
- 1adb install 时 日志输出Performing Streamed Instal 一直卡着不动,处理方法_performing streamed install
- 2【STM32+HAL+Proteus】系列学习教程---串口USART(DMA 方式)定长,不定长收发。
- 3Java常用实现八种排序算法与代码实现_java排序算法代码
- 4【Vue】Vue 入门学习文档_vue文档
- 5达梦数据库安装超详细教程(小白篇)
- 6Linux Centos7 修改yum源镜像_centos7修改yum镜像
- 7三十分钟理解博弈论“纳什均衡” -- Nash Equilibrium
- 8stm32知识记录
- 9【重磅开源】一款可以生成SpringBoot+Vue代码的轻量级项目
- 10精选Axure原型设计模板,RP原型组件库(PC端移动端元件库及Axure函数及运算符说明)_大饼pc端产品设计标准设化模板原型
【机器学习算法】关联规则-1 关联规则的概念,Apriori算法,实例和优缺点_apriori算法有什么缺点
赞
踩
目录
我的主页:晴天qt01的博客_CSDN博客-数据分析师领域博主
目前进度:第四部分【机器学习算法】
关联规则
关联规则的概念:
关联规则是由数据挖掘之父Rakesh Agrawal提出
当他提出这个关联规则之后数据挖掘概念一度非常火,比如非常著名的啤酒与尿布,其实就是通过关联规则找出啤酒与尿布的关联规则关系。
而且这个关联规则被运用到商业中,并且运用的非常成功,它刚开始是在IBM,现在被微软挖墙角,现在在微软工作,是微软的技术工作人员。

建立软件IBM Intelligent Miner ,当时就被部署到云计算中去,在IBM的云中。
许多数据挖掘算法的设计者Apriori和AprioriAll都是他设计建立的。
关联规则是为了寻找经常购买的产品组合。从交易数据库里,找到经常购买的数据库组合
关联规则的原因:
购物篮分析(如果我们知道了哪些产品顾客会同时购买,我们把商品包装为一个pakege,比如AB这两个商品经常被一起购买,所以我们就可以针对这项目,进行设定折扣活动,做交叉销售(cross -marketing,),就一个客户经常购买A类产品,就可以推荐他来购买B,或者catalog design现在某人购买了商品A,下面的推荐页就会出现与A相关的BCD商品组。甚至我们可以进行空间的设计,什么商品应该放在什么商品的旁边,(shelf space layout design)比如我们购买小孩玩具的时候,一般都会多购买几个电池,所以就可以把电动玩具和电池放在同一个位置,这就是透过关联规则了解商品被一起购买的可能性,然后一起购买,或者etc)
案例:
关联规则表示一:
表示为:Body——》Head[Support,Confidence]
Buys(x,“Computer”)——》buys(x,“Software”)[2%,60%]
代表了x购买computer之后再次购买软件的关系,我们有两个指标,一个是支持度support和置信度confidence,在这个规则里,支持度就是百分之2,置信度就是百分之60。置信度就是条件概率,就是在卖电脑的情况下,购买软件的概率是百分之60,支持度一会我们细说。
这种形式的关联规则,我们叫单维度得到关联规则,因为它只涉及一个维度,买什么影响买什么,
关联规则表示二:
