
- 1Ai创作系统源码的原理是什么?如何开发一套属于企业私有的AIGC工具_ai源码系统
- 2Python打包发布_assertionerror: unsupported schema
- 3LaTeX基本文档结构_\backmatter 包
- 4flex布局实现等分_flex 二等分
- 5测试金字塔
- 6软件工程应用与实践(2)——application.properties配置文件分析_application.properties文件的作用
- 7C++:红黑树_c++ 红黑树
- 8mybatis3 :insert返回插入的主键(selectKey)
- 9【2023亲测可用】JS 获取电脑本地IP 和 电脑网络IP(外网IP|公网IP)_js获取当前电脑ip地址
- 10最新(2023.3.17)配置llvm、clang、clangd、clang-tidy方法,极其简单,轻松上手_clang-tidy 安装 windows
大数据开发的面试总结_大数据开发面试
赞
踩
想学习架构师构建流程请跳转:Java架构师系统架构设计

1 谈谈你对大数据的理解
复盘一下对于我这个java程序员/项目经理/架构师,在简历中写了很多对于大数据项目开发的人的一些问题,也许能帮到大家,因为我是一个对于分布式,高并发,高性能,高可用,海量数据都有解决方案和架构思想一个人,不断的突破自己,能更好的发挥自己在企业中的价值。对于大数据和算法体系可能有些java工程师觉得这不关我们的事儿,但是随着业务发展数据体系不断变大,用户量剧增,除非这个企业不发展技术,那是很可怕的一件事儿,我们必须要对大数据的一些基础的知识有大致的了解,这样才可以使用大数据的运用去完成你业务相关的一些能力。然后再对应的一个项目介绍,或者面试官的一扩展介绍当中,你才能够体现出你在大数据和算法方面有一些积累,并且有一些成型的落地应用。那我们首先来一起看一下大数据的一个知识脉络体系。那大数据平台整个来说的话,经过了最近几年的一个发展,本质上来说已经变成了一些相当成熟的应用体系,所以面试也是一项加分项。
MapReduce核心原理?
我们都知道所谓的大数据处理本质上来说是你如何去处理大量级别的一个大规模的数据,并且在一个有限的时间内可以得到你想要的一个处理结果。那google 的map reduce 的一个思想,本质上来说奠定了大数据所有处理器的一个处理思想集合。它奠定了你作为大数据处理的基本思想map reduce 的处理思想非常的简单,主要分为map 和reduce 两部分。那我们在这边看一下这张图,这张图假设我们要读取一个文件系统。
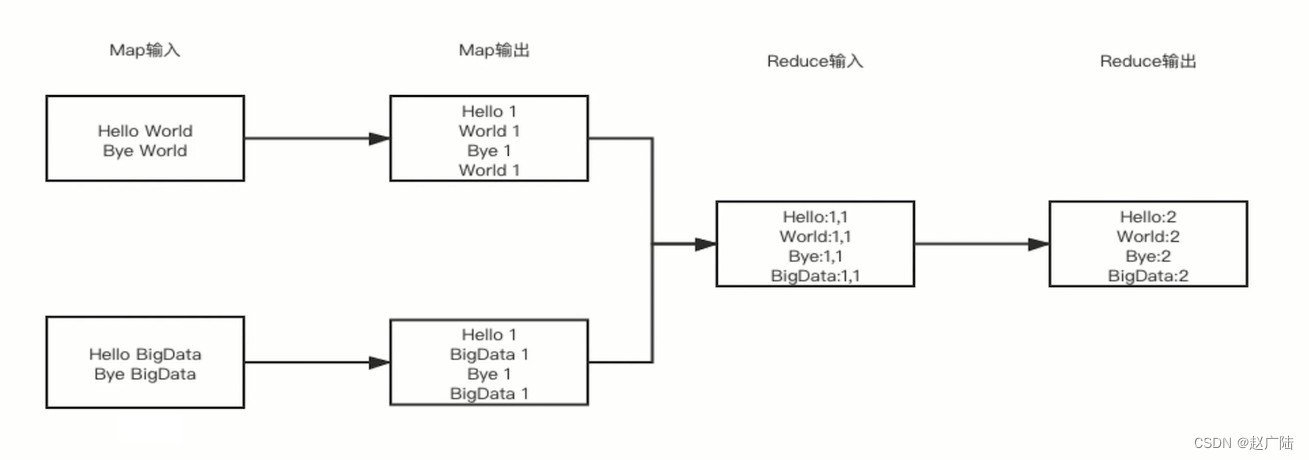
这个文件系统内有以行为切割符的这样的一些文件字符串。我们要做一个demo count 单词技术这样的一个功能。那我们怎么做呢?本质上来说,我们采取map reduce 的思想,使用对应的一个切割器split,将每行的一个数据切切成对应的一个key 和value。对的形式。
我们这边的key 就是字符串本身,而value 就是它出现的一个频次。然后我们通过reduce 对应的一个处理函数,将其reduce 给它add count 成对应的一个技术的项目数量。说白了就是分而治之的思想。
2 HDFS核心原理
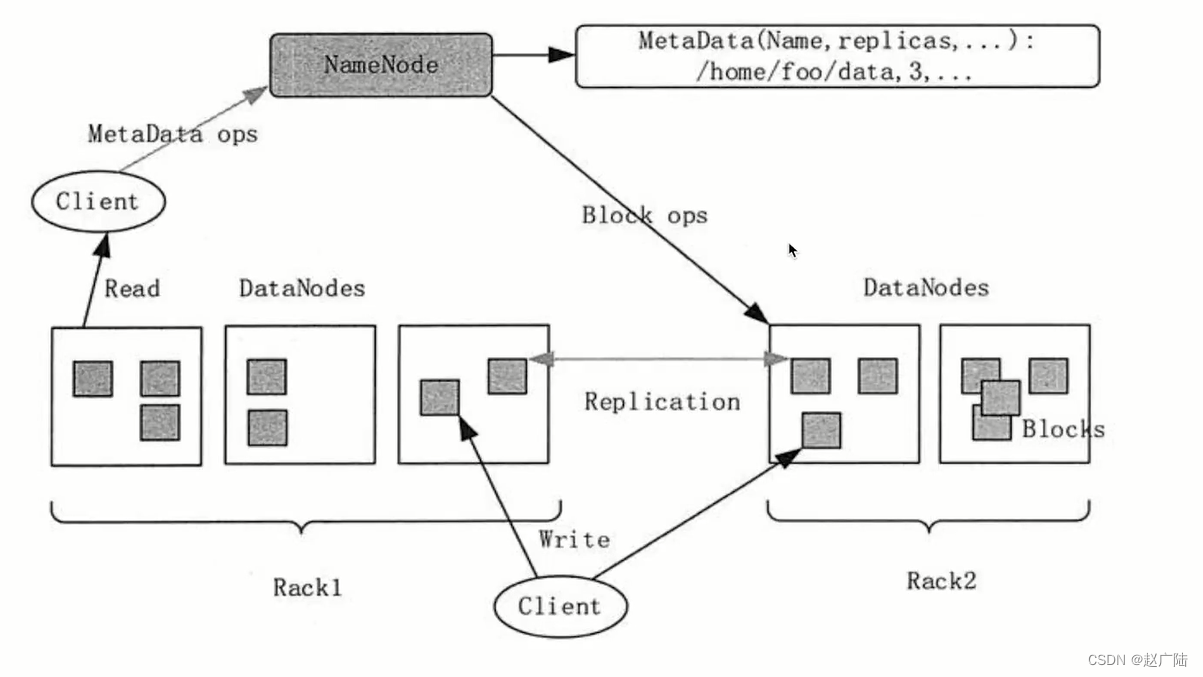
下来我们来看一下Hadoop对应的一个大数据家族当中另一个非常重要的hdfs,Hadoop分布式文件系统。那Hadoop分布式文件系统提供给了整个的一个大数据平台分布式文件处理的一个能力。
那我们来看一下之前讲的mapreduce。map,request分为三个环节,map的输入、reduce的输出,以及map和reduce中间的一个shuffle的一个合并数据的一个转化。
这个的一个输入数据、结果数据和一个中间数据,在Hadoop mapreduce的程序框架当中,都是通过hdfs做文件系统级别的一个数据转储用的。
如果说我们不试运行的mapreduce,单纯这样的一个hdfs也可以对外提供网络文件系统这样的一个分布式的一个存储环境。
因此hdfs和。map reduce并不是一个强绑定的关系,hdfs提供给我们了一些client的一个api,能够让我们以对应的一个本地文件的一个方式去read write读取、写入对应的一个文件系统,以此来满足整个的一个分布式文件系统当中的一个可扩展的需求。
那换句话来说,如果说今天我们有hdfs,我们完全在上面可以跑mapreduce程序,也可以不跑mapreduce。好,类似于像hive spark、hbase这样的一些mapreduce改进版的程序。那假设我们有mapreduce的程序,我们也可以不去在hdfs上面运行,而是是在本地内存,甚至于本地文件电系统当中去做对应的运行。
这两者之间都是结偶的,只不过恰好哈杜普提供给我们了mapreduce和hdfs。的这样的一个融合的方案。好,那接下来我们来看一下,既然hdfs对整个的一个大数据平台来说说提供的是一个存储层这样一个能力,那它势必就要能够满足整个的分布式的一个架构需要。
那我们来看一下,hdfs提供给了我们外部什么样的一个文件读取和写入的能力呢?
