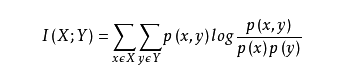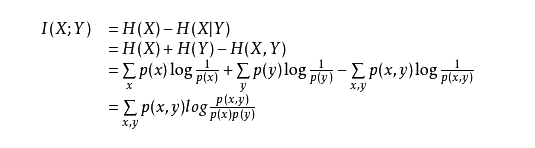- 1微信小程序接入直播_微信小程序如何对接直播
- 2鸿蒙开发—【扩展textinput组件】_鸿蒙开发 textinput换行
- 3vue3 hooks封装方法
- 4简述C++ 多线程编程:实现并发性与性能的关键_c++ 多线程 性能
- 5linux shell常用实例,常用shell实例1
- 6ChatGPT 消息发不出去了?我找到解决方案了_chatgpt发不出消息
- 7011-Grafana之Pie Chart使用_grafana pie chart sql
- 8Java反射获取Android系统属性值_安卓代码反射遍历activity中所有属性名称
- 92023年河南省中等职业教育技能大赛网络建设与运维项目比赛试题(一)_ac使用loopback1 ipv4 地址分别为ac1 的ipv4管理地址。ap三层自动注册,ap采
- 10java ftpclient getreplycode_FtpClient ReplyCode 意义及 FtpClientHelper辅助类
交叉熵,相对熵(KL散度),互信息(信息增益)及其之间的关系_最大互信息与交叉熵损失有什么关系
赞
踩
刚刚查了点资料,算是搞清楚了相对熵与互信息之间的关系。在这里记录一下,后面忘记的话可以方便查阅。
首先,同一个意思的概念太多也是我开始搞混这些概念的原因之一。
首先说一下编码问题:
最短的平均编码长度 = 信源的不确定程度 / 传输的表达能力。
其中信源的不确定程度,用信源的熵来表示,又称之为被表达者,传输的表达能力,称之为表达者表达能力,如果传输时有两种可能,那表达能力就是
l
o
g
2
2
=
1
log_{2}^{2}=1
log22=1,如果是传输时有三种可能,那表达能力就是
l
o
g
2
3
log_2^3
log23。
交叉熵
假设有这样一个样本集,p为它的真实分布,q为它的估计分布。如果按照真实分布p来度量识别一个样本所需要的编码长度的期望为:
如果使用估计的分布q来表示来自真实分布p的平均编码长度,则下面表达式就是交叉熵:
交叉熵可以这么理解:用估计的分布对来自真实分布的样本进行编码,所需要的平均长度。
根据Gibbs’ inequality可知交叉熵要大于等于真实分布的信息熵(最优编码)。Gibbs’ inequality如下:
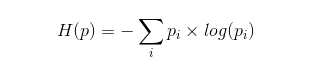
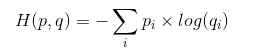
对于样本服从分布
P
=
(
p
1
,
p
2
,
.
.
.
p
n
)
P=(p_1,p_2,...p_n)
P=(p1,p2,...pn),对于其他任何概率分布
Q
=
(
q
1
,
q
2
,
.
.
.
q
n
)
Q=(q_1,q_2,...q_n)
Q=(q1,q2,...qn),都有:
当且仅当
p
i
=
q
i
,
i
=
1...
n
p_i = q_i,i=1...n
pi=qi,i=1...n时,等号成立。
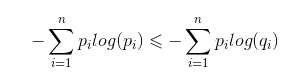
相对熵就是KL散度,用来度量两个分布之间的距离。
由交叉熵可知,用估计的概率分布所需的编码长度,比真实分布的编码长,但是长多少呢?这个就需要另一个度量,相对熵,也称KL散度。
相对熵:用交叉熵减去真实分布的信息熵,表示用估计分布计算的平均编码长度比最短平均编码长度长多少。因此有:
交叉熵=信息熵+相对熵
由于对数函数是凸函数,则有:
因此,相对熵始终是大于等于0的。从上面的描述中也可以看得出,相对熵其实可以理解成两种分布的距离。
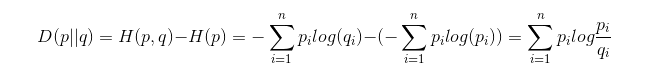
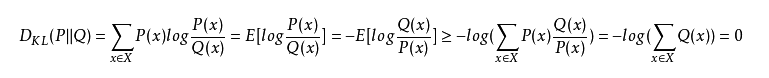
互信息
两个随机变量X,Y的互信息,定义为:X,Y的联合分布P(X,Y)与乘积分布P(X)P(Y)的相对熵:
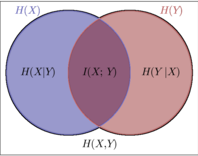
怎么理解呢?也就是用乘积分布P(X)P(Y)与联合分布的交叉熵,减去联合分布的信息熵,就是互信息,还不好理解,就可以看如下图示:
相当于一种不严谨的说法就是:
(
X
+
Y
)
−
X
⋃
Y
=
X
⋂
Y
(X+Y)-X\bigcup Y=X\bigcap Y
(X+Y)−X⋃Y=X⋂Y
或许另一种等价的定义好理解:
I
(
X
;
Y
)
=
H
(
X
)
−
H
(
X
∣
Y
)
I(X;Y)=H(X)-H(X|Y)
I(X;Y)=H(X)−H(X∣Y)
到这里相信大家已经看出来了,上面这个公式表示的就是,在Y已知的条件下,X的信息量减少的多少。也就是决策树中的信息增益
其实两种定义是等价的: