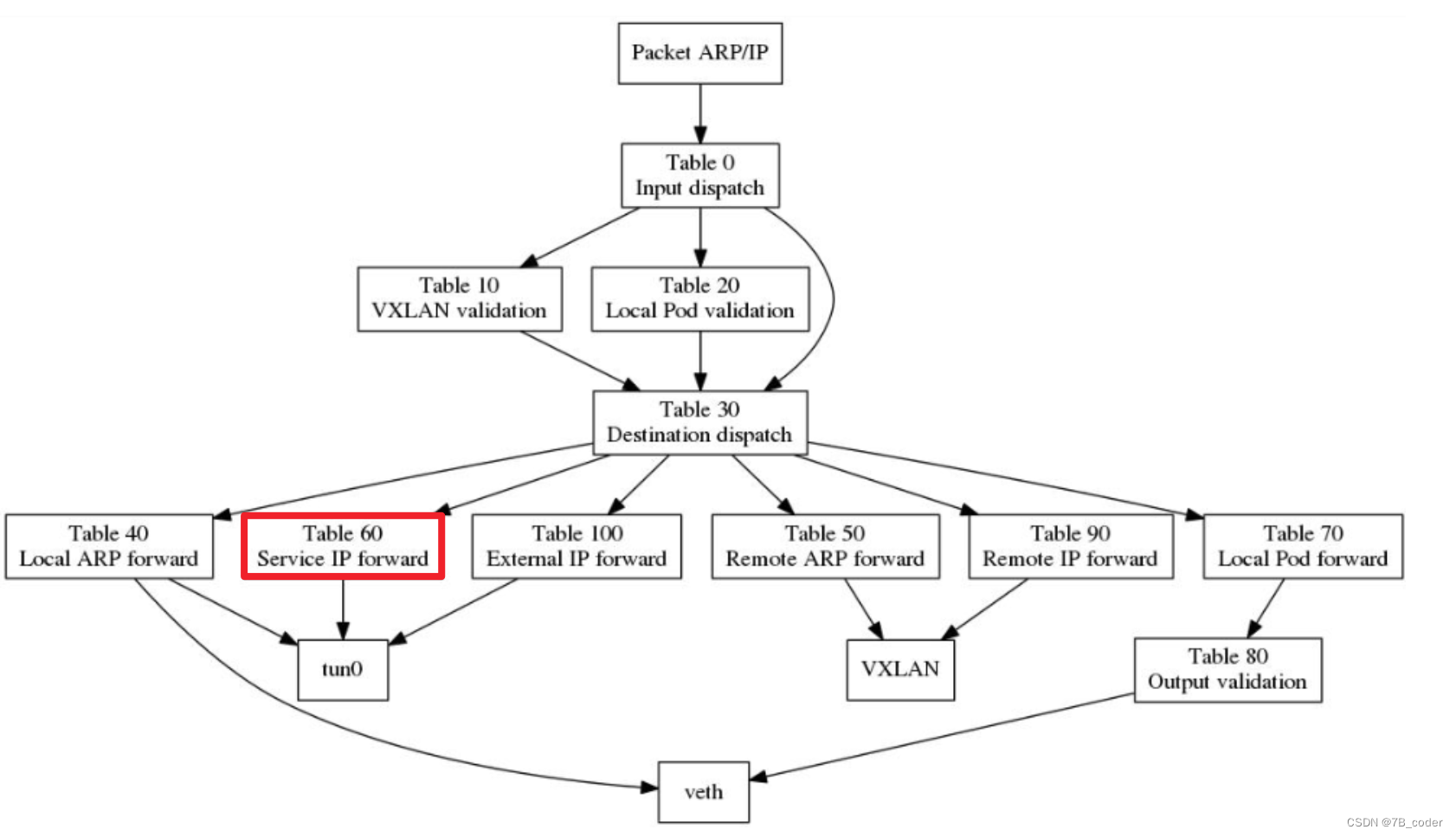
使用CT流表规则
OVS 2.5之后开始支持ConnTrack,其底层也是跟iptables一样使用的内核中的conntrack模块。我们可以使用OVS中的CT Action实现类似iptables中的NAT规则,使用Group规则来实现负载均衡中多个Pod后端的选取。
- table=0,ip,nw_src={pod_cidr},nw_dst={service_cidr},ct_state=-trk,action=ct(table=2)
-
- table=0,ip,nw_src={pod_cidr},nw_dst={pod_cidr},ct_state=-trk,action=ct(table=4)
-
- table=2,ip,nw_dst={svc1_ip},tp_dst={svc1_port},ct_state=+trk+new,action=group:1
-
- table=2,ip,nw_dst={svc2_ip},tp_dst={svc2_port},ct_state=+trk+new,action=group:2
-
- table=2,ct_state=+trk-new,action=table:4
-
- table=4 contains the original switching / routing rules
-
- group_id=1,type=select, bucket=ct(commit,nat(dst={pod1_ip}:{pod_port}),table=4,
-
- bucket=ct(commit,nat(dst={pod2_ip}:{pod_port}),table=4,
-
- bucket=ct(commit,nat(dst={pod3_ip}:{pod_port}),table=4

使用Stateless NAT规则
如果在看到Dst是Service IP的时候将其切换为Pod的IP,同时将Src修改为一个Shifted IP,比如10.244.x.y → 172.24.x.y。这种方式可以不使用任何内核中的规则,方便与一些DPDK之类的用户态程序整合。
- table=0,ip,nw_src={pod_cidr},nw_dst={service_cidr},action=table:2
-
- table=0,ip,nw_src={pod_cidr},nw_dst={shifted_pod_cidr},action=table:3
