
- 1springboot web创建失败,解决Could not find artifact org.springframework.boot:spring-boot-starter-parent:pom
- 2从IT主管到CIO成长之路(2万字)
- 3JSON parse error: Cannot deserialize instance of `java.util.ArrayList` out of START_OBJECT token; ne
- 4ChatGPT使用案例之自然语言处理_chatgpt在自然语言处理中的应用
- 5[附源码]JAVA毕业设计高校校园社交网络(系统+LW)_javaweb校园社交系统
- 6SAP MB52改为ALV显示格式_sap mb52 alv
- 7Android 创建桌面组件Widget——构建应用微件(二)_android 10 自定义widget
- 8零基础学FPGA(六):FPGA时钟架构(Xilinx为例,完整解读)_fpga中的全局时钟
- 9hadoop启动缺少NameNode, 缺少ResourceManager, 缺少NodeManager_hadoop没有namenode
- 10Flutter运行MacOs网络请求报错Unhandled Exception: DioException [connection error]:...
使用深度学习进行图像去噪_图像去噪,特征融合,神经网络,下采样
赞
踩
图像去噪是研究人员几十年来试图解决的一个经典问题。在早期,研究人员使用滤波器器来减少图像中的噪声。它们曾经在噪音水平合理的图像中工作得相当好。然而,应用这些滤镜会使图像模糊。如果图像太过嘈杂,那么合成的图像会非常模糊,图像中的大部分关键细节都会丢失。
使用深度学习架构会更好的解决这个问题。目前看深度学习远远超过了传统的去噪滤波器。在这篇文章中,我将使用一个案例来逐步解释几种方法,从问题的形成到实现最先进的深度学习模型,然后最终看到结果。
内容摘要
-
图像中的噪声是什么?
-
问题表述
-
机器学习问题提法
-
数据来源
-
探索性数据分析
-
图像去噪的传统滤波器概述
-
用于图像去噪的深度学习模型
-
结果比较
-
未来的工作和改进的范围
-
参考文献
图像中的噪点是什么?
图像噪声是所捕获图像中亮度或颜色信息的随机变化。 这是由外部源引起的图像信号劣化。 从数学上讲,图像中的噪点可以表示为
A(x,y)= B(x,y)+ H(x,y)
- 1
其中
A(x,y)=噪声图像的函数;
B(x,y)=原始图像的函数;
H(x,y)=噪声的函数;
问题表述
传统的图像降噪算法始终假定噪声是均匀的高斯分布。但是,实际上,真实图像上的噪点可能要复杂得多。真实图像上的这种噪声称为真实噪声或盲噪声。传统的滤波器无法在具有此类噪点的图像上表现良好。
所以问题的表述变成了:我们如何去噪包含盲噪声的图像?
我们的目的是用盲噪声对彩色图像进行去噪,没有延迟的限制,因为我想对图像进行降噪处理,使其尽可能接近真实值实况,即使它花费了合理的时间
盲去噪是指在去噪过程中,用于去噪的基础是从有噪声的样本本身学习来的。换句话说,无论我们构建什么样的深度学习体系结构,都应该学习图像中的噪声分布并去噪。所以和往常一样,这都取决于我们提供给深度学习模型的数据类型。
机器学习问题提法
首先,让我们考虑一下RGB图像的格式。

一个图像的3个颜色通道
任何RGB图像对于每个像素都有三个颜色通道——红、绿、蓝。
现在,每种颜色都由一个范围为0-255的8位数字表示。任何图像都可以用一个三维矩阵来表示。

对于一个有噪声的图像。

我们在前面的章节中看到,噪声是像素的随机变化。换句话说,图像中3个通道的一些像素数值被破坏了。为了恢复图像的原始形式,我们需要纠正那些损坏的像素值。
我们可以把这看作是一个监督学习回归问题,在这个问题中我们预测被损坏像素的真实值[0-255范围内的数字]。
我将使用的损失是MSE(均方误差)。分数越低越好。
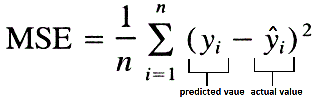
对于绩效评估,我会使用两个指标,分数越高越好
- PSNR (Peak Signal to Noise Ratio) 峰值信噪比
- SSIM (Structural Similarity Index Measure) 结构相似性
数据来源
由于这是一个监督学习问题,我们需要一对有噪声的图像(x)和ground truth图像(y)。
我从三个方面收集了这些数据。
SIDD -包含160对来[噪声-真值]图像
RENOIR -包含80对[嘈杂的-真值]图像
NIND -包含62对[噪声-真值]图像
探索性数据分析
元数据分析

