
- 1AI自然语言处理NLP原理与Python实战:语音识别的进阶_nlp语音识别
- 2数据处理入门:自然语言处理NLP常用文本预处理操作整理_nlp 读取文档内容 并生成目录的方法
- 3利用Fragment编写简易新闻界面,布局同时适应Android手机和平板电脑_fragment简易新闻
- 4一分钟告诉你究竟DevOps是什么鬼?_dno会是哪个dou
- 5Kaggle使用GPU之绑定手机号_kaggle怎么注册手机号
- 6Torch.nn.embedding_nn.embedding引用
- 7jwt鉴权登录实现步骤(JWT工具类+拦截器+前端配置)——前后端鉴权方案和使用_jwtsigner
- 8语义分割论文-DeepLab系列_deeplabv语义分割论文
- 9人工智能:支持向量机SVM 练习题(带解析)_对于线性可分的二分类任务样本集,将训练样本分开的超平面有很多,支持向量机试图寻
- 1004---springboot实现增删改查
Kubernetes基础(八)-工作负载_工作负载类型
赞
踩
目录
10.4 kubernetes CronJob和Linux crontab对比
1 什么是工作负载?
工作负载是在kubernetes上运行的应用程序。
2 为什么需要工作负载?
在kubernetes中,pod代表的是集群上处于运行状态的一组容器。Pod有确定的生命周期,例如,当某个pod在集群中运行时,pod运行所在的节点出现致命错误时,所有该节点上的pods都会失败。kubernetes将这类失败视为最终状态,也就是说,即使该节点后来恢复正常,也需要创建新的pod来恢复应用。
工作负载的出现,使得用户无需直接管理每个pod,而是通过负载资源来进行管理一组pods。这些资源配置控制器来确保合适类型、处于运行状态的pod个数是正确的,并与约定所指定的状态一致。
3 工作负载类型
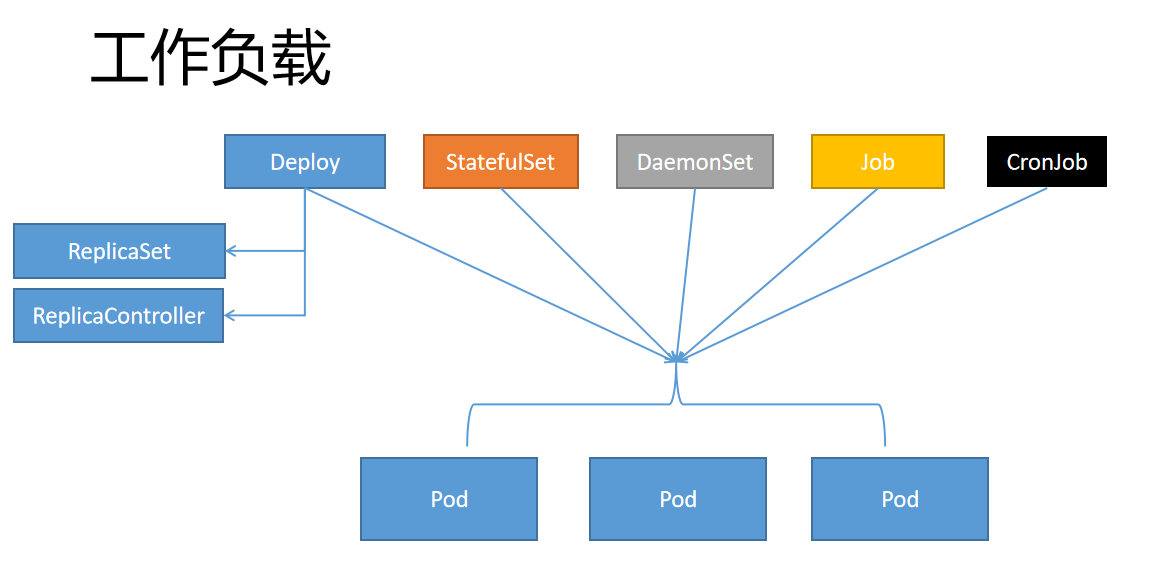 Kubernetes提供若干种内置的工作负载资源:
Kubernetes提供若干种内置的工作负载资源:
3.1 无状态工作负载
无状态工作负载管理的pod是相互等价的,需要的时候可以互相替换。主要有以下几种类型:
DeploymentReplicaSetReplicationController
3.2 有状态工作负载
有状态的工作负载为每个pod维护了一个唯一的ID,能够保证pod的顺序和唯一性,每个pod是不可替代的。有状态工作负载可跟踪Pod状态,可使用持久存储来保存服务产生的状态。主要类型有:
StatefulSet。
3.3 守护进程工作负载
守护进程工作负载主要用来管理节点上运行的守护进程。主要类型有:
DaemonSet
3.4 批处理工作负载
批处理工作负载用于处理一次性或周期性任务,定义一些一直运行到结束并停止的任务,其主要类型有:
- Job:用来表达一次性任务,
- CronJob:周期性任务。
4 Deployment
deployment适合部署无状态的应用服务,其主要用来管理pod和replicaset,但deployment并不是直接控制pod,而是通过管理replicaset来间接管理pod,即:deployment管理replicaset,replicaset管理pod。所以deployment比replicaset的功能更强大。

4.1 主要功能
- 支持replicaset的所有功能
- 支持发布的停止、继续
- 支持版本的滚动更新和版本回退
4.2 deployment的资源清单yaml文件
deployment资源文件及配置详解见:Kubernetes系列-deployment资源的yaml文件_deployment yaml文件_alden_ygq的博客-CSDN博客
deployment案例:
- # 创建名为dev的命名空间
- # 版本号
- apiVersion: v1
- # 表明创建的种类为命名空间
- kind: Namespace
- # 定义资源的元数据信息,比如资源的名称、namespace、标签等信息
- metadata:
- #定义命名空间的名称
- name: dev
-
- ---
- # 创建 service (一组pod 对外访问的包装)
- # 版本号
- apiVersion: v1
- # 表明创建资源的种类为service
- kind: Service
- metadata:
- # 定义service的名称,在同一namespace中必须是唯一的
- name: nginx-svc
- # 定义资源属于哪一个命名空间
- namespace: dev
- # 定义service所需要的参数属性
- spec:
- ports:
- # 当type=Nodeport时,指定映射到物理机的端口
- - nodePort: 32036
- # 服务本身监听的端口
- port: 80
- protocol: TCP
- # 需要转发到后端的端口,nginx默认端口为80
- targetPort: 80
- selector:
- # 如何确定需要代理哪一个服务,通过标签,设置后会自动匹配同一命名空间下标签为nignx的pod代理
- app: nginx
- # service的类型,指定service的访问方式,默认ClusterIP
- type: NodePort
- #ClusterIP:虚拟的服务ip地址,用于k8s集群内部的pod访问,在Node上kube-porxy通过设置的iptables规则进行转发
- #NodePort:使用宿主机端口,能够访问各Node的外部客户端通过Node的IP和端口就能访问服务器
- #LoadBalancer:使用外部负载均衡器完成到服务器的负载分发,
-
- ---
- # 版本号
- apiVersion: apps/v1
- # 类型
- kind: Deployment
- metadata:
- # 名字
- name: nginx
- # 属于的命名空间
- namespace: dev
- labels:
- # 给自己打个标签
- app: nginx
- spec:
- # 副本数量,为2,稍后会创建两个pod
- replicas: 2
- selector:
- matchLabels:
- # 这里设置将要匹配的标签
- app: nginx
- template:
- metadata:
- labels:
- # 设置创建pod后将要给它打上的标签
- app: nginx
- spec:
- containers:
- # 资源名,创建时会自动加后缀,防止名称重复
- - name: nginx
- # 创建资源的镜像,这里选择的是之前上传到harbor仓库的镜像
- image: harbor.k8s.info.com/yueyong/centos-nginx:1.22.0
- # 拉取策略,这里的意思是如果本地没有就从远程仓库拉取
- imagePullPolicy: IfNotPresent
- ports:
- - containerPort: 80 #容器对外开放的端口
4.3 创建deployment
deployment的创建方式有两种,分别是:
- 命令行方式
- yaml配置文件方式
一般情况下,创建deployment的同时也会创建pod
4.3.1 命令方式
1)创建deployment及pod
kubectl run nginx --image=nginx --replicas=2nginx:应用名称
- --replicas:指定应用运行的 pod 副本数
- --image:使用的镜像(默认从dockerhub拉取)
2)查看deployment
- # kubectl get deployment 或者 kubectl get deploy
- NAME READY UP-TO-DATE AVAILABLE AGE
- nginx 2/2 2 2 19m
3)查看 replicaset
- # kubectl get replicaset 或者 kubectl get rs
- NAME DESIRED CURRENT READY AGE
- nginx-5578584966 2 2 2 18m
4)查看 pod
- # kubectl get pods -o wide
- NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
- nginx-5578584966-m7fcz 1/1 Running 0 45s 10.244.2.5 node2 <none> <none>
- nginx-5578584966-nmffb 1/1 Running 0 45s 10.244.1.4 node1 <none> <none>
4.3.2 yaml配置文件方式
1) 创建配置文件
- $ vim deploy-nginx.yaml
-
- # 文件内容
- apiVersion: apps/v1
- kind: Deployment
- metadata:
- name: nginx-app
- spec:
- replicas: 2
- selector:
- matchLabels:
- app: nginx
- template:
- metadata:
- labels:
- app: nginx
- spec:
- containers:
- - name: nginx
- image: nginx
- ports:
- - containerPort: 80
2)创建deployment
kubectl apply -f deploy-nginx.yaml3)查看deployment
- # kubectl get deployment 或者 kubectl get deploy
- NAME READY UP-TO-DATE AVAILABLE AGE
- nginx 2/2 2 2 19m
4)查看 replicaset
- # kubectl get replicaset 或者 kubectl get rs
- NAME DESIRED CURRENT READY AGE
- nginx-5578584966 2 2 2 18m
5)查看 pod
- # kubectl get pods -o wide
- NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
- nginx-5578584966-m7fcz 1/1 Running 0 45s 10.244.2.5 node2 <none> <none>
- nginx-5578584966-nmffb 1/1 Running 0 45s 10.244.1.4 node1 <none> <none>
deployment、rs、pod三者形式上的区别是:rs是在deployment之后加了一段字符串,而pod是在rs之后加了一段字符串
4.4 扩缩容
deployment的扩容是指对pod进行扩缩容,常见扩缩容方式有两种:
- 命令行方式
-
deploy文件
4.4.1 命令行方式
1)语法
kubectl scale deploy deploy名称 --replicas=pod数量 -n 命名空间2)案例
- # kubectl scale deploy nginx --replicas=5 -n dev
- deployment.apps/nginx scaled
- # kubectl get pod -n dev
- NAME READY STATUS RESTARTS AGE
- nginx-5d89bdfbf9-bhcns 1/1 Running 0 83s
- nginx-5d89bdfbf9-cfls7 1/1 Running 0 83s