其实我们也有多维度的关联规则,比如我们输入的是一张表格,而不是一笔一笔的交易。
规则表示如下:
major(x,“CS”)^takes(x,“DB”)——》grade(x,“A”)[1%,75%]
如果X它的科系是电脑CS,修了一门数据库DB的课,这个人成绩得到A的概率是百分之75。
而之后我们用Apriori算法既可以得到多维度的关联规则,又可以得到单维度的关联规则
关联规则的评估指标
-评估指标也就是支持度和置信度
刚才我们已经说了置信度,其实就是条件概率,在body发生的概率下,Head发生的概率。
现在说一下支持度
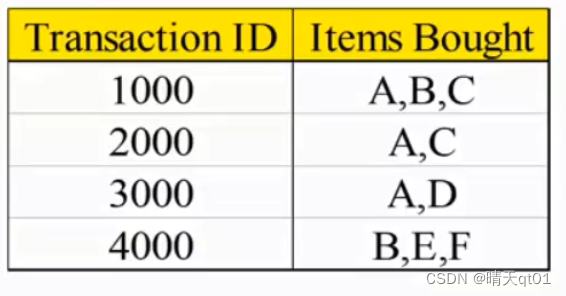
下面是案例:

字段1是我们的交易编号,通常关联规则是以一个交易为单位,所以这里就有它的交易编号,这里我们代表也是一个交易编号,代表顾客同时购买了几种商品。
第一个记录代表的就是ABC3个产品同时被顾客购买
第二笔记录是顾客同时购买AC这两种商品。
现在我们就2个商品A——》C这两个商品,这个方向,的关联规则
A——》C,关联规则都会有两个指标
支持度Support=Support({A,C})=50%
置信度Confidence=Support({A,C})/Support({A})=66.6%
支持度是什么,就是我们不看——》这个方向,我们单纯就看,A与C同时被购买的概率就是我们的支持度。
我们来看看我们的数据,有多少数据是A和C同时被购买,第一笔,第二笔AC都被同时购买,所以AC被同时购买的支持率就是被购买的笔数除以/总笔数。就是2/4,百分之50
置信度就是,AC的支持度和A的支持度的除法,也就是AC同时被购买的概率除以A被购买的概率。也就是2/4除以3/4。也可以理解为,购买A的次数有3次,其中有2次也购买C了,用2/3就是置信度。也就是在A被购买的情况下C也被购买的概率。
但是一条规则有了支持度和置信度,它不一定是关联规则。关联规则我们必须舍得一个最低门槛,同时满足两个条件,第一个就是我们定义的最小支持度的门槛,minimum support和最小置信度的门槛minimum confidence。
所以我们做关联规则必须设定2个参数,一个是最小支持度,一个是最小置信度。
我们也把关联规则的确定叫做购物篮分析,主要原因就是因为,我们的市场分析师,就是为了分析顾客会放什么东西到我们的购物篮里面。购物篮的东西就是同时间被购买的东西,市场分析师想了解哪些商品顾客会同时购买,那如果他知道这个信息,就可以进行很多相关的活动设定,所以我们把关联规则分析也叫做购物篮分析。
假如你得到了一个关联规则。
Shirt和tie[13.5%,70%]
现在你要用两句话来描述着两个关联规则,你要怎么说
顾客买了一件shirt,再同时购买tie的概率有百分之70,
顾客同时购买shirt和tie的概率占总购买量的百分之13.5
现在,我们有一个案例
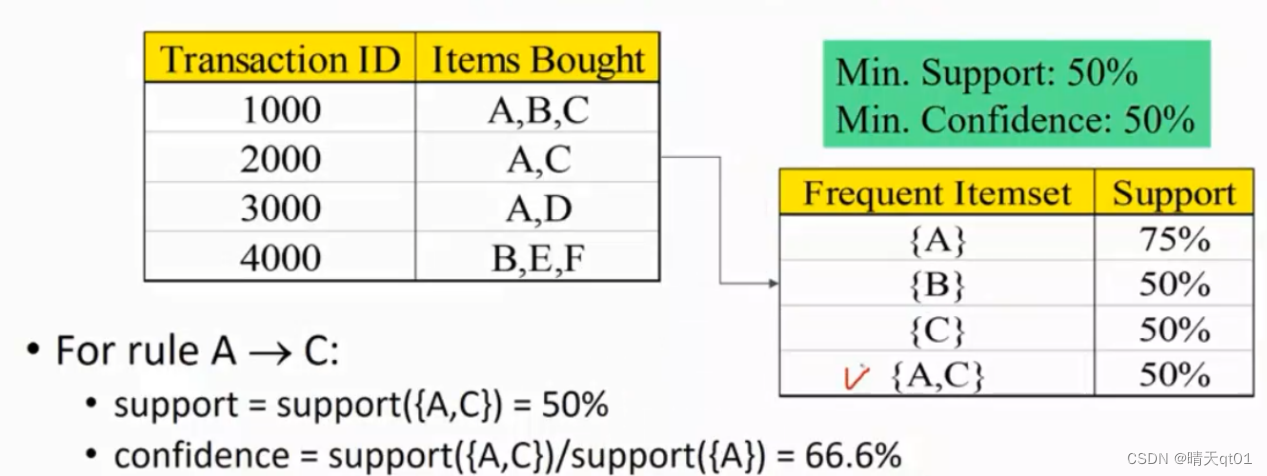
我们设定,我们的最小支持度为百分之50,最小置信度为百分之50。那么我们就会得到2条关联规则。
A——》C[50%,66.6%]
C——》A[50%,100%]
首先我们看AC各自的支持度,AC和CA都是占了案例的一半。置信度,在A条件下的c有百分之66.6,而在C条件下的A为百分之百所以这两对会同时出现。
但是这两个关联规则一定会同时出现吗
不见得,如果我们把置信度的要求设定为百分之70.
