
爬虫教程:https://piaosanlang.gitbooks.io/spiders/content/
如何入门 Python 爬虫:https://zhuanlan.zhihu.com/p/21479334
静觅 崔庆才的个人博客 Python 爬虫系列:http://cuiqingcai.com/category/technique/python
http://www.cnblogs.com/miqi1992/category/1105419.html
Python 爬虫从入门到放弃系列博客:https://www.cnblogs.com/zhaof/tag/爬虫/default.html?page=2
Python 爬取功能汇总:https://www.jb51.net/Special/985.htm
Python 3.8.5 文档
官方文档:https://docs.python.org/zh-cn/3/
1. 爬虫入门 初级篇
IDE 选择: PyCharm (推荐) 、SublimeText3、Visual Studio
Python 版本:Python3。( 最简单的是直接安装 Anaconda,使用 Anaconda 管理虚拟环境 )
- Windows 平台:https://docs.python.org/zh-cn/3/using/windows.html
- Linux Ubuntu 平台:https://docs.python.org/zh-cn/3/using/unix.html
1.1 为什么要学习爬虫
学习需求:抓取的某个网站或者某个应用的内容,提取有用的价值
实现手段:模拟用户在浏览器或者应用(app)上的操作,实现自动化的程序爬虫应用场景(利用爬虫能做什么?)
大家最熟悉的应用场景:抢票神器(360抢票器)、投票神器(微信朋友圈投票)
企业应用场景
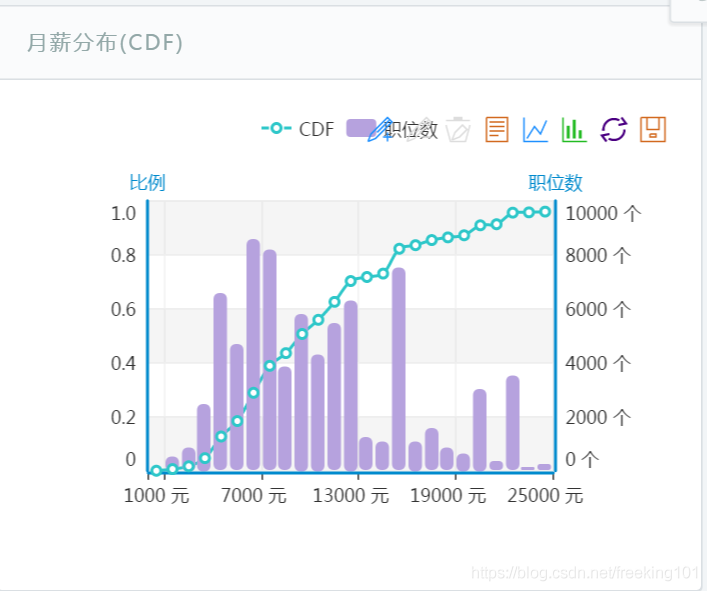
1、各种热门公司招聘中的职位数及月薪分布
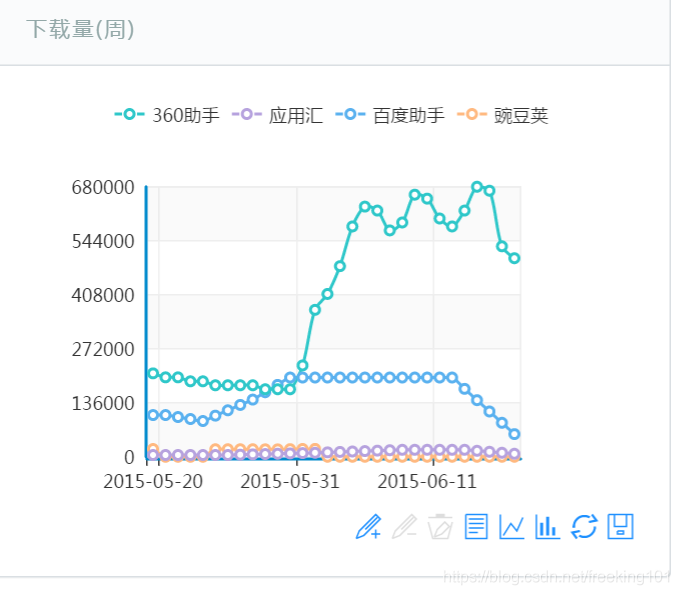
2、对某个 App 的下载量跟踪
3、 饮食地图

4、 票房预测

1.2 爬虫是什么 ?
专业术语: 网络爬虫(又被称为网页蜘蛛,网络机器人)是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本。
爬虫起源(产生背景):随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战;搜索引擎有Yahoo,Google,百度等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。网络爬虫是搜索引擎系统中十分重要的组成部分,它负责从互联网中搜集网页,采集信息,这些网页信息用于建立索引从而为搜索 引擎提供支持,它决定着整个引擎系统的内容是否丰富,信息是否即时,因此其性能的优劣直接影响着搜索引擎的效果。
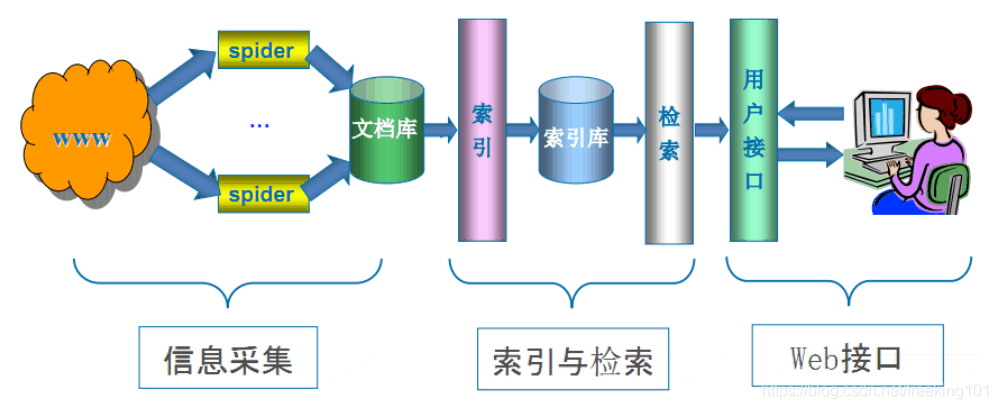
网络爬虫程序的优劣,很大程度上反映了一个搜索引擎的好差。不信,你可以随便拿一个网站去查询一下各家搜索对它的网页收录情况,爬虫强大程度跟搜索引擎好坏基本成正比。
搜索引擎工作原理
- 第一步:抓取网页(爬虫)。搜索引擎是通过一种特定规律的软件跟踪网页的链接,从一个链接爬到另外一个链接,像蜘蛛在蜘蛛网上爬行一样,所以被称为“蜘蛛”也被称为“机器人”。搜索引擎蜘蛛的爬行是被输入了一定的规则的,它需要遵从一些命令或文件的内容。 Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。
robots.txt 示例: https://www.taobao.com/robots.txt http://www.qq.com/robots.txt
示例:CSDN robot.txt ( https://blog.csdn.net/robots.txt ) 文件中 Sitemap:- # -*- coding: UTF-8 -*-
- import re
- import requests
- def download(url, retry_count=3):
- html = None
- for retry in range(retry_count):
- print(f'Downloading : {url}')
- custom_headers = {
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
- }
- try:
- r = requests.get(url, headers=custom_headers, verify=False)
- if r.status_code == 200:
- print('status_code : {0}'.format(r.status_code))
- html = r.text # html = r.content
- else:
- print('status_code : {0}'.format(r.status_code))
- break
- except BaseException as ex:
- print(f'Download error : {ex}')
- return html
- if __name__ == "__main__":
- temp_url = r'https://blog.csdn.net/s/sitemap/pcsitemapindex.xml'
- sitemap = download(temp_url)
- links = re.findall(r'<loc>(.*?)</loc>', sitemap)
- for link in links:
- print(link)
- pass
- 第二步:数据存储。搜索引擎是通过蜘蛛跟踪链接爬行到网页,并将爬行的数据存入原始页面数据库。其中的页面数据与用户浏览器得到的 HTML 是完全一样的。搜索引擎蜘蛛在抓取页面时,也做一定的重复内容检测,一旦遇到权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行。
- 第三步:预处理。搜索引擎将蜘蛛抓取回来的页面,进行各种步骤的预处理。 ⒈提取文字, ⒉中文分词, ⒊去停止词, ⒋消除噪音(搜索引擎需要识别并消除这些噪声,比如版权声明文字、导航条、广告等……), 5 正向索引, 6 倒排索引, 7 链接关系计算, 8 特殊文件处理等。 除了HTML文件外,搜索引擎通常还能抓取和索引以文字为基础的多种文件类型,如 PDF、Word、WPS、XLS、PPT、TXT 文件等。我们在搜索结果中也经常会看到这些文件类型。但搜索引擎还不能处理图片、视频、Flash 这类非文字内容,也不能执行脚本和程序。
- 第四步:排名,提供检索服务

但是,这些通用性搜索引擎也存在着一定的局限性,如:
- (1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
- (2) 通用搜索引目标是尽可能的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
- (3) 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
- (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。 聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。
与通用爬虫(general purpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
聚焦爬虫工作原理以及关键技术概述:
网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题:
- (1) 对抓取目标的描述或定义;
- (2) 对网页或数据的分析与过滤;
- (3) 对URL的搜索策略。
抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。这两个部分的算法又是紧密相关的。
网络爬虫的发展趋势
随着 AJAX/Web2.0 的流行,如何抓取 AJAX 等动态页面成了搜索引擎急需解决的问题,如果搜索引擎依旧采用“爬”的机制,是无法抓取到 AJAX 页面的有效数据的。 对于 AJAX 这样的技术,所需要的爬虫引擎必须是基于驱动的。而如果想要实现事件驱动,首先需要解决以下问题:
- 第一:JavaScript 的交互分析和解释;
- 第二:DOM 事件的处理和解释分发;
- 第三:动态 DOM 内容语义的抽取。
爬虫发展的几个阶段(博士论文copy)
- 第一个阶段:可以说是 早期爬虫,斯坦福的几位同学完成的抓取,当时的互联网基本都是完全开放的,人类流量是主流;
- 第二个阶段:是 分布式爬虫,但是爬虫面对新的问题是数据量越来越大,传统爬虫已经解决不了把数据都抓全的问题,需要更多的爬虫,于是调度问题就出现了;
- 第三阶段:是 Deep Web 爬虫。此时面对新的问题是数据之间的link越来越少,比如淘宝,点评这类数据,彼此link很少,那么抓全这些数据就很难;还有一些数据是需要提交查询词才能获取,比如机票查询,那么需要寻找一些手段“发现”更多,更完整的不是明面上的数据。
- 第四阶段:智能爬虫,这主要是爬虫又开始面对新的问题:社交网络数据的抓取。
社交网络对爬虫带来的新的挑战包括
- 有一条账号护城河。我们通常称UGC(User Generated Content)指用户原创内容。为 web2.0,即数据从单向传达,到双向互动,人民群众可以与网站产生交互,因此产生了账号,每个人都通过账号来标识身份,提交数据,这样一来社交网络就可以通过封账号来提高数据抓取的难度,通过账号来发现非人类流量。之前没有账号只能通过cookie和ip。cookie又是易变,易挥发的,很难长期标识一个用户。
- 网络走向封闭。新浪微博在 2012 年以前都是基本不封的,随便写一个程序怎么抓都不封,但是很快,越来越多的站点都开始防止竞争对手,防止爬虫来抓取,数据逐渐走向封闭,越来越多的人难以获得数据。甚至都出现了专业的爬虫公司,这在2010年以前是不可想象的。。
- 反爬手段,封杀手法千差万别。写一个通用的框架抓取成百上千万的网站已经成为历史,或者说已经是一个技术相对成熟的工作,也就是已经有相对成熟的框架来”盗“成百上千的墓,但是极个别的墓则需要特殊手段了,目前市场上比较难以抓取的数据包括,微信公共账号,微博,facebook,ins,淘宝等等。具体原因各异,但基本无法用一个统一框架来完成,太特殊了。如果有一个通用的框架能解决我说的这几个网站的抓取,这一定是一个非常震撼的产品,如果有,一定要告诉我,那我公开出来,然后就改行了。
当面对以上三个挑战的时候,就需要智能爬虫。智能爬虫是让爬虫的行为尽可能模仿人类行为,让反爬策略失效,只有”混在老百姓队伍里面,才是安全的“,因此这就需要琢磨浏览器了,很多人把爬虫写在了浏览器插件里面,把爬虫写在了手机里面,写在了路由器里面(春节抢票王)。再有一个传统的爬虫都是只有读操作的,没有写操作,这个很容易被判是爬虫,智能的爬虫需要有一些自动化交互的行为,这都是一些抵御反爬策略的方法。
1.3 爬虫基本原理
爬虫是模拟用户在浏览器或者某个应用上的操作,把操作的过程、实现自动化的程序,当我们在浏览器中输入一个 url 后回车,后台会发生什么?比如说你输入http://www.sina.com.cn/,简单来说这段过程发生了以下四个步骤:
- 1. 查找域名对应的IP地址。
- 2. 向IP对应的服务器发送请求。
- 3. 服务器响应请求,发回网页内容。
- 4. 浏览器解析网页内容。
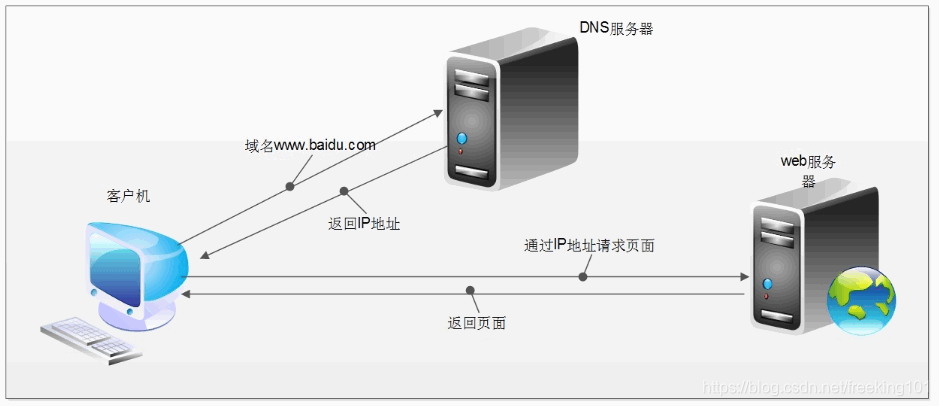
网络爬虫本质:本质就是浏览器http请求。浏览器和网络爬虫是两种不同的网络客户端,都以相同的方式来获取网页。
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据, 而不需要一步步人工去操纵浏览器获取。
浏览器是如何发送和接收这个数据呢?
