- 1利用逻辑回归进行鸢尾花分类_鸢尾花逻辑回归
- 2Unity2019.4.16安卓环境及AR环境安装_com.preface.unity.lib.bridge.apibridge
- 3MySQL too many connections 之解决方法_too many connections"}
- 4具有非线性不确定干扰的多智能体系统的固定时间事件触发一致性控制(附论文链接+源码Matlab)_随机 固定时间 一致性 时滞
- 5Hello算法6:哈希表
- 6CentOS系统中使用yum快速安装python3_centos yum python3
- 720款超级好用的idea插件,开发效率翻倍!!!_idea实用插件
- 8使用TensorFlow Serving进行模型的部署和客户端推理_tensorflow server
- 9dom型xss ---(waf绕过)_dom类xss如何判断
- 10笑死!推特限流,微博赢麻了;使用ChatGPT撰写简历;SD电脑配置推荐;斯坦福67门AI课程学习路径 | ShowMeAI日报
Python基础入门教程(上)_python文字教程
赞
踩
目录
一、你好Python
1.1、Python安装
win版
双击打开下载的安装包
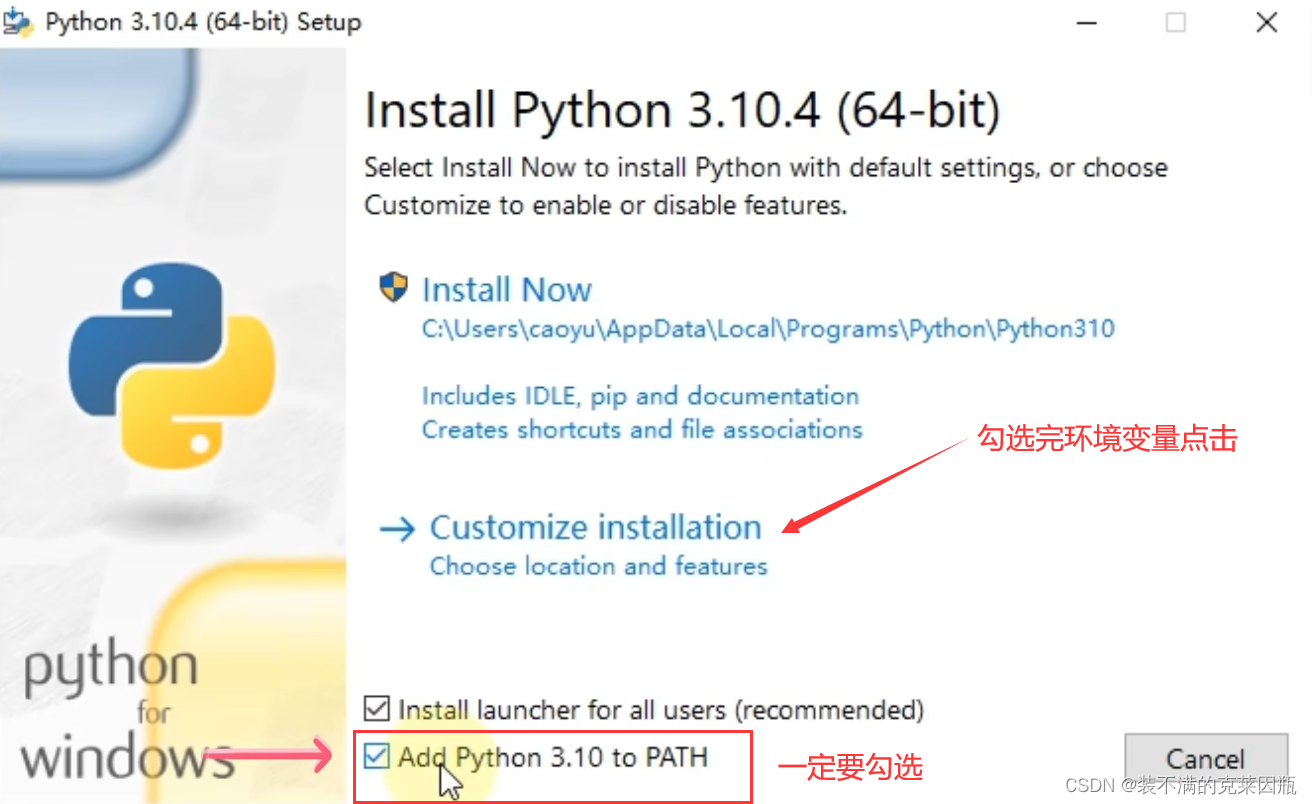
后面直接默认就行,尽量把盘符变为非系统盘。
验证一下python是否安装成功,使用python --version命令即可。
Linux版
首先我们不管是Centos还是Ubuntu,都有个自带的Python。
第一步:在Linux上安装Python需要先安装前置依赖程序。
登陆到Linux中,使用yum程序进行依赖程序安装,执行如下命令:
yum install wget zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make zlib zlib-devel libffi-devel -y
第二步:下载Python3.10.4
注意:正常来说我们都去python官网下载,但由于网速原因,所以我们这里提供了安装包,要的可以私聊我。
第三步:解压python-3.10.4.tgz
tar -xvf Python-3.10.4.tgz第四步:configure配置
- cd Python-3.10.4
- ./configure --prefix=/usr/local/python3.10.4
Python将会安装到/usr/local/python3.10.4路径下。
第五步:编译和安装
make && make install这个过程时间有点长,耐心等待...
第六步:查看安装后的文件
- cd /usr/local/python3.10.4/
- ll

