
- 1能当老板的AI大模型多智体框架MetaGPT自动完成项目_多智能体框架
- 2linux安装rabbitmq_宝塔安装rabbitmq
- 3搭建CFimagehost私人图床,实现公网远程访问的详细指南_cf远程访问
- 4leetcode——哈希表与哈希集合总结_leetcode什么时候hash
- 5非关系型数据库(缓存数据库)redis的性能管理
- 6VMware Workstation Pro创建虚拟机(基于Ubuntu系统)
- 7【您的免费在线虚拟 Arduino 模拟器 - 2023】_arduino模拟器
- 8机器学习框架PyTorch详解和案列分析_pytorch机器学习
- 9设置中文环境_我花几年时间找到的学习中文好方法,值得你一看
- 10Hadoop 入门笔记—核心组件 HDFS_为什么部署hadoop组件需要耗费资源
多模态推荐系统最新进展总结
赞
踩
省时查报告-专业、及时、全面的行研报告库
省时查方案-专业、及时、全面的营销策划方案库
【免费下载】2023年1月份热门报告合集
ChatGPT团队背景研究报告
ChatGPT的发展历程、原理、技术架构及未来方向
ChatGPT使用总结:150个ChatGPT提示此模板
ChatGPT数据集之谜
《ChatGPT:真格基金分享.pdf》
2023年AIGC发展趋势报告:人工智能的下一时代
作者:西安交通大学,香港城市大学 刘启东
TLDR:今天跟大家分享一篇来自于香港城市大学、西安交通大学总结的多模态推荐系统综述,该文章总结了64篇多模态推荐系统相关的文献。具体的,该文根据统一的范式概括了多模态推荐的三个步骤,并从三个技术技术角度总结了现有的研究。另外,还总结了多模态推荐系统常用的数据集。作者希望通过总结的文章为该领域的学者与实践人员提供一个整体化的视角。

论文: https://arxiv.org/abs/2302.03883
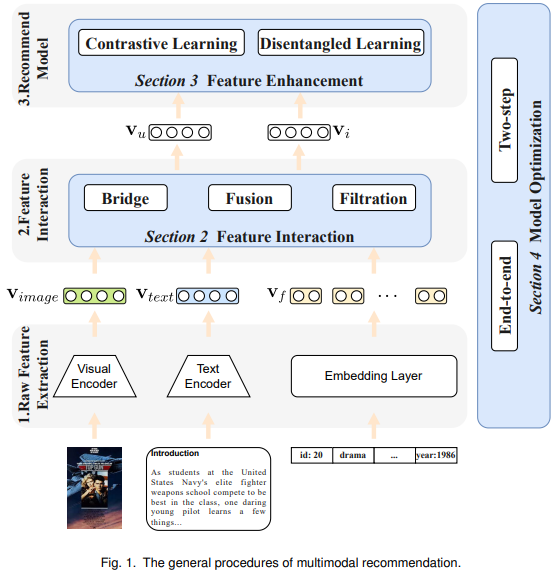
