
学习笔记——对抗攻击模型_attack攻击模型
赞
踩
以下内容来源与李宏毅老师的课程。
现在希望machine learning model不仅能够对抗一般的杂讯,还希望其能对抗一些人类恶意制造出来的想要骗过机器的恶意的攻击
- 对噪声鲁棒且“大部分时间”工作的分类器是不够的
- 我们希望分类器是健壮的可以应付带有恶意的输入讯息的
那真的有一些恶意的信息想要骗过机器的吗?其实生活上还是有的,比如一些垃圾信息,恶意软件,还有一些网络入侵。就以垃圾信息为例,普通的垃圾信息是可以被机器拦截的,但是如果其带有一些恶意的杂讯,骗过了机器,这就是一种恶意的攻击。
现在发现,攻击是比较容易的,而防御是比较困难的
一、攻击
1.对抗攻击基本概念
对于一张图片使其带有一些特殊的认为的信息,而不是一些随机高斯分布的信息,因为这些随机高斯分布的信息是不能对机器造成太大的影响的。而将这加了特殊信息的图片,丢带机器中去识别,便会得到不一样的结果。这个就是所谓攻击要去做的事情。

而现在的问题就变成了如何找出这个特别的信息△x
- Training:
一般的过程就是,通过调整一个神经网络的参数,使得输入一张图片后得到的结果与真实的结果相似,不断训练的使得输出值与真实值的交叉熵越小越好。
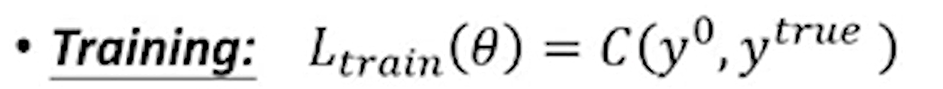
- Non-targeted Attack(无目标攻击):
对于无目标攻击中,现在想要找到一个杂讯的信息,让其添加到原来的图片上,并借此希望骗过机器,使得这个输出与原来的真实值可以差距越大越好。与上面的训练方式是不一样的,对于正常的训练来说,其输入是固定的,并希望通过改变网络的参数来调整输出。而对于无目标攻击来说,其网络的参数是固定的,因为这是我们想要骗过的机器,然后我们需要调整输入使得可以得到一个不一样的结果。
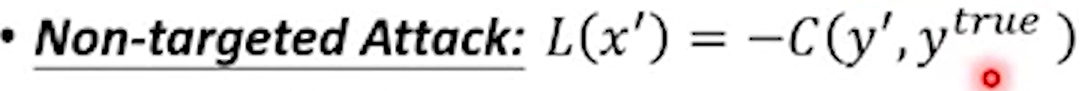
- Targeted Attack(有目标攻击):
如果是有目标的攻击,就不仅仅希望加入了杂讯的输出值可以与真实值的差距越大越好,同时还希望其可以与一个错误的答案越近越好。这个错误的答案是自己设计的,是为了让攻击的目标想让输入的图片变成什么的东西。注意这个Ytrue与Yfalse都是一个独热编码,其中一位是1,其他都是0
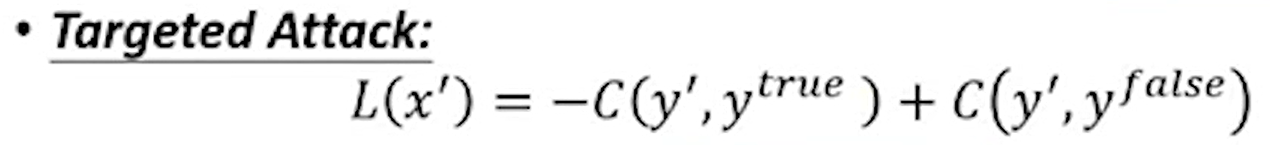
- Constraint:
但是现在会有一个新的限制,会希望杂讯与输入越接近越好,直到人没有办法发现其中的差异就最好了,但是实际上是有一点点的不同。也就是这个原输入与杂讯的某种距离是小于某一个阈值的。
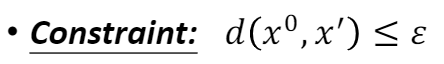
大概的流程:

对于上面这两者的距离,有两种方法可以计算出来:

1)L2-norm

也就是将相减后的结果求一个平方和
2)L-infinity

也就是去相减之后最大的那个值
其实,也就是有很多种的distance,可以根据不同的任务进行不同的设计,取决于人类的感知来定义这个L。不过在影像的攻击上面,L-infinity可能是比较好的。举一个例子:

在上面的这个图像中,其中一个是对每一个像素稍稍调整的结果,而另外一个是对其中的一个像素调整的结果。这两个输出与输入的原图的L2-norm的distance是一样的,但是对人眼来说,这两者看起来的不一样的,因为觉得第一个输出甚至都没有啥变化。而如果用L-infinity来计算,上面的两张距离是比较小的,而下面的两张图片的L-infinity是比较大的。
现在定义了distance的计算公式,然后可以得到一个优化函数:
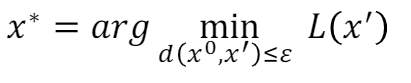
现在是希望能够找到一个杂讯可以使得输出值与真实值差距越大越好,并且希望这个杂讯与原输入的L-infinity不能超过某一个阈值。就像训练一个神经网络,只是网络参数
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