第七步:创建软链接
由于系统默认有个python环境,是2.7.5的,所以我们先要删除老版本的软链接。
rm -rf /usr/bin/python创建软链接
ln -s /usr/local/python3.10.4/bin/python3.10 /usr/bin/python第八步:查看Python版本,看是否安装成功
python --version
第九步:修改yum安装依赖
为什么要修改?因为在Linux系统中,yum这个程序本质上使用的是Python2的老版本,但因为我们刚才已经把老版本的Python给顶替掉了,所以yum此时是不能正常运行的。
vi /usr/libexec/urlgrabber-ext-down
将python改为python2
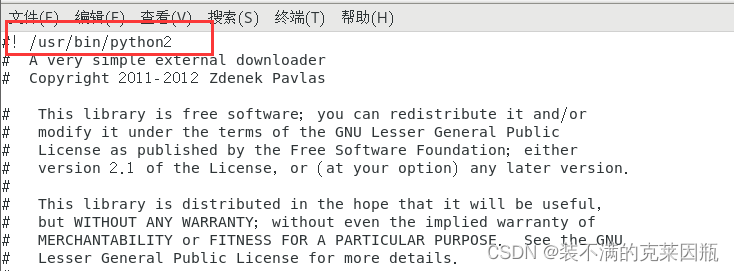
保存即可。
vi /usr/bin/yum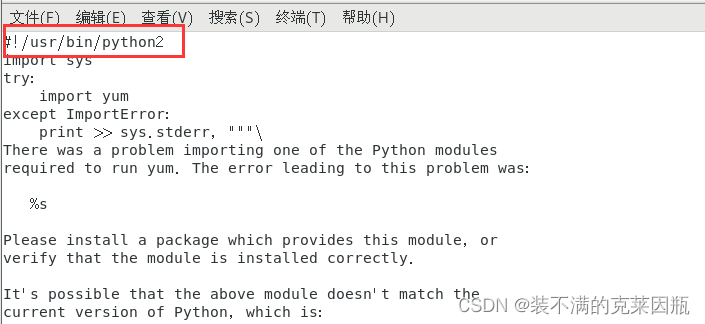
还是将第一行改为python2。
1.2、第一个Python程序
打开DOS窗口,输入python。
开始编程,输入代码:
print('HelloWorld')
二、Python基本语法
2.1、字面量
字面量:在代码中,被写下来的固定的值,称之为字面量。
示例代码:
- 15
- 13.14
- "字面量"
2.2、注释
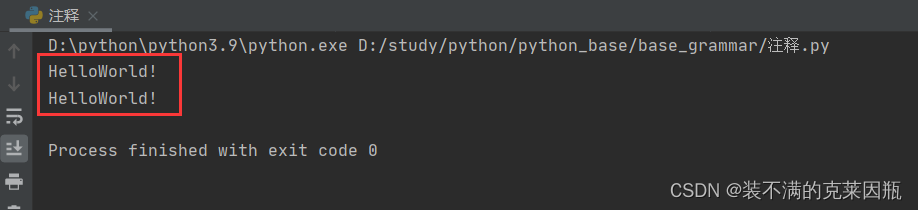
注释:注释不是程序,不能被执行,只是对程序代码进行解释说明,让别人可以看懂程序代码的作用,能够大大增强程序的可读性。
单行注释:以 #开头,#右边的所有文字当作说明,而不是真正要执行的程序,起辅助说明作用。
多行注释:以 一对三个双引号 引起来 ( """注释内容""" )来解释说明一段代码的作用使用方法。
示例代码:
- # 我是单行注释
- print("HelloWorld!")
-
- """
- 我是多行注释
- 我可以注释多行
- """
- print("HelloWorld!")
2.3、变量
变量:变量的特征就是,变量存储的数据,是可以发生改变的。
示例代码:
- name = '张飞'
- print("我的名字是:", name)
- name = '赵云'
- print("改过后的名字是:", name)
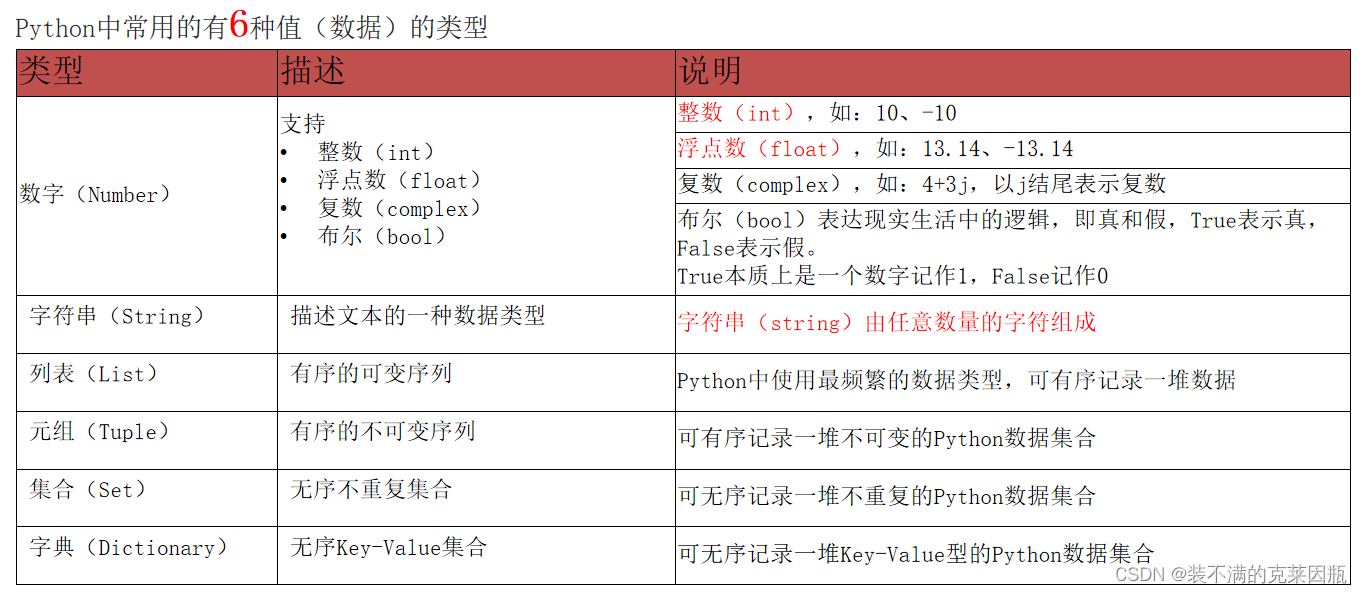
2.4、数据类型
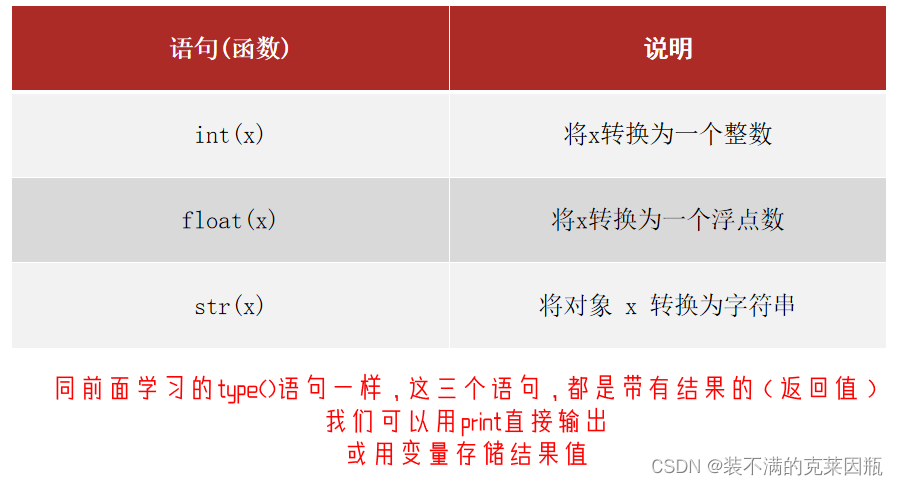
type()函数
我们可以通过type()语句来得到数据的类型:type(被查看类型的数据)
示例代码:
- name = "张飞"
- print(type(name))
- print(type(13.14))