在本文所介绍的综述中,其对多模态推荐系统的一般流程进行了介绍:
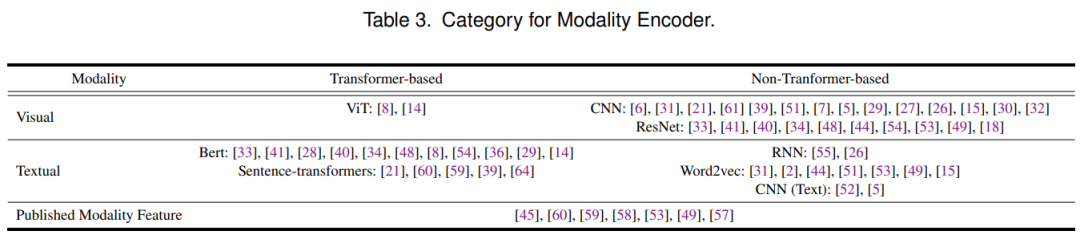
特征提取 :在多模态推荐中,每个待推荐物品包括两类特征。一类是表格特征,例如物品的id、类别等。另一类是多模态特征,包括物品的描述性图片、评价文本等。在这一阶段,多模态推荐系统使用模态encoder对多模态特征进行编码,如使用ViT对图片进行处理,使用Bert对文本进行处理。
特征交互 :特征提取得到的不同模态特征的表征向量通常在不同的语义空间中,且用户对于不同的模态有不同的偏好。因此,在这一阶段多模态推荐系统对多模态表征进行交互和融合,获取物品和用户的表征向量。
推荐 :在得到了用户和物品的表征向量后,可以利用推荐模型去计算推荐概率,从而输出推荐列表。
此外,该综述文章总结了多模态推荐系统的三大挑战:①如何融合不同语义空间下的模态表征并获得对每种模态的偏好;②如何在数据稀疏的情况下获得良好的表征;③如何同时优化参数量少的推荐模型和参数量大的模态编码器。
综述文章根据应对上述三大挑战的技术,将现有的多模态推荐研究划分为了三类:特征交互 、 特征增强 和 模型优化 。
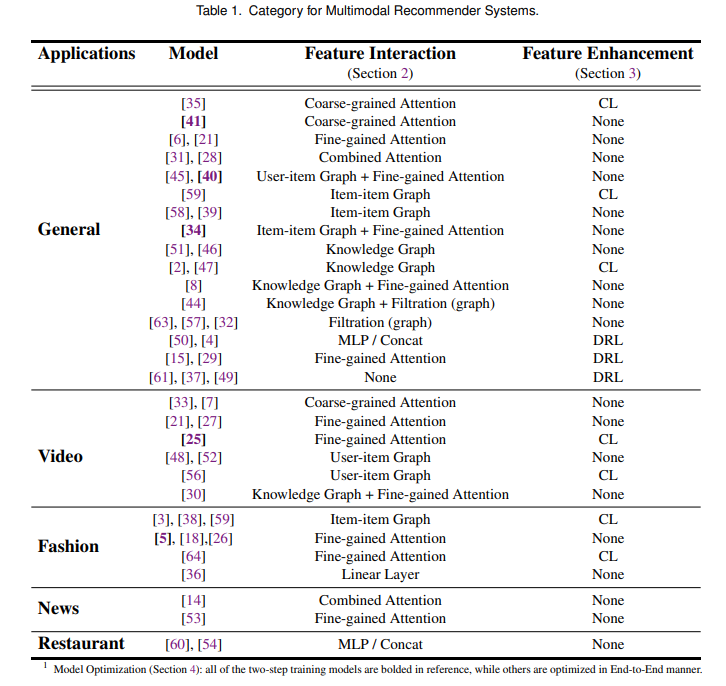
1 特征交互
多模态数据是指描述信息的各种模态。因为它们是稀疏的并且具有不同的语义空间,将它们连接到推荐任务是必不可少的。特征交互可以通过非线性转换实现将不同特征空间转换为统一的语义空间,最终提升推荐的性能和泛化能力。如图 2 所示,我们将特征交互分为三种类型:桥接 、 融合 和 过滤 。这三个多种类型的技术实现了来自不同视图的交互,因此它们可以同时应用于一个多模态推荐模型。
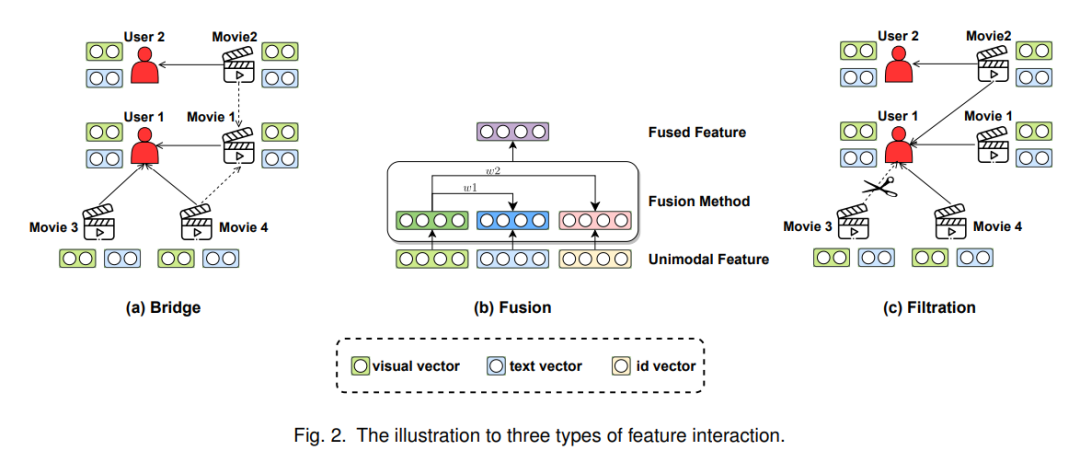
1.1 桥接
