
热门标签
热门文章
- 1(51单片机)第八章-I2C总线AT24C02芯片应用
- 2计算机网络基础知识(五)——什么是TCPUDP协议?图文并茂的方式对两大传输层协议进行从头到尾的讲解_什么是tcp/udp协议栈
- 3线程间的通信机制介绍_线程与主线程之间的通信机制
- 4Linux 网络配置基础_/etc/sysconfig/network-scripts/ifcfg-eth0和/etc/res
- 530岁转行网络安全来得及吗?有发展空间吗?_37岁入行网络安全工程师
- 6数据结构Day02树的学习_创建一个node类,数据结构实现结点类的基本方法。
- 7【ROS机械臂入门教程】
- 8《数据结构》---三元组的实现_数据结构实现三元组
- 9VScode 配置 ros环境& gdb调试_vscode ros gdb
- 10Pytorch从零开始实现Transformer (from scratch)_用pytorch实现transformers
当前位置: article > 正文
LMDeploy 推理部署工具
作者:羊村懒王 | 2024-04-19 06:09:33
赞
踩
LMDeploy 推理部署工具
一. 大模型部署面临的挑战
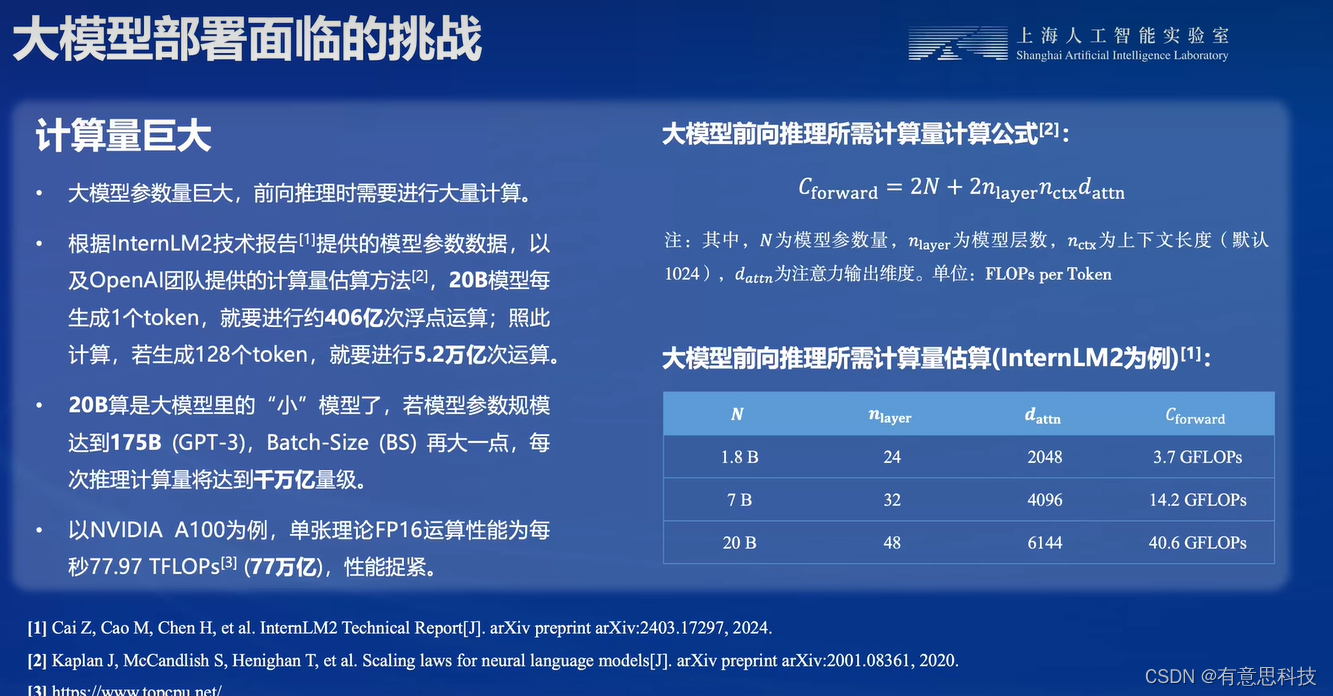
1. 计算量巨大
大模型参数量巨大,前向推理时需要进行大量计算。
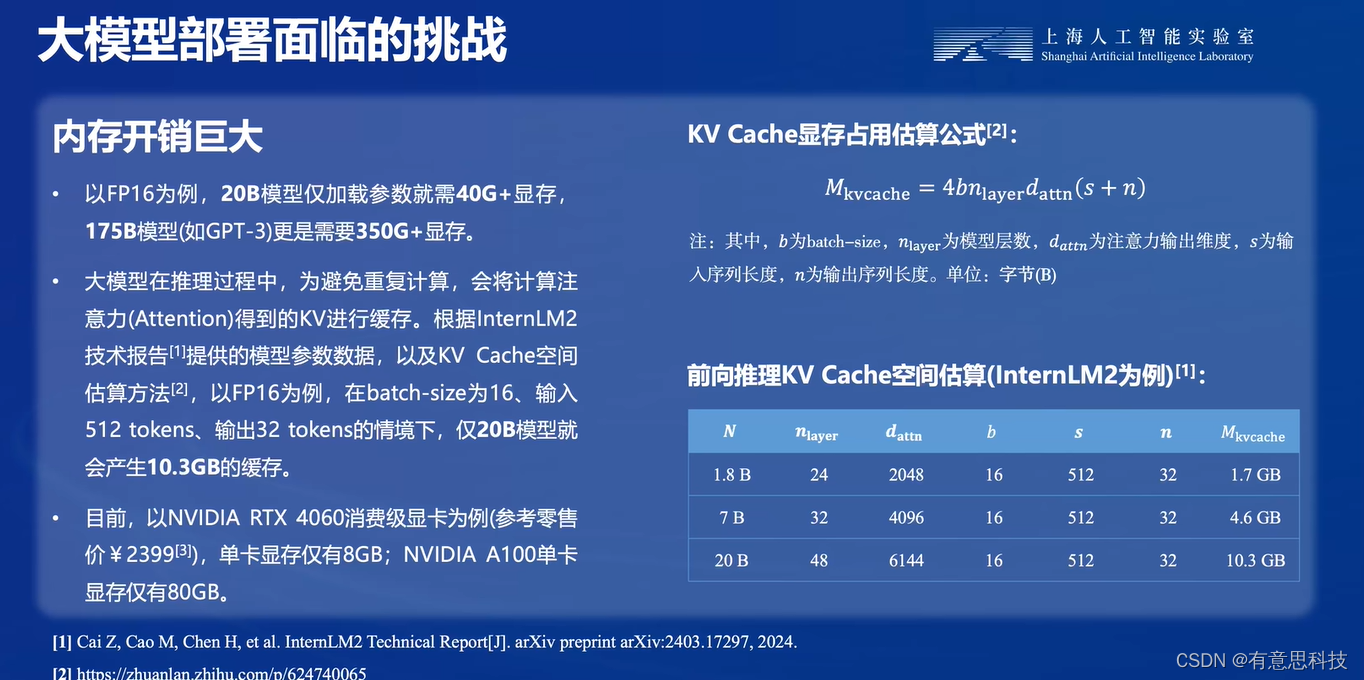
2. 内存开销巨大
大模型在推理过程中,以FP16为例,20B模型仅加载参数就需40G+显存,175B模型更是需要350G+显存。同时在推理过程中,为避免重复计算,会将计算注意力得到的KV进行缓存。
而目前的最大的GPU的显存仅为80GB。
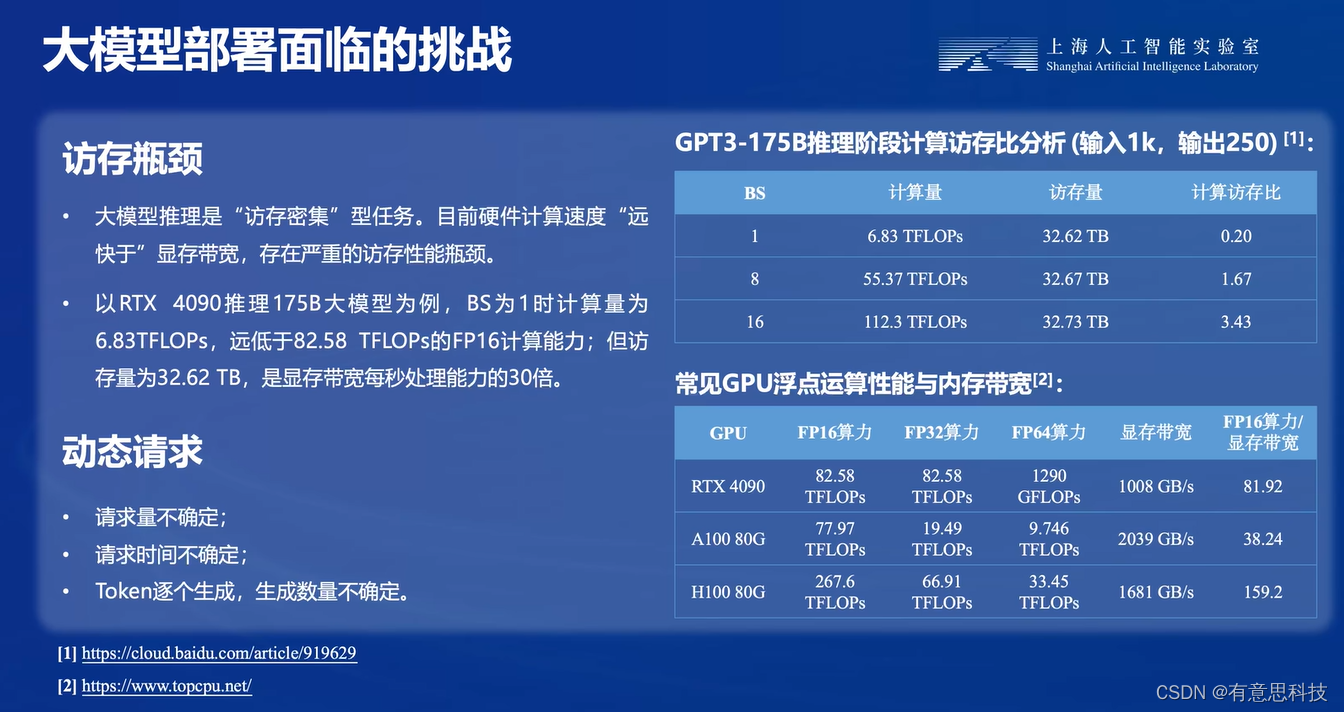
