
- 1又整新活,新版 IntelliJ IDEA 有点东西!_idea2024新特性
- 2docker privileged用法_docker --privileged
- 3mysql语法大全_mysql语句大全及用法
- 4【算法】—贪心算法详解
- 5卡塔训练_kata training
- 6gemini国内怎么用
- 7简单来说,无人机单片机是如何控制电机的?_n-mos空心杯
- 8基于微信小程序的运动打卡系统的设计与实现(附源码)_计步小程序源码
- 9手把手教你在Mac中搭建iOS的 React Native环境_mac react native ios note: building targets in dep
- 10Redis实现短信登入功能(二)Redis实现登入功能_string cachecode = stringredistemplate.opsforvalue
[NAS]MCUNet: Tiny Deep Learning on IoT Devices
赞
踩
MCUNet:在 IoT设备上的微型深度学习
Abstract
基于MCU的微型物联网设备上进行深度学习是一个吸引人但又有挑战性的任务,因为MCU的内存比手机端还要小2-3个数量级。本文提出的MCUNet框架将高效的神经网络架构搜索TinyNAS和轻量级的推理引擎TinyEngine相结合,能够实现在MCU上进行ImageNet的推理。
TinyNAS采用两阶段的NAS搜索方法,首先对搜索空间进行优化满足资源约束,然后在优化后的搜索空间中设计网络结构,这样可以在较低的搜索成本下满足对设备、延迟、功耗、内存等的约束条件。
TinyEngine则是一个内存高效的推理引擎,主要用来扩展搜索空间从而适合一个更大的模型,TinyEngine会根据网络整体结构调整memory scheduling,而不是进行逐层的优化,这样比TF-Lite优化的结果加速推理1,7-3.3倍,memory压缩3.4x。
MCUNet是第一个在现有的MCU上实现ImageNet分类超过70%精度的实现,与量化后的MobileNetV2相比,SRAM个Falsh分别减少了3.5倍和5.7倍。在视觉和音频唤醒任务中MCUNet实现了最优精度,并且运行速度比MobileNetV2和ProxylessNAS相比峰值SRAM减少了3.7-4.1倍。本文的研究表明在物联网设备上运行微型机器学习的时代已经来临。
Section I Introduction
在基于MCU处理的物联网设备越来越多,如智能制造、个性化建康、精细农业、自动化零售等,这些低成本、低功耗的MCU创造了一个TinyMLd的时代,这样可以直接在传感器侧就进行数据分析,从而显著扩大了AI的应用范畴。
但是MCU的计算和存储资源十分有限,尤其是SRAM和Flash。比如片上内存一般比手机第3个量级,更比GPU低5-6个量级,使得部署深度学习网络十分困难。参见Tab 1可以看到在ARM Cortex-M7 MCU的片上内存是320kB,1MB Flash,而ResNet-50的硬盘需求是其100倍,MobileNet的内存需求是其22倍,即使是int8量化后的版本也内存超了5,3倍,说明了目前期望的和实际可用的硬件容量之间的巨大差距。
TinyAI和云端AI、移动端AI都不同,因为MCU本身没有OS也没有DRAM,因此需要共同设计深度学习模型额推理库,精细设计MCU的计算和存储资源,现有的网络设计和NAS算法大多专注于GPU和移动端,它们的内存和存储都更加充足。

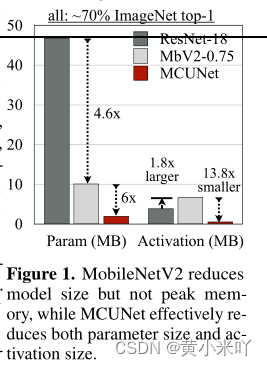
因此它们只需要优化FLOPs来降低延迟,有这种并不适合MCU的设计。比如在ImageNet70%的精度下MobileNetV2比ResNet-18将模型尺寸压缩了4.6倍,参见Fig 1。但是激活值的峰值却增加了1.8倍,这样在MCU上适配SRAM更加困难。但是由于缺乏系统-算法的协同设计,目前的工作主要研究小型数据集比如CIFAR但这与实际用例相去甚远,或者研究性能不是最优的网络。
本文提出的MCUNet是一个系统-模型协同设计框架,通过TinyNAS和TinyEngine的联合优化适配MCU上稀缺的片上内存。
