
- 1【数据结构】哈希
- 2MySQL Workbench切换设置成中文(仅菜单项汉化)_mysql workbench中文设置
- 3iPad绘画之旅:从小白到文创手账设计的萌系简笔画探索
- 4Python程序设计作业笔记_python使用input()函数读取输入,输入是字符串,则返回字符串,输入是数值,则返回也
- 5python实现k均值聚类(kMeans)基于numpy_python k据类
- 6SourceTree使用看这一篇就够了_sourtree
- 7Spring Boot+Vue的高校食材采供管理系统
- 8面向对象设计原则实验之“接口隔离原则”
- 9数字IC设计SOC入门进阶_ic进阶
- 10数据结构—堆(Heap)的原理介绍以及Java代码的完全实现_java heap 是基于数组实现的吗
Yolov5缺陷检测/目标检测 Jetson nx部署Triton server_triton server 程序文件下载
赞
踩
使用AI目标检测进行缺陷检测时,部署到Jetson上即小巧算力还高,将训练好的模型转为tensorRT再部署到Jetson 上供http或GRPC调用。
- 1
1 Jetson nx 刷机
找个ubuntu 系统NVIDIA官网下载安装Jetson 的sdkmanager一步步刷机即可。
本文刷的是JetPack 5.1, 其中包含
CUDA 11.4
cuDNN 8.6.0
TensorRT 8.5.2.2
Python 3.8.10
Ubuntu 20.04
2 下载解压/安装/测试Triton Server