- HTTP 简介:HTTP协议(HyperText Transfer Protocol,超文本传输协议)目的是为了提供一种发布和接收HTML(HyperText Markup Language)页面的方法。
- HTTP 协议所在的协议层(了解):HTTP 是基于TCP协议之上的。在 TCP/IP 协议参考模型的各层对应的协议如下图,其中HTTP是应用层的协议。 默认HTTP的端口号为80,HTTPS的端口号为443。

网络模型图
HTTP 工作过程
一次 HTTP 操作称为一个事务,其工作整个过程如下:
- 1 ) 、地址解析。如用客户端浏览器请求这个页面:http://localhost.com:8080/index.htm从中分解出协议名、主机名、端口、对象路径等部分,对于我们的这个地址,解析得到的结果如下: 协议名:http 主机名:localhost.com 端口:8080 对象路径:/index.htm在这一步,需要域名系统DNS解析域名localhost.com,得主机的IP地址。
- 2)、封装 HTTP 请求数据包。把以上部分结合本机自己的信息,封装成一个HTTP请求数据包
- 3)封装成 TCP 包,建立TCP连接(TCP的三次握手)。在HTTP工作开始之前,客户机(Web浏览器)首先要通过网络与服务器建立连接,该连接是通过TCP来完成的,该协议与IP协议共同构建Internet,即著名的TCP/IP协议族,因此Internet又被称作是TCP/IP网络。HTTP是比TCP更高层次的应用层协议,根据规则,只有低层协议建立之后才能,才能进行更层协议的连接,因此,首先要建立TCP连接,一般TCP连接的端口号是80。这里是8080端口
- 4)客户机发送请求命令。建立连接后,客户机发送一个请求给服务器,请求方式的格式为:统一资源标识符(URL)、协议版本号,后边是MIME信息包括请求修饰符、客户机信息和可内容。
- 5)服务器响应。服务器接到请求后给予相应的响应信息,其格式为一个状态行,包括信息的协议版本号、一个成功或错误的代码,后边是 MIME 信息包括服务器信息、实体信息和可能的内容。实体消息:服务器向浏览器发送头信息后,它会发送一个空白行来表示头信息的发送到此为结束,接着,它就以Content-Type应答头信息所描述的格式发送用户所请求的实际数据
- 6)服务器关闭 TCP 连接。一般情况下,一旦 Web 服务器向浏览器发送了请求数据,它就要关闭 TCP 连接,然后如果浏览器或者服务器在其头信息加入了这行代码 Connection:keep-alive 。TCP连接在发送后将仍然保持打开状态,于是,浏览器可以继续通过相同的连接发送请求。保持连接节省了为每个请求建立新连接所需的时间,还节约了网络带宽。
HTTP 协议栈数据流
HTTPS。HTTPS(全称:Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,简单讲是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL。其所用的端口号是443。
SSL:安全套接层,是netscape公司设计的主要用于web的安全传输协议。这种协议在WEB上获得了广泛的应用。通过证书认证来确保客户端和网站服务器之间的通信数据是加密安全的。
有两种基本的加解密算法类型:
- 1)对称加密(symmetrcic encryption):密钥只有一个,加密解密为同一个密码,且加解密速度快,典型的对称加密算法有DES、AES,RC5,3DES等;对称加密主要问题是共享秘钥,除你的计算机(客户端)知道另外一台计算机(服务器)的私钥秘钥,否则无法对通信流进行加密解密。解决这个问题的方案非对称秘钥。
- 2)非对称加密:使用两个秘钥:公共秘钥和私有秘钥。私有秘钥由一方密码保存(一般是服务器保存),另一方任何人都可以获得公共秘钥。这种密钥成对出现(且根据公钥无法推知私钥,根据私钥也无法推知公钥),加密解密使用不同密钥(公钥加密需要私钥解密,私钥加密需要公钥解密),相对对称加密速度较慢,典型的非对称加密算法有RSA、DSA等。
https 通信的优点:
客户端产生的密钥只有客户端和服务器端能得到;
加密的数据只有客户端和服务器端才能得到明文;
客户端到服务端的通信是安全的。
1.4 爬虫工作流程
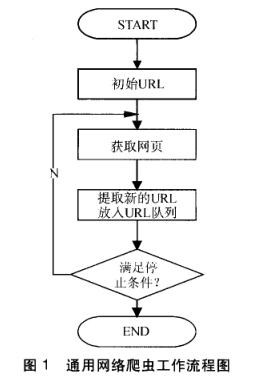
网络爬虫的基本工作流程如下:
- 1. 首先选取一部分精心挑选的种子 URL;
- 2. 将这些 URL 放入待抓取 URL 队列;
- 3. 从待抓取 URL 队列中取出待抓取在 URL,解析 DNS,并且得到主机的 ip,将 URL 对应的网页下载下来并存储到已下载网页库中。此外,将这些 URL 放进已抓取 URL 队列。
- 4. 分析已抓取 URL 队列中的 URL,分析其中的其他 URL,并且将 URL 放入待抓取 URL 队列,从而进入下一个循环。
校花网 爬取 示例:爬取 大学校花( http://www.521609.com/daxuexiaohua/ )
这个爬虫只是爬取一个 URL,并没有提取更多 URL 进行爬取
- # -*- coding:utf-8 -*-
- import os
- import chardet
- import requests
- from bs4 import BeautifulSoup
-
-
- def spider():
- url = "http://www.521609.com/daxuexiaohua/"
- proxies = {
- "http": "http://172.17.18.80:8080",
- "https": "https://172.17.18.80:8080"
- }
- r = requests.get(
- url,
- # proxies=proxies
- )
- html = r.content.decode("gbk")
- soup = BeautifulSoup(html, "lxml")
-
- divs = soup.find_all("div", class_="index_img list_center")
- print(f'len(divs) : {len(divs)}')
- for div in divs:
- tag_ul = div.find('ul')
- tag_all_li = tag_ul.find_all('li')
- print(f'len(tag_all_li): {len(tag_all_li)}')
- for tag_li in tag_all_li:
- tag_img = tag_li.find('img')
- print(f'mm_name: {tag_img["alt"]}')
- print(f'\t\t mm_pic: http://www.521609.com{tag_img["src"]}')
- home_page = tag_li.find('a')
- print(f'\t\t home_page: http://www.521609.com{home_page["href"]}')
- # print(soup)
-
-
- if __name__ == "__main__":
- spider()
- # input('press any key to continue......')
- # pass
1.5 HTTP 代理神器 Fidder
Fiddler 不但能截获各种浏览器发出的HTTP请求, 也可以截获各种智能手机发出的 HTTP/HTTPS请求。 Fiddler 能捕获 IOS 设备发出的请求,比如 IPhone, IPad, MacBook. 等等苹果的设备。 同理,也可以截获 Andriod,Windows Phone 的等设备发出的HTTP/HTTPS。工作原理:Fiddler 是以代理 web 服务器的形式工作的,它使用代理地址:127.0.0.1,端口:8888。
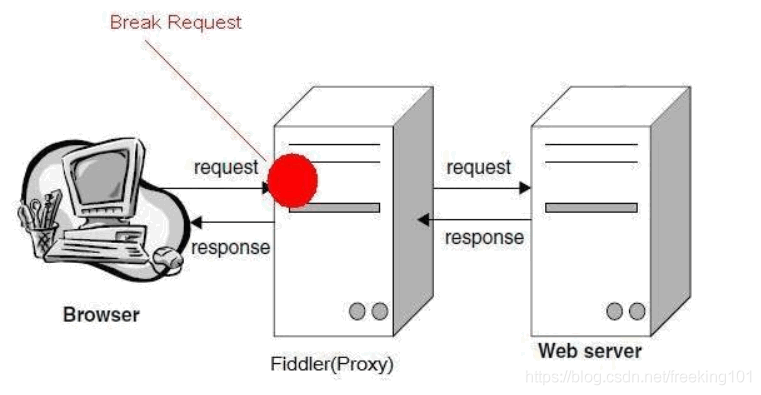
Fiddler 抓取 HTTPS 设置:启动 Fiddler,打开菜单栏中的 Tools > Fiddler Options,打开 “Fiddler Options” 对话框。
选中 Capture HTTPS CONNECTs,再选中下方 Ignore server certificate errors,
然后再点击 Actions 安装证书( 要抓取 HTTPS 的流量,必须安装证书 ),安装为 "根证书"。。。

配置 Fiddler 允许远程连接( 可以抓取手机流量 ):
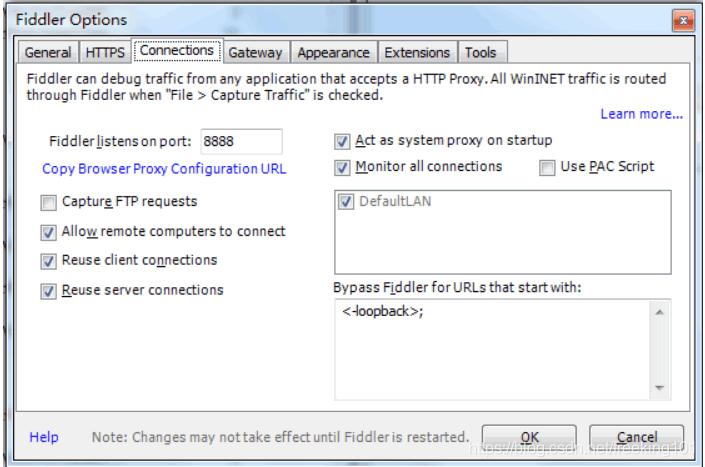
Connections 页签,选中 Allow remote computers to connect。重启 Fidler(这一步很重要,必须做)。
Fiddler 如何捕获 Chrome的会话:switchyomega 安装插件
百度( 百度的时候把点去掉 ):i点sha点dow点socks 或者 lan点tern
打开网址 chrome 网上应用商店,然后搜索 "switchyomega"。

Fiddler 如何捕获 Firefox 的会话
能支持 HTTP 代理的任意程序的数据包都能被 Fiddler 嗅探到,Fiddler 的运行机制其实就是本机上监听 8888 端口的 HTTP代理。 Fiddler2启动的时候默认IE的代理设为了127.0.0.1:8888,而其他浏览器是需要手动设置的,所以将Firefox的代理改为127.0.0.1:8888就可以监听数据了。 Firefox 上通过如下步骤设置代理 点击: Tools -> Options, 在Options 对话框上点击Advanced tab - > network tab -> setting.