TinyNAS是一种两阶段的NAS算法可以处理不同MCU上不同的内存约束。我们都知道NAS性能很大程度上依赖搜索空间,但关于小规模空间的启发式搜索研究却比较稀少。TinuNAS首先会自动优化搜索空间,在优化后的空间上极性NAS搜索。TinyNAS通过缩放输入分辨率和模型的宽度来生成不同规模的搜索空间,收集满足FLOPs约束的搜索空间来赋予空间优先级。TinyNAS基于以下假设:在内存约束下FLOPs更大的搜索空间可以生成性能更好的模型。实验表明优化后的空间可以提升NAS搜索模型的精度。
此外为了应对MCU上极其严格的资源约束本文还提出一个TinyEngine来减轻不必要的内存开销,二者结合可以提升深度学习模型的天花板。TinyEngine通过基于代码生成的编译方法改进现有推理库来减轻内存开销,它支持模型自适应内存调度,会根据网络的整体结构进行特定的计算内核优化,如循环展开、操作融合等,并且逐层进行,这进一步加速了推理。
MCUNet大大提升了在MCU上部署深度网络的性能,TinyEngine将峰值内存降低了3,4倍,推理加速比达到了1.7倍-3.3倍。通过系统-算法的协同设计最终在商用MCU上实现了70.7%的ImageNet分类精度。在视频和音频唤醒任务中,也达到了SOTA精度并且比当前解决方案推理加速为2.4-3.4倍,SRAM压缩3,7-4.1倍。在交互式应用中,在语音命令数据及上达到了10fps,精度为91%。
Section II Background
MCU的内存都十分有限。比如ARM Cortex-M7 MCU STM32F746 只有320kB SRAM, 1MB Flash.因此需要设计网络模型和推理库来适应内存约束。SRAM限制激活大小(读写),Flash限制模型大小(只读)
Deep Learning Inference on MCU
当前的框架如TF-Lite,CMSIS-NN,CMix-NN和Mocir-TVM或多或少有以下局限:
(1)大多数框架在运行时来解释网络图,这回占用大量的SRAM和Flash,峰值内存占用能到65%,延迟也会增加22%
(2)优化在层级进行,没有利用整体网络结构来进一步减少内存使用。
Efficient Neural Network Design
网络效率对深度学习系统的整体性能至关重要,可以通过剪枝、量化来消除冗余,张量分解也是一种有效的压缩方法。另一流派是直接涉及一个高校2网络,近年来也有借助NAS直接搜索的方法。
NAS搜索的性能大大依赖于搜索空间的质量。之前人们遵循人工设计启发式的NAS搜索空间设计,比如基于MobileNetV2的适合移动端的搜索空间,设定类似的卷积核、模块深度、扩展了。但是对于内存受限的MCU目前缺乏标准的搜索空间设计,只能手动调整但是这一劳动密集型任务大大限制了模型在MCU上的大量部署,因此需要设计一种方法来自动优化小型、不同部署场景下的搜索空间。
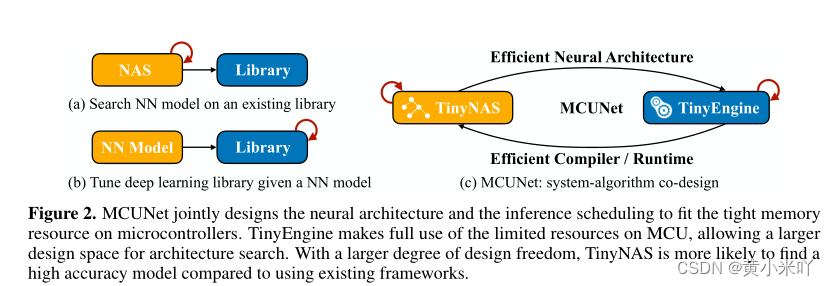
Section III System-Algorithm Co-Design
MCUNet是一个系统-算法协同设计框架,在同一个循环中联合优化神经网络架构(TinyNAS)和推理调度(TinyEngine)。传统方法一般基于一个给定的深度学习的库来进行NAS搜索,或者为某一个特定网络来优化推理速度,MCUNet可以更好的通过协同设计来利用班上资源。
Part 1 TinyNAS:Two-stage NAS for Tiny Memory Constraints
TinyNAS是一种两阶段的NAS算法,首先会优化搜索空间来适应各种微小、不同的资源约束,随后在优化后的搜索空间内进行NAS搜索,基于优化后的空间显著提升了最终模型的精度。
Automated search space optimization
本文提倡以较低的计算成本自动进行搜索空间的优化。本文的搜索空间变化的是不同的输入分辨率和width multiplier,分别是:
R = {48, 64, 80, …, 192, 208, 224}
width multiplier W = {0.2, 0.3, 0.4, …, 1.0}
这样一共有129=108中可能的搜索空间,所有搜索空间一共包含3.310^25个可能的子网络。本文的目标是找到包含具有最高精度的模型对应的最佳搜索空间配置Sstar,同时满足资源约束。
一种方法是对每个搜索空间进行NAS搜索并比较最终结果,但这一搜索成本是天文数字。本文会从搜索空间中随机抽样m个网络并比较他们的分布信息来评估搜索空间的指令。但本文并没有收集网络精度的CDF而是比较FLOPs的CDF,参见Fig 3.
