
- 1Django框架_python django object
- 2长Ping网络丢包如何排查_ping丢包测试
- 3【Flutter】创建 Flutter 项目 ( Android Studio 创建并运行 Flutter 应用 | 命令行创建并运行 Flutter 应用 | 运行 Flutter 应用三种方式 )_androidstudio创建flutter
- 4tcp特性:可靠传输_tcp可靠传输
- 5SpringBoot操作Excel实现导入和导出功能(详细讲解+Gitee源码)_springboot导出excel
- 6文件包含漏洞(本地包含配合文件上传)_本地前台图片上传包含漏洞
- 7鸿蒙开发-ArkTS 语言(一)_arkts鸿蒙开发语言
- 8支持绘画-教你部署一个属于自己的chatgpt网站-收费版(源码)_gpt怎么搭建网站收费
- 9【工作准备】OpenHarmony鸿蒙操作系统开发——基础必备软件_鸿蒙开发模拟器哪个比较好
- 10STM32CubeMX(03)GPIO口输出+定时器实验实现交通灯
Elasticsearch实战(五):Springboot实现Elasticsearch电商平台日志埋点与搜索热词_elasticsearch项目实战
赞
踩
系列文章索引
Elasticsearch实战(一):Springboot实现Elasticsearch统一检索功能
Elasticsearch实战(二):Springboot实现Elasticsearch自动汉字、拼音补全,Springboot实现自动拼写纠错
Elasticsearch实战(三):Springboot实现Elasticsearch搜索推荐
Elasticsearch实战(四):Springboot实现Elasticsearch指标聚合与下钻分析
Elasticsearch实战(五):Springboot实现Elasticsearch电商平台日志埋点与搜索热词
一、提取热度搜索
1、热搜词分析流程图
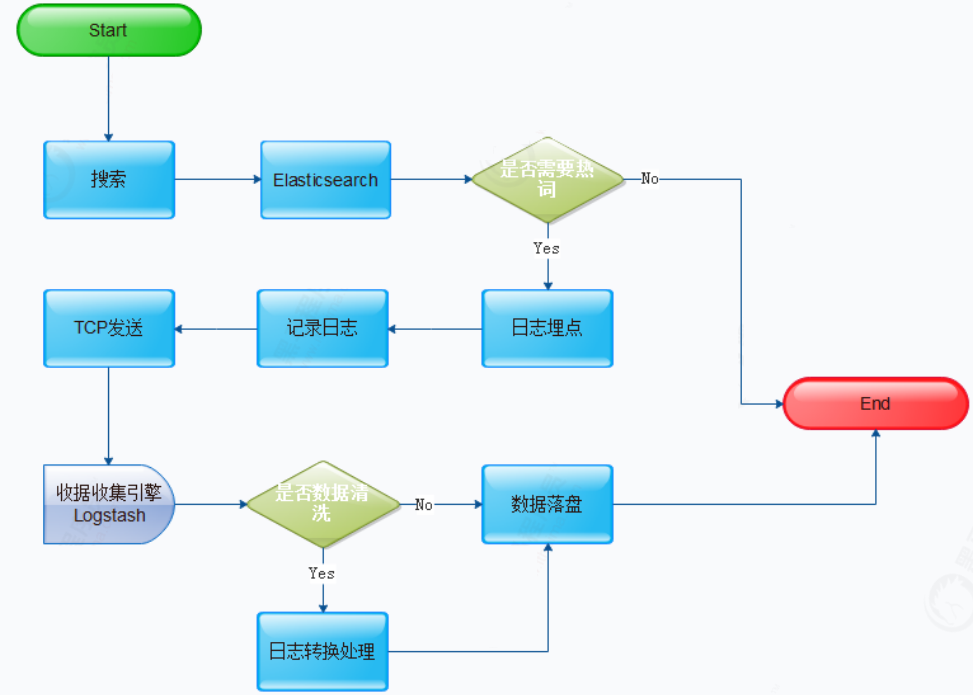
2、日志埋点
整合Log4j2
相比与其他的日志系统,log4j2丢数据这种情况少;disruptor技术,在多线程环境下,性能高于logback等10倍以上;利用jdk1.5并发的特性,减少了死锁的发生;
(1)排除logback的默认集成。
因为Spring Cloud 默认集成了logback, 所以首先要排除logback的集成,在pom.xml文件
<!--排除logback的默认集成 Spring Cloud 默认集成了logback-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-logging</artifactId>
</exclusion>
</exclusions>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(2)引入log4j2起步依赖
<!-- 引入log4j2起步依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-log4j2</artifactId>
</dependency>
<!-- log4j2依赖环形队列-->
<dependency>
<groupId>com.lmax</groupId>
<artifactId>disruptor</artifactId>
<version>3.4.2</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
(3)设置配置文件
如果自定义了文件名,需要在application.yml中配置
进入Nacos修改配置
logging:
config: classpath:log4j2-dev.xml
- 1
- 2
(4)配置文件模板
<Configuration>
<Appenders>
<Socket name="Socket" host="172.17.0.225" port="4567">
<JsonLayout compact="true" eventEol="true" />
</Socket>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Socket"/>
</Root>
</Loggers>
</Configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
从配置文件中可以看到,这里使用的是Socket Appender来将日志打印的信息发送到Logstash。
注意了,Socket的Appender必须要配置到下面的Logger才能将日志输出到Logstash里!
另外这里的host是部署了Logstash服务端的地址,并且端口号要和你在Logstash里配置的一致才行。
(5)日志埋点
private void getClientConditions(CommonEntity commonEntity, SearchSourceBuilder searchSourceBuilder) {
//循环前端的查询条件
for (Map.Entry<String, Object> m : commonEntity.getMap().entrySet()) {
if (StringUtils.isNotEmpty(m.getKey()) && m.getValue() != null) {
String key = m.getKey();
String value = String.valueOf(m.getValue());