其实triton server 不用安装,直接下载解压开箱即用,要安装的是一堆依赖。
下载triton server 软件包,Release 2.35.0 corresponding to NGC container 23.06
找到下面tritonserver2.35.0-jetpack5.1.2.tgz下载到Jetson并解压到home。
根据jetson.md安装triton server 的依赖包,如果不在jetson上使用triton 客户端可以不装triton client 的依赖。
将Triton server main分支下的docs文件夹下载后放到home/tritonserver2.35.0-jetpack5.1.2/tritonserver中,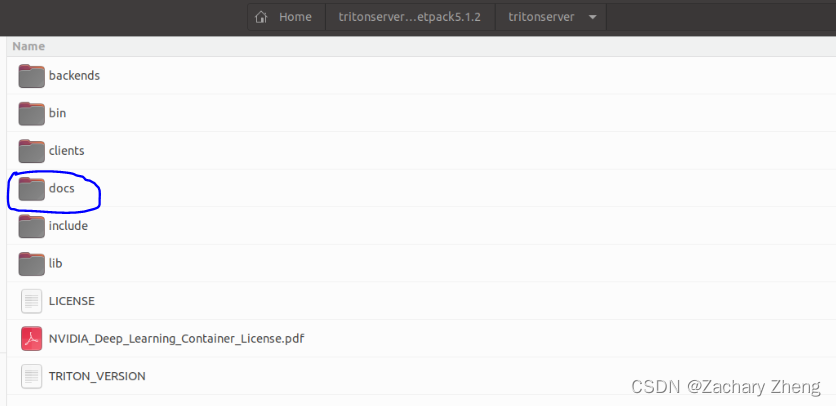
$ cd docs/examples
$ ./fetch_models.sh
下载示例模型,cd 到home/tritonserver2.35.0-jetpack5.1.2/tritonserver/bin
$./tritonserver --model-repository=…/docs/examples/model_repository --backend-directory=…/backends
如果看到下图8001/8000/8002 说明示例打开成功,triton server 安装成功。 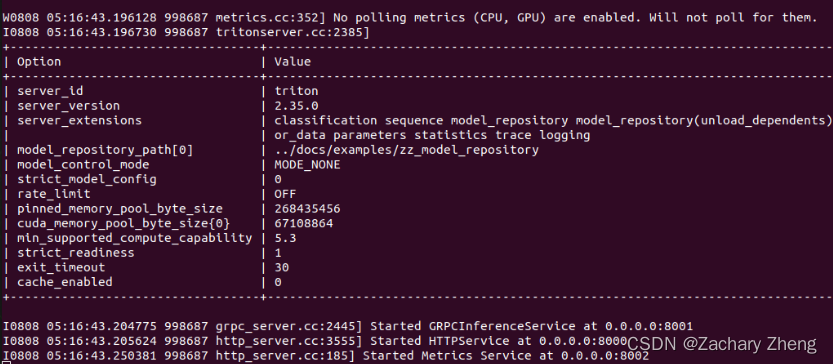