这里的桥接指的是多模态信息传递通道的构建。它专注于根据多模态信息来捕获用户和项目之间的交互关系。多模态推荐与传统推荐的区别在于物品中包含丰富的多媒体信息。早期的研究简单地使用多模态内容来增强物品表达,但他们往往忽略了用户与用户之间的关联关系。图神经网络可以通过消息传递机制来捕获用户和物品之间的交互关系,从而增强用户表征,并进一步捕获用户对不同模态信息的偏好。图 2(a)举个例子:许多研究通过聚合每个模态的交互项目来获得用户1的偏好。此外,电影1的模态表示可以从潜在的项目-项目图中获得。
1.2 融合
多模态推荐场景下,用户和物品的多模态信息类型和数量非常大。因此,有必要融合不同的多模态信息来生成特征向量从而服务推荐模型。与桥接相比,融合更关注物品内的多模态关系。具体来说,它旨在将各种偏好与模式结合起来。由于物品间和和物品内模态关系对于学习物品表征都至关重要,因此许多 MRS 模型甚至同时采用融合和桥接。注意力机制是应用最广泛的特征融合方法,可以灵活地将多模态信息根据关注度和兴趣结合起来。如图 2(b) 所示,首先按融合粒度划分注意力机制,然后介绍 MRS 中存在的其他一些融合方法。
1.3 过滤
由于多模态数据不同于用户交互数据,它包含许多与用户偏好无关的信息。如图 2(c) 所示,电影3和用户1之间的交互是误交互,应该被移除。过滤在多模态推荐任务中去除噪声数据,通常可以提高推荐性能。值得的注意的是交互图或多模态特征本身可能存在噪声,因此可以分别在桥接和融合中结合过滤的方法。
2 多模态特征增强
同一对象的不同模态表征具有独特和共同的语义信息。如果可以区分这两种特征,MRS的推荐性能和泛化能力可以显著提高。最近,为了解决这个问题,部分工作提出了Disentangled Representation Learning(DRL)和Contrastive Learning(CL)进行基于交互的特征增强,如图3所示。

2.1 解耦表征学习
不同模态的特征由于各种因素对不同的物品有不同程度的偏好。然而,每种模态中不同因素的表示往往是纠缠在一起的,因此许多研究人员引入了解耦学习技术来挖掘用户偏好中的细粒度因素,例如DICER、MacridVAE。此外,一些多模态推荐工作提出通过多模态数据挖掘各种隐藏因素,这些因素以复杂的方式高度纠缠在一起。