字符串类型的不同定义方式
示例代码:
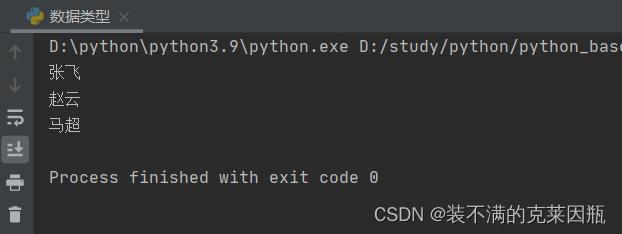
- name = "张飞"
- name1 = '赵云'
- name2 = """马超"""
- print(name)
- print(name1)
- print(name2)
2.5、数据类型转换
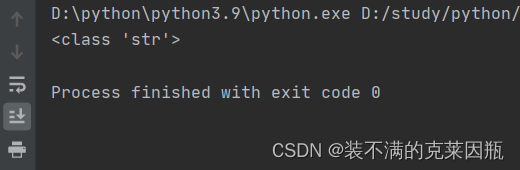
示例代码:
- num = 1
- print(type(str(num)))
2.6、标识符
在Python程序中,我们可以给很多东西起名字,比如: 变量的名字 方法的名字 类的名字,等等 这些名字,我们把它统一的称之为标识符,用来做内容的标识。 所以。
标识符: 是用户在编程的时候所使用的一系列名字,用于给变量、类、方法等命名。
标识符命名中,只允许出现: 英文 中文 数字 下划线(_) 这四类元素。而且大小写敏感,不能以数字开头, 其余任何内容都不被允许。
2.7、运算符
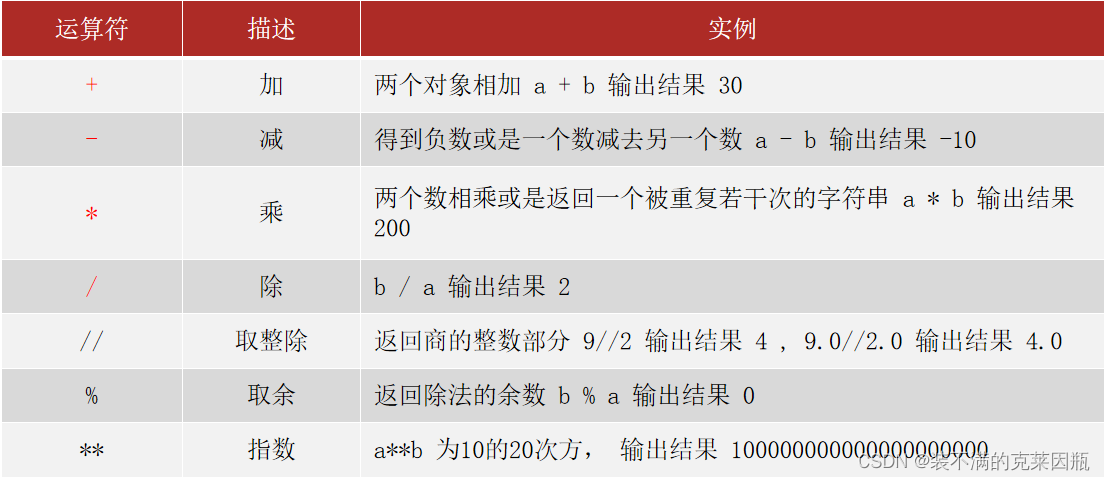
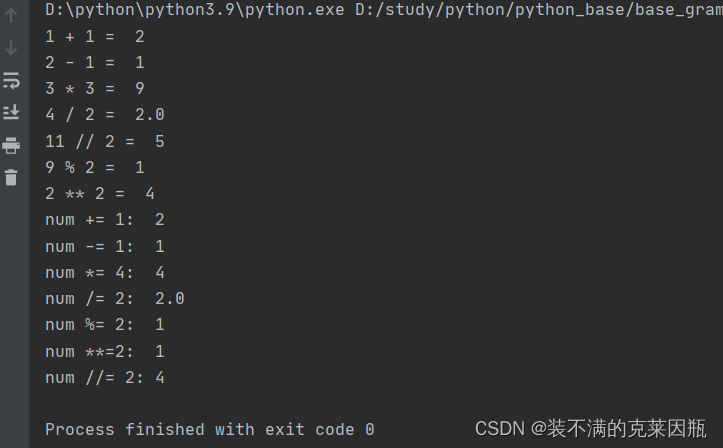
示例代码:
- """
- 演示Python中的各类运算符
- """
- # 算术(数学)运算符
- print("1 + 1 = ", 1 + 1)
- print("2 - 1 = ", 2 - 1)
- print("3 * 3 = ", 3 * 3)
- print("4 / 2 = ", 4 / 2)
- print("11 // 2 = ", 11 // 2)
- print("9 % 2 = ", 9 % 2)
- print("2 ** 2 = ", 2 ** 2)
- # 赋值运算符
- num = 1 + 2 * 3
- # 复合赋值运算符
- # +=
- num = 1
- num += 1 # num = num + 1
- print("num += 1: ", num)
- num -= 1
- print("num -= 1: ", num)
- num *= 4
- print("num *= 4: ", num)
- num /= 2
- print("num /= 2: ", num)
- num = 3
- num %= 2
- print("num %= 2: ", num)
-
- num **= 2
- print("num **=2: ", num)
-
- num = 9
- num //= 2
- print("num //= 2:", num)

2.8、字符串扩展
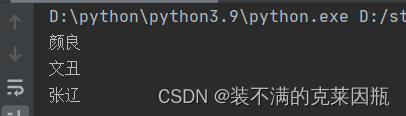
字符串的三种定义方式
示例代码:
- name1 = "颜良"
- name2 = "文丑"
- name3 = """张辽"""
- print(name1)
- print(name2)
- print(name3)
但用""""""修饰的字符串还有一个作用,那就是可以换行,如下代码:
- writeTxt = """
- 斩颜良诛文丑,
- 过五关斩六将,
- 千里走单骑
- """
- print(writeTxt)

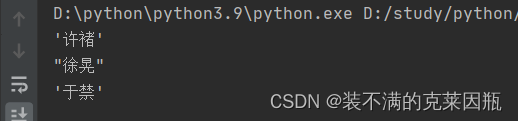
字符串转义
比如我想字符串中就包含单引号或者双引号,例如:

那么如何做呢?
- 可以使用:\来进行转义
- 单引号内可以写双引号或双引号内可以写单引号
示例代码:
- name = "'许褚'"
- print(name)
-
- name2 = '"徐晃"'
- print(name2)
-
- name3 = '\'于禁\''
- print(name3)
字符串拼接
直接用+号拼接。
示例代码:
- name = '装不满的克莱因瓶'
- address = '黑龙江省哈尔滨市'
- print('我是:' + name + ',我的地址是:' + address)

注意:只能字符串和字符串之间拼接,不能字符串与其它类型拼接,比如你想用字符串和整形进行拼接,那就会报错。这点和Java有所不同。
字符串格式化(%方式)
单个字符串占位
我们可以通过如下语法,完成字符串和变量的快速拼接。
- name = '装不满的克莱因瓶'
- message = '我的名字叫 %s' % name
- print(message)
其中的,%s
- % 表示:我要占位
- s 表示:将变量变成字符串放入占位的地方
所以,综合起来的意思就是:我先占个位置,等一会有个变量过来,我把它变成字符串放到占位的位置。
多个字符串占位
- name = '黄忠'
- address = '蜀国'
- message = '我的名字叫 %s,我所在地址是 %s' % (name, address)
- print(message)
多个字符串占位(多种类型)
- name = '黄忠'
- address = '蜀国'
- age = 66
- message = '我的名字叫 %s,我所在地址是 %s,年龄是 %d' % (name, address, age)
- print(message)
格式化的精度控制
先看下面的代码:
- name = '装不满的克莱因瓶'
- num = 19.99
- message = '我的名字是 %s,我喜欢的数字是 %f' %(name, num)
- print(message)

细心的同学可能会发现: 浮点数19.99,变成了19.990000输出。

按照定义来看,我们将上述代码改为这样即可:
- name = '装不满的克莱因瓶'
- num = 19.99
- message = '我的名字是 %s,我喜欢的数字是 %.2f' %(name, num)
- print(message)

字符串格式化(f方式)
语法 :f"内容{变量}"的格式来快速格式化。
示例代码:
- name = '装不满的克莱因瓶'
- age = 27
- print(f"我是{name},我的年龄是{age}")

2.9、数据输入
- name = input('请输入你的名字:')
- print(name)