- nginx-5d89bdfbf9-k8j9n 1/1 Running 0 8m54s
- nginx-5d89bdfbf9-vw87k 1/1 Running 0 8m54s
- nginx-5d89bdfbf9-x7nsm 1/1 Running 0 8m54s
4.4.2 deploy文件
1)语法
kubectl edit deploy deploy名字 -n 命名空间2)案例
- # kubectl edit deploy nginx -n dev
- 找到replicas,将其数量改为3
- spec:
- progressDeadlineSeconds: 600
- replicas: 3
- # kubectl get pod -n dev
- NAME READY STATUS RESTARTS AGE
- nginx-5d89bdfbf9-k8j9n 1/1 Running 0 15m
- nginx-5d89bdfbf9-vw87k 1/1 Running 0 15m
- nginx-5d89bdfbf9-x7nsm 1/1 Running 0 15m
4.5 镜像更新
deployment的扩容是指对pod进行扩缩容,常见扩缩容方式有两种:
- 重建更新
- 滚动更新
默认滚动更新,
4.5.1 设置方式
通过strategy选项进行配置。
- strategy:指定新的pod替换旧的pod的策略,支持两个属性:
- type:指定策略类型,支持两种策略
- Recreate:在创建出新的pod之前会先杀掉所有已存在的pod
- RollingUpdate:滚动更新,就是杀死一部分,就启动一部分,在更新过程中,存在两个版本pod,支持两个属性
- maxUnavailable:用来指定在升级过程中不可用pod的最大数量,默认为25%
- maxSurge:用来指定在升级过程中可以超过期望的pod的最大数量,默认为25%
- type:指定策略类型,支持两种策略
4.5.2 重建更新
1)设置策略
编辑deploy-nginx.yaml,在spec节点下添加更新策略:
- $ vim deploy-nginx.yaml
- spec:
- strategy: #策略
- type: Recreate #重建更新策略
- $ kubectl apply -f deploy-nginx.yaml
- Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
- deployment.apps/nginx configured
2)验证策略
- # kubectl get pod -n dev
- NAME READY STATUS RESTARTS AGE
- nginx-5d89bdfbf9-bqf86 1/1 Running 0 8s
- nginx-5d89bdfbf9-kz6jt 1/1 Running 0 8s
- nginx-5d89bdfbf9-z7d9z 1/1 Running 0 8s
-
- #更改pod镜像
- $ kubectl set image deploy nginx nginx=nginx:1.17.2 -n dev
- deployment.apps/nginx image updated
-
- #再次查看pod
- $ kubectl get pod -n dev
- NAME READY STATUS RESTARTS AGE
- nginx-675d469f8b-b9rwd 1/1 Running 0 27s
- nginx-675d469f8b-kc7rr 1/1 Running 0 27s
- nginx-675d469f8b-kxgkq 1/1 Running 0 27s
- # 查看镜像
- $ kubectl describe pod nginx-675d469f8b-b9rwd | grep image
-
4.5.3 滚动更新
1)设置策略
编辑deploy-nginx.yaml,在spec节点下添加滚动更新策略(也可以把strategy去掉,因为默认滚动更新策略)。
- $ vim deploy-nginx.yaml
- strategy:
- type: RollingUpdate #滚动更新策略
- rollingUpdate:
- maxUnavailable: 25%
- maxSurge: 25%
- $ kubectl apply -f deploy-nginx.yaml
- Warning: kubectl apply should be used on resource created by either kubectl create --save-config or kubectl apply
- deployment.apps/nginx configured
2)验证策略
- $ kubectl get pod -n dev
- NAME READY STATUS RESTARTS AGE
- nginx-5d89bdfbf9-526wf 1/1 Running 0 61s
- nginx-5d89bdfbf9-b5x5v 1/1 Running 0 64s
- nginx-5d89bdfbf9-kc7hb 1/1 Running 0 59s
- #更新镜像
- $ kubectl set image deploy nginx nginx=nginx:1.17.2 -n dev
- deployment.apps/nginx image updated
- #查看pod状态
- $ kubectl get pod -n dev
- NAME READY STATUS RESTARTS AGE
- nginx-5d89bdfbf9-526wf 0/1 Terminating 0 2m2s
- nginx-5d89bdfbf9-b5x5v 1/1 Running 0 2m5s
- nginx-5d89bdfbf9-kc7hb 0/1 Terminating 0 2m
- nginx-675d469f8b-7vw6x 1/1 Running 0 3s
- nginx-675d469f8b-rzq82 0/1 ContainerCreating 0 2s
- nginx-675d469f8b-zk4fs 1/1 Running 0 5s
- $ kubectl get pod -n dev
- NAME READY STATUS RESTARTS AGE
- nginx-675d469f8b-7vw6x 1/1 Running 0 38s
- nginx-675d469f8b-rzq82 1/1 Running 0 37s
- nginx-675d469f8b-zk4fs 1/1 Running 0 40s
4.5.4 镜像更新过程rs的变化
在镜像更新过程中,rs会保留至少两个版本信息,除最新版本的rs意外,其他版本rs下pod是0,此机制的目的是快速回滚。
4.6 版本回退
deployment支持版本升级过程中的暂停,继续功能以及版本回退等诸多功能。
4.6.1 回滚策略
kubectl rollout:版本升级相关功能,支持下面的选项:
- status:显示当前升级状态
- history:显示升级历史记录
- pause:暂停版本升级过程
- resume:继续已经暂停的版本升级过程
- restart:重启版本升级过程
- undo:回滚到上一级版本(可以使用--to-revision回滚到指定版本)
4.6.2 案例
- #查看升级状态
- # kubectl rollout status deploy nginx -n dev
- deployment "nginx" successfully rolled out
-
- #查看升级历史(注意:如果只显示版本号说明一开始使用yaml创建文件的时候没有加上--record命令)
- # kubectl rollout history deploy nginx -n dev
- deployment.apps/nginx
- REVISION CHANGE-CAUSE
- 1 kubectl create --filename=deploy-nginx.yaml --record=true
- 2 kubectl create --filename=deploy-nginx.yaml --record=true
-
- #版本回滚
- #这里使用--to-revision=1回滚到1版本,如果省略这个选项,则会回退到上个版本
- # kubectl rollout undo deploy nginx --to-revision=1 -n dev
- deployment.apps/nginx rolled back
-
- #查看是否回滚成功,发现5序号开头的rs被启动了
- # kubectl get rs -n dev
- NAME DESIRED CURRENT READY AGE
- nginx-5d89bdfbf9 3 3 3 31m
- nginx-675d469f8b 0 0 0 22m
4.7 Deployment状态
Deployment的生命周期中会有许多状态,如Processing、Complete或Failed。
当deployment执行以下任务时,其状态是Processing的:
- 创建新的ReplicaSet
- 为新的ReplicaSet扩容
- 为旧的ReplicaSet缩容
- 新的pods已经就绪或者可用(持续运行minReadySeconds 时间)
.sepc.minReadySeconds表示新创建的pod被视为可用时需要持续就绪的时间,默认为0。
可以使用kubectl rollout status 监视deployment的状态。
4.7.1 Complete 状态
1)描述
如果 Deployment 符合以下条件,Kubernetes 将其状态标记为 complete:
- 该 Deployment 中的所有 Pod 副本都已经被更新到指定的最新版本。
- 该 Deployment 中的所有 Pod 副本都处于 可用(available) 状态。
- 该 Deployment 中没有旧的 ReplicaSet 正在运行。
简而言之就是更新过程已经完全成功,就会进入complete状态。
2)案例
- $ kubectl get deployment
- NAME READY UP-TO-DATE AVAILABLE AGE
- web-nginx 2/2 2 2 36m
-
-
- $ kubectl rollout status deployment.v1.apps/web-nginx
- deployment "web-nginx" successfully rolled out
4.7.2 Failed 状态
1)描述
Deployment 在更新其最新的 ReplicaSet 时,可能卡住而不能达到 complete 状态。如下原因都可能导致此现象发生:
- 集群资源不够
- 就绪检查(readiness probe)失败
- 镜像抓取失败
- 权限不够
- 资源限制
- 应用程序的配置错误导致启动失败
指定 Deployment 定义中的 .spec.progressDeadlineSeconds 字段,Deployment Controller 在等待指定的时长后,将 Deployment 的标记为处理失败。
2)案例
例如,执行命令 kubectl patch deployment.v1.apps/nginx-deployment -p ‘{“spec”:{“progressDeadlineSeconds”:600}}’ 使得 Deployment Controller 为 Deployment 的处理过程等候 15 分钟(一般使用默认的10分钟即可),输出结果如下所示:
- $ kubectl get deployment
- NAME READY UP-TO-DATE AVAILABLE AGE
- web-nginx 2/2 2 2 40m
-
-
- $ kubectl patch deployment.v1.apps/web-nginx -p '{"spec":{"progressDeadlineSeconds":900}}'
- deployment.apps/web-nginx patched
如果上面指定的900s(15分钟)到达之后,replicaset还没到达complete状态,deployment controoler将在deployment的.status.conditions 字段添加如下 deploymentCondition
- Type=Progressing
- Status=False
- Reason=ProgressDeadlineExceeded
注:
- 除了添加一个
Reason=ProgressDeadlineExceeded的DeploymentCondition到.status.conditions字段以外,Kubernetes 不会对被卡住的Deployment做任何操作。我们可以执行kubectl rollout undo命令,将Deployment回滚到上一个版本- 如果暂停了 Deployment,Kubernetes 将不会检查
.spec.progressDeadlineSeconds。
3)处于failed状态的deployment如何解决
可以针对 Failed 状态下的 Deployment 执行任何适用于 Deployment 的指令,例如:
- scale up / scale down
- 回滚到前一个版本
- 暂停(pause)Deployment,以对 Deployment 的 Pod template 执行多处更新
4.7.4 kubectl describe分析
- $ kubectl describe deployment web-nginx
- ....... # 省略部分输出
- Conditions:
- Type Status Reason
- ---- ------ ------
- Available True MinimumReplicasAvailable
- Progressing True NewReplicaSetAvailable
- Type=Available 及 Status=True 代表您的 Deployment 具备最小可用的 Pod 数(minimum availability)。Minimum availability 由 Deployment 中的 strategy 参数决定。
- Type=Progressing 及 Status=True 代表您的 Deployment 要么处于滚动更新的过程中,要么已经成功完成更新并且 Pod 数达到了最小可用的数量。
Deployment 中的 strategy 参数如下:
- strategy:
- rollingUpdate:
- maxSurge: 25% # 滚动更新过程中一次更新几个pod。
- maxUnavailable: 25% # 当pod不可用数为多少时,停止滚动更新。
5 ReplicaSet
ReplicaSet是无状态的工作负载,其目的是维护一组在任何时候都处于运行状态的pod副本的稳定集合。
5.1 yaml文件
- apiVersion: apps/v1
- kind: ReplicaSet
- metadata:
- name: frontend
- labels:
- app: guestbook
- tier: frontend
- spec:
- # 按你的实际情况修改副本数
- replicas: 3
- selector:
- matchLabels:
- tier: frontend
- template:
- metadata:
- labels:
- tier: frontend
- spec:
- containers:
- - name: php-redis
- image: gcr.io/google_samples/gb-frontend:v3
事实上,一般不会直接使用ReplicaSet,而是用Deployment。Deployment是一个更高级的概念,它管理ReplicaSet,并向pod提供声明式的更新和其他功能。
ReplicaSet通过选择符来获取pod,它所获得的pod都在其ownerReferences字段中包含了ReplicaSet信息。查看前文中通过deployment创建的pod的的YAML:
kubectl get pod/nginx-deployment-66b957f9d-nxtmb -o yaml可以看到如下信息:
- ownerReferences:
- - apiVersion: apps/v1
- blockOwnerDeletion: true
- controller: true
- kind: ReplicaSet
- name: nginx-deployment-66b957f9d
- uid: 258330af-a097-402c-9054-97c38dd1f324
- resourceVersion: "312558"
- uid: 1744870f-4b9f-451d-bbf6-1d9becbc610e
这里的属主ReplicaSet正是deployment管理的ReplicaSet,通过kubectl get rs可以看到。
5.2 创建rs
kubectl apply -f rs.yaml - # kubectl get rs
- NAME DESIRED CURRENT READY AGE
- myapp 2 2 2 2m36s
- # kubectl get pods
- NAME READY STATUS RESTARTS AGE
- liveness-httpget 1/1 Running 1 2d1h
- myapp-84lr8 1/1 Running 0 3m7s
- myapp-tpthp 1/1 Running 0 3m7s
- poststart-pod 1/1 Running 1 100m
- readiness-httpget-pods 1/1 Running 0 2d
5.3 ReplicatSet的三个属性
ReplicaSet 是通过一组字段来定义的,包括三个属性:
- 一个用来识别可获得的 Pod 的集合的选择算符;
- 一个用来标明应该维护的副本个数的数值
- 一个用来指定应该创建新 Pod 以满足副本个数条件时要使用的 Pod 模板。
5.4 ReplicaSet属性分析
ReplicaSet 需要 apiVersion、kind 和 metadata 字段。 对于 ReplicaSet 而言,其 kind 始终是 ReplicaSet。然后,ReplicaSet 也需要 .spec 部分。.spec 部分分为 副本数、选择器(选择算符)、Pod模板三个部分。
5.4.1 Replicas
可以通过设置 .spec.replicas 来指定要同时运行的 Pod 个数。 ReplicaSet 创建、删除 Pod 以与此值匹配。如果没有指定 .spec.replicas,那么默认值为 1。
5.4.2 Pod 选择算符
.spec.selector 字段是一个标签选择算符,这些是用来标识要被获取的 Pod 的标签。在签名的 frontend.yaml 示例中,选择算符为:
- matchLabels:
- tier: frontend
在 ReplicaSet 中,.spec.template.metadata.labels 的值必须与 spec.selector 值相匹配,否则该配置会被 API 拒绝。
说明:对于设置了相同的 .spec.selector,但 .spec.template.metadata.labels 和 .spec.template.spec 字段不同的两个 ReplicaSet 而言,每个 ReplicaSet 都会忽略被另一个 ReplicaSet 所创建的 Pod。
5.4.3 Pod 模板
.spec.template 是一个 Pod 模板, 要求设置标签。在 frontend.yaml 示例中,我们指定了标签 tier: frontend。
对于模板的重启策略 字段,.spec.template.spec.restartPolicy,唯一允许的取值是 Always,这也是默认值。
5.5 使用ReplicaSet
5.5.1 删除 ReplicaSet操作
kubectl 命令支持级联删除。
- 当设置 --cascade=foreground,可以使用 kubectl 在前台删除附属对象。
- 当设置 --cascade=orphan,会使附属对象成为孤立附属对象。
- 当不指定 --cascade 或者明确地指定它的值为 background 的时候, 默认的行为是在后台删除附属对象。
1)删除 ReplicaSet 和 Pod
使用 kubectl apply -f replicaset.yaml 创建了 replicaset 和 pod,如果现在要删除 ReplicaSet 和它的所有 Pod,使用 kubectl delete replicaset xxx(rs-name) 命令 或者 kubectl delete -f replicaset.yaml 命令。执行此命令后, 默认情况下,Kubernetes 垃圾收集器 自动删除所有依赖的 Pod。
唯一注意的是,要删除的是replicaset,而不是下面一个或三个Pod,如果是删除一个或三个Pod,因为 replica 属性被设置为 3 ,被删除的Pod仍然会被创建出来。
- kubectl get all -o wide
- kubectl delete rs frontend
- kubectl get all -o wide
也可使用命令:
- # 第一个机器
- kubectl proxy --port=8080
-
- # 第二个机器
- curl -X DELETE 'localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend' \
- -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Foreground"}' \
- -H "Content-Type: application/json"
2)只删除 replicaset
只删除 ReplicaSet 而不影响它的各个 Pod,方法是使用 kubectl delete 命令并设置 --cascade=orphan 选项。
kubectl delete rs frontend --cascade=orphan也可使用命令
- # 第一个机器
- kubectl proxy --port=8080
-
- # 第二个机器
- curl -X DELETE localhost:8080/apis/apps/v1/namespaces/default/replicasets/frontend \
- -d '{"kind":"DeleteOptions","apiVersion":"v1","propagationPolicy":"Orphan"}' \
- -H "Content-Type: application/json"
5.6 ReplicaSet手动扩缩容
通过更新 .spec.replicas 字段,ReplicaSet 可以被轻松地进行扩缩。ReplicaSet 控制器能确保匹配标签选择器的数量的 Pod 是可用的和可操作的。