-
- table=0,ip,nw_src={pod_cidr},nw_dst={pod_cidr},action=table:4
-
- table=2,ip,nw_dst={svc1_ip},tp_dst={svc1_port},actions=load:44056->NXM_OF_IP_SRC[16..31],group:1
-
- table=3,ip,nw_src={pod1_ip},tp_src={pod_port},actions=mod_nw_src:{svc1_ip},mod_tp_src:{svc1_port}
-
- ,load:2804->NXM_OF_IP_DST[16..31],resubmit:4
-
- table=4 contains the original switching / routing rules
-
- group_id=1,type=select, bucket=mod_nw_dst:{pod1_ip},mod_tp_dst:{pod_port},resubmit=4,
-
- bucket=mod_nw_dst:{pod2_ip},mod_tp_dst:{pod_port},resubmit=4,
-
- bucket=mod_nw_dst:{pod3_ip},mod_tp_dst:{pod_port},resubmit=4
就绪探针
kubelet 使用 liveness probe(存活探针)来确定何时重启容器。例如,当应用程序处于运行状态但无法做进一步操作,liveness 探针将捕获到 deadlock,重启处于该状态下的容器,使应用程序在存在 bug 的情况下依然能够继续运行下去。
Kubelet 使用 readiness probe(就绪探针)来确定容器是否已经就绪可以接受流量。只有当 Pod 中的容器都处于就绪状态时 kubelet 才会认定该 Pod处于就绪状态。该信号的作用是控制哪些 Pod应该作为service的后端。如果 Pod 处于非就绪状态,那么它们将会被从 service 的 load balancer中移除。
Ingress
Service 虽然解决了服务发现和负载均衡的问题,但它在使用上还是有一些限制:只支持4层负载均衡,不支持7层负载均衡;对外访问的时候,NodePort 类型需要在外部搭建额外的负载均衡,而 LoadBalancer 要求 kubernetes 必须跑在支持的 cloud provider 上面,Pod漂移后NodeIP也会变化。Ingress 就是为了解决这些限制而引入的新资源,主要用来将服务暴露到 cluster 外面,并且可以自定义服务的路由访问策略。