那么A——》C就不会出现了不见得会成对产生。
APriori算法
-非常有名的算法,解决暴力法的弊端、apriori的算法
于是我们就考虑,我们直接把全部的支持度和置信度都整理出来,不就可以找到了合理的关联规则了吗。
但是这里有一个问题,我们的关联规则是指数递增的我们要从这个指数个数的小规则里,寻找到全部的关联规则,需要的时间要非常非常的久,假如我们单一商品一共有100种
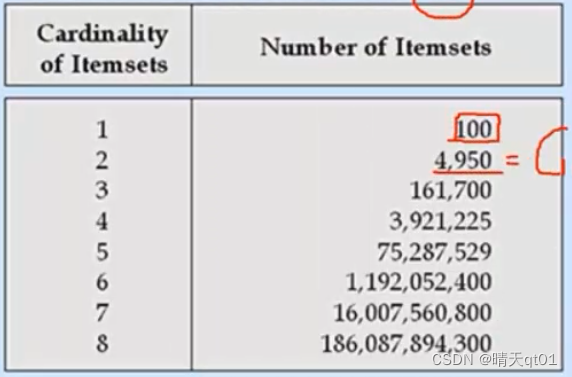
如果要寻找商品之间两两关联的规则,就有4950个规则,3个产品的组合,比如AB——》C,那就要求C100取3.也就是161700
如果要把每种方法都尝试一遍,就要关联2100-1次。在里面寻找我们需要的关联规则,这就已经是一个天文数字了,而且我们卖场还不只有100件商品,10万种商品这样,2的10万次方-1,不可能短时间得到,所以我们不可能用暴力法得到关联规则的问题。它的问题就是执行时间太久。
算法Apriori其实只有一个理论,Apriori Principle
它其实就是一句话,如何frequent itemset的子集合也一定是frequent itemset
Frequent itemset就是频繁被购买的组合。一个被频繁购买的组合,它的子集合也一定会被频繁购买。举例来讲
A,C,有4笔交易,有两笔是包含AC,支持度是百分之50.我们设定的最小支持度是百分之50,所以AC就是一个频繁项目。也就是只要大于最小支持度的就会被我们算做频繁商品组合。
而我们的理论Apriori Principle代表的就是,AC既然指数出现两次,那么其中A,C也肯定至少出现2次。最差的情况就是和AC的支持度。这就是被频繁购买的组合,它的子集也一定被频繁购买。
这就是我们算法的唯一理论。
但是我们apriori算法使用的时候,不是直接使用,而是倒着用。比如我们有一个商品E,它仅仅出现一次,支持度是1/4,那么所有和E的组合你就不用考虑了,AE,BE,CE都不用考虑。因为最好的情况也就是1/4。也就是说,子集合数据都不够,那么与它相关的集合,也就不用考虑了。
Apriori的步骤
首先寻找经常被购买的组合是哪一些,例如,AB经常被购买,因为AB的支持度大于最小支持度的门槛值。所以AB代表经常被购买的产品组合。
这时代表它们的最小支持度已经够了,接下来再由经常被购买的项目里产生关联规则。
