
- 1Android 手把手教你实现百度身份证识别
- 2R统计绘图-线性混合效应模型详解(理论、模型构建、检验、选择、方差分解及结果可视化)
- 3注意力、自注意力、多头注意力机制_注意力机制 key query value怎么计算
- 4收藏 一句话问答 linux _172.168.3.222
- 5微信小程序routeDone错误_routedone with a webviewid 1 that is not the curre
- 6resize-observer源码解读
- 7mysql 外键相关_sysql 外键程序
- 8宇视摄像头ip搜索软件_实战演示安卓木马程序监控手机摄像头
- 9RTK switch的SDK 初始化启动流程分析_rtk_vlan_init
- 10HarmonyOS之深入解析线程管理_鸿蒙系统线程管理api
朴素贝叶斯(分类算法)理论+Python代码实现_贝叶斯定理python实现
赞
踩
朴素贝叶斯(分类算法)理论+Python代码实现
一、理论基础
贝叶斯分类算法是基于贝叶斯方法的一列分类算法,包括朴素贝叶斯、半朴素贝叶斯、贝叶斯网络、EM算法等,朴素贝叶斯分类器是贝叶斯分类器中最简单,也是最常见的一种分类方法。
先验概率:是指根据以往经验和分析得到的概率。
后验概率:事情已经发生,要求这件事情发生的原因是由某个因素引起的可能性的大小。后验概率类似于条件概率。
联合概率:设二维离散型随机变量(X,Y)所有可能取得值为,记则称 为随机变量X和Y的联合概率,计算如下:
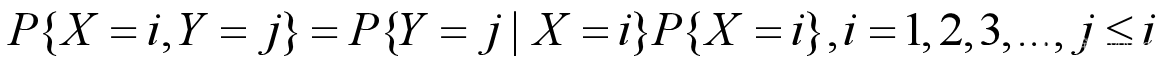
1. 贝叶斯定理
贝叶斯公式是建立在条件概率的基础上寻找事件发生的原因(即大事件A已经发生的条件下,分割中的小事件 Bi 的概率),设 B1,B2,…, 是样本空间 Ω 的一个划分,则对任一事件A(P(A)>0),有贝叶斯定理:
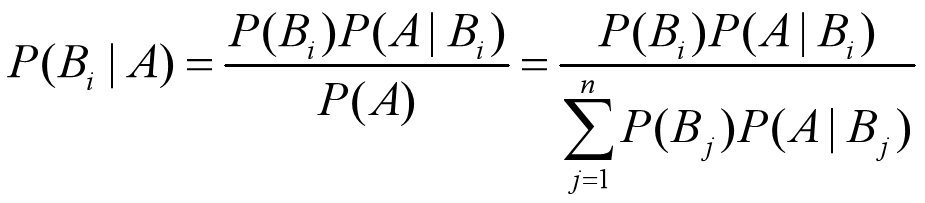
对于每个特征 x,想要知道样本在这个特性 x下属于哪个类别,即求后验概率 P(c|x) 最大的类标记。这样基于贝叶斯公式,可以得到:
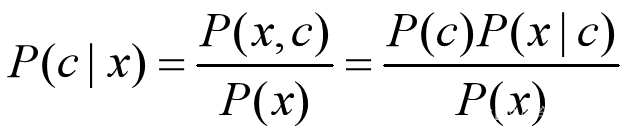
式中,c 代表类别,x 代表特征。
2. 基于贝叶斯决策理论的分类方法
贝叶斯决策理论:
p 1 ( x , y ) > p 2 ( x , y ) p_1(x,y)>p_2(x,y) p1(x,y)>p2(x,y),类别为1
p 2 ( x , y ) > p 1 ( x , y ) p_2(x,y)>p_1(x,y) p2(x,y)>p1(x,y),类别为2
选择概率高的决策。
-
模型适用:
- 优点:在数据较少的情况下仍然有效,可以处理多类别问题
- 缺点:对于输入数据的准备方式较为敏感
- 适用数据类型:标称型数据(分类数据)
-
计算公式:
p ( c i ∣ x , y ) > p ( x , y ∣ c i ) p ( c i ) p ( x , y ) p(c_i | x,y)>\frac{p(x,y|c_i)p(c_i)}{p(x,y)} p(ci∣x,y)>p(x,y)p(x,y∣ci)p(ci)

二、实验内容
1. 使用朴素贝叶斯进行文档分类
朴素贝叶斯假设特征之间相互独立。机器学习的一个重要应用就是文档的自动分类。我们可以观察文档中出现的词,并把每个词的出现或者不出现作为一个特征。
- 朴素贝叶斯的一般过程:
- 收集数据:RSS源
- 准备数据
- 分析数据:当有大量特征时,使用直方图绘制特征效果更好
- 训练算法:计算不同的独立特征的条件概率
- 测试算法:计算错误率
- 使用算法:应用于文档分类。
2. 使用scikit-learn库进行
from sklearn.feature_extraction.text import CountVectorizer from sklearn.model_selection import train_test_split from sklearn.naive_bayes import MultinomialNB from sklearn import metrics corpus=pd.read_csv('朴素贝叶斯数据.csv') labels=pd.read_csv('朴素贝叶斯label.csv') # 将文本数据转换为词袋模型的表示 vectorizer = CountVectorizer() X = vectorizer.fit_transform(corpus) # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, labels, test_size=0.25, random_state=42) # 