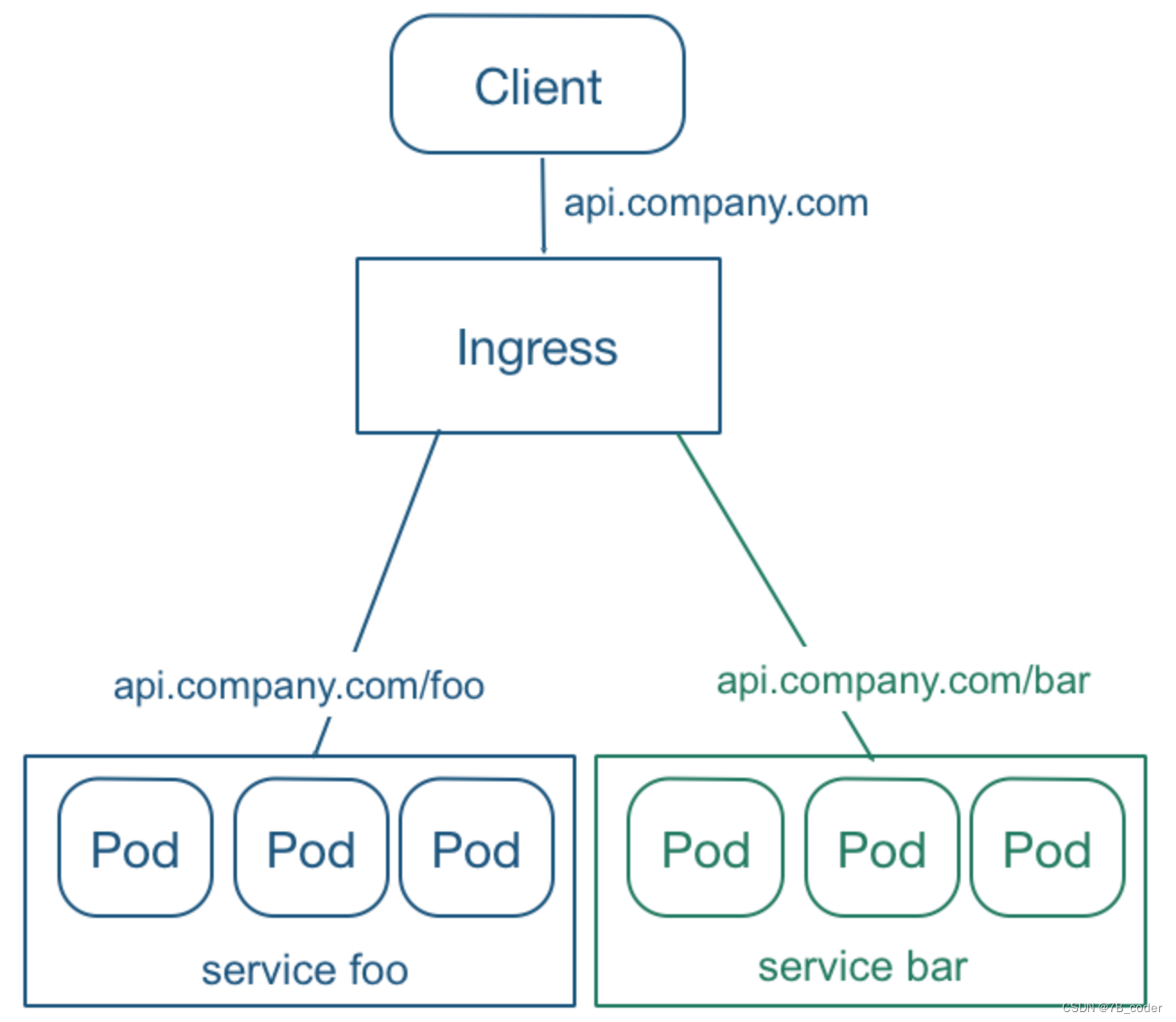
Ingress 可以给 service 提供集群外部访问的 URL、负载均衡、SSL 终止、HTTP 路由等。为了配置这些 Ingress 规则,集群管理员需要部署一个 Ingress controller,它监听 Ingress 和 service 的变化,并根据规则配置负载均衡并提供访问入口。在TLS场景,可以通过指定包含 TLS 私钥和证书的 Secret来加密 Ingress。
Ingress 正常工作需要集群中运行 Ingress Controller。Ingress Controller 与其他作为 kube-controller-manager 中的在集群创建时自动启动的 controller 成员不同,需要用户选择最适合自己集群的 Ingress Controller,或者自己实现一个。Ingress Controller 以 Kubernetes Pod 的方式部署,以 daemon 方式运行,保持 watch Apiserver 的 /ingress 接口以更新 Ingress 资源,以满足 Ingress 的请求。常见的有Nginx Ingress Controller和Traefik Ingress Controller。下图是Nginx Ingress的工作流程,Nginx Pod直接访问具体Service的Pod,而不是通过Service的ClusterIP(通常后端Service使用Headless Service,没有ClusterIP):
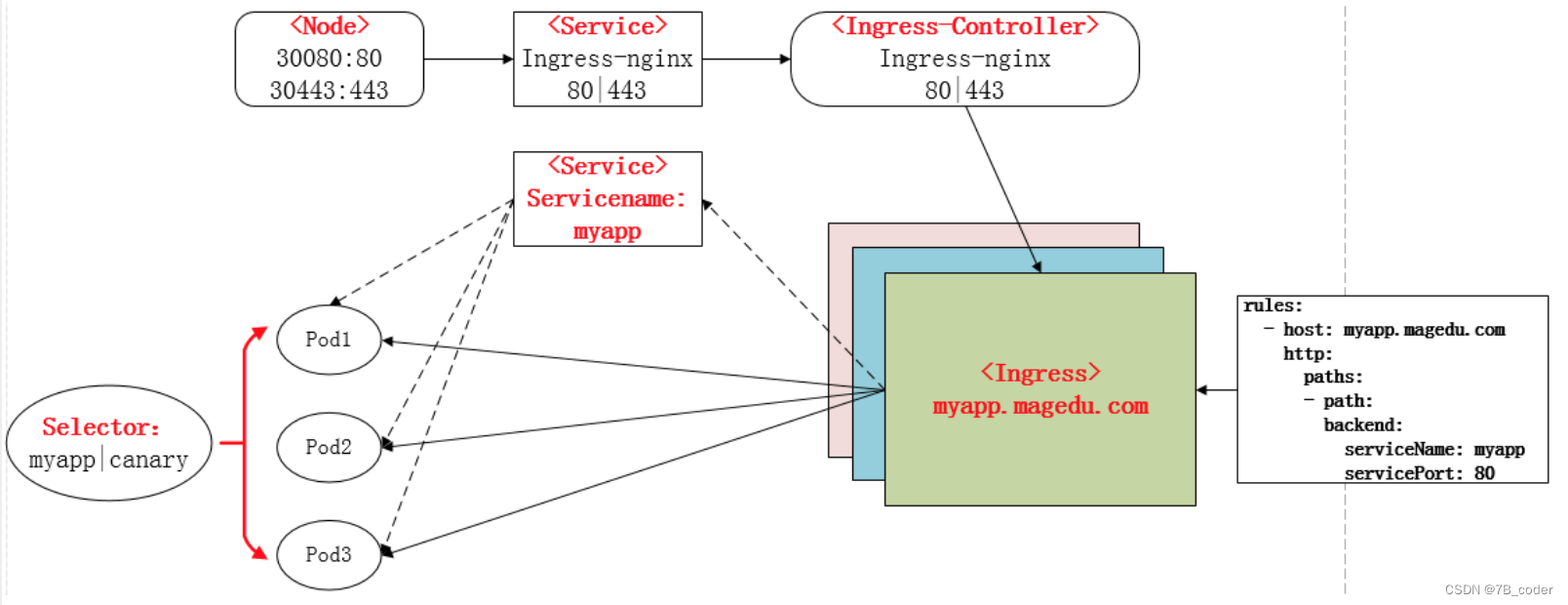
外界访问Service
对一些应用(如 Frontend)的某些部分,可能希望通过外部Kubernetes 集群外部IP 地址暴露 Service。Kubernetes ServiceTypes 允许指定一个需要的类型的 Service,默认是 ClusterIP 类型。
Type 的取值以及行为如下:
-
Cluster IP:只在Cluster内部能够访问的Virtual IP(通过kube-proxy在Node上配置iptables规则,将ClusterIP DNAT到具体Service的PodIP)
