
- 1matlab曲线拟合_matlab拟合曲线并得到方程
- 2基于深度学习大模型实现离线翻译模型私有化部署使用,通过docker打包开源翻译模型,可到内网或者无网络环境下运行使用,可以使用一千多个翻译模型语言模型进行翻译_离线翻译大模型
- 3图像情感识别
- 4华为OD机试 - 模拟数据序列化传输(Java & JS & Python & C & C++)_python实现模拟一套简化的序列化传输方式,请实现下面的数据编码与解码过程 编码前
- 5五子棋简单AI算法(C#版)_五子棋ai
- 6大数据学习第十二天(hadoop概念)
- 7【项目实战】常见的HTTP状态码(401 - Unauthorized)_401 unauthorized
- 8人工智能:神经细胞模型到神经网络模型_mp模型中的mp什么意思
- 9CAD2018下载AutoCAD2018下载安装教程附软件下载
- 10python怎么在数据集中加入新_Python学习笔记 - day11 - Python操作数据库
OpenCV4 快速入门 (学习笔记 全)_opencv4快速入门pdf
赞
踩
第1章 基础知识
1.1 基础结构介绍
作者博客https://blog.csdn.net/shuiyixin?type=blog
https://blog.csdn.net/shuiyixin/article/details/106046827
1.1.1 Mat类
https://blog.csdn.net/shuiyixin/article/details/106014341
Mat src, src_roi;
src = imread("./image/cat.jpg");
if (!src.data)
{
cout << "ERROR : could not load image.\n";
waitKey(0);
return -1;
}
imshow("input image", src);
src_roi = Mat(src, Rect(100, 100, 300, 200));//很常用的构建mat类型的方法
imshow("roi image", src_roi);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

1.1.2 Rect_结构
https://blog.csdn.net/shuiyixin/article/details/106085233
1.1.3 Scalar_结构
Scalar其实是一个从Vec派生得到的四元向量的模板类
Scalar_(_Tp v0, _Tp v1, _Tp v2=0, _Tp v3=0);
Scalar(0, 0, 255); // 红色
Scalar(0, 255, 0); // 绿色
Scalar(255, 0, 0); // 蓝色
- 1
- 2
- 3
- 4
- 5
- 6
- 7
一般情况,我们只赋值前三个,第一个参数表示蓝色,第二个参数表示绿色,第三个参数表示红色,也就是BGR:
https://blog.csdn.net/shuiyixin/article/details/106111460
1.1.4 RNG类
https://blog.csdn.net/weixin_43588171/article/details/104810295
1.2 基础函数
1.2.1 saturate_cast()
https://blog.csdn.net/qq_27278957/article/details/88648737
在opencv中,saturate_cast的作用是防止数据溢出,作出保护。原理可理解为如下代码功能:
if(data < 0)
data = 0;
else if(data > 255)
data = 255;
- 1
- 2
- 3
- 4
1.2.2 reshape()
C++: Mat Mat::reshape(int cn, int rows=0) const
- 1
cn: 表示通道数(channels), 如果设为0,则表示保持通道数不变,否则则变为设置的通道数。
rows: 表示矩阵行数。 如果设为0,则表示保持原有的行数不变,否则则变为设置的行数。
1.2.3 Create()
函数原型:
inline void Mat::create(int _rows, int _cols, int _type)
inline void Mat::create(Size _sz, int _type)
void Mat::create(int ndims, const int* sizes, int type)
函数功能:
1)如果需要,分配新的数组数据
2)创建一个图像矩阵的矩阵体
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.3 程序
1.3.1 退出程序
char key = (char)waitKey();
if (key == 27 || key == 'q' || key == 'Q')
{
break;
}
- 1
- 2
- 3
- 4
- 5
第2章 数据载入、显示和保存
2.1 图像存储容器
数字图像在计算机中是以矩阵形式存储的,矩阵中的每一个元素都描述一定的图像信息,如亮度、颜色等
OpenCV利用Mat 类用于存储数据,利用自动内存管理技术很好地解决了内存自动释放的问题,当变量不再需要时, 立即释放内存.
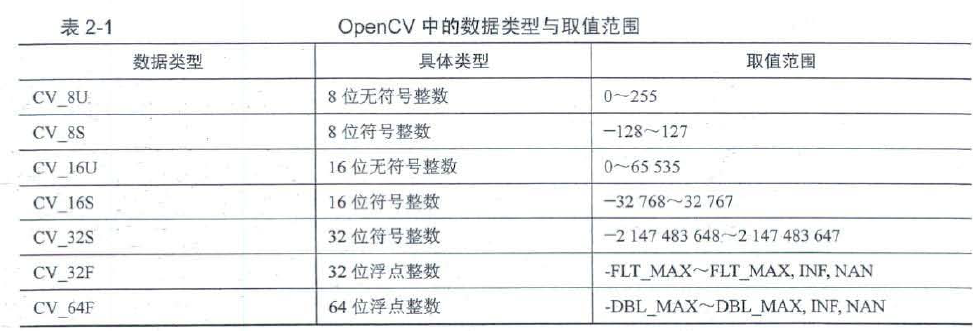

CV_8U是 unsign 的8位/像素-即一个像素的值在0-255区间,这是大多数图像和视频格式的正常范围。
CV_32F是 float -像素是在0-1.0之间的任意值,这对于一些数据集的计算很有用,但是它必须通过将每个像素乘以255来转换成8位来保存或显示。
2.1.2 Mat类构造与赋值
1.Mat类的构造
cv::Mat::Mat(3,3,CV_8S);//对应代码清单2-5
cv::Mat::Mat(cv::Size(3, 3), CV_8UC1);//对应代码清单2-6
cv::Mat A = cv::Mat_<double>(3, 3);
cv::Mat f = cv::Mat::Mat(3,3,CV_8S);
cv::Mat g = cv::Mat::Mat(cv::Size(3, 3), CV_8UC1);
cv::Mat h(cv::Size(3, 3), CV_8UC1);
cv::Mat i = g;
cv::Mat j(g);//修改j会修改g的值
cv::Mat k(g, cv::Range(2, 5), cv::Range::all());//range表示下标索引,,从0开始,0是第一行,这个意思是表示为下标为2的第3行到下标为5的第6行前(不包括下标为5的第6行)
cv::Mat k(g, cv::Range(2, 5), cv::Range::all());//修改k会修改g的值
cv::Mat::Mat(g, cv::Range(2, 5), cv::Range::all());//修改xx会修改g的值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
2.Mat类的赋值
cv::Mat g = cv::Mat::Mat(cv::Size(3, 3), CV_8UC1, cv::Scalar(255)); cv::Mat g = (cv::Mat_<int>(3, 3) << 1, 2, 3, 4, 5, 6, 7, 8, 9); cv::Mat c = cv::Mat_<int>(3, 3); for (int i = 0; i < c.rows; i++) { for (int j = 0; j < c.cols; j++) { c.at<int>(i, j) = i + j;//与cv::Mat_<int>(3, 3);的int必须一致 } } //生成单位矩阵 cv::Mat a(cv::Mat::eye(3, 3, CV_8UC1)); //生成特定对角矩阵 cv::Mat b = (cv::Mat_<int>(1, 3) << 1, 2, 3); cv::Mat c = cv::Mat::diag(b); //生成1矩阵、零矩阵 cv::Mat d = cv::Mat::ones(3, 3, CV_8UC1); cv::Mat e = cv::Mat::zeros(3, 3, CV_8UC3); //矩阵运算 cv::Mat a = (cv::Mat_<int>(3, 3) << 1, 2, 3, 4, 5, 6, 7, 8, 9); cv::Mat b = (cv::Mat_<int>(3, 3) << 1, 2, 3, 4, 5, 6, 7, 8, 9); cv::Mat c = (cv::Mat_<double>(3, 3) << 1.0, 2.1, 3.2, 4.0, 5.1, 6.2, 2, 2, 2); cv::Mat d = (cv::Mat_<double>(3, 3) << 1.0, 2.1, 3.2, 4.0, 5.1, 6.2, 2, 2, 2); cv::Mat e, f, g, h, i; e = a + b;//四则运算超了最大值按照最大值算 f = c - d; g = 2 * a; h = d / 2.0; i = a - 1; cv::Mat j, m;/*Mat 类中的数据类型必须是CV_32FC I 、CV_64FCI 、CV _32FC2 , CV 64FC2 这4 种中的一种,也就是对于一个二维的Mat 类矩阵, 其保存的数据类型必、须是float类型或者 double 类型*/ double k; j = c * d; k = a.dot(b);//相当于向量运算中的点成,也叫向量的内积、数量积 //Mat矩阵的dot方法扩展了一维向量的点乘操作,把整个Mat矩阵扩展成一个行(列)向量,之后执行向量的点乘运算,仍然要求参与dot运算的两个Mat矩阵的行列数完全一致。 //dot操作不对参与运算的矩阵A、B的数据类型做要求 //若参与dot运算的两个Mat矩阵是多通道的,则计算结果是所有通道单独计算各自.dot之后,再累计的和,结果仍是一个double类型数据。 m = a.mul(b);//对应位相乘,放在原位 // 对数据类型没有要求,但A、B必须一致 // 产生的数据类型默认与A、B一致 /*在图像处理领域, 常用的数据类型是CV_8U ,其范围是0-255 ,当两个比较大的整数相乘时, 就会产生结果溢出的现象, 输出结果为255 ,因此,在使用mu1 0方法时, 需要防止出现数据溢出 的问题.*/

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49


2.1.4 Mat元素的读取
cv::Mat b(3, 4, CV_8UC3, cv::Scalar(0, 0, 1)); cv::Vec3b vc3 = b.at<cv::Vec3b>(0, 0);//cv::Vec3x对应三通道数据,cv::Vec2x对应二通道数据,cv::Vec4x对应四通道数据 int first = (int)vc3.val[0]; int second = (int)vc3.val[1]; int third = (int)vc3.val[2]; std::cout << first << " " << second << " " << third << "" << std::endl; for (int i = 0; i < b.rows; i++) { uchar* ptr = b.ptr<uchar>(i); for (int j = 0; j < b.cols*b.channels(); j++) { std::cout << (int)ptr[j] << " "; } std::cout << std::endl; } //当读取第2行数据中第3个数据时, 可以用b.ptr<uchar>(1)[2]的形式来直接访问. cv::MatIterator_<cv::Vec3b> it = b.begin<cv::Vec3b>();//mat是什么类型,就要用什么类型的iterator接受指针,不然会报错 cv::MatIterator_<cv::Vec3b> it_end = b.end<cv::Vec3b>(); for (int i = 0; it != it_end; it++) { std::cout << *it << " ";//可以直接输出vec3b类型的值,,,*it if ((++i % b.cols) == 0) { std::cout << std::endl; } } std::cout << (int)(*(b.data + b.step[0] * 1 + b.step[1] * 1 + 1)) << std::endl;//https://blog.csdn.net/baoxiao7872/article/details/80210021讲解了data和step的用法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
image.at<uchar>(i, j)
- 1
其中有一个要注意的地方是i对应的是点的y坐标,j对应的是点的x坐标,而不是我们习惯的(x,y)