5.6.1 修改 replicaset.yaml 文件方式
- apiVersion: apps/v1
- kind: ReplicaSet
- metadata:
- name: frontend
- labels:
- app: guestbook
- tier: frontend
- spec:
- # 按你的实际情况修改副本数
- replicas: 3
- selector:
- matchLabels:
- tier: frontend
- template:
- metadata:
- labels:
- tier: frontend
- spec:
- containers:
- - name: php-redis
- image: nginx:1.16.0
5.6.2 kubectl命令行方式
- kubectl scale replicaset frontend --replicas 5
- kubectl scale replicaset frontend --replicas 1
5.7 ReplicaSet自动扩容缩容
Horizontal Pod Autoscaler(HPA)的控制器,用于实现基于CPU使用率进行自动Pod扩容和缩容的功能。HPA控制器基于Master的kube-controller-manager服务启动参数–horizontal-pod-autoscaler-sync-period定义的时长(默认周期为30s),周期性地监测目标Pod的CPU使用率,并在满足条件时对ReplicationController或Deployment中的Pod副本数量进行调整,以符合用户定义的平均Pod CPU使用率。Pod CPU使用率来源于Heapster组件,所以需要预先安装好Heapster。
创建HPA时可以使用kubectl autoscale命令进行快速创建或者使用yaml配置文件进行创建。在创建HPA之前,需要已经存在一个Deployment/RC对象,并且该Deployment/RC中的Pod必须定义resources.requests.cpu的资源请求值,如果不设置该值,则Heapster将无法采集到该Pod的CPU使用情况,会导致HPA无法正常工作。
通过为一个RC设置HPA,然后使用一个客户端对其进行压力测试,对HPA的用法进行示例。
5.7.1 通过yaml文件来创建
- apiVersion: apps/v1
- kind: ReplicaSet
- metadata:
- name: frontend
- labels:
- app: guestbook
- tier: frontend
- spec:
- # 按你的实际情况修改副本数
- replicas: 3
- selector:
- matchLabels:
- tier: frontend
- template:
- metadata:
- labels:
- tier: frontend
- spec:
- containers:
- - name: php-redis
- image: nginx:1.16.0
- resources:
- requests:
- cpu: 200m
- ports:
- - containerPort: 80
- apiVersion: v1
- kind: Service
- metadata:
- name: frontend
- spec:
- ports:
- - port: 80
- selector:
- tier: frontend
- apiVersion: autoscaling/v1
- kind: HorizontalPodAutoscaler
- metadata:
- name: frontend-scaler
- spec:
- scaleTargetRef:
- apiVersion: apps/v1
- kind: ReplicaSet
- name: frontend
- minReplicas: 1
- maxReplicas: 10
- targetCPUUtilizationPercentage: 50
自动扩容缩容包括三个属性: max 最大副本数Pod、min 最小副本数Pod、targetCPUUtilizationPercentage。
5.7.2 通过命令来创建
kubectl autoscale rs frontend --max=10 --min=1 --cpu-percent=505.8 ReplicaSet的局限以及代替方案
5.8.1 ReplicaSet的局限性
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行。 然而,Deployment 是一个更高级的概念,它管理 ReplicaSet,并向 Pod 提供声明式的更新以及许多其他有用的功能。 因此,建议使用 Deployment 而不是直接使用 ReplicaSet, 除非需要自定义更新业务流程或根本不需要更新。
这实际上意味着,可能永远不需要操作 ReplicaSet 对象:而是使用 Deployment,并在 spec 部分定义应用。
5.8.2 ReplicaSet 的替代方案
1)Deployment(推荐)
Deployment 是一个可以拥有 ReplicaSet 并使用声明式方式在服务器端完成对 Pod 滚动更新的对象。 尽管 ReplicaSet 可以独立使用,目前ReplicaSet 主要用途是提供给 Deployment 作为编排 Pod 创建、删除和更新的一种机制。当使用 Deployment 时,可不必关心如何管理Deployment 所创建的 ReplicaSet,Deployment 拥有并管理其 ReplicaSet。 因此,建议在需要 ReplicaSet 时使用 Deployment。
2)Deployment(推荐)
与用户直接创建 Pod 的情况不同,ReplicaSet 会替换那些由于某些原因被删除或被终止的 Pod,例如在节点故障或破坏性的节点维护(如内核升级)的情况下。 因为这个原因,建议使用 ReplicaSet,即使应用程序只需要一个 Pod。 想像一下,ReplicaSet 类似于进程监视器,只不过ReplicaSet 在多个节点上监视多个 Pod, 而不是在单个节点上监视单个进程。 ReplicaSet 将本地容器重启的任务委托给了节点上的某个代理(例如,Kubelet)去完成。
3)Job
使用Job 代替 ReplicaSet, 可以用于那些期望自行终止的 Pod。
4)DaemonSet
对于管理那些提供主机级别功能(如主机监控和主机日志)的容器, 就要用 DaemonSet 而不用 ReplicaSet。 这些 Pod 的寿命与主机寿命有关:这些 Pod 需要先于主机上的其他 Pod 运行, 并且在机器准备重新启动/关闭时安全地终止。
5)ReplicationController
ReplicaSet 是 ReplicationController 的后继者。二者目的相同且行为类似,只是 ReplicationController 不支持 标签用户指南 中讨论的基于集合的选择算符需求。 因此,相比于 ReplicationController,应优先考虑 ReplicaSet。
6 Replication Controller
简称RC,能够在任何时候都有特定数量的 Pod 副本处于运行状态,并且在任何时候都有指定数量的Pod副本,在此基础上提供一些高级特性,比如滚动升级和弹性伸缩。
RC会在每个节点上创建Pod,Pod上如果有相应的Images可以直接创建,如果没有,则会拉取这个镜像再进行创建。
6.1 功能
- 确保pod数量:它会确保Kubernetes中有指定数量的Pod在运行。如果少于指定数量的pod,Replication Controller会创建新的,反之则会删除掉多余的以保证Pod数量不变。
- 确保pod健康:当pod不健康,运行出错或者无法提供服务时,Replication Controller也会杀死不健康的pod,重新创建新的。
- 弹性伸缩 :在业务高峰或者低峰期的时候,可以通过Replication Controller动态的调整pod的数量来提高资源的利用率。同时,配置相应的
- 监控功能(Hroizontal Pod Autoscaler),会定时自动从监控平台获取Replication Controller关联pod的整体资源使用情况,做到自动伸缩。
- 滚动升级:滚动升级为一种平滑的升级方式,通过逐步替换的策略,保证整体系统的稳定,在初始化升级的时候就可以及时发现和解决问题,避免问题不断扩大。
6.2 工作原理
当 Pod 数量过多时,ReplicationController 会终止多余的 Pod。当 Pod 数量太少时,ReplicationController 将会启动新的 Pod。与手动创建的 Pod 不同,由 ReplicationController 创建的 Pod 在失败、被删除或被终止时会被自动替换。例如,在中断性维护(如内核升级)之后,应用Pod 会在节点上重新创建。因此,即使应用程序只需要一个 Pod,也应该使用 ReplicationController 创建 Pod。ReplicationController 类似于进程管理器,但是 ReplicationController 不是监控单个节点上的单个进程,而是监控跨多个节点的多个 Pod。
6.3 创建RC
- $ vim rc.yaml
- apiVersion: v1
- kind: ReplicationController
- metadata:
- name: nginx
- spec:
- replicas: 3
- selector:
- app: nginx
- template:
- metadata:
- name: nginx
- labels:
- app: nginx
- spec:
- containers:
- - name: nginx
- image: nginx
- ports:
- - containerPort: 80
- $ kubectl apply -f rc.yaml
- $ kubectl get pod
- NAME READY STATUS RESTARTS AGE
- ingress-demo-app-694bf5d965-q4l7m 1/1 Running 0 23h
- ingress-demo-app-694bf5d965-v652j 1/1 Running 0 23h
- nfs-client-provisioner-dc5789f74-nnk77 1/1 Running 1 (8h ago) 22h
- nginx-87sxg 1/1 Running 0 34s
- nginx-kwrqn 1/1 Running 0 34s
- nginx-xk2t6 1/1 Running 0 34s
- $ kubectl describe replicationcontrollers nginx
- Name: nginx
- Namespace: default
- Selector: app=nginx
- Labels: app=nginx
- Annotations: <none>
- Replicas: 3 current / 3 desired
- Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
- Pod Template:
- Labels: app=nginx
- Containers:
- nginx:
- Image: nginx
- Port: 80/TCP