-
Node Port:通过NodePort将Virtual IP暴露给Cluster外部(通过yaml文件中显式创建nodeport,底层自动创建ClusterIP,通过iptables将NodePort转到ClusterIP,再转到具体Service的PodIP)
-
Load Balancer:将K8S内部的Serivce通过云厂商的LoadBalancer暴露给外部(底层自动创建NodePort和ClusterIP,将NodePort作为RealServer挂载到云上LB)
-
ExternalName:将K8S内部DNS CNAME指向到外部DNS,并不指向K8S集群内部的Pod
公有云上容器网络方案
各家公有云厂商的容器网络方案有两种方案:
-
VPC路由方案
-
ENI弹性网卡和辅助IP方案
VPC路由
类似Flannel为每个Node分配一个网段,在公有云上使用实例路由的方式。
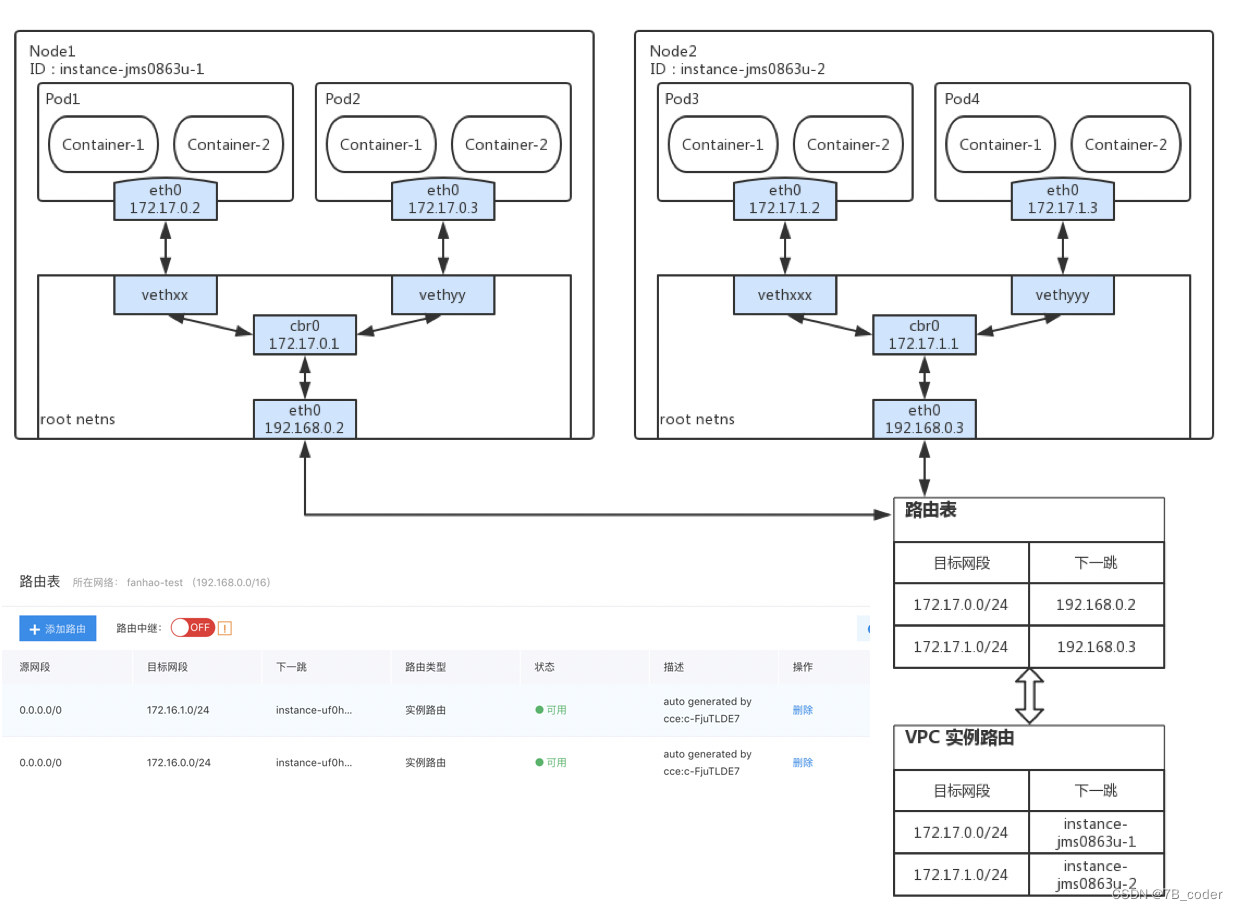
ENI
VPC路由方案虽然能够解决容器互通的需求,但是因为容器网络并没有被VPC纳管,只能依靠路由表进行引流。由于容器网络没有被VPC管理,在对等连接、专线等混合云场景容易出现VPC对端IP地址与容器网络地址冲突。为了解决地址冲突的问题,一种直观的解决方案是为Pod分配VPC内的地址。在ENI弹性网卡产品出来之后,可以简单的为每个Pod分配一个ENI的方式实现每个Pod一个IP,也可以通过ENI上辅助IP的方式来实现这个功能。
ENI在产品设计上都是有一些随资源规格相关的配额限制,下面是阿里云ENI的规格限制:
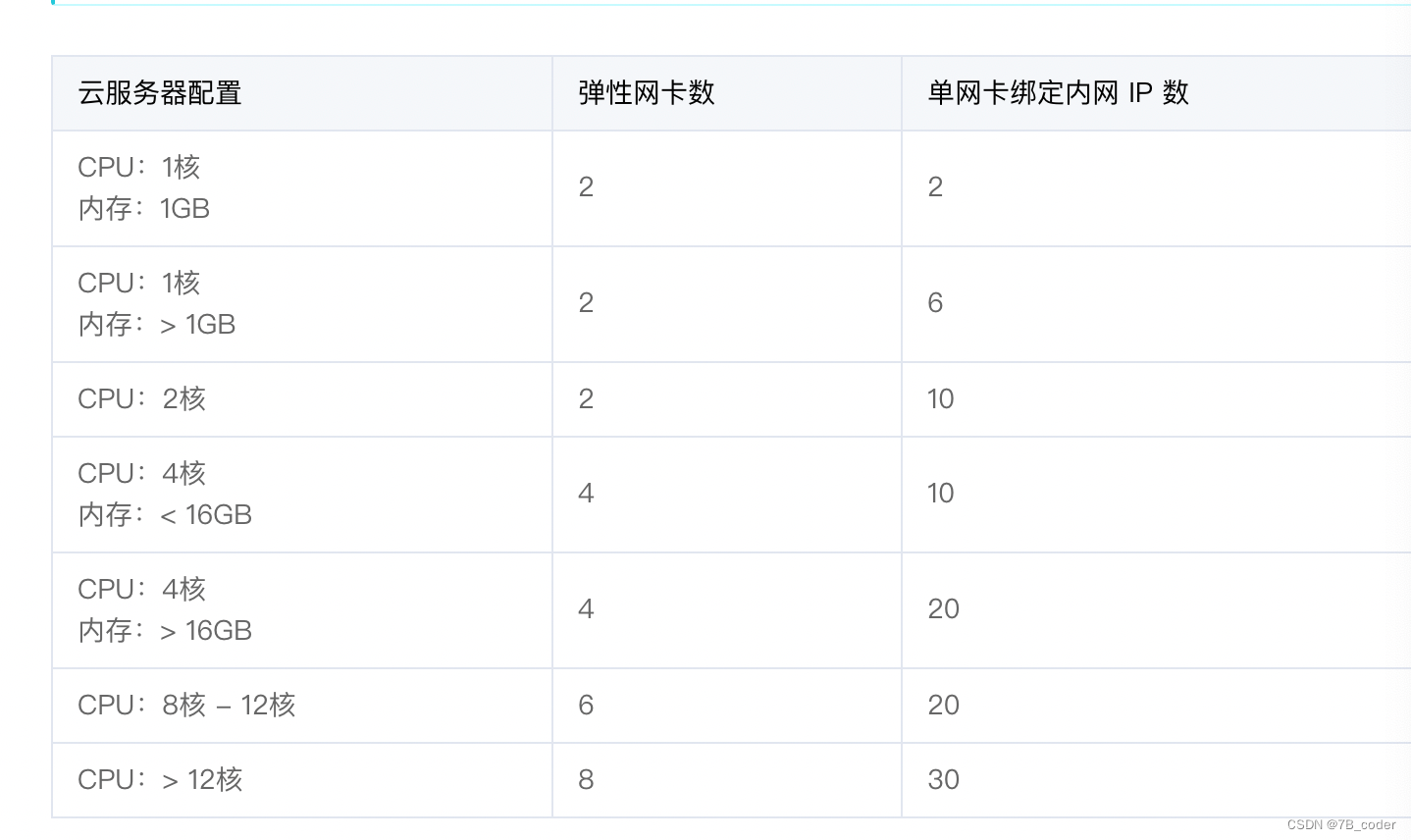
这里面需要注意的是由于QEMU虚拟的机器模型和PCIE总线的限制,只能插入32个PCIE设备,所以单个VM能够插入的ENI数量也是有限的,不能为每个Pod创建一个ENI。同时由于规格限制中单个ENI上最多能够挂载辅助IP的数量也有限制,所以也不能只插入一个ENI为这个VM上每个Pod创建一个辅助IP。使用ENI实现容器网络的话,就需要采用多弹性网卡多辅助IP的方式,按照VM规格最大辅助IP数量来计算需要多少个弹性网卡。
单ENI多辅助IP也有多种容器网络方案:
-
bridge:受限于VPC的源MAC检查
-
策略路由:走Host协议栈,性能下降明显
-
MACVLAN:受限于VPC的源MAC检查
-