3 Train yolov5 model
使用ultralytics的yolov5 模型train 一个自己的model, 我选用的是yolov5l6,略微大一些, best.pt 153.1MB。
4 .pt 转ONNX 转TensorRT
个人认为只有使用TensorRT模型部署NVIDIA显卡才是推理速度最极致的体验。
Jetson 上官网下载一个Pycharm 软件压缩包,新建python环境。
安装yolov5的依赖,参考Deploy on NVIDIA Jetson using TensorRT and DeepStream SDK
安装到pytorch 和torchvision 即可,
再使用yolov5文件夹内export.py
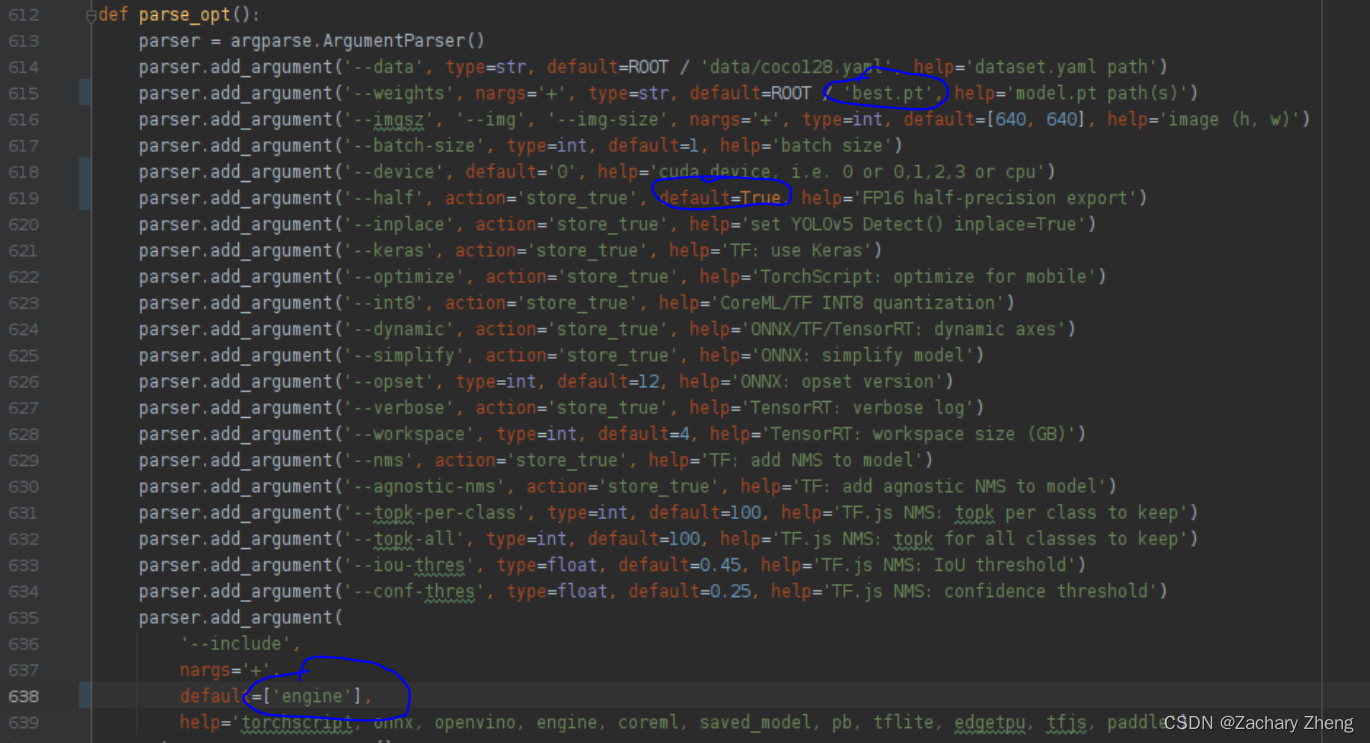
修改615行 --weights default ROOT / ‘best.py’
修改619行增加default=True使用半精度
修改638行default=[‘engine’]
Terminal $python3 export.py 可以看到log是先生成best.onnx再生成best.engine
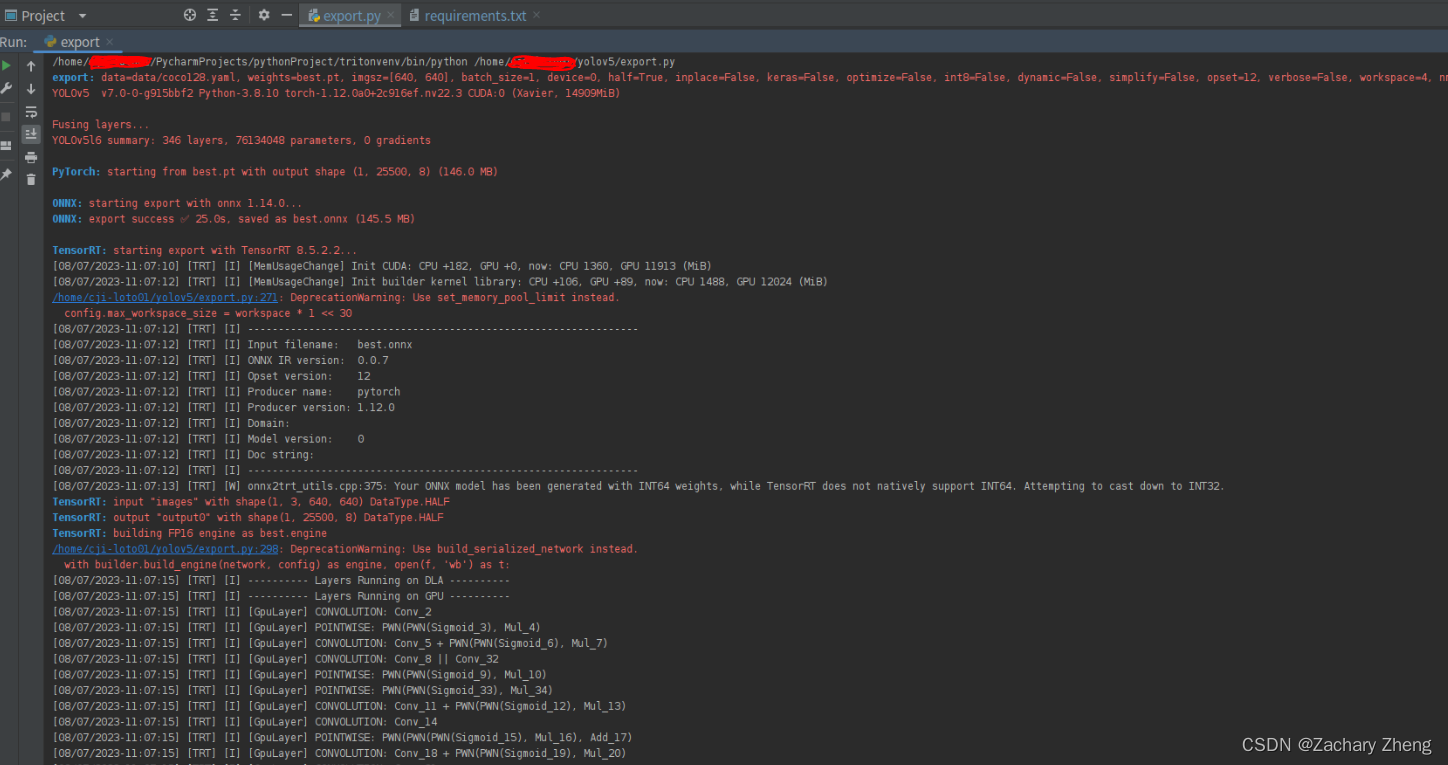
半小时后转化完毕。
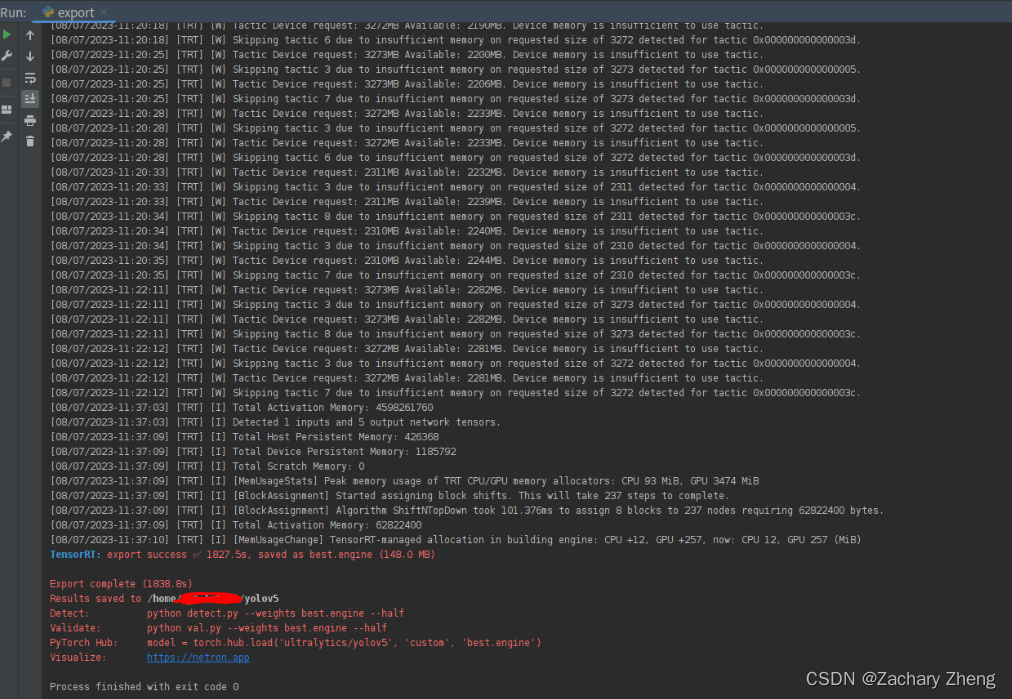
5部署yolov5 到triton sever
在examples文件夹下新建自己的模型仓库文件夹zz_model_repository