我们可以看到,大部分照片是在iPhone 7上被拍摄的,其次是三星S6和谷歌Pixel。LG G4的照片数量最少。

数据集中总共使用了14个唯一的ISO级别设置。大多数照片都是在低ISO设置下点击的。最常用的ISO设置是100和800,然后是1600,400和3200。曝光越高,图像就越亮,反之亦然。

大多数照片是在100快门速度下拍摄的,其次是400和800快门。快门速度越快,图像就越暗,反之亦然。

大多数照片是在普通亮度模式下点击的,其次是低亮度模式。三星S6在高亮度下只点击了2张照片。
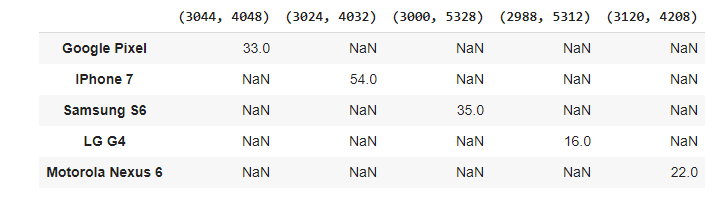
我们可以看到每一部手机都有自己的图像分辨率。每一部手机都以相同的分辨率拍摄照片。

可以看出,大部分的平均像素值处于较低到中值(较暗到中亮度的图像)。只有少数是非常高的价值(明亮的图像)。你也可以看到在噪声图像中的一些平均值与真实图像有差异。这种差异在较高像素值时更容易看到。

可以观察到,与原始图像相比,噪声图像具有像素强度的平滑分布。 产生这样的原因是,每当图像中有噪点时,相机便无法捕获这些像素的颜色信息(由于各种原因),因此,在这些像素中填充“无颜色”(大部分是 通过相机软件填充一些随机值。 由于这些随机值(噪声),像素值变得平滑了。
传统图像去噪滤波器概述
传统上,研究人员想出了滤波器器来对图像进行降噪。大多数滤波器器特定于图像所具有的噪声类型。有几种类型的噪声,例如高斯噪声,泊松噪声,斑点噪声,椒盐(脉冲)噪声等。每种类型的噪声都有特定的滤波器。因此,使用传统滤波器对图像进行降噪的第一步是识别图像中存在的噪声类型。确定后,我们可以继续应用特定的滤波器器。为了识别噪声的类型,有一些数学公式可以帮助我们猜测噪声的类型。否则,领域专家可以仅通过查看图像来决定。还有一些滤波器可以处理任何类型的噪声。
有大量的滤波器可用于对图像进行降噪。每个人都有其优点和缺点。在这里,我将讨论非局部均值(NLM)算法,该算法被认为可以很好地对图像进行去噪。
NLM的公式,
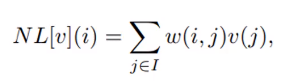
该算法将像素的估计值计算为图像中所有像素的加权平均值,但是权重族取决于像素i和j之间的相似度。 换句话说,它查看一个图像块,然后识别整个图像中的其他相似块,并对它们进行加权平均。 要了解这一点,请考虑以下图像,

相似的色块用相同颜色的方框标记。 因此,现在,它将相似补丁的像素的加权平均值作为目标像素的估计值。 该算法将色块大小和色块距离作为输入。
考虑以下使用NLM滤镜去噪的灰度图像。

您可以看到NLM在图像去噪方面做得不错。 如果仔细观察,将会发现去噪图像略有模糊。 这是由于应用于任何数据的均值将使值平滑。
但是,当噪声水平太高时,NLM无法提供良好的结果。 考虑以下图像,该图像已使用NLM滤波器进行了去噪。

