
热门标签
热门文章
- 1Python实现SSA智能麻雀搜索算法优化BP神经网络分类模型(BP神经网络分类算法)项目实战_ssa-bpnn python
- 2这7本书都没有,还学什么Web安全?(附全套PDF)_白帽子讲web安全pdf下载
- 3【web安全】IDEA+Tomcat+JSP
- 4水稻微生物组时间序列分析4-随机森林回归_微生物组 时序数据
- 5教程|Unity中使用Tilemap快速创建2D游戏世界_unity ruletile草地
- 6【论文阅读】InstructGPT: Training language models to follow instructions with human feedback
- 7python3 svm实现_svm 完整代码示例 python3
- 8机器学习:基本概念_机器学习的基本概念
- 9调频连续波(FMCW)雷达目标轨迹提取_fmcw雷达的重复频率与采样率
- 10ZZULIOJ:1016: 银行利率_设银行1年期定期存款年利率为2.25%,存款本金为capital元,试编程计算并输出n年后的
当前位置: article > 正文
82.长短期记忆网络(LSTM)以及代码实现_lstm代码实现
作者:羊村懒王 | 2024-02-29 20:13:21
赞
踩
lstm代码实现
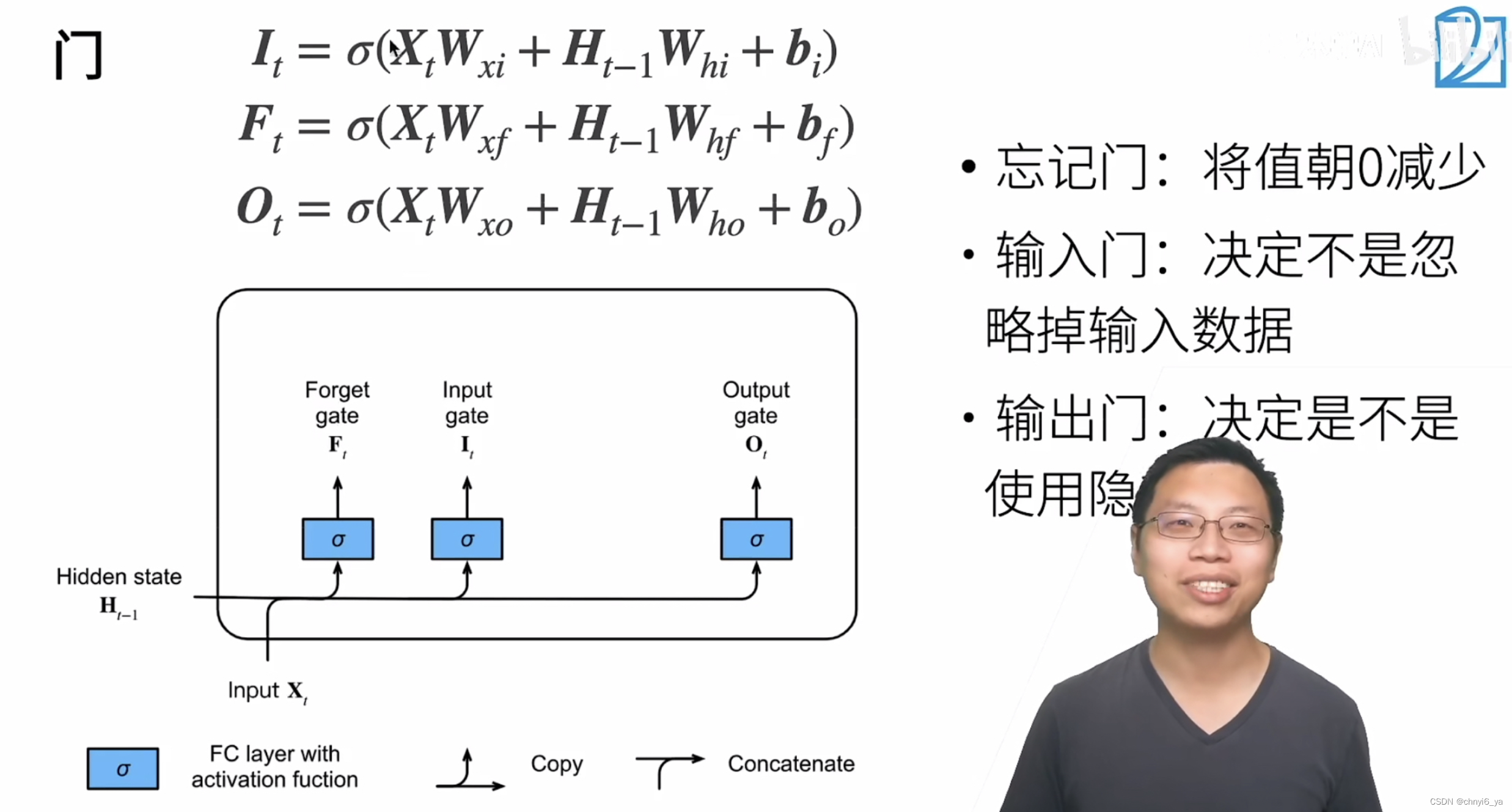
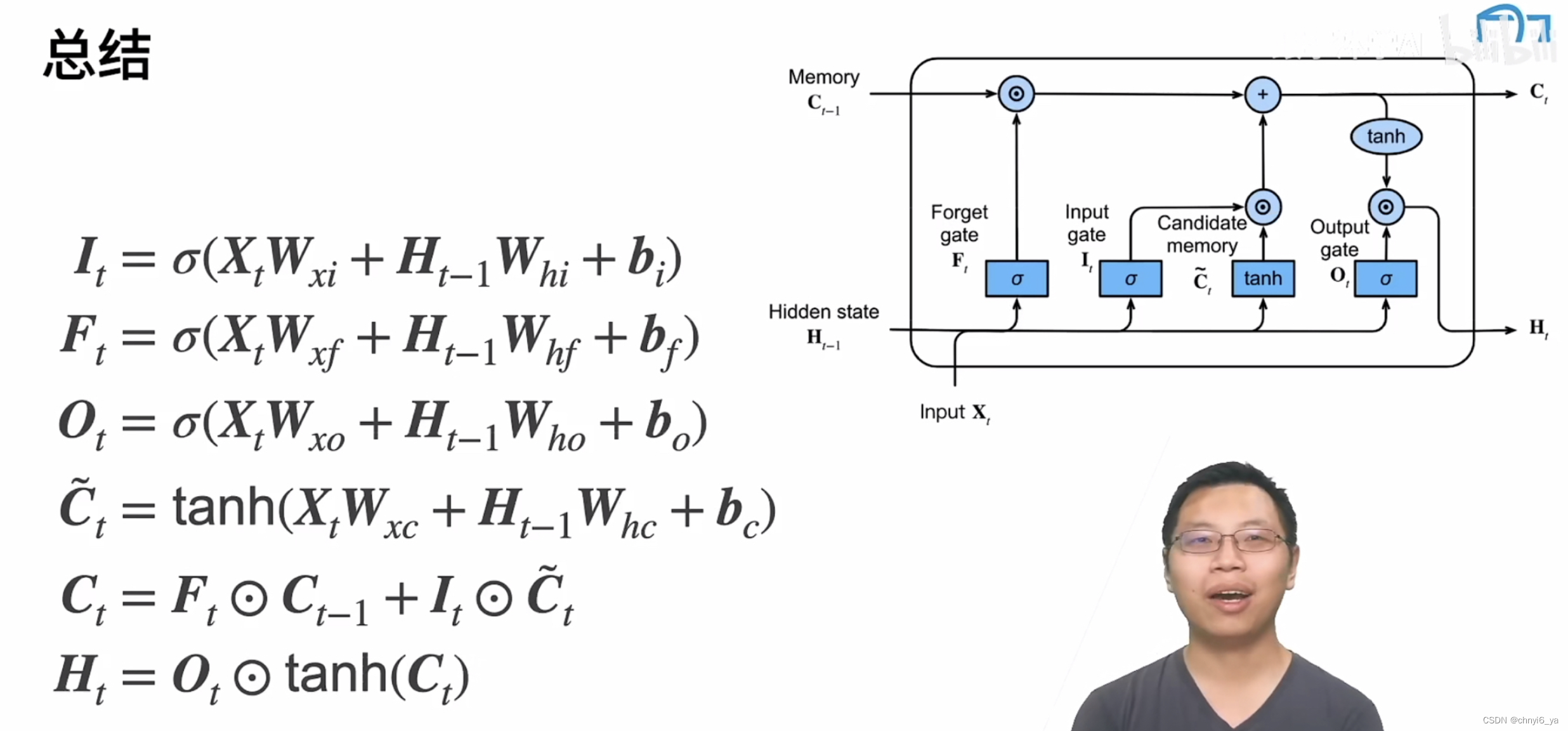
1. 长短期记忆网络
- 忘记门:将值朝0减少
- 输入门:决定不是忽略掉输入数据
- 输出门:决定是不是使用隐状态
2. 门
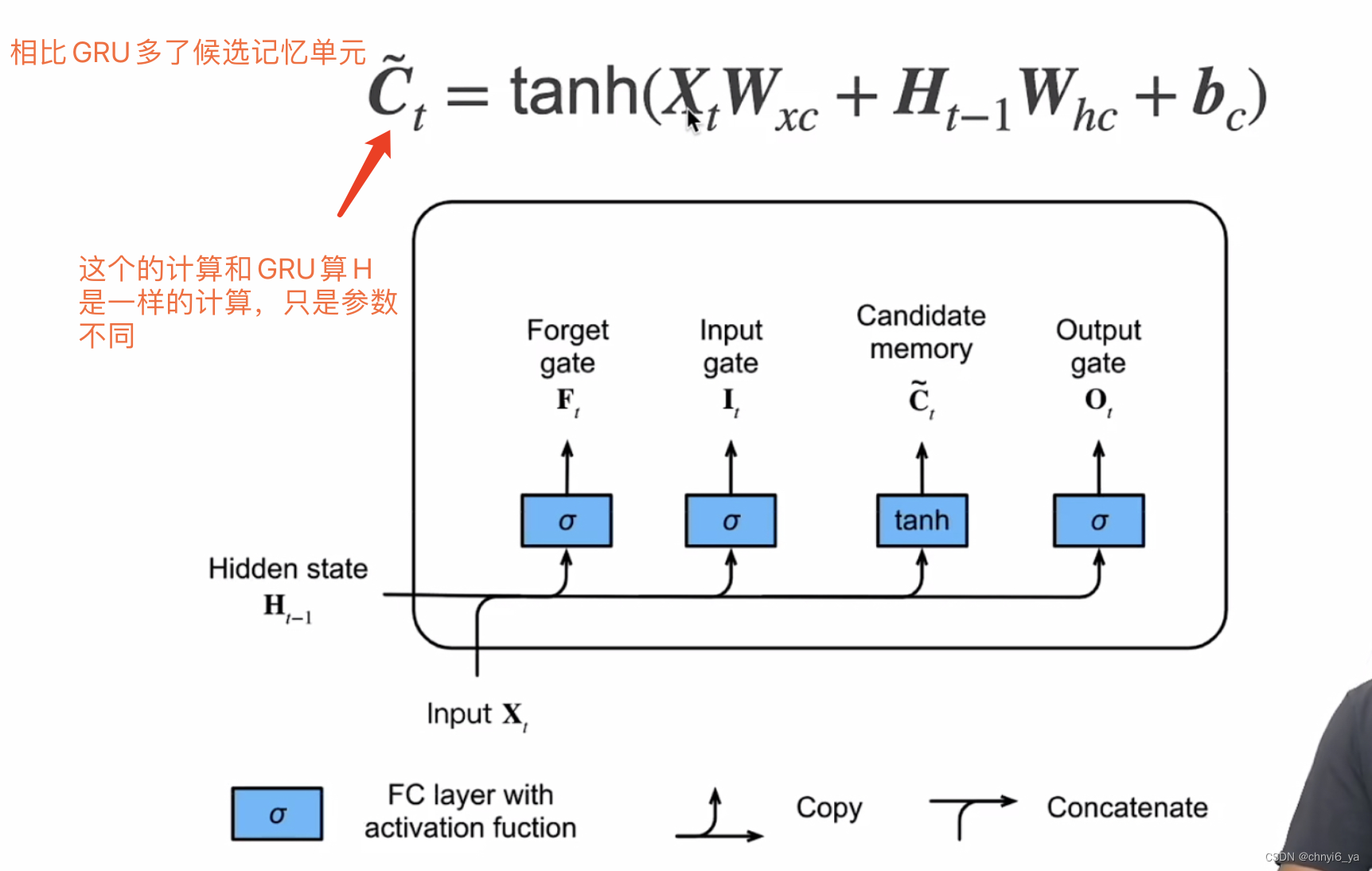
3. 候选记忆单元
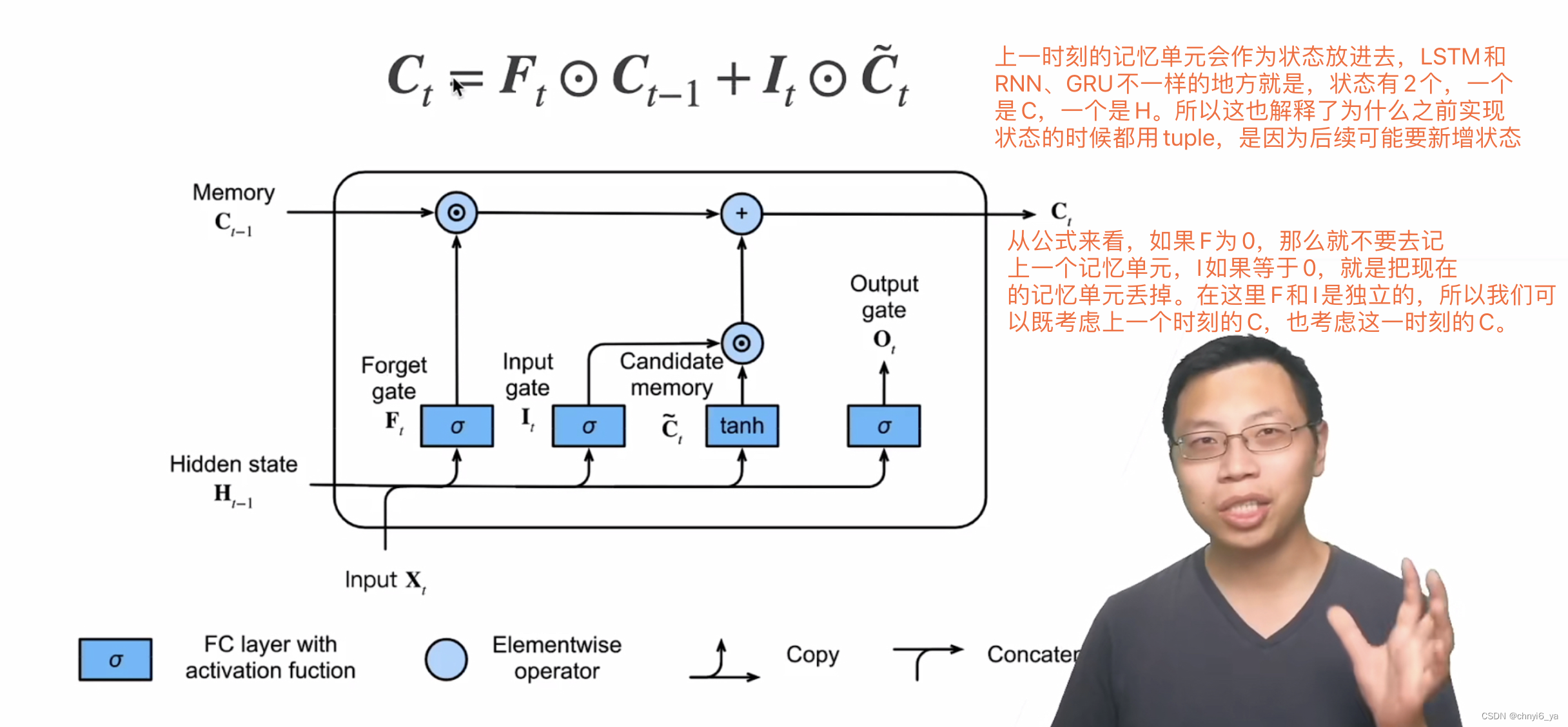
4. 记忆单元
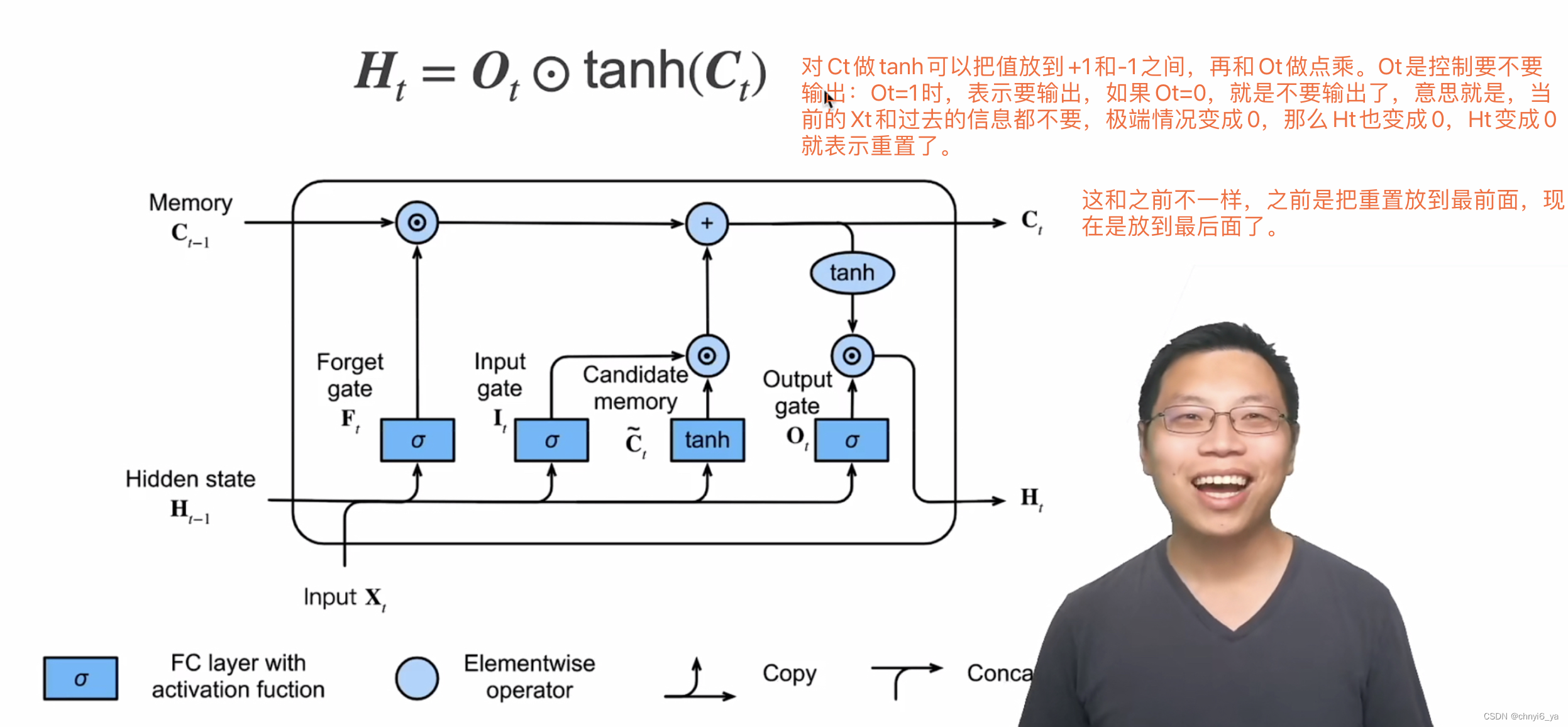
