
- 1Flutter 上了 Apple 第三方重大列表,2024 春季 iOS 的隐私清单究竟是什么?_privacy tracking domains
- 2PL/SQL实现1到100素数判断_plsql求素数
- 3【单片机家电产品学习记录--红外线】
- 4网络工程师——常用必背专业词汇_网络工程师常用英语汇总
- 5【并查集】Leetcode 547.省份数量_并查集 547
- 6【Python】成功解决AttributeError: ‘list‘ object has no attribute ‘replace‘_list' object has no attribute 'replace
- 7oracle 12c vs oracle 11204 优化器特性(optimizer_features_enable)差异_oracle _optimizer_partial_join_eval
- 82023年第十四届蓝桥杯javaB组 蜗牛解题思路(动态规划 O(n))_蓝桥杯蜗牛
- 9Python免费下载安装全流程(Python 最新版本),新手小白必看!_python下载教程
- 10华为某正式员工哀叹:自己被劝退了,同期入职的OD还好好的,正式员工还没外包稳定!...
【多模态】1、几种多模态 vision-language 任务和数据集介绍_多模态数据集
赞
踩
现在多模态任务越来越火,但之前没接触过的朋友们可能一脸懵,这些专有名词到底是什么意思?这任务到底要干一件什么事情?很茫然,我也是多模态小白,所以在做多模态之前,让我们一起先整明白这些任务到底在干什么。
一、Phrase Grounding
1.1 概念介绍
这个很难直接翻译,直译的话就是 “短语接地”,所以到底指的是啥?
其实最好不要直接翻译,要从任务中理解,这个任务就指的是给定一个文本输入,如 “一个穿绿衣服的人”,从图像中找到这个文本描述指向的目标并框出来
所以,phrase grounding 就是将自然语言中提到的有效目标和图像中特定区域对应起来的任务,注意是全部提到的目标,如下图所示

现在也有方法将目标检测构建成了 phrase grounding 任务了(GLIP),将 prompt 改成如下格式即可:

1.2 常用数据集介绍
1、Flickr30k Entities
论文:Flickr30k Entities: Collecting Region-to-Phrase Correspondences for Richer Image-to-Sentence Models
官网下载链接:http://shannon.cs.illinois.edu/DenotationGraph/data/index.html
github 链接:https://github.com/BryanPlummer/flickr30k_entities
标注文件在 github 链接中下载!!!
- 主要是用于图像描述的一个数据集,region-to-phrase 形式的对应,
- 包含 31783 张 image
- 每张图会对应 5 个不同的 caption,共 158915 个英文 caption
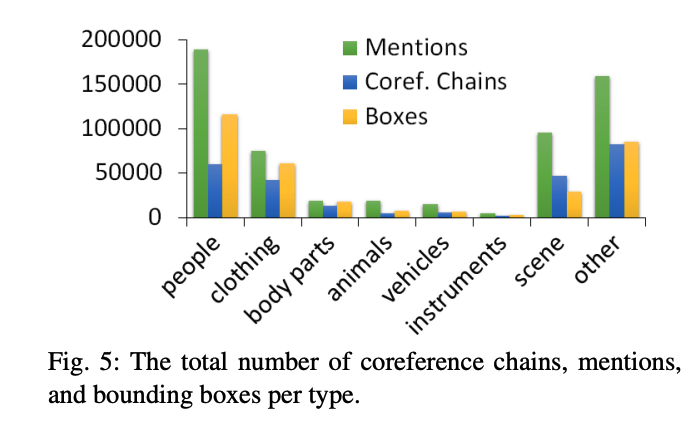
- 还包含 275775 个 phrase-box 标注。对于每个 phrase 还细分为 people, clothing, body parts, animals, vehicles, instruments, scene, othera八个不同的类别,如下图所示

1.3 评估指标
1、准确率
prediction box 和 groud-truth box 的 IoU 大于0.5记为一次正确定位,以此来计算准确率(Accuracy)
2、Recall@k
表示预测概率前 k 大的 prediction box 和 ground-truth box 的 IoU 大于 0.5 的定位准确率。
3、Point game
选择最终预测的 attention mask 中权重最大的像素位置,如果该点落在 ground-truth 区域内,记为一次正确定位。相比 Acc 指标更加宽松。
二、Referring Expression Comprehension(REC)
2.1 概念介绍
这个任务是框出文本中提到的一个特定目标
如输入文本为 “穿红短袖且背球拍的人”,则输出就会框出一个目标 person

2.2 常用数据集介绍
Refcoco 论文:Modeling Context in Referring Expressions
标注文件下载:https://github.com/lichengunc/refer
RefCOCO, RefCOCO+, RefCOCOg:
- 是三个从 MSCOCO 中选取图像得到的数据集,数据集中对所有的 phrase 都有 bbox 的标注
- RefCOCO 有19,994幅图像,包含142,210个引用表达式,包含50,000个对象实例。
- RefCOCO+ 共有19,992幅图像,包含 49,856 个对象实例的 141,564 个引用表达式。
- Ref COCOg 有25,799幅图像,指称表达式 95,010 个,对象实例 49,822个。

下图是论文中的一个图,每个图的 caption 描述在图片正下方,绿色是根据下面的 caption 标注的 gt,蓝色是预测正确的框,红色是预测错误的框


三、Visual Question Answer(VQA)
3.1 概念介绍
该任务是输入问题和图像,输出模型的回答
如输入 “左侧女孩手里拿的是什么”,模型会回答 “雨伞”

四、Image Caption
4.1 概念介绍
该任务是给图像生成描述,一般输入 prompt 为:“ a picture of {}”
模型的回答为:girls holding umbrellas.