比如AB,就可以产生2条关联规则,比如A——》B或者B——》A。
这时就只要考虑这两个规则的置信度,如果有,就是我们的关联规则,没有就不是我们的关联规则,如果都满足,就可以输出我们的关联规则
Apriori算法的实例说明
-候选项集的产生和候选项集的缩减

这个案例是5笔交易,代表这些项目被同时购买的5笔订单。
我们现在设定我们的最小支持度为百分之30,最小置信度为百分之60
我们会得到一条规则(orange juice)——》(soda)
也就是买orange juice就很可能买soda。
而且仅有这条关联规则,那么这条真的是关联规则吗。我们来看看,第一订单他们俩被同时购买,第3笔订单他们也被同时购买。剩下的没有。
所以它的支持度是百分之40,置信度是百分之66.6因为3笔购买orange juice的情况购买了
我们来看看apriori的实际处理过程。

我们来看第一个表格,它是把全部的商品的支持度都计算出来,寻找其中满足置信度大于最小置信度的商品。最后剩下左上第二个表格的3个商品,1orange juice 2soda 3window cleaner。
然后我们可以根据这3个商品组合出长度是二的商品组合。也就是左下角的图片,这3个图进行求支持度,因为后两个关联规则不满足条件然后它就被我们过滤掉。于是我们就只找到 关联规则orange juice和soda的关联规则。
而且由于长度为2的关联规则只有1,我们就没法去组长度为3的关联规则。
然后我们就可以去找卖orange juice——》soda
和soda——》orange juice的规则
第一条规则的置信度是百分之66.6
第二条规则的置信度是百分之50
为什么第二条才一半呢,因为soda有4次购买,其中只有2次购买了orange juice

于是我们就得到他的过程,就是这样。先从单个项目中去筛,然后两两关联的项目中去筛,因为不能得到3个关联规则的情况,最后利用置信度,来筛出关联规则。
再举一个复杂一些的例子。
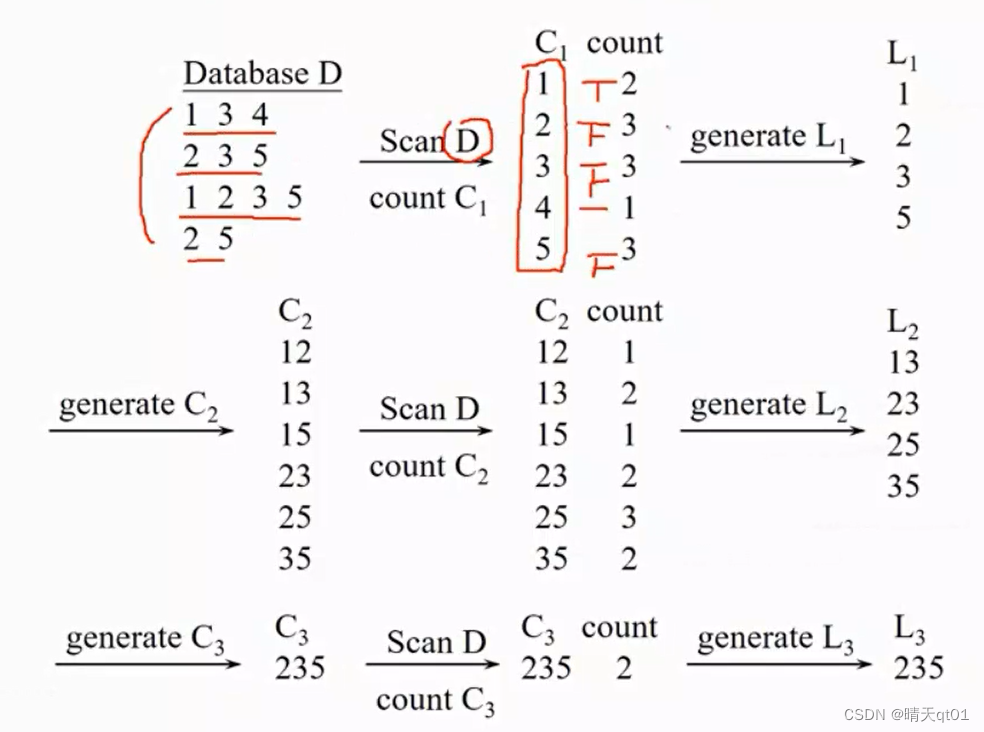