注意:无论你输入的是什么数据类型,结果都是字符串类型。
三、判断语句
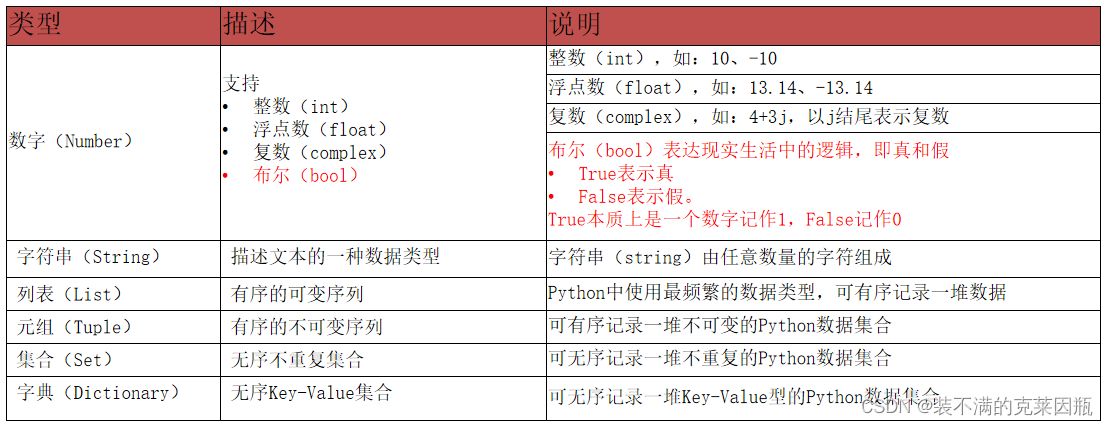
3.1、布尔类型和比较运算符
布尔类型
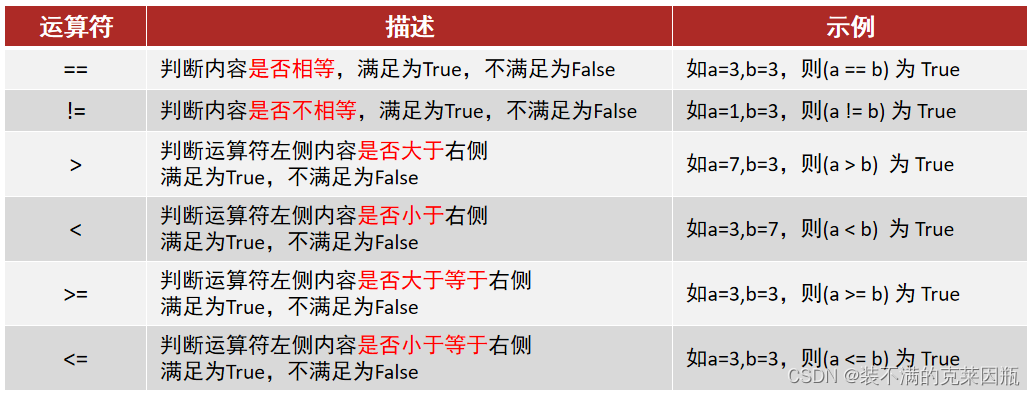
比较运算符
3.2、if语句
示例代码:
- name = '赵云'
-
- if name == '张飞':
- print(f"我是{name}")
- elif name == '黄忠':
- print(f"我是{name}")
- else:
- print(f"我是{name}")

四、循环语句
4.1、while语句
示例代码:
- i = 0
- while i < 10:
- print(f"循环第{i+1}次")
- i += 1

4.2、for语句
语法:
- for 临时变量 in 待处理数据集:
- 循环满足条件时执行的代码
示例代码1:当要遍历的值是字符串
- msg = '哈尔滨工业大学'
- for m in msg:
- print(m)

示例代码2:当要遍历的值是数组
- arr = ['赵云', '马超', '魏延']
- for p in arr:
- print(p)

4.3、range语句
语法一
range(num)获取一个从0开始,到num结束的数字序列(不含num本身)
如range(5)取得的数据是:[0,1,2,3,4]
语法二
range(num1,num2)获得一个从num1开始,num2结束的数字序列(不含num2本身)
如range(5,10)取得的数据是:[5,6,7,8,9]
语法三
range(num1,num2,step)获得一个从num1开始,num2结束的数字序列(不含num2本身)
数字之间的步长,以step为准(step默认为1)
如range(5,10,2)取得的数据是:[5,7,9]
range可以搭配for循环来使用
示例代码:
- for x in range(10):
- print(x)

4.4、变量作用域
思考
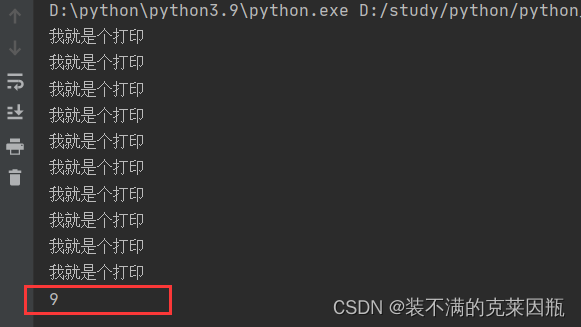
如下代码,思考一下?最后一句print语句,能否访问到变量i?
- for i in range(10):
- print("我就是个打印")
-
- print(i)
编程规范上是不可以这样做的,实际上还是可以的。
for循环的变量作用域
如果实在需要在循环外访问循环内的临时变量,可以在循环外预先定义。
- i = 0
- for i in range(10):
- print("我就是个打印")
-
- print(i)
如上代码,每一次循环的时候,都会将取出的值赋予i变量。 由于i变量是在循环之前(外)定义的 在循环外访问i变量是合理的、允许的。
4.5、循环中断:break和continue
思考
无论是while循环或是for循环,都是重复性的执行特定操作。 在这个重复的过程中,会出现一些其它情况让我们不得不暂时跳过某次循环,直接进行下一次提前退出循环,不在继续。
对于这种场景,Python提供continue和break关键字 用以对循环进行临时跳过和直接结束。
continue
continue关键字用于:中断本次循环,直接进入下一次循环。
continue可以用于:for循环和while循环,效果一致。
示例代码:
- # 循环[1,2,3,4,5],当i=4时,跳过此次循环,不再执行下面的代码,开始继续下一次循环
- for i in range(1, 6):
- if i == 4:
- continue
- print(i)

continue在嵌套循环中使用
continue关键字只可以控制:它所在的循环临时中断。

break
break关键字用于:直接结束所在循环。
break可以用于:for循环和while循环,效果一致
示例代码:
- # 循环[1,2,3,4,5],当i=4时,直接跳出循环
- for i in range(1, 6):
- if i == 4:
- break
- print(i)

注意:在嵌套循环中,continue和break都是只能作用在所在的循环上,无法对上层循环起作用。
五、函数
5.1、函数介绍
函数:是组织好的,可重复使用的,用来实现特定功能的代码段,也可以叫做方法。
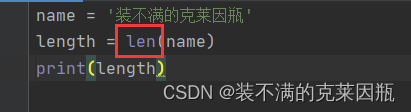
比如这段代码,为什么随时都可以使用len()统计长度?
因为,len()是Python内置的函数:
- 是提前写好的
- 可以重复使用
- 实现统计长度这一特定功能的代码段
我们前面出现过的:input()、print()、str()、int()等都是Python的内置函数。
5.2、函数的定义
函数的定义:
- def 函数名(传入参数):
- 函数体
- return 返回值
函数的调用:
函数名(参数)注意:
- 参数不需要:可以省略
- 返回值不需要:可以省略
5.3、函数的传入参数
痛点
有如下代码,完成了2个数字相加的功能:
- def add():
- result = 1 + 2
- print(result)
函数的功能非常局限,只能计算1 + 2。
有没有可能实现:每一次使用函数,去计算用户指定的2个数字,而非每次都是1 + 2呢?
答案是可以的,使用函数的传入参数功能,即可实现。
解决痛点
通过动态传递参数即可实现。
- def add(num1, num2):
- result = num1 + num2
- print(result)
-
- add(1, 2)
- add(5, 6)

语法解析
(1)上面函数定义中,提供的num1和num2,称之为:形式参数(形参),表示函数声明将要使用2个参数。
(2)函数调用中,提供的1和2,称之为:实际参数(实参),表示函数执行时真正使用的参数值。
5.4、函数的返回值
返回值
所谓“返回值”,就是程序中函数完成事情后,最后给调用者的结果。
示例代码:
- def add(num1, num2):
- result = num1 + num2
- return result
-
- result1 = add(1, 2)
- result2 = add(5, 6)
- print(result1)
- print(result2)