IPVLAN:无MAC问题,不过Host协议栈,性能好
IPVLAN虽然性能很好,但是由于其驱动限制无法支持Pod和Node互通,并且Service的kube-proxy需要走Node的三层协议栈,这些都需要针对IPVLAN方案进行细化。
百度云方案
IPVLAN L3 + veth PTP(Point-to-Point),为每个Pod插入两个网卡,一个网卡是Pod的主网卡,一个网卡用来跟Node和Service通信,跟Node和Service通信的网卡上也需要配置IP地址。

阿里云方案
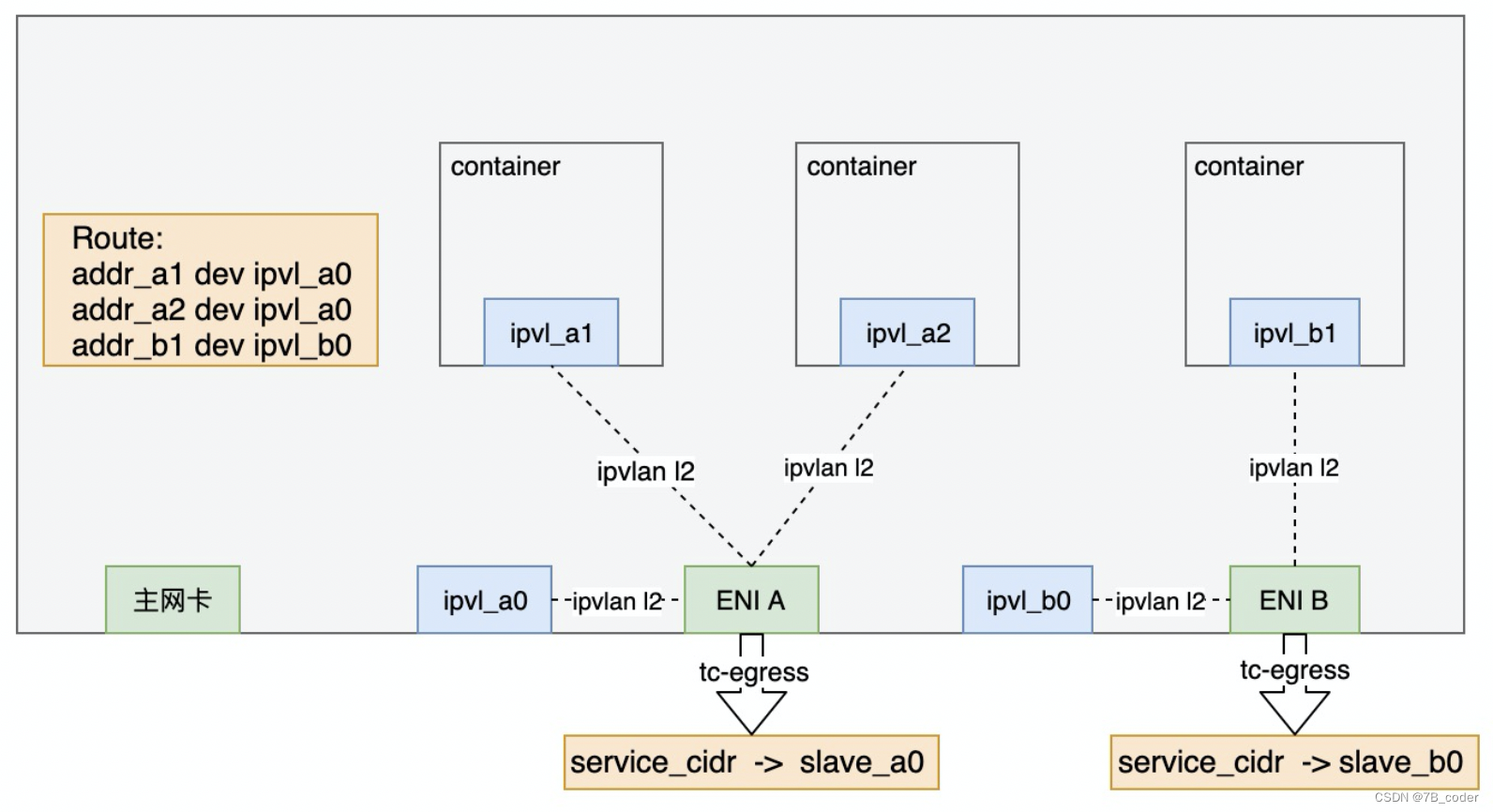
IPVLAN L2+TC,无需veth Point-to-Point,在Node的主设备上除了Pod的IPVLAN从设备之外再创建一个Node的IPVLAN从设备用于Node与Pod通信。在主设备上设置TC重定向规则,将Service流量重定向给Node的IPVLAN从设备。
LB FastPath演进
借助于公有云网络的VPC路由和ENI方案解决了Pod间容器网络问题,对于Service如果继续采用K8S原生的iptables/ipvs实现方式,维护起来代价依然较大,可以考虑将Service也使用公有云网络的LB进行实现,不仅作为Service外部访问入口,也作为内部访问入口,将Service的VIP也纳入到VPC地址空间中。
K8S原生的Service实现相当于一种分布式LoadBalancer,Client上直接进行负载均衡,带外集中式健康检查。这种方案的好处是Service流量直接点对点,没有流量瓶颈、延迟也比较低、故障域较小。如果直接将Service映射到BLB上,BLB采用FullNAT方式的话,这样会存在流量瓶颈、较大的故障域、延迟会Double。这个时候我们需要对LB进行FastPath优化,来解决这些问题。
顾名思义,LB FastPath就是实现LB流量不过集中式的BGW网关,在LB三次握手完成之后即可通知Client和RealServer进行直通,在当前DSR数据流的基础上,Client上将后续发出的报文伪装成BGW发出的报文(实际过程是将VIP:VPORT DNAT成RIP:RPORT)。
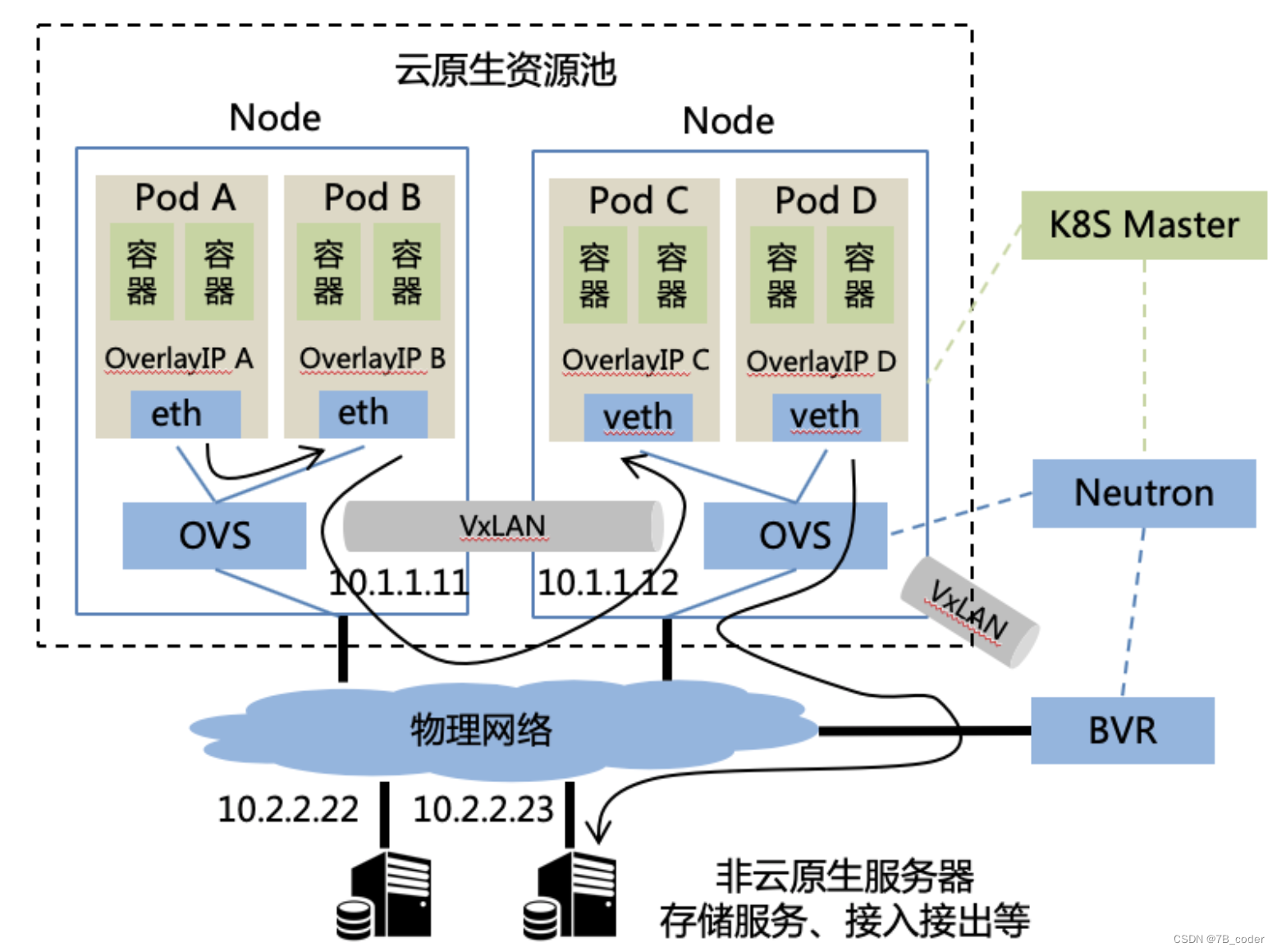
百度云云原生容器网络方案
需求
-
需要Pod间东西向互访(Pod使用11.0.0.0/8,需配置默认路由)
-
需要Pod与非容器物理机东西向互访
-