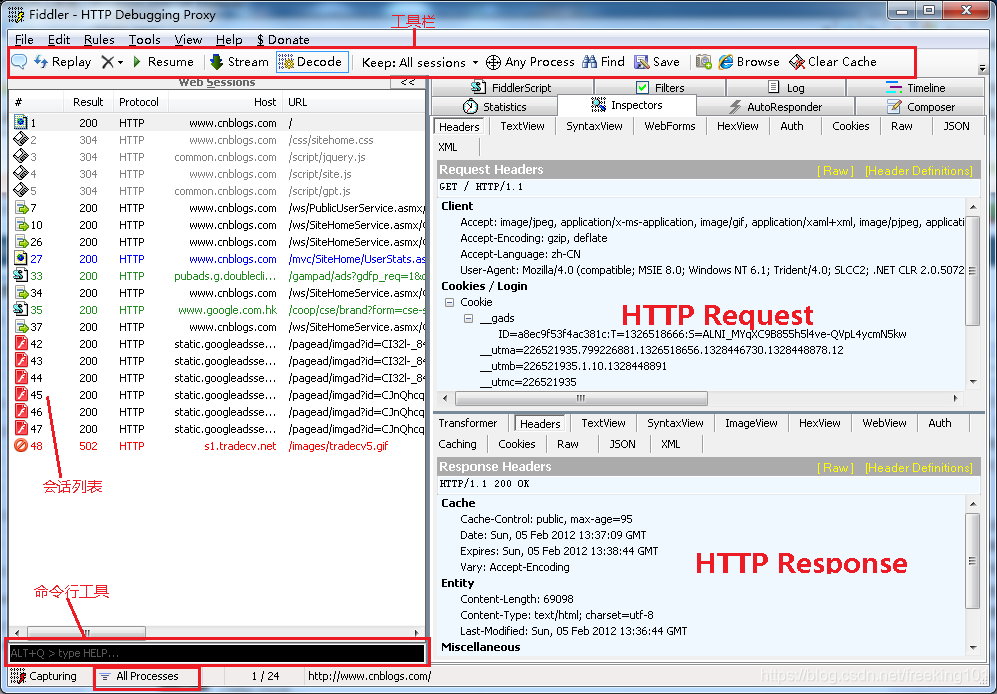
Fiddler 的基本界面
特别注意: 遇到这个 Click 请点击 Click
Fiddler 强大的 Script 系统
Fiddler 包含了一个强大的基于事件脚本的子系统,并且能使用 .net 语言进行扩展。
官方的帮助文档: http://www.fiddler2.com/Fiddler/dev/ScriptSamples.asp
Fiddler 的 Fiddler Script 标签,如下图:

在里面我们就可以编写脚本了, 看个实例让所有 cnblogs 的会话都显示红色。 把这段脚本放在 OnBeforeRequest(oSession: Session) 方法下,并且点击 "Save script"
- if (oSession.HostnameIs("www.cnblogs.com")) {
- oSession["ui-color"] = "red";
- }
这样所有的cnblogs的会话都会显示红色。
1.6 HTTP 协议介绍
HTTP (HyperText Transfer Protocol) 提供了一种发布和接收HTML(HyperText Markup Language)页面的方法。
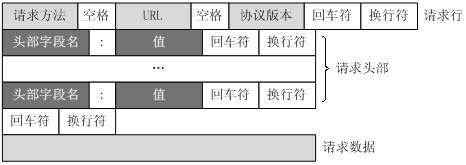
Http 两部分组成:请求、响应。
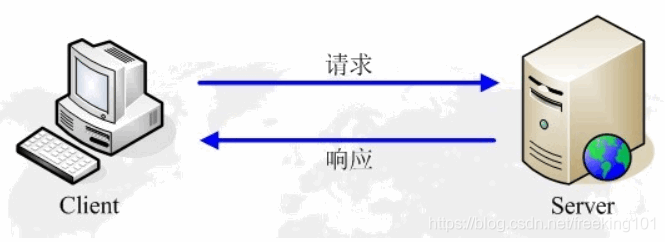
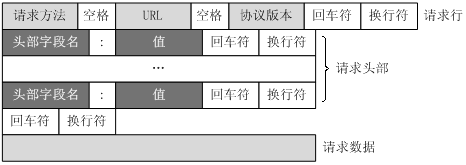
客户端请求消息:客户端发送一个HTTP请求到服务器的请求消息包括以下格式:请求行(request line)、请求头部(header)、空行和请求数据四个部分组成,下图给出了请求报文的一般格式。
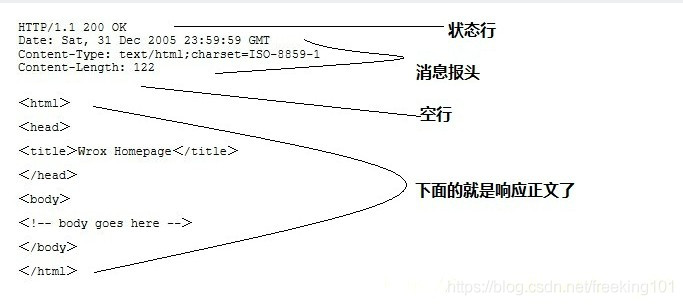
服务器响应消息:HTTP 响应也由四个部分组成,分别是:状态行、消息报头、空行 和 响应正文。
cookies 和 session
服务器 和 客户端 的交互仅限于请求/响应过程,结束之后便断开, 在下一次请求服务器会认为新的客户端。为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息:
- Cookie 通过在客户端记录信息确定用户身份。
- Session 通过在服务器端记录信息确定用户身份。
HTTP 请求
请求方法
根据 HTTP 标准,HTTP 请求可以使用多种请求方法。
HTTP 1.0 定义了三种请求方法: GET,POST 和 HEAD方法。
HTTP 1.1 新增了五种请求方法:OPTIONS,PUT,DELETE,TRACE 和 CONNECT 方法。
| 序号 | 方法 | 描述 |
| 1 | GET | 请求指定的页面信息,并返回实体主体。 |
| 2 | HEAD | 类似于 get 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| 3 | POST | 向指定资源提交数据进行处理请求(例如提交表单或者上传文件)。数据被包含在请求体中。 POST 请求可能会导致新的资源的建立和/或已有资源的修改。 |
| 4 | PUT | 从客户端向服务器传送的数据取代指定的文档的内容。 |
| 5 | DELETE | 请求服务器删除指定的页面。 |
| 6 | CONNECT | HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。 |
| 7 | OPTIONS | 允许客户端查看服务器的性能。 |
| 8 | TRACE | 回显服务器收到的请求,主要用于测试或诊断。 |
GET和POST方法区别归纳如下几点:
- 1. GET 是从服务器上获取数据,POST 是向服务器传送数据。
- 2. GET 请求的时候,参数都显示在浏览器网址上。POST 请求的时候,参数在请求体当中,消息长度没有限制而且以隐式的方式进行发送
- 3. 尽量避免使用 Get 方式提交表单,因为有可能会导致安全问题。 比如说在登陆表单中用 Get 方式,用户输入的用户名和密码将在地址栏中暴露无遗。 但是在分页程序中用 Get 方式就比用 Post 好。
URL概述
统一资源定位符(URL,英语 Uniform / Universal Resource Locator的缩写)是用于完整地描述 Internet 上网页和其他资源的地址的一种标识方法。
URL 格式:基本格式如下 schema://host[:port#]/path/…/[?query-string][#anchor]
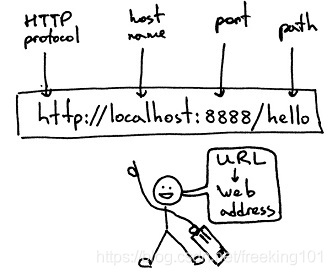
- 1. schema 协议 (例如:http, https, ftp)
- 2. host 服务器的IP地址或者域名
- 3. port# 服务器的端口(如果是走协议默认端口,缺省端口80)
- 4. path 访问资源的路径
- 5. query-string 参数,发送给http服务器的数据
- 6. anchor- 锚(跳转到网页的指定锚点位置)
例子:
- http://www.sina.com.cn/
- http://192.168.0.116:8080/index.jsp
- http://item.jd.com/11052214.html#product-detail
- http://www.website.com/test/test.aspx?name=sv&x=true#stuff
URL 和 URI 的区别
- URL:统一资源定位符(uniform resource location);平时上网时在 IE 浏览器中输入的那个地址就是 URL。比如:网易 http://www.163.com 就是一个URL 。URL 是 Internet上用来描述信息资源的字符串,主要用在各种 WWW 客户程序和服务器程序上。采用 URL 可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
- URI:统一资源标识符(uniform resource identifier)。Web 上可用的每种资源 - HTML 文档、图像、视频片段、程序, 由一个通过通用资源标志符 (Universal Resource Identifier, 简称 "URI") 进行定位。URI 是个纯粹的语法结构,用于指定标识 web资源的字符串的各个不同部分,URL 是 URI 的一个特例,它包含定位 web 资源的足够信息。
- URL 是 URI 的一个子集
一个 URL 的请求过程:
- 当你在浏览器输入URL https://www.baidu.com/ 的时候,浏览器发送一个Request 去获取 https://www.baidu.com/ 的 html。
- 服务器把 Response 发送回给浏览器.
- 浏览器分析 Response 中的 HTML,发现其中引用了很多其他文件,比如:图片,CSS文件,JS文件。
- 浏览器会自动再次发送 Request 去获取图片,CSS文件,或者JS文件。
- 当所有的文件都下载成功后, 网页就被显示出来了。
常用的请求报头
- Host:Host初始URL中的主机和端口,用于指定被请求资源的Internet主机和端口号,它通常从HTTP URL中提取出来的
- Connection:表示客户端与服务连接类型;
1. client 发起一个包含 Connection:keep-alive 的请求
2. server 收到请求后,如果 server 支持 keepalive 回复一个包含Connection:keep-alive的
响应不关闭连接,否则回复一个包含Connection:close的响应关闭连接。
3. 如果 client 收到包含 Connection:keep-alive 的响应,向同一个连接发送下一个请求,
直到一方主动关闭连接。 Keep-alive在很多情况下能够重用连接,减少资源消耗,缩短响应时间HTTP - Accept:表示浏览器支持的 MIME 类型
MIME 的英文全称是 Multipurpose Internet Mail Extensions(多用途互联网邮件扩展)
eg:
Accept:image/gif,表明客户端希望接受GIF图象格式的资源;
Accept:text/html,表明客户端希望接受html文本。
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
意思:浏览器支持的 MIME 类型分别是 text/html、application/xhtml+xml、application/xml 和 */*,
优先顺序是它们从左到右的排列顺序。
Text:用于标准化地表示的文本信息,文本消息可以是多种字符集和或者多种格式的;
Application:用于传输应用程序数据或者二进制数据;设定某种扩展名的文件用一种应用程序来
打开的方式类型,当该扩展名文件被访问的时候,浏览器会自动使用指定应用程序来打开
q 是权重系数,范围 0 =< q <= 1,q 值越大,请求越倾向于获得其“;”之前的类型表示的内容,
若没有指定 q 值越大,请求越倾向于获得其“,则默认为1,
若被赋值为0,则用于提醒服务器哪些是浏览器不接受的内容类型。
| Mime类型 | 扩展名 |
| text/html | .htm .html *.shtml |
| text/plain | text/html是以html的形式输出,比如 |
| application/xhtml+xml | .xhtml .xml |
| text/css | *.css |
| application/msexcel | .xls .xla |
| application/msword | .doc .dot |
| application/octet-stream | *.exe |
| application/pdf | |
| ..... | ..... |
- Content-Type:POST 提交,application/x-www-form-urlencoded 提交的数据按照 key1=val1&key2=val2 的方式进行编码,key 和 val 都进行了 URL 转码。
- User-Agent: 浏览器类型
- Referer: 请求来自哪个页面,用户是从该 Referer URL页面访问当前请求的页面。
- Accept-Encoding:浏览器支持的压缩编码类型,比如gzip,支持gzip的浏览器返回经gzip编码的HTML页面。许多情形下这可以减少5到10倍的下载时间
eg:
Accept-Encoding:gzip;q=1.0, identity; q=0.5, *;q=0 // 按顺序支持 gzip , identity
如果有多个Encoding同时匹配, 按照q值顺序排列
如果请求消息中没有设置这个域,服务器假定客户端对各种内容编码都可以接受。
- Accept-Language:浏览器所希望的语言种类,当服务器能够提供一种以上的语言版本时要用到。
eg:
Accept-Language:zh-cn
如果请求消息中没有设置这个报头域,服务器假定客户端对各种语言都可以接受。 - Accept-Charset:浏览器可接受的字符集,用于指定客户端接受的字符集
eg:
Accept-Charset:iso-8859-1,gb2312
ISO8859-1,通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符;
gb2312是标准中文字符集;
UTF-8 是 UNICODE 的一种变长字符编码,可以解决多种语言文本显示问题,从而实现应用国际化和本地化。
如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。
HTTP 响应
服务器上每一个HTTP 应答对象 response 都包含一个数字 "状态码"。HTTP 状态码表示 HTTP 协议所返回的响应的状态。
比如:客户端向服务器发送请求,如果成功地获得请求的资源,则返回的状态码为200,表示响应成功。如果请求的资源不存在, 则通常返回404错误。
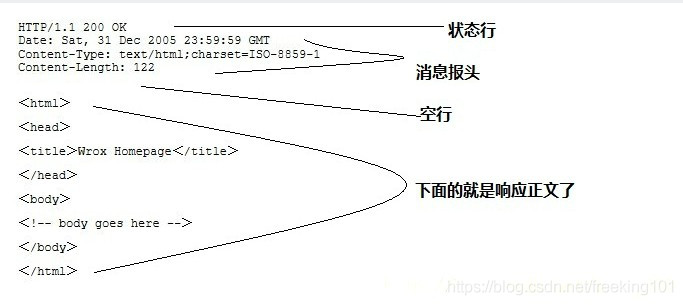
HTTP 响应状态码通常分为5种类型,分别以1~5五个数字开头,由3位整数组成,第一个数字定义了响应的类别:
| 分类 | 分类描述 |
| 1** | 信息,服务器收到请求,需要请求者继续执行操作 |
| 2** | 成功,操作被成功接收并处理 |
| 3** | 重定向,需要进一步的操作以完成请求 |
| 4** | 客户端错误,请求包含语法错误或无法完成请求 |
| 5** | 服务器错误,服务器在处理请求的过程中发生了错误 |
最常用的响应状态码
200 (OK): 请求成功,找到了该资源,并且一切正常。处理方式:获得响应的内容,进行处理
201 请求完成,结果是创建了新资源。新创建资源的URI可在响应的实体中得到 处理方式:爬虫中不会遇到
202 请求被接受,但处理尚未完成 处理方式:阻塞等待
204 服务器端已经实现了请求,但是没有返回新的信 息。如果客户是用户代理,则无须为此更新自身的文档视图。 处理方式:丢弃
300 该状态码不被HTTP/1.0的应用程序直接使用, 只是作为3XX类型回应的默认解释。存在多个可用的被请求资源。 处理方式:若程序中能够处理,则进行进一步处理,如果程序中不能处理,则丢弃
301 (Moved Permanently): 请求的文档在其他地方,新的URL在Location头中给出,浏览器应该自动地访问新的URL。处理方式:重定向到分配的URL
302 (Found): 类似于301,但新的URL应该被视为临时性的替代,而不是永久性的。处理方式:重定向到临时的URL
304 (NOT MODIFIED): 该资源在上次请求之后没有任何修改。这通常用于浏览器的缓存机制。处理方式:丢弃
400 (Bad Request): 请求出现语法错误。非法请求 处理方式:丢弃
401 未授权 处理方式:丢弃
403 (FORBIDDEN): 客户端未能获得授权。这通常是在401之后输入了不正确的用户名或密码。禁止访问 处理方式:丢弃
404 (NOT FOUND): 在指定的位置不存在所申请的资源。没有找到 。 处理方式:丢弃
5XX 回应代码以“5”开头的状态码表示服务器端发现自己出现错误,不能继续执行请求 处理方式:丢弃
500 (Internal Server Error): 服务器遇到了意料不到的情况,不能完成客户的请求
503 (Service Unavailable): 服务器由于维护或者负载过重未能应答。
例如,Servlet可能在数据库连接池已满的情况下返回503。服务器返回503时可以提供一个Retry-After头
常用的响应报头(了解)
Location:表示客户应当到哪里去提取文档,用于重定向接受者到一个新的位置
Server:服务器名字,包含了服务器用来处理请求的软件信息
eg: Server响应报头域的一个例子:
Server:Apache-Coyote/1.1
Set-Cookie:设置和页面关联的Cookie。
例如:前一个 cookie 被存入浏览器并且浏览器试图请求 http://www.ibm.com/foo/index.html 时
Set-Cookie:customer=huangxp; path=/foo; domain=.ibm.com;
expires= Wednesday, 19-OCT-05 23:12:40 GMT;
Set-Cookie的每个属性解释如下:
Customer=huangxp 一个"名称=值"对,把名称customer设置为值"huangxp",这个属性在Cookie中必须有。
path=/foo 服务器路径。
domain=.ibm.com 指定cookie 的域名。
expires= Wednesday, 19-OCT-05 23:12:40 GMT 指定cookie 失效的时间
POST 请求方式
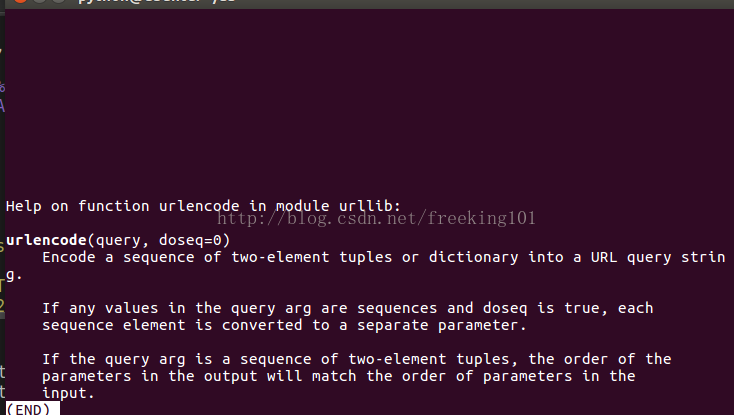
urllib 使用示例:
- # encoding:UTF-8
- import urllib.request
-
-
- def get_data():
- url = "http://www.baidu.com"
- data = urllib.request.urlopen(url).read()
- z_data = data.decode('UTF-8')
- print(z_data)
-
-
- get_data()
get 和 post 方法:
- import urllib.request
- import urllib.parse
- import urllib.error # url异常处理
-
-
- def get_method():
- # GET 方法
- keyword = "python"
- keyword = urllib.parse.quote(keyword) # 搜索中文的方法
- url = "http://www.baidu.com/s?wd=" + keyword
- req = urllib.request.Request(url)
- data = urllib.request.urlopen(req).read()
- print(data.decode('utf-8', 'ignore')) # 转为utf-8,如果出现异常,责忽略
- fh = open("./1.html", "wb")
- fh.write(data)
- fh.close()
-
-
- def post_method():
- # POST 方法
- keyword = "python"
- keyword = urllib.parse.quote(keyword)
- url = "http://www.baidu.com/s"
- my_data = urllib.parse.urlencode({"wd": "python"}).encode('utf-8')
- req = urllib.request.Request(url, my_data)
- data = urllib.request.urlopen(req).read().decode("utf-8")
- print(data)
-
-
- if __name__ == '__main__':
- get_method()
- post_method()
- '''
- 在清求url请求时会发现存在异常情况,常用的请求异常类是 HTTPError/URLError 两种,
- HTTPError异常时URLError异常的子类,是带异常状态码和异常原因的,而URLError异常类
- 是不带状态码的,所以在使用中不用直接用URLError代替HTTPError异常,如果要代替,一定
- 要判断是否有状态码属性
- URLError:
- 1/连接不上远程服务器;
- 2/url不存在;
- 3/本地没有网络;
- 4/假如触发 http error
- 所以通常用特殊处理来使用URLError来替代HTTPError异常
- '''
- try:
- urllib.request.urlopen("http://www.blog.csdn.net")
- except urllib.error.URLError as e:
- if hasattr(e, "code"):
- print("code:")
- print(e.code)
- if hasattr(e, "reason"):
- print("reason:")
- print(e.reason)
- finally:
- print("URLError ")
- pass
抓取拉钩招聘信息:https://www.lagou.com/jobs/list_爬虫
- # -*- coding: utf-8 -*-
-
- import string
- from urllib import request, parse
-
-
- # proxy_handler = request.ProxyHandler({"http": 'http://192.168.17.1:8888'})
- # opener = request.build_opener(proxy_handler)
- # request.install_opener(opener)
-
- page_num = 1
- output = open('lagou.json', 'w')
-
- for page in range(1, page_num + 1):