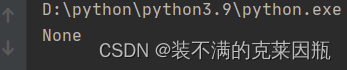
None类型
思考:如果函数没有使用return语句返回数据,那么函数有返回值吗?
实际上是:有的。
Python中有一个特殊的字面量:None,其类型是:<class 'NoneType'> 无返回值的函数,实际上就是返回了:None这个字面量。
None表示:空的、无实际意义的意思 函数返回的None,就表示,这个函数没有返回什么有意义的内容。 也就是返回了空的意思。
- def add(num1, num2):
- result = num1 + num2
-
- result1 = add(1, 2)
- print(result1)
None类型的应用场景
None作为一个特殊的字面量,用于表示:空、无意义,其有非常多的应用场景。
(1)用在函数无返回值上
(2)用在if判断上
- 在if判断中,None等同于False
- 一般用于在函数中主动返回None,配合if判断做相关处理
- def check_age(age):
- if age > 18:
- return "已经成年了"
- return None
-
- result = check_age(5)
- if not result:
- print("未成年,禁止入内")
(3)定义变量,但暂时不需要变量有具体值,可以用None来代替
- # 暂不赋予变量具体值
- name = None
5.5、函数说明文档
函数是纯代码语言,想要理解其含义,就需要一行行的去阅读理解代码,效率比较低。 我们可以给函数添加说明文档,辅助理解函数的作用。 语法如下:

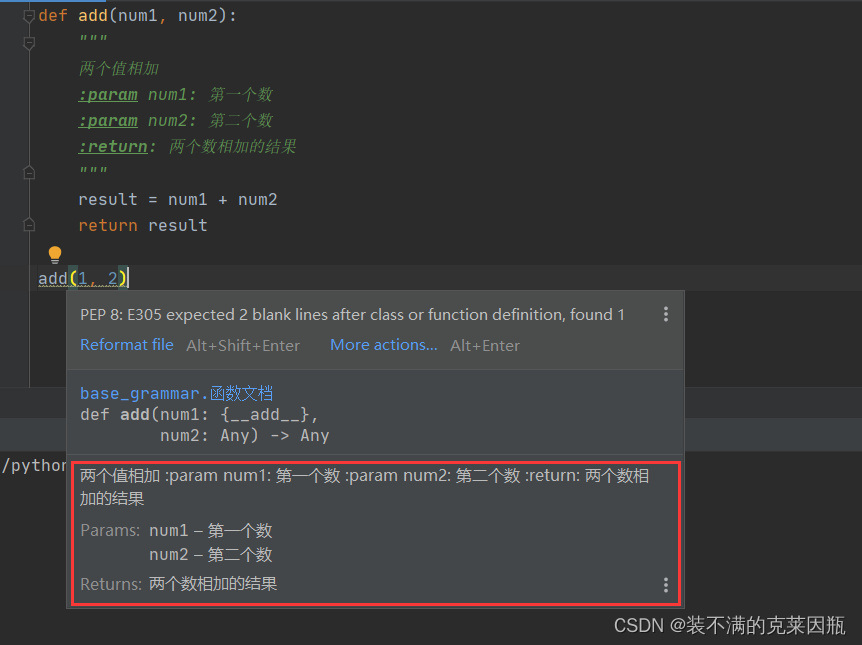
示例代码:
- def add(num1, num2):
- """
- 两个值相加
- :param num1: 第一个数
- :param num2: 第二个数
- :return: 两个数相加的结果
- """
- result = num1 + num2
- return result
-
- add(1, 2)
当我们用PyCharm编码时,鼠标移动到调用方法那里,就自动会出现函数的说明文档。
5.6、变量的作用域
变量作用域指的是变量的作用范围(变量在哪里可用,在哪里不可用)。
主要分为两类:局部变量和全局变量。
局部变量
局部变量:所谓局部变量是定义在函数体内部的变量,即只在函数体内部生效。
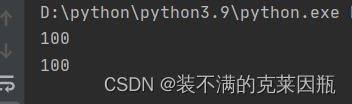
- def test():
- a = 100
- print(a)
-
- print(a)
变量a是定义在test函数内部的变量,在函数外部访问则立即报错。
局部变量的作用:在函数体内部,临时保存数据,即当函数调用完成后,则销毁局部变量。
全局变量
全局变量:所谓全局变量,指的是在函数体内、外都能生效的变量。
思考:如果有一个数据,在函数A和函数B中都要使用,该怎么办?
答:将这个数据存储在一个全局变量里面。
- num = 100
-
- def A():
- print(num)
-
- def B():
- print(num)
-
- A()
- B()
global关键字
思考:B函数需要修改变量num的值为200,如何修改程序?
- num = 100
-
- def A():
- print(num)
-
- def B():
- num = 200
- print(num)
-
- A()
- B()
- print(num)
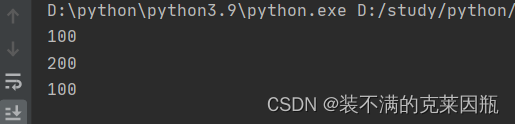
我们发现结果好像与我们预想的不一样,我明明已经通过B函数将全局变量num值改为200了,为什么全局变量的num还是100呢?
那是因为当我们在函数中修改全局变量时,会把num变为局部变量,里面的num和外面的num没有任何关系了。那问题又来了,我就是想要修改num值,如何做?加global。
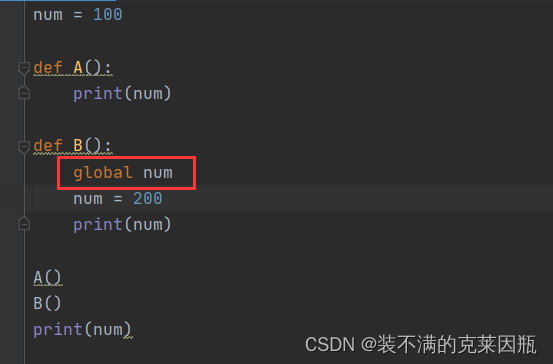
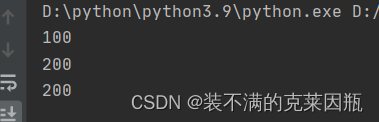
加完global关键字修饰,里面的num就和外面的num一样了。
六、数据容器
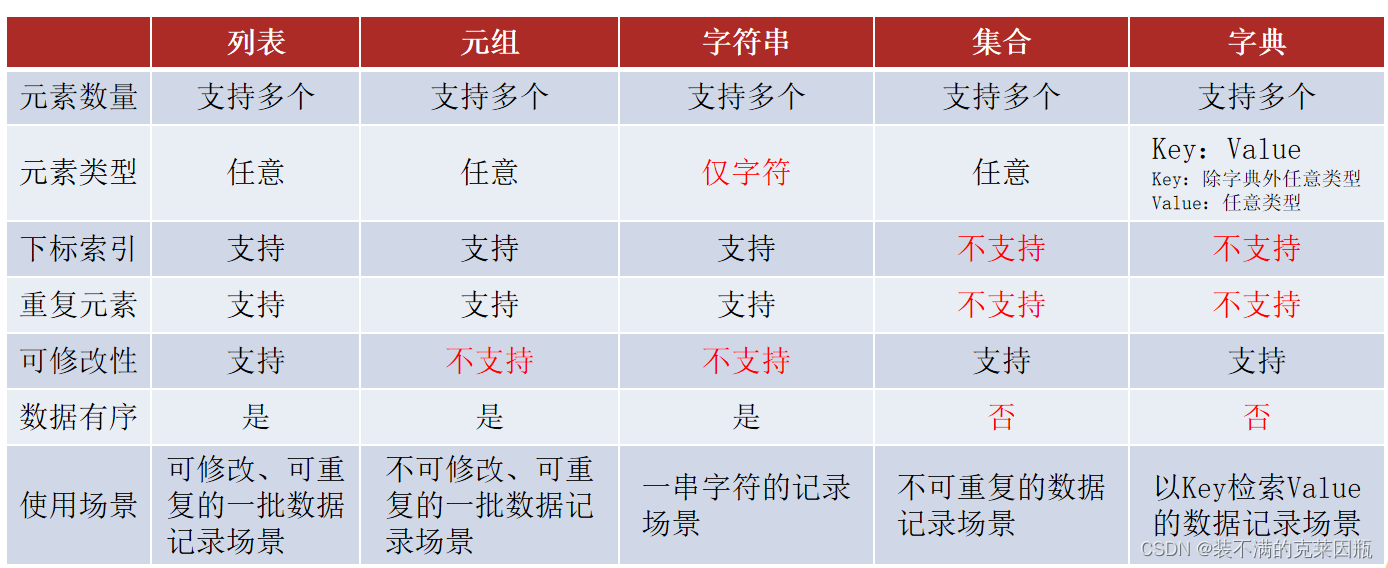
6.1、数据容器入门
思考一个问题:如果我想要在程序中,记录5名学生的信息,如姓名。
如何做呢?
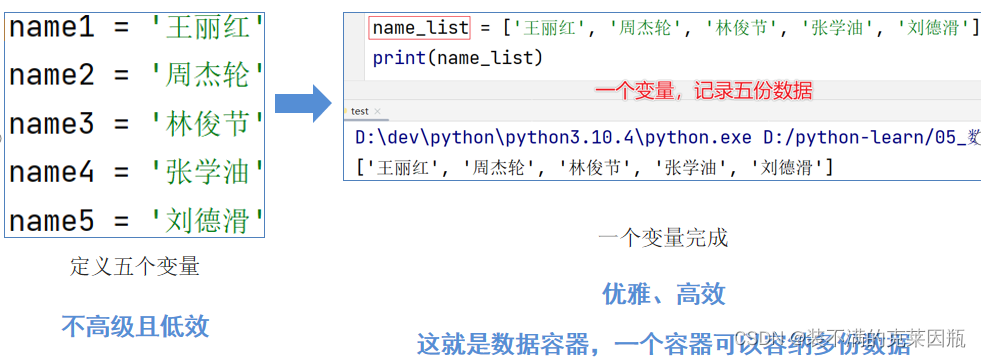
Python中的数据容器:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素每一个元素,可以是任意类型的数据,如字符串、数字、布尔等。
数据容器根据特点的不同,如:
- 是否支持重复元素
- 是否可以修改
- 是否有序,等
分为5类,分别是: 列表(list)、元组(tuple)、字符串(str)、集合(set)、字典(dict)
6.2、list(列表)
列表的定义
语法:
- # 字面量
- [元素1,元素2,元素3...]
-
- # 定义变量
- 变量名称 = [元素1,元素2,元素3...]
-
- # 定义空列表
- 变量名称 = ()
- 变量名称 = list()
示例代码:
- names = ['赵云', '许褚', '程普']
- print(names)
- print(type(names))