需要跨机房网络QoS(CN设置overlay外层DSCP)
-
不需要组播、广播
-
不需要IPv6
-
不需要安全组
-
不需要DHCP(IPAM由K8S负责,指定IP创建Port)
-
不需要DNS(DNS由K8S的kube-dns/CoreDNS负责)
Service
百度IDC网络场景主要有如下几种:
-
外到内:EBGW+BFE的7层访问
-
内到外:BigNAT
-
内到内:BNS服务发现,IBGW VIP
K8S容器网络要在内部落地,除了传统K8S集群内Pod和Service的通信之外,还需要解决如下问题:
-
IDC非K8S机器和K8S内部Pod间通信
-
IDC非K8S机器和K8S内部Service间通信
-
外网访问K8S的Service/Ingress
IDC非K8S机器和K8S内部Pod间通信
通过上面的BVR可以将PodIP暴露到IDC网络中,Neutron采取Port的FixedIP=FloatingIP的方式,这样无需做NAT对业务比较友好。
IDC非K8S机器和K8S内部Service间通信
如上面百度IDC网络场景的分析,IDC非K8S机器要访问K8S内部的Service,我们需要兼容支持BNS和BGW VIP两种方式。BNS等同于K8S中的Headless Service,大部分时候将负载均衡交由RPC框架或者是Mesh,BGW和BFE也都支持挂载BNS。因此将Pod IP与BNS打通之后,就可以相对完美的支持IDC内服务访问常用的BNS、BGW VIP和BFE三种方式。
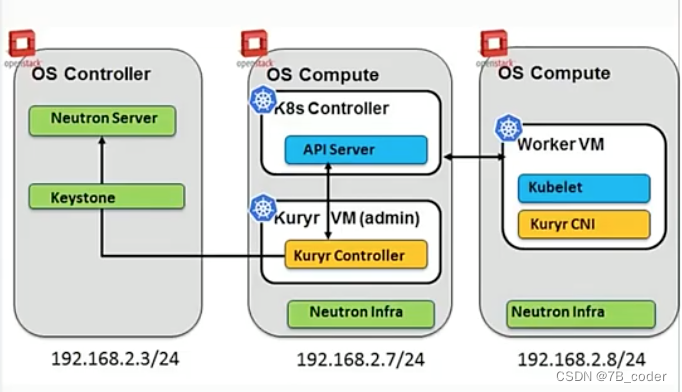
Kuryr
Kuryr是一个OpenStack子项目,是一个捷克语单词,意思是“信使”。顾名思义,Kuryr是连接K8S和Neutron之间的信使,通过使用K8S的CNI对接Neutron实现K8S的容器网络,借助Neutron的Overlay能力实现容器网络,在VM场景中可以避免嵌套Overlay。
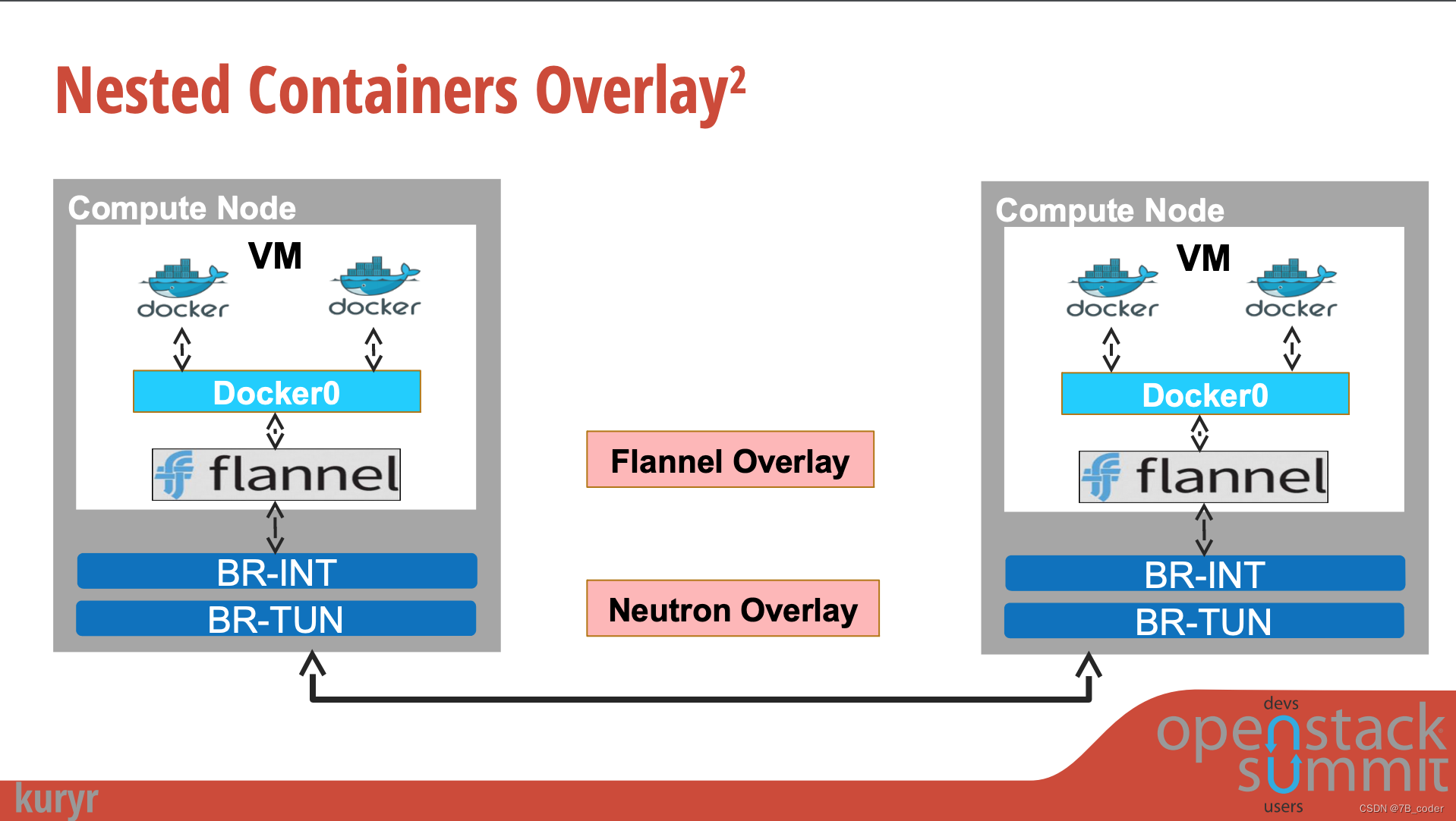
Kuryr Controller主要实现了两个映射:
-
K8S的Pod映射到Neutron的Port (Pod → Port)
-
K8S的Service映射到Neutron的Loadbalancer(Service → VS, EndPoint → RS)
Kuryr的整体架构包括两部分:
-
Kuryr Controller,集中式控制器与Neutron进行Port和Loadbalancer的对接