2.2 图像的读取与显示
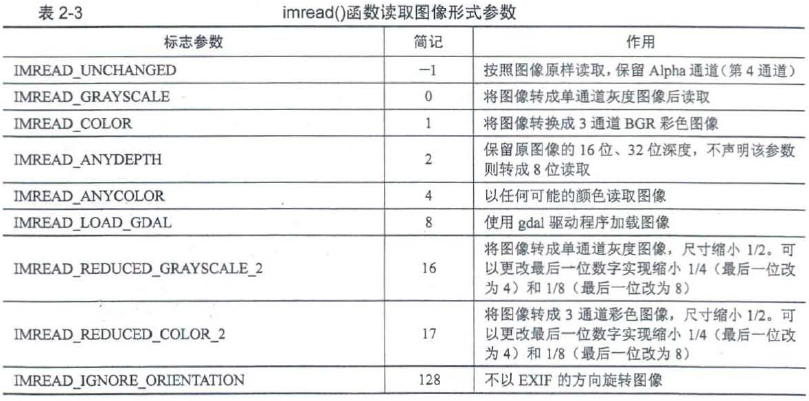
cv::Mat cv::imread(const string & filename, int flags = IMREAD_COLOR)//这些标志参数在功能不冲突的前提下可以同时声明多个,不同参数之间用" 1 " 隔开。
//在默认情况下,读取图像的像章数目必须小于2^30,可以通过修改革统变量中的OPENCV 10 MAX IMAGE: PIXELS 参数调整能够读取的最大像章数目.
//empty()函数是否为真来判断是否成功读取图像,如果读取图像失败,那么data 属性返回值为0. emptyO函数返回值为1
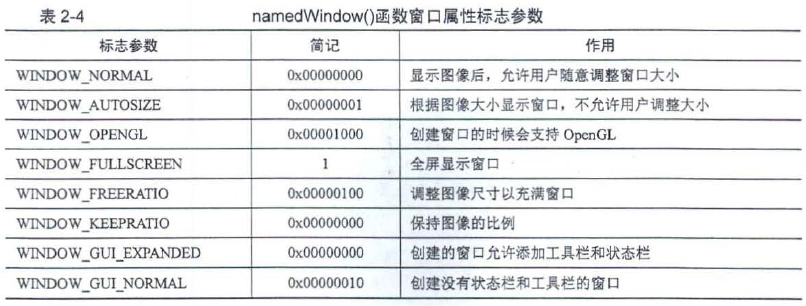
void cv::namedWindow(const String & winname, int flags = WINDOW_AUTOSIZE)//namedWindow()窗口函数属性标志餐数
void cv::imshow(const string & winname, InputArray mat)//如果后面程序执行完直接退出,那么显;示的图像有可能闪一下就消失,因此在需要显示图像的程序中,往往会在imshow()函数后跟有cv::waitKey()函数,用于将程序暂停一段时间.cv::waitKey()函数是以毫秒计的等待时长,如果参数默认或者为"0" ,那么表示等待用户按键结束该函数.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
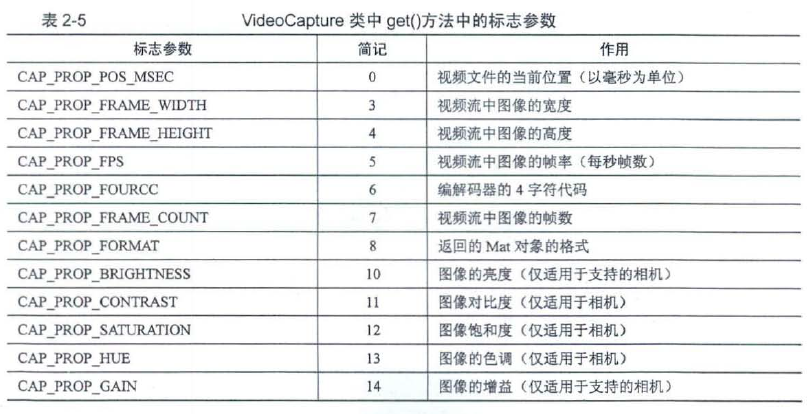
2.3 视频加载与摄像头调用
//这是打开视频
cv::VideoCapture::VideoCapture();
cv::VideoCapture::VideoCapture(const String & filename, int apiPreference = CAP_ANY);
//需要通过自Opened()函数进行判断.如果读取成功, 则返回值为true; 如果读取失败,则返回值为false .
//这事调用摄像头
cv::VideoCapture::VideoCapture(int index, int apiPreference = CAP_ANY);//摄像头号从0开始
- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.4 数据保存
bool cv::imwrite(const String & filename, InputArray img, const std::vector<int>& params = std::vectro<int>());
cv::VideoWriter::VideoWriter(const String & filename, int fourcc, double fps, Size frameSize, bool isColor=true);
cv::FileStroage::FileStorage();//需要用open()函数操作
cv::FileStroage::FileStorage(const String & filename, int flags, const String & encoding = String());
cv::FielStorage::open(const String & filename, int flags, const String & encoding = String());
cv::FielStorage::write(const String & name, int val);//存在多个重载,可以写多种类型的变量值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
#include <opencv2/opencv.hpp> #include <iostream> #include <string> using namespace std; using namespace cv; int main(int argc, char** argv) { system("color F0"); //修改运行程序背景和文字颜色 //string fileName = "datas.xml"; //文件的名称 string fileName = "datas.yaml"; //文件的名称 //以写入的模式打开文件 cv::FileStorage fwrite(fileName, cv::FileStorage::WRITE); //存入矩阵Mat类型的数据 Mat mat = Mat::eye(3, 3, CV_8U); fwrite.write("mat", mat); //使用write()函数写入数据 //存入浮点型数据,节点名称为x float x = 100; fwrite << "x" << x; //存入字符串型数据,节点名称为str String str = "Learn OpenCV 4"; fwrite << "str" << str; //存入数组,节点名称为number_array fwrite << "number_array" << "[" <<4<<5<<6<< "]"; //存入多node节点数据,主名称为multi_nodes fwrite << "multi_nodes" << "{" << "month" << 8 << "day" << 28 << "year" << 2019 << "time" << "[" << 0 << 1 << 2 << 3 << "]" << "}"; //关闭文件 fwrite.release(); //以读取的模式打开文件 cv::FileStorage fread(fileName, cv::FileStorage::READ); //判断是否成功打开文件 if (!fread.isOpened()) { cout << "打开文件失败,请确认文件名称是否正确!" << endl; return -1; } //读取文件中的数据 float xRead; fread["x"] >> xRead; //读取浮点型数据 cout << "x=" << xRead << endl; //读取字符串数据 string strRead; fread["str"] >> strRead; cout << "str=" << strRead << endl; //读取含多个数据的number_array节点 FileNode fileNode = fread["number_array"]; cout << "number_array=["; //循环遍历每个数据 for (FileNodeIterator i = fileNode.begin(); i != fileNode.end(); i++) { float a; *i >> a; cout << a<<" "; } cout << "]" << endl; //读取Mat类型数据 Mat matRead; fread["mat="] >> matRead; cout << "mat=" << mat << endl; //读取含有多个子节点的节点数据,不使用FileNode和迭代器进行读取 FileNode fileNode1 = fread["multi_nodes"]; int month = (int)fileNode1["month"]; int day = (int)fileNode1["day"]; int year = (int)fileNode1["year"]; cout << "multi_nodes:" << endl << " month=" << month << " day=" << day << " year=" << year; cout << " time=["; for (int i = 0; i < 4; i++) { int a = (int)fileNode1["time"][i]; cout << a << " "; } cout << "]" << endl; cout << " time=["; for (FileNodeIterator i = fileNode1["time"].begin(); i != fileNode1["time"].end(); i++) { float a; *i >> a; cout << a << " "; } cout << "]" << endl;//两种读取方法都行,一种使用迭代器,一种使用地址。 system("pause"); //关闭文件 fread.release(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
第3章 图像基本操作
3.1 图像颜色空间
3.1.1 颜色模型与转换——converTo()
RGB模型再OpenCV中是BGR的顺序。
RGB模型增加透明度就是RGBA模型
HSV、YUV、Lab、GRAY
void cv::Mat::convertTo(OutputArray m, int rtype, double alpha =1, double beta = 0);//rtype转换图像的数据类型,alpha转换过程中的缩放因子,beta转换过程中的偏置因子
- 1
alpha和beta两个餐数用于声明两个数据类型间的转换关系,形式如m(x,y)=saturate_cast(α(*this)(x,y)+β),该转换方式就是将原有数据进行线性转换
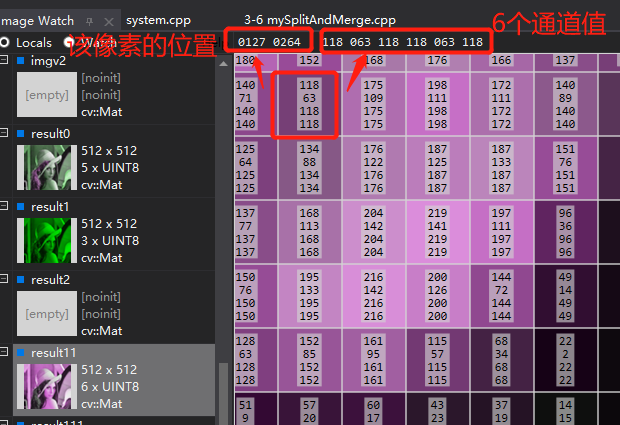
3.1.2 多通道分离与合并——split(), merge()
//多通道分离
void cv::split(const Mat & src, Mat * mvbegin);//需要定义mvbegin的长度
void cv::split(InputArray m, OutputArrayofArrays mv);//mv是vector形式,不需要提前定义数组长度
//多通道融合
void cv::merge(const Mat *mv, size_t count, OutputArray dst);//mv需要合并的图像数组,每个图像必须拥有相同的尺寸和数据类型.count输入的图像数组长度
void cv::merge(InputArrayofArrays mv, OutputArray dst);//mv需要合并的图像向量vector,每个图像必须拥有相同的尺寸和数据类型
//多通道融合可以超过4个通道,image watch上每个像素点内不显示4之后的通道值,但是上面会显示每个通道的值
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
下面这个图是把1个lena的img拆分了三个通道,分别放在一个mat[6]内,使用merge合并出来的6通道图片
3.2 图像像素操作处理
3.2.1 图像像素统计
1.寻找像素最大值与最小值——minMaxLoc()
void cv::minMaxLoc(InputArray src,
double * minVal,
double * maxVal = 0,
Point * minLoc = 0,
Point * maxLoc =0,
InputArray mask = noArray());//src输入的单通道矩阵
- 1
- 2
- 3
- 4
- 5
- 6
数据类型Point用于表示图像的像素坐标,
图像的像素坐标轴以左上角为坐标原点, 水平方向为x 轴, 垂直方向为y 轴
Point(x.y)对应于图像的行和列表示为Point (列数,行数)
在OpenCV 中对于二维坐标和三维坐标都设置了多种数据类型,针对二维坐标数据类型, 定义了整型坐标cv::Point2i (或者cv: :Point ) 、double 型坐标cv : :Point2d、浮点型坐标cv: :Point2f. 对于三维坐标,同样定义了上述的坐标数据类型,只需要将其中的数字" 2" 变成"3 气对于坐标中x、y、z 轴的具体数据, 可以通过变量的x、y、z 属性进行访问, 例如Point.x可以读取坐标的x 轴数据.
寻找多通道矩阵需要使用cv::Mat::reshape()将多通道变成单通道
cv::Mat MatA_reshape = MatA.reshape(int cn, int rows = 0)//cn指通道数,rows指转换后矩阵的行数,默认0与转换前相同
- 1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SPdtTvkr-1666660001256)(https://gitee.com/lyz-npu/typora-image/raw/master/img/%E5%9B%BE3-7.png)]
2.计算图像的平均值和标准差——mean, meanStdDev
图像的平均值表示图像整体的亮暗程度, 图像的平均值越大,则图像整体越亮。
标准差表示图像中明暗变化的对比程度, 标准差越大, 表示图像中明暗变化越明显。
//求平均值
cv::Scalar cv::mean(InputArray src, InputArray mask = noArray())//用scalar结构接收
//求平均值和标准差
void cv::meanStdDev(InputArray src, OutputArray mean, OutputArray stddev, InputArray mask = noArray())//用mat结构接收
- 1
- 2
- 3
- 4
3.2.2 图像间的像素操作
1.两幅图像的比较运算——max(), min()
void cv::max(InputArray src1,InputArray src2,OutputArray dst)
void cv::min(InputArray src1,InputArray src2,OutputArray dst)
- 1
- 2
这种比较运算主要用在对矩阵类型数据的处理上. 与掩模图像进行比较运算可以实现抠图或者选择通道的效果.
//对两张彩色图像进行比较运算 Mat img0 = imread("E:/graduate/learn/OpenCV/《OpenCV 4快速入门》数据集/data/lena.png"); Mat img1 = imread("E:/graduate/learn/OpenCV/《OpenCV 4快速入门》数据集/data/noobcv.jpg"); if (img0.empty() || img1.empty()) { cout << "请确认图像文件名称是否正确" << endl; return -1; } Mat comMin, comMax; max(img0, img1, comMax); min(img0, img1, comMin); imshow("comMin", comMin); imshow("comMax", comMax); //与掩模进行比较运算 Mat src1 = Mat::zeros(Size(512, 512), CV_8UC3);//生成一个512*512的0矩阵 Rect rect(100, 100, 300, 300);//创建一个坐标点(100,100)开始的300*300的矩形 src1(rect) = Scalar(255, 255, 255); //生成一个低通300*300的掩模,,,,把rect矩形叠加进src1矩阵中,rect中的值用scalar修改为255,255,255 Mat comsrc1, comsrc2; min(img0, src1, comsrc1); imshow("comsrc1", comsrc1); Mat src2 = Mat(512, 512, CV_8UC3, Scalar(0, 0, 255)); //生成一个显示红色通道的低通掩模 min(img0, src2, comsrc2); imshow("comsrc2", comsrc2);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UUdc5njU-1666660001256)(https://gitee.com/lyz-npu/typora-image/raw/master/img/%E5%9B%BE3-11.png)]
用黑框图片作为一个低通掩膜和lena图片求min(),就可以把外面的值剪掉。红色掩膜同理
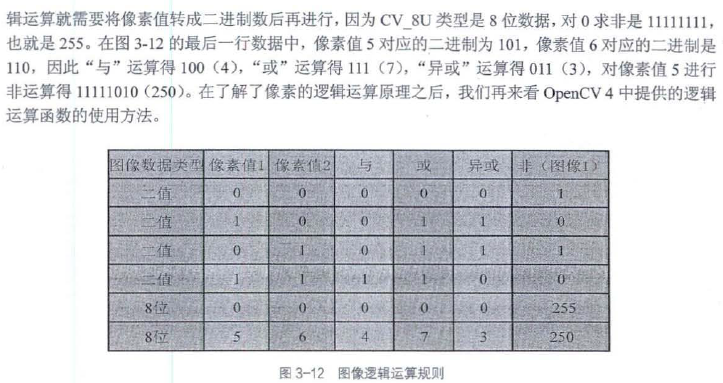
2.两幅图片的逻辑运算——bitwise_()
//逻辑与
void cv::bitwise_and(InputArray src1, Input Array src2, OutputArray dst, InputArray mask = noArray())
//逻辑与
void cv::bitwise_or(InputArray src1, Input Array src2, OutputArray dst, InputArray mask = noArray())
//逻辑异或
void cv::bitwise_xor(InputArray src1, Input Array src2, OutputArray dst, InputArray mask = noArray())
//逻辑非
void cv::bitwise_not(InputArray src, OutputArray dst, InputArray mask = noArray())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

3.2.3 图像二值化——threshold()
double cv::threshold(InputArray src,
OutputArray dst,
double thresh,
double maxval,
int type
)
//thresh二值化的阈值
//maxval二值化过程的最大值,只有THRESH_BINARY和THRESH_BINARY_INV两种二值化方法才使用,
//type二值化方法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

THRESH_OTSU和THRESH_TRIANGLE这两种标志是获取阈值的方法,并不是阈值比较方法的标志, 这两个标志可以与前面5 种标志一起使用, 例如" THRESH_BINARY | THRESH_OTSU" . 前面5 种标志在调用函数时都需要人为地设置阈值,如果对图像不了解,设置的阈值不合理, 就会对处理后的效果造成严重的影响.这两个标志分别表示利用大津法(OTSU)和三角形法(TRlANGLE)结合国像灰度值分布特性获取二值化的阈值,并将阈值以函数返回值的形式给出.因此,如果该函数最后一个参数设置了这两个标志中的任何一个,那么该函数第三个参数thresh将由系统自动给出,但是在调用函数时仍然不能默认,只是程序不会使用这个数值.需要注意的是,到目前为止. OpenCV 4 中针对这两个标志只支持输入CV_8UC1类型的图像.
大津法——最大类间方差法:https://blog.csdn.net/yxswhy/article/details/77838622?locationNum=10&fps=1
三角形法——适用于单峰直方图:https://blog.csdn.net/qq_45769063/article/details/107102117
由threshold()函数全局只使用一个阈值,在实际情况中, 由于光照不均匀以及阴影的存在, 全局只有一个阈值会使得在阴影处的白色区域也会被函数二值化成黑色, 因此adaptiveThreshold() 函数提供了两种局部自适应阈值的二值化方法,基本的思路就是以目标像素点为中心选择一个块,然后对块区域里面的像素点进行高斯或者均值计算,将得到的平均值或者高斯值作为目标像素点的阈值,以此来对目标像素格进行二值化。对图像每一个像素格进行如此操作就完成了对整个图像的二值化处理。
void cv::adaptiveThreshold(InputArray src,
OutputArray dst,
double maxValue,
int adaptiveMehtod,
int threshType,
int blockSize,
double C
)
//maxValue二值化的最大值
//adaptiveMethod自适应确定阈值的方法,均值法ADAPTIVE_THRESH_MEAN_C和高斯法ADAPTIVE_GAUSSIAN_MEAN_C两种.
//thresholdType选择图像二值化的方法,只能是THRESH_BINARY和THRESH_BINARY_INV两种二值化方法
//blockSize自适应确定阈值的像素邻域大小,一般为3,5,7的奇数
//从平均值或者加权平均值中减去的常数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
3.2.4 查找表——LUT()
查找表,Look-Up-Table
void cv::LUT(InputArray src,//只能输入CV_8U类型
InputArray lut,//256 个像素灰度值的查找表,单通道或者与src 通道数相同.
OutputArray dst//输出图像矩阵,尺寸与src 相同,数据类型与lut 相同.
)
- 1
- 2
- 3
- 4
函数输出图像的数据类型与LUT的数据类型保持一致,不与原图像保持一致。
如果第二个参数是单通道,则输入变量中的每个通道都按照一个LUT进行映射,如果第二个参数是多通道,则输入变量中的第i个通道按照第二个参数的第i个通道LUT进行映射.
3.4 图像变换
3.3.1 图像连接——cv::vconcat, cv::hconcat
void cv::vconcat(const Mat * src, size_t nsrc, OutputArray dst)//src是Mat矩阵类型的数组,nsrc数组中Mat类型数据的数目
void cv::vconcat(InputArray src1, InputArray src2, OutputArray dst)
- 1
- 2
vconcat是纵向连接**,两者需要具有相同的宽度、数据类型及通道数**
void cv::hconcat(const Mat * src, size_t nsrc, OutputArray dst)//src是Mat矩阵类型的数组,nsrc数组中Mat类型数据的数目
void cv::hconcat(InputArray src1, InputArray src2, OutputArray dst)
- 1
- 2
hconcat是纵向连接**,两者需要具有相同的高度、数据类型及通道数**

3.3.2 图像尺寸变换——resize()
void cv::resize(InputArray src,
OutputArray dst,
Size dsize, //输出图像的尺寸
double fx = 0,//水平轴的比例因子
double fy = 0,//垂直轴的比例因子
int interpolation = INTER_LINEAR//插值方法的标志
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
该函数的dsize 和fx ( fy ) 同时可以调整输出图像的参数,因此两类参数在实际使用时只需要使用一类,当根据两个参数计算出来的输出图像尺寸不一致时,以dsize 设置的图像尺寸为准.
dsize=Size(round(fx*src.cols), round(fy*src.rows))
缩小图像,通常使用INTER_AREA标志会有较好的效果
放大图像,采用INTER_CUBIC和INTER_LINEAR标志通常会有比较好的效果
| 标志参数 | 简记 | 作用 |
|---|---|---|
| INTER_NEAREAST | 0 | 最近邻插值法 |
| INTER_LINEAR | 1 | 双线性插值法 |
| INTER_CUBIC | 2 | 双三次插值 |
| INTER_AREA | 3 | 使用像素区域关系重新采样,首选用于图像缩小,图像放大时效果与INTER_NEAREST相似 |
| INTER_LANCZOS4 | 4 | Lanczos插值法 |
| INTER_LINEAR_EXACT | 5 | 位精确双线性插值法 |
| INTER_MAX | 7 | 用掩码进行插值 |
最邻近插值法、双线性插值:https://www.cnblogs.com/wanghui-garcia/p/11171954.html
双三次插值:https://blog.csdn.net/u013185349/article/details/84529982?
3.3.3 图像翻转——flip()
void cv::flip(InputArray src,
OutputArray dst,
int flipCode// >0,绕y轴翻转;
// =O,绕x轴翻转;
// <O,绕x,y轴翻转
)
- 1
- 2
- 3
- 4
- 5
- 6
3.3.4 图像仿射变换——getRotationMatrix2D(), warpAffine(), getAffineTransform()
OpenCV4 提供了getRotationMatrix2D()函数用于计算旋转矩阵, 提供了warpAffine()函数用于实现图像的仿射变换.
Mat cv::getRotationMatrix2D(Point2f center,
double angle,
double scale)//获取旋转矩阵
- 1
- 2
- 3
确定了旋转矩阵后,通过warpAffine()函数进行放射变换可以实现矩阵的旋转。
void cv::warpAffine(InputArray src,
OutputArray dst,
InputArray M, //2*3的变换矩阵
Size dsize, //输出图像的尺寸
int flags = INTER_LEANER, //插值方法
int borderMode = BORDER_CONSTANT, //像素边界外推方法的标志
const Scalar & borderValue = Scalar()//填充边界使用的数值, 默认情况下为0.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
相比于图像尺寸变换增加了两个插值方法,可以与其他插值方法一起用