这里我们有一个数据D,代表4笔交易,我们会对里面的商品进行计数处理,得到C1,然后我们现在设定支持度,这里我们不用百分比,直接用次数介绍,也就是,至少要出现2笔交易,于是就筛选出1235这4个情况L1,我们现在通过L1产生交叉长度为2的候选人,最后得到,12,13,15,23,25,35,再次扫描一下数据库,扫描他们出现的次数。最后得到出现次数为121232.筛除出长度为2的频繁项目:13,23,25,35。然后我们要得到长度为3的频繁项目。一个长度为3的频繁项目要求,每个两两对应的单独频繁项目都有频繁出现过才能检查,比如235,就要求23,25,35都频繁出现过,这就是我们的候选人235,其他都不用考虑。最后我们就得到235的项目组合。
还有一个更为复杂的案例:
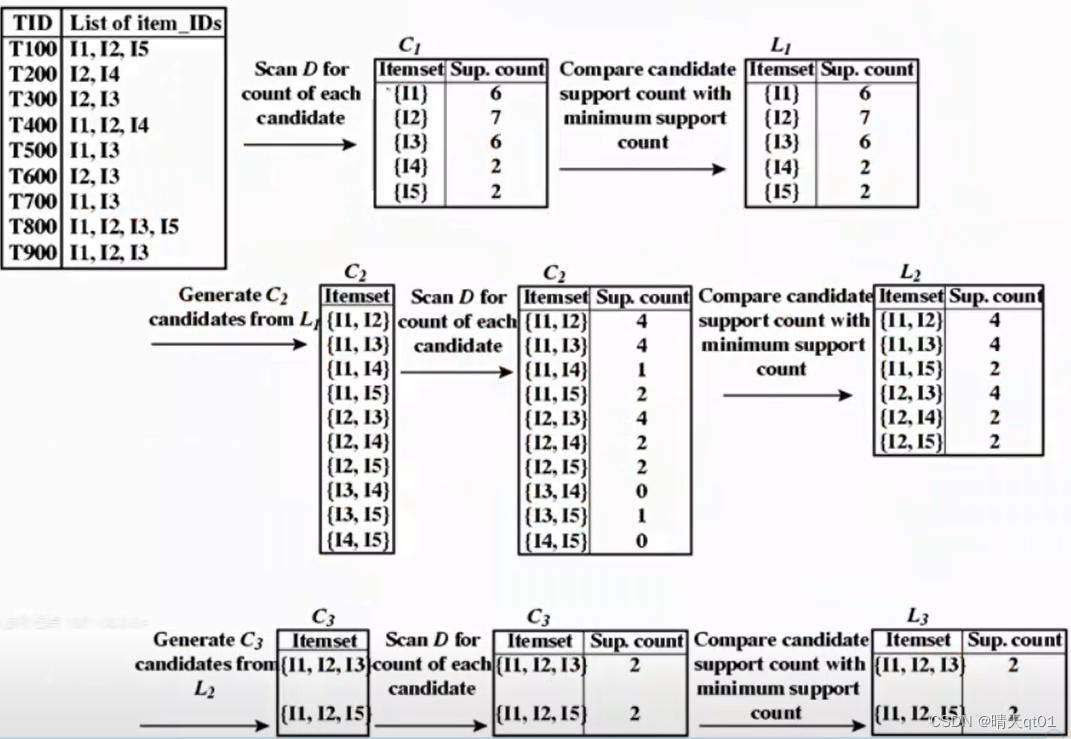
它也是一样,进行单独商品的计数,然后寻找两两对应的商品组合进行计数,在组长度为3的组合,我们要找头相同尾巴不同的组合,得到2个关联规则I1I2I3,I1I2I5候选人,进行计数,次数都大于二,所以这3个就可以被作为被频繁购买的项目集。
如果我们要组合出L4的话,那么我们也是一样的处理方法,
比如现在有4个长度为3的频繁项目(abc,abd,acd,ace,bcd)
那么我们就可以找到abcd和acde,因为没有cde,所以我们就只有一个长度为4的候选人abcd。
Apriori算法的实例的缺点及瓶颈
Apriori算法的瓶颈就是它的速度慢,它是用频繁被购买的候选集合,去产生频繁被购买的集合。用l2产生c3再产生l3
每次产生都得扫描数据库的内容才知道那些要保留,那些要删除。
也就是2步,产生候选人,在扫描数据库。
瓶颈1:候选人可能非常非常多。比如我们之前的案例,长度为1的样本就只有5个候选人就产生了10个。更不用说之后商品假如有1万个。就要产生1千万个长度为2的候选人。候选人集合很大,很占用记忆空间,
瓶颈2,如果你要产生长度为n的数据,那么就可能要扫描n+1次原始数据。比如我们选择c5经过扫描,没有通过就只能选择l4,所以程度为4的数据,那么就要扫描5次。如果原始数据有几万笔,那么不断的扫描会很浪费时间。
所以有浪费记忆体和浪费时间的缺点。于是有人就提出FPGrower的方法来解决这两项缺点。
小结:
我们今天讲了关联规则的概念,和它的两个指标,还有说明了一个算法Apriori的算法,它是为了解决暴力法的弊端所出现的,我们也发现Apriori的缺点,如何解决呢?于是就有FPgrowth的方法。
- mysql分区 ...
赞
踩

