
- 1冒泡和归并排序对比_lyqabqh
- 2前端和算法实现:给网站上加上自己的水印(简单+复杂)
- 3oracle not in和not exists在处理null值时的区别_oracle的not in空值
- 4Python使用lxml模块抓取数据_etree 获取数据
- 5左(6)hash,大数据,位运算_大文件hash
- 6EXISTS和IN的区别_in和exists的区别
- 7navicat64位和ql\sql64位连接oracle11g, 不安装oracle客户端,缺少oci.dll_nivact连oracle需要装客户端吗?
- 8携程Apollo统一配置中心的搭建和使用(java)
- 9杂项:git修改历史提交(commit)信息(超详细,图文并茂)_git 修改历史commit
- 10hadoop生态系统的详细介绍-详细一点_简述hadoop生态体系
机器学习实战2.1. 超详细的k-近邻算法KNN(附Python代码)_knn实例附代码python
赞
踩
机器学习实战2.1. 超详细的k-近邻算法KNN(附Python代码)
搜索微信公众号:‘AI-ming3526’或者’计算机视觉这件小事’ 获取更多机器学习干货
csdn:https://blog.csdn.net/baidu_31657889/
github:https://github.com/aimi-cn/AILearners
本文参考地址:[apachecn/AiLearning]
本文出现的所有代码,均可在github上下载,不妨来个Star把谢谢~:Github代码地址
KNN 概述
k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法。
一句话总结:近朱者赤近墨者黑!
工作原理:
存在一个样本数据集合,也称作为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一个数据与所属分类的对应关系。输入没有标签的新数据后,将新的数据的每个特征与样本集中数据对应的特征进行比较,然后算法提取样本最相似数据(最近邻)的分类标签。一般来说,我们只选择样本数据集中前k个最相似的数据,这就是k-近邻算法中k的出处,通常k是不大于20的整数。最后,选择k个最相似数据中出现次数最多的分类,作为新数据的分类。
k近邻算法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k 近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻算法不具有显式的学习过程。
k近邻算法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。 k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。
KNN 场景
电影可以按照题材分类,那么如何区分 动作片 和 爱情片 呢?
- 动作片:打斗次数更多
- 爱情片:亲吻次数更多
基于电影中的亲吻、打斗出现的次数,使用 k-近邻算法构造程序,就可以自动划分电影的题材类型。
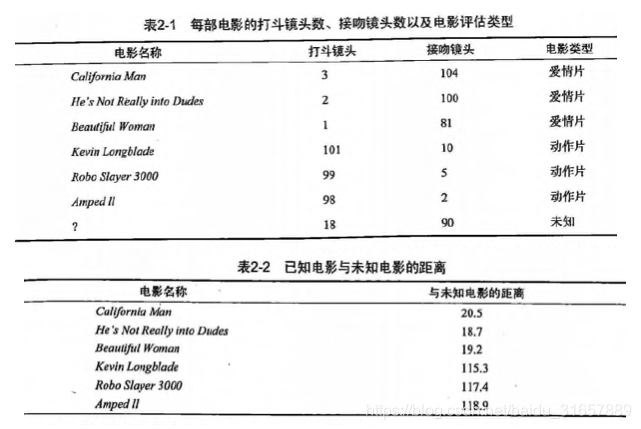
现在根据上面我们得到的样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到 k 个距离最近的电影。
假定 k=3,则三个最靠近的电影依次是, He’s Not Really into Dudes 、 Beautiful Woman 和 California Man。
knn 算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
对于K近邻算法概念还没搞太清楚的同学 可以往下面看 直到看完整个demo你就可以理解KNN算法是干啥的了
KNN 原理
KNN 工作原理
- 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
- 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
- 计算新数据与样本数据集中每条数据的距离。
- 对求得的所有距离进行排序(从小到大,越小表示越相似)。
- 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。
- 求 k 个数据中出现次数最多的分类标签作为新数据的分类。
KNN 通俗理解
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的 k 个实例,这 k 个实例的多数属于某个类,就把该输入实例分为这个类。
KNN 开发流程
收集数据:任何方法
准备数据:距离计算所需要的数值,最好是结构化的数据格式
分析数据:任何方法
训练算法:此步骤不适用于 k-近邻算法
测试算法:计算错误率
使用算法:输入样本数据和结构化的输出结果,然后运行 k-近邻算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
- 1
- 2
- 3
- 4
- 5
- 6
KNN 算法特点
优点:精度高、对异常值不敏感、无数据输入假定
缺点:计算复杂度高、空间复杂度高
适用数据范围:数值型和标称型
- 1
- 2
- 3
话不多说直接上代码:
代码地址:https://github.com/aimi-cn/AILearners/tree/master/src/py2.x/ml/jqxxsz/2.KNN/KNN.py