仿射变换又称为三点变换
Mat cv::getAffineTransform(const Point2f src[], const Point2f dst[]);//利用3个对应点俩去欸的那个变换矩阵M
- 1

3.3.5 图像透视变换——getPerspectiveTransform(), warpPerspective()

透视变换又叫做四点变换。
Mat cv::getPerspectiveTransform(const Point2f src[], //四个像素坐标
const Point2f dst[]
int solveMethod = DECOMP_LU//计算透视变换矩阵方法的标志,默认选择最佳主轴元素的高斯消元法DECOMP_LU
);
- 1
- 2
- 3
- 4
void cv::warpPerspective(InputArray src,
OutputArray dst,
InputArray M, //
Size dsize, //输出图像的尺寸
int flags = INTER_LEANER, //插值方法
int borderMode = BORDER_CONSTANT, //像素边界外推方法的标志
const Scalar & borderValue = Scalar()//填充边界使用的数值, 默认情况下为0.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3.3.6 极坐标变换——warpPolar()
极坐标变换就是将图像在直角坐标系与极坐标系中互相变换,
void cv::warpPolar(InputArray src,
OutputArray dst,
Size dsize, //输出图像的尺寸
Point2f center,
double maxRadius,
int flags//插值方法与极坐标映射方法标志, 两个方法之间通过"+"或者'"|" 号连接.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.4 在图像上绘制几何图形
绘制圆形

绘制直线

绘制椭圆

绘制椭圆多边形

绘制多边形



3.5 感兴趣区域(ROI), 深拷贝与浅拷贝
Rect_(_Tp _x, _Tp _y, _Tp _width, _Tp _height)
cv::Range(int start, int end)
- 1
- 2
在img中截取图像
img(Rect(p.x, p.y, width, height))
img(Range(rows_start, rows_end), Range(cols_start,cols_end))
- 1
- 2
OpenCV中提到的图像截取以及通过=赋值,都是浅拷贝
深拷贝方式, OpenCV 4 通过**copyTo()**函数实现两类方法
void cv::Mat::copyTo(OutputArray m)const
void cv::Mat::copyTo(OutputArray m, InputArray mask)const//掩膜矩阵只能是CV_8U,尺寸相同,但是对通道数没有要求
//当掩模矩阵中某一位置不为0 时,表示复制原图像中相同位置的元素到新的图像中,
void cv::copyTo(InputArray src, OutputArray dst, InputArray mask)
- 1
- 2
- 3
- 4
3.6 图像金字塔
https://blog.csdn.net/zhu_hongji/article/details/81536820
图像"金字塔"的底部是待处理图像的高分辨率表示, 顶部是低分辨率的表示.
图像金字塔在特征检测中时基础理论和技术
高斯金字塔 ( Gaussian pyramid): 用来向下/降采样,主要的图像金字塔
拉普拉斯金字塔(Laplacian pyramid): 用来从金字塔低层图像重建上层未采样图像,在数字图像处理中也即是预测残差,可以对图像进行最大程度的还原,配合高斯金字塔一起使用。
这里的向下与向上采样,是对图像的尺寸而言的(和金字塔的方向相反),**向上就是图像尺寸加倍,向下就是图像尺寸减半。**而如果我们按上图中演示的金字塔方向来理解,金字塔向上图像其实在缩小,这样刚好是反过来了。
3.6.1 高斯“金字塔”——解决尺度不确定性
尺度:通俗理解,一格图像中包含的内容,,,缩小的 图像,一格中包含的信息多,是大尺度;一格中包含的信息少,是小尺度。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9V1hBRqL-1666660001260)(https://gitee.com/lyz-npu/typora-image/raw/master/img/%E5%9B%BE3-30.png)]
⑴对图像的向下取样
为了获取层级为 G_i+1 的金字塔图像,我们采用如下方法:
**<1>**对图像G_i进行高斯内核卷积
**<2>**将所有偶数行和列去除
每往上一层就会通过下来样缩小一次图像的尺寸, 通常情况下,尺寸会缩小为原来的一半
OpenCV 4 中提供了pyrDown() 函数专门用于图像的下来样计算
卷积:
https://www.cnblogs.com/geeksongs/p/11132692.html——讲的比较易懂
https://www.cnblogs.com/skyofbitbit/p/4471675.html——讲的比较仔细
//向下采样
void cv::pyrDown(InputArray src,
OutputArray dst,
const Size & dstsize = Size(),
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
高斯图像“金字塔”用到了卷积核

高斯分布https://blog.csdn.net/weixin_39124778/article/details/78411314
//向上采样
void cv::pyrUp(InputArray src,
OutputArray dst,
const Size & dstsize = Size(),
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
2.拉普拉斯金字塔
拉普拉斯金字塔是向上采样,重建上层未采样图像,在图像处理中预测残差。得到的图像比原来图像的尺寸大。向上采样如下:
(1)将图像在每个方向上扩大为原来的两倍,新增的行和列以0填充
(2)使用先前同样的内核(乘以4)与放大后的图像卷积,或得”新增像素”的近似值
乘4是因为用原来的一个像素高斯卷积核操作了新加的三个0像素,,,总共四个像素块,,用一个像素操作总共四个像素
3.7 窗口操作
3.7.1 窗口交互操作
int cv::createTracker(const String & trackbarname,//滑动条名
const String & winname,//滑动条窗口名
int * value,//指向整数变量的指针
int count,//最大值
TrackerbarCallback onChange = 0,//每次滑块位置更改时调用的函数指针,如果回调时NULL指针,不会调用任何回调,只跟新数值
void * userdata = 0//传给回调函数的可选参数
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
回调函数是什么
https://www.zhihu.com/question/19801131
3.7.2 鼠标响应
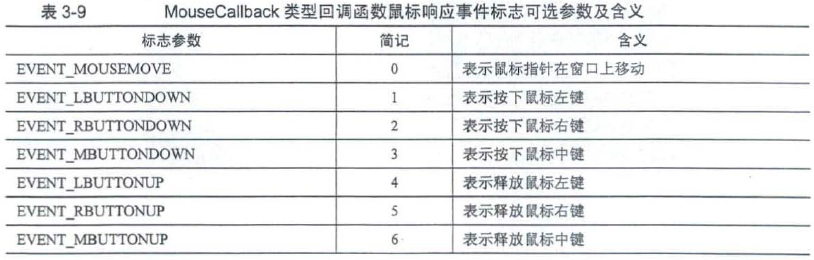
void cv::setMouseCallback(const String & winname,
MouseCallback onMouse,//鼠标响应的回调函数
void * userdata = 0
)
typedef void(* cv::MouseCallback)(int event,//鼠标响应事件标志,参数为EVENT*_
int x,
int y,
int flags,
void *userdata
)
if (event == EVENT_MOUSEMOVE && (flags & EVENT_FLAG_LBUTTON))
// 提取flags的CV_EVENT_FLAG_LBUTTON 标志位
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
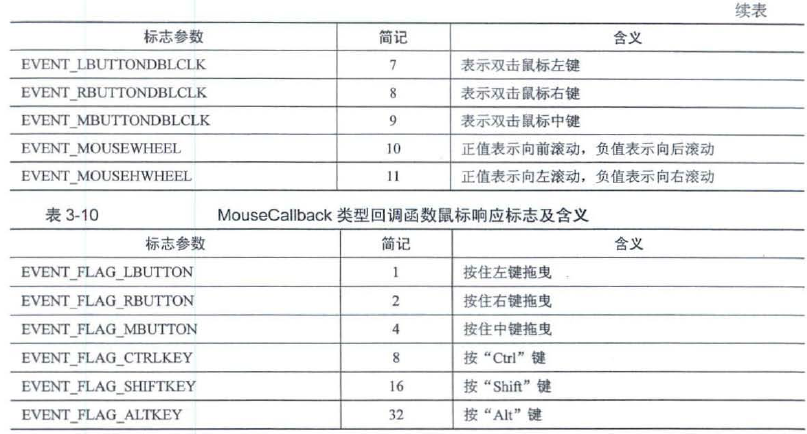
第4章 图像直方图与模板匹配
4.1 图像直方图的绘制(一维)
同一物体无论是旋转还是平移,在图像中都具有相同的灰度值,因此直方因具有平移不变性、放缩不变性等优点
图像直方阁就是统计图像中每个灰度值的个数,之后将图像灰度值作为横轴,以灰度值个数或者灰度值所占比率作为纵轴绘制的统计图.
void cv::calcHist(const Mat * images,//数组中所有的图像应具有相同的尺寸和数据类型,数据类型只能是CV_8U 、CV_16U和CV_32F这3种中的一种
int nimages,
const int * channels,
InputArray mask,
OutputArray hist,
int dims,//需要计算直方图的维度,必须是整数,并且不能大于CV_MAX_DIMS = 32
const int * histSize,
const float ** ranges,
bool uniform = true,
bool accumulate = false
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
calcHist可以生成二维直方图
https://www.bilibili.com/video/BV1i54y1m7tw?p=26
4.2 直方图操作
4.2.1 直方图归一化——normalize()
另一种常用的归一化方式是寻找统计结果中的最大数值,把所有结果除以这个最大的数值,以实现将所有数据归一化为0~1 .
如果不进行归一化,每一个灰度值下的像素数目统计会随着图像尺寸的变大而变化
void cv::normalize(InputArray src,
OutputArray dst,
double alpha = 1,//归一化下边界的标准值
double beta =0,//归一化的上线范围
int norm_type = NORM_L2,//归一化过程中数据范数种类标志
in dtype=-1,//输出数据类型选择标志,负数为输出数据与src拥有相同类型,否则与src拥有相同的通道数
InputArray mask = noArray()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
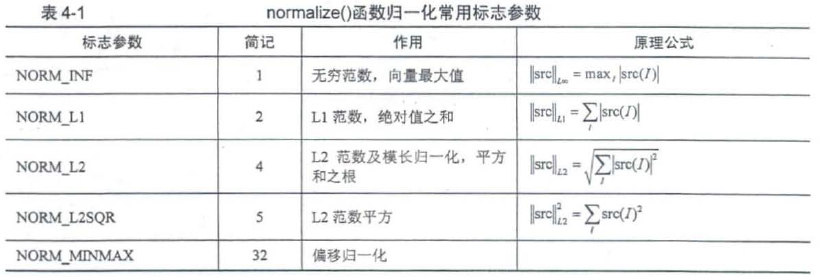
偏移归一化: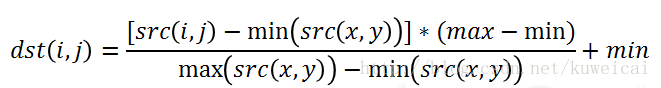
数组的数值被平移或缩放到一个指定的范围,线性归一化。
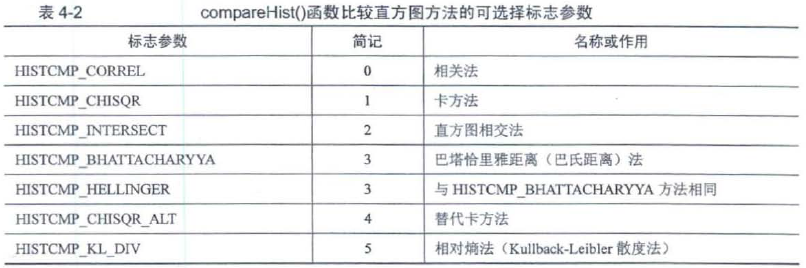
4.2.2 直方图比较——compareHist()
double cv::compareHist(InputArray H1,InputArray H2,int method)//method比较方法标志
- 1
通过不同的方法计算相关系数,代表的含义不同
4.3 直方图应用
4.3.1 直方图均衡化——equalizeHist()
通过映射关系,将图像中灰度值的范围扩大,增加原来两个灰度值之间的差值,就可以提高图像的对比度,进而将图像中的纹理突出显现出来,这个过程称为图像直方图均衡化.
对原图直方图进行均衡化之后,虽然不是很平坦,但是比原图直方图平坦(每个颜色出现的次数相等)的多;扩展了动态范围,以前很窄,现在把其拉开;对于对比度出现很暗或者很亮的地方,没有什么对比度或集中在一块;通过均衡化一下就能把图像给拉开;
https://blog.csdn.net/schwein_van/article/details/84336633直方图均衡化操作
用r的累积分布函数作为变换函数,可产生一幅灰度级分布均匀概率密度的图像
void cv::equalizeHist(InputArray src,OutputArray dst)//但是该函数不能指定均衡化后的直方图分布形式.
- 1

4.3.2 直方图匹配(直方图规定化)
将直方图映射成指定分布形式的算法
直方图匹配操作能够有目的地增强某个灰度区间, 相比于直方图均衡化操作, 该算法虽然多了一个输入, 但是变换后
的结呆也更灵活.
直方图规定化是在直方图均衡化的基础上完成的(从结果来看跳过了图像均衡化的过程)
https://blog.csdn.net/superjunenaruto/article/details/80037777
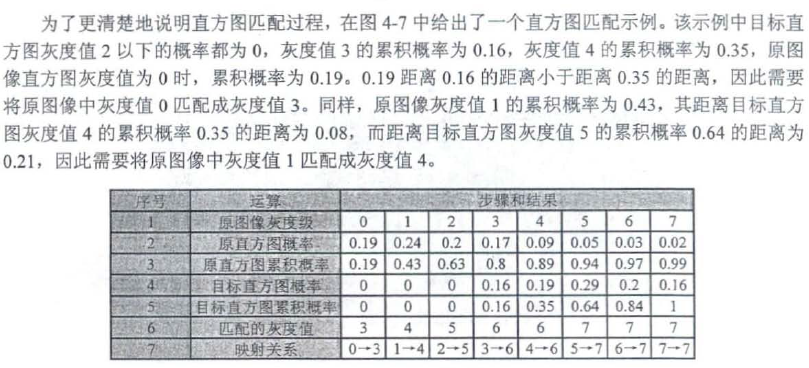
按照累积概率插值最小原则进行映射,,,,例如原直方图5像素0.94累积概率到目标直方图的6像素0.84的距离大于到目标直方图7像素1的距离,因此原直方图5像素映射到目标直方图7像素的位置。
4.3.3 直方图反向投影——calcBackProject()
void cv::calcBackProject(const Mat * images,
int nimages,
const int * channels,
InputArray hist,
OutputArray backProject,
const float ** ranges,
double scale =1,
bool uniform = true
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
void cv::applyColorMap(InputArray src, OutputArray dst, int COLORMAP_*);
- 1
4.3.4 限制对比度的自适应直方图均衡化——CLANE()
直方图与增强对比度 - 程序员阿德的文章 - 知乎 https://zhuanlan.zhihu.com/p/98541241
4.4 图像的模板匹配
void cv::matchTemplate(InputArray image,
OutputArray templ,
OutputArray result,
int method, //模板匹配方法
InputArray mask = noArray())
- 1
- 2
- 3
- 4
- 5
第5章 图像滤波
5.1 图像卷积
https://www.cnblogs.com/geeksongs/p/11132692.html
图像卷积操作常将卷积模板通过缩放使得所有数值的和为1.进而解决卷积后数值越界的情况发生,
void cv::filter2D(InputArray src,
OutputArray dst,
int ddepth, //输入如下表所示的类型,默认-1
InputArray kernel, //CV_32FC1类型的矩阵
Point anchor = Point(-1,-1),
double delta = 0,
int borderType = BORDER_DEFAULT)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