- form_data = {
- 'first': 'true',
- 'pn': '1',
- 'kd': '爬虫'
- }
- # 注意:对于需要传入的 data 数据,需要进行 urlencode 编码。
- form_data = parse.urlencode(form_data).encode('utf-8')
-
- print(f'运行到第 ({page}) 页面')
-
- send_headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36',
- 'Accept': 'application/json, text/javascript, */*; q=0.01',
- 'X-Requested-With': 'XMLHttpRequest'
- }
-
- # url = 'http://www.lagou.com/jobs/positionAjax.json?px=new&needAddtionalResult=false'
- url = 'https://www.lagou.com/jobs/positionAjax.json?city=北京&needAddtionalResult=false'
-
- # Python3 出现 'ascii' codec can't encode characters问题
- # https://www.cnblogs.com/wuxiangli/p/9957601.html
- url = parse.quote(url, safe=string.printable)
-
- req = request.Request(url=url, headers=send_headers, data=form_data, method='POST')
- # req.add_header('X-Requested-With', 'XMLHttpRequest')
- # req.headers = send_headers
- response = request.urlopen(req)
- res_html = response.read().decode('utf-8')
- print(res_html)
- # output.write(res_html + '\n')
- output.close()
- print('-' * 4 + 'end' + '-' * 4)
提出一个问题,如果要采集的是 拉钩招聘网站 北京>>朝阳区>>望京 以这个网站为例,该如何理解这个url ?
http://www.lagou.com/jobs/list_?px=default&city=%E5%8C%97%E4%BA%AC&district=%E6%9C%9D%E9%98%B3%E5%8C%BA&bizArea=%E6%9C%9B%E4%BA%AC#filterBox
URL 编码 / 解码:http://tool.chinaz.com/tools/urlencode.aspx
- # -*- coding: utf-8 -*-
-
- from urllib import request, parse
-
- query = {
- 'city': '北京',
- 'district': '朝阳区',
- 'bizArea': '望京'
- }
- print(parse.urlencode(query))
- page = 3
- values = {
- 'first': 'false',
- 'pn': str(page),
- 'kd': '后端开发',
- }
- form_data = parse.urlencode(values)
- print(form_data)
小结
- Content-Length: 是指报头Header以外的内容长度,指 表单数据长度
- X-Requested-With: XMLHttpRequest :表示Ajax异步请求
- Content-Type: application/x-www-form-urlencoded :表示:提交的表单数据 会按照name/value 值对 形式进行编码。例如:name1=value1&name2=value2... 。name 和 value 都进行了 URL 编码(utf-8、gb2312)
2. 爬虫入门 基础篇
| 数据格式 | 描述 | 设计目标 |
| XML | Extensible Markup Language (可扩展标记语言) | 被设计为传输和存储数据,其焦点是数据的内容 |
| HTML | HyperText Markup Language(超文本标记语言) | 显示数据以及如何更好显示数据 |
| HTML DOM | HTML Document Object Model(文档对象模型) | 通过 JavaScript,您可以重构整个HTML文档。您可以添加、移除、改变或重排页面上的项目。要改变页面的某个东西,JavaScript就需要对HTML文档中所有元素进行访问的入口。 |
XML
XML DOM 定义访问和操作 XML 文档的标准方法。 DOM 将 XML 文档作为一个树形结构,而树叶被定义为节点。
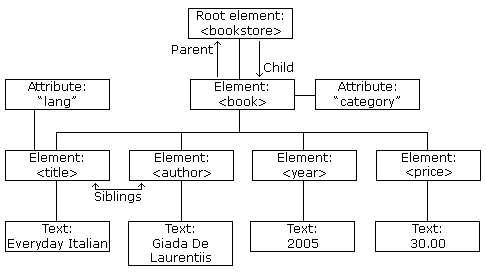
XML 示例
- <?xml version="1.0" encoding="utf-8"?>
- <bookstore>
- <book category="cooking">
- <title lang="en">Everyday Italian</title>
- <author>Giada De Laurentiis</author>
- <year>2005</year>
- <price>30.00</price>
- </book>
- <book category="children">
- <title lang="en">Harry Potter</title>
- <author>J K. Rowling</author>
- <year>2005</year>
- <price>29.99</price>
- </book>
- <book category="web">
- <title lang="en">XQuery Kick Start</title>
- <author>James McGovern</author>
- <author>Per Bothner</author>
- <author>Kurt Cagle</author>
- <author>James Linn</author>
- <author>Vaidyanathan Nagarajan</author>
- <year>2003</year>
- <price>49.99</price>
- </book>
- <book category="web" cover="paperback">
- <title lang="en">Learning XML</title>
- <author>Erik T. Ray</author>
- <year>2003</year>
- <price>39.95</price>
- </book>
- </bookstore>
HTML DOM 示例
HTML DOM 定义了访问和操作 HTML 文档的标准方法。 DOM 以树结构表达 HTML 文档。
2.1 页面解析之数据提取
抓取网站或者某个应用的数据一般分为两部分,非结构化的文本,或结构化的文本。
- 结构化的数据:JSON、XML
- 非结构化的数据:HTML文本(包含JavaScript代码)
HTML文本(包含JavaScript代码)是最常见的数据格式,理应属于结构化的文本组织,但因为一般我们需要的关键信息并非直接可以得到,需要进行对HTML的解析查找,甚至一些字符串操作才能得到,所以还是归类于非结构化的数据处理中。
把网页比作一个人,那么 HTML 便是他的骨架,JS 便是他的肌肉,CSS 便是它的衣服。常见解析方式如下:
- XPath
- CSS选择器
- 正则表达式
一段文本,例如一篇文章,或者一句话,我们的初衷是提取有效信息,所以如果是滞后处理,可以直接存储,如果是需要实时提取有用信息,常见的处理方式如下:
- 分词,根据抓取的网站类型,使用不同词库,进行基本的分词,然后变成词频统计
- NLP 自然语言处理,进行语义分析,用结果表示,例如正负面等。
2.2 非结构化数据之 XPath
XPath 语言:XPath(XML Path Language)是 XML 路径语言,它是一种用来定位 XML 文档中某部分位置的语言。将 HTML 转换成 XML 文档之后,用 XPath 查找 HTML 节点或元素。比如:用 "/" 来作为上下层级间的分隔,第一个 "/" 表示文档的根节点(注意,不是指文档最外层的 tag 节点,而是指文档本身),对于一个 HTML 文件来说,最外层的节点应该是 "/html" 。
XPath开发工具:开源的 XPath 表达式编辑工具:XMLQuire(XML格式文件可用)、chrome 插件 XPath Helper
firefox插件 XPath Checker
XPath语法 ( XPath语法参考文档:http://www.w3school.com.cn/xpath/index.asp )
XPath 是一门在 XML 文档中查找信息的语言。
XPath 可用来在 XML 文档中对元素和属性进行遍历。
- <?xml version="1.0" encoding="ISO-8859-1"?>
- <bookstore>
- <book>
- <title lang="eng">Harry Potter</title>
- <price>29.99</price>
- </book>
- <book>
- <title lang="eng">Learning XML</title>
- <price>39.95</price>
- </book>
- </bookstore>
选取节点 XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的。
下面列出了最有用的路径表达式:
| 表达式 | 描述 |
| / | 从根节点选取。 |
| nodename | 选取此节点的所有子节点。 |
| // | 从当前节点 选择 所有匹配文档中的节点 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
在下面的表格中,我们已列出了一些路径表达式以及表达式的结果:
| 路径表达式 | 结果 |
| /bookstore | 选取根元素 bookstore。注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore | 选取 bookstore 元素的所有子节点。默认从根节点选取 |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| //book/./title | 选取所有 book 子元素,从当前节点查找title节点 |
| //price/.. | 选取所有 book 子元素,从当前节点查找父节点 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
谓语条件(Predicates)
谓语用来查找某个特定的信息或者包含某个指定的值的节点。
所谓"谓语条件",就是对路径表达式的附加条件
谓语是被嵌在方括号中,都写在方括号"[]"中,表示对节点进行进一步的筛选。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
| 路径表达式 | 结果 |
| /bookstore/book[1] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang=’eng’] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| //book[price] | 选取所有 book 元素,且被选中的book元素必须带有price子元素 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00 |
选取未知节点:XPath 通配符可用来选取未知的 XML 元素。
| 通配符 | 描述 |
| * | 匹配任何元素节点。 |
| @* | 匹配任何属性节点。 |
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
| /bookstore/* | 选取 bookstore 元素的所有子元素。 |
| //* | 选取文档中的所有元素。 |
| //title[@*] | 选取所有带有属性的 title 元素。 |
选取若干路径: 通过在路径表达式中使用“|”运算符,您可以选取若干个路径。
在下面的表格中,我们列出了一些路径表达式,以及这些表达式的结果:
| 路径表达式 | 结果 |
| //book/title | //book/price | 选取 book 元素的所有 title 和 price 元素。 |
| //title | //price | 选取文档中的所有 title 和 price 元素。 |
| /bookstore/book/title | //price | 选取属于 bookstore 元素的 book 元素的所有 title 元素,以及文档中所有的 price 元素。 |
XPath 高级用法
模糊查询 contains
目前许多 web 框架,都是动态生成界面的元素id,因此在每次操作相同界面时,ID都是变化的,这样为自动化测试造成了一定的影响。
- <div class="eleWrapper" title="请输入用户名">
- <input type="text" class="textfield" name="ID9sLJQnkQyLGLhYShhlJ6gPzHLgvhpKpLzp2Tyh4hyb1b4pnvzxFR!-166749344!1357374592067" id="nt1357374592068" />
- </div>
解决方法 使用 xpath 的匹配功能,//input[contains(@id,'nt')]
- 测试使用的XML
- <Root>
- <Person ID="1001" >
- <Name lang="zh-cn" >张城斌</Name>
- <Email xmlns="www.quicklearn.cn" > cbcye@live.com </Email>
- <Blog>http://cbcye.cnblogs.com</Blog>
- </Person>
- <Person ID="1002" >
- <Name lang="en" >Gary Zhang</Name>
- <Email xmlns="www.quicklearn.cn" > GaryZhang@cbcye.com</Email>
- <Blog>http://www.quicklearn.cn</Blog>
- </Person>
- </Root>
1.查询所有Blog节点值中带有 cn 字符串的Person节点。Xpath表达式:/Root//Person[contains(Blog,'cn')]
2.查询所有Blog节点值中带有 cn 字符串并且属性ID值中有01的Person节点。Xpath表达式:/Root//Person[contains(Blog,'cn') and contains(@ID,'01')]
xpath 学习笔记
1.依靠自己的属性,文本定位
//td[text()='Data Import']
//div[contains(@class,'cux-rightArrowIcon-on')]
//a[text()='马上注册']
//input[@type='radio' and @value='1'] 多条件
//span[@name='bruce'][text()='bruce1'][1] 多条件
//span[@id='bruce1' or text()='bruce2'] 找出多个
//span[text()='bruce1' and text()='bruce2'] 找出多个
2.依靠父节点定位
//div[@class='x-grid-col-name x-grid-cell-inner']/div
//div[@id='dynamicGridTestInstanceformclearuxformdiv']/div
//div[@id='test']/input
3.依靠子节点定位
//div[div[@id='navigation']]
//div[div[@name='listType']]
//div[p[@name='testname']]
4.混合型
//div[div[@name='listType']]//img
//td[a//font[contains(text(),'seleleium2从零开始 视屏')]]//input[@type='checkbox']
5.进阶部分
//input[@id='123']/following-sibling::input 找下一个兄弟节点
//input[@id='123']/preceding-sibling::span 上一个兄弟节点
//input[starts-with(@id,'123')] 以什么开头
//span[not(contains(text(),'xpath'))] 不包含xpath字段的span
6.索引
//div/input[2]
//div[@id='position']/span[3]
//div[@id='position']/span[position()=3]
//div[@id='position']/span[position()>3]
//div[@id='position']/span[position()<3]
//div[@id='position']/span[last()]
//div[@id='position']/span[last()-1]
7.substring 截取判断
<div data-for="result" id="swfEveryCookieWrap"></div>
//*[substring(@id,4,5)='Every']/@id 截取该属性 定位3,取长度5的字符
//*[substring(@id,4)='EveryCookieWrap'] 截取该属性从定位3 到最后的字符
//*[substring-before(@id,'C')='swfEvery']/@id 属性 'C'之前的字符匹配
//*[substring-after(@id,'C')='ookieWrap']/@id 属性'C之后的字符匹配
8.通配符*
//span[@*='bruce']
//*[@name='bruce']
9.轴
//div[span[text()='+++current node']]/parent::div 找父节点
//div[span[text()='+++current node']]/ancestor::div 找祖先节点
10.孙子节点
//div[span[text()='current note']]/descendant::div/span[text()='123']
//div[span[text()='current note']]//div/span[text()='123'] 两个表达的意思一样
11.following pre
https://www.baidu.com/s?wd=xpath&pn=10&oq=xpath&ie=utf-8&rsv_idx=1&rsv_pq=df0399f30003691c&rsv_t=7dccXo734hMJVeb6AVGfA3434tA9U%2FXQST0DrOW%2BM8GijQ8m5rVN2R4J3gU
//span[@class="fk fk_cur"]/../following::a 往下的所有a
//span[@class="fk fk_cur"]/../preceding::a[1] 往上的所有a
xpath提取多个标签下的text
在写爬虫的时候,经常会使用xpath进行数据的提取,对于如下的代码:
<div id="test1">大家好!</div>
使用xpath提取是非常方便的。假设网页的源代码在selector中:
data = selector.xpath('//div[@id="test1"]/text()').extract()[0]
就可以把“大家好!”提取到data变量中去。
然而如果遇到下面这段代码呢?