列表的下标索引

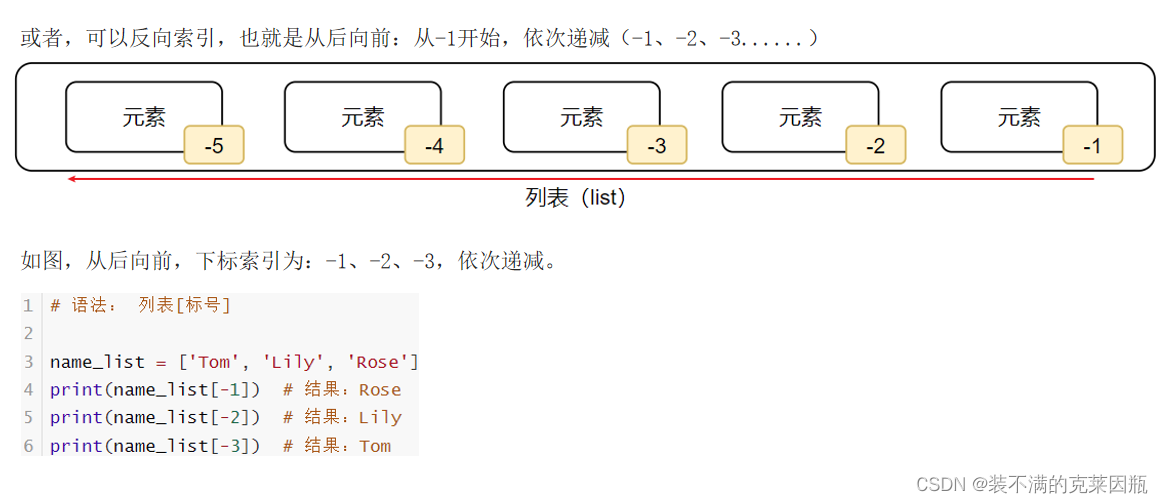
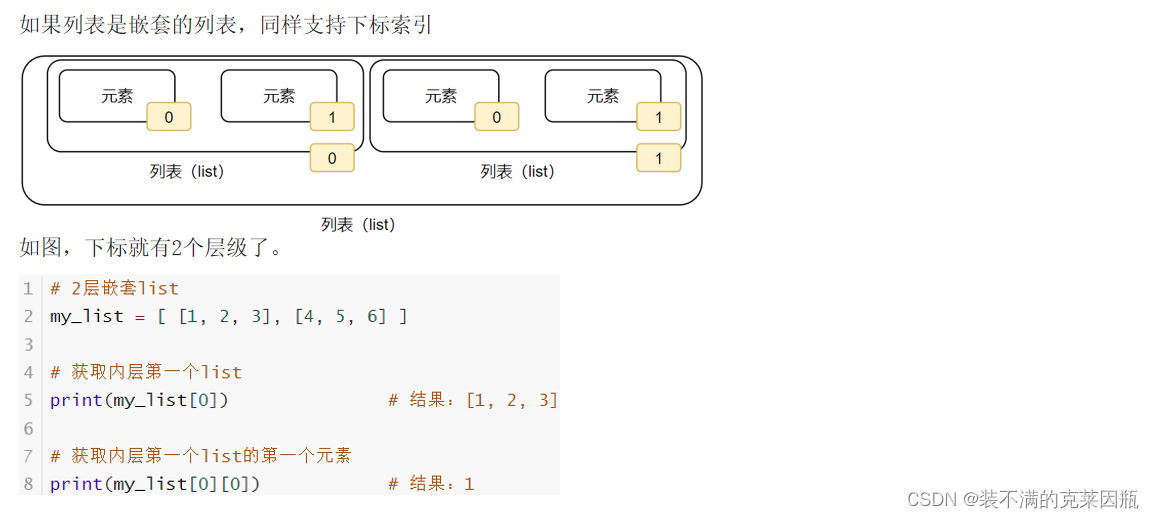
常用操作
查找元素下标
功能:查找指定元素在列表的下标,如果找不到,报错ValueError。
语法:列表.index(元素)
示例代码:
- names = ['赵云', '许褚', '程普']
- index = names.index('程普')
- print(index) # 2
修改特定下标的元素值
语法:列表[下标] = 值
示例代码:
- names = ['赵云', '许褚', '程普']
- names[0] = '关羽'
- print(names) # ['关羽', '许褚', '程普']
插入元素
语法:列表.insert(下标, 元素),在指定的下标位置,插入指定的元素。
示例代码:
- names = ['赵云', '许褚', '程普']
- names.insert(1, '张飞')
- print(names) # ['赵云', '张飞', '许褚', '程普']
追加元素(方式一)
语法:列表.append(元素),将指定元素,追加到列表的尾部。
示例代码:
- names = ['赵云', '许褚', '程普']
- names.append('张辽')
- names.append('马岱')
- print(names) # ['赵云', '许褚', '程普', '张辽', '马岱']
追加元素(方式二)
语法:列表.extend(其它数据容器),将其它数据容器的内容取出,依次追加到列表尾部。
示例代码:
- names01 = ['赵云', '关羽', '张飞']
- names02 = ['程普', '黄盖', '凌统']
- names01.extend(names02)
- print(names01) # ['赵云', '关羽', '张飞', '程普', '黄盖', '凌统']
删除元素(根据下标)
语法1:del 列表[下标]
语法2:列表.pop(下标)
示例代码1:
- names = ['赵云', '关羽', '张飞']
- del names[1]
- print(names) # ['赵云', '张飞']
示例代码2:
- names = ['赵云', '关羽', '张飞']
- names.pop(1)
- print(names) # ['赵云', '张飞']
删除元素(根据元素)
语法:列表.remove(元素)
示例代码:
- names = ['赵云', '关羽', '张飞', '关羽']
- names.remove('关羽')
- print(names) # ['赵云', '张飞', '关羽']
看代码得知,当list中有重复的元素,remove只能删除第一个,要想删除第二个还得再调用一个remove方法。
清空列表
语法:列表.clear()
示例代码:
- names = ['赵云', '关羽', '张飞']
- names.clear()
- print(names) # []
统计某元素在列表内的数量
语法:列表.count(元素)
示例代码:
- names = ['赵云', '关羽', '张飞', '关羽']
- count = names.count('关羽')
- print(count) # 2
统计列表内,有多少元素
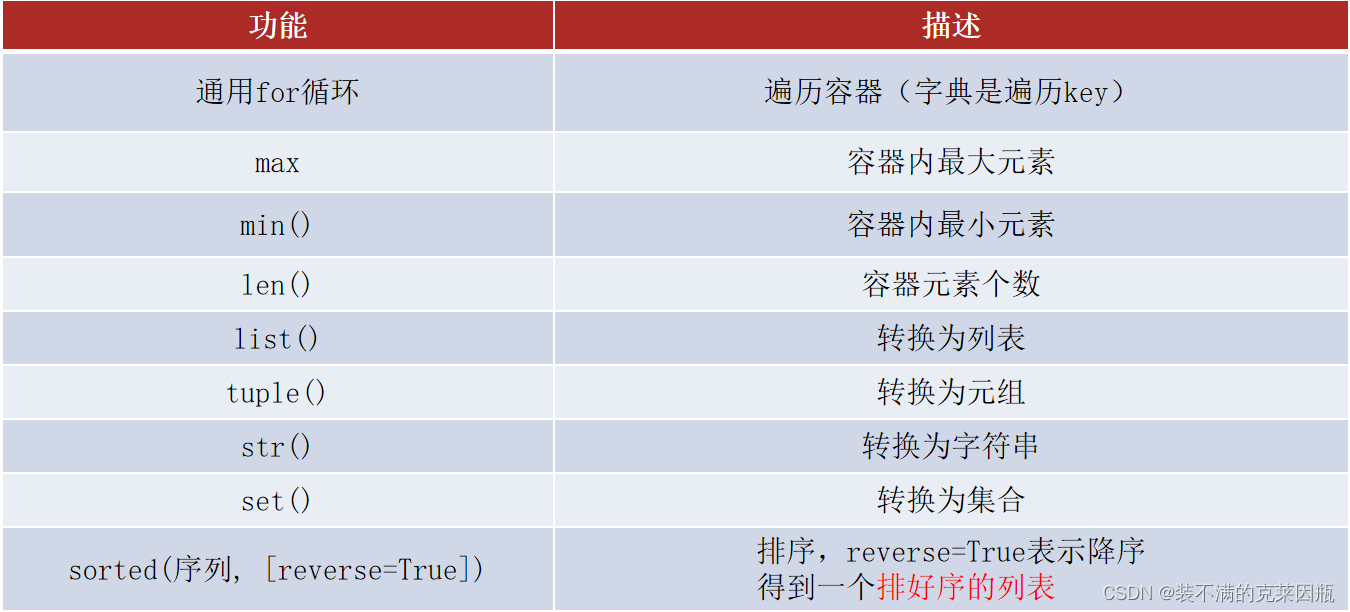
语法:len(列表)
示例代码:
- names = ['赵云', '关羽', '张飞']
- length = len(names)
- print(length) # 3
列表的特点