name node和data node之间是一种类似于像master和worker这种这样子的一个结构。name node上存储了整个分布式文件系统的meta data,包括我什么样的文件放在什么样的data node当中,如何去做分块,以及它的一个replication的数量分别是多少。举个例子,当我的client要去读取一个home/for/data这样的一个路径下的一个文件的时候,它首先要向我们的name node去请求对应的这样的一个文件系统的meta data。
这个时候由于我们的name node和data node之间是通过zookeeper请求去保持对应的一个网络通信的,因此。我们的name node清楚地知道说我对应的哪个data node活着,并且通过meta data里的数据还清楚地知道说,我对应的这样的一个文件系统需要到哪个data node当中去存取。
那这个时候我们的name node就会寻找离这个client最近的一个data node,并且含有对应的这样的一个home for data这样的一个文件的一个meta data的地址信息返回给我们的client。
那我们的client拿到了这样一个data node的地址和快信息之后,就会向这个data node去发起read的请求。
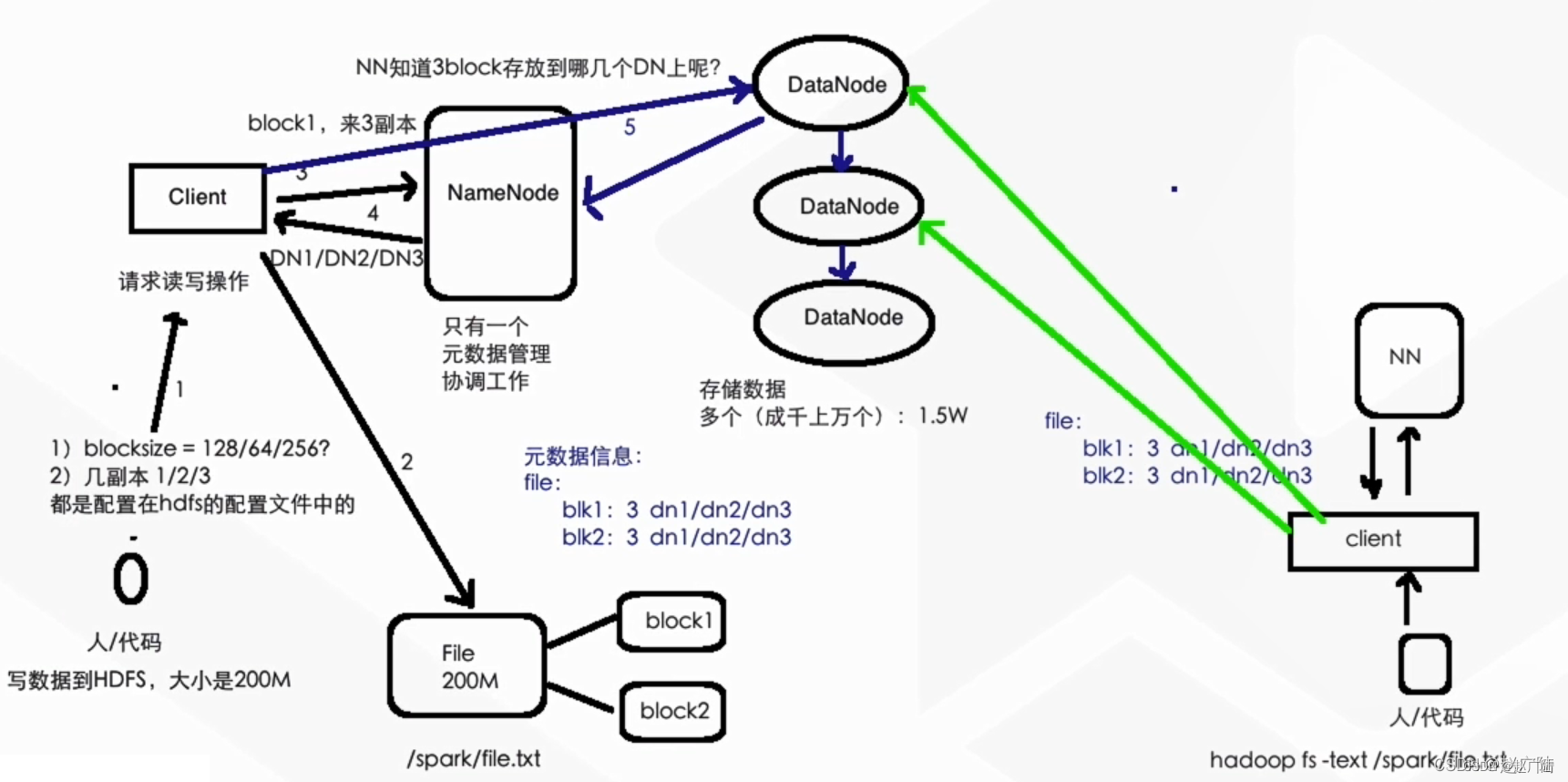
那在hdfs当中,整个的一个文件会被切成block,也就是快结构一个文件可能会属于一个block,也可能会被切成多个block。
切成多个block好处就在于我们的client在读取文件的时候,假设一个10兆的文件被切分成了四个2.5兆的这样的文件。 分别位于不同的四个data node当中,那我们的cat就可以发起并行的read操作,将这四个block一起读取出来,然后在内存当中做组装,返回给外部。 那当我们这个client清楚地知道说我到哪个data node去读取属于这个文件的那个block之后,我们就可以向不同的data node去发起readf的请求,然后将整个的文件给它读取到client当中,返回我们的对应的客户端。那这种样子的一个方式,我们把它理解为block的一个并行度。那因此整个的一个hdfs的一个读性呢是非常非常的高效的。
接下来我们来看一下写操作。
我们的client要发起我们对应的一个对hdfs的文件某一个路径上的一个写操作,无论这个文件是否存在,我们对应的client都仍然到name node当中去发起这个写请求,并且告诉我们的name node,我要操作的这个文件的路径。
我们的这个name node会去判断。由于name node内部有完整的meta data的视图,我们name node会去判断当前这个文件是否存在,以及它对应的路径到底在哪儿。如果说不存在的话,就走负载均衡的一个分配方式,分配到负载比较轻的data node节点上,然后会将写数据的meta data返回给我们的client。然后我们的client会进行分block的一个区域写那写操作。
由于涉及到replication的机制,比如说当我的client往name node发起写请求的时候,会告诉我的name node,当前我对应的这个data需要三份replication,那我的client在向其中的一个data node发起写操作的时候,这个data node会开启向两个data node的一个replication,保证三份数据同时写成功之后,整个的再能返回我们的client,整个写操作成功。
那有的同学可能会问,如果说我对应的data node在做数据同步的时候产生了一些问题,这个时候我们的这个client到底算不算这个副本写成功了呢?
