
python实战-HTML形式爬虫-批量爬取电影下载链接_批量下载电影
赞
踩
文章目录
- 一、前言
二、思路
1、网站返回内容
2、url分页结构
3、子页面访问形式
4、多种下载链接判断
三、具体代码的实现
四、总结
一、前言
喜欢看片的小伙伴,肯定想打造属于自己的私人影院,在线观看的话会有很多限制,所以可以到专门下载电影的网站下载自己想看的电影,如果想要下载大量电影的话,一个一个手点击页面去点击下载链接,实在让人崩溃,那么可以通过技术手段方便我们获取电影链接,看过我前面文章的小伙伴就知道了,我们可以采用python爬虫的形式去批量爬取电影下载链接,然后批量下载,岂不美哉。
对python爬虫还没有了解的小伙伴可以先看看这一片内容(基于python爬虫快速入门),上篇在html形式讲解的代码示例就以及获取了子页的链接,那么接下来将就是继续上手实战,敏感内容我会打码,主要学习的是思路。
https://blog.csdn.net/syl321314362/article/details/127780756
- 1
二、思路
首先我们第一步先是分析目标网站的请求结构,页面是怎么返回渲染的,分页形式是怎么样的,子页面是怎么样的形式访问,电影下载链接有没有不同形式的,所以弄大体的结构才有好的思路,把思路用代码的方式实现。
1、网站返回内容
首先我们可以打开浏览器的开发工具页面(快捷键 F12),通过网络请求查看对应的请求去判断,也可以直接python写一个request请求,看看response.text返回的是不是想要的页面html。
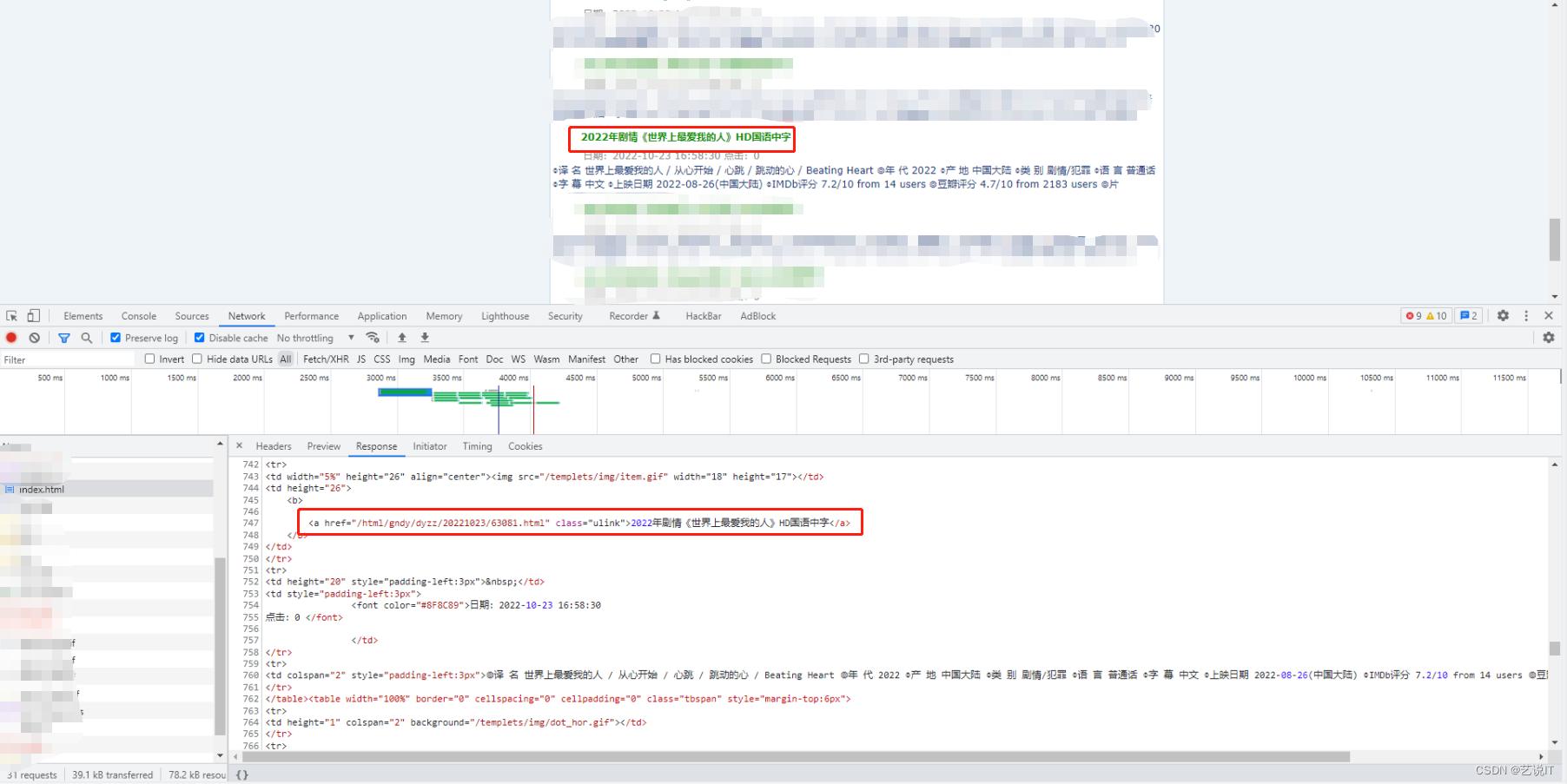
2、url分页结构
电影肯定有很多,所以制作网页的时候要采取分页展现的设计,所以要点击分页栏,查看地址栏url的变化,滚动式加载也是这种思路,观察地址栏url或者网络请求的变化。
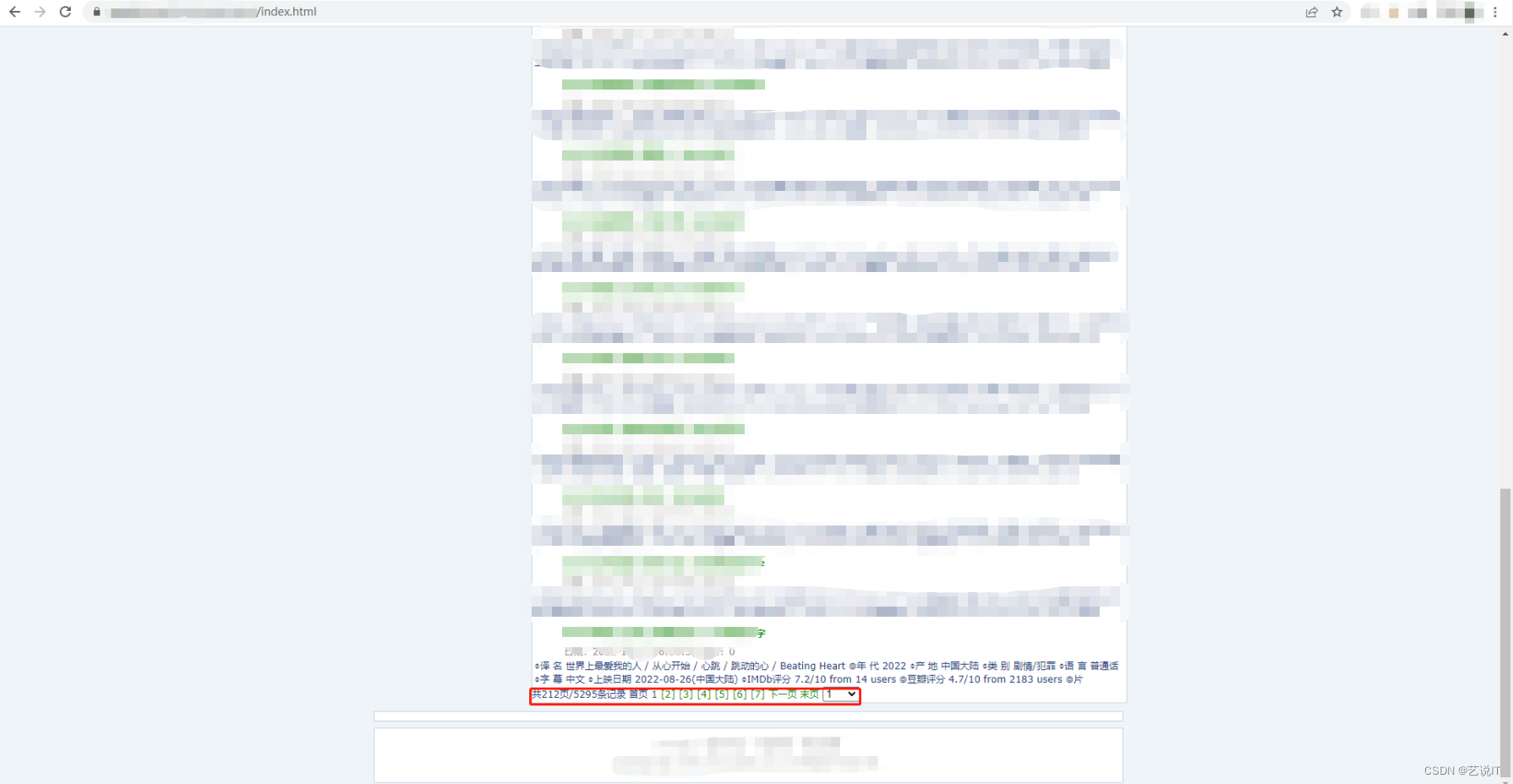
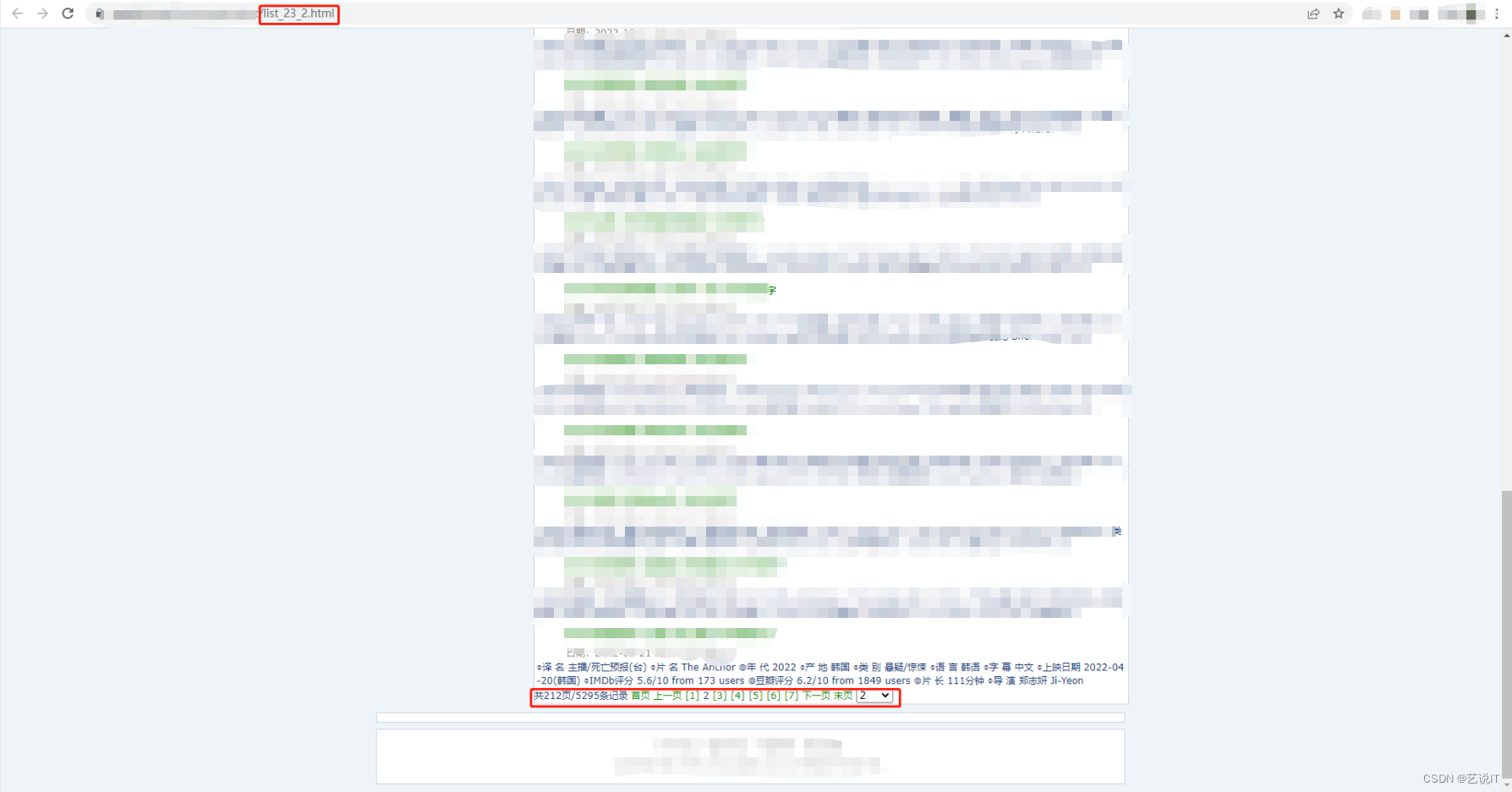