使用MultinomialNB进行训练 clf = MultinomialNB() clf.fit(X_train, y_train) # 在测试集上进行预测 y_pred = clf.predict(X_test) # 输出分类报告 print("Classification Report:\n", metrics.classification_report(y_test, y_pred))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
3. 使用Python进行从零实现贝叶斯文本分类
词表到向量的转换函数
loadDataSet()创建了一些实验样本
createVocabList()创建了一个包含在所有文档中出现的不重复词的列表,利用set()函数去重
setOfWords2Vec()函数输出文档向量,向量的每一元素为1或0,表示词汇表中的单词是否出现在文档中。
import numpy as np def loadDataSet(): postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0, 1, 0, 1, 0, 1] #1 is abusive, 0 not return postingList, classVec def createVocabList(dataSet): vocabSet = set([]) #create empty set for document in dataSet: vocabSet = vocabSet | set(document) #union of the two sets return list(vocabSet) def setOfWords2Vec(vocabList, inputSet): returnVec = [0]*len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1 else: print("the word: %s is not in my Vocabulary!" % word) return returnVec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
-
训练算法:从词向量计算概率
- 伪代码:
计算每个类别中的文档数目
对每篇训练文档:
对每个类别:
如果词条出现在文档中–>增加该词条的计算值
增加所有词条的计算值
对每个类别:
对每个词条:
将该词条的数目除以总词条数目得到条件概率
返回每个类别的条件概率
- 朴素贝叶斯分类器训练函数
def trainNB0(trainMatrix, trainCategory): numTrainDocs = len(trainMatrix) numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory)/float(numTrainDocs) p0Num = np.ones(numWords); p1Num = np.ones(numWords) #change to np.ones() p0Denom = 2.0; p1Denom = 2.0 #change to 2.0 for i in range(numTrainDocs): if trainCategory[i] == 1: p1Num += trainMatrix[i] p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = np.log(p1Num/p1Denom) #change to np.log() p0Vect = np.log(p0Num/p0Denom) #change to np.log() return p0Vect, p1Vect, pAbusive
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
if else ,二分类问题,所以直接用了else,相当于 1 − p ( 0 ) 1-p(0) 1−p(0)
利用贝叶斯分类器对文档分类时,要计算多个概率的乘积,但如果 p ( w 0 ∣ 1 ) p ( w 1 ∣ 1 ) p ( w 2 ∣ 1 ) p{(w_0|1)}p(w_1|1)p(w_2|1) p(w0∣1)p(w1∣1)p(w2∣1)中有一个为0,那么最后的乘积也会为0,为降低这种影响,可以将数初始化1,将分母初始化2.