那其实这个本质上来看,是也是要看我们当前的这个写请求,除了对meta data当中的replications要求之外,还有一个mini replication,也就是最少要求的副本数是多少。
如果说最少要求的副本数是和副本数一样的,那在data node内部会产生对应的一个重试机制,保证三份副本都写成功。来返回我们的client就要写成功,否则的话我们就会有对应的一个失败写的产生。那如果说mini replication数量少,那我们的data node会返回client说主对应的主在data note当中,一个副文写成功,另外两个副文写失败,一样会把原始的信息告诉我们看,并且同时会在name node当中去维护这些meta data的一个信息。

3 hive原理
自从有了大数据的mapreduce之后,我们编写mapreduce程序成为了一种时尚的潮流。但是毕竟对一个初学者来说,mapreduce的一个应用的实现成本以及对应的一个语法术本质上来说是比较复杂的。
针对大数据处理以及相关的一些bi,以及对应的ba相关的一些人员,本质上来说还是习惯于使用类似于mysql这样的一个sql语句去操作整个的一个数据库。实际的应用和落地场景来说,对应的一个sql语法语句也已经成为了对应行业内操作数据的一个标准,那因此hive就产生了。
那hi本质上来说它是可以用写sql语句的一个操作方式去操作一个map reduce的应用,而且它优雅地实现了join的操作。
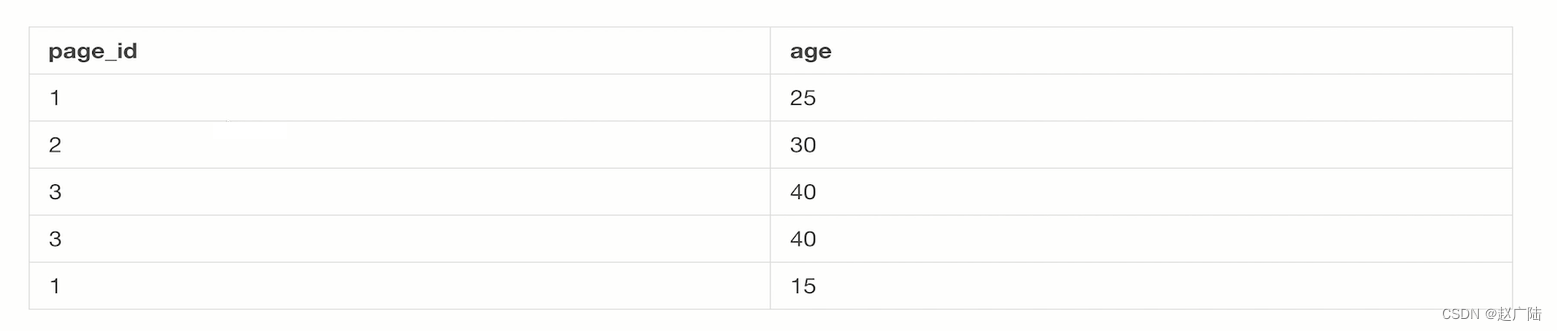
假设我们对应的一个hdfs上有一个数据文件,内部的数据文件的一个meta data的组织形式,可以将其文件内容组织成数据库的一张表。
这样的一个情况我们假设有一个页面和访问的一个用户年龄表代表了每一个page_id它对应的一个age是什么样的。
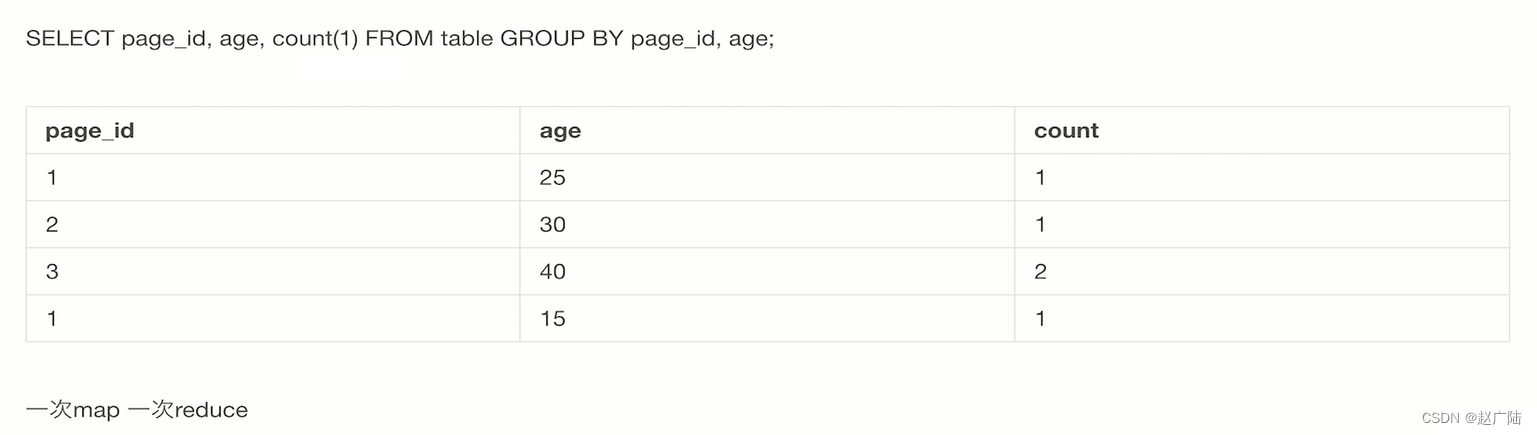
那这个时候我们对应的一个hive的console控制台上,用户就可以输入简单的一个GROUP BY,统计对应的每一个page_id和对应的age当中,GROUP BY起来它的一个counter数是多少。
那hive非常优雅地将植入的这条sql去转化成mapreduce应用,并且结合对应的hdfs上对应文件的meta data,去完整地解析出来了对应的这条sql语句,并且做了对应的mapreduce应用的转化和实现,最终将一个统计数据的结果。展示在了hive的console上。
那我们其实可以看到,有了hive这样的一个大数据的sql语句处理分析引擎,我们无需去编写整个的一个hdfs的mapreduce应用,而仅仅只需要使用最最基本的sql语句操作hdfs上带有表结构的meta data定义的文件即可。
那整个的一个数据流我们来看一下,针对这样的一条sql语句,本质上来说它会翻译为一次map操作和一次redis操作。
所谓的map操作本质上来说就是这边的一个对应的GROUP BY对应的这样条语句。
GROUP BY语句是一个聚合类的操作,将相同的page_id和age这样的信息当作map的key,将其聚合在一起,然后做了一次对应的count操作,其实就是将相同的page_id和age对应的一个key的信息数据内容,给他做了一次reduce的sam,也就是这边的一个加操作。
因此原本3这条记录对应40这样的一个age,它会产生两条对应的count,其余的都是仅仅只产生一条。
那其实我们可以看到,针对一个sql语句来说,所谓的group by或者对应的一个带了where语句,它本质上来说是一次map操作,而一个reduce操作是针对类似于count(1) 这种样子的一些聚合计算类的操作,对应的是reduce。

那我们来看一下下一条sql语句,这条sql语句非常的简单,没有带GROUP BY,他只不过是带了一个where的一个filter,age=30。
那它本质上来说是经历了一次map,但是这次map是带了一个filter条件的,只map出对应的age=30,这样的一个记录并没有产生一个reduce。
我们其实可以看到,如果说我们要应对一些很复杂的一个sql语句,本质上来说在hive内部的存储引擎翻译mapreduce的过程,仅仅只不过将不同的map方法、不同的reduce方法做了一些串联,完成了对应的一个hive数据库的一个存储。
好,那接下来我们来看一下join操作,join操作是怎么样去实现的?