6.3、list(列表)的遍历
while循环
示例代码:
- names = ['赵云', '关羽', '张飞', '黄忠', '马超']
- i = 0
- while i < len(names):
- print(names[i])
- i += 1

for循环
示例代码:
- names = ['赵云', '关羽', '张飞', '黄忠', '马超']
- for element in names:
- print(element)

6.4、tuple(元组)
定义
元组定义:定义元组使用小括号,且使用逗号隔开各个数据,数据可以是不同的数据类型。
语法:
- # 定义元组变量
- names = ('赵云', '关羽', '张飞', '黄忠', '马超')
-
- # 定义空元组(两种方式)
- names = ()
- names = tuple()
元组嵌套:
- names = (('赵云', '关羽'), ('程普', '太史慈'))
- print(names[0][1]) # 关羽

元组的相关操作
| 编号 | 方法 | 作用 |
| 1 | index() | 查找某个数据,如果数据存在返回对应的下标,否则报错 |
| 2 | count() | 统计某个数据在当前元组出现的次数 |
| 3 | len(元组) | 统计元组内的元素个数 |
元组由于不可修改的特性,所以其操作方法非常少。
元组的注意事项

元组的遍历
和list列表一模一样。
元组的特点
经过上述对元组的学习,可以总结出list列表有如下特点:
- 可以容纳多个数据
- 可以容纳不同类型的数据(混装)
- 数据是有序存储的(下标索引)
- 允许重复数据存在
- 不可以修改(增加或删除元素等)
- 支持for循环
多数特性和list一致,不同点在于不可修改的特性。
6.5、str(字符串)
字符串的下标
和其它容器如:列表、元组一样,字符串也可以通过下标进行访问
- 从前向后,下标从0开始
- 从后向前,下标从-1开始
- str = '装不满的克莱因瓶'
- print(str[0]) # 装
- print(str[1]) # 不
同元组一样,字符串是一个:无法修改的数据容器。
所以:
- 修改指定下标的字符(如:字符串[0] = “a”)
- 移除特定下标的字符(如:del 字符串[0]、字符串.remove()、字符串.pop()等)
- 追加字符等(如:字符串.append()) 均无法完成。
如果必须要做,只能得到一个新的字符串,旧的字符串是无法修改。
字符串的常用操作
查找特定字符串的下标索引值
语法:字符串.index(字符串)
字符串的替换
语法:字符串.replace(字符串1,字符串2)
功能:将字符串内的全部:字符串1,替换为字符串2
注意:不是修改字符串本身,而是得到了一个新字符串。
示例代码:
- school = '哈尔滨工业大学'
- school = school.replace('业', '程')
- print(school) # 哈尔滨工程大学
字符串的分割
语法:字符串.split(分隔符字符串)
功能:按照指定的分隔符字符串,将字符串划分为多个字符串,并存入列表对象中
注意:字符串本身不变,而是得到了一个列表对象。
示例代码:
- schools = '哈尔滨工业大学,哈尔滨工程大学,哈尔滨医科大学'
- school_list = schools.split(',')
- print(school_list) # ['哈尔滨工业大学', '哈尔滨工程大学', '哈尔滨医科大学']
字符串的规整操作(去前后空格)
语法:字符串.strip()
示例代码:
- name = ' 装不满的克莱因瓶 '
- name = name.strip()
- print(name) # 装不满的克莱因瓶
字符串的规整操作(去前后指定字符串)
语法:字符串.strip(字符串)
示例代码:
- name = '12装不满的克莱因瓶211'
- name = name.strip('12')
- print(name) # 装不满的克莱因瓶
注意:传入的是“12” 其实就是:”1”和”2”都会移除,是按照单个字符。
统计字符串中某字符串的出现次数
语法:字符串.count(字符串)
统计字符串的长度
语法:len(字符串)
数字(1、2、3...) 字母(abcd、ABCD等) 符号(空格、!、@、#、$等) 中文 均算作1个字符。
6.6、序列的切片
什么是序列?
序列是指:内容连续、有序,可使用下标索引的一类数据容器。
列表、元组、字符串,均可以可以视为序列。
序列的常用操作 - 切片
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列:
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
- 步长1表示,一个个取元素
- 步长2表示,每次跳过1个元素取
- 步长N表示,每次跳过N-1个元素取
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)
示例代码:
- my_str = "12345"
- new_str = my_str[::-1] # 从头(最后)开始,到尾结束,步长-1(倒序)
- print(new_str) # 结果:"54321"
-
- my_list = [1, 2, 3, 4, 5]
- new_list = my_list[3:1:-1] # 从下标3开始,到下标1(不含)结束,步长-1(倒序)
- print(new_list) # 结果:[4, 3]
-
- my_tuple = (1, 2, 3, 4, 5)
- new_tuple = my_tuple[:1:-2] # 从头(最后)开始,到下标1(不含)结束,步长-2(倒序)
- print(new_tuple) # 结果:(5, 3)
6.7、set(集合)
集合的定义
- # 定义集合
- 变量名称 = {元素1,元素2,元素3...}
-
- # 定义空集合
- 变量名称 = set()
集合最典型的特征:去重且无序。
集合的常用操作
首先,因为集合是无序的,所以集合不支持:下标索引访问。
但是集合和列表一样,是允许修改的,所以我们来看看集合的修改方法。
添加新元素
语法:集合.add(元素)。将指定元素,添加到集合内
结果:集合本身被修改,添加了新元素
示例代码:
- my_set = {'角木蛟', '斗木獬', '奎木狼'}
- my_set.add('井木犴')
- print(my_set) # {'斗木獬', '角木蛟', '奎木狼', '井木犴'}
移除元素
语法:集合.remove(元素),将指定元素,从集合内移除
结果:集合本身被修改,移除了元素
示例代码:
- my_set = {'角木蛟', '斗木獬', '奎木狼', '井木犴'}
- my_set.remove('井木犴')
- print(my_set) # {'角木蛟', '奎木狼', '斗木獬'}
从集合中随机取出元素