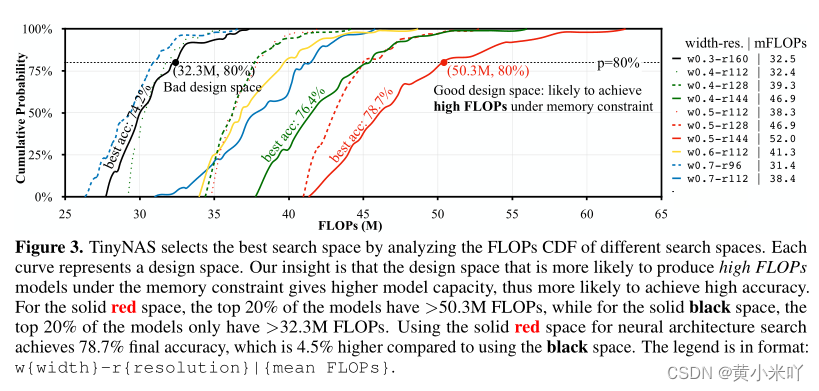
一个知觉的结论是在同一个模型家族中精度通常与计算结果呈正相关,计算量越大的模型容量越大,也就更有可能实现更高的精度。 比如本文研究了在STM32F746上的ImageNet-100的最佳搜索空间,Fig 3中显示了前10个搜索空间的CDG,从每个搜索空间中采样m=1000个网络,并使用TinyEngine来优化每个模型的内存调度,最终只保留满足内存需求的 模型,可以看到平均FLOPs=52M的搜索空间比平均FLOPs=46.9M的搜索空间精度提升了2.3%说明了更大搜索空间的有效性。
Part 2 TinyEngine:A Memory-Efficient Inference Library
研究人员之前假设基于不同的深度学习框架只会影响推理速度并不会影响准确性但对TinyML二者都会受到影响。一个良好的推理框架将会充分利用片上资源避免内存浪费,并允许算法提供更大二段搜索空间,具有更大的设计自由度。
From interpretation to code generation
大多数现有的推理库都是interpreter-based,更好支持跨平台开发但是运行时需要存储模型元信息,如模型结构参数,这都会耗费MCU宝贵的资源。TinyEngine会将这些运行时操作offload到编译时生成代码交给TinyNAS执行。由于二者是协同设计可以完全控制运行什么模型、这样节省了运行时解释的时间还释放了内存的使用从而允许更大的模型运行。与CMSIS-NN相比通过代码生成减少了2.1x的内存使用,推理效率提升了22%,参见Fig 4和Fig 5。
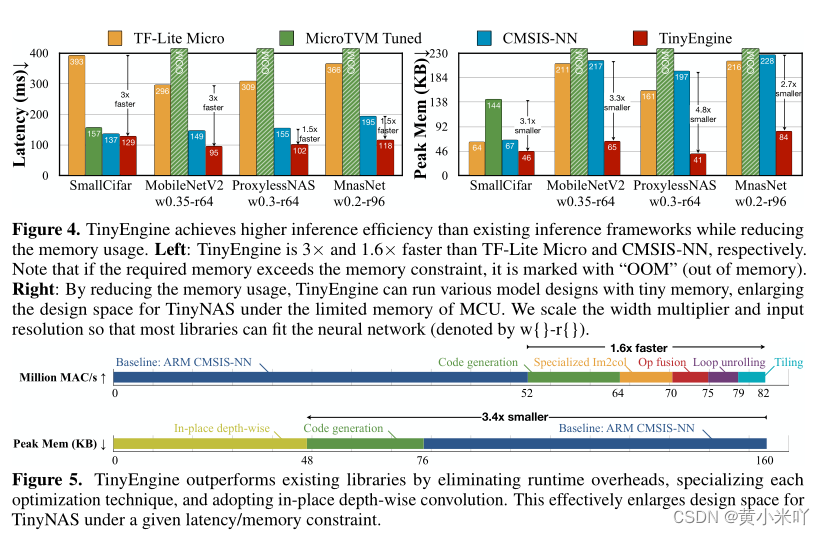
TinyEngine的二进制代码规模很小,不像interpreter-based如TF-Lite会将每个操作都准备一份代码,即使不会用到这一操作,这是十分冗余的。本文只对模型所使用的的操作编译为二进制文件,从Fig 6可以看出与TF-Lite和CMSIS-NN相比分别将二进制代码规模减少了4.5x和5x.