往往会被一些大数据的一个面试官做对应的一个询问。
你作为java研发的程序员来说,如果说不太了解对应的一个join操作的一个hive表的实现也没有太大的关系,因为毕竟是应用层的。
但是如果说你可以深入的理解清楚,并且跟面试官阐述清楚你对join操作的一个理解,以及它内部实现的原理,那无疑对你来说是一个大大的加分。
那我们来看一下一个join操作的一个实现。
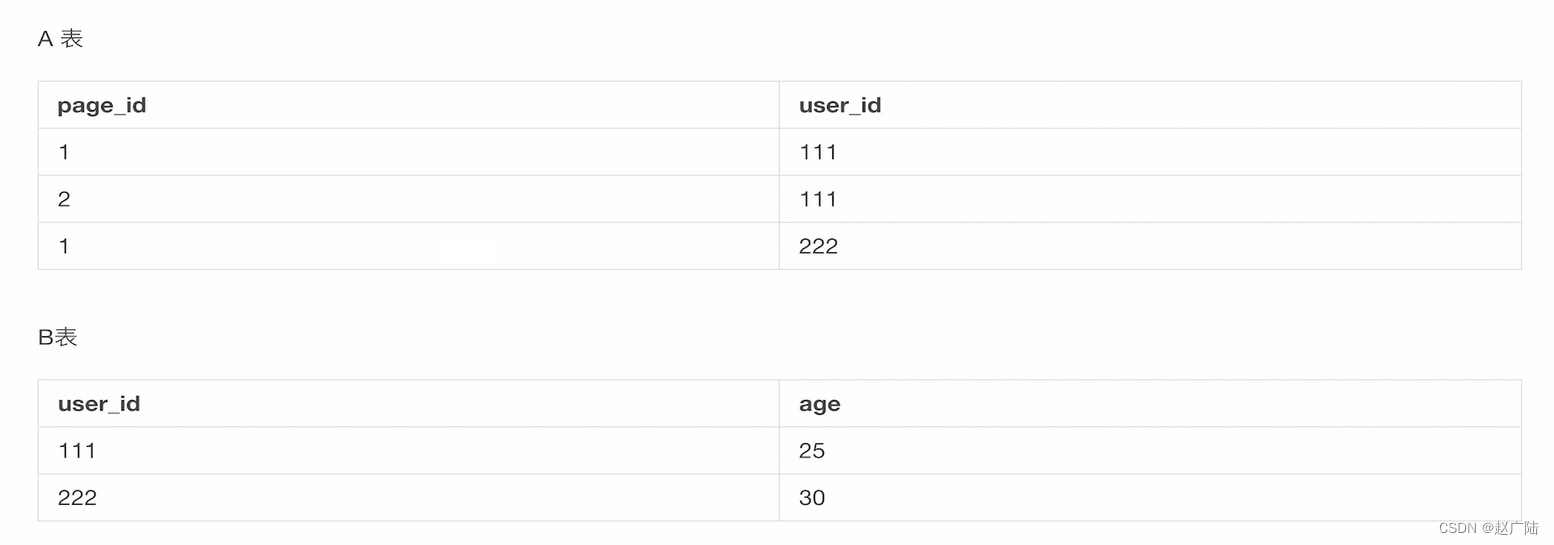
假设我们有两张表,a表和b表,那a表存储的是某一个page_id,被用户id的一个uv(访问)的一个记录。然后b表的话对应的是这个user_id它的一个年龄。
那我们要做的这条sql语句是

那本身来说就是将这两个user_id通过内连接的方式连接在一起,去查询出来不同的id,它对应age信息是怎么样的。那由于是对应的一个inner方式,那我们其实可以看到在这边有对应的一个user_id,是相同的,两条记录它对应。你的page_id在这边,那就会做一个笛卡尔集,这边会出现两个age=25这样的记录。
那针对mapreduce,还有下面的mapreduce内部的任务,这个join操作是怎么实现的呢?