可以看到地址栏中的url明显的有变化,所以这里一共有212页所以就是list_23_1.html 到 list_23_212.html,我们去页面证实一下,果然没错。
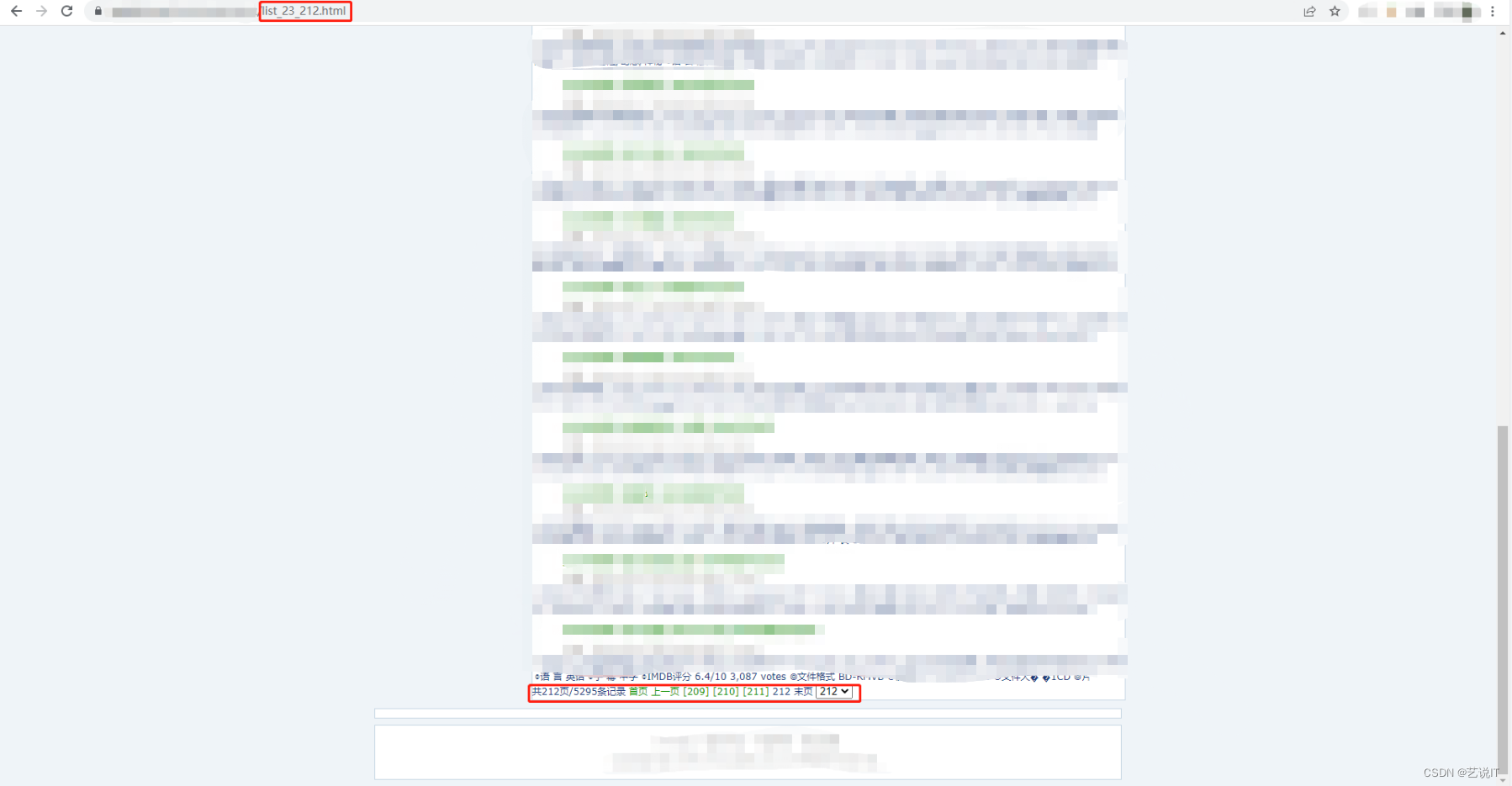
所以批量爬取就要搞清楚目标的页面结构,那么我们知道有这么多页的时候就要通过for循环去遍历这212页的内容,去匹配获取子页面。
3、子页面访问形式
通过子页面与主页的url拼接即可访问,url = “https://xxxx” + “/html/gndy/dyzz/20221109/63138.html”

4、多种下载链接判断
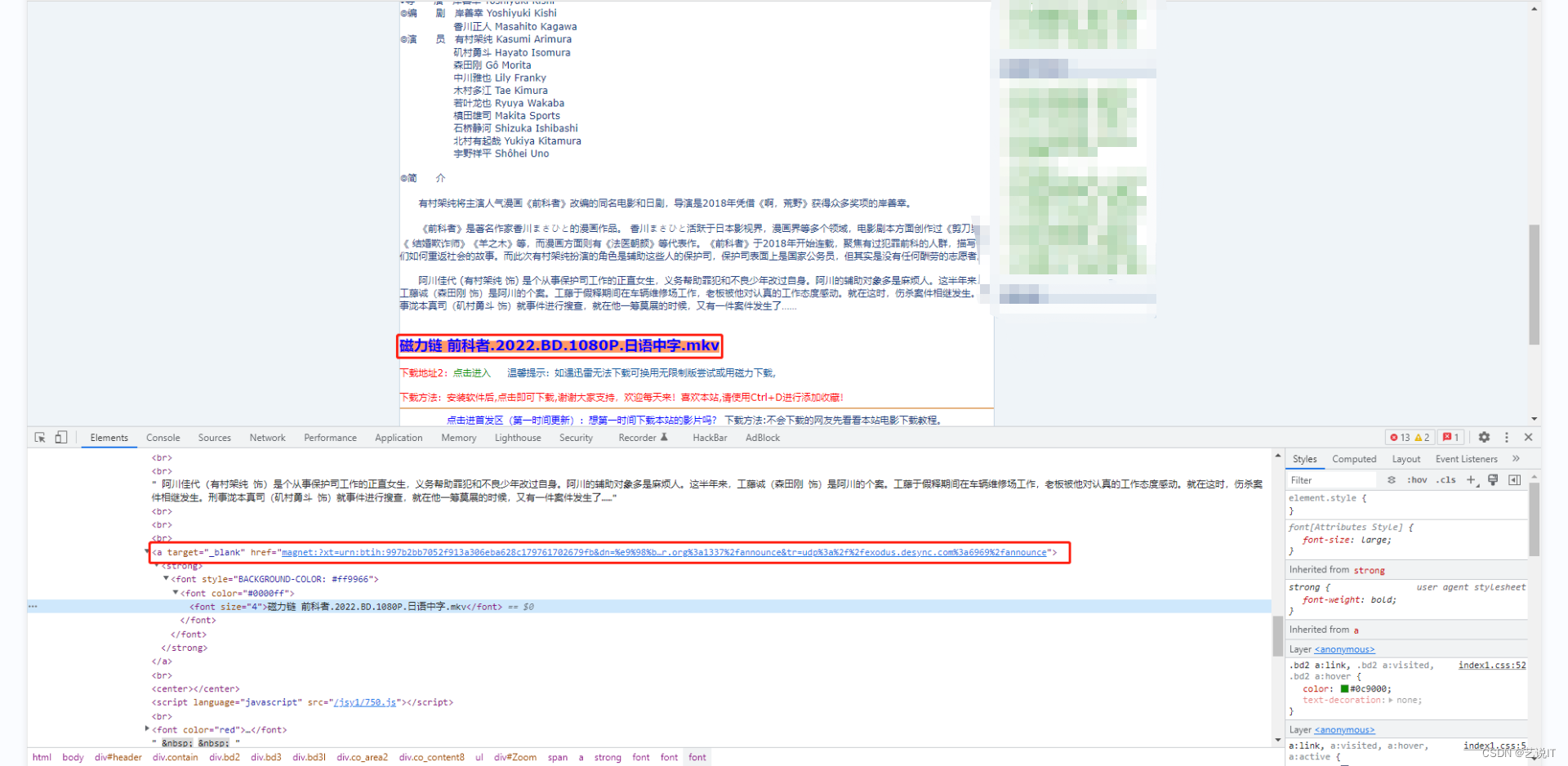
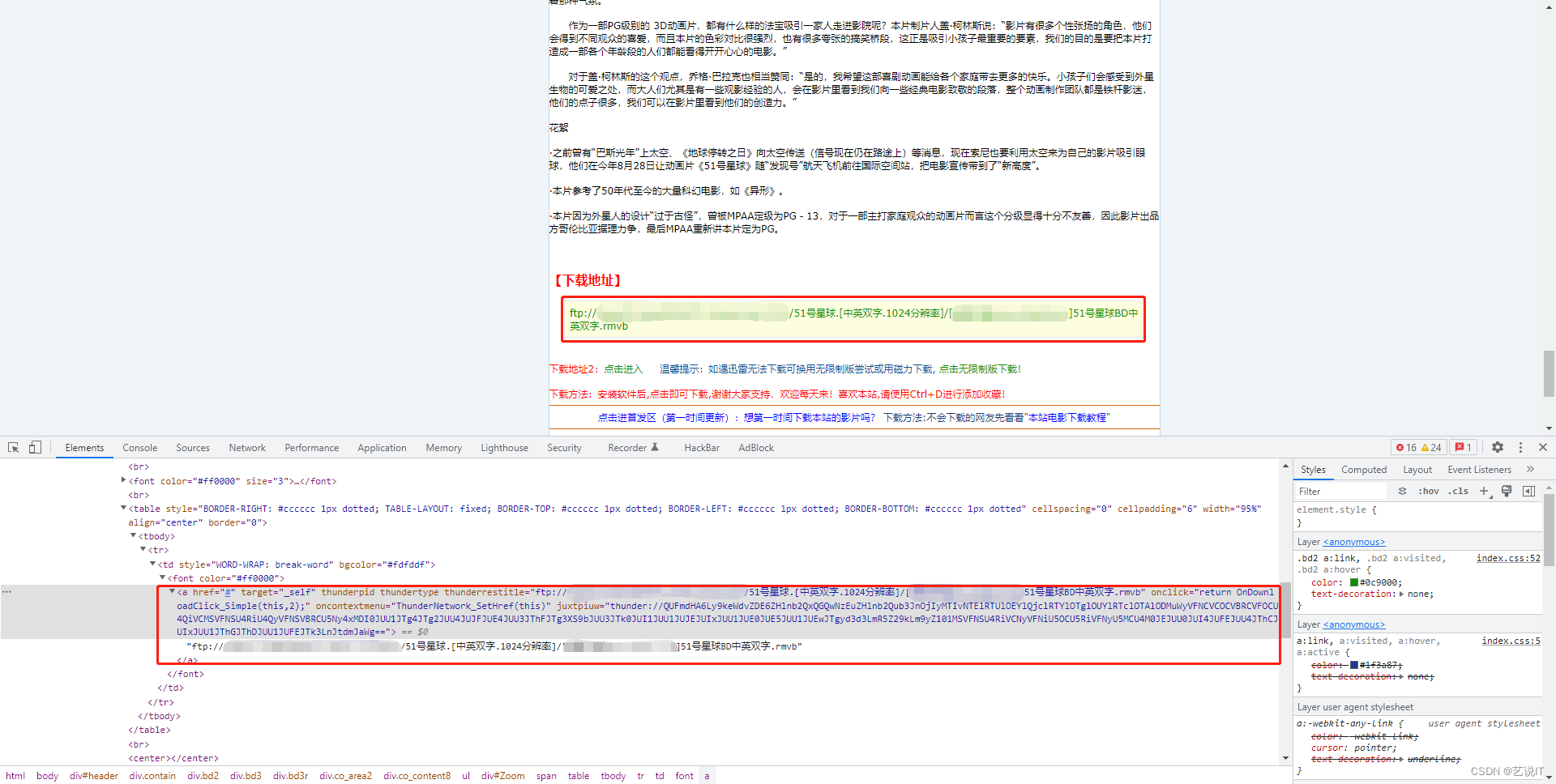
每个子页面的的链接展现的形式是不同的,所以我们要多点击几个子页观察有哪些不同的地方,在爬取链接的时候就需要多加注意多加判断。
实例就有两种形式的链接ftp和magnet,所渲染的标签样式与视频后缀名也是有些差别的。