Model-adaptive memory scheduling
现有的推理库仅根据层本身进行调度:最开始使用一个较大的buffer来存储im2col之后的输入激活值;每一层只会使用转换后的一列加入buffer。而TinyEngine会调整内存调度模型,最大的内存M会适配所有层中最大的那一列输入Li,以及保证尽可能多的列能够与内存适配:
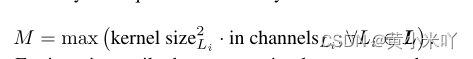
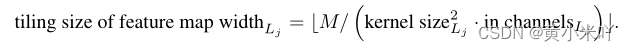
因此即使两个模型有相同的配置(相同的卷积核、输入输出通道)TinyEngine也会提供不同的优化策略,致力于内存的复用、输入输入的复用,减少内存碎片和数据移动,参见Fig 5
推理效率提升了13%
Computational kernel specialization
TinyEngine还会针对每一层的卷积核进行优化,针对不同大小的卷积核进行循环展开,对COnv+padding+ReLU+BN进行融合操作,这一步提升推理效率22%
In-place depth-wise convolution
本文还提出了原地深度卷积来进一步降低峰值内存。因为深度卷积不执行跨通道操作,因此一个通道的计算完成就可以覆盖这一通道的输入激活值并用来存储下一个通道的输出激活,这样原地计算将内存使用量减少了1.6x

因此即使两个模型有相同的配置(相同的卷积核、输入输出通道)TinyEngine也会提供不同的优化策略,致力于内存的复用、输入输入的复用,减少内存碎片和数据移动,参见Fig 5退李小龙提升了13%
Computational kernel specialization
TinyEngine还会针对每一层的卷积核进行优化,针对不同大小的卷积核进行循环展开,对COnv+padding+ReLU+BN进行融合操作,这一步提升推理效率22%
In-place depth-wise convolution
本文还提出了原地深度卷积来进一步降低峰值内存。因为深度卷积不执行跨通道操作,因此一个通道的计算完成就可以覆盖这一通道的输入激活值并用来存储下一个通道的输出激活,这样原地计算将内存使用量减少了1.6x
Section IV Experiments
硬件部署:STM32F412 (Cortex-M4, 256kB
SRAM/1MB Flash), STM32F746 (Cortex-M7, 320kB/1MB Flash), STM32F765 (Cortex-M7, 512kB
SRAM/1MB Flash), STM32H743 (Cortex-M7, 512kB SRAM/2MB Flash)