新建模型文件夹yolov5l6再新建名称为1 的文件夹将best.engine copy进来改名为model.plan
在yolov5l6下新建文件config.pbtxt输入以下内容:
name: "yolov5l6" platform: "tensorrt_plan" max_batch_size: 1 input [ { name: 'images' data_type: TYPE_FP16 format: FORMAT_NCHW dims: [3, 640, 640] } ] output [ { name: 'output0' data_type: TYPE_FP16 dims: [25500, 8] } ] backend: 'tensorrt'

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
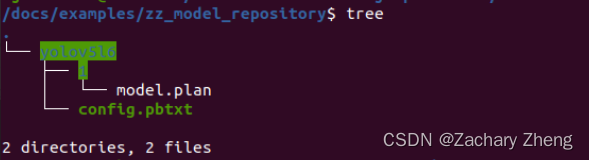
同样cd 到home/tritonserver2.35.0-jetpack5.1.2/tritonserver/bin
$./tritonserver --model-repository=…/docs/examples/zz_model_repository --backend-directory=…/backends
出现下图说明模型加载成功。
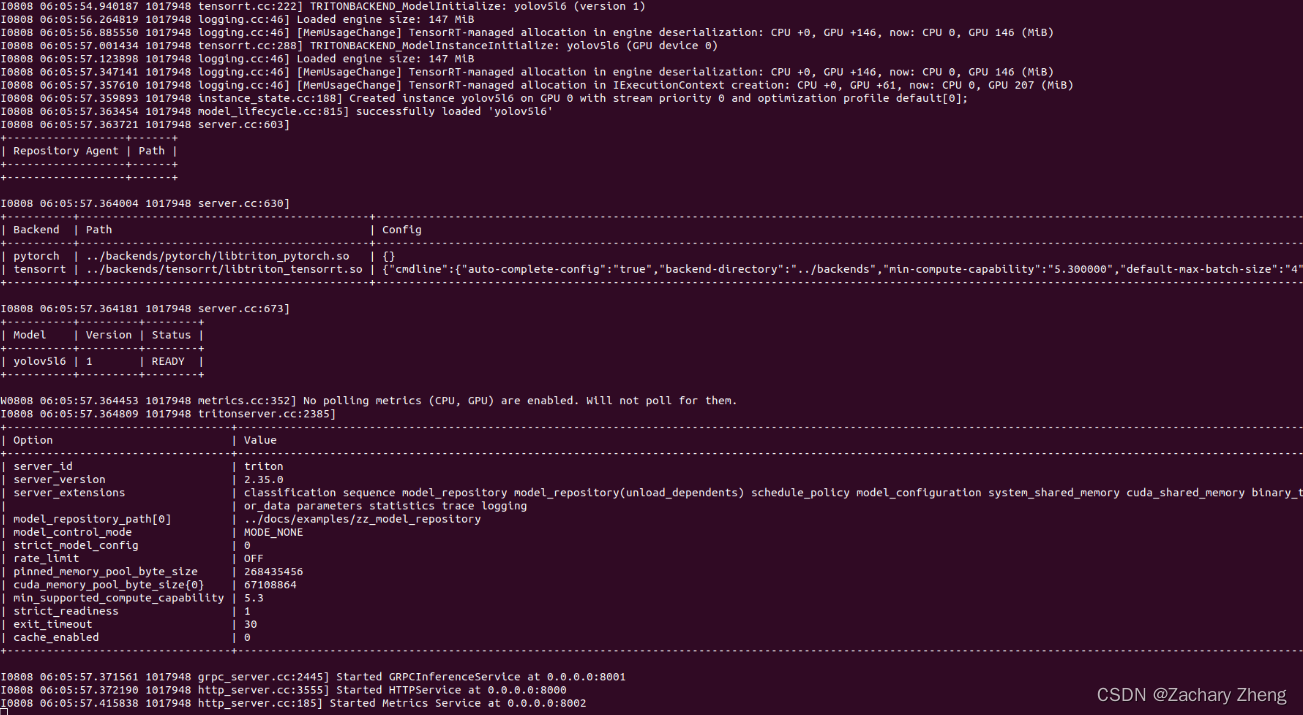
6Triton client 调用模型
这一部分就是开发相机,图像前处理,调用模型,图像后处理部分了,略过。