需要用不同的卷积模板对不同的通道进行卷积操作,就需要先使用split()函数将图像多个通道分离之后单独对每一个通道求取卷积运算
filter2D()函数不会将卷积模板进行旋转,如果卷积模板不对称,需要讲卷积模板旋转180°在输入给该函数
5.2 噪声的种类与生成
图像中常见的噪声主要有4种,分别是高斯噪声、椒盐噪声、泊松噪声和乘性噪声.
5.2.1 椒盐噪声
随机数函数原型
int cvflann::rand()
double cvflann::rand_double(double high = 1.0,double low = 0)
int cvflann::rand_int(int high = RAND_MAX, int low = 0)//rand_max系统中最大为32767
- 1
- 2
- 3
OpenCV中没有直接生成椒盐噪声的函数
椒盐噪声又称作脉冲噪声, 它会随机改变图像中的像素值,是由相机成像、图像传输、解码处理等过程产生的黑白相间的亮暗点噪声
5.2.2 高斯噪声
高斯噪声,顾名思义是指服从高斯分布(正态分布)的一类噪声,通常是因为不良照明和高温引起的传感器噪声。通常在RGB图像中,显现比较明显。
区别于椒盐噪声随机出现在图像中的任意位置,高斯噪声出现在图像中的所有位置.

void cv::RNG::fill(InputOutArray mat,
int distType, //目前生成的随机数支持均匀分布(RUNG::UNIFORM, 0)和高斯分布(RNG::NORMAL, 1).
InputArray a, //确定分布规律的参数。当选择均匀分布时, 该参数表示均匀分布的最小下限, 当选择高斯分布时, 该参数表示高斯分布的均值.
InputArray b, //确定分布规律的参数。当选择均匀分布时, 该参数表示均匀分布的最大下限, 当选择高斯分布时, 该参数表示高斯分布的标准差.
bool saturateRange = false)//预饱和标志,仅用于均匀分布.
- 1
- 2
- 3
- 4
- 5
OpenCV 4 的RNG类,是一个非静态成员函数
静态函数可以直接通过 类::函数 中方式调用,不用通过对象来调用函数,而非静态函数必须通过对象来调用,这里面还涉及到实例化对象时候的内存分配。
cv::RNG rng;
rng.fill(mat, RNG::NORMAL, 10, 20);
- 1
- 2
5.3 线性滤波
图像滤波是指去除图像中不重要的内容而使关心的内容表现得更加清晰的方法,例如去除图像中的噪声、提取某些信息等
将图像滤波分为消除图像噪声的滤波和提取图像中部分特征信息的滤波.
图像滤波使用的滤波器允许通过的信号频段,决定了滤波操作是去除噪声(低通、高阻:去除图像中的噪声)还是提取特征信息(高通:对图像边缘信息提取、增强和图像锐化的作用.).
在低通滤液中,模糊可以与滤波等价,例如图像高斯模糊和图像高斯低通滤波是个概念.
卷积操作中的卷积模板在图像滤波中称为滤波筷扳、滤波器或者邻域算子
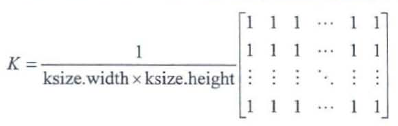
5.3.1 均值滤波——blur()
求所有数据的平均值
void cv::blur(InputArray src,
OutputArray dst,
Size ksize, //卷积核尺寸
Point anchor = Point(-1,-1),
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
5.3.2 方框滤波——boxFilter()
方框滤波可以选择不归一化,将所有像素值的和作为滤波结果,而不是所有像素值的平均值
boxFilter()默认进行归一化,不考虑数据类型的情况下,与blur()滤波结果相同。

void cv::boxFilter(InputArray src,
OutputArray dst,
int ddepth,
Size ksize,
Poitn anchor = Point(-1,-1),
bool normalize = true, //默认进行归一化
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
sqrBoxFiler()函数实现对滤波器内每个像数值的平方求和,多用来处理CV_32F类型的图像数据,归一化后,变模糊的同时亮度也会变暗
该函数的归一化一样是除kernel的元素数
void cv::sqrBoxFiler(InputArray src,
OutputArray dst,
int ddepth,
Size ksize,
Poitn anchor = Point(-1,-1),
bool normalize = true, //默认进行归一化
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
该函数的归一化一样是除kernel的元素数
5.3.3 高斯滤波——GaussianBlur()
高斯平滑也用于计算机视觉算法中的预先处理阶段,以增强图像在不同比例大小下的图像效果(参见尺度空间表示以及尺度空间实现)

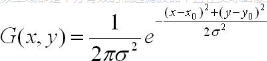
void cv::GaussianBlur(InputArray src, //任意的通道数目,但是数据类型必需为CV_8U、CV_16U、CV_16S、CV_32F或CV_64F .
OutputArray dst,
Size ksize,
double sigmaX,
double sigmaY = 0,
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
建议将该函数的第三个、第四个、第五个参数都明确地给出.
高斯滤汲器的尺寸和标准偏差存在着一定的互相转换关系.
Mat cv::getGaussianKernel(int ksize, double sigma, int ktype = CV_64F)
- 1
可以用该函数获取一个方向的高斯滤波器,然后两个方向的滤波器相乘得到一个k*k的二维滤波器
5.3.4 可分离滤波——sepFilter2D()
可分离性指的是先对x ( y ) 方向滤波, 再对y ( X ) 方向滤波的结果与将两个方向的滤波器联合后整体滤波的结果相同。两个方向的滤波器的联合就是将两个方向的滤波器相乘,

void cv::sepFilter2D(InputArray src,
OutputArray dst,
int ddepth,
InputArray kernelX,
InputArray kernelY,
Point anchor = Point(-1,-1),
double delta = 0,
int borderType = BORDER_DEFAULT)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
可以输入两个方向的滤波器,sepFilter2D不区分xy方向的滤波方向,但是filter2D需要区分

5.4 非线性滤波
常见的非线性滤波有中值滤液和双边滤波
5.4.1 中值滤波——medianBlur()
中值滤波不依赖于滤波器内那些与典型值差别很大的值, 因此对斑点噪声和椒盐噪声的处理具有较好的效果.
void cv::medianBlur(InputArray src, //可以是单通道、三逼迫和四通道(二通道和更多通道不行)
OutputArray dst,
int ksize)
- 1
- 2
- 3
5.4.2 双边滤波——bilateralFilter()
双边滤波对高频率的波动信号起到平滑的作用, 同时保留大幅值变化的信号波动, 进而实现对保留图像中边缘信息的作用.
滤波器对边缘附近的像素进行滤波时,距离边缘较远的像素值不会对边缘上的像索值影响太多,进而保留边缘的清晰性.
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-02ucXQ8J-1666660001265)(https://gitee.com/lyz-npu/typora-image/raw/master/img/%E5%9B%BE5-24.png)]
双边滤波采用了空间和灰度距离两个高斯滤波的结合
•空间距离指当前点与卷积核中心点的欧式距离,离中心点越近的点权重系数越大
•灰度距离指当前点灰度与中心点灰度的差的绝对值,颜色越接近的点权重系数越大
void cv::bilateralFilter(InputArrray src,
OutputArray dst,
int d,
double sigmaColor, //颜色空间滤被器的标准差值.这个参数越大,表明该像素领域内有越多的颜色被混合到一起, 产生较大的半相等颜色区域.
double sigmaSpace, //空间坐标中滤波器的标准差值.这个参数越大,表明越远的像素会相互影响,从而使更大领域中有足够相似的颜色获取相同的颜色.
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.5 图像的边缘检测
5.5.1 边缘检测原理

得到的正数值表示像素值突然由低变高,得到的负数值表示像素值由高到低,这两种都是图像的边缘,因此,为了在图像中同时表示出这两种边缘信息, 需要将计算的结果求绝对值.
void cv::convertScaleAbs(InputArrray src,
OutputArray dst,
double alpha = 1, //缩放因子,默认只求绝对值不缩放
double beta = 0//偏值
)
- 1
- 2
- 3
- 4
- 5
5.5.2 Sobel算子——Sobel()
https://blog.csdn.net/qq_32811489/article/details/90312421
Sobel算子还结合了高斯平滑滤波的思想,将滤波器尺寸由ksize x 1改进为ksize x ksize. 提高了对平缓区域边缘的响应,效果更好

是一种中心差分,对中间水平线和垂直线上赋予较高的权重

其中第一个式子是n等于2时展开式的高斯平滑算子,也就是二项式展开式的系数,第二个式子表示差分。
最后得到的结果就是3阶sobel边缘检测算子。
void cv::Sobel(InputArray src,
OutputArray dst,
int ddepth,
int dx, //x方向的差分阶数
int dy, //y方向的差分阶数
int ksize = 3, //sobel算子尺寸,,,任意一个方向的差分阶数都需要小子算子的尺寸
double scale = 1,
double delta = 0, //偏值
int borderType = BORDRE_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
5.5.3 Scharr算子——Scharr()

算子只有上面两种
void cv::Scharr(InputArray src,
OutputArray dst,
int dx,
int dy,
double scale = 1,
double delta = 0,
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.5.4 生成边缘检测滤波器——getDeriveKernels()
Scharr()和Sobel()函数就是通过调用getDeriveKernels()函数得到了他们使用的算子
void cv::getDeriveKernels(OutputArray kx,
OutputArray ky,
int dx,
int dy,
int ksize,
bool normalize = false,
int ktype = CV_32F
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.5.5 Laplacian算子——Laplacian()
Sobel算子和Scharr算子都需要提取x方向的边缘和y方向的边缘,然后将两个方向的边缘总和得到图像的整体边缘。
Laplacian算子具有个方向同性的特点



Laplacian算子对噪声具有无法接受的敏感性
void cv::Laplacian(InputArray src,
OutputArray dst,
int ddepth,
int ksize = 1,
double scale = 1,
double delta = 0,
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

5.5.6 Canny算子——Canny()
https://blog.csdn.net/likezhaobin/article/details/6892176
https://www.cnblogs.com/king-lps/p/8007134.html
该算法不容易受到噪声的影响,能够识别图像中的弱边缘和强边缘,并结合强弱边缘的位置关系, 综合给出图像整体的边缘信息.
void cv::Canny(InputArray image, //必须是三通道或者单通道图像
OutputArray edges,
double threshold1, //第一个滞后阈值
double threshold2, //第二个滞后阈值
int apertureSize = 3,//Sobel算子直径
int L2gradient = false
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.5.7 LOG算子

5.5.8 斑点检测
LOG斑点检测https://www.cnblogs.com/ronny/p/3895883.html
SimpleBlobDetector
- 1
第6章 图像形态学操作
6.1 像素距离与连通域
6.1.1 图像像素距离变换——distanceTransform()
图像形态学操作主要包括图像腐蚀、膨胀、开运算与闭运算
图像形态学在图像处理中具有广泛的应用, 主要应用于从图像中提取对于表达和描述区域形状有意义的图像分嚣, 以便后续的识别工作能够抓住对象最为本质的形状特性,例如边界、连通域等.
图像处理中常用的距离有欧氏距离、街区距离和棋盘距离



该函数用于实现图像的距离变换. 即统计图像中所有像素距离0像素的最小距离.
void cv::distanceTransform(InputArray src,
OutputArray dst,
OutputArrya labels, //输出一个voronoi图
int distanceType, //距离类型
int maskSize, //距离变换掩码矩阵尺寸,参数可以选择的尺寸DIST_MASK_3(3*3),DIST_MASK_5(5*5)
int labelType = DIST_LABEL_CCOMP
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
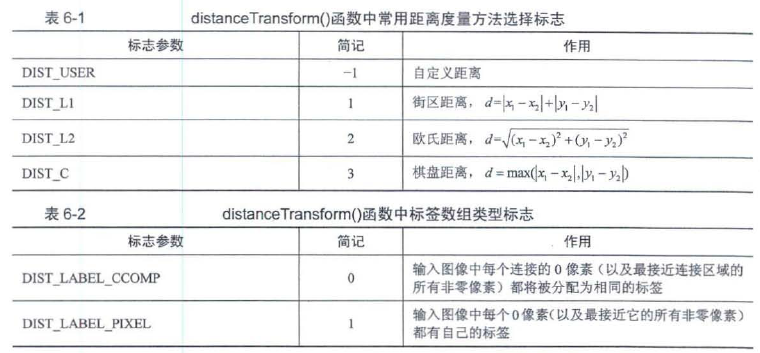
Voronoi图,又叫泰森多边形或Dirichlet图,它是由一组由连接两邻点直线的垂直平分线组成的连续多边形组成。

void distanceTransform(InputArray src,
OutputArray dst,
int distanceType,
int maskSize,
int dstType = CV_32F
)
- 1
- 2
- 3
- 4
- 5
- 6
6.1.2 图像连通域分析——connectedComponents()
图像的连通域是指图像中具有相同像素值并且位置相邻的像素组成的区域.
.提取图像中不同的连通域是图像处理中较为常用的方法,例如在车牌识别、文字识别、目标检测等领域对感兴趣区域的分割与识别
int cv::connectedComponents(InputArray image,
OutputArray labels,
int connectivity, //4邻域还是8邻域
int ltype, //输出图像类型
int ccltype//标记连通域使用的算法
)
- 1
- 2
- 3
- 4
- 5
- 6

常用的图像邻域分析法有两遍扫描法和种子填充法.
https://blog.csdn.net/sy95122/article/details/80757281
//该函数既可以计算连通域,同时还可以标记处不同连通域的位置,面积信息
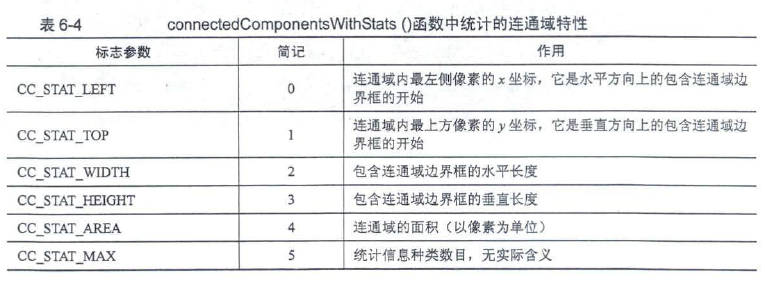
int cv::connectedComponentsWithStats(InputArray image,
OutputArray labels,
OutputArray stats, //不同连通域统计信息,如下表
OutputArray centroids, //每个连通域质心的坐标
int connectivity,
int ltype,
int ccltype)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
//该函数既可以计算连通域,同时还可以标记处不同连通域的位置,面积信息
int cv::connectedComponentsWithStats(InputArray image,
OutputArray labels,
OutputArray stats,
OutputArray centroids, //每个连通域质心的坐标
int connectivity = 8, //4表示4邻域,8表示8邻域
int ltype = CV_32S)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
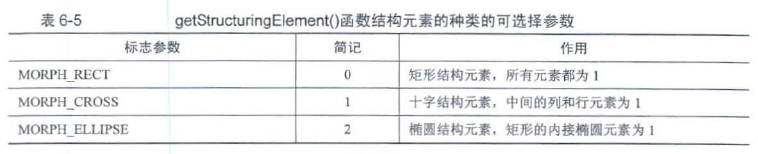
6.2 腐蚀和膨胀
腐蚀和膨胀是形态学的基本运算,通过这些基本运算可以去除图像中的噪声、分割出独立的区域或者将两个连通域连接在一起等.
6.2.1 图像腐蚀——erode()

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cFQHVRjl-1666660001271)(https://gitee.com/lyz-npu/typora-image/raw/master/img/%E5%9B%BE6-12.jpg)]
cv::Mat cv::getStructuringElement(int shape, //如下表
Size ksize,
Point anchor = Point(-1,-1)
)
- 1
- 2
- 3
- 4
void cv::erode(InputArray stc,
OutputArray dst,
InputArray kernel, //可以用getStructuringElement()生成
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_DEFAULT,
const Scalar & borderValue = morphologyDefaultBorderValue()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
白底图像黑底图像操作相反
6.2.2 图像膨胀——dilate()

void cv::dilate(InputArray src,
OutputArray dst,
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
const Scalar & boderValue = morphologyDefaultBorderValue()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
6.3 形态学应用
6.3.1 开运算——morphologyEx()
图像开运算可以去除图像中的噪声, 消除较小连通域, 保留较大连通域,同时能够在两个物体纤细的连接处将两个物体分离, 并且在不明显改变较大连通域面积的同时能够平滑连通域的边界.
腐蚀—>膨胀
void cv::morphologyEx(InputArray src,
OutputArray dst,
int op,//形态学操作类型的标志
InputArray kernel,
Point anchor = Point(-1,-1),
int iterations = 1,
int borderType = BORDER_CONSTANT,
const Scalar & boderValue = morphologyDefaultBorderValue()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