<div id="test2">美女,<font color=red>你的微信是多少?</font><div>
如果使用:
data = selector.xpath('//div[@id="test2"]/text()').extract()[0]
只能提取到“美女,”;
如果使用:
data = selector.xpath('//div[@id="test2"]/font/text()').extract()[0]
又只能提取到“你的微信是多少?”
可是我本意是想把“美女,你的微信是多少?”这一整个句子提取出来。
<div id="test3">我左青龙,<span id="tiger">右白虎,<ul>上朱雀,<li>下玄武。</li></ul>老牛在当中,</span>龙头在胸口。<div>
而且内部的标签还不固定,如果我有一百段这样类似的html代码,又如何使用xpath表达式,以最快最方便的方式提取出来?
使用xpath的string(.)
以第三段代码为例:
data = selector.xpath('//div[@id="test3"]')
info = data.xpath('string(.)').extract()[0]
这样,就可以把“我左青龙,右白虎,上朱雀,下玄武。老牛在当中,龙头在胸口”整个句子提取出来,赋值给info变量。2.3 非结构化数据之 lxml 库
lxml 是一种使用 Python 编写的库,可以迅速、灵活地处理 XML ,支持 XPath (XML Path Language),可以利用 XPath 语法快速的定位特定元素以及节点信息,提取出 HTML、XML 目标数据
lxml python 官方文档 http://lxml.de/index.html
简单使用
首先利用 lxml 来解析 HTML 代码,先来一个小例子来感受一下它的基本用法。使用 lxml 的 etree 库,然后利用 etree.HTML 初始化,然后我们将其打印出来。
- from lxml import etree
- text = '''
- <div>
- <ul>
- <li class="item-0"><a href="link1.html">first item</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
- <li class="item-1"><a href="link4.html">fourth item</a></li>
- <li class="item-0"><a href="link5.html">fifth item</a>
- </ul>
- </div>
- '''
- # Parses an HTML document from a string
- html = etree.HTML(text)
- # Serialize an element to an encoded string representation of its XML tree
- result = etree.tostring(html)
- print(result)
所以输出结果如下,不仅补全了 li 标签,还添加了 body,html 标签。
- <html><body><div>
- <ul>
- <li class="item-0"><a href="link1.html">first item</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
- <li class="item-1"><a href="link4.html">fourth item</a></li>
- <li class="item-0"><a href="link5.html">fifth item</a>
- </li></ul>
- </div>
- </body></html>
XPath 实例测试
(1)获取所有的 <li> 标签
- from lxml import etree
- html_text = '''
- <div>
- <ul>
- <li class="item-0"><a href="link1.html">first item</a></li>
- <li class="item-1"><a href="link2.html">second item</a></li>
- <li class="item-inactive"><a href="link3.html"><span class="bold">third item</span></a></li>
- <li class="item-1"><a href="link4.html">fourth item</a></li>
- <li class="item-0"><a href="link5.html">fifth item</a>
- </ul>
- </div>
- '''
- # Parses an HTML document from a string
- html = etree.HTML(text=html_text)
- # Serialize an element to an encoded string representation of its XML tree
- # result = etree.tostring(html)
- # print(result)
-
- print(type(html))
- result = html.xpath('//li')
- print(result)
- print(len(result))
- print(type(result))
- print(type(result[0]))
- 每个元素都是 Element 类型;是一个个的标签元素,类似现在的实例
<Element li at 0x1014e0e18> Element类型代表的就是
<li class="item-0"><a href="link1.html">first item</a></li>
[注意]:Element 类型是一种灵活的容器对象,用于在内存中存储结构化数据。每个 element 对象都具有以下属性:
1. tag:string对象,标签,用于标识该元素表示哪种数据(即元素类型)。
2. attrib:dictionary对象,表示附有的属性。
3. text:string对象,表示element的内容。
4. tail:string对象,表示element闭合之后的尾迹。

(2)获取 <li> 标签的所有 class
- html.xpath('//li/@class')
-
- # 运行结果:['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
(3)获取 <li> 标签下属性 href 为 link1.html 的 <a> 标签
- html.xpath('//li/a[@href="link1.html"]')
-
- # 运行结果:[<Element a at 0x10ffaae18>]
(4)获取 <li> 标签下的所有 <span> 标签
- 注意这么写是不对的 html.xpath('//li/span')
- 因为 / 是用来获取子元素的,而 <span> 并不是 <li> 的子元素,所以,要用双斜杠
-
- html.xpath('//li//span')
- # 运行结果:[<Element span at 0x10d698e18>]
(5)获取 <li> 标签下的所有 class,不包括 <li>
- html.xpath('//li/a//@class')
- # 运行结果:['blod']
(6)获取最后一个 <li> 的<a> 的 href
- html.xpath('//li[last()]/a/@href')
- # 运行结果:['link5.html']
(7)获取 class 为 bold 的标签
- result = html.xpath('//*[@class="bold"]')
- print result[0].tag
- # 运行结果:span
腾讯招聘:https://careers.tencent.com/search.html?pcid=40001
2.4 非结构化数据之 CSS Selector(CSS 选择器)
CSS 即层叠样式表Cascading Stylesheet。 Selector 来定位(locate)页面上的元素(Elements)。 Selenium 官网的Document 里极力推荐使用 CSS locator,而不是 XPath 来定位元素,原因是 CSS locator 比 XPath locator 速度快。
Beautiful Soup
安装:https://pypi.org/project/bs4/
官方文档链接: https://www.crummy.com/software/BeautifulSoup/bs4/doc/
Beautiful Soup 是从 HTML 或 XML 文件中提取数据,支持 Python 标准库中的 HTML 解析器。还支持一些第三方的解析器,其中一个是 lxml。
Beautiful Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup 就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。另一个可供选择的解析器是纯 Python 实现的 html5lib , html5lib 的解析方式与浏览器相同,可以选择下列方法来安装 html5lib: pip install html5lib
下表列出了主要的解析器:
| 解析器 | 使用方法 | 优势 | 劣势 |
| Python标准库 | BeautifulSoup(markup, "html.parser") | Python的内置标准库;执行速度适中;文档容错能力强 | Python 2.7.3 or 3.2.2前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快;文档容错能力强 ; | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, ["lxml-xml"]) BeautifulSoup(markup, "xml") | 速度快;唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") | 最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档 | 速度慢;不依赖外部扩展 |
推荐使用 lxml 作为解析器,因为效率更高。在 Python2.7.3 之前的版本和 Python3 中 3.2.2 之前的版本,必须安装 lxml 或html5lib, 因为那些 Python 版本的标准库中内置的 HTML 解析方法不够稳定.
示例:使用 BeautifulSoup 解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出:
- from bs4 import BeautifulSoup
-
- html_doc = """
- <html><head><title>The Dormouse's story</title></head>
- <body>
- <p class="title"><b>The Dormouse's story</b></p>
- <p class="story">Once upon a time there were three little sisters; and their names were
- <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
- <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
- <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
- and they lived at the bottom of a well.</p>
- <p class="story">...</p>
- """
-
- soup = BeautifulSoup(html_doc,'lxml')
-
- print(soup) # 打印 soup 对象的内容
打印 soup 对象的内容
格式化输出soup 对象
print(soup.prettify())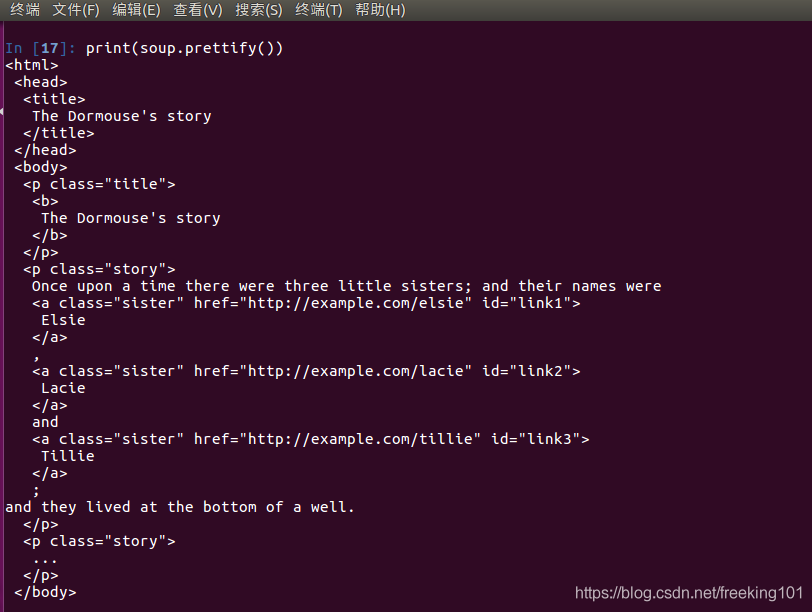
CSS 选择器
在写 CSS 时:标签名不加任何修饰。类名前加点。id名前加 “#”。
利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list
通过标签名查找
- from bs4 import BeautifulSoup
-
- html_doc = """
- <html><head><title>The Dormouse's story</title></head>
- <body>
- <p class="title"><b>The Dormouse's story</b></p>
- <p class="story">Once upon a time there were three little sisters; and their names were
- <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
- <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
- <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
- and they lived at the bottom of a well.</p>
- <p class="story">...</p>
- """
-
- soup = BeautifulSoup(html_doc, 'lxml')
-
- # print(soup) # 打印 soup 对象的内容
- print(soup.select('title'))
- # [<title>The Dormouse's story</title>]
- print(soup.select('a'))
- print(soup.select('b'))
- # [<b>The Dormouse's story</b>]
通过类名查找
print(soup.select('.sister'))通过 id 名查找
- print(soup.select('#link1'))
- #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]
直接子标签查找
- print(soup.select("head > title"))
- #[<title>The Dormouse's story</title>]
组合查找:组合查找即标签名与类名、id名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1的内容,
属性 和 标签 不属于 同一节点 二者需要用 空格分开
- print(soup.select('p #link1'))
- #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]
属性查找
查找时还可以加入属性元素,属性需要用中括号括起来
注意:属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到
- print(soup.select('a[class="sister"]'))
-
- print(soup.select('a[href="http://example.com/elsie"]'))
- #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]
同样,属性仍然可以与上述查找方式组合。不在同一节点的使用空格隔开,在同一节点的则不用加空格
- print soup.select('p a[href="http://example.com/elsie"]')
- #[<a class="sister" href="http://example.com/elsie" id="link1"></a>]
以上的 select 方法返回的结果都是列表形式,可以遍历形式输出
用 get_text() 方法来获取它的内容。
- print soup.select('title')[0].get_text()
- for title in soup.select('title'):
- print(title.get_text())
Tag:Tag 是什么?通俗点讲就是 HTML 中的一个个标签,例如:
- <a class="sister" href="http://example.com/elsie" id="link1">Elsie</a>
-
- print type(soup.select('a')[0])
-
- 输出:bs4.element.Tag
对于 Tag,它有两个重要的属性,是 name 和 attrs,下面我们分别来感受一下
1. name
- print(soup.name)
- print(soup.select('a')[0].name)
-
- 输出:
- [document]
- 'a'
soup 对象本身比较特殊,它的 name 即为 [document],对于其他内部标签,输出的值便为标签本身的名称。
2. attrs
- print(soup.select('a')[0].attrs)
-
- 输出:
- {'href': 'http://example.com/elsie', 'class': ['sister'], 'id': 'link1'}
- 在这里,我们把 soup.select('a')[0] 标签的所有属性打印输出了出来,得到的类型是一个字典。
- 如果我们想要单独获取某个属性,可以这样,例如我们获取它的 class 叫什么
-
-
- print soup.select('a')[0].attrs['class']
-
- 输出:
- ['sister']
实战案例:腾讯招聘网站:https://careers.tencent.com/search.html
2.5 正则表达式
掌握了 XPath、CSS选择器,为什么还要学习正则?