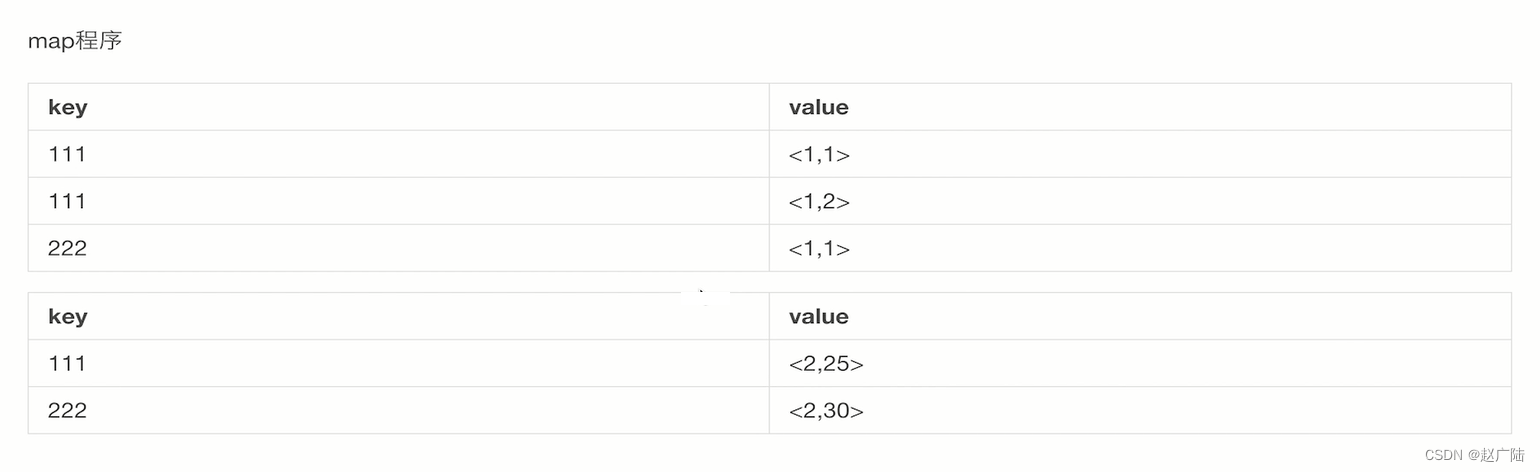
key是没个user_id,值对应的一个<1表的然后对应的id>,<2b表对应的age>
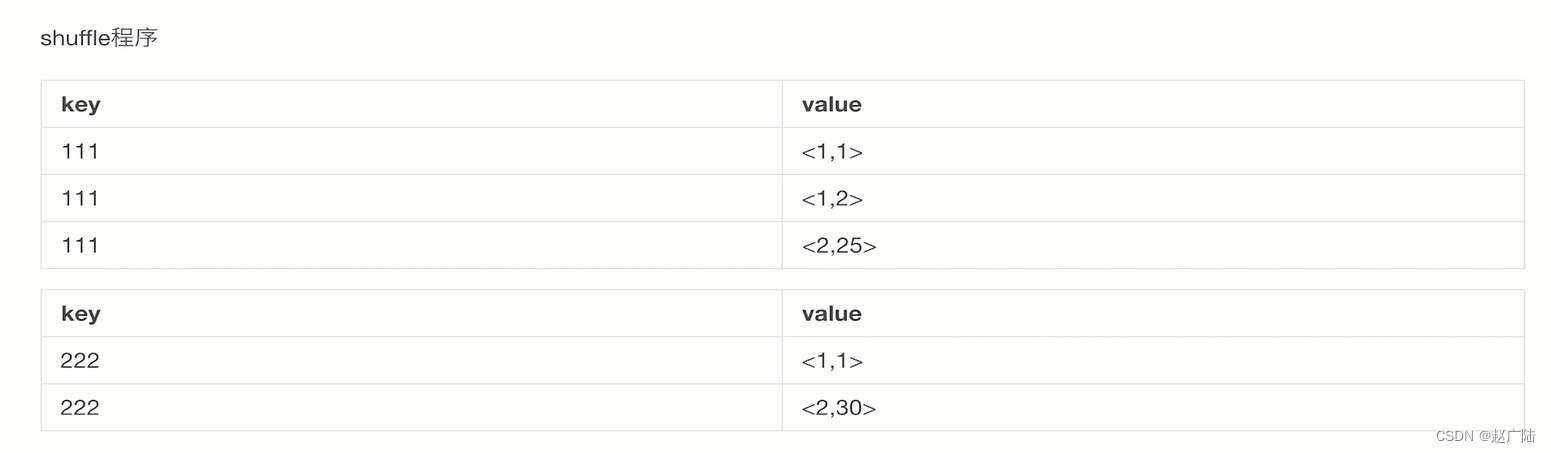
期间呢会有一个shuffle操作,将相同的key放在一起
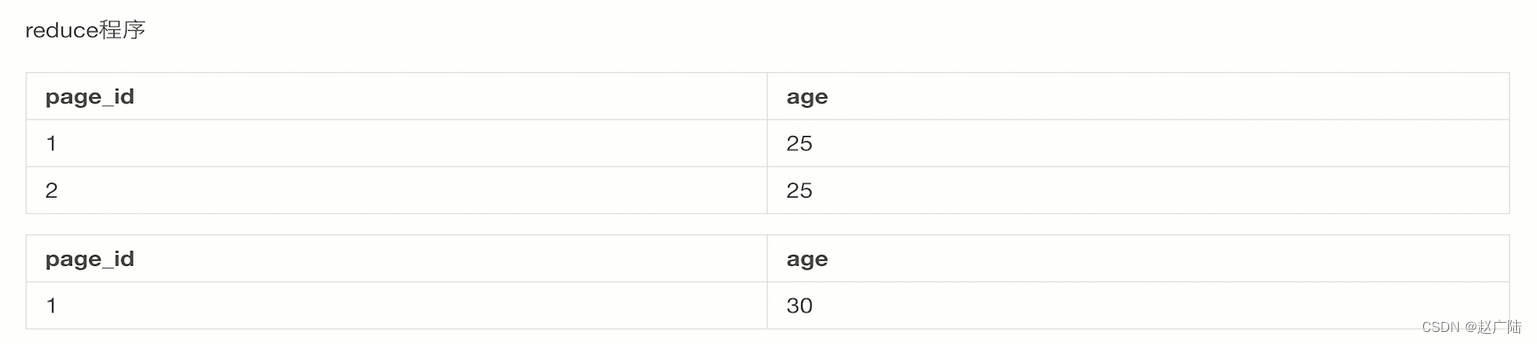
最后reduce,将key忽略,将第一张表和第二张表做一个笛卡尔积,也就是1对应25,2对应25两条记录
那我们其实可以总结一下,整个一个hive的一个sql语句的解析过程,本质上来说是在将其翻译成mapreduce的一个任务。
那针对join来说,使用对应的一个key,对应的一个表的一个index(索引就是第几张表)作为对应的value当中的一个key,然后对所有的value做一个笛卡尔积。
那细想一下,整个sql语句内部的一个实现,本质上来说也是这样的原理,仅仅只不过是hive使用大数据的一个处理方式,将其转化为了一个mapreduce的任务。
4 spark家族

接下来我们来看一下spark。那在对应的一个spark 出现之前,我们整个的一个mapreduce 任务也好,hive 也好,底层本质上来说都是基于mapreduce 加hdfs 的一个文件传输去做运行的。因此整个mapreduce 和hive对应它的mapreduce 运行速度都是非常的慢的。我甚至于执行一个非常简单的一个组件查询的sql 语句。由于它内部并不是sql的innodb 这样的一个索引机制,而是使用mapreduce 任务去做文件级别的扫描。因此它的一个数据的一个存储效率以及读取效率都是异常的慢。我们做一个非常简单的sql语句也需要上秒级别的一个访问的时间。
之后我们出现了一个spark 生态体系,spark 对应的生态体系相比于mapreduce 来说会有一些质的改进,主要体现在运行效率上面。我们对应的spark 的运行效率是非常非常高的,往往会比传统的hadoop mapreduce 高上一个数量级。

为什么spark 会比mapreduce 更快呢?本质上来说,首先是因为reduce 和map 任务的一个接洽机制。我们试想一下,一般来说我们要做map,reduce 的任务都需要将map 结果输出出去,然后输入到某一个对应的h dfs 文件上,然后做对应的reduce 任务的一个读取。那针对spark 来说,它可以优化整个map,reduce 的一个执行效率图,将我们的一个reduce 任务直接接洽到下一个map 任务上。这样的话就可以做到说我原本做一次map reduce,要做下一个任务,要将之前的reduce 的一个输出结果读取出来,变成下一个map的一个输入。而针对spark 来说,它将不同的一个reduce 任务的一个闭环给它连接起来,直接将reduce 的一个输出打到下一个任务的一个map 输入上。
因此它中间的接洽的速度是非常快,而无需使用hdfs 做一个中间层的一个转储。
第二个传统的mapreduce 的一个任务,无论做map 还是reduce 还是shuffle,中间都是需要依靠hdfs 做数据的转存。也就是我的一个map 的输出必须得先存到hdfs 上,再由下一个reduce 任务的一个输入,从h dfs 上将对应的文件读取出来。但是其实往往许多时候完全没有必要。我们可以通过网络的一个传输机制,在内存级别就将map 或者reduce 的一个输出直接下发到下一个对应的map 或者reduce 的一个输入上。因此整个的一个数据依赖是内存优先的,而并非是hdfs。