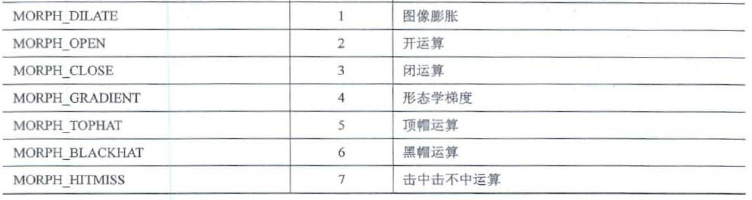
6.3.2 闭运算
图像闭运算可以去除连通域内的小型空洞, 平滑物体轮廓, 连接两个临近的连通域.
膨胀—>腐蚀
6.3.3 形态学梯度
形态学梯度能够描述目标的边界, 根据图像腐蚀和膨胀与原图之间的关系计算得到, 形态学梯度可以分为基本梯度、内部梯度和外部梯度.基本梯度是原图像膨胀后图像与腐蚀后图像间的差值图像, 内部梯度图像是原图像与腐蚀后图像间的差值图像, 外部梯度是膨胀后图像与原图像间的差值图像.
6.3.4 顶帽运算
图像顶帽运算是原图像与开运算结果之间的差值,往往用来分离比邻近点亮一些的斑块
腐蚀—>膨胀—>减原图像

6.3.5 黑帽运算
黑帽运算是原图像与顶帽运算结果之间的差值, 往往用来分离比邻近点暗一些的斑块.
膨胀—>腐蚀—>减原图像

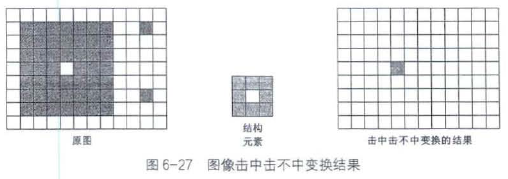
6.3.6 击中击不中变换
击中击不中变换要求原图像中需要存在与结构元素一模一样的结构
6.3.7 图像细化——thinning()
图像细化是将图像的线条从多像素宽度减少到单位像索宽度的过程,有时又称为"骨架化"或者"中轴变换气"
细化算法主要分为迭代细化算法和非迭代细化算法
迭代细化算法:串行细化算法、并行细化算法
Zhang 细化方法被广泛使用.
void cv::ximgproc::thinning(InputArray src,
OutputArray dst,
int thinningType = THINNING_ZHANGSUEN//还有一种THINNING_GUOHALL,,,Guo细化方法
)
- 1
- 2
- 3
- 4
第7章 目标检测
7.1 形状检测
7.1.1 直线检测——HoughLines()
霍夫变换(Hough Transfonn ) 是图像处理中检测是否存在直线的重要算法


//标准霍夫变换,,多尺度霍夫变换
void cv::HoughLines(InputArray image, //必须是CV_8U的单通道二值图像
OutputArray lines, //NX2 的vector<Vec2f>
double rho, //常用1
double theta, //常用CV_PI/180
int threshold,
double srn = 0,
double stn = 0,
double min_theta = 0,
double max_theta = CV_PI
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用标准霍夫变换和多尺度霍夫变换函数HoughLine()提取直线时无法准确知道图像中直线或者线段的长度,只能得到图像中是否存在符合要求的直线,以及直线的极坐标解析式.
//渐进概率式霍夫变换函数
void cv::HoughLinesP(InputArray image, //必须是CV_8U的单通道二值图像
OutputArray lines, //NX4 的vector<Vec4i>
double rho, //常用1
double theta, //常用CV_PI/180
int threshold,
double minLineLength = 0, //直线的最小长度,当检测直线的长度小于该数值时将被剔除.
double maxLineGap = 0//同一直线上相邻的两个点之间的最大距离.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
Vec4i 中前两个元素分别是直线或者线段一个端点的x 坐标和y 坐标,后两个元素分别是直线或者线段另一个端点的x 坐标和y 坐标
//检测点集中的直线
void cv::HoughLinesPointSet(InputArray _Point, //必须是cv_32FC2或CV_32SC2图像
//vector<Point2f>或者vector<Point2i>
OutputArray _lines, //在输入点集合中可能存在的直线, 每一条直线都具有3个参数,分别是权重、直线距离坐标原点的距离r和坐标原点到直线的垂线与x轴的夹角a.,,,权重越大表示是直线的可靠性越高,
int lines_max,//检测直线的最大数目.如果数目过大, 检测到的直线可能存在权重较小的情况.
int threshold,
double min_rho, //检测直线长度的最小距离, 以像素为单位.
double max_rho,
double rho_step,//以像素为单位的距离分辨率. 即距离r 离散化时的单位长度.
double min_theta, //检测直线的最小角度值,以弧度为单位.
double max_theta,
double theta_step//以弧度为单位的角度分辨率,即家教θ离散化时的单位角度.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
7.1.2 直线拟合——fitLine()
与直线检测相比,直线拟合的最大特点是将所有数据只拟合除一条直线
最小二乘M-estimator 方法
void cv::fitLine(InputArray points, //输入待拟合直线的二维或者三维点集.vector<>或者Mat
OutputArray line, //二维点集描述参数为Vec4f 类型,三维点集描述参数为Vec6f类型。
int distType, //M-estirnator 算法使用的距离类型标志
double param, //某些距离类型的数值参数( C) . 如果数值为0 , 那么自动选择最佳值.
double reps, //坐标原点与拟合直线之间的距离精度,数值0表示选择自适应参数, 一般选择0.01 .
double aeps//拟合直线的角度精度,数值0表示选择自适应参数,一般选择0.01.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
7.1.3 圆形检测——HoughCircles()
https://blog.csdn.net/weixin_44638957/article/details/105883829



void cv::HoughCircles(InputArray image, //数据类型必须是CV_8UC1.
OutputArray circles, //存放在vector<Vec3f>类型的变量,分别是圆心的坐标和圆的半径.
int method, //目前仅支持HOUGH_GRADIENT方法.
double dp, //离散化时分辨率与图像分辨率的反比.
double minDist, //检测结果中两个圆心之间的最小距离.
double paraml = 100, //Canny 检测边缘时两个阈值的级大值,较小阙值默认为较大值的一半.
double param2 = 100, //检测圆形的累加器阈值,
int minRadius = 0,
int maxRadius = 0
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
7.2 轮廓检测
7.2.1 轮廓发现与绘制——findContours()、drawContours()
https://blog.csdn.net/dcrmg/article/details/51987348
为了描述不同轮廓之间的结构关系,定义由外到内的轮廓级别越来越低,也就是高一层级的轮廓包围着较低层级的轮廓

void cv::findContours(InputArray image, //数据类型为CV_8U 的单通道灰皮图像或者二值化图像.
OutputArrayOfArrays coutours, //检测到的轮廓,每个轮廓中存放像素的坐标.vector<vector<Point>>
OutputArray hierarchy, //轮廓结构关系描述向量.vector<Vec4i>
int mode, //轮廓检测模式标志
int method, //轮廓逼近方法标志
Point offset = Point()//每个轮廓点移动的可选偏移量.这个参数主要用在从ROI图像中找出轮廓并基于整个图像分析轮廓的场景中.
)
//不输出轮廓的结构关系,避免内存资源的浪费
void cv::findContours(InputArray image,
OutputArrayOfArrays coutours,
int mode,
int method,
Point offset = Point()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

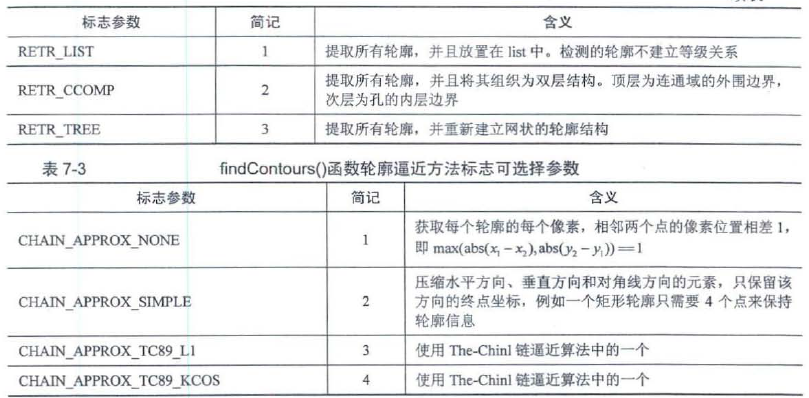
对于连接了图片边框的内容(例如下图的手),整个手不是个封闭图形,因此,在canny算子下找出了外轮廓,尽管使用了RETR_EXTERNEL来寻找最外层边框,依然会找到多余的边框。其实内部多出来的黑色轮廓是和手外部轮廓的同级边框

void cv::drawContours(InputOutputArray image, //绘制轮廓的目标图像.
InputArrayOfArray coutours, //所有将要绘制的轮廓.//vector<Vector<Point>>
int contourIdx, //轮廓的索引编号。若为负值,则绘制所有轮廓。
const Scalar & color,
int thickness,
int lineType = LINE_8, //边界线的连接类型
InputArray hierarchy = noArray(), //可选的结构关系信息,默认值为noArray().
int maxLevel = INT_MAX, //表示绘制轮廓的最大等级, 默认值为INT_MAX .
Point offset = Point()//可选的轮廓偏移参数,按指定的移动距离绘制所有的轮廓。
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

7.2.2 轮廓面积——contourArea()
通过轮廓面积的大小可以进一步分析每个轮廓隐含的信息.例如通过轮廓面积区分物体大小、识别不同的物体等
double cv::contourArea(InputArray coutour, //轮廊的像素点. vector<Point>或者Mat.
bool oriented = false//区域面积是否具有方向的标志. true 表示面积具有方向性. false 表示面积不具有方向性,默认值为面积不具有方向性的false.默认输出绝对值
)
- 1
- 2
- 3
当参数取值为true时, 表示统计的面积具有方向性, 轮廓顶点顺时针给出和逆时针给出时统计的面积互为相反数;当参数取值为false 时, 表示统计的面积不具有方向性,输出轮廓面积的绝对值.
7.2.3 轮廓长度(周长)——arcLength()
double cv::arcLength(InputArray curve, //轮廓或者曲线的二维像素点. vector<Point>或者Mat
bool closed//轮廓或者曲线是否闭合的标志, true 表示闭合.
)
- 1
- 2
- 3
若第二个参数式true,则三角形三个顶点的周长为三边和,,,,若为false,则周长为两边之和
7.2.4 轮廓外接多边形——boundingRect()、minAreaRect()、approxPolyDP()
//求取轮廓最大外接矩形
Rect cv::boundingRect(InputArray array)//array 表示输入的灰度图像或者二维点集,数据类型为vector<Point>或者Mat
//输入一个findContour的contour矩阵
//求取最小外接矩形
RotatedRect cv::minAreaRect(InputArray points)//point表示输入的二维点集合.
- 1
- 2
- 3
- 4
- 5
- 6

//多边形逼近轮廓
void cv;:approxPolyDp(InputArray curve, //输入轮廓像素点.vector<Point>或者Mat
OutputArray approxCurve, //多边形逼近结果,以顶点坐标的形式给出.CV_32SC2类型的Nx1的Mat类矩阵,
double epsilon, //逼近的精度,即原始曲线和逼近曲线之间的最大距离.
bool closed//逼近曲线是否为封闭曲线的标志, true 表示曲线封闭,
)
- 1
- 2
- 3
- 4
- 5
- 6
7.2.5 点到轮廓距离——pointPolygonTest()
点到轮廓的距离,对于计算轮廓在图像中的位置、两个轮廓之间的距离以及确定图像上某一点是否在轮廓内部具有重要的作用.
double cv::pointPolygonTest(InputArray coutour, //输入的轮廓. vector<Point>或者Mat
Point2f pt, //需要计算与轮廓距离的像素点.
bool measureDist//计算的距离是否具有方向性的标志.当参数取值为true 时,点在轮廓内部时,距离为正,点在轮廓外部时,距离为负;;;;当参数取值为false时,只检测点是否在轮廓内.
)
- 1
- 2
- 3
- 4
7.2.6 凸包检测——convexHull()
将二维平面上的点集最外层的点连接起来构成的凸多边形称为凸包.但是逼近结果一定为凸多边形.
void cv::convexHull(InputArray points, //输入的二维点集或轮廓坐标. vector<Point>或者Mat
OutputArray hull, //输出凸包的顶点. vector<Point>或者vector<int>
bool clockwise = false, //当参数取值为true时,凸包顺序为顺时针方向:
bool returnPoints = true
)
- 1
- 2
- 3
- 4
- 5
7.3 矩的计算
7.3.1 几何矩与中心矩——moments()
https://www.zhihu.com/question/26803016
矩是描述图像特征的算子,广泛应用于图像检索和识剔,图像匹配,图像重建,图像压缩,以及运动图像序列分析等领域.

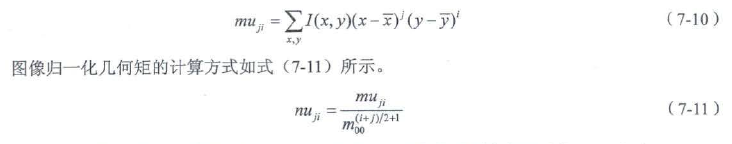
Moments cv::moments(InputArray array, //计算矩的区域二维像素坐标集合或者单通道的CV_8U图像.
bool binaryImage = false//是否将所有非零像素值视为1的标志.
)
- 1
- 2
- 3

7.3.2 Hu矩——HuMoments()
Hu 矩具有旋转、平移和缩放不变性,因此,在图像具有旋转和缩放的情况下, Hu矩具有更广泛的应用.
//需要先计算图像的矩,将图像的矩输入到HuMonments()函数中
void cv::HuMoments(const Moments & moments, //输入的图像矩.
double hu[7]//输出Hu 矩的7 个值.
)
void cv::HuMoments(const Moments & m,
OutputArray hu//输出Hu 矩的矩阵.
)
Moments M = Moments(imgContours);
HuMoments(m, hu);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
7.3.3 基于Hu矩的轮廓匹配——matchShapes()
由于Hu 矩具有旋转、平移和缩放不变性,因此可以通过Hu 实现图像轮廓的匹配.
double cv::matchShapes(InputArray contour1, //原灰度图像或者轮廓.
InputArray contour2, //模板图像或者轮廓.
int method, ///匹配方法的标志
double parameter//特定于方法的参数( 现在不支持) .可以设置为0
)
- 1
- 2
- 3
- 4
- 5

7.4 点集拟合


//该函数能够找到包含给定三维点集的最小区域的三角形,,,返回值为double 类型的三角形面积.
double cv::minEnclosingTriangle(InputArray points, //vector<>或者Mat类型的变量,CV_32S或CV_32F;
OutputArray triangle//三角形的3个顶点坐标,存放在vector<Point2f>变量中
)
- 1
- 2
- 3
- 4
//寻找二维点集的最小包围圆形
void cv::minEnclosingCircle(InputArray points, //vector<>或者Mat类型的变量
Point2f & center,
float & radius
)
- 1
- 2
- 3
- 4
- 5
7.5 QR二维码检测