正则表达式,用标准正则解析,一般会把 HTML当 做普通文本,用指定格式匹配当相关文本,适合小片段文本,或者某一串字符(比如电话号码、邮箱账户),或者HTML包含javascript的代码,无法用CSS选择器或者XPath
在线正则表达式测试网站:https://tool.oschina.net/regex/
Python 正则表达式 官方文档:https://docs.python.org/zh-cn/3.8/library/re.html#regular-expression-objects
正则表达式常见概念
边界匹配
^ -- 与字符串开始的地方匹配,不匹配任何字符;
$ -- 与字符串结束的地方匹配,不匹配任何字符;
str = "cat abdcatdetf ios"
^cat : 验证该行以c开头紧接着是a,然后是t
ios$ : 验证该行以t结尾倒数第二个字符为a倒数第三个字符为c
^cat$: 以c开头接着是a->t然后是行结束:只有cat三个字母的数据行
^$ : 开头之后马上结束:空白行,不包括任何字符
^ : 行的开头,可以匹配任何行,因为每个行都有行开头\b -- 匹配一个单词边界,也就是单词和空格之间的位置,不匹配任何字符;
"er\b"可以匹配"never"中的"er",但不能匹配"verb"中的"er"。\B -- \b取非,即匹配一个非单词边界;
"er\B"能匹配"verb"中的"er",但不能匹配"never"中的"er"。数量词的贪婪模式与非贪婪模式
正则表达式通常用于在文本中查找匹配的字符串。Python里数量词默认是贪婪的(在少数语言里也可能是默认非贪婪),总是尝试匹配尽可能多的字符;非贪婪的则相反,总是尝试匹配尽可能少的字符。例如:
正则表达式"ab*"如果用于查找"abbbc",将找到"abbb"。而如果使用非贪婪的数量词"ab*?",将找到"a"。反斜杠问题
与大多数编程语言相同,正则表达式里使用"\"作为转义字符,这就可能造成反斜杠困扰。
假如你需要匹配文本中的字符"\",那么使用编程语言表示的正则表达式里将需要4个反斜杠"\\\\":前两个和后两个分别用于在编程语言里转义成反斜杠,转换成两个反斜杠后再在正则表达式里转义成一个反斜杠。
Python里的原生字符串很好地解决了这个问题,这个例子中的正则表达式可以使用r"\\"表示。
同样,匹配一个数字的"\\d"可以写成r"\d"。有了原生字符串,你再也不用担心是不是漏写了反斜杠,写出来的表达式也更直观。
- import re
- a=re.search(r"\\","ab123bb\c")
- print a.group()
- \
- a=re.search(r"\d","ab123bb\c")
- print a.group()
- 1
Python Re模块
Python 自带了 re 模块,它提供了对正则表达式的支持。
match 函数:re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match() 就返回 none。
下面是此函数的语法:re.match(pattern, string, flags=0)
| 参数 | 描述 |
| pattern | 这是正则表达式来进行匹配。 |
| string | 这是字符串,这将被搜索匹配的模式,在字符串的开头。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功则 re.match 方法返回一个匹配的对象,否则返回 None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
| 匹配对象的方法 | 描述 |
| group(num=0) | 此方法返回整个匹配(或指定分组num) |
| groups() | 此方法返回所有元组匹配的子组(空,如果没有) |
示例代码:
- #!/usr/bin/python
- import re
-
- line = "Cats are smarter than dogs"
-
- matchObj = re.match(r'(.*) are (.*?) .*', line, re.M | re.I)
-
- if matchObj:
- print("matchObj.group() : {0}".format(matchObj.group()))
- print("matchObj.group(1) : {0}".format(matchObj.group(1)))
- print(f"matchObj.group(2) : {matchObj.group(2)}")
- else:
- print("No match!!")
-
-
- '''
- 输出:
- matchObj.group() : Cats are smarter than dogs
- matchObj.group(1) : Cats
- matchObj.group(2) : smarter
- '''
正则表达式修饰符 - 选项标志
正则表达式字面可以包含一个可选的修饰符来控制匹配的各个方面。修饰符被指定为一个可选的标志。可以使用异或提供多个修饰符(|),如先前所示,并且可以由这些中的一个来表示:
| 修饰符 | 描述 |
| re.I(re.IGNORECASE) | 使匹配对大小写不敏感 |
| re.M(MULTILINE) | 多行匹配,影响 ^ 和 $ |
| re.S(DOTALL) | 使 . 匹配包括换行在内的所有字符 |
| re.X(VERBOSE) | 正则表达式可以是多行,忽略空白字符,并可以加入注释 |
findall() 函数
re.findall(pattern, string, flags=0)
返回字符串中所有模式的非重叠的匹配,作为字符串列表。该字符串扫描左到右,并匹配返回的顺序发现
默认:
pattren = "\w+"
target = "hello world\nWORLD HELLO"
re.findall(pattren,target)
['hello', 'world', 'WORLD', 'HELLO']
re.I:
re.findall("world", target,re.I)
['world', 'WORLD']
re.S:
re.findall("world.WORLD", target,re.S)
["world\nworld"]
re.findall("hello.*WORLD", target,re.S)
['hello world\nWORLD']
re.M:
re.findall("^WORLD",target,re.M)
["WORLD"]
re.X:
reStr = '''\d{3} #区号
-\d{8}''' #号码
re.findall(reStr,"010-12345678",re.X)
["010-12345678"]search 函数
re.search 扫描整个字符串并返回第一个成功的匹配。
下面是此函数语法:re.search(pattern, string, flags=0)
| 参数 | 描述 |
| pattern | 这是正则表达式来进行匹配。 |
| string | 这是字符串,这将被搜索到的字符串中的任何位置匹配的模式。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
匹配成功则 re.search 方法返回一个匹配的对象,否则返回None。
我们可以使用group(num) 或 groups() 匹配对象函数来获取匹配表达式。
- #!/usr/bin/python
- import re
-
- line = "Cats are smarter than dogs"
-
- searchObj = re.search(r'(.*) are (.*?) .*', line, re.M | re.I)
-
- if searchObj:
- print("matchObj.group() : {0}".format(searchObj.group()))
- print("matchObj.group(1) : {0}".format(searchObj.group(1)))
- print(f"matchObj.group(2) : {searchObj.group(2)}")
- else:
- print("No match!!")
-
- '''
- 输出:
- matchObj.group() : Cats are smarter than dogs
- matchObj.group(1) : Cats
- matchObj.group(2) : smarter
- '''
re.match 与 re.search 的区别
- re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;
- re.search 匹配整个字符串,直到找到一个匹配。
示例代码:
- #!/usr/bin/python
- import re
-
- line = "Cats are smarter than dogs";
-
- matchObj = re.match(r'dogs', line, re.M | re.I)
- if matchObj:
- print(f"match --> matchObj.group() : {matchObj.group()}")
- else:
- print("No match!!")
-
- searchObj = re.search(r'dogs', line, re.M | re.I)
- if searchObj:
- print(f"search --> searchObj.group() : {searchObj.group()}")
- else:
- print("Nothing found!!")
-
-
- '''
- No match!!
- search --> searchObj.group() : dogs
- '''
搜索 和 替换
Python 的 re 模块提供了 re.sub 用于替换字符串中的匹配项。
语法:re.sub(pattern, repl, string, max=0)
返回的字符串是在字符串中用 RE 最左边不重复的匹配来替换。如果模式没有发现,字符将被没有改变地返回。 可选参数 count 是模式匹配后替换的最大次数;count 必须是非负整数。缺省值是 0 表示替换所有的匹配。
实例:
- #!/usr/bin/python
- import re
-
- url = "http://hr.tencent.com/position.php?&start=10"
- page = re.search(r'start=(\d+)', url).group(1)
-
- next_url = re.sub(r'start=(\d+)', 'start=' + str(int(page) + 10), url)
- print(f"Next Url : {next_url}")
-
-
- # 当执行上面的代码,产生以下结果:
- # Next Url : http://hr.tencent.com/position.php?&start=20
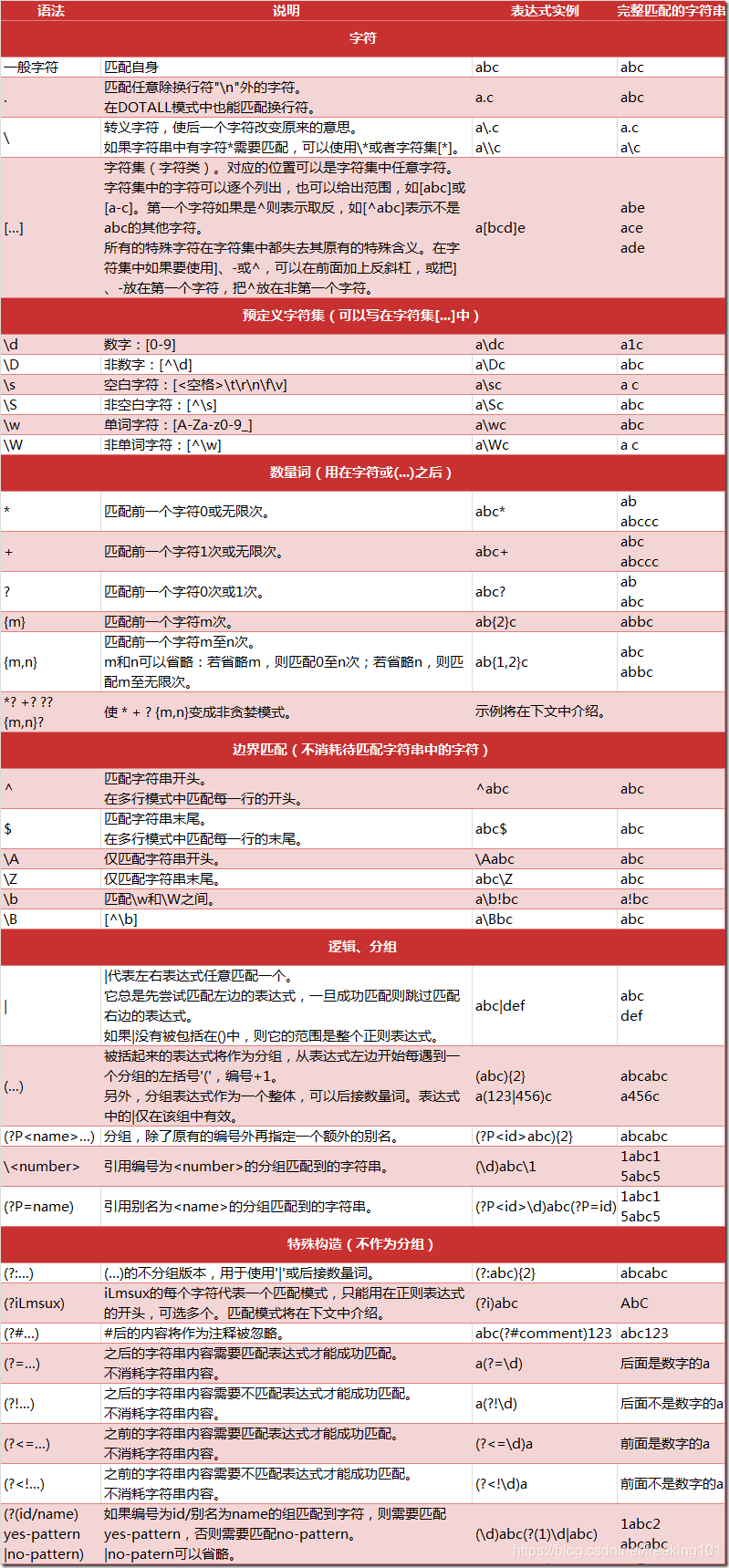
正则表达式语法
2.6 页面解析之结构化数据
结构化的数据是最好处理,一般都是类似 JSON 格式的字符串,直接解析 JSON 数据,提取 JSON 的关键字段即可。
JSON (JavaScript Object Notation) 是一种轻量级的数据交换格式;适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。Python 自带了 JSON 模块,直接 import json 就可以使用了。Json 模块提供了四个功能:dumps、dump、loads、load,用于字符串 和 python数据类型间进行转换
Python 操作 json 的标准 api 库参考:https://docs.python.org/zh-cn/3/library/json.html
在线 JSON 格式化代码:https://tool.oschina.net/codeformat/json
1. json.loads()
作用:json字符串 转化 python 的类型,返回一个python的类型
从 json 到 python 的类型转化对照如下:
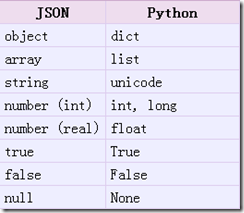
示例 :
- import json
-
- a = "[1,2,3,4]"
- b = '{"k1":1,"k2":2}' # 当字符串为字典时{}外面必须是''单引号{}里面必须是""双引号
- print(json.loads(a))
- # [1, 2, 3, 4]
-
- print(json.loads(b))
- # {'k2': 2, 'k1': 1}
豆瓣读书 示例:
- import re
- import json
- import requests
-
-
- def crawl():
- custom_headers = {
- 'Host': 'book.douban.com',
- 'Connection': 'keep-alive',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36',
- 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;'
- 'q=0.8,application/signed-exchange;v=b3;q=0.9',
- 'Referer': 'https://book.douban.com/',
- }
- db_url = 'https://book.douban.com/subject/26393282/'
- r = requests.get(url=db_url, headers=custom_headers, verify=False)
- if 200 == r.status_code:
- html_text = r.text
- result_list = re.findall(r'<script type="application/ld\+json">([\s\S]*?)</script>', html_text)
- if len(result_list):
- json_string = result_list[0]
- # print(json_string)
- json_dict = json.loads(json_string)
- # print(json.dumps(json_dict, ensure_ascii=False, indent=4))
-
- print(f'name: {json_dict["name"]}')
- print(f'author: {json_dict["author"][0]["name"]} {json_dict["author"][1]["name"]}')
- print(f'url: {json_dict["url"]}')
- print(f'isbn: {json_dict["isbn"]}')
-
-
- if __name__ == '__main__':
- crawl()
- pass
2. json.dumps()
实现 python 类型转化为 json 字符串,返回一个 str 对象
从 python 原始类型向 json 类型的转化对照如下:
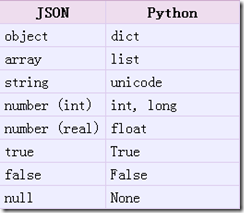
示例:
- import json
- a = [1,2,3,4]
- b ={"k1":1,"k2":2}
- c = (1,2,3,4)
-
- json.dumps(a)
- # '[1, 2, 3, 4]'
-
- json.dumps(b)
- # '{"k2": 2, "k1": 1}'
-
- json.dumps(c)
- # '[1, 2, 3, 4]'
json.dumps 中的 ensure_ascii 参数引起的中文编码问题
如果 Python Dict 字典含有中文,json.dumps 序列化时对中文默认使用的 ascii 编码
- import chardet
- import json
-
- b = {"name":"中国"}
-
- json.dumps(b)
- # '{"name": "\\u4e2d\\u56fd"}'
-
- print json.dumps(b)
- # {"name": "\u4e2d\u56fd"}
-
- chardet.detect(json.dumps(b))
- # {'confidence': 1.0, 'encoding': 'ascii'}
'中国' 中的 ascii 字符码,而不是真正的中文。想输出真正的中文需要指定 ensure_ascii=False
- json.dumps(b,ensure_ascii=False)
- # '{"name": "\xe6\x88\x91"}'
-
- print json.dumps(b,ensure_ascii=False)
- # {"name": "我"}
-
- chardet.detect(json.dumps(b,ensure_ascii=False))
- # {'confidence': 0.7525, 'encoding': 'utf-8'}
3. json.dump()
把 Python 类型 以 字符串的形式 写到文件中
- import json
- a = [1,2,3,4]
- json.dump(a,open("digital.json","w"))
- b = {"name":"我"}
- json.dump(b,open("name.json","w"),ensure_ascii=False)
- json.dump(b,open("name2.json","w"),ensure_ascii=True)
4. json.load()
读取 文件中 json 形式的字符串元素 转化成 python 类型
- # -*- coding: utf-8 -*-
- import json
- number = json.load(open("digital.json"))
- print number
- b = json.load(open("name.json"))
- print b
- b.keys()
- print b['name']
实战项目:获取 lagou 城市表信息
- import json
- import chardet
- import requests
-
- url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json?'