- Host Port: 0/TCP
- Environment: <none>
- Mounts: <none>
- Volumes: <none>
- Events:
- Type Reason Age From Message
- ---- ------ ---- ---- -------
- Normal SuccessfulCreate 102s replication-controller Created pod: nginx-xk2t6
- Normal SuccessfulCreate 102s replication-controller Created pod: nginx-kwrqn
- Normal SuccessfulCreate 102s replication-controller Created pod: nginx-87sxg
当删除其中一个Pod或者删除全部Pod的时候,RC会自动再次创建Pod,直到满足配置文件中定义的个数。
- $ kubectl delete pod nginx-87sxg
- pod "nginx-87sxg" deleted
- $ kubectl get pod
- NAME READY STATUS RESTARTS AGE
- ingress-demo-app-694bf5d965-q4l7m 1/1 Running 0 23h
- ingress-demo-app-694bf5d965-v652j 1/1 Running 0 23h
- nfs-client-provisioner-dc5789f74-nnk77 1/1 Running 1 (8h ago) 22h
- nginx-ex3xh 1/1 Running 0 34s
- nginx-kwrqn 1/1 Running 0 34s
- nginx-xk2t6 1/1 Running 0 34s
6.4 弹性伸缩
弹性伸缩就是在现有环境不能满足业务需求的时候,进行的扩容或缩容。
6.4.1 缩容Pod
- $ kubectl scale replicationcontroller nginx --replicas=1
- replicationcontroller "nginx-rc" scaled
- $ kubectl get pod
- NAME READY STATUS RESTARTS AGE
- nginx-ex3xh 1/1 Running 0 34s
- $ kubectl get rc nginx
- NAME READY STATUS RESTARTS AGE
- nginx 1 1 1 1
6.4.2 扩容Pod
- $ kubectl scale replicationcontroller nginx-rc --replicas=3
- replicationcontroller "nginx-rc" scaled
- $ kubectl get pod
- $ kubectl get rc nginx
6.4.3 判断当前Pod副本是否正确,并修改数量
- # 判断当前副本数是否为3个,如果是,则更改为1个副本
- $ kubectl scale rc nginx-rc --current-replicas=3 --replicas=1
7 StatefulSet
StatefulSet和Deployment一样,可以保证集群中运行指定个数的pod,也支持横向扩展。除此之外StatefulSet中每一个pod会分配一个内部标记用来区分。尽管StatefulSet的pod确实是从同一个pod模板创建的,但每个pod都是不可互换的。无论pod被怎样调度,它们的标记都不会改变。StatefulSet的这个特性,使得其下管理的每个pod具有不同的网络标识(可以指定发送请求到具体哪个pod,这些pod之间也可以相互通信),也可以绑定不同的持久化存储(pod重新调度之后,和它绑定的存储仍然是原先那个)。
7.1 StatefulSet的限制和要求
- pod的存储必须使用StorageClass关联的PVC提供,或者由管理员预先创建好。
- 删除StatefulSet或者是减小StatefulSet的replicas,k8s不会自动删除和已终止运行的pod绑定的数据卷。这样做是为了保证数据安全。
- 为了确保StatefulSet管理的每个pod的网络标识不同,需要创建对应的headless service。
- 当StatefulSet被删除的时候,它不能保证所有被管理的pod都停止运行。因此,在删除StatefulSet之前,需要先将它scale到0个pod。
- pod管理策略使用默认的OrderedReady,进行滚动升级的时候可能会出现问题,需要手工修复。
7.2 应用场景
- 稳定的持久化存储,即Pod重新调度后还是能访问到相同的持久化数据,基于PVC来实现
- 稳定的网络标志,即Pod重新调度后其PodName和HostName不变,基于Headless Service(即没有Cluster IP的Service)来实现
- 有序部署,有序扩展,即Pod是有顺序的,在部署或者扩展的时候要依据定义的顺序依次依次进行(即从0到N-1,在下一个Pod运行之前所有之前的Pod必须都是Running和Ready状态),基于init containers来实现
- 有序收缩,有序删除(即从N-1到0)
7.3 创建StatefulSet
注意:在创建StatefulSet之前已经创建了一个配套的headless service。
7.3.1 yaml文件
- apiVersion: v1
- kind: Service
- metadata:
- name: nginx
- labels:
- app: nginx
- spec:
- ports:
- - port: 80
- name: web
- clusterIP: None
- selector:
- app: nginx
- ---
- apiVersion: apps/v1
- kind: StatefulSet
- metadata:
- name: web
- spec:
- selector:
- matchLabels:
- app: nginx # has to match .spec.template.metadata.labels
- serviceName: "nginx"
- replicas: 3 # by default is 1
- template:
- metadata:
- labels:
- app: nginx # has to match .spec.selector.matchLabels
- spec:
- terminationGracePeriodSeconds: 10
- containers:
- - name: nginx
- image: k8s.gcr.io/nginx-slim:0.8
- ports:
- - containerPort: 80
- name: web
- volumeMounts:
- - name: www
- mountPath: /usr/share/nginx/html
- volumeClaimTemplates:
- - metadata:
- name: www
- spec:
- accessModes: [ "ReadWriteOnce" ]
- storageClassName: "my-storage-class"
- resources:
- requests:
- storage: 1Gi
- $ kubectl create -f statefulset.yaml
- statefulset.apps/nginx created
- $ kubectl get statefulset
- NAME READY AGE
- nginx 3/3 107s
-
- $ kubectl get pods
- NAME READY STATUS RESTARTS AGE
- nginx-0 1/1 Running 0 112s
- nginx-1 1/1 Running 0 69s
- nginx-2 1/1 Running 0 39s
此时如果手动删除nginx-1这个Pod,然后再次查询Pod,可以看到StatefulSet重新创建了一个名称相同的Pod,通过创建时间5s可以看出nginx-1是刚刚创建的。
- # kubectl delete pod nginx-1
- pod "nginx-1" deleted
-
- # kubectl get pods
- NAME READY STATUS RESTARTS AGE
- nginx-0 1/1 Running 0 3m4s
- nginx-1 1/1 Running 0 5s
- nginx-2 1/1 Running 0 1m10s
进入容器查看容器的hostname,可以看到同样是nginx-0、nginx-1和nginx-2。
- # kubectl exec nginx-0 -- sh -c 'hostname'
- nginx-0
- # kubectl exec nginx-1 -- sh -c 'hostname'
- nginx-1
- # kubectl exec nginx-2 -- sh -c 'hostname'
- nginx-2
同时可以看一下StatefulSet创建的PVC,可以看到这些 PVC,都以“PVC名称-StatefulSet名称-编号”的方式命名,并且处于 Bound 状态。
- # kubectl get pvc
- NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
- data-nginx-0 Bound pvc-f58bc1a9-6a52-4664-a587-a9a1c904ba29 1Gi RWX csi-nas 2m24s
- data-nginx-1 Bound pvc-066e3a3a-fd65-4e65-87cd-6c3fd0ae6485 1Gi RWX csi-nas 101s
- data-nginx-2 Bound pvc-a18cf1ce-708b-4e94-af83-766007250b0c 1Gi RWX csi-nas 71s
7.4 应用组织状态
StatefulSet 将应用设计抽象为了两种状态:
- 拓扑状态
- 存储状态
7.4.1 拓扑状态
应用存在多个实例,但多个实例地位并不完全对等。
应用的多个实例必须按照某种顺序启动,并且必须成组存在,例如一个应用中必须存在一个 A Pod 和两个 B Pod,且 A Pod 必须先于 B Pod 启动的场景。
7.4.2 存储状态
应用存在多个实例,但每个实例绑定的存储数据不同,那么对于一个 Pod 来说,无论它是否被重新创建,它读到的数据状态应该是一致的。
7.5 StatefulSet网络标识
7.5.1 Kubernetes Service访问方式
Kubernetes 的 Service 就是对外提供的可访问服务,它有两种访问方式:
-
VIP 方式:它是 Virtual IP 的缩写,通过将服务绑定到 Kubernetes 虚拟的 IP 地址,提供给外部调用,通过虚拟 IP 地址隐藏了服务的具体实现与地址。
-
DNS 方式:与虚拟 IP 地址类似,外部通过访问 DNS 记录的方式实现对具体 Service 的转发。
-
Normal Service:将 DNS 地址绑定到虚拟 IP 地址,从而复用虚拟 IP 地址的设计和逻辑;
-
Headless Service:将 DNS 地址直接代理到 Pod。
-
7.5.2 实战Headless Service