#!/usr/bin/env python # -*- encoding: utf-8 -*- ''' @File : KNN.py @Time : 2019/03/27 11:07:01 @Author : xiao ming @Version : 1.0 @Contact : xiaoming3526@gmail.com @Desc : KNN近邻算法 @github : https://github.com/aimi-cn/AILearners @reference: https://github.com/apachecn/AiLearning ''' # here put the import lib from __future__ import print_function from numpy import * import numpy as np import operator # 导入科学计算包numpy和运算符模块operator from os import listdir from collections import Counter def createDataSet(): """ 创建数据集和标签 调用方式 import kNN group, labels = kNN.createDataSet() """ group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A','A','B','B'] return group, labels def test1(): group, labels = createDataSet() ''' [[1. 1.1] #标签对应A [1. 1. ] #标签对应A [0. 0. ] #标签对应B [0. 0.1]] #标签对应B ['A', 'A', 'B', 'B'] ''' #print(str(group)) #print(str(labels)) #print(classify0([0.1, 0.1], group, labels, 3)) print(classify1([0.1, 0.1], group, labels, 3)) def classify0(inX, dataSet, labels, K): ''' inX: 用于分类的输入向量 输入的测试数据 dataSet:输入的训练样本 lables:标签向量 k:选择最近邻居的数目 通常小于20 注意:labels元素数目和dataSet行数相同;程序使用欧式距离公式. 预测数据所在分类可在输入下列命令 kNN.classify0([0,0], group, labels, 3) ''' # -----------实现 classify0() 方法的第一种方式---------------------------------------------------------------------------------------------------------------------------- # 1. 距离计算 #计算数据大小 dataSetSize = dataSet.shape[0] ''' tile使用: 列3表示复制的行数, 行1/2表示对inX的重复的次数 In [2]: inx = [1,2,3] In [3]: tile(inx,(3,1)) #列3表示复制的行数 行1表示对inX的重复的次数 Out[3]: array([[1, 2, 3], [1, 2, 3], [1, 2, 3]]) In [4]: tile(inx,(3,2)) #列3表示复制的行数 行2表示对inX的重复的次数 Out[4]: array([[1, 2, 3, 1, 2, 3], [1, 2, 3, 1, 2, 3], [1, 2, 3, 1, 2, 3]]) ''' # tile生成和训练样本对应的矩阵,并与训练样本求差 diffMat = tile(inX, (dataSetSize, 1)) - dataSet ''' 欧氏距离: 点到点之间的距离 第一行: 同一个点 到 dataSet的第一个点的距离。 第二行: 同一个点 到 dataSet的第二个点的距离。 ... 第N行: 同一个点 到 dataSet的第N个点的距离。 [[1,2,3],[1,2,3]]-[[1,2,3],[1,2,0]] (A1-A2)^2+(B1-B2)^2+(c1-c2)^2 ''' # 取平方 sqDiffMat = diffMat ** 2 # 讲矩阵的每一行相加 sqDistances = sqDiffMat.sum(axis=1) # 开方 distances = sqDistances ** 0.5 #print ('distances=', distances) #distances= [1.3453624 1.27279221 0.14142136 0.1] # 根据距离排序从小到大的排序,返回对应的索引位置 sortedDistIndicies = distances.argsort() #print ('distances.argsort()=', sortedDistIndicies) #distances.argsort()= [3 2 1 0] # 2. 选择距离最小的K个点 classCount = {} for i in range(K): #找到该样本的类型 voteIlabel = labels[sortedDistIndicies[i]] # 在字典中将该类型加一 # 字典的get方法 # 如:list.get(k,d) 其中 get相当于一条if...else...