5. 隐状态
6. 总结
7. 从零实现的代码
我们首先加载时光机器数据集。
import torch
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
- 1
- 2
- 3
- 4
- 5
- 6
7.1 初始化模型参数
接下来,我们需要定义和初始化模型参数。 如前所述,超参数num_hiddens定义隐藏单元的数量。 我们按照标准差 0.01 的高斯分布初始化权重,并将偏置项设为 0 。
def get_lstm_params(vocab_size, num_hiddens, device): num_inputs = num_outputs = vocab_size def normal(shape): return torch.randn(size=shape, device=device)*0.01 def three(): return (normal((num_inputs, num_hiddens)), normal((num_hiddens, num_hiddens)), torch.zeros(num_hiddens, device=device)) W_xi, W_hi, b_i = three() # 输入门参数 W_xf, W_hf, b_f = three() # 遗忘门参数 W_xo, W_ho, b_o = three() # 输出门参数 W_xc, W_hc, b_c = three() # 候选记忆元参数 # 输出层参数 W_hq = normal((num_hiddens, num_outputs)) b_q = torch.zeros(num_outputs, device=device) # 附加梯度 params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c, W_hq, b_q] for param in params: param.requires_grad_(True) return params

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
7.2 定义模型
在初始化函数中, 长短期记忆网络的隐状态需要返回一个额外的记忆元, 单元的值为0,形状为(批量大小,隐藏单元数)。 因此,我们得到以下的状态初始化。
# C和H都要初始化
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
- 1
- 2
- 3
- 4
实际模型的定义与我们前面讨论的一样: 提供三个门和一个额外的记忆元。 请注意,只有隐状态才会传递到输出层, 而记忆元 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/168084
推荐阅读
相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