所有的延迟基于STM32F746上测试得到
Part 2 Large-scale Image Recognition on Tiny Devices
对比的网络有MobileNetV2和ProxylessNAS
Co-design brings better performance
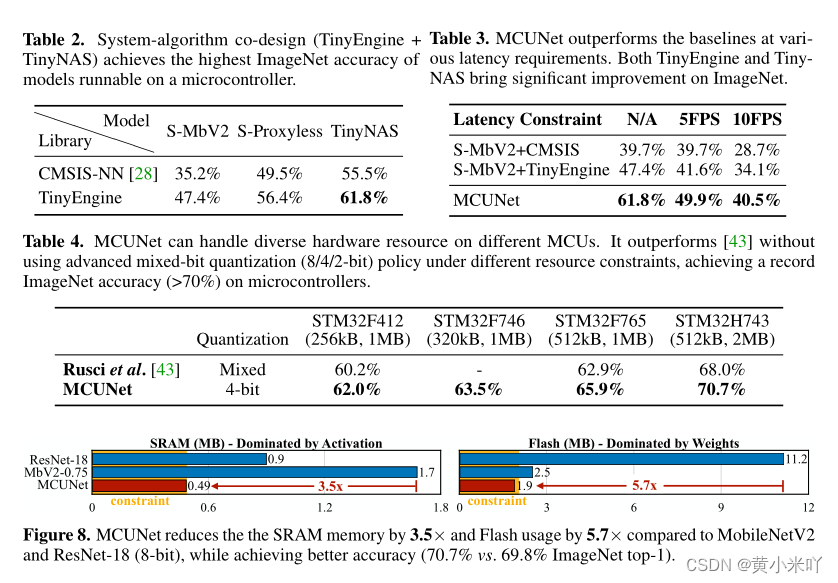
从Tab 2可以看出二者的协同设计有助于资源优化,性能提升,在320kBSRAM和1MBFlash下运行时,使用CMSIS-NN的MobileNetV2仅达到35.2%和49.5%的前1精度。使用TinyEngine可以拟合更大的模型,其精度达到更高的47.4%和56.4%;使用TinyNAS,可以在严格的内存约束下定制化一个更精确的模型,以达到55.5%的top-1精度。最后,通过系统-算法的协同设计,MCUNet将准确率进一步提高到61.8%,显示了协同优化的优势。
从Table 3可以看到TinyEngine在5FPS下精度提升了1.9%,10FPS提升了5.4%,最终MCUNet将二者进一步提升了8.3%和6.4%。
Diverse Hardware constrains and lower bit precision
本文在不同硬件上使用了int8量化(工业最常用)和int4量化(可以容纳更大的模型),结果展示在Table 4.
不借助混合精度就可以在MCU上达到sota,显示了系统-算法协同设计的优越性。本文的MCUNet在STM32上达到了ImageNet 70.7%的top_1精度这是目前我们所知第一个在商用MCU上超过70%的算法。虽然与MobileNetV2和ResNet V2相近但是本文比分别减少了3.5x的memory和5.7倍的Flash。
Part 3 Visual and Audio Wake Words
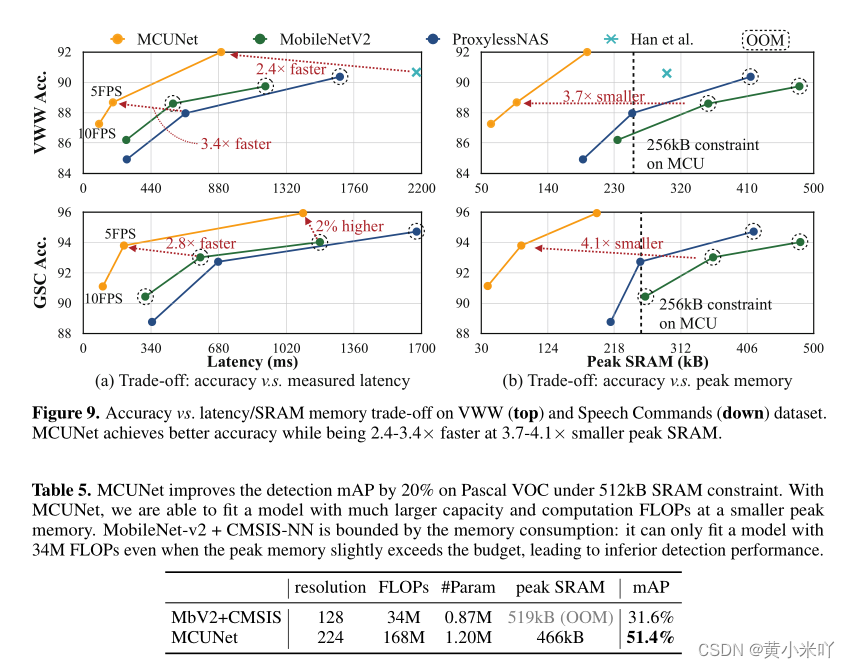
在视觉唤醒数据集和谷歌语音命令数据集上主要对比精度-延迟 和精度-峰值memory的trade off。结果参见Fig 9.在VWW数据集上,我们可以在2.4-3.4×的推理速度和3.7×的峰值内存下实现更高的精度;在语音命令数据集上,MCUNet在2.8×的推理速度和4.1×的峰值内存下实现了更高的精度。在256kbSRAM约束下,它比最大的MobileNetV2提高了2%的准确率,比最大的ProxylessNAS提高了3.3%。
Part 4 Object Detection on MCUs