可以清楚地看到,去噪后的图像太模糊了,大部分关键细节都丢失了。例如,观察蓝色卡车的橙色前灯。
用于图像去噪的深度学习模型
随着深度学习技术的出现,现在可以从图像中去除盲目的噪声,这样的结果非常接近于真实图像的细节损失最小。
已经实现了三个深度学习架构,
REDNet、MWCNN、PRIDNet
REDNet -Residual Encoder-Decoder Networks
这是一个基于CNN的跳过连接的自动编码器架构。体系结构如下:

在这里,我用了5层卷积的编码器和5层反卷积的解码器。这是一个非常简单的体系结构,我将其作为基准。
input_0 = Input(shape=(256,256,3), name="input_layer") conv_layer_1 = Conv2D(filters=256, kernel_size=2, padding='same', name="conv_1")(input_0) conv_layer_2 = Conv2D(filters=256, kernel_size=2, padding='same', name="conv_2")(conv_layer_1) conv_layer_3 = Conv2D(filters=256, kernel_size=3, padding='same', name="conv_3")(conv_layer_2) conv_layer_4 = Conv2D(filters=256, kernel_size=3, padding='same', name="conv_4")(conv_layer_3) conv_layer_5 = Conv2D(filters=128, kernel_size=3, padding='same', name="conv_5")(conv_layer_4) deconv_layer_5 = Conv2DTranspose(filters=256, kernel_size=2, padding='same', name="deconv_5")(conv_layer_5) deconv_layer_5 = Add(name="add_1")([conv_layer_4, deconv_layer_5]) deconv_layer_4 = Conv2DTranspose(filters=256, kernel_size=2, padding='same', name="deconv_4")(deconv_layer_5) deconv_layer_3 = Conv2DTranspose(filters=256, kernel_size=3, padding='same', name="deconv_3")(deconv_layer_4) deconv_layer_3 = Add(name="add_2")([conv_layer_2, deconv_layer_3]) deconv_layer_2 = Conv2DTranspose(filters=128, kernel_size=3, padding='same', name="deconv_2")(deconv_layer_3) deconv_layer_1 = Conv2DTranspose(filters=3, kernel_size=3, padding='same', name="deconv_1")(deconv_layer_2) out = Add(name="add_3")([input_0, deconv_layer_1]) model = Model(inputs=[input_0], outputs=[out])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17


如您所见,该体系结构在去噪图像方面效果很好。 您绝对可以看到噪点有所减少,并且图像正在尝试针对损坏的像素适应图像的原始颜色。该体系结构的PSNR得分为30.5713,SSIM得分为0.7932。
MWCNN — Multi-level Wavelet CNN
这是基于小波的深度学习架构。 它的架构与U-Net架构有着惊人的相似性。 MWCNN的唯一区别在于,与U-Net中的下采样和上采样不同,这里我们使用DWT(离散小波变换)和IWT(逆小波变换)。 DWT和IWT的工作方式已超出此文章的范围。 但是,我在[参考资料部分]附加了一些资源,您可以从中学习这些资源。

在这里,我已将此体系结构扩展到4个级别。 因此,我的网络深度变为32。此代码有点长,我在Keras中使用了自定义层。 您可以在Github存储库中查看有关MWCNN的完整代码。



我们可以看到,与REDNet相比,该架构的工作方式更好,图像更清晰。该体系结构的PSNR得分为32.5221,SSIM得分为0.8397。
PRIDNet — Pyramid Real Image Denoising Network
这是用于盲降噪的最先进的深度学习架构。 这种体系结构不像我们在前面的两个网络中看到的那样简单。 PRIDNet有几个模块,分为三个主要部分。

起初看起来似乎有些不知所措。 但是让我将其分解成细节,这很容易理解。
频道注意力模块

通道注意模块负责注意力机制。 这里注意力机制的实现方式是将注意力放在输入U的每个通道上。可以将这种“注意力”视为权重。 因此,每个通道将有一个权重。 注意力权重将是大小为C [通道数]的向量。 该向量将与输入U相乘。由于我们要“学习”注意力,因此我们需要该向量是可训练的。 因此PRIDNet实施的过程是,首先对输入进行全局平均池化,然后从2个全连接层传递它,其结果应该是带有通道数的向量。 这些是注意权重μ。
多尺度特征提取模块/金字塔模块