还有一个问题是下溢出:通过求对数可以避免这种情况。
上述代码已经很好的解决这些问题。

朴素贝叶斯分类函数
def classifyNB(vec2Classify, p0Vec, p1Vec, pClass1): p1 = sum(vec2Classify * p1Vec) + np.log(pClass1) #element-wise mult p0 = sum(vec2Classify * p0Vec) + np.log(1.0 - pClass1) if p1 > p0: return 1 else: return 0 def testingNB(): listOPosts, listClasses = loadDataSet() myVocabList = createVocabList(listOPosts) trainMat = [] for postinDoc in listOPosts: trainMat.append(setOfWords2Vec(myVocabList, postinDoc)) p0V, p1V, pAb = trainNB0(np.array(trainMat), np.array(listClasses)) testEntry = ['love', 'my', 'dalmation'] thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb)) testEntry = ['stupid', 'garbage'] thisDoc = np.array(setOfWords2Vec(myVocabList, testEntry)) print(testEntry, 'classified as: ', classifyNB(thisDoc, p0V, p1V, pAb))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
目前为止,我们将每个词的出现与否作为一个特征,这可以被描述为词集模型(set-of-words-model)。如果某个词在文档中出现不止一次,可能意味着包含该词是否出现在文档中所不能表达的某种信息,这种方法被称为词袋模型(bag-of-words-model)。
def bagOfWords2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] += 1
return returnVec
- 1
- 2
- 3
- 4
- 5
- 6
4. 示例:使用朴素贝叶斯过滤垃圾邮件
- 收集数据:提供文本文件
- 准备数据:将文本文件解析成词条向量
- 分析数据:检查词条确保解析的正确性
- 训练数据:使用trainNB0()函数
- 测试算法:使用classifyNB(),并且构建一个新的测试函数来计算错误率
- 使用算法:构建一个完整的程序对一组文档进行分类,输出错分的文档
- 使用string.split()函数,标点符号也会被切分
- 使用正则表达式,含有空字符串
- 句子的字母区分大小写,但训练时不区分,.lower()、.upper()
mysent="This book is the best book on Python or M.L I have ever laid eyes upon."
mysent.split()
import re
regEx = re.compile('\\W*')
listoftokens = regEx.split(mysent)
listoftokens
[tok for tok in listoftokens if len(tok) > 0]
[tok.lower() for tok in listoftokens if len(tok) > 0]
emailText = open('email/ham/6.txt').read()
listoftokens = regEx.split(emailText)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
第一个函数textParse()接受一个大写字符串并将其解析为字符串列表。该函数去掉了少于两个字符的字符串,并将所有字符转换为小写。
第二个函数spamTest()对贝叶斯垃圾邮件分类器进行自动化处理。其中采用了留存交叉验证进行训练。
输出在10封随机选择的电子邮件上的分类错误率,由于随机选择,每次的结构会有差别。如果想要更好的估计错误率,可将上述过程重复多次,然后求平均值。6%
def textParse(bigString): #input is big string, #output is word list import re listOfTokens = re.split(r'\W+', bigString) return [tok.lower() for tok in listOfTokens if len(tok) > 2] def spamTest(): docList = []; classList = []; fullText = [] for i in range(1, 26): wordList = textParse(open('email/spam/%d.txt' % i, encoding="ISO-8859-1").read()) docList.append(wordList) fullText.extend(wordList) classList.append(1) wordList = textParse(open('email/ham/%d.txt' % i, encoding="ISO-8859-1").read()) docList.append(wordList) fullText.extend(wordList) classList.append(0) vocabList = createVocabList(docList)#create vocabulary trainingSet = range(50); testSet = [] #create test set for i in range(10): randIndex = int(np.random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) del(list(trainingSet)[randIndex]) trainMat = []; trainClasses = [] for docIndex in trainingSet:#train the classifier (get probs) trainNB0 trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) errorCount = 0 for docIndex in testSet: #classify the remaining items wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: errorCount += 1 print("classification error", docList[docIndex]) print('the error rate is: ', float(errorCount)/len(testSet)) #return vocabList, fullText
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
the error rate is: 0.0 Q:运行多次后的错误率一直是0,随机数的作用似乎不行,或者是数据集太刚好了?