三、具体代码的实现
运行前先安装lxml库
pip install lxml
- 1
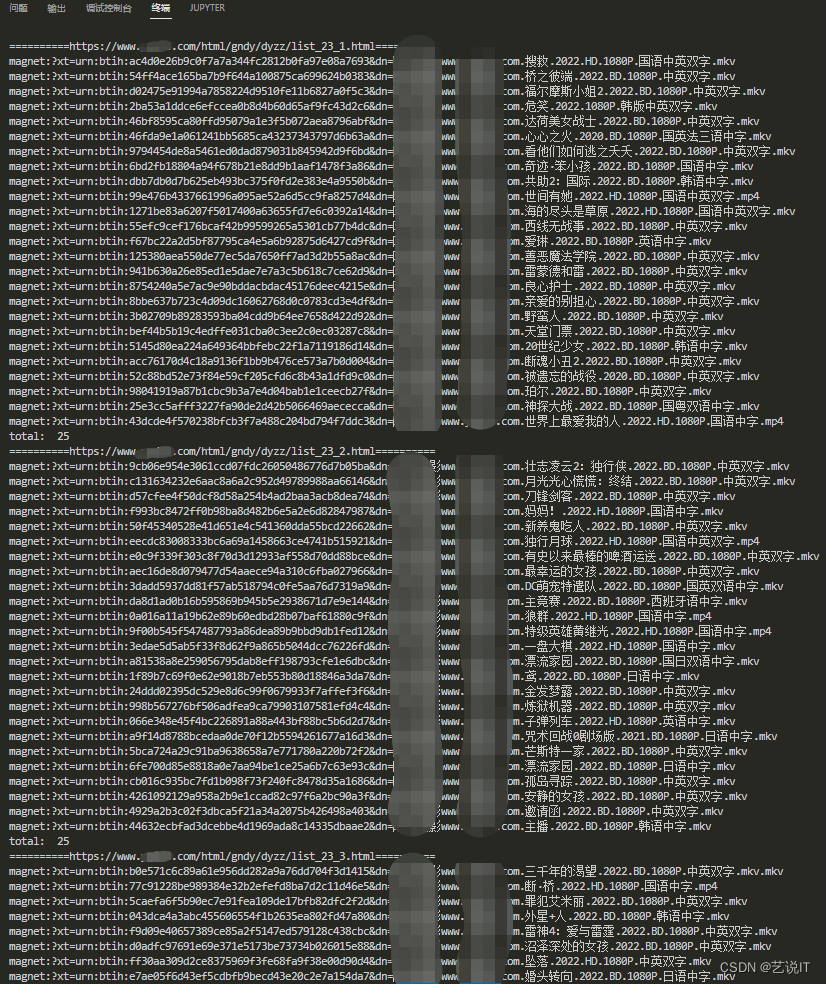
import re import time import urllib3 import requests from lxml import etree from urllib.parse import unquote # 解决requests请求出现的InsecureRequestWarning错误 urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning) header = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:40.0) Gecko/20100101 Firefox/40.1' } for i in range(1, 215): # 分页页面首页 indexUrl = "https://www.xxxxx.com/html/gndy/dyzz/list_23_{}.html".format(i) print("="*10 + indexUrl + "="*10) res = requests.get(indexUrl, headers=header, verify=False) if res.status_code == 200: lxml_tree = etree.HTML(res.content) # 获取分页页面中的电影页面路径 href_name = lxml_tree.xpath( '//div[@class="co_content8"]//table//a//@href') if len(href_name) < 25: lxml_tree = etree.HTML(res.text) href_name = lxml_tree.xpath( '//div[@class="co_content8"]//table//a//@href') for urlPath in href_name: if "/html/gndy/dyzz/" in urlPath: try: # 拼接详细电影页面url url = "https://www.xxxxx.com" + urlPath res2 = requests.get(url=url, headers=header, verify=False) if res2.status_code == 200: # 防止中文乱码 res2.encoding = "GBK" lxml_tree2 = etree.HTML(res2.text) # 获取电影下载链接 href_name2 = lxml_tree2.xpath( '//div[@id="Zoom"]//a//@href') if href_name2: # 正则匹配获取mkv或mp4格式链接或rmvb格式 pattern = re.compile(r'.*.mkv|.*.mp4|.*.rmvb') film = pattern.search(unquote(href_name2[0]))[0] print(film) #下载链接写入文本 with open("allFilm.txt", "a", encoding="utf-8") as f: f.write(film + "\n") else: # 记录访问错误的页面 with open("fail.txt", "a", encoding="utf-8") as f: f.write(url + "\n") time.sleep(1) except Exception as e: print("errer: ", e) continue print("total: ", len(href_name))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
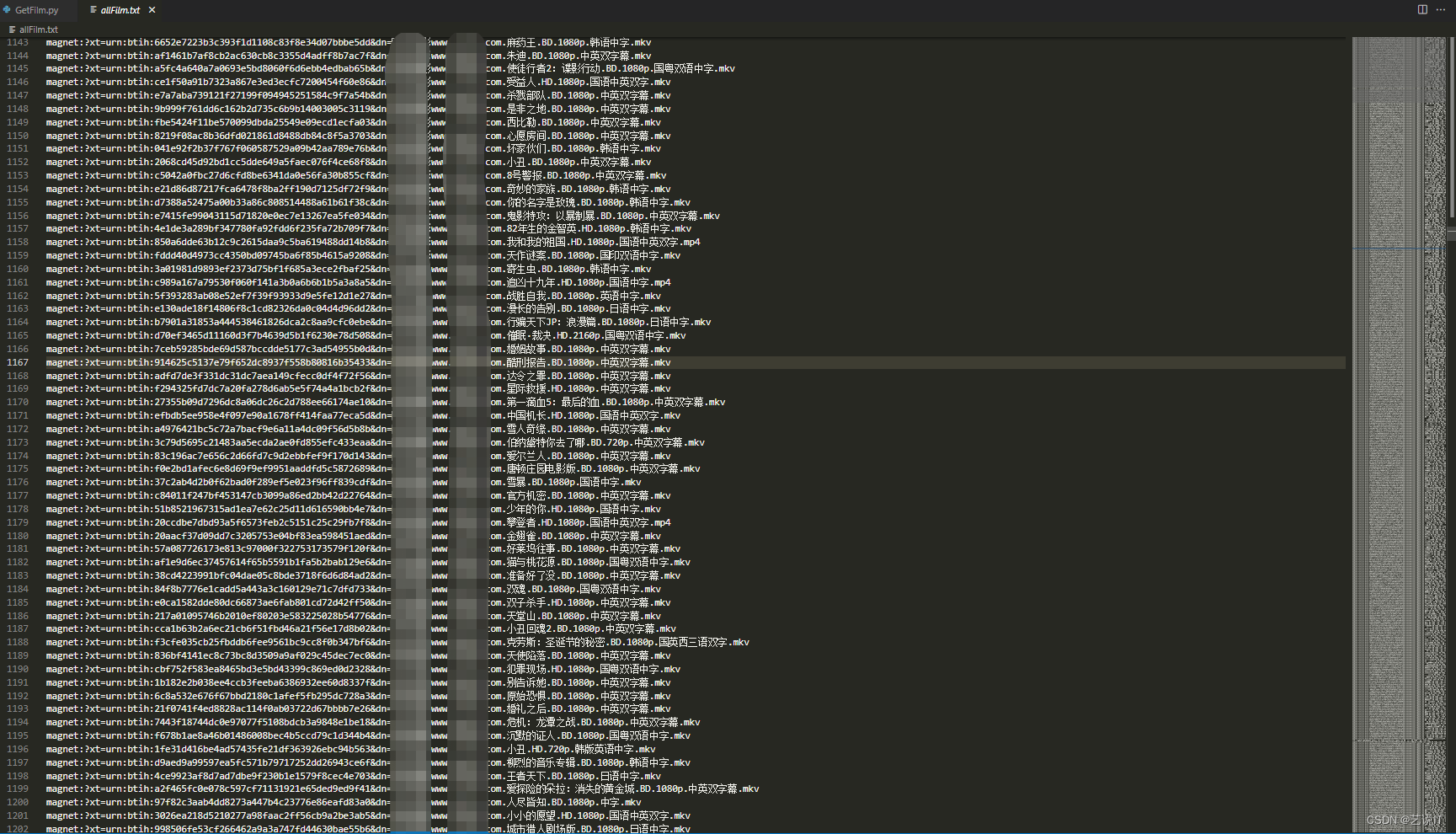
四、总结
技术是一把双刃剑,就看持剑的人是怎么想的,爬虫有风险,操作需谨慎,爬虫被判刑的例子比比皆是,需谨慎。