对QR 二维码的识别儒要借助第三方工具,常用的是zbar 解码库.OpenCV4提供了解码函数
针对QR 二维码识别的两个过程. OpenCV 4 提供了多个函数用于实现每个过程, 这些函数分别是定位QR二维码的detect()函数、根据定位结果解码二维码的decode()函数,以及同时定位和解码的detectAndDecode()函数.
//定位不解码
bool cv::QRCodeDetector::detect(InputArray img,
OutputArray points//二维码的4 个顶点坐标.。。vector<Point>
)
- 1
- 2
- 3
- 4
//对定位结果进行解码
std::string cv::QRCodeDetector::decode(InputArray img, //含有QR 二维码的图像.
InputArray points, //包含QR二维码的最小区域的四边形的4 个顶点坐标.
OutputArray straight_qrcode = noArray()//经过校正和二值化的QR二维码.
)
- 1
- 2
- 3
- 4
- 5
//一步完成定位和解码
std::string cv::QRCodeDetector::detectAndDecode(InputArray img,
OutputArray points = noArray(),
OutputArray straight_qrcode = noArray()
)
cv::QRCodeDetector qrcodedetector;
qrcodedetector.detect();
qrcodedetector.decode();
qrcodedetector.detectAndDecode();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
第8章 图像分析与修复
8.1 傅里叶变换
https://www.bilibili.com/video/BV1HJ411a7cp?spm_id_from=333.880
通俗讲解:图像傅里叶变换 - 麻花团子的文章 - 知乎 https://zhuanlan.zhihu.com/p/99605178
任何信号都可以由一系列正弦信号叠加形成, 一维领域信号是一维正弦波的叠加,二维领域是二维平面波的增加.由于图像可以看作是二维信号, 因此可以对图像进行傅里叶变换
对图像进行离散傅里叶变换
离散傅里叶变换广泛应用在图像的去噪、滤波等卷积领域
理解傅里叶分析:https://blog.csdn.net/u013921430/article/details/79683853
数字图像傅里叶分析:https://blog.csdn.net/u013921430/article/details/79934162
8.1.1 离散傅里叶变换——dft()、idft()
图像离散傅里叶变换之后的结果会得到既含有实数又含有虚数的图像,在实际使用时常将结果分成实数图像和虚数图像,或者用复数的幅值和相位来表示变换结果, 可以分成幅值图像和相位图像.
图像中像素波动较大的区域对应的频域是高频区域,因此高频区域体现的是图像的细节、边缘、纹理信息,而低频信息代表了图像的内容信息.
//对图像进行傅里叶变换
void cv::dft(InputArray src, //输入的图像或者数组矩阵,可以是实数也可以是复数.CV_32F 或者CV_64F
OutputArray dst, //存放离散傅里叶变换结果的数组矩阵.
int flags = 0, //变换类型可选标志
int nonzeroRows = 0//输入、输出结果的形式,默认值为o .
)
- 1
- 2
- 3
- 4
- 5
- 6
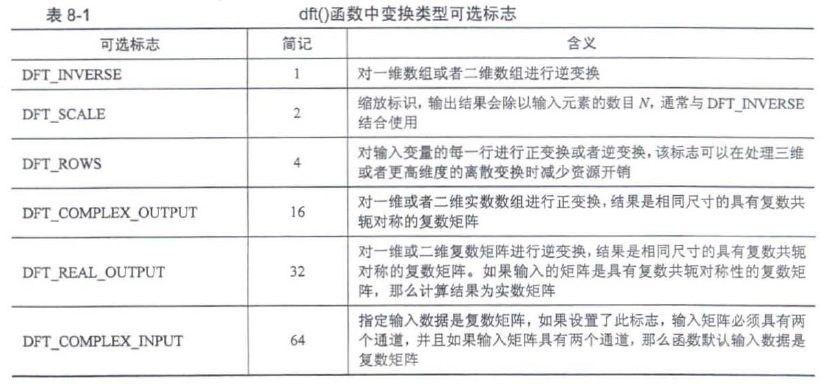
//对图像进行离散傅里叶逆变换
idft(src, dst, flags)相当于dft(src, dst, flags | DFT_INVERSE)
- 1
- 2
离散傅里叶变换算法倾向于对某些特定长度的输入矩阵进行处理, 而不是对任意尺寸的矩阵进行处理.因此,如果尺寸小于处理的最佳尺寸,那么常需要对输入矩阵进行尺寸变化以使得函数拥有较快的处理速度.常见的尺寸调整方式为在原矩阵的周围增加多层。像素, 因此dft()函数第四个参数才会讨论矩阵中出现第一个非零行.
填充多少行,列需要由下面的函数进行计算,,计算需要多少行、列
//计算最优尺寸
int cv::getOptimalDFTSize(int vecsize);//vecsize是图像的rows,cols
- 1
- 2
计算好最有尺寸后,改变图像的尺寸,在图像周围生成外框
void cv::copyMakeBorder(InputArray src,
OutputArray dst,
int top,
int bottom,
int left,
int right,
int borderType,
const Scalar & value = Scalar()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由于离散傅里叶变换得到的数值可能为双通道的复数, 在实际使用过程中更加关注复数的幅值, 因此OpenCV 4 提供了magnitude()函数用于计算由两个矩阵组成的二维向量矩阵的幅值矩阵.
void cv::magnitude(InputArray x,
InputArray y,
OutputArray magnitude
)
- 1
- 2
- 3
- 4

因为F(u,v)衰减、变化比较快,直接画图看不到什么点,因此需要加个1,,,再log运算,,,然后再对幅值谱进行分析
.在该程序中, 首先计算适合图像离散傅里叶变换的最优尺寸,之后利用copyMakeBorder()函数扩展图像尺寸,然后进行离散傅里叶变换,最后计算变换结果的幅值.为了能够显示变换结果中的幅值,将结果进行归一化处理。变换的原点位于4 个顶点,因此通过图像变换,将变换结果的原点调整到图像中心.
需要注意一点的是,频域图像归一化处理仅仅只是观察频谱图时有所帮助.包括对数变换也是一样,是为了更好的观察频域的能量分布的,因为图像的能量大多集中在低频区域,因此变换的结果大多也就是看到低频上一些白斑
图像傅里叶变换后为什么要归一化? - DBinary的回答 - 知乎 https://www.zhihu.com/question/354081645/answer/890215427
#include <opencv2/opencv.hpp> #include <iostream> using namespace std; using namespace cv; int main() { //对矩阵进行处理,展示正逆变换的关系 Mat a = (Mat_<float>(5, 5) << 1, 2, 3, 4, 5, 2, 3, 4, 5, 6, 3, 4, 5, 6, 7, 4, 5, 6, 7, 8, 5, 6, 7, 8, 9); Mat b, c, d; dft(a, b, DFT_COMPLEX_OUTPUT); //正变换 dft(b, c, DFT_INVERSE | DFT_SCALE | DFT_REAL_OUTPUT); //逆变换只输出实数 idft(b, d, DFT_SCALE); //逆变换 //对图像进行处理 Mat img = imread("pic/lena.png"); if (img.empty()) { cout << "请确认图像文件名称是否正确" << endl; return -1; } Mat gray; cvtColor(img, gray, COLOR_BGR2GRAY); resize(gray, gray, Size(502, 502)); imshow("原图像", gray); //计算合适的离散傅里叶变换尺寸 int rows = getOptimalDFTSize(gray.rows); int cols = getOptimalDFTSize(gray.cols); //扩展图像 Mat appropriate; int T = (rows - gray.rows) / 2; //上方扩展行数 int B = rows - gray.rows - T; //下方扩展行数 int L = (cols - gray.cols) / 2; //左侧扩展行数 int R = cols - gray.cols - L; //右侧扩展行数 copyMakeBorder(gray, appropriate, T, B, L, R, BORDER_CONSTANT); imshow("扩展后的图像", appropriate); //构建离散傅里叶变换输入量 Mat flo[2], complex; flo[0] = Mat_<float>(appropriate); //实数部分 flo[1] = Mat::zeros(appropriate.size(), CV_32F); //虚数部分 merge(flo, 2, complex); //合成一个多通道矩阵 //进行离散傅里叶变换 Mat result; dft(complex, result); //将复数转化为幅值 Mat resultC[2]; split(result, resultC); //分成实数和虚数 Mat amplitude; magnitude(resultC[0], resultC[1], amplitude); //进行对数放缩公式为: M1 = log(1+M),保证所有数都大于0 amplitude = amplitude + 1; log(amplitude, amplitude);//求自然对数 //与原图像尺寸对应的区域 amplitude = amplitude(Rect(T, L, gray.cols, gray.rows));//gray扩充了矩阵尺寸,,因此构建矩阵的时候把边框裁掉,匹配原来的初始图像 normalize(amplitude, amplitude, 0, 1, NORM_MINMAX); //归一化 imshow("傅里叶变换结果幅值图像", amplitude); //显示结果 //重新排列傅里叶图像中的象限,使得原点位于图像中心 int centerX = amplitude.cols / 2; int centerY = amplitude.rows / 2; //分解成四个小区域 Mat Qlt(amplitude, Rect(0, 0, centerX, centerY));//ROI区域的左上 Mat Qrt(amplitude, Rect(centerX, 0, centerX, centerY));//ROI区域的右上 Mat Qlb(amplitude, Rect(0, centerY, centerX, centerY));//ROI区域的左下 Mat Qrb(amplitude, Rect(centerX, centerY, centerX, centerY));//ROI区域的右下 //交换象限,左上和右下进行交换 Mat med; Qlt.copyTo(med); Qrb.copyTo(Qlt); med.copyTo(Qrb); //交换象限,左下和右上进行交换 Qrt.copyTo(med); Qlb.copyTo(Qrt); med.copyTo(Qlb); imshow("中心化后的幅值图像", amplitude); waitKey(0); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
8.1.2 傅里叶变换进行卷积——mulSpecturms()
傅里叶变换可以将两个矩阵的卷积转换成两个矩阵傅里叶变换结果的乘积,通过这种方式可以极大地提高卷积的计算速度.但是图像傅里叶变换结果都是具有复数共辄对称性的复数矩阵,两个矩阵相乘需要计算对应位置的两个复数乘积. OpenCV 4 提供了用于计算两个复数矩阵的乘积的mulSepctrums()函数
void cv::mulSpecturms(InputArray a,
InputArray b,
OutputArray c,
int flags, //DFT_COMPLEX_OUTPUT
bool conjB = false//是否对第二个输入矩阵进行共辄变换的标志.当参数为false时,不进行其辄变换;当参数为true时,进行共辄变换.
)
- 1
- 2
- 3
- 4
- 5
- 6
通过离散傅里叶变换方式进行图像的卷积时,需要将卷积核也扩展到与图像相同的尺寸,然后同时对两个图片做尺寸最优化扩展矩阵, 并对乘积结果进行离散傅里叶变换的逆交换.
8.1.3 离散余弦变换
https://blog.csdn.net/akadiao/article/details/79778095
离散余弦变换经常使用在信号处理和图像处理领域中,主要用于对信号和图像的有损数据压缩中.离散余弦变换具有"能量集中" 的特性,信号经过变换后能量主要集中在结果的低频部分.
void cv::dct(InputArray src, //处理单通道数据
OutputArray dst,
int flags = 0
)
- 1
- 2
- 3
- 4
目前dct()函数只支持偶数大小的数组,
//逆变换
void cv::idct(InputArray src,
OutputArray dst,
int flags = 0
)
- 1
- 2
- 3
- 4
- 5
离散余弦变换具有很强的”能量集中”特性,左上方称为低频数据,右下方称为高频数据。

8.2 积分图像
用于快速计算图像某些区域像素的平均灰度
.积分图像是比原因像尺寸大1 的新图像,例如,原因像尺寸为NxN , 那么积分图像尺寸为(N + 1) x (N + 1) .
积分图像中每个像素的像素值为原图像中该像素点与坐标原点组成的矩形内所有像素值的和,
P0的像素值为原图像中前四行和前四列相交区域内所有像素值之和
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-er9De8kL-1666660001277)(https://gitee.com/lyz-npu/typora-image/raw/master/img/%E5%9B%BE8-7.png)]
积分图像:标准求和积分图像、平方求和积分图像、倾斜求和积分图像(只是累加方向旋转了45°)
//标准求和积分 void cv::intergral(InputArray src, //NxN OutputArray sum, //(N+I)x(N+I) int sdepth = -1 ) //平方求和积分 void cv::intergral(InputArray src, OutputArray sum, OutputArray sqsum, //输出平方求和积分图像 int sdepth = -1, int sqdepth = -1 ) //平方求和积分 void cv::intergral(InputArray src, OutputArray sum, OutputArray sqsum, //输出平方求和积分图像 Output Array tilted,//输出倾斜求和积分图像 int sdepth = -1, int sqdepth = -1 )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
8.3 图像分割
8.3.1 漫水填充法——floodFill()
int cv::floodFill(InputOutputArray imgae, //单通道或者三通道 InputOutputArray mask, //尺寸比输入图像宽和高各大2 的单通道图像,用于标记漫水填充的区域. Point seedPoint, //种子点 Scalar newVal, //归入种子点区域内像素点的新像素值. Rect * rect = 0, //种子点漫水填充区域的最小矩形边界, 默认值为0 ,表示不输出边界 Scalar loDiff = Scalar(), //·添加进种子点区域条件的下界差值 Scalar upDiff = Scalar(), //添加进种子点区域条件的上界差值 int flags = 4//漫水填充法的操作标志,,,,,邻域种类、掩码矩阵中被填充像素点的像素值、填充算法 //41 | (255<<8) | FLOODFILL_FIXED_RANGE ) int cv::floodFill(InputOutputArray imgae, Point seedPoint, Scalar newVal, Rect * rect = 0, Scalar loDiff = Scalar(), Scalar upDiff = Scalar(), int flags = 4 )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
8.3.2 分水岭法——watershed()
区别在于漫水填充法是从某个像素值进行分割, 是一种局部分割算法,而分水岭法是从全局出发,需要对全局进行分割.
https://zhuanlan.zhihu.com/p/67741538
void cv::watershed(InputArray image, //是CU_8U数据类型的三通道彩色图像
InputOutputArray markers//CV_32S 数据类型的单通道图像的标记结果
)
- 1
- 2
- 3
两个区域的边界是-1,其他区域的值是1-n的数字,数字不可能大于 contour的数量。
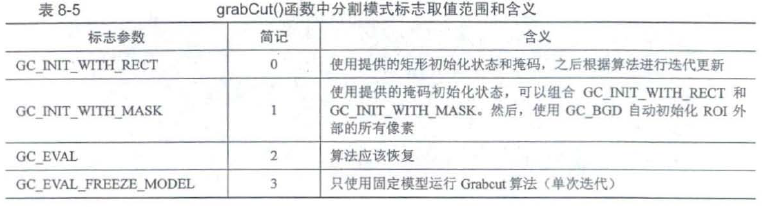
8.3.3 Grabcut法——grabCut()
Grabcut 法是重要的图像分割算法,其使用高斯混合模型估计目标区域的背景和前景.该算法通过法代的方法解决了能量函数最小化的问题, 使得结果具有更高的可靠性.
void cv::grabCut(InputArray img, //CV_8U
InputOutputArray mask, //CV_8U
Rect rect, //的ROI 区域, 该参数仅在mode = GC_INIT_WITH_RECT 时使用.
InputOutputArray bgdModel, //背景模型的临时数组.
InputOutputArray fgdModel, //前景模型的临时数组.
int iterCount, //法代次数.
int mode = GC_EVAL//分割模式标志,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

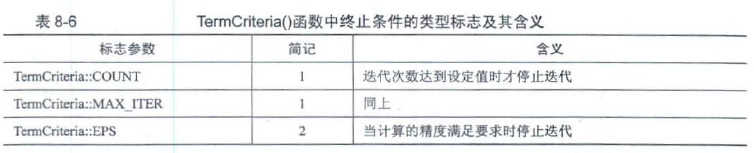
8.3.4 Mean-Shift法——pyrMeanShiftFiltering()
https://blog.csdn.net/ttransposition/article/details/38514127
百度文库PPT:https://wenku.baidu.com/link?url=kZt9aLkbV0D74VY9AjCs_aL4cO4eSrbU8rDdzk2pLP0ZbSieurP-xFAJAPGxZSx3bLLxv14bMC5WoSlTkjZ5QXO7UOOO5IKKMqVixxsZst_
meanshift经常用来寻找模态点,即密度最大的点
均值漂移法,是一种基于颜色空间分布的图像分割算法,该算法的输出是一个经过滤色的“分色“图像,其图像会变得渐变,细纹纹理会变的平缓。,每个像素点用一个五维向量(x, y, b, g, r)表示,
void cv:pyrMeanShiftFiltering(InputArray src, //CU_8U
OutputArray dst,
double sp, //滑动窗口的半径.
double sr, //滑动窗口颜色幅度.
int maxLevel = 1, //分割金字塔缩放层数.
TermCriteria = TermCriteria(TermCriteria::MAX_ITER+TermCriteria::EPS,5,1))//法代算法终止条件.
- 1
- 2
- 3
- 4
- 5
- 6
cv::TermCriteria::TermCriteria(int Type,
int maxCount, //最大法代次数或者元素数.
double epsilon//法代算法停止时需要满足的精度或者参数变化.
)
- 1
- 2
- 3
- 4
8.4 图像修复
去除图像中受"污染"的区域。图像修复不但可以去除图像中的划痕,而且可以去除图像中的水印、日期等.
void cv::inpaint(InputArray src, //当图像为三通道时, 数据类型必须是CV_8U.
InputArray inpaintMask,
OutputArray dst,
double inpaintRadius, //算法考虑的每个像素点的圆形邻域半径.
int flags//修复图像方法标志,
)
- 1
- 2
- 3
- 4
- 5
- 6