-
Kuryr CNI,部署在每一个Worker Node上执行Pod绑定
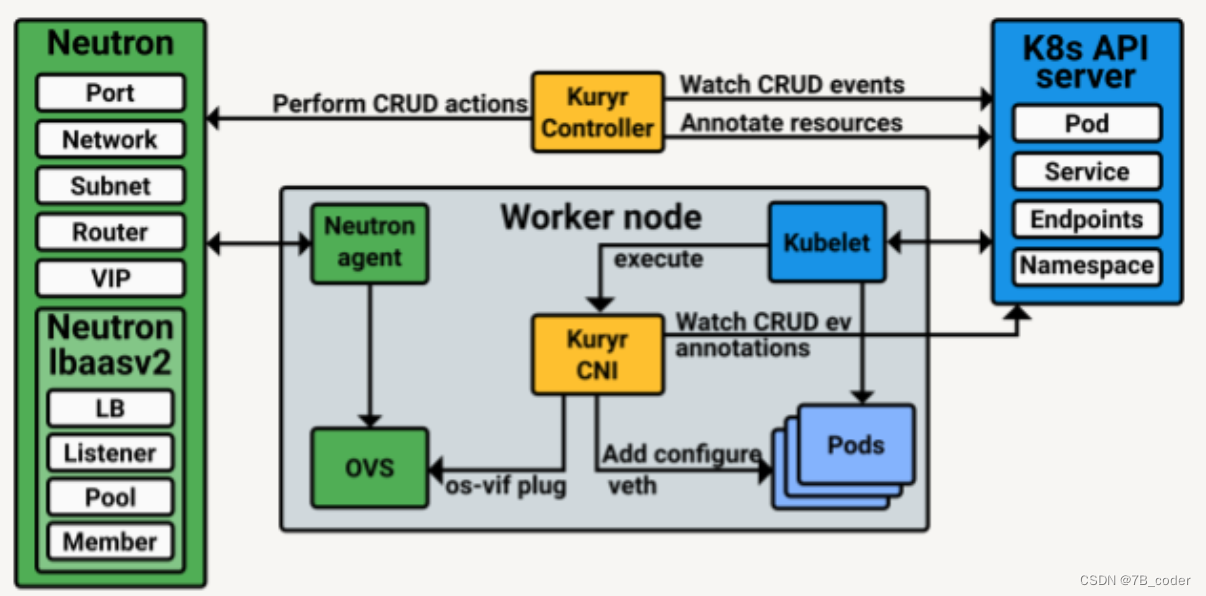
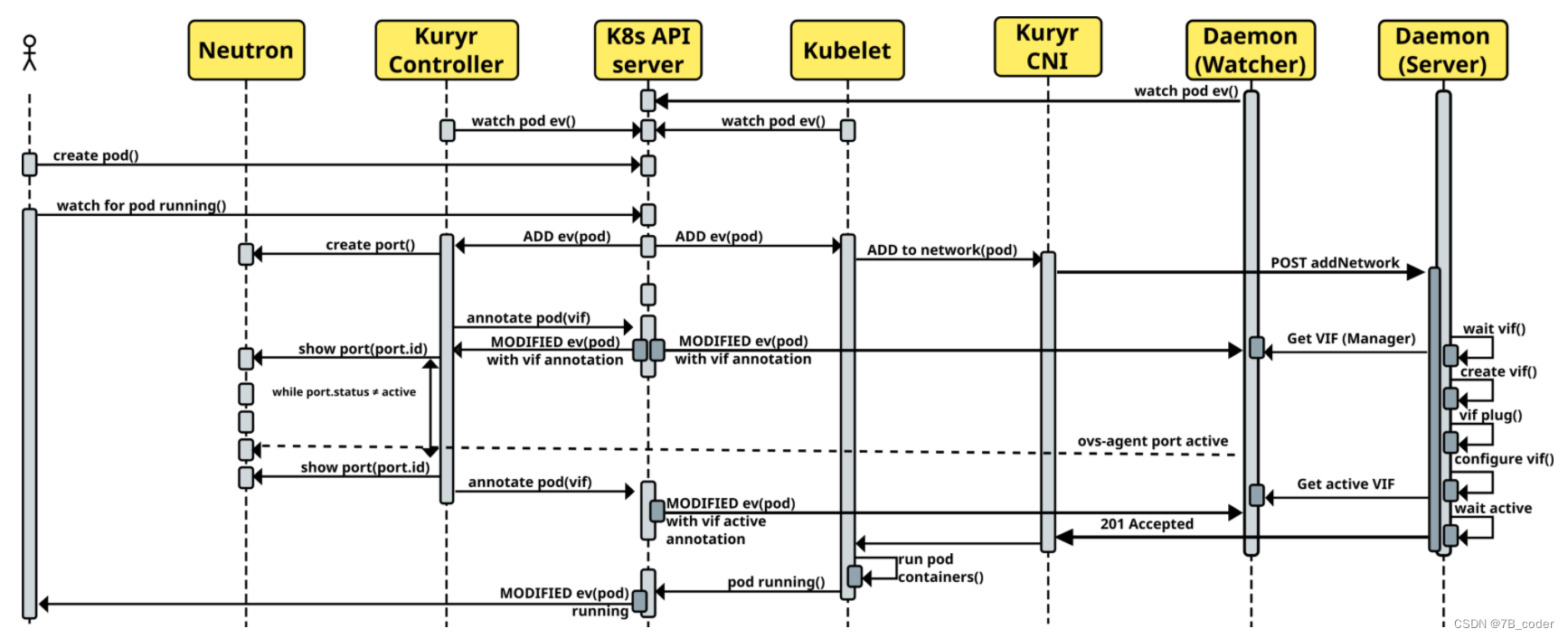
Kuryr的设计是一个松耦合的架构,CNI驱动不直接依赖于Neutron,也不直接与Kuryr Controller通信,他们借助K8S的APIServer进行元信息传递(使用Pod元信息中的annotation)。CNI驱动也分为Client和Server两部分,Server是每个节点上的一个守护进程,Server响应来自Client的CNI网络创建和释放请求,并从APIServer中Watch Pod的网络信息,执行vif的绑定操作。具体执行流程如下:
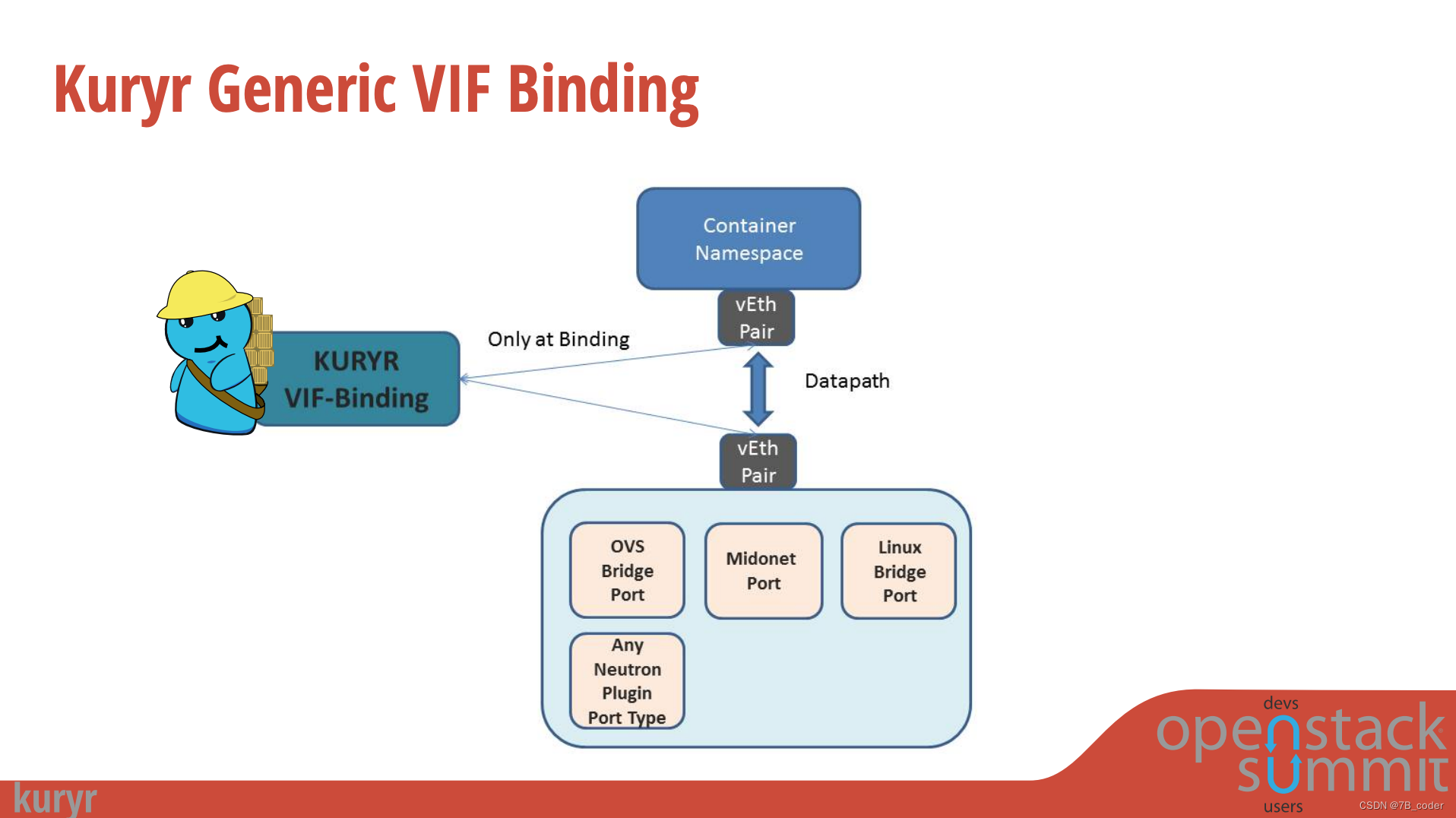
Kuryr除了对接Neutron API来实现一些K8S容器网络概念与Neutron的对接之外,还有一个通用的VIF绑定层来在Node上执行VIF的绑定,创建一个veth pair,一块是Container Interface用于接在容器的Network Namespace中,一块是Host Interface用于接在Neutron的L2拓扑中。这里面包括一些通用的工作比如IPAM和vEth的创建等,也有可以根据vif_type执行不同vendor的绑定脚本。
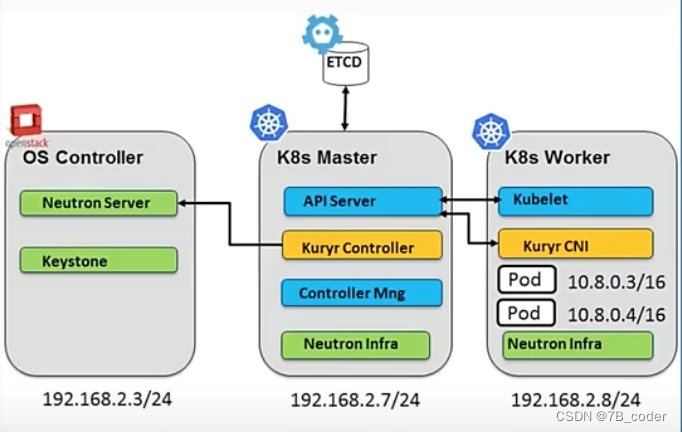
Kuryr支持两种部署模式,一种是部署在裸机上,一种是部署在VM上。部署在裸机上比较容易理解,部署在VM中依然是单层Overlay,只是将整个K8S部署在VM中,打通Kuryr Controller与部署在Underlay上的OpenStack之间的访问通路。无论是裸机部署还是VM部署,底层思路是一样的,为每个Pod分配一个Neutron的Port,或者是Port上的一个辅助IP。
多云容器网络方案
现在越来越多的互联网公司开始上云,基于稳定性和议价因素他们大都选择使用Kubernetes做多云。K8S在做多云的时候,需要打通多个K8S集群的容器网络,解决多个K8S集群上面容器网络中提到的Pod间通信、Pod与Service的通信和外部访问Service问题。