//构造请求体中“query”:{}部分的内容 ,QueryBuilders静态工厂类,方便构造
queryBuilder
searchSourceBuilder.query(QueryBuilders.matchQuery(key, value));
logger.info("search for the keyword:" + value);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(6)创建索引
下面的索引存储用户输入的关键字,最终通过聚合的方式处理索引数据,最终将数据放到语料库
PUT es-log/ { "mappings": { "properties": { "@timestamp": { "type": "date" }, "host": { "type": "text" }, "searchkey": { "type": "keyword" }, "port": { "type": "long" }, "loggerName": { "type": "text" } } } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3、数据落盘(logstash)
(1)配置Logstash.conf
连接logstash方式有两种
(1) 一种是Socket连接
(2)另外一种是gelf连接
input { tcp { port => 4567 codec => json } } filter { #如果不包含search for the keyword则删除 if [message] =~ "^(?!.*?search for the keyword).*$" { drop {} } mutate{ #移除不需要的列 remove_field => ["threadPriority","endOfBatch","level","@version","threadId","tags","loggerFqcn","thread","instant"] #对原始数据按照:分组,取分组后的搜索关键字 split=>["message",":"] add_field => { "searchkey" => "%{[message][1]}" } #上面新增了searchkey新列,移除老的message列 remove_field => ["message"] } } # 输出部分 output { elasticsearch { # elasticsearch索引名 index => "es-log" # elasticsearch的ip和端口号 hosts => ["172.188.0.88:9200","172.188.0.89:9201","172.188.0.90:9202"] } stdout { codec => json_lines } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
重启Logstash,对外暴露4567端口:
docker run --name logstash -p 4567:4567 -v /usr/local/logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml -v /usr/local/logstash/config/conf.d/:/usr/share/logstash/pipeline/ -v /usr/local/logstash/config/jars/mysql-connector-java-5.1.48.jar:/usr/share/logstash/logstash-core/lib/jars/mysql-connector-java-5.1.48.jar --net czbkNetwork --ip 172.188.0.77 --privileged=true -d c2c1ac6b995b
- 1
- 2
(2)查询是否有数据
GET es-log/_search { "from": 0, "size": 200, "query": { "match_all": {} } } 返回: { "_index" : "es-log", "_type" : "_doc", "_id" : "s4sdPHEBfG2xXcKw2Qsg", "_score" : 1.0, "_source" : { "searchkey" : "华为全面屏", "port" : 51140, "@timestamp" : "2023-04-02T18:18:41.085Z", "host" : "192.168.23.1", "loggerName" : "com.service.impl.ElasticsearchDocumentServiceImpl" } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
(3)执行API全文检索
参数:
{
"pageNumber": 1,
"pageSize": 3,
"indexName": "product_list_info",
"highlight": "productname",
"map": {
"productname": "小米"
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
二、热度搜索OpenAPI
1、聚合
获取es-log索引中的文档数据并对其进行分组,统计热搜词出现的频率,根据频率获取有效数据。
2、DSL实现
field:查询的列,keyword类型
min_doc_count:热度大于1次的
order:热度排序
size:取出前几个