离边缘区域越远的像索估计的准确度越低, 因此, 如果" 污染" 区域较大, 修复的效果就会降低.
先创建掩模(掩模是图像中的污染,通过二值化等操作求出污染的区域),然后可以适当膨胀扩大掩模的污染区域,在inpaint()函数中输入要去除污染的图像和污染掩模
第9章 特征点检测与匹配
9.1 角点检测

9.1.1 显示关键点——drawKeypoints()
关键点是对图像中含有特殊信息的像素点的一种称呼,主要含有像素点的位置、角度等信息.
drawKeypoints() 函数用于一次性绘制所有的关键点
void cv::drawKeypoints(InputArray image,
const std::vector<Keypoint> & keypoints,
InputOutputArray outImage, //绘制关键点后的图像
const Scalar & color = Scalar::all(-1), //关键点的颜色
DrawMatchesFlags flags = DrawMatchesFlasgs::DEFAULT//绘制功能选择标志
)
- 1
- 2
- 3
- 4
- 5
- 6
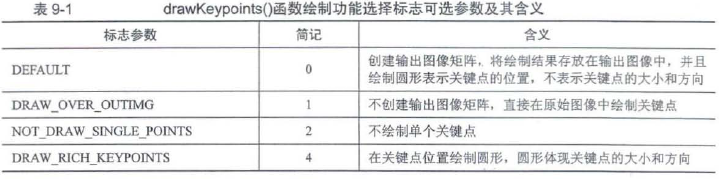
//KeyPoint类
class KeyPoint{
float angle //关键点的角度
int class_id //关键点的分类号
int octave //特征点来源“金字塔”
Point2f pt //关键点坐标
float response //最强关键点的响应,可用于进一步分类和二次来样
float size //关键点邻域的直径
}
//关键点类型变量的其他属性可以默认,但是坐标属性必须具有数据.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
9.1.2 Harris角点检测——cornerHarris()
Harris角点对于旋转、平移具有不变性,,但是对于缩放没有不变性
Harris角点响应函数表达式是怎么得来的? - 大黑的回答 - 知乎 https://www.zhihu.com/question/37871386/answer/2311779754
角点检测:Harris 与 Shi-Tomasi - 程序员阿德的文章 - 知乎 https://zhuanlan.zhihu.com/p/83064609
Harris角点是最经典的角点之一,其从像素值变化的角度对角点进行定义,像素值的局部最大峰值即为Harris 角点
void cv::cornerHarris(InputArray src, //CV_8U 或者CV_32F
OutputArray dst, //存放Harris评价系数R的矩阵,数据类型为CV_32F的单通道图像,
int blockSize, //邻域大小. 常常取2
int ksize, //Sobel算子的半径,用于得到梯度信息. 多使用3或者5
double k, //计算Harris 评价系数R 的权重系数. 一般取值为0.02~0.04.
int borderType = BORDER_DEFAULT
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
该函数计算得到的结果是Harris评价系数,但是由于其取值范围较广并且有正有负, 常需要通过normalize()函数将其归一化到指定区域内后,再通过阈值比较判断像素点是否为Harris 角点
9.1.3 Shi-Tomas角点检测——goodFeaturesToTrack()

void cv::goodFeaturesToTrack(InputArray image,
OutputArray corners, //vector<Point2扣的向盘或者Mat 类矩阵中,那么如果存放在Mat类矩阵中, 那么生成的是数据类型为CV_32F 的单列矩阵,
int maxCorners,
double qualityLevel, //角点阈值与最佳角点之间的关系,又称为质量等级,如果参数为0.01. 那么表示角点阀值是最佳角点的0.01倍.
double minDistance, //两个角点之间的最小欧氏距离.
InputArray mask = noArray(),
int blockSize = 3, //计算梯度协方差矩阵的尺寸,,,,默认3
bool useHarrisDetector = false, //是否使用Har由角点检测.
double k = 0.04//Harris角点检测过程中的常值权重系数.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
9.1.4 亚像素级别角点检测——cornerSubPix()


void cv::cornerSubPix(InputArray image,
InputOutputArray corners, //角点坐标, 既是输入的角点坐标, 又是精细后的角点坐标.
Size winSize, //搜索窗口尺寸的一半, 必须是整数.实际的搜索窗口尺寸比该参数的2倍大1.
Size zeroZone, //搜索区域中间"死区"大小的一半,即不提取像素点的区域,(-1,-1)表示没"死区"
TermCriteria criteria//:终止角点优化法代的条件.
)
- 1
- 2
- 3
- 4
- 5
- 6
亚像素级别角点检测是先计算出Harris角点/Shi-Tomas角点后,再精细化计算亚像素角点
9.1.5 FAST角点检测——FAST()
https://blog.csdn.net/tostq/article/details/49314017
https://aibotlab.blog.csdn.net/article/details/65662648
1.fast很快;
2.没有sift的尺度不变性,也不具有旋转不变性;
3.当图片中的噪点较多时,它的健壮性并不好,而且算法的效果还依赖于一个阈值t
FAST(gray, fastPt, 50,true,FastFeatureDetector::TYPE_9_16);
//等价于下面
Ptr<FastFeatureDetector> fast = FastFeatureDetector::create(50, true, FastFeatureDetector::TYPE_9_16);
fast->detect(gray, fastPt);
//Ptr<类名>的用法,Ptr是一个智能指针,可以在任何地方都不使用时自动删除相关指针,从而帮助彻底消除内存泄漏和悬空指针的问题。,Ptr<类名>是一个模板类,其类型为指定的类,
OpenCV笔记(Ptr) https://www.cnblogs.com/fireae/p/3684915.html
//Ptr计数指针的技术问题
shared_ptr的引用计数原理 https://blog.csdn.net/qq_29108585/article/details/78027867
深入理解智能指针之shared_ptr https://www.cnblogs.com/mrbendy/p/12701339.html
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
9.2 特征点检测
特征点与角点在宏观定义上相同,都是能够表示图像中局部特征点多的像素点,但是特征点去有别于角点的是其具有能够唯一描述像素点特征的描述子,例如该点左侧像素比右侧像素大,该点是局部最低点等。
通常特征点有关键点和描述子组成,例如SIFT特征点、ORB特征点等都需要先计算关键点坐标,之后再计算描述子
9.2.1 关键点

virtual void cv::Feature2D::detect(InputArray image,
std::vector<KeyPoint> & keypoints,
InputArray mask = noArray()
)
- 1
- 2
- 3
- 4
该函数需要被其他类继承之后才能使用,即只有在特征点具体的类中才能使用,例如在ORB特征点的ORB类中,可以通过ORB::detect()函数计算ORB特征点的关键点,在SIFT特征点的SIFT类中,可以通过SIFT::detect()函数计算SIFT特征点的关键点
9.2.2 描述子——detectAndCompute()
描述子是用来唯一描述关键点的一串数字,与每个人的个人信息类似,通过描述子可以区分两个不同的关键点,也可以在不同的图像中寻找同一个关键点
//计算描述子
virtual void cv::Feature2D::compute(InputArray image,
std::vector<KeyPoint> &keypoints, //已经在输入图像中计算得到的关键点.
OutputArray descriptors
)
- 1
- 2
- 3
- 4
- 5
//直接计算关键点和描述子
virtual void cv::Feature2D::detectAndCompute(InputArray image,
InputArray mask, //计算关键点时的掩码图像.
std::vector<KeyPoint> & keypoints, //计算得到的关键点.
OutputArray descriptors, //每个关键点对应的描述子.
bool useProvidedKeypoints = false//是否使用己有关键点的标识符。
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
9.2.3 SIFT特征点检测——Ptr<SIFT>
SIFT 特征点之所以备受欢迎, 是因为其在光照、噪声、视角、缩放和旋转等干扰下仍然具有良好的稳定性.

Sift算子特征点提取https://blog.csdn.net/dcrmg/article/details/52577555
128维特征项量的来源:https://www.cnblogs.com/wangguchangqing/p/4853263.html
S1FT类变量,用于表明从Features2D类中继承的函数是计算SIFT特征点,而不是计算其他特征点、SIFT 类在xfeatures2d 头文件和命名空间中,因此在使用时需要在程序中通过"#include <xfeatures2d.hpp>"包含头文件,
static Ptr<SIFT> cv::xfeatures2D::SIFT::create(int nfeatures = 0, //计算SIFT特征点数目。
int nOctaveLayers = 3,//金字塔中每组的层数.
double contrastTheshold =0.04, //过滤较差特征点的阈值,该参数值越大,返回的特征点越少.
double edgeThreshold = 10, //过滤边缘效应的阈值, 该参数值越大,返回的特征点越多.
double sigma = 1.6//"金字塔"第0 层图像高斯滤波的系数,即上图的σ0
)
- 1
- 2
- 3
- 4
- 5
- 6
9.2.4 SURF特征点检测——Ptr<SURF>
https://blog.csdn.net/zrz0258/article/details/113176528
SURF 特征点直接用方框滤波器去逼近高斯差分空间
SURF 特征点中, 不同组间图像的尺寸都是相同的, 但不同组使用的方框滤波器的尺寸逐渐增大,同一组内不同层间使用相同尺寸的滤波器,但是滤波器的模糊系数逐渐增大.
static Ptr<SURF> cv:xfeatures2d::SURF::create(double hessianThreshold = 100, //SURF关键点检测的阈值.
int nOctaves = 4, //构建"金字塔"的组数.
int nOctaveLayers = 3, //"金字塔"中每组的层数
bool extended = false, //是否拓展64维描述子至128维.
int upright = false//是否计算关键点方向的标志.
)
- 1
- 2
- 3
- 4
- 5
- 6

9.2.5 ORB特征点检测——Ptr<ORB>
https://www.cnblogs.com/alexme/p/11345701.html
https://blog.csdn.net/yang843061497/article/details/38553765
ORB 特征点以计算速度快著称,计算速度可以达到SURF 特征点的10 倍、SIFT 特征点的100 倍,
ORB特征点由FAST角点与BRIEF描述子组成,首先通过FAST角点确定图像中与周围像索存在明显像素点作为关键点, 之后计算每个关键点的BRIEF描述子, 从而唯一确定ORB特征点.
具有旋转不变性和尺度不变性
static Ptr<ORB> cv::ORB::create(int nfeatures = 500,
float scaleFactor = 1.2f, //" 金字塔"尺寸缩小的比例
int nlevels = 8, //金字塔"层数
int edgeThreshold = 31, //边缘阈值.
int firstLevel = 0, //将原图像放入"金字塔"中的等级,例如放入第0 层.
int WTA_K = 2, //生成每位描述子时需要用的像索点数目.
ORB::ScoreType scoreType = ORB::HARRIS_SCORE, //检测关键点时关键点评价方法.
int patchSize = 31, //生成描述子时关键点周围邻域的尺寸.
int fastThreshold = 20//计算FAST 角点时像素值差值的阈值.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
9.3 特征点匹配
特征点匹配就是再不同的图像中寻找统一物体的同一个特征点


9.3.1 DescriptorMatcher类介绍
//一对一的匹配
void cv::DescriptorMatcher::match(InputArray queryDescriptors,//查询描述子集合.
InputArray trainDescriptors,//训练描述子集合.
std::vector<DMatch> & matches,//两个集合描述子匹配结果.匹配结果数目可能小于描述子的数目
InputArray mask = noArray()//描述子匹配时的掩码矩阵,用于指定匹配哪些描述子.
)
- 1
- 2
- 3
- 4
- 5
- 6
DMatch 类型是OpenCV4 中用于存放特征点描述子匹配关系的类型,类型中存放着两个描述子的索引、距离等.
class cv::DMatch{
float distance //两个描述子之间的距离
int imgIdx //训练描述子来自的图像索引
int queryIdx //查询描述子集合中的索引
int trainIdx //训练描述子集合中的索引
}
- 1
- 2
- 3
- 4
- 5
- 6
//一对多的描述子匹配
void cv::DescriptorMatcher::knnMatch(InputArray queryDescriptors,
INputArray trainDescriptors,
std::vector<std::vector<DMatch>> & matches,//即matches[i]中存放的是k个或者更少的与查询描述子匹配的训练描述子.
int k,//每个查询描述子在训练描述子集合中寻找的最优匹配结果的数目.————————就是一个训练描述子集合可以寻找k个查询描述子
InputArray mask = noArray(),
bool compactResult = false//输出匹配结果数目是否与查询描述子数目相同的选择标志。
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
//匹配所有满足条件的描述子,即将与查询描述子距离小于阈值的所有训练描述子都作为匹配点输出
void cv::DescriptorMatcher::radiusMatch(InputArray queryDescriptors,
INputArray trainDescriptors,
std::vector<std::vector<DMatch>> & matches,
float maxDistance,
InputArray mask = noArray(),
bool compactResult = false
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
与特征点detect()函数很像,,只有创建了类继承了虚类后,才能使用match函数
9.3.2 暴力匹配——BFMatcher.match()

cv::BFMatcher::BFMatcher(int normType = NORM_L2,
bool crossCheck = false
)
- 1
- 2
- 3
暴力匹配会对每个查询描述子寻找一个最佳的描述子,但是有时这种约束条件也会造成较多错误匹配,例如某个特征点只在查询描述子图像中出现,这种情况在另一幅图像中不会存在匹配的特征点,但是根据暴力匹配原理,这个特征点也会在另一幅图像中寻找到与之匹配的特征点,造成错误的匹配.
void cv::drawMatches(InputArray img1,
const std::vector<KeyPoint> & keypoints1,
InputArray img2,
const std::vector<KeyPoint> & keypoints2,
const std::vector<DMatch> & matches1to2,
InputOutputArray outImg,
const Scalar & matchColor = Scalar::all(-1),
const Scalar & singlePointColor = Scalar::all(-1),
const std::vector<char> & matchesMask = std::vector<char>(),
DrawMatchesFlags flags = DrawMathcesFlags::DEFAULT//绘制功能选择标志,
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
9.3.4 FLANN匹配——FlannBaesdMatcher.match()
虽然暴力匹配的原理简单, 但是算法的复杂度高, 当遇到特征点数目较大的情况时, 会严重影响程序运行时间,因此OpenCV 4 提供了快速最近邻搜索库( Fast Library for Approximate Nearest Neighbors. FLANN) 用于实现特征点的高效匹配.
cv::FlannBasedMatcher::FlannBasedMatcher(
const Ptr<flann::IndexParams> & indexParams = makePtr<flann::KDTreeIndexParams>(),
const Ptr<flann::SearchParams> & searchParams = makePtr<flann::SearchParams>()//法代遍历次数终止条件、一般情况下使用默认参数即可。
)
//使用FLANN方法进行匹配时描述子需要是CV_32F 类型,因此ORB 特征点的描述子变量需要进行类型转换后才可以实现特征点匹配.
- 1
- 2
- 3
- 4
- 5
- 6

k-d树结构:https://blog.csdn.net/u011067360/article/details/23934361

k-means聚类:https://www.cnblogs.com/pinard/p/6164214.html
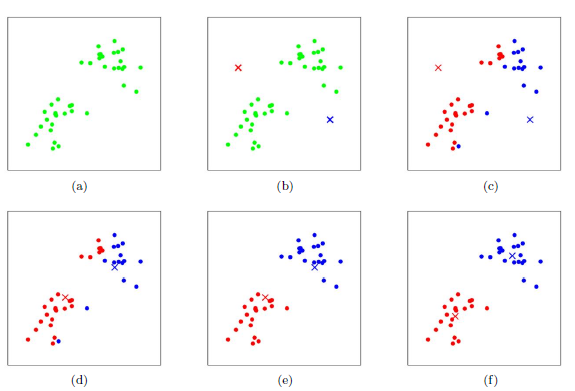
Hierarchical Clustering层次聚类:https://blog.csdn.net/zhangyonggang886/article/details/53510767
层次聚类(Hierarchical Clustering)是聚类算法的一种,通过计算不同类别数据点间的相似度来创建一棵有层次的嵌套聚类树。在聚类树中,不同类别的原始数据点是树的最低层,树的顶层是一个聚类的根节点。创建聚类树有自下而上合并和自上而下分裂两种方法,本篇文章介绍合并方法。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-fcKn9Lj6-1666660001284)(https://gitee.com/lyz-npu/typora-image/raw/master/img/20161207212645385)]
9.3.5 RANSAC优化特征匹配
为了更好地提高特征点匹配精度, 我们可以采用RANSAC 算法。 随机抽样一致算法( RANdom SAmple Consensus )
**RANSAC:**https://blog.csdn.net/robinhjwy/article/details/79174914,,,,,,非常重要的算法
使用了数据集内随机挑选的点拟合出一个模型,并计算数据集的点是否落在阈值内成为内点,不断迭代,迭代过程依据内点数量,计算找到内点最多效果最好的拟合的模型的数据,,,,,,,其价值在于去除离群点outlier,然后再使用剩余的inlier内点,使用xxx拟合算法求出较为准确的模型
单应矩阵理解:https://blog.csdn.net/lyhbkz/article/details/82254893