StatefulSet创建后,可以看下Pod是有固定名称的,那Headless Service是如何起作用的呢,那就是使用DNS,为Pod提供固定的域名,这样Pod间就可以使用域名访问,即便Pod被重新创建而导致Pod的IP地址发生变化,这个域名也不会发生变化。
Headless Service创建后,每个Pod的IP都会有下面格式的域名。
<pod-name>.<svc-name>.<namespace>.svc.cluster.local例如上面的三个Pod的域名是:
- nginx-0.nginx.default.svc.cluster.local
- nginx-1.nginx.default.svc.cluster.local
- nginx-1.nginx.default.svc.cluster.local
实际访问时可以省略后面的.<namespace>.svc.cluster.local。
7.5.3 dns验证
1)使用tutum/dnsutils镜像创建一个Pod,进入这个Pod的容器。
- $ kubectl run -i --tty --image tutum/dnsutils dnsutils --restart=Never --rm /bin/sh
- If you don't see a command prompt, try pressing enter.
- / # nslookup nginx-0.nginx
- Server: 10.247.3.10
- Address: 10.247.3.10#53
- Name: nginx-0.nginx.default.svc.cluster.local
- Address: 172.16.0.31
2)使用nslookup命令查看Pod对应的域名,可以发现能解析出Pod的IP地址。
- / # nslookup nginx-1.nginx
- Server: 10.247.3.10
- Address: 10.247.3.10#53
- Name: nginx-1.nginx.default.svc.cluster.local
- Address: 172.16.0.18
-
- / # nslookup nginx-2.nginx
- Server: 10.247.3.10
- Address: 10.247.3.10#53
- Name: nginx-2.nginx.default.svc.cluster.local
- Address: 172.16.0.19
可以看到DNS服务器的地址是10.247.3.10,这是在创建CCE集群时默认安装CoreDNS插件,用于提供DNS服务。
7.5.4 StatefulSet缩容
 7.6 StatefulSet存储状态
7.6 StatefulSet存储状态
StatefulSet 通过为每一个 pod 分配有粘性的 ID,并且在 pod 发生变更时,维持 ID 的稳定,从而保证了网络状态下不对等关系的各个 Pod 在启动、删除和重建过程中能够始终保持稳定。
但在实际的使用场景中,用户不仅仅需要维护网络拓扑的稳定性,Pod 与分布式存储的存储节点之间关系的稳定性往往也是非常重要的,而这也正是 StatefulSet 的另一个优势。
7.6.1 Persistent Volume
Persistent Volume 简称 PV,是 Kubernetes 集群中某个网络存储对应的一块存储,是整个集群的分布式存储资源。
与Volume 不同,PV 并不是被定义在 Pod 上的资源,而是独立于 Pod 之外,由运维人员单独维护的资源,当 Pod 需要使用 PV 时,Pod 通过引用 PV 中创建的 PVC(Persistent Volume Claim)来实现对分布式存储空间的创建和分配。如下描述了一个 NFS 类型的 PV:
- # 创建一个NFS类型的PV示例,容量为2G
- apiVersion: v1
- kind: PersistentVolume
- metadata:
- name: pv001
- labels:
- name: pv001
- spec:
- nfs:
- path: /data/training/nfs
- server: 10.68.4.64
- accessModes:
- - ReadWriteMany
- capacity:
- storage: 2Gi
7.6.2 Persistent Volume Claim
Persistent Volume Claim 简称 PVC,顾名思义,是对 Persistent Volume 资源的请求,正如 Pod 请求节点资源一样,PVC 是对 PV 资源的请求。
- # 创建PVC示例,申请1G存储空间
- apiVersion: v1
- kind: PersistentVolumeClaim
- metadata:
- name: pv-claim
- spec:
- accessModes: ["ReadWriteMany"]
- resources:
- requests:
- storage: 1Gi
这样就完成了一个 PVC 的创建,在 Pod 中直接使用即可。
7.6.3 Pod 中挂载 pvc
在一个 Pod 的定义,在 volumes 中,它声明了对 PVC 的使用:
- apiVersion: v1
- kind: Pod
- metadata:
- name: pv-pod
- spec:
- containers:
- - name: pv-container
- image: nginx
- ports:
- - containerPort: 80
- name: http-server
- volumeMounts:
- - mountPath: "/usr/share/nginx/html"
- name: pv-storage
- volumes:
- - name: pv-storage
- persistentVolumeClaim:
- claimName: pv-claim
7.6.4 PV 的优点
PV 的存在,旨在分离分布式存储的集中维护与使用。通过 PV 与 PVC 的分离,在存储的维护上,产生了类似 Kubernetes 集群资源与 Pod 请求之间的抽象。从而让相关维护人员的关注点更加集中和明确。运维人员负责整个 PV 的维护,他们只关心存储的类型、容量、硬件位置等信息,而使用人员则再也不需要关注这些存储本身的细节信息,而只需要关心自己的业务需要使用哪些资源、多少资源。
7.6.5 存储状态
对于一个 Pod 来说,它需要挂载和使用的分布式存储节点必须是稳定的。Id 为 web-0 的 Pod 如果在某一时刻挂载了 web-1 Pod 对应的存储资源,结果可能是不堪设想的。
StatefulSet 控制器通过 volumeClaimTemplates 解决了这一问题。
如果为一个 StatefulSet 配置了 volumeClaimTemplates,那么就意味着,这个控制器中管理的每个 Pod 都会自动声明一个自己 ID 所对应的 PVC,而这个 PVC 定义所需的属性,则均来自于 volumeClaimTemplates 中的声明。
- apiVersion: apps/v1
- kind: StatefulSet
- metadata:
- name: web
- spec:
- serviceName: "nginx"
- replicas: 2
- selector:
- matchLabels:
- app: nginx
- template:
- metadata:
- labels:
- app: nginx
- spec:
- containers:
- - name: nginx
- image: nginx:1.9.1
- ports:
- - containerPort: 80
- name: web
- volumeMounts:
- - name: www
- mountPath: "/usr/share/nginx/html"
- volumeClaimTemplates:
- - name: www
- metadata:
- name: www
- spec:
- accessModes:
- - ReadWriteOnce
- resources:
- requests:
- storage: 1Gi
- $ kubectl create −f statefulset.yaml
- $ kubectl get pvc -l app=nginx
- NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
- www-web-0 Bound pvc-669431a8-4f5f-4744-bbee-65c9e6564120 1Gi RWO standard 2m37s
- www-web-1 Bound pvc-db848c7d-9158-4cd3-8ccc-721127ecd19b 1Gi RWO standard 2m20s
PVC都以“<PVC 名字 >-<StatefulSet 名字 >-< 编号 >”的方式命名,并且处于 Bound 状态。
StatefulSet 创建出来的所有 Pod,都会声明使用编号的 PVC。比如,在名叫 web-0 的 Pod 的 volumes 字段,它会声明使用名叫 www-web-0 的 PVC,从而挂载到这个 PVC 所绑定的 PV。
当 web-0 Pod 向挂载给他的 PV 节点中写入数据后,即使 web-0 Pod 发生宕机或重启,从而被一个全新的同样 ID 为 web-0 的 Pod 替换后,由于新的 Pod 挂载的仍然是 Id 为 www-web-0 的 PVC,所以,它依然可以读取到此前 web-0 Pod 写入的数据。
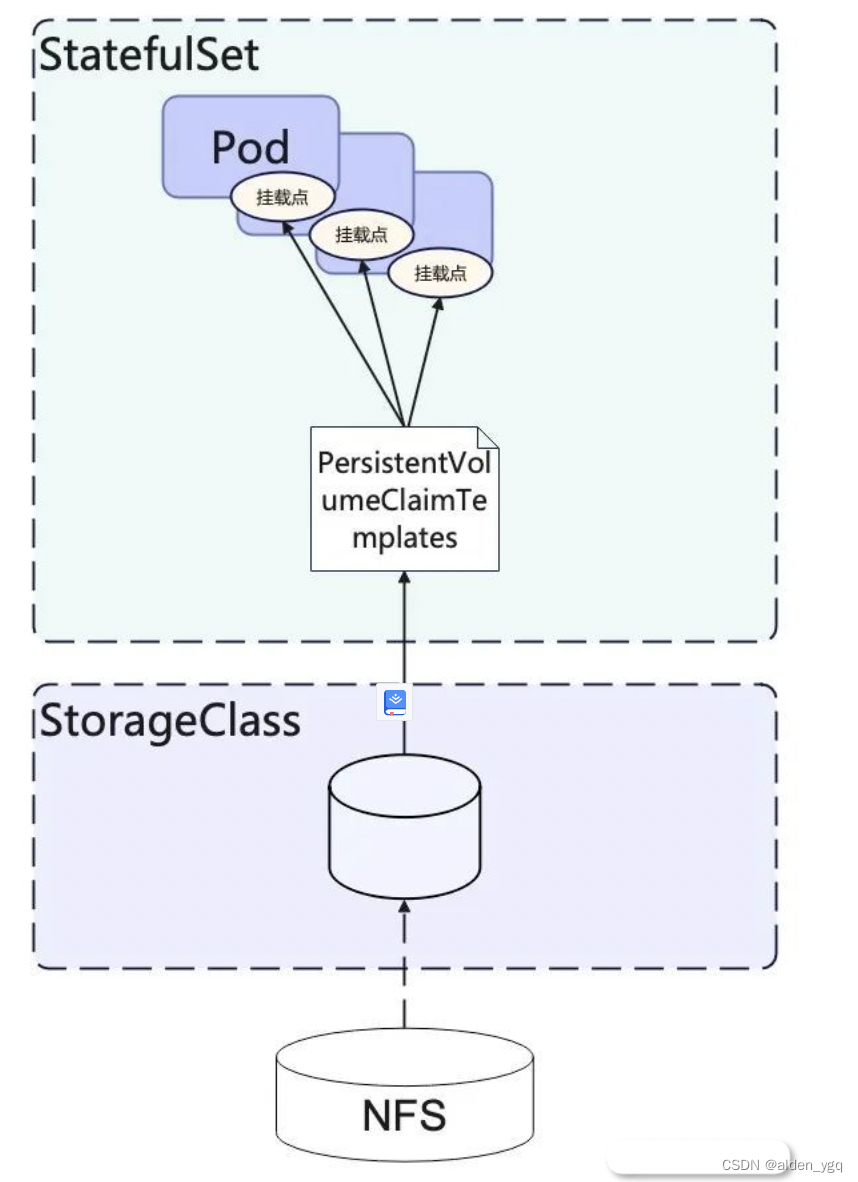
StatefulSet与 Deployment 最大的不同在于StatefulSet并不借助于 ReplicaSet,而是直接管理所有的 Pod,因为在 StatefulSet 中,Pod 之间的地位是不完全对等的。
在 Pod 的管理过程中,StatefulSet 通过为每个 Pod 维护一个唯一 id 以及唯一的 DNS 记录,保证了 Pod 的地位,无论 Pod 发生变更、宕机还是重启,StatefulSet 只需要保证每个 DNS 记录都对应唯一的 Pod,就可以保证它所管理的网络拓扑结构的稳定。
同时,对于存储状态来说,StatefulSet 通过维护 PersistentVolumeClaimTemplates 实现对每一个 Pod 所对应的分布式存储节点的管理,借由每个 ID 的 Pod 所对应的 PVC 的稳定,维护了整个 StatefulSet 管理下应用存储状态的稳定。
8 DaemonSet
8.1 概述
DaemonSet,简称DS。其确保全部(或者某些)节点上运行一个Pod副本。当有新节点加入集群时,其会在该新节点上新增一个Pod;当有节点从集群移除时,该Pod也会被自动回收。可以看到,DS的典型使用场景如下所示:
- 在每个节点上运行集群守护进程
- 在每个节点上运行日志收集守护进程
- 在每个节点上运行监控守护进程
8.2 DaemonSet工作原理
Daemonset的控制器会监听kuberntes的Daemonset 对象、pod 对象、node 对象,这些被监听的对象之变动,就会触发syncLoop循环让kubernetes集群朝着Daemonset对象描述的状态进行演进。
8.3 DaemonSet与Deployment的区别
Deployment部署的副本Pod会分布在各个Node上,每个Node都可能运行一个或多个副本;而DaemonSet的不同之处在于每个Node上最多只能运行一个副本。
8.4 创建DS