关注我,后续有这两种形式的python实战爬虫还有反防爬虫(反反爬虫)等技术干货,并附带源码,对你有帮助请点个赞,感谢各位帅哥美女。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,Python自动化测试学习等教程。带你从零基础系统性的学好Python!
一、Python学习大纲
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python必备开发工具

三、入门学习视频
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
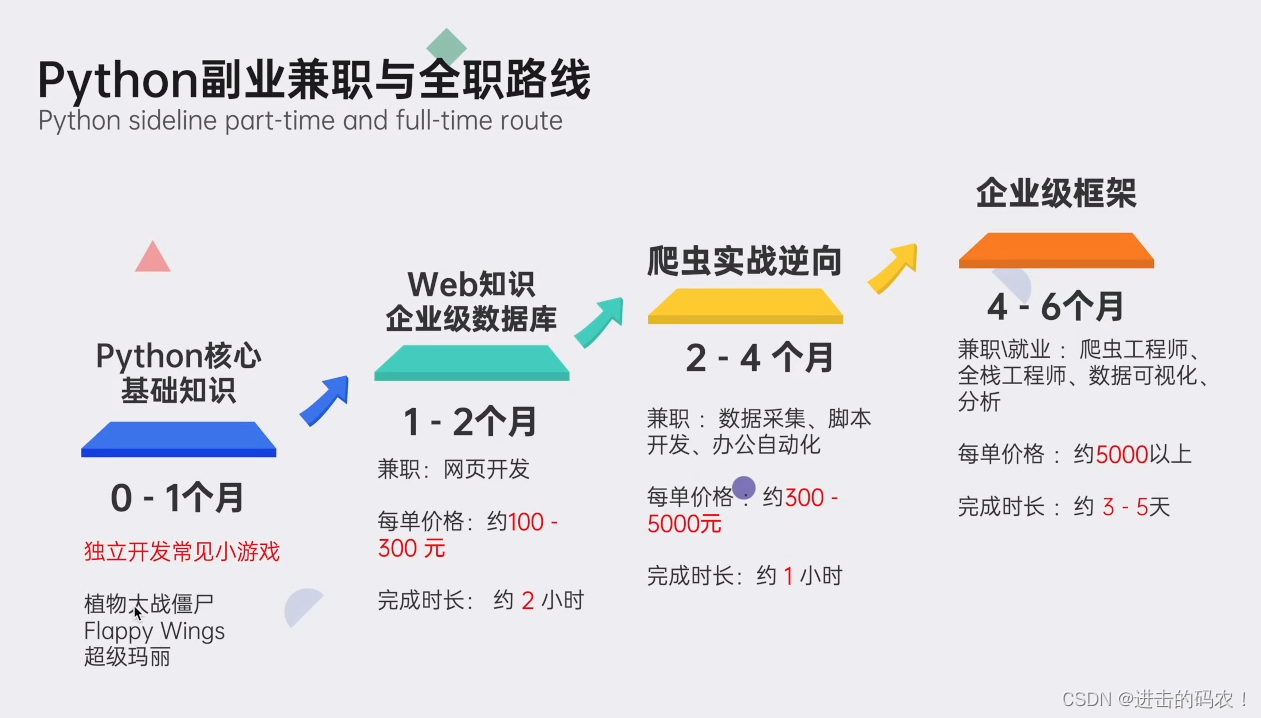
五、python副业兼职与全职路线
上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/393351

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