语法:集合.pop()
功能:从集合中随机取出一个元素
结果:会得到一个元素的结果。同时集合本身被修改,元素被移除
示例代码:
- my_set = {'角木蛟', '斗木獬', '奎木狼', '井木犴'}
- element = my_set.pop()
- print(element) # 奎木狼
- print(my_set) # {'井木犴', '斗木獬', '角木蛟'}
清空集合
语法:集合.clear()
功能:清空集合
结果:集合本身被清空
示例代码:
- my_set = {'角木蛟', '斗木獬', '奎木狼', '井木犴'}
- my_set.clear()
- print(my_set) # set()
取出2个集合的差集
语法:集合1.difference(集合2)
功能:取出集合1和集合2的差集(集合1有而集合2没有的)
结果:得到一个新集合,集合1和集合2不变
示例代码:
- set1 = {'角木蛟', '斗木獬', '奎木狼', '井木犴'}
- set2 = {'角木蛟', '斗木獬'}
- set3 = set1.difference(set2)
- print(set3) # {'井木犴', '奎木狼'}
消除2个集合的差集
语法:集合1.difference_update(集合2)
功能:对比集合1和集合2,在集合1内,删除和集合2相同的元素。
结果:集合1被修改,集合2不变
示例代码:
- set1 = {'角木蛟', '斗木獬', '奎木狼', '井木犴'}
- set2 = {'角木蛟', '斗木獬'}
- set1.difference_update(set2)
- print(set1) # {'奎木狼', '井木犴'}
- print(set2) # {'角木蛟', '斗木獬'}
两个集合合并
语法:集合1.union(集合2)
功能:将集合1和集合2组合成新集合
结果:得到新集合,集合1和集合2不变
示例代码:
- set1 = {'角木蛟', '斗木獬'}
- set2 = {'奎木狼', '井木犴'}
- set3 = set1.union(set2)
- print(set3) # {'斗木獬', '井木犴', '角木蛟', '奎木狼'}
查看集合的元素数量
语法:len(集合)
功能:统计集合内有多少元素
结果:得到一个整数结果
示例代码:
- set1 = {'角木蛟', '斗木獬', '奎木狼', '井木犴'}
- print(len(set1)) # 4
集合同样支持使用for循环遍历
- set1 = {'角木蛟', '斗木獬', '奎木狼', '井木犴'}
- for ele in set1:
- print(ele)
要注意:集合不支持下标索引,所以也就不支持使用while循环。
6.8、dict(字典)
字典的定义
字典的定义,同样使用{},不过存储的元素是一个个的:键值对,如下语法:
- # 定义字典变量
- my_dict = {key:value...}
-
- # 定义空字典
- my_dict = {}
- my_dict = dict()
Key和Value可以是任意类型的数据(key不可为字典)。
Key不可重复,重复会对原有数据覆盖。
字典数据的获取
字典同集合一样,不可以使用下标索引
但是字典可以通过Key值来取得对应的Value
- my_dict = {'name': '装不满的克莱因瓶', 'age': 27, 'school': '哈尔滨工业大学'}
- print(my_dict['name']) # 装不满的克莱因瓶
- print(my_dict['age']) # 27
- print(my_dict['school']) # 哈尔滨工业大学
字典的特点
键值对的Key和Value可以是任意类型(Key不可为字典)。
字典内Key不允许重复,重复添加等同于覆盖原有数据。
字典不可用下标索引,而是通过Key检索Value。
字典的常用操作
新增元素
语法:字典[Key] = Value
结果:字典被修改,新增了元素
示例代码:
- my_dict = {'person01': '莫言', 'person02': '余华', 'person03': '刘震云'}
- my_dict['person04'] = '史铁生'
- print(my_dict) # {'person01': '莫言', 'person02': '余华', 'person03': '刘震云', 'person04': '史铁生'}
更新元素
语法:字典[Key] = Value
结果:字典被修改,元素被更新
示例代码:
- my_dict = {'person01': '莫言', 'person02': '余华', 'person03': '刘震云'}
- my_dict['person01'] = '史铁生'
- print(my_dict) # {'person01': '史铁生', 'person02': '余华', 'person03': '刘震云'}
删除元素
语法:字典.pop(Key)
结果:获得指定Key的Value,同时字典被修改,指定Key的数据被删除
示例代码:
- my_dict = {'person01': '莫言', 'person02': '余华', 'person03': '刘震云'}
- my_dict.pop('person03')
- print(my_dict) # {'person01': '莫言', 'person02': '余华'}
清空字典
语法:字典.clear()
结果:字典被修改,元素被清空
示例代码:
- my_dict = {'person01': '莫言', 'person02': '余华', 'person03': '刘震云'}
- my_dict.clear()
- print(my_dict) # {}
获取全部的key
语法:字典.keys()
结果:得到字典中的全部Key
示例代码:
- my_dict = {'person01': '莫言', 'person02': '余华', 'person03': '刘震云'}
- keys = my_dict.keys()
- print(keys) # dict_keys(['person01', 'person02', 'person03'])
遍历字典
语法:for key in 字典.keys()
示例代码:
- my_dict = {'person01': '莫言', 'person02': '余华', 'person03': '刘震云'}
- keys = my_dict.keys()
- for k in keys:
- print(my_dict[k])
计算字典内的全部元素(键值对)数量
语法:len(字典)
结果:得到一个整数,表示字典内元素(键值对)的数量
示例代码:
- my_dict = {'person01': '莫言', 'person02': '余华', 'person03': '刘震云'}
- print(len(my_dict)) # 3
6.9、数据容器特点对比