- 1
- 2
5. 示例:使用朴素贝叶斯分类器从个人广告中获取区域倾向
- 收集数据:从RSS源收集内容,这里需要对RSS源构建一个接口
- 准备数据:将文本文件解析成词条向量
- 分析数据:检查词条确保解析的正确性
- 训练数据:使用trainNB0()函数
- 测试算法:观察错误率,确保分类器可用。可以修改切分程序降低错误率。
- 使用算法:构建一个完整的程序封装所有内容,给定两个RSS源,该程序会显示最常用的公共词。
RSS源分类器及高频词去除函数
calcMostFreq()函数遍历词汇表中的每个词并统计它在文本中出现的次数,然后根据出现次数从高到低对词典进行排序,返回排序最高的30个单词。
localWords()函数使用两个RSS源作为参数,RSS源函数要在函数外导入,保证输入的一致性,RSS源会随着时间而改变。
def calcMostFreq(vocabList, fullText): import operator freqDict = {} for token in vocabList: freqDict[token] = fullText.count(token) sortedFreq = sorted(freqDict.items(), key=operator.itemgetter(1), reverse=True) return sortedFreq[:30] def localWords(feed1, feed0): import feedparser docList = []; classList = []; fullText = [] minLen = min(len(feed1['entries']), len(feed0['entries'])) for i in range(minLen): wordList = textParse(feed1['entries'][i]['summary']) docList.append(wordList) fullText.extend(wordList) classList.append(1) #NY is class 1 wordList = textParse(feed0['entries'][i]['summary']) docList.append(wordList) fullText.extend(wordList) classList.append(0) vocabList = createVocabList(docList)#create vocabulary top30Words = calcMostFreq(vocabList, fullText) #remove top 30 words for pairW in top30Words: if pairW[0] in vocabList: vocabList.remove(pairW[0]) trainingSet = range(2*minLen); testSet = [] #create test set for i in range(20): randIndex = int(np.random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) del(list(trainingSet)[randIndex]) trainMat = []; trainClasses = [] for docIndex in trainingSet:#train the classifier (get probs) trainNB0 trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V, p1V, pSpam = trainNB0(np.array(trainMat), np.array(trainClasses)) errorCount = 0 for docIndex in testSet: #classify the remaining items wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) if classifyNB(np.array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: errorCount += 1 print('the error rate is: ', float(errorCount)/len(testSet)) return vocabList, p0V, p1V ny = feedparser.parse("http://nasa.gov/rss/dyn/image_of_the_day.rss") sf = feedparser.parse("http://www.cppblog.com/kevinlynx/category/6337.html/rss") vocabList,pSF,pNY = localWords(ny, sf)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
Q:通过查看获取的信息,发现entries为空,猜测可能是这个网站停止更新或者清空了
Solve:使用替代的RSS源网页¶
http://nasa.gov/rss/dyn/image_of_the_day.rss
http://www.cppblog.com/kevinlynx/category/6337.html/rss
the error rate is: 0.5
- 1
-
多次运行后 发现错误率较高,猜测是因为用于移除高频词的代码要做调整,尝试通过调整函数caclMostFreq()改变要移除的单词数目
-
通过观察单词的分布统计结果,我发现高频词所占比例巨大,因此错误率较高的原因可能是移除了太多的高频词,我首先考虑将移除高频词的代码注释掉,观察结果
the error rate is: 0.05
- 1
说明进行调整后,结果有了较好的改善,错误率较低,分类效果较好。
先对向量pSF和pNY进行排序,然后按顺序将词打印出来。
最具表征性的词汇显示函数
getTopWords()使用两个RSS源作为输入,然后训练朴素贝叶斯分类器,返回使用的概率值。可以设置概率大于一定阈值的所有词。
def getTopWords(ny, sf):
import operator
vocabList, p0V, p1V = localWords(ny, sf)
topNY = []; topSF = []
for i in range(len(p0V)):
if p0V[i] > -6.0: topSF.append((vocabList[i], p0V[i]))
if p1V[i] > -6.0: topNY.append((vocabList[i], p1V[i]))
sortedSF = sorted(topSF, key=lambda pair: pair[1], reverse=True)
print("SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**SF**")
for item in sortedSF:
print(item[0])
sortedNY = sorted(topNY, key=lambda pair: pair[1], reverse=True)
print("NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**NY**")
for item in sortedNY:
print(item[0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
import nltk
nltk.download('stopwords')
- 1
- 2
[nltk_data] Error loading stopwords: <urlopen error [WinError 10060]
[nltk_data] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
False
import nltk
import ssl
try:
_create_unverified_https_context = ssl._create_unverified_context
except AttributeError:
pass
else:
ssl._create_default_https_context = _create_unverified_https_context
nltk.download('stopwords')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[nltk_data] Error loading stopwords: <urlopen error [WinError 10060]
[nltk_data] 由于连接方在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。
False
在下载停用词表的过程中,出现了一些问题,可能需要手动下载文件进行保存后调用,由于下载速度较慢,在本次验证实验中暂时没有继续进行验证。
参考文献:
[1] 机器学习-周志华
[2] 机器学习实战(中文版)-Peter Harrington
转载请显示来源~~