语句,参数k在字典中,字典将返回list[k];如果参数k不在字典中则返回参数d,如果K在字典中则返回k对应的value值 # l = {5:2,3:4} # print l.get(3,0)返回的值是4; # Print l.get(1,0)返回值是0; classCount[voteIlabel] = classCount.get(voteIlabel, 0) + 1 #print(classCount) #{'A': 1, 'B': 2} # 3. 排序并且返回出现最多的那个数据类型 # 字典的 items() 方法,以列表返回可遍历的(键,值)元组数组。 # 例如:dict = {'Name': 'Zara', 'Age': 7} print "Value : %s" % dict.items() Value : [('Age', 7), ('Name', 'Zara')] # sorted 中的第2个参数 key=operator.itemgetter(1) 这个参数的意思是先比较第几个元素 # 例如:a=[('b',2),('a',1),('c',0)] b=sorted(a,key=operator.itemgetter(1)) >>>b=[('c',0),('a',1),('b',2)] 可以看到排序是按照后边的0,1,2进行排序的,而不是a,b,c # b=sorted(a,key=operator.itemgetter(0)) >>>b=[('a',1),('b',2),('c',0)] 这次比较的是前边的a,b,c而不是0,1,2 # b=sorted(a,key=opertator.itemgetter(1,0)) >>>b=[('c',0),('a',1),('b',2)] 这个是先比较第2个元素,然后对第一个元素进行排序,形成多级排序。 #我们现在需要出现次数最多的那个 所以使用reverse=True列表反向排序 sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True) return sortedClassCount[0][0] def classify1(inX, dataSet, labels, K): ''' inX: 用于分类的输入向量 输入的测试数据 dataSet:输入的训练样本 lables:标签向量 k:选择最近邻居的数目 通常小于20 注意:labels元素数目和dataSet行数相同;程序使用欧式距离公式. 预测数据所在分类可在输入下列命令 kNN.classify0([0,0], group, labels, 3) ''' # -----------实现 classify0() 方法的第二种方式---------------------------------------------------------------------------------------------------------------------------- # 欧氏距离: 点到点之间的距离 # 第一行: 同一个点 到 dataSet的第一个点的距离。 # 第二行: 同一个点 到 dataSet的第二个点的距离。 # ... # 第N行: 同一个点 到 dataSet的第N个点的距离。 # [[1,2,3],[1,2,3]]-[[1,2,3],[1,2,0]] # (A1-A2)^2+(B1-B2)^2+(c1-c2)^2 # inx - dataset 使用了numpy broadcasting,见 https://docs.scipy.org/doc/numpy-1.13.0/user/basics.broadcasting.html # np.sum() 函数的使用见 https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.sum.html # """ dist = np.sum((inX - dataSet)**2, axis=1)**0.5 # """ # 2. k个最近的标签 # 对距离排序使用numpy中的argsort函数, 见 https://docs.scipy.org/doc/numpy-1.13.0/reference/generated/numpy.sort.html#numpy.sort # 函数返回的是索引,因此取前k个索引使用[0 : k] # 将这k个标签存在列表k_labels中 # """ k_labels = [labels[index] for index in dist.argsort()[0 : K]] # """ # 3. 出现次数最多的标签即为最终类别 # 使用collections.Counter可以统计各个标签的出现次数,most_common返回出现次数最多的标签tuple,例如[('lable1', 2)],因此[0][0]可以取出标签值 # """ label = Counter(k_labels).most_common(1)[0][0] return label if __name__ == '__main__': test1()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
输入: dataSet:输入的训练样本 [[1.0,1.1] #标签对应A [1.0,1.0] #标签对应A [0, 0] #标签对应B [0, 0.1]] #标签对应B lables:标签向量 ['A', 'A', 'B', 'B'] inX: 用于分类的输入向量 输入的测试数据 [0.1, 0.1] 输出: B 说明这个输出的标签更靠近B 输入B类 ### 详细介绍看代码注释哈
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
AIMI-CN AI学习交流群【1015286623】 获取更多AI资料
扫码加群:

分享技术,乐享生活:我们的公众号每周推送“AI”系列资讯类文章,欢迎您的关注!