本文还在MCU上测试了目标检测任务,测试MCUNet的泛化能力。因为目标检测对MCU来说更具挑战性,通常需要输入较高分辨率检测相对较小的对象,这回显著影响峰值性能。本文使用YOLOv2作为检测器,结果参见Table 5可以看在内存只有512kB的SRAM和2MB Flash下MCUNet显著提升205mAP,这使得AIoT的应用更可行。
Part 5 Analysis
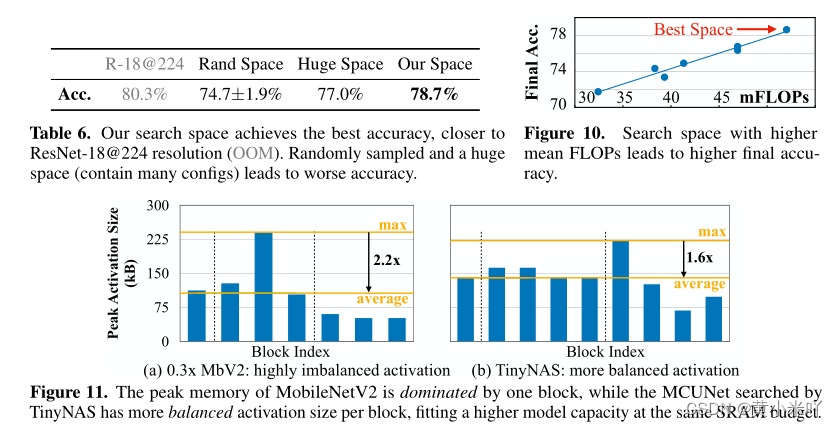
Search space optimization matters
搜索空间优化会显著提升NAS精度,Fig 3展示了消融实验的结果,可以看到前10的网络然后本文从中进行采样。
使用本文的搜索方法可以达到78.7%的精度但是从top-10中采样得到的效果并不好;本文还测试在较大的搜索空间进行搜索支持更多的分辨率和width multiplier但是也没有获得良好的性能,因为虽然搜索空间很大也增加了超网训练的难度。本文在Fig10中绘制了最终搜索模型的额精度与搜索空间配置之间的关系,可以看到是清晰的正相关关系,也验证了本文的假设。
Per-block peak memory analysis
Fig 11比较了不同网络在320kB SRAM下的峰值内存分布,可以看到MobileNetV2十分不平衡,有的层的峰值激活大小是平均的2.2x,那么其他模块就要被迫缩小容量。TinyNAS搜索的MCUNet拥有更平衡的峰值内存大小,网络整体容量更高,并且会自动进行内存分配,无需进行启发式研究。
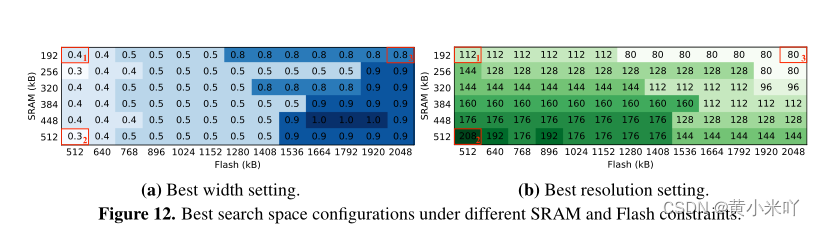
Sensitivity analysis on search space optimization
本文还发现了一些有趣的模式,参见Fig 12.可以看到更大的SRAM 可以存储更多激活值,因此可以使用更高的输入分辨率;更大的Flash可以存储更大的模型,因此可以使用更大的width multiplier。
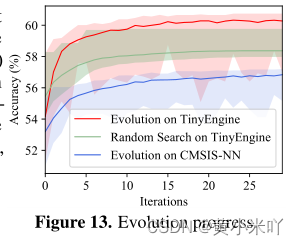
Evolution Search
Fig 13展示的则是进化搜索与RS的对比,在TinyEngine上,进化明显优于随机搜索,最佳准确率高出1%。由于内存不足,CMSIS-NN上的进化导致了更差的结果。
# Section V Conclusion
本文提出算法-系统协同设计更适合小型硬件的深度学习,分别通过TinyNAS和TinyEngine实现。本文在当前MCU上实现了创纪录的ImageNet精度(70.7%),并将唤醒词任务的推理加速了2.4-3.4×。我们的研究表明,在物联网设备上进行微型机器学习的时代已经到来