虽然Kubernetes社区从1.3版本开始提供了Federation的方案,实现跨 Region 跨服务商 Kubernetes 集群服务。每个 Kubernetes Federation 有自己的分布式存储、API Server 和 Controller Manager。用户可以通过 Federation 的 API Server 注册子 Kubernetes Cluster,通过 Federation 的 API Server 创建、更改 API 对象时,会在子 Kubernetes Cluster 都创建一份对应的 API 对象,实现K8S集群的元信息同步。但是由于当前项目较新不成熟,且存在Federation控制面故障会波及全部Kubernetes集群,同时由于多K8S集群还引入了Template进行不同集群的Selector和配置派生,这些都带来了一些复杂性,因此较少在生产环境中使用。
Pod间互通
Pod间互通,不管容器网络使用的是VPC路由还是ENI方案,都可以通过专线+VPC路由的方式来打通。
Pod访问Service/外部访问Service
跨Cluster的Pod访问Service和外部访问Service是一个问题,将Service通过Cloud Provider的LoadBalancer暴露出去,这样Service的VIP就从只能内部访问变为外部也能访问了,通过上面Pod间互通的VPC专线路由配置就可以实现Pod访问Service。
如果专线对端是Underlay网络,可以使用Calico通过BGP动态路由方式将Service的VIP暴露出来,这样通过VPC专线路由也可以实现云上Pod访问云下Service。需要注意的是公有云VPC一般不支持BGP动态路由,因此无法在公有云上使用Calico BGP路由方式来发布Service的VIP,只能通过公有云的LoadBalancer来暴露出来。
DNS
可以通过Local DNS配置实现不同域名后缀递归到不同的K8S集群的kube-dns,每个集群的kube-dns也通过上面Pod访问Service中的LoadBalancer方式暴露到外部。比如在每个Node上部署一个dnsmasq/unbound都可以实现缓存和后缀按需递归(最初AWS的混合云DNS方案就是这样的)。
参考
Kuryr Kubernetes Integration Design
Kubernetes-Networking-Made-Easy-with-Open-vSwitch-and-OpenFlow-Péter-Megyesi-LeanNet-ltd..pdf