- custom_headers = {
- 'Host': 'www.lagou.com',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36',
-
- }
-
- response = requests.get(url, verify=False, headers=custom_headers)
-
- print(response.status_code)
- res_Html = response.text
- json_obj = json.loads(res_Html)
- print(type(json_obj))
- print(json_obj)
-
- city_list =[]
-
- all_cities = json_obj['content']['data']['allCitySearchLabels']
-
- print(all_cities.keys())
-
- for key in all_cities:
- print(type(all_cities[key]))
- for item in all_cities[key]:
- name = item['name']
- print(f'name: {name}')
- city_list.append(name)
-
- fp = open('city.json', 'w')
- content = json.dumps(city_list, ensure_ascii=False)
- print(content)
- fp.write(content)
- fp.close()
JSONPath
- JSON 信息抽取类库,从JSON文档中抽取指定信息的工具
- JSONPath 与 Xpath 区别:JsonPath 对于 JSON 来说,相当于 XPATH 对于XML。
下载地址:https://pypi.python.org/pypi/jsonpath/
安装方法:下载 jsonpath,解压之后执行 'python setup.py install '
| XPath | JSONPath | Result |
|
|
| the authors of all books in the store |
|
|
| all authors |
|
|
| all things in store, which are some books and a red bicycle. |
|
|
| the price of everything in the store. |
|
|
| the third book |
|
|
| the last book in order. |
|
|
| the first two books |
|
|
| filter all books with isbn number |
|
|
| filter all books cheapier than 10 |
|
|
| all Elements in XML document. All members of JSON structure. |
案例
还是以 http://www.lagou.com/lbs/getAllCitySearchLabels.json 为例,获取所有城市
- import json
- import jsonpath
- import chardet
- import requests
-
- url = 'http://www.lagou.com/lbs/getAllCitySearchLabels.json?'
- custom_headers = {
- 'Host': 'www.lagou.com',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36',
-
- }
-
- response = requests.get(url, verify=False, headers=custom_headers)
-
- print(response.status_code)
- res_Html = response.text
- json_obj = json.loads(res_Html)
-
- city_list = jsonpath.jsonpath(json_obj, '$..name')
-
- print(city_list)
- print(type(city_list))
- fp = open('city.json', 'w')
- content = json.dumps(city_list, ensure_ascii=False)
- print(content)
- fp.write(content)
- fp.close()
XML
xmltodict 模块让使用 XML 感觉跟操作 JSON 一样
Python 操作 XML 的第三方库参考:https://github.com/martinblech/xmltodict
模块安装:pip install xmltodict
- import json
- import xmltodict
-
- book_dict = xmltodict.parse("""
- <bookstore>
- <book>
- <title lang="eng">Harry Potter</title>
- <price>29.99</price>
- </book>
- <book>
- <title lang="eng">Learning XML</title>
- <price>39.95</price>
- </book>
- </bookstore>
- """)
-
- print(book_dict.keys())
- print(json.dumps(book_dict, indent=4))
数据提取总结
- HTML、XML:XPath、CSS选择器、正则表达式、转化成 Python 类型(xmltodict)
- JSON:JSONPath,转化成 Python 类型进行操作(json类)
- 其他(js、文本、电话号码、邮箱地址):正则表达式
3. 爬虫实践篇
右键 ---> 查看源代码 和 F12 区别:
- 右键查看源代码:实质是一个 Get 请求
- F12 是整个页面 所有的请求 url 加载完成的页面
3.1 案例 1:( 采集 百度贴吧 信息 )
http://tieba.baidu.com/f?ie=utf-8&kw=%E7%BD%91%E7%BB%9C%E7%88%AC%E8%99%AB&fr=search
解决问题思路:
- 1. 确认需求数据在哪。右键查看源代码
- 2. Fidder 模拟发送数据
代码示例:https://cuiqingcai.com/993.html
3.2 案例 2:( 惠州市网上挂牌交易系统 )
为例:http://www.hdgtjy.com/index/Index4/ 采集所有的挂牌交易信息
- import json
- import requests
-
-
- def crawl():
- url = 'http://www.hdgtjy.com/Index/PublicResults'
- custom_headers = {
- 'X-Requested-With': 'XMLHttpRequest',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36',
- 'Content-Type': 'application/x-www-form-urlencoded',
- }
-
- form_data = {
- 'page': 1,
- 'size': 500
- }
-
- r = requests.post(url=url, data=form_data, headers=custom_headers)
- if 200 == r.status_code:
- json_string = r.text
- json_dict = json.loads(json_string)
- print(json.dumps(json_dict, ensure_ascii=False, indent=4))
- else:
- print(f'status_code:{r.status_code}')
-
-
- if __name__ == '__main__':
- crawl()
- pass
3.3 案例 3:( Requests 基本用法 与 药品监督管理局 )
Requests
优点:Requests 继承了 urllib2 的所有特性。Requests 支持 HTTP 连接保持和连接池,支持使用 cookie 保持会话,支持文件上传,支持自动确定响应内容的编码,支持国际化的 URL 和 POST 数据自动编码。
缺陷:requests 不是 python 自带的库,需要另外安装 easy_install or pip install。直接使用不能异步调用,速度慢(自动确定响应内容的编码)。pip install requests
文档:http://cn.python-requests.org/zh_CN/latest/index.html http://www.python-requests.org/en/master/#
使用方法:
requests.get(url, data={'key1': 'value1'},headers={'User-agent','Mozilla/5.0'})
requests.post(url, data={'key1': 'value1'},headers={'content-type': 'application/json'})以 药品监督管理局 为例,采集 药品 ---> 国产药品 下的所有的商品信息:http://app1.nmpa.gov.cn/data_nmpa/face3/base.jsp?tableId=25&tableName=TABLE25&title=国产药品&bcId=152904713761213296322795806604
- # -*- coding: utf-8 -*-
- import urllib
- from lxml import etree
- import re
- import json
- import chardet
- import requests
-
-
- curstart = 2
-
- values = {
- 'tableId': '32',
- 'State': '1',
- 'bcId': '124356639813072873644420336632',
- 'State': '1',
- 'tableName': 'TABLE32',
- 'State': '1',
- 'viewtitleName': 'COLUMN302',
- 'State': '1',
- 'viewsubTitleName': 'COLUMN299,COLUMN303',
- 'State': '1',
- 'curstart': str(curstart),
- 'State': '1',
- 'tableView': urllib.quote("国产药品商品名"),
- 'State': '1',
- }
-
- post_headers = {
- 'Content-Type': 'application/x-www-form-urlencoded',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
- }
- url = "http://app1.sfda.gov.cn/datasearch/face3/search.jsp"
-
- response = requests.post(url, data=values, headers=post_headers)
-
- resHtml = response.text
- print response.status_code
- # print resHtml
-
- Urls = re.findall(r'callbackC,\'(.*?)\',null', resHtml)
- for url in Urls:
- # 坑
- print url.encode('gb2312')
查看运行结果,感受一下。
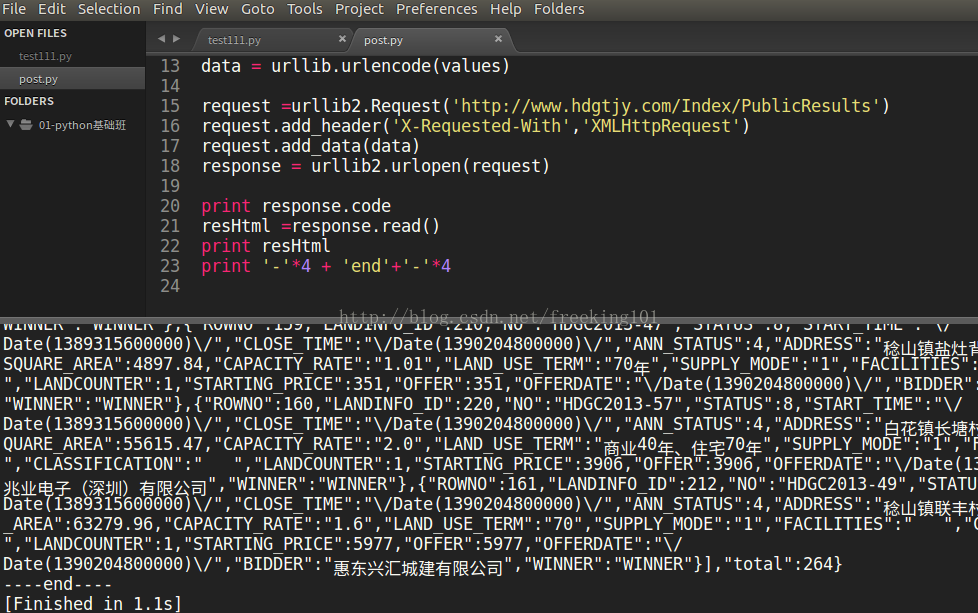
总结
1. User-Agent 伪装 Chrome,欺骗 web 服务器
2. urlencode 字典类型 Dict、元祖 转化成 url query 字符串
1. 完成商品详情页采集
2. 完成整个项目的采集
详情页
- # -*- coding: utf-8 -*-
- from lxml import etree
- import re
- import json
- import requests
-
- url ='http://app1.sfda.gov.cn/datasearch/face3/content.jsp?tableId=32&tableName=TABLE32&tableView=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&Id=211315'
- get_headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
- 'Connection': 'keep-alive',
- }
- item = {}
- response = requests.get(url,headers=get_headers)
- resHtml = response.text
- print response.encoding
- html = etree.HTML(resHtml)
- for site in html.xpath('//tr')[1:]:
- if len(site.xpath('./td'))!=2:
- continue
- name = site.xpath('./td')[0].text
- if not name:
- continue
- # value =site.xpath('./td')[1].text
- value = re.sub('<.*?>', '', etree.tostring(site.xpath('./td')[1],encoding='utf-8'))
- item[name.encode('utf-8')] = value
-
- json.dump(item,open('sfda.json','w'),ensure_ascii=False)
完整项目
- # -*- coding: utf-8 -*-
- import urllib
- from lxml import etree
- import re
- import json
- import requests
-
-
- def ParseDetail(url):
- # url = 'http://app1.sfda.gov.cn/datasearch/face3/content.jsp?tableId=32&tableName=TABLE32&tableView=%B9%FA%B2%FA%D2%A9%C6%B7%C9%CC%C6%B7%C3%FB&Id=211315'
- get_headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
- 'Connection': 'keep-alive',
- }
- item = {}
- response = requests.get(url, headers=get_headers)
- resHtml = response.text
- print response.encoding
- html = etree.HTML(resHtml)
- for site in html.xpath('//tr')[1:]:
- if len(site.xpath('./td')) != 2:
- continue
- name = site.xpath('./td')[0].text
- if not name:
- continue
- # value =site.xpath('./td')[1].text
- value = re.sub('<.*?>', '', etree.tostring(site.xpath('./td')[1], encoding='utf-8'))
- value = re.sub('', '', value)
- item[name.encode('utf-8').strip()] = value.strip()
-
- # json.dump(item, open('sfda.json', 'a'), ensure_ascii=False)
- fp = open('sfda.json', 'a')
- str = json.dumps(item, ensure_ascii=False)
- fp.write(str + '\n')
- fp.close()
-
-
- def main():
- curstart = 2
-
- values = {
- 'tableId': '32',
- 'State': '1',
- 'bcId': '124356639813072873644420336632',
- 'State': '1',
- 'tableName': 'TABLE32',
- 'State': '1',
- 'viewtitleName': 'COLUMN302',
- 'State': '1',
- 'viewsubTitleName': 'COLUMN299,COLUMN303',
- 'State': '1',
- 'curstart': str(curstart),
- 'State': '1',
- 'tableView': urllib.quote("国产药品商品名"),
- 'State': '1',
- }
-
- post_headers = {
- 'Content-Type': 'application/x-www-form-urlencoded',
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
- }
- url = "http://app1.sfda.gov.cn/datasearch/face3/search.jsp"
-
- response = requests.post(url, data=values, headers=post_headers)
-
- resHtml = response.text
- print response.status_code
- # print resHtml
-
- Urls = re.findall(r'callbackC,\'(.*?)\',null', resHtml)
- for url in Urls:
- # 坑
- url = re.sub('tableView=.*?&', 'tableView=' + urllib.quote("国产药品商品名") + "&", url)
- ParseDetail('http://app1.sfda.gov.cn/datasearch/face3/' + url.encode('gb2312'))
-
-
- if __name__ == '__main__':
- main()
3.4 案例 4:( 拉钩招聘网 )
以拉钩具体详情页为例,进行抓取。http://www.lagou.com/jobs/2101463.html
- from lxml import etree
- import requests
- import re
-
- response = requests.get('http://www.lagou.com/jobs/2101463.html')
- resHtml = response.text
-
- html = etree.HTML(resHtml)
-
- title = html.xpath('//h1[@title]')[0].attrib['title']
- #salary= html.xpath('//span[@class="red"]')[0].text
-
- salary = html.xpath('//dd[@class="job_request"]/p/span')[0].text
- worklocation = html.xpath('//dd[@class="job_request"]/p/span')[1].text
- experience = html.xpath('//dd[@class="job_request"]/p/span')[2].text
- education = html.xpath('//dd[@class="job_request"]/p/span')[3].text
- worktype = html.xpath('//dd[@class="job_request"]/p/span')[4].text
- Temptation = html.xpath('//dd[@class="job_request"]/p[2]')[0].text
-
- print salary,worklocation,experience,education,worktype,Temptation
-
- description_tag = html.xpath('//dd[@class="job_bt"]')[0]
- description = etree.tostring( description_tag,encoding='utf-8')
- #print description
- deal_descp = re.sub('<.*?>','',description)
- print deal_descp.strip()
- publisher_name = html.xpath('//*[@class="publisher_name"]//@title')[0]
- pos = html.xpath('//*[@class="pos"]')[0].text
- chuli_lv = html.xpath('//*[@class="data"]')[0].text