Mat cv::findHomography(InputArray srcPoints, //原始图像中特征点的坐标. CV_32FC2或者vector<Point2f>
InputArray dstPoints, //目标图像中特征点的坐标.
int method = 0, //计算单应矩阵方法的标志
double ransacReprojThreshold = 3, //重投影的最大误差.选择RANSAC和RHO时有用,
OutputArray mask = noArray(), //掩码矩阵,使用RANSAC 算法时表示满足单应矩阵的特征点.
const int maxIters = 3000, //RANSAC 算法法代的最大次数.
const double confidence = 0.995//置信区间,取值范围为0- 1 .
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

通过该函数优化匹配的特征点,需要判断输出的掩码矩阵中每一个元素是否为0. 如果不为0.那么表示该点是成功匹配的特征点, 边而在vector<DMatch>里寻找与之匹配的特征点, 将匹配结果放在新的存放DMatch 类型的向量中.
//RANSAC算法实现 void ransac(vector<DMatch> matches, vector<KeyPoint> queryKeyPoint, vector<KeyPoint> trainKeyPoint, vector<DMatch> &matches_ransac) { //定义保存匹配点对坐标 vector<Point2f> srcPoints(matches.size()), dstPoints(matches.size()); //保存从关键点中提取到的匹配点对的坐标 for (int i = 0; i<matches.size(); i++) { srcPoints[i] = queryKeyPoint[matches[i].queryIdx].pt; dstPoints[i] = trainKeyPoint[matches[i].trainIdx].pt; } //匹配点对进行RANSAC过滤 vector<int> inliersMask(srcPoints.size()); //Mat homography; //homography = findHomography(srcPoints, dstPoints, RANSAC, 5, inliersMask); findHomography(srcPoints, dstPoints, RANSAC, 5, inliersMask); //手动的保留RANSAC过滤后的匹配点对 for (int i = 0; i<inliersMask.size(); i++) if (inliersMask[i]) matches_ransac.push_back(matches[i]); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
第10章 立体视觉
10.1 单目视觉
10.1.1 单目相机模型
测量内参系数是使用摄像头之前首先要进行的步骤
相机的内参矩阵只与相机的内部参数相关, 因此称为内参矩阵。通过内参矩阵可以将相机坐标系下任意的三维坐标映射到像素坐标系中, 构建空间点与像素点之间的映射关系.

//非齐次坐标转换成齐次坐标
void cv::convertPointsToHomogeneous(InputArray src, //非齐次坐标,,vector<Pointnf>或者Mat
OutputArray dst//其次坐标,维数大1
)
//齐次坐标转换为非齐次坐标
void cv::convertPointsFromHomogeneous(InputArray src,
OutputArray dst
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
10.1.2 标定板角点提取
https://zhuanlan.zhihu.com/p/94244568

bool cv::findChessboardCorners(InputArray image,
Size patternSize, //图像中棋盘内角点行数和列数.
OutputArray corners, //在vector<Point2
ing flags = CALIB_CB_ADAPTIVE_THRESH+CALIB_CB_NORMALIZE_IMAGE//检测内角点方式的标志
)
- 1
- 2
- 3
- 4
- 5
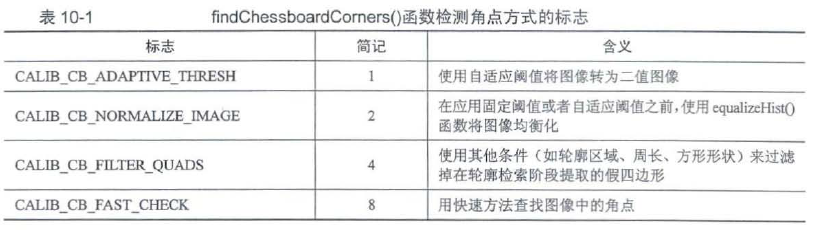
findChessboardComers()函数检测到的内角点坐标只是近似值,为了更精确地确定内角点坐标,可以使用我们前面介绍过的计算亚像素角点坐标的comerSubPix()函数.此外. OpenCV4也有专用于提高标定板内角点坐标精度的find4QuadConerSubpix()函数。
bool cv::find4QuadConerSubpix(InputArray img,
InputOutputArray corners, //待优化的内角点坐标
Size region_size//优化坐标时考虑的邻域范围。
)
- 1
- 2
- 3
- 4
//对于圆形标定板
bool cv::findCirclesGrid(InputArray image,
Size patternSize, //图像中每行和每列圆形的数目.
OutputArray centers,
int flags = CALIB_CB_SYMMETRIC_GRID, //检测圆心的操作标志
const Ptr<FeatureDetector> & blobDetector = SimpleBlobDetector::create()//在浅色背景中寻找黑色圆形斑点的特征探测器.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
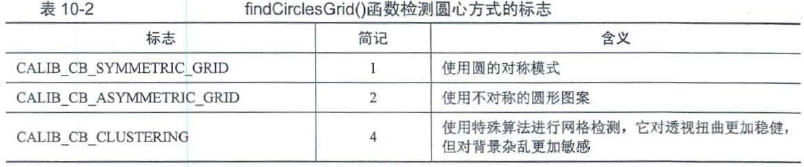
//绘制角点位置
void cv::drawChessboardCorners(InputArray image, //需要绘制角点的目标图像,必须是CU_8U 类型的彩色图像.
Size patternSize, //标定板每行和每列角点的数目.
InputArray corners, //检测到的角点坐标数组.
bool patternWasFound//绘制角点样式的标志,用于显示是否找到完整的标定板.
)
- 1
- 2
- 3
- 4
- 5
- 6
10.1.3 单目相机标定
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CpCz6Uum-1666660001286)(https://gitee.com/lyz-npu/typora-image/raw/master/img/%E5%9B%BE10-6.png)]

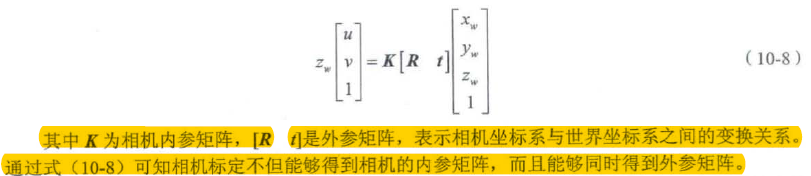

相机标定主要是计算机相机内参矩阵和相机畸变的5个系数
double cv::calibrateCamera(InputArrayOfArrays objectPoints,
InputArrayOfArrays imagePoints,
Size imageSize,
InputOutputArray cameraMatrix,
InputOutputArray distCoeffs,
OutputArrayOfArrays rvecs,
OutputArrayOfArrays tvecs,
int flags = 0,
TermCriteria criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS, 30, DBL_EPSILON))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
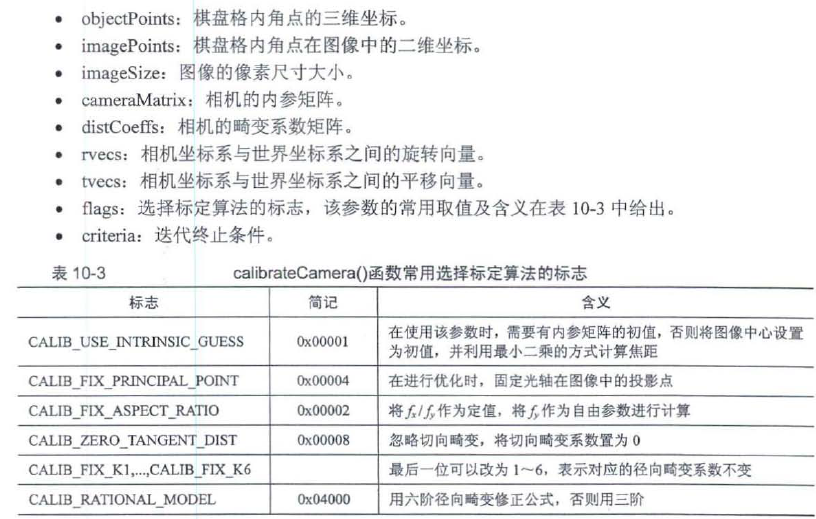
10.1.4 单目相机校正
在得到相机的畸变系数矩阵后,可以根据畸变模型将图像中的畸变去掉,生成理论上不含畸变的图像,
一:initUndistortRectifyMap()——remap()
二:unidistort()
void cv::initUndistoritRectifyMap(InputArray cameraMatrix,
InputArray distCoeffs,
InputArray R,
InputArray newCameraMatrix,
Size size,
int mltype,
OutputArray map1,
OutputArray map2
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

void cv::remap(InputArray src,
OutputArray dst,
InputArray map1,
InputArray map2,
int interpolation,
int borderMode = BORDER_CONSTANT,
const Scalar & borderValue = Scalar()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

//直接矫正
void cv::undistort(InputArray src,
OutputArray dst,
InputArray cameraMatrix,
InputArray distCoeffs,
InputArray newCameraMatrix = noArray()
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

10.1.5 单目投影
单目投影是指根据相机的成像模型计算空间中三维坐标点在图像二维平面中坐标的过程.OpenCV4 中提供了projectPoints()函数用于计算世界坐标系中的三维点投影到像素坐标系中的二维坐标
void cv::projectPoints(InputArray objectPoints,
InputArray rvec,
InputArray tvec,
InputArray cameraMatrix,
InputArray disCoeffs,
OutputArray imagePoints,
OutputArray jacobian = noArray(),
double aspectRatio = 0
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

10.1.6 单目位姿估计

bool cv::solvePnP(InputArray objectPoints,
InputArray imagePoints,
InputArray cameraMatrix,
InputArray disCoeffs,
OutputArray rvec,
OutputArray tvec,
bool useExtrinsicGuess = false,
int flags = SOLVEPNP_ITERATIVE
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9






第11章 视频分析
.本章中将重点介绍如何检测视频中移动的物体,并对移动物体进行跟踪, 主要的方法有差值法、均值迁移法和光流法.
11.1 插值法检测移动物体
//用于计算两个图像差值的绝对值
void cv::absdiff(InputArray src1,
InputArray src2,
OutputArray dst
)
- 1
- 2
- 3
- 4
- 5
11.2 均值迁移法目标跟踪
11.2.1 均值迁移法实现的目标跟踪
均值迁移法能够实现目标跟踪,其原理是首先计算给定区域内的均值, 如果均值不符合最优值条件, 那么将区域向靠近最优条件的方向移动, 经过不断地法代来找到目标区域。
均值迁移法又可以称为爬山算法。


int cv::meanShift(InputArray probImage, //目标区域的直方图的反向投影
Rect & window, //初始搜索窗口和搜索结束时的窗口
TermCriteria criteria//迭代停止算法
)
- 1
- 2
- 3
- 4
//鼠标选取目标区域
Rect cv::selectROI(const String & windowName,
InputArray img, //选择ROI 区域的图像.
bool showCrosshair = true, //是否显示选择矩形中心的十字准线的标志.
bool fromCenter = false//ROI 矩形区域中心位置标志.当该参数值为true 时,鼠标当前坐标为ROI 矩形的中心,当该参数值为false时,鼠标当前坐标为ROI 矩形区域的左上角.
)
- 1
- 2
- 3
- 4
- 5
- 6
11.2.2 自适应均值迁移法实现的目标跟踪
自适应均值迁移法对均值迁移法进行了改进,使得可以根据跟踪对象的大小自动调整搜索窗口的大小。除此之外,改进的均值迁移法不但能返回跟踪目标的位置, 而且能够返回角度信息.
RotateRect cv::Camshift(InputArray probImage,
Rect & window,
TermCriteria criteria
)
- 1
- 2
- 3
- 4
11.3 光流法目标跟踪
光流是空间运动物体在成像图像平面上投影的每个像素移动的瞬时速度, 在较短的时间间隔内可以等同于像素点的位移。在忽略光照变化影响的前提下,光流的产生主要是由于场景中目标的移动、相机的移动或者两者的共同运动。光流表示了图像的变化,由于它包含了目标运动的信息, 因此可被观察者用来确定目标的运动情况,进而实现目标跟踪.

光流法要求像素移动较小距离,但是有时得到的连续图像中像素的移动距离较大,此时需要采用图像"金字塔" 来解决大尺度移动的问题.
根据计算光流速度的像素点数目, 光流法可以分为稠密光流法(所有像素都要使用)和稀疏光流法.(只使用部分像素点)
11.3.1 Farneback多项式扩展算法
void cv::calcOpticalFlowFarnback(InputArray prev,
InputArray next,
InputOutputArray flow,
double pyr_scale,
int levels,//金字塔层数
int winsize, //均值窗口的尺寸
int iterations,
int ploy_n, //在每个像素中找到多项式展开的像素邻域的大小.
double poly_sigma, //高斯标准差.
int flags//计算方法标志. 当该参数值为OPTFLOW_USE_INITIAL_FLOW时, 表示使用输入流作为初始流的近似值:当该参数值为OPTFLOW_FARNEBACK_GAUSSIAN时,表示使用离斯滤波器代替方框滤波器进行光流估计.
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
//计算二维向量方向和模长
void cv::cartToPolar(InputArray x,
InputArray y,
OutputArray magnitude,
OutputArray angle,
bool angleInDegrees = false
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
稠密光流法常用于相机固定的视频数据的目标跟踪.
11.3.2 基于LK稀疏光流法的跟踪
https://blog.csdn.net/a_31415926/article/details/50515835
//TermCriteria终止条件
cv::TermCriteria::TermCriteria(int type, //判定迭代终止的条件类型,要么只按count算,要么只按EPS算,要么两个条件达到一个就算结束
int maxCount, //具体的最大迭代的次数是多少
double epsilon//具体epsilon值是多少
)
/*
COUNT:按最大迭代次数算
EPS:就是epsilon,按达到某个收敛的阈值作为求解结束标志
COUNT + EPS:要么达到了最大迭代次数,要么按达到某个阈值作为收敛结束条件。
*/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
void cv::calcOpticalFlowPyrLK(InputArray prevImg,
InputArray nextImg,
InputArray prePts,
InputOutputArray nextPts,
OutputArray status,
OutputArray err,
Size winSize = Size(21,21),
int maxLevel = 3,
TermCriteria criteria = TermCriteria(TermCriteria::COUNT+TermCriteria::EPS,30,0.01)
int flags = 0,
double minEigThreshold = 1e-4
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

calcOpticalFlowPyrLK()函数需要人为输入图像中稀疏光流点的坐标,通常情况下可以检测图像中的特征点或者角点,将特征点或者角点的坐标作为初始稀疏光流点的坐标输入
最大的问题:角点数目越来越少,因此需要时刻统计跟踪的焦点数目,当角点数目小于一定阈值时,需要再次检测角点,以增加角点数目。如果图像中有不运动的物体,那么每幅图像中都能检测到这些物体上的角点,从而使得角点数目一直高于阈值,然而这些固定的特征点不是我们需要的,因此需要判断角点在两帧图像中是否移动,删除不移动的角点,进而跟踪移动的物体。