那这也是spark 比mapreduce 快许多的一个原因。
那spark 发展至今会有spark 家族诞生,主要分为第一个用的比较多的spark sql 主要是通过sql语句去操作spark 类似于dataframe 或者dataset 这样的一个结构。那这样的一个结构的操作有点类似于我们将一个数据库的一个表结构下发到内存当中,直接写sql语句操作内存。那我们的一些spark 这样的一个操作,本质上来说也是采用这样的原理,使得用户仍然可以使用sql 语句下发到的一个hive的counsel上。但是它内部的一个存储引擎以及执行引擎并不是mapreduce ,而是这个spark sql。
我们甚至于可以用spark sql 是类似于jdbc 连接一样去操作我们的mysql 数据库。那这些都是spark sql做sql 标准赖生存的原因。
第二个是最近也是比较火热的一个窗口式的流式处理spark streaming。那我们都知道,无论是hive还是mapreduce ,更多的是处理离线任务用的。那如果说我们要处理流式的任务怎么办呢?那流失的任务往往是以有一个准实时性。比如说我们希望用户在我们的电商页面刚刚点击完某一个商品的详情页,我们就把对应的这个埋点信息流式处理到我们的大数据引擎分析当中,为他做后续的一个推荐,打定数据基础。那这种样子的方式就是spark streaming 流式处理,做数据回流用的一个最好的一个方式。
那第三个是机器学习框架。一旦说到大数据,我们的大数据和算法就密不可分。spark machine learning lib (MLlib) 在内部给我们实现了常见的一些机器学习框架。
那我们可以直接使用spark MLlib去操作。我在hdfs 上为我们准备了一个训练数据,训练出一个模型,并且可以封装一些常用的模型测试方法。比如说测试它的一个准确率,召回率等等。
那面试官经常会考的一道题目是说你了不了解spark streaming 和flink 的区别。
flink 也和spark streaming 一样,是一个流式处理框架。
spark streaming 和flink 有一些什么样的区别呢?
好,我们来看一下。
spark 和flink 区别。
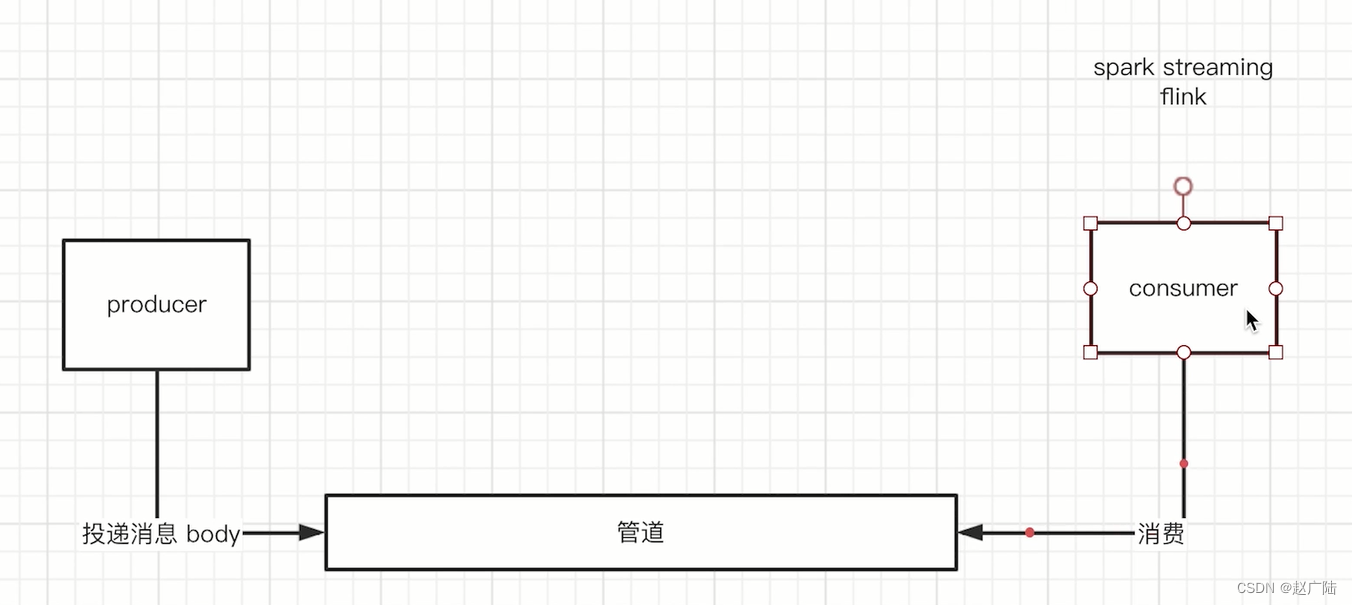
那我们都知道所谓的流式处理框架代表的是说我有一个流式处理的producer,也就是内容生产者还需要有一个流失处理的管道。然后再加一个流失处理的一个消费者。看清了。
好,那接下来我们来看一下。
我们讲解对应的流失处理的一个根本是在于consumer 上。比如说我们可以用spark streaming 以及flink 去做对应的处理。那两者处理的区别是什么?我们假设这根管道,我们一般比如说用kafka,然后我们的producer 向我们对应的管道内部去投递消息。
我们假设这个消息是一个对应的body 结构。好,这个body 里面比如说有消息id 消息对应的字段以及或者其他的一些角色数据。然后我们的consumer 去向管道当中去消费对应的一个消息。好,那两者的区别到底是什么?