per_count:"自定义聚合名
POST es-log/_search?size=0 { "aggs": { "result": { "terms": { "field": "searchkey", "min_doc_count": 5, "size": 2, "order": { "_count": "desc" } } } } } 结果: { "took": 13, "timed_out": false, "_shards": { "total": 1, "successful": 1, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 40, "relation": "eq" }, "max_score": null, "hits": [] }, "aggregations": { "per_count": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 12, "buckets": [ { "key": "阿迪达斯外套", "doc_count": 14 }, { "key": "华为", "doc_count": 8 } ] } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
3、 OpenAPI查询参数设计
/* * @Description: 获取搜索热词 * @Method: hotwords * @Param: [commonEntity] * @Update: * @since: 1.0.0 * @Return: java.util.List<java.lang.String> * */ public Map<String, Long> hotwords(CommonEntity commonEntity) throws Exception { //定义返回数据 Map<String, Long> map = new LinkedHashMap<String, Long>(); //执行查询 SearchResponse result = getSearchResponse(commonEntity); //这里的自定义的分组别名(get里面)key当一个的时候为动态获取 Terms packageAgg = result.getAggregations().get(result.getAggregations().getAsMap().entrySet().iterator().next().getKey()); for (Terms.Bucket entry : packageAgg.getBuckets()) { if (entry.getKey() != null) { // key为分组的字段 String key = entry.getKey().toString(); // count为每组的条数 Long count = entry.getDocCount(); map.put(key, count); } } return map; } /* * @Description: 查询公共调用,参数模板化 * @Method: getSearchResponse * @Param: [commonEntity] * @Update: * @since: 1.0.0 * @Return: org.elasticsearch.action.search.SearchResponse * */ private SearchResponse getSearchResponse(CommonEntity commonEntity) throws Exception { //定义查询请求 SearchRequest searchRequest = new SearchRequest(); //指定去哪个索引查询 searchRequest.indices(commonEntity.getIndexName()); //构建资源查询构建器,主要用于拼接查询条件 SearchSourceBuilder sourceBuilder = new SearchSourceBuilder(); //将前端的dsl查询转化为XContentParser XContentParser parser = SearchTools.getXContentParser(commonEntity); //将parser解析成功查询API sourceBuilder.parseXContent(parser); //将sourceBuilder赋给searchRequest searchRequest.source(sourceBuilder); //执行查询 SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT); return response; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
调用hotwords方法参数:
{ "indexName": "es-log", "map": { "aggs": { "per_count": { "terms": { "field": "searchkey", "min_doc_count": 5, "size": 2, "order": { "_count": "desc" } } } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
field表示需要查找的列
min_doc_count:热搜词在文档中出现的次数
size表示本次取出多少数据
order表示排序(升序or降序)