2.2 对比学习
与 DRL 不同,对比学习方法通过数据增强来增强表示,这也有助于处理稀疏性问题。MRS中的很多作品都引入了CL损失函数,主要是针对模态对齐和增强正负样本之间的深层特征信息。
3 模型优化
不同于传统的推荐任务,由于多模态信息的存在,当多模态编码器和推荐模型一起训练时,模型训练对计算量的要求会大大提高。因此,多模态推荐模型在训练时可以分为两类:End-to-end训练和两步训练。如图4(a)所示,End-to-end训练可以更新推荐模型的参数。两步训练包括第一阶段预训练编码器和面向任务的优化的第二阶段,如图 4(b) 所示。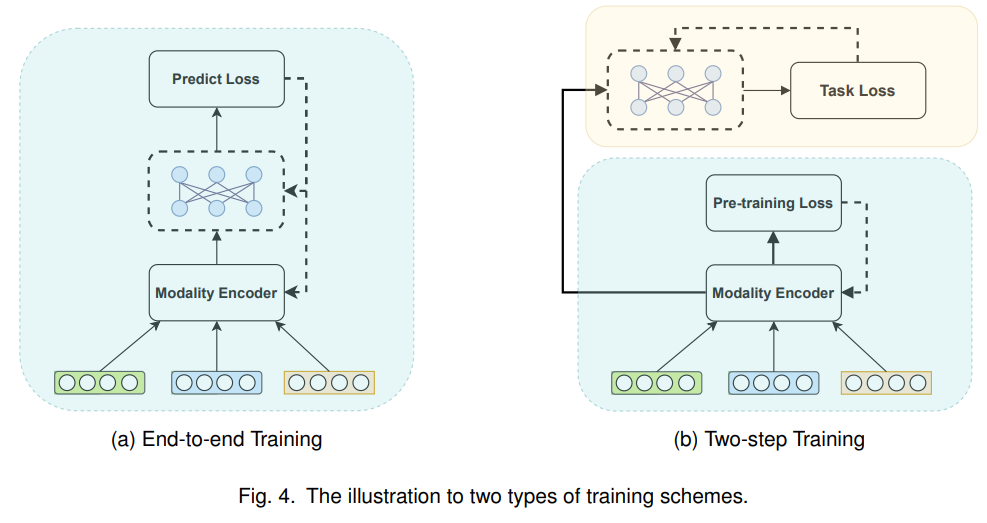
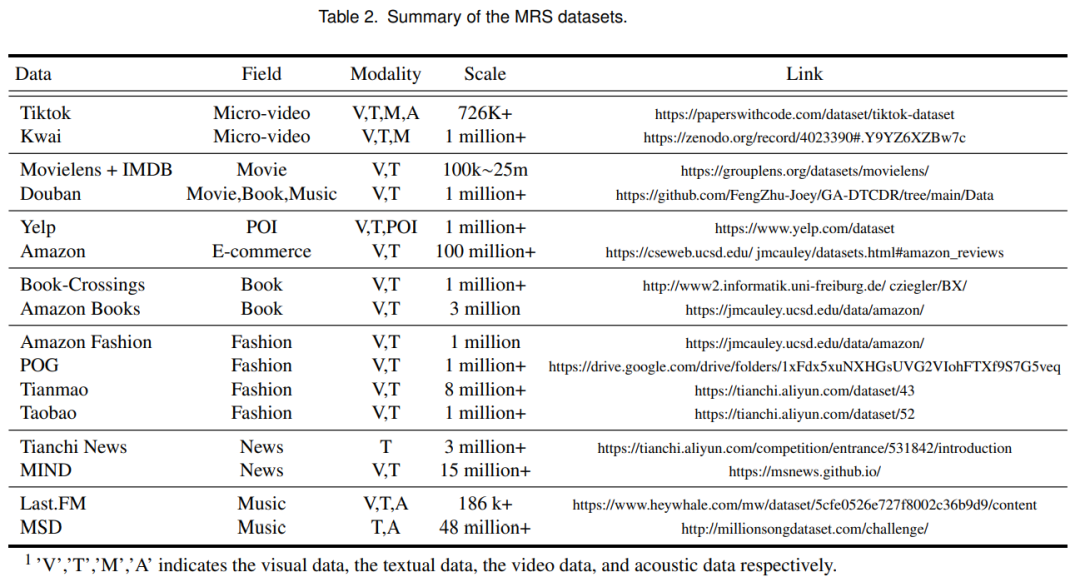
4 数据集与模态编码器
在本节中,我们列举了典型的 MRS 数据集,以方便研究人员使用。另外, 介绍了模态编码器来处理不同数据集中的各种模态特征。
5 挑战
最后,我们列出了几个研究的现有挑战:
通用解决方案 : 值得注意的是,虽然大部分工作就模型中一些阶段提出了方法,但没有提供这些技术组合的最新通用解决方案。
模型可解释性 :多模态模型的复杂性使其推荐难以解释,这会限制用户对系统的信任度和透明度。虽然少数工作提到了它,但它仍然需要探索。
计算复杂性 :MRS 需要大量数据和计算资源,这使得将它扩展到大型数据集和用户上具有挑战。多模态数据和模型的复杂性会增加计算量,从而增加推荐生成所需的成本和时间,使其对实时应用程序具有挑战性。
隐私 :虽然多模态信息可以通过减轻数据稀疏性使推荐系统受益,但它也增加了隐私泄露的风险。多模态信息丰富条件下如何保护个人隐私对研究人员来说也是一个很大的挑战。
一般的MRS数据集 :目前,MRS的数据集仍然有限,覆盖的模态不够广泛。此外,不同模式的数据质量和可用性可能会有所不同,这会影响准确性和推荐的可靠性。
更多细节请点击阅读原文精读原始论文。
更多干货请点击:
【免费下载】2023年1月份热门报告盘点