- chuli_yongshi = html.xpath('//*[@class="data"]')[1].text
-
- print chuli_lv,chuli_yongshi,pos,publisher_name
3.5 案例 5:( 爬取糗事百科段子 )
确定URL并抓取页面代码,首先我们确定好页面的URL是 http://www.qiushibaike.com/8hr/page/4, 其中最后一个数字1代表页数,我们可以传入不同的值来获得某一页的段子内容。我们初步构建如下的代码来打印页面代码内容试试看,先构造最基本的页面抓取方式,看看会不会成功。在Composer raw 模拟发送数据
GET http://www.qiushibaike.com/8hr/page/2/ HTTP/1.1
Host: www.qiushibaike.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36
Accept-Language: zh-CN,zh;q=0.8在删除了 User-Agent、Accept-Language 报错。应该是 headers 验证的问题,加上一个 headers 验证试试看
- # -*- coding:utf-8 -*-
- import urllib
- import requests
- import re
- import chardet
- from lxml import etree
-
- page = 2
- url = 'http://www.qiushibaike.com/8hr/page/' + str(page) + "/"
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
- 'Accept-Language': 'zh-CN,zh;q=0.8'}
- try:
- response = requests.get(url, headers=headers)
- resHtml = response.text
-
- html = etree.HTML(resHtml)
- result = html.xpath('//div[contains(@id,"qiushi_tag")]')
- for site in result:
- #print etree.tostring(site,encoding='utf-8')
-
- item = {}
- imgUrl = site.xpath('./div/a/img/@src')[0].encode('utf-8')
- username = site.xpath('./div/a/@title')[0].encode('utf-8')
- #username = site.xpath('.//h2')[0].text
- content = site.xpath('.//div[@class="content"]')[0].text.strip().encode('utf-8')
- vote = site.xpath('.//i')[0].text
- #print site.xpath('.//*[@class="number"]')[0].text
- comments = site.xpath('.//i')[1].text
-
- print imgUrl, username, content, vote, comments
-
- except Exception, e:
- print e
多线程爬虫 实战:糗事百科
python 下多线程的思考
Queue 是 python 中的标准库,可以直接 import Queue 引用; 队列是线程间最常用的交换数据的形式。对于共享资源,加锁是个重要的环节。因为 python 原生的 list,dict 等,都是 not thread safe 的。而 Queue,是线程安全的,因此在满足使用条件下,建议使用队列。
Python Queue 模块有三种队列及构造函数:
1、Python Queue模块的FIFO队列先进先出。 class Queue.Queue(maxsize)
2、LIFO类似于堆,即先进后出。 class Queue.LifoQueue(maxsize)
3、还有一种是优先级队列级别越低越先出来。 class Queue.PriorityQueue(maxsize)Queue(队列对象)
初始化: class Queue.Queue(maxsize) FIFO 先进先出
包中的常用方法:
Queue.qsize() 返回队列的大小
Queue.empty() 如果队列为空,返回True,反之False
Queue.full() 如果队列满了,返回True,反之False
Queue.full 与 maxsize 大小对应
Queue.get([block[, timeout]])获取队列,timeout等待时间调用队列对象的 get()方法从队头删除并返回一个项目。可选参数为block,默认为True。
如果队列为空且 block 为 True,get() 就使调用线程暂停,直至有项目可用。
如果队列为空且 block 为 False,队列将引发 Empty 异常。
- import Queue
-
- # 创建一个“队列”对象
- myqueue = Queue.Queue(maxsize = 10)
-
- # 将一个值放入队列中
- myqueue.put(10)
-
- # 将一个值从队列中取出
- myqueue.get()

示例代码:
- # -*- coding:utf-8 -*-
- import requests
- from lxml import etree
- from Queue import Queue
- import threading
- import time
- import json
-
-
- class thread_crawl(threading.Thread):
- '''
- 抓取线程类
- '''
-
- def __init__(self, threadID, q):
- threading.Thread.__init__(self)
- self.threadID = threadID
- self.q = q
-
- def run(self):
- print "Starting " + self.threadID
- self.qiushi_spider()
- print "Exiting ", self.threadID
-
- def qiushi_spider(self):
- # page = 1
- while True:
- if self.q.empty():
- break
- else:
- page = self.q.get()
- print 'qiushi_spider=', self.threadID, ',page=', str(page)
- url = 'http://www.qiushibaike.com/hot/page/' + str(page) + '/'
- headers = {
- 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36',
- 'Accept-Language': 'zh-CN,zh;q=0.8'}
- # 多次尝试失败结束、防止死循环
- timeout = 4
- while timeout > 0:
- timeout -= 1
- try:
- content = requests.get(url, headers=headers)
- data_queue.put(content.text)
- break
- except Exception, e:
- print 'qiushi_spider', e
- if timeout < 0:
- print 'timeout', url
-
-
- class Thread_Parser(threading.Thread):
- '''
- 页面解析类;
- '''
-
- def __init__(self, threadID, queue, lock, f):
- threading.Thread.__init__(self)
- self.threadID = threadID
- self.queue = queue
- self.lock = lock
- self.f = f
-
- def run(self):
- print 'starting ', self.threadID
- global total, exitFlag_Parser
- while not exitFlag_Parser:
- try:
- '''
- 调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。
- 如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。
- 如果队列为空且block为False,队列将引发Empty异常。
- '''
- item = self.queue.get(False)
- if not item:
- pass
- self.parse_data(item)
- self.queue.task_done()
- print 'Thread_Parser=', self.threadID, ',total=', total
- except:
- pass
- print 'Exiting ', self.threadID
-
- def parse_data(self, item):
- '''
- 解析网页函数
- :param item: 网页内容
- :return:
- '''
- global total
- try:
- html = etree.HTML(item)
- result = html.xpath('//div[contains(@id,"qiushi_tag")]')
- for site in result:
- try:
- imgUrl = site.xpath('.//img/@src')[0]
- title = site.xpath('.//h2')[0].text
- content = site.xpath('.//div[@class="content"]')[0].text.strip()
- vote = None
- comments = None
- try:
- vote = site.xpath('.//i')[0].text
- comments = site.xpath('.//i')[1].text
- except:
- pass
- result = {
- 'imgUrl': imgUrl,
- 'title': title,
- 'content': content,
- 'vote': vote,
- 'comments': comments,
- }
-
- with self.lock:
- # print 'write %s' % json.dumps(result)
- self.f.write(json.dumps(result, ensure_ascii=False).encode('utf-8') + "\n")
-
- except Exception, e:
- print 'site in result', e
- except Exception, e:
- print 'parse_data', e
- with self.lock:
- total += 1
-
- data_queue = Queue()
- exitFlag_Parser = False
- lock = threading.Lock()
- total = 0
-
- def main():
- output = open('qiushibaike.json', 'a')
-
- #初始化网页页码page从1-10个页面
- pageQueue = Queue(50)
- for page in range(1, 11):
- pageQueue.put(page)
-
- #初始化采集线程
- crawlthreads = []
- crawlList = ["crawl-1", "crawl-2", "crawl-3"]
-
- for threadID in crawlList:
- thread = thread_crawl(threadID, pageQueue)
- thread.start()
- crawlthreads.append(thread)
-
- #初始化解析线程parserList
- parserthreads = []
- parserList = ["parser-1", "parser-2", "parser-3"]
- #分别启动parserList
- for threadID in parserList:
- thread = Thread_Parser(threadID, data_queue, lock, output)
- thread.start()
- parserthreads.append(thread)
-
- # 等待队列清空
- while not pageQueue.empty():
- pass
-
- # 等待所有线程完成
- for t in crawlthreads:
- t.join()
-
- while not data_queue.empty():
- pass
- # 通知线程是时候退出
- global exitFlag_Parser
- exitFlag_Parser = True
-
- for t in parserthreads:
- t.join()
- print "Exiting Main Thread"
- with lock:
- output.close()
-
-
- if __name__ == '__main__':
- main()
3.5 模拟登陆 及 验证码
使用表单登陆
这种情况属于 post 请求,即先向服务器发送表单数据,服务器再将返回的 cookie 存入本地。
data = {'data1':'XXXXX', 'data2':'XXXXX'}Requests:data 为 dict,json
- import requests
-
- response = requests.post(url=url, data=data)
使用 cookie 登陆
使用 cookie 登陆,服务器会认为你是一个已登陆的用户,所以就会返回给你一个已登陆的内容。因此,需要验证码的情况可以使用带验证码登陆的 cookie 解决。
- import requests
-
- requests_session = requests.session()
- response = requests_session.post(url=url_login, data=data)
若存在验证码,此时采用 response = requests_session.post(url=url_login, data=data)是不行的,做法应该如下:
- response_captcha = requests_session.get(url=url_login, cookies=cookies)
- response1 = requests.get(url_login) # 未登陆
- response2 = requests_session.get(url_login) # 已登陆,因为之前拿到了Response Cookie!
- response3 = requests_session.get(url_results) # 已登陆,因为之前拿到了Response Cookie!
实战项目:登录豆瓣,并发表动态
模拟登陆的重点,在于找到表单真实的提交地址,然后携带cookie,post数据即可,只要登陆成功,我们就可以访问其他任意网页,从而获取网页内容。
一个请求,只要正确模拟了method,url,header,body 这四要素,任何内容都能抓下来,而所有的四个要素,只要打开浏览器-审查元素-Network就能看到!
验证码这一块,现在主要是先把验证码的图片保存下来,手动输入验证码,后期可以研究下 python 自动识别验证码。
但是验证码保存成本地图片,看的不不太清楚(有时间在改下),可以把验证码的 url 地址在浏览器中打开,就可以看清楚验证码了。
主要实现 登录豆瓣,并发表一句话
- # -*- coding:utf-8 -*-
-
- import re
- import requests
- from bs4 import BeautifulSoup
-
-
- class DouBan(object):
- def __init__(self):
- self.__username = "豆瓣帐号" # 豆瓣帐号
- self.__password = "豆瓣密码" # 豆瓣密码
- self.__main_url = "https://www.douban.com"
- self.__login_url = "https://www.douban.com/accounts/login"
- self.__proxies = {
- "http": "http://172.17.18.80:8080",
- "https": "https://172.17.18.80:8080"
- }
- self.__headers = {
- "Host": "www.douban.com",
- "Origin": self.__main_url,
- "Referer": self.__main_url,
- "Upgrade-Insecure-Requests": "1",
- "User-Agent": 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 '
- '(KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'
- }
- self.__data = {
- "source": "index_nav",
- "redir": "https://www.douban.com",
- "form_email": self.__username,
- "form_password": self.__password,
- "login": u"登录"
- }
-
- self.__session = requests.session()
- self.__session.headers = self.__headers
- self.__session.proxies = self.__proxies
- pass
-
- def login(self):
- r = self.__session.post(self.__login_url, self.__data)
- if r.status_code == 200:
- html = r.text
- soup = BeautifulSoup(html, "lxml")
- captcha_address = soup.find('img', id='captcha_image')['src']
- print(captcha_address)
- # 验证码存在
- if captcha_address:
- # 利用正则表达式获取captcha的ID
- re_captcha_id = r'<input type="hidden" name="captcha-id" value="(.*?)"/'
- captcha_id = re.findall(re_captcha_id, html)[0]
- print(captcha_id)
- # 保存到本地
- with open('captcha.jpg', 'w') as f:
- f.write(requests.get(captcha_address, proxies=self.__proxies).text)
- captcha = input('please input the captcha:')
-
- self.__data['captcha-solution'] = captcha
- self.__data['captcha-id'] = captcha_id
- r = self.__session.post(self.__login_url, data=self.__data)
- if r.status_code == 200:
- print("login success")
- data = {
- "ck": "NBJ2",
- "comment": "模拟登录"
- }
- r = self.__session.post(self.__main_url, data=data)
- print(r.status_code)
-
- else:
- print("登录不需要验证码")
- # 不需要验证码的逻辑 和 上面输入验证码之后 的 逻辑 一样
- # 此处代码省略
- else:
- print("login fail", r.status_code)
- pass
-
-
- if __name__ == "__main__":
- t = DouBan()
- t.login()
- pass
运行截图:

登录豆瓣帐号,可以看到说了一句话 “模拟登录”

Python 性能优化
因为 GIL 的存在,Python很难充分利用多核 CPU 的优势。
但是,可以通过内置的模块 multiprocessing 实现下面几种并行模式:
- 1、 多进程并行编程:对于CPU密集型的程序,可以使用multiprocessing的Process、Pool 等封装好的类,通过多进程的方式实现并行计算。但是因为进程中的通信成本比较大,对于进程之间需要大量数据交互的程序效率未必有大的提高。
- 2、 多线程并行编程:对于IO密集型的程序,multiprocessing.dummy 模块使用 multiprocessing 的接口封装 threading,使得多线程编程也变得非常轻松(比如可以使用Pool的map接口,简洁高效)。
- 3、分布式:multiprocessing 中的 Managers 类 提供了可以在不同进程之共享数据的方式,可以在此基础上开发出分布式的程序。 不同的业务场景可以选择其中的一种或几种的组合实现程序性能的优化。