8.4.1 保持在每个node上部署一个pod
以下以三节点集群为例。
- # API组、版本
- apiVersion: apps/v1
- # 资源类型
- kind: DaemonSet
- metadata:
- # RS名称
- name: my-log-service-ds-1
- spec:
- # 标签选择器
- selector:
- matchLabels:
- app: log-service
- # Pod 模板
- template:
- metadata:
- # 标签信息
- labels:
- app: log-service
- spec:
- # 容器信息
- containers:
- - name: my-log-service-1
- image: luksa/kubia

8.4.2 在特定节点部署一个Pod
可以通过DS中Pod模板的节点选择器 实现 DS只针对特定节点部署一个Pod。
例如需要部署一个固态硬盘的监控服务,可以指定pod部署到搭载固态硬盘的工作节点上即可。
- # API组、版本
- apiVersion: apps/v1
- # 资源类型
- kind: DaemonSet
- metadata:
- # RS名称
- name: my-ssd-monitor-ds-1
- spec:
- # 标签选择器
- selector:
- matchLabels:
- app: ssd-monitor
- # Pod 模板
- template:
- metadata:
- # 标签信息
- labels:
- app: ssd-monitor
- spec:
- # 节点选择器
- nodeSelector:
- disk: ssd
- # 容器信息
- containers:
- - name: my-ssd-monitor-1
- image: luksa/ssd-monitor
对3个工作节点均打上名为disk的标签,其值要么是ssd、要么是hhd。然后创建DS,可以看到其会根据节点选择器选择具有disk=ssd标签的节点部署一个Pod。效果如下所示:

8.5 DaemonSet Spec
与所有其他Kubernetes配置一样,DaemonSet也需要apiversion、kind和metadata字段。DaemonSet对象的名称必须是一个合法的DNS子域名。
DaemonSet也需要.spec节区。
8.5.1 Pod模板与选择符
与其他工作负载一样,.spec中需要template模板,用来描述生成pod的信息。还需要指定合理的标签,以供选择器来筛选。
在DaemonSet中的Pod模板必须具有一个值为Always的RestartPolicy,当该值未指定时,默认是Always。
一旦DaemonSet创建成功,其选择器.sepc.selector就不能修改。选择器有多个条件时,按逻辑与操作处理。
8.5.2 仅在某些节点上运行Pod
如果指定了 .spec.template.spec.nodeSelector,DaemonSet 控制器将在能够与Node选择算符匹配的节点上创建 Pod。 类似这种情况,可以指定 .spec.template.spec.affinity,DaemonSet 控制器将在能够与节点亲和性匹配的节点上创建 Pod。 如果根本就没有指定,则 DaemonSet Controller 将在所有节点上创建 Pod。
8.6 更新DaemonSet
如果节点的标签被修改,DaemonSet将立刻向新匹配的节点添加Pod,并删除不匹配的节点上的Pod。
可以修改DaemonSet创建的pod,不过并非所有的字段都可更新。
可以删除一个DaemonSet,对应的pod也会被删除。如果使用--cascade-orhpan选项,则pod会被保留。接下来如果使用相同选择器创建新的DaemonSet,则新的DaemonSet会收养已有的pod。如果有pod需要被替换,DaemonSet会根据其updateStrategy来替换。
8.7 DaemonSet的替代方案
8.7.1 init脚本
可以使用初始化脚本直接在节点上启动守护进程(如使用init、upstartd、systemd)。但大多数情况下这是不推荐的,不如使用DaemonSet。
8.7.2 静态Pod
通过在一个指定的、受kubelet监视的目录下编写文件创建pod也是可行的。这类pod被称为静态Pod。不像DaemonSet,静态Pod不受kubectl和其他Kubernetes API客户端管理,静态pod不依赖于API服务器,这使得它们在启动引导新集群的情况下非常有用。此外,静态Pod在将来可能会被废弃。
8.7.3 Deployment
DaemonSet与Deployment非常类似,都能创建pod,并且pod中的进程都不希望被终止(如Web服务器、存储服务器)。
建议为无状态的服务使用Deployment。对这些服务而言。对副本数量进行扩缩容、平滑升级,比精确控制Pod运行在某个主机上重要得多。当需要Pod副本总是运行在全部或特定主机上,并且当该DaemonSet提供了节点级别的功能(允许其他pod在该节点上正确运行)时,才应该使用DaemonSet。例如,网络插件通常包含一个以DaemonSet运行的组件。这个DaemonSet组件确保它所在节点的网络正常工作。
9 Job
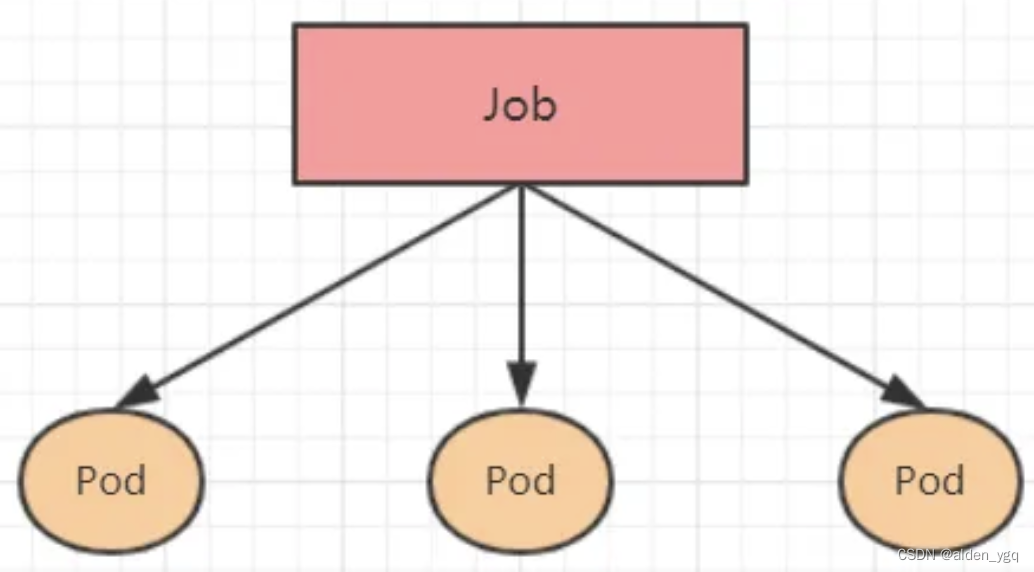
9.1 概述
Kubernetes Job是一个控制器,它可以创建和管理一次性任务。Job会创建一个或多个Pod,并将执行这些创建的pod,直到所有的pod成功终止。
与其他控制器不同,Job控制器负责确保Pod成功地完成任务后删除它们。这意味着如果任务失败或调度失败(例如,由于资源不足),Kubernetes将自动重新启动失败的Pod,直到任务成功完成为止。
删除Job的操作会清除所创建的全部pod,挂起Job的操作会删除Job的所有活跃Pod,直到Job被再次恢复执行。
9.2 Job架构
9.3 资源清单
- apiVersion: batch/v1 # 版本号
- kind: Job # 类型
- metadata: # 元数据
- name: # job 名称
- namespace: # 所属命名空间
- labels: #标签
- controller: job
- spec: # 详情描述
- completions: 1 # 指定 job 需要成功运行 Pods 的次数。默认值: 1
- parallelism: 1 # 指定 job 在任一时刻应该并发运行 Pods 的数量。默认值: 1,如果上面的 completions 为 6 ,这个参数为 3 ,表示有 6 个 pod,允许有 3 个 pod 并发运行
- activeDeadlineSeconds: 30 # 指定 job 可运行的时间期限,超过时间还未结束,系统将会尝试进行终止。
- backoffLimit: 6 # 指定 job 失败后进行重试的次数。默认是 6
- manualSelector: true # 是否可以使用 selector 选择器选择 pod,默认是 false
- selector: # 选择器,通过它指定该控制器管理哪些 pod
- matchLabels: # Labels 匹配规则
- app: counter-pod
- matchExpressions: # Expressions 匹配规则
- - {key: app, operator: In, values: [counter-pod]}
- template: # 模板,当副本数量不足时,会根据下面的模板创建 pod 副本
- metadata:
- labels:
- app: counter-pod
- spec:
- restartPolicy: Never # 重启策略只能设置为 Never 或者 OnFailure
- containers:
- - name: counter
- image: busybox:1.30
- command: ["bin/sh","-c","for i in 9 8 7 6 5 4 3 2 1; do echo $i;sleep 2;done"]
9.4 spec 规约
job.spec 描述了任务执行的具体情况信息:
- FIELDS:
- activeDeadlineSeconds <integer>
- ## 系统尝试终止任务之前任务可以持续活跃的持续时间(秒),时间长度是相对于 startTime 的; 字段值必须为正整数。如果任务被挂起(在创建期间或因更新而挂起), 则当任务再次恢复时,此计时器会被停止并重置
- backoffLimit <integer>
- ## 指定标记此任务失败之前的重试次数。默认值为 6。
-
- completionMode <string>
- ## 指定如何跟踪 Pod 完成情况。它可以是 NonIndexed (默认) 或者 Indexed。
- ## NonIndexed 表示当有 .spec.completions 个成功完成的 Pod 时,认为 Job 完成。每个 Pod 完成都是彼此同源的。
- ## Indexed 意味着 Job 的各个 Pod 会获得对应的完成索引值,从 0 到(.spec.completions - 1),可在注解 "batch.kubernetes.io/job-completion-index" 中找到。当每个索引都对应有一个成功完成的 Pod 时, 该任务被认为是完成的。 当值为 Indexed 时,必须指定 .spec.completions 并且 .spec.parallelism 必须小于或等于 10^5。 此外,Pod 名称采用 $(job-name)-$(index)-$(random-string) 的形式,Pod 主机名采用 $(job-name)-$(index) 的形式。
- completions <integer>
- ## 指定任务应该运行并预期成功完成的 Pod 个数。设置为 nil 意味着任何 Pod 的成功都标识着所有 Pod 的成功, 并允许 parallelism 设置为任何正值。设置为 1 意味着并行性被限制为 1,并且该 Pod 的成功标志着任务的成功。
-
- manualSelector <boolean>
- ## manualSelector 控制 Pod 标签和 Pod 选择器的生成。
-
- parallelism <integer>
- ## 指定任务应在任何给定时刻预期运行的 Pod 个数上限。
-
- selector <Object>
- ## 对应与 Pod 计数匹配的 Pod 的标签查询。通常,系统会为你设置此字段
-
- suspend <boolean>
- ## 指定 Job 控制器是否应该创建 Pod。如果创建 Job 时将 suspend 设置为 true,则 Job 控制器不会创建任何 Pod。 如果 Job 在创建后被挂起(即标志从 false 变为 true),则 Job 控制器将删除与该 Job 关联的所有活动 Pod。 用户必须设计他们的工作负载来优雅地处理这个问题。暂停 Job 将重置 Job 的 startTime 字段, 也会重置 ActiveDeadlineSeconds 计时器。默认为 false。
-
- template <Object> -required-
- ## 描述执行任务时将创建的 Pod。
-
- ttlSecondsAfterFinished <integer>
- ## 限制已完成执行(完成或失败)的任务的生命周期。如果设置了这个字段, 在 Job 完成 ttlSecondsAfterFinished 秒之后,就可以被自动删除。 当 Job 被删除时,它的生命周期保证(例如终结器)会被考察。 如果未设置此字段,则任务不会被自动删除。如果此字段设置为零,则任务在完成后即可立即删除。