大家往往都说从flink 推出之后,spark streaming 用武之地就少了很多。spark streaming 本质上来说并不一定是流式处理,而flink 才是真正意义上的流式处理。那什么意思呢?spark streaming 在设置对应的一个消费的时候,往往会设置一个window size,也就是窗口大小。这个窗口大小是可以时间戳为维度去做。比如说一秒钟,那因此它是一个伪流式处理,什么意思呢?试想一下,我们对应的spark streaming 设置了一秒钟的窗口函数,代表了我们的consumer 每隔一秒钟会从管道内部去拉取一个数据。然后假设这一秒钟里边这个管道内投递进来了两个半这样的一个保底的消息。那这个时候我们对应的spark streaming 就会将另外半条消息hold 住,也就是那个半条消息,它不会从管道里边摘出来,而是仅仅只不过是回调出来两条消息而已。
这个时候我们就可以看到我们对应的spark streaming 本质上来说是一个间歇性的一个拉取的一个策略。每隔固定的周期去拉取消息。当然拉取过来有可能是一条有可能是两条,也有可能没有,或者是半条。那等于是没有,因为被hold 在内存里。
而flink 不一样,flink 是真正意义上的流失处理,它没有窗口函数这样的一个概念。也就是说只要有一条完整的消息投递进了管道,通过网络传输,我们的flink 在consumer 端就可以完整的收到。那试想一下,这样的话才是真正意义上的一个准事实,而不像spark streaming 一样,必须得以最最小力度的一个时间窗口,为单位去做对应的一个内容的拉取。
好,那这个就是我们面试官经常会考的spark streaming 和flink 的区别。它本质上来说是一个窗口拉取和真正意义上的流失处理的区别。
5 hbase原理
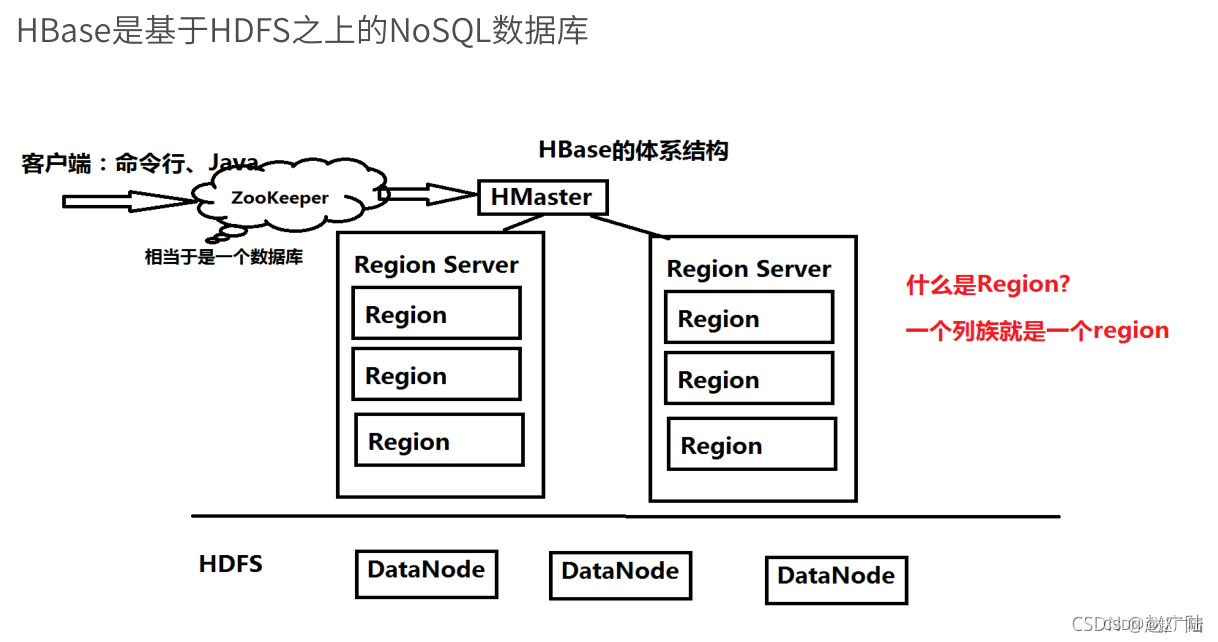
好,那最后我们来看一下hadoop 家族的大数据家族的最后一个应用hbase。那hbase 非常流行的一个原因就是因为虽然说它本质上来说是一个大数据相关的一款产品,但是它提供了非常优秀的一个实时数据处理的一个key value对nosql 数据库。那经常我们会把hbase 和mongodb 以及对应的类似于nosql 数据库这些对应的redis,对应的一些nosql 数据库这样的一个产品去做性能的一些对比。那毫无疑问,hbase 针对大规模的一个数据集以及对应的一个组件分片均匀的这样访问的一个数据能力,本质上来说是可以表现出较为优异的一个性能。那我们首先来看一下hbase 对应的这样的一个架构是一个什么样的。首先hbase 是非常也是非常传统的master worker 这样的一个对应的一个架构。
master 主机主要用来存放对应的一些meta data 数据,包含了我们对应的一些容器,也就是组件对应的一个数据的一个结构以及数据的地址范围等等。
然后我们对应的master 会将对应自身的一个信息注册到zookeeper 上。并且master 为了保证高可用,实际也是多台在使用zookeeper 的一个竞选机制去完成对应的一个主从复制的一个主从备份的一个选举。然后我们来看一下我们对应的一个client。如果说要向hbase 发起查询,首先要从zookeeper 当中拔取到master 节点的一些对应的一个信息地址。那这个时候我们的client 就会向我们的master 去发起对应的一个表操作的一个请求。比如说创建数据表以及对应的一个删除数据表,也就是所有的ddl 语句。本质上来说client 是要向master 发起的。然后我们再来看一下,如果是dml语句的数据操作会怎么样呢?由于我们的master 管理了所有对应下面的它的一个叫regionserver
也就是我们类似于hdfs 的data node,也就是所有的数据都是存储在region server 当中。并且我们的master 有所有数据分布的一些结构的信息。那因此如果说我们对应的一个client 想要获取对应的一个数据的时候,也可以先通过zookeeper 当中去获取对应的一个数据的地址。因为我们的master 会将region server 所有管理的一个数据的地址和范围存储在zookeeper 上。那我们的client 会去查询我们对应的一个zookeeper 上面去查询我们对应的一个想要查询的组件,也就是rowkey的一个地址。然后一旦查询获得之后,就会向对应的一个region server 去发起对应的一个查询或者对应的insert update 这样的一个修改或者插入的一个请求。而真正的一个region server 本质上来说也是通过hdfs去存储对应的一个数据。
6 如何应用大数据技术?
接下来我们来看一下大数据的应用。
提到大数据的应用场景,其实我们有很多很多,小到最基本的一些di的一个数据分析,大到我们系统的一个决策系统,帮助领导层通过大数据挖掘下钻、上行等等这样的一系列操作,发现我们数据当中一些潜在的价值。
对于我们的业务工程研发来说,大数据相关的应用往往会走得比较远,因为刚才所说的一些数据分析相关的都会有大数据团队去使用。
我们作为一个业务工程的研发团队以及研发人员来说,怎么体现自己在大数据方面的一些应用造诣呢?