3. 访存瓶颈
大模型推理时”访问密集“型任务。目前硬件计算数据"远快于”显存带宽,存在严重的访存性能瓶颈。
二. LMDeploy
1. 简介
LMDeploy由MMDeploy 和 MMRazor 团队联合开发,时涵盖了LLM任务的全套轻量化,部署和服务解决方案。核心功能包括高效推理,可靠量化,便捷服务和有状态推理。

2. 核心功能
LMDeploy主要提供 模型高效推理,量化压缩,服务化部署等核心功能。

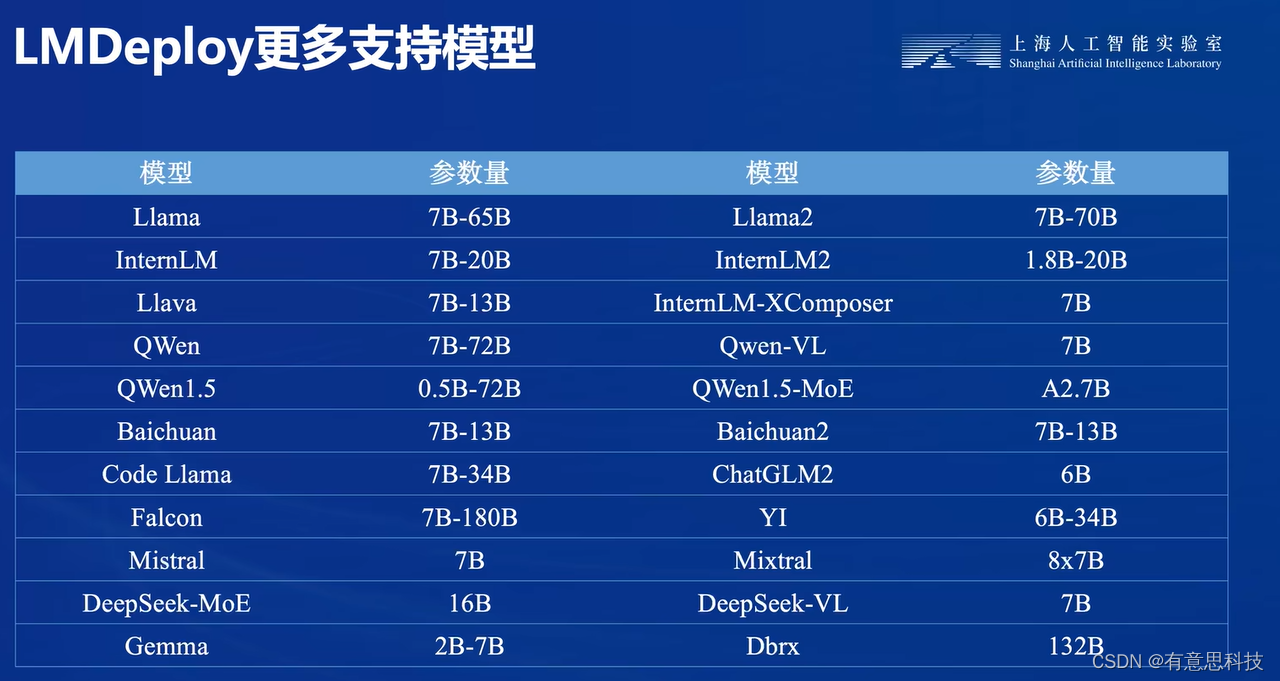
3. 支持的模型
不仅仅支持InternLM,而且支持目前大部分的开源模型,包括国外的LLama,国内的Qwen, baichuan等。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/450278
推荐阅读
相关标签