9.5 Job实战
参考:
https://www.cnblogs.com/renshengdezheli/p/17450685.html
k8s--job 控制器_行走在这人世间的 tester的技术博客_51CTO博客
9.6 Job的终止和清理
9.6.1 当 Job 完成后
- 将不会创建新的 Pod
- 已经创建的 Pod 也不会被清理掉。此时,您仍然可以继续查看已结束 Pod 的日志,以检查 errors/warnings 或者其他诊断用的日志输出
- Job 对象也仍然保留着,以便您可以查看该 Job 的状态
- 由用户决定是否删除已完成的 Job 及其 Pod
- 可通过
kubectl命令删除 Job,例如:kubectl delete jobs/pi; - 删除 Job 对象时,由该 Job 创建的 Pod 也将一并被删除。
- 可通过
9.6.2 当job异常时
Job 通常会顺利的执行下去,但是在如下情况可能会非正常终止:
- 某一个 Pod 执行失败(且
restartPolicy=Never) - 或者某个容器执行出错(且
restartPolicy=OnFailure)- 此时,Job 按照 处理Pod和容器的失败中
.spec.bakcoffLimit描述的方式进行处理 - 一旦重试次数达到了
.spec.backoffLimit中的值,Job 将被标记为失败,且尤其创建的所有 Pod 将被终止
- 此时,Job 按照 处理Pod和容器的失败中
- Job 中设置了
.spec.activeDeadlineSeconds。该字段限定了 Job 对象在集群中的存活时长,一旦达到.spec.activeDeadlineSeconds指定的时长,该 Job 创建的所有的 Pod 都将被终止,Job 的 Status 将变为type:Failed、reason: DeadlineExceeded。
Job 中
.spec.activeDeadlineSeconds字段的优先级高于.spec.backoffLimit。因此,正在重试失败 Pod 的 Job,在达到.spec.activeDeadlineSecondes时,将立刻停止重试,即使.spec.backoffLimit还未达到。
- apiVersion: batch/v1
- kind: Job
- metadata:
- name: pi-with-timeout
- spec:
- backoffLimit: 5
- activeDeadlineSeconds: 100
- template:
- spec:
- containers:
- - name: pi
- image: perl
- command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
- restartPolicy: Never
Job 中有两个 activeDeadlineSeconds:
.spec.activeDeadlineSeconds.spec.template.spec.activeDeadlineSeconds
10 CronJob
10.1 概述
一个CronJob对象就像是一个Linux环境的crontab文件一样,它会在给定的调度周期(crontab格式)内定期的创建一些job。
所有的定时任务的调度周期都基于kube-controller-manager的时区。
通常情况下,CronJob对于创建定期和重复的任务非常有用,比如定期的备份和邮件发送之类的任务场景。
10.2 Cron时间表
- ┌───────────── 分钟 (0 - 59)
- │ ┌───────────── 小时 (0 - 23)
- │ │ ┌───────────── 月的某天 (1 - 31)
- │ │ │ ┌───────────── 月份 (1 - 12)
- │ │ │ │ ┌───────────── 周的某天 (0 - 6)(周日到周一;在某些系统上,7 也是星期日)
- │ │ │ │ │ 或者是 sun,mon,tue,web,thu,fri,sat
- │ │ │ │ │
- │ │ │ │ │
- * * * * *
| 输入 | 描述 | 相当于 |
| @yearly (or @annually) | 每年 1 月 1 日的午夜运行一次 | 0 0 1 1 * |
| @monthly | 每月第一天的午夜运行一次 | 0 0 1 * * |
| @weekly | 每周的周日午夜运行一次 | 0 0 * * 0 |
| @daily(or @midnight) | 每天午夜运行一次 | 0 0 * * * |
| @hourly | 每小时的开始一次 | 0 * * * * |
例如,下面这行指出必须在每个星期五的午夜以及每个月 13 号的午夜开始任务:
0 0 13 * 5要生成 CronJob 时间表表达式,还可以使用crontab.guru之类的 Web 工具。
10.3 时区
对于没有指定时区的CronJob,kube-controller-manager基于本地时区解释排期表(Schedule)。
如果启用了 CronJobTimeZone 特性门控, 可以为 CronJob 指定一个时区(如果没有启用该特性门控,或者使用的是不支持试验性时区功能的Kubernetes版本,集群中所有CronJob的时区都是未指定的)。
启用该特性后,可以将 spec.timeZone 设置为有效时区名称。 例如,设置 spec.timeZone: "Etc/UTC" 指示 Kubernetes采用UTC来解释排期表。
Go 标准库中的时区数据库包含在二进制文件中,并用作备用数据库,以防系统上没有可用的外部数据库。
10.4 kubernetes CronJob和Linux crontab对比
熟悉Linux系统的对crontab定时任务应该不陌生,下面看看kubernetes CronJob和Linux crontab两者差异。
Linux 下的 crontab 和 Kubernetes 下的 CronJob 都是用于执行周期性任务的工具,但它们在实现方式和使用方式上有以下几点不同:
- 调度精度:Linux 下的 crontab 支持分钟级别的调度,而 Kubernetes 下的 CronJob 可以支持到秒级别的调度。
- 状态管理:Linux 下的 crontab 只能通过查看日志等方式来了解任务的运行情况,而 Kubernetes 下的 CronJob 可以通过 kubectl 工具查看任务的运行状态,并且可以对任务进行修改和删除等操作。
- 并发控制:Linux 下的 crontab 没有内置的并发控制机制,如果同一个任务同时被多次触发,可能会导致资源抢占。而 Kubernetes 下的 CronJob 可以通过
.spec.concurrencyPolicy字段指定任务的并发策略,从而避免资源抢占的问题。 - 环境隔离:Linux 下的 crontab 所有任务都运行在同一个环境中,容易出现依赖冲突等问题。而 Kubernetes 下的 CronJob 可以定义多个 Pod 来运行不同的任务,从而实现了任务之间的环境隔离。
- 缩放性:Linux 下的 crontab 通常只能运行在单台服务器上,无法进行水平扩展。而 Kubernetes 下的 CronJob 可以运行在多节点的集群上,并且可以通过水平扩展来提高任务的并发度和可用性。
综上所述,Linux 下的 crontab 和 Kubernetes 下的 CronJob 在功能和使用方式上都有不同,具体使用哪种工具取决于具体的需求和场景。
10.5 Cronjob参数详情
- spec.startingDeadlineSeconds: 表示统计错过调度次数(100次)的开始时间,默认从最后一次调度时间开始统计错过调度次数(超过100不再调度)。
- spec.concurrencyPolicy: 并发调度策略,可选值:{“Allow”:“允许并发”,“Forbid”:“不允许”,“Replace”:“调度覆盖”}。Allow: 注意:当设置为Allow时,需要考虑到任务执行时间和调度周期,因为可能上个任务没执行成功,下个任务就到执行时间了,如此下来可能会有多个相同的任务在同时执行,造成资源浪费或者并发安全问题;Replace: 当使用Replace遇到上述情况,后个任务会将前一个任务替换掉,如此一来所有的任务可能都不会完整执行;Forbid: 不允许并发调度,也即当前任务未完成时,即使到了下一个调度周期,调度任务也不会执行。此种情况下可能出现任务异常阻塞。如果此时startingDeadlineSeconds参数也没有设置,就可能会出现经过100个调度周期后,该任务不再调度。
- spec.schedule: 调度周期,格式为标准的crontab格式[分 时 日 月 周]。
- spec.failedJobsHistoryLimit: 历史失败的任务数限制(通常可以保留1-2个,用于查看失败详情,以调整调度策略)。
- spec.successfulJobsHistoryLimit: 历史成功的任务数限制(可以自己决定保留多少个成功任务)。
- spec.jobTemplate: 标准的pod运行的模板(容器运行时的相关参数)。
- spec.suspend: 可选参数,如果设置为true,所有后续的任务都会被暂停执行,该参数不适用于已经运行的任务,默认为False。
10.6 Cronjob调度丢失
一个Cronjob每执行一次调度就会创建一个Jobs对象。大概是因为有时候可能会有两个job被创建,或者没有任务创建。官方尝试去解决这个问题,但是目前仍然无法避免。因此在设计过程中,所有的Job都应该是幂等性的(idempotent)。
如果CronJob未能在预定时间创建,则该任务将被视为错过调度。对于每一个Cronjob来说,CronJob控制器会检查从上一次调度时间到现在的持续时间内它错过了多少个调度,如果错过调度100次,它将不再执行调度,并且会有如下相关异常:
Cannot determine if job needs to be started. Too many missed start time (> 100). Set or decrease .spec.startingDeadlineSeconds or check clock skew.值得注意的是,如果设置了startingDeadlineSeconds参数(不为空),控制器统计错过的调度次数将不再是从最后一次调度时间,而是按startingDeadlineSeconds的值统计。比如,如果设置startingDeadlineSeconds:200,控制器会统计在最后200秒内错过了的调度次数。
当设置concurrencyPolicy: Forbid时,如果前一个任务还在运行时,CronJob尝试再次被调度,此时会被forbid掉,也会被记录为错过一次调度。
假设一个定时任务被设置在08:30:00开始每一分钟执行一次,并且startingDeadlineSeconds:200。如果CronJob控制器在8:30-10:30时间段故障了,Job将会在10:30:00开始继续执行。 因为控制器仅会计算在过去的200秒内,错过调度的次数,这远远小于100次,所有定时任务会在控制器恢复后继续调度,而不会影响正常的任务。
另外需要注意的是,CronJob仅负责调度和创建匹配的Jobs,而由Jobs真正去管理真正执行任务的Pods。
10.7 cronjob实战
参考:
https://www.cnblogs.com/renshengdezheli/p/17452237.html