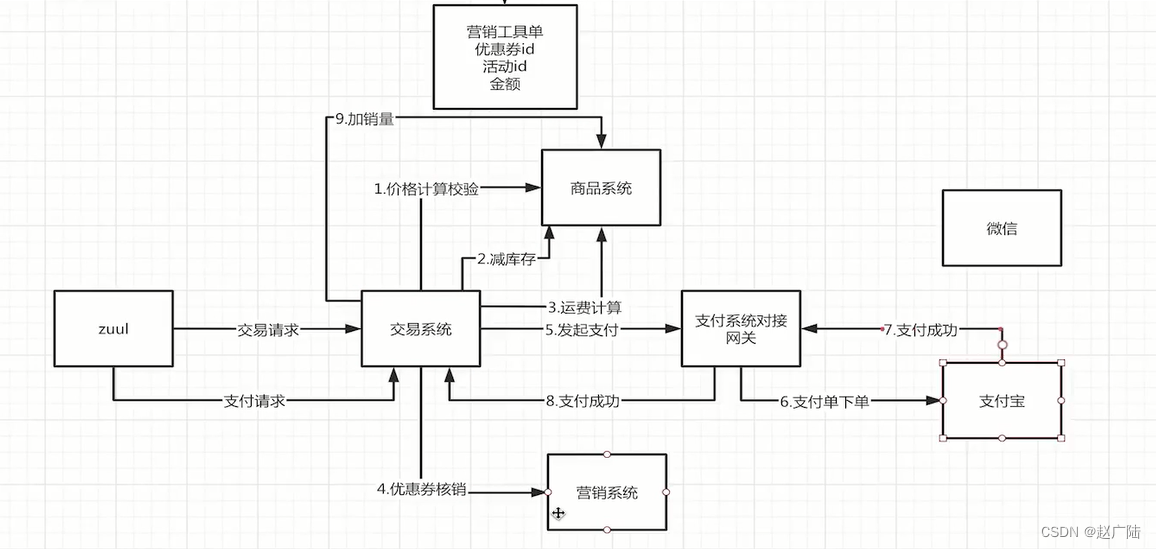
我们来回忆一下我们交易模型的交易系统,那我们来看一下,我们在整个一个商品交易的过程当中,会从交易系统发起订单的一个操作,并且到商品系统内。进行价格计算、校验以及减库存,到营销系统内做优惠券的核销,到最后的一个支付网关系统的对接。
那这样的一些分布式的应用过程当中,如果说我们的系统是稳定的,硬件也不会有任何的故障,网络延迟都是在比较低的一个情况。自然这些系统的设计以及对应的流程都是会正确无误地跑过。但是如果说我们的系统的运行状态或者软件的一个代码设计上有一些缺陷,整个的系统就会发生严重的问题。
举个例子,我们交易系统,用户成功交易并且下单支付,完了并且通过支付宝扣款,但是我们的营销系统内的一个优惠券并没有帮助用户去做核销。
那就相当于说用户明明在界面上面使用了他的优惠券,但是还是付了优惠券以外,对应的所有的钱,并没有将优惠券的一个。金额计算,给他算到对应的交易系统内。这个时候我们整个的系统就会出现一些问题,用户也会发生一些投诉。
第二种情况是说,当我们交易系统没有成功地做下单交易,然后但是营销系统却将优惠券核销掉了,这个时候我们也会发生客诉。那这两些客诉相对来说还好一些,因为是用户吃亏,平台并没有发生一些资金的一个损害。
但是试想一下,如果说我们对一个实际的一个用户操作当中,我们的交易系统将营销系统的优惠券的钱扣减掉了,并且只通过支付宝扣款收了用户营销系统优惠券以外的一个金额的钱,但是并没有将营销系统的优惠券核销掉。
那这个时候等于是用户的优惠也没有被核销,他还能继续享用优惠,而我们平台也没有收到对应。相应价值的一个金钱。
这个时候整个的一个对应的系统就会发生一些资损的一个问题。
作为我们做大数据应用相关的,如何结合我们大数据应用,去给我们交易系统和我们的营销系统发现这样的一些资损问题呢?这个就是我们常见的一个在交易系统内的一个大数据应用,也就是使用hard解决资损核对的问题。
那无论是刚才的哪一种情况,本质上来说都是我们在处理交易系统和营销系统的分布式事务之间没有做到最终的一致性。
也就是说无论是交易系统还有营销系统哪一块出现了问题,我们做系统核对的时候都应该能够及时的发现这样一个异常,以使得系统可以做及时的一个修复,或者至少可以通知我们的开发人员说你的系统可能存在隐患,我们需要。停止系统的能力,做线上的hot fix修复。
那我们来看一下我们如何使用hive解决止损的一个核对问题。
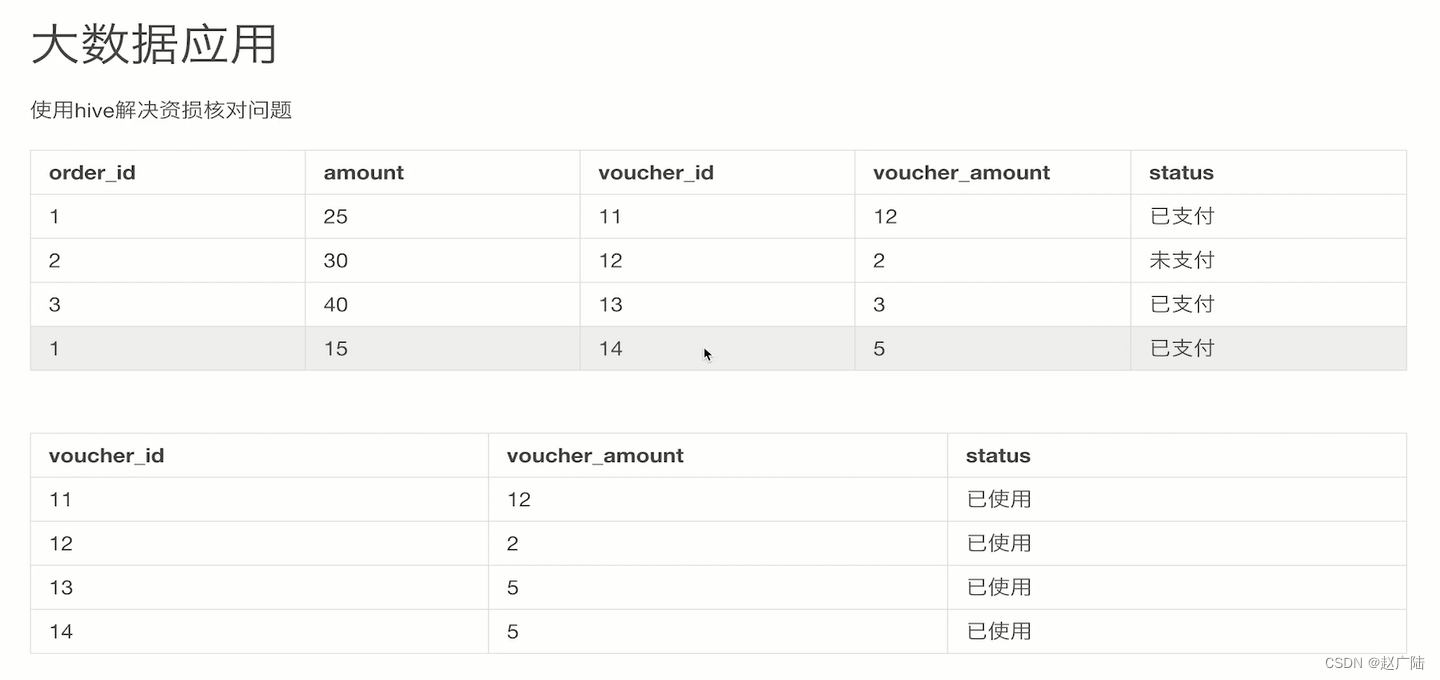
不论是实时分析还是离线分析,就是分析出mysql的错误数据并且进行反馈,比如3这个订单明显就是进行多扣费,这时运营人员再去查询时就可以进行一个反馈,这单有问题需要进行一个退费。
7 对开发来说算法意味着什么?推荐系统算法
基于用户基于物品采用欧几里德距离算法或者基于夹角余弦相似度算法,如果是稀疏矩阵建议ALS的最小二乘法进行计算评分矩阵模型。


