
热门标签
热门文章
- 1反向传播算法(Backpropagation)----Gradient Descent的推导过程_gradient 反向传播
- 2docker安装ollama_docker 如何安装ollama容器
- 3python3.8搭建Keras +TensorFlow环境_python3.8安装tensorflow,keras的版本
- 4最长回文子序列_最长回文子序列 c++给定一个字符串s,找到其中最长的回文子序列,并返回该序列的长
- 5Java-常用API-2
- 6为什么Redis单线程却比多线程快_单线程为什么比多线程快
- 7Journal of Electronic Imaging(JEI)从投稿到录用过程分享
- 8使用Python进行自动化测试Selenium与PyTest的结合_使用 pytest-xdist 结合 selenium-grid 实现自动化用例分布式并发执行示例
- 9蓝桥杯集训·每日一题 AcWing 3729. 改变数组元素(差分)_acwing3729 题java解法
- 10Vue3 官方文档速通_vue3.0官方文档
当前位置: article > 正文
【AI】一文介绍索引增强生成RAG的原理和结构
作者:羊村懒王 | 2024-04-27 09:58:56
赞
踩
【AI】一文介绍索引增强生成RAG的原理和结构
今天向大家介绍一下关于RAG的一些知识和经验。
这里说的RAG可以理解为目前针对企业知识库问答等AI应用场景的解决方案,这个场景就是利用自然语言大模型LLM与用户自有的文件进行对话的能力。
【RAG的优势】
首先,讲一讲RAG的优势特征。
如果把AI想象成一个待上岗的人类助手,让这个助手成功帮你做事存在两种方法。
第一种,把你公司的所有业务都让他认真学习,效果是这些知识会真正进入这个助手的大脑,这些知识会被学得,反映到AI,就是FineTuning的过程中,供AI学习的素材会影响这个AI的内部参数。使得在训练成功后这个AI不需要查阅原本的文档就能够根据他目前的综合理解回答你的问题,因为这个AI已经学会了。
这种学习训练的应用方法的缺点也很明显,AI受到的影响是黑盒,用户无法完全把控,只能对结果事后审核。训练过程费时费力,需要高性能的硬件支撑训练过程,成本很高。后续如果有新的知识,那么这个高成本的训练过程也需要持续进行。
第二种方法,就是让助手本身具备正常沟通的能力,接下来需要什么材料,让助手找给你就行了。最多再根据他的CommonSense做一些整理。结论的来源也都会给你标出出处。这就是RAG的模式。LLM只是沟通媒介,AI并没有去真正学习后台向量库的知识,只是把这些知识找到并简单整理。
RAG在企业知识库场景下的优势很明显,无需经历痛苦繁琐的训练过程,后台的知识库可以随时增减,即时生效。结果更加忠于出处并可溯源。
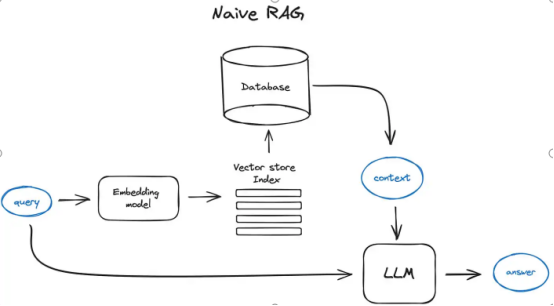
【RAG
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/羊村懒王/article/detail/496130
推荐阅读
相关标签