这是整个体系结构的核心。 在这里,我们将使用给定内核大小的平均池化。 这将对图像进行下采样。 然后,我们将对其应用U-Net架构。 我选择了5个级别的深层U-Net。 最后,我们将以与平均池化相同的大小进行上采样。 因此,这会将图像恢复为与输入(此模块的输入)相同的大小。
我们将使用不同的内核大小执行5次此操作,然后最后将结果连接起来。
内核选择模块

该模块的灵感来自介绍选择性内核网络的研究论文。 该研究论文很好地阐述了该网络背后的思想,如下所示:
在标准的卷积神经网络(CNN)中,每一层中的人工神经元的感受野被设计为共享相同的大小。 在神经科学界众所周知,视觉皮层神经元的感受野大小是受刺激调节的,在构建CNN时很少考虑。
设计了一个称为选择性内核(SK)单元的构建块,其中使用softmax注意融合了内核大小不同的多个分支,这些注意由这些分支中的信息指导。 对这些分支的不同关注会导致融合层中神经元有效接受场的大小不同。
此模块与“通道注意力”模块非常相似。 根据PRIDNet论文,大小为C的合成矢量α,β,γ分别表示对U’,U’和U’’的柔和注意。
整个PRIDNet架构图如下所示,

结果如下:



可以看到,与先前讨论的体系结构相比,该体系结构可提供最佳结果。 在上面的眼睛特写图像中,请注意去噪图像中眼球的细节水平!


嘈杂图像中的黑色书籍[Cropped Library books]。 它们几乎与周围的棕色家具没有区别。 一切似乎都是黑色的。 但是,我们的模型能够以至少可以区分书籍和周围家具的方式对其进行去噪。 第二张图片[裁剪的图书馆家具]也是如此。 在嘈杂的图像中,您可以看到家具非常黑,顶部似乎几乎是黑色的。 但是,我们的模型能够理解棕色并对其进行去噪。 这太神奇了!
该体系结构的PSNR得分为33.3105,SSIM得分为0.8534。
结果对比

我们可以清楚地看到PRIDNet是性能最佳的体系结构,用于消噪单个图像的时间最少。
现在,我们比较一下NLM滤波器和PRIDNet的结果。


要比较的关键领域
- 黄色卡车的车顶区域
- 橙色卡车的座位
- 蓝色卡车中的橙色大灯
- 蓝色卡车的车顶(观察阴影)
- 地板中间的两个细条纹
还有很多
未来的工作和改进范围
图像去噪是一个活跃的研究领域,并且时不时地有许多惊人的架构正在开发以对图像进行去噪。 最近,研究人员正在使用GAN来对图像进行降噪,事实证明,这种方法会产生令人惊讶的结果。 好的GAN架构肯定会进一步改善去噪效果。
引用
- https://medium.com/image-vision/noise-in-digital-image-processing-55357c9fab71 (What is noise?)
- https://www.youtube.com/watch?v=Va4Rwoy1v88&ab_channel=DigitalSreeni (Non-Local Means)
- https://www.eecs.yorku.ca/~kamel/sidd/dataset.php (SIDD dataset)
- http://adrianbarburesearch.blogspot.com/p/renoir-dataset.html (RENOIR dataset)
- https://commons.wikimedia.org/wiki/Natural_Image_Noise_Dataset#Tools (NIND dataset)
- https://arxiv.org/pdf/1606.08921.pdf (REDNet)
- https://arxiv.org/pdf/1805.07071.pdf (MWCNN)
- https://arxiv.org/pdf/1908.00273.pdf (PRIDNet)
- https://arxiv.org/pdf/1505.04597.pdf (U-Net)
- https://arxiv.org/pdf/1903.06586.pdf (Selective Kernel Networks)
- https://www.eecis.udel.edu/~amer/CISC651/IEEEwavelet.pdf (Wavelets)
- https://towardsdatascience.com/what-is-wavelet-and-how-we-use-it-for-data-science-d19427699cef (Wavelets)
- http://gwyddion.net/documentation/user-guide-en/wavelet-transform.html (Wavelet transforms)
本文代码地址:https://github.com/chintan1995/Image-Denoising-using-Deep-Learning
作者:Chintan Dave
deephub翻译组

