
- 1HTTP2的多路复用_http2的多路复用特性是怎么
- 2【C++】CentOS环境搭建-编译安装Boost库(附CMAKE编译文件)
- 3YOLOV5 自动刷图脚本实战补充课之PyCharm安装PyQt5(Qt Designer、PyUIC)_pyqt pycharm yolov5
- 4淘宝爬虫评论数据采集_淘宝评论爬虫
- 5sse转neon_sse2neon
- 6Docker镜像仓库Harbor之搭建及配置_docker login harbor
- 7前端工程化-VSCode插件集成脚手架和组件库
- 8L学姐阿里测开 & 后端 一面面经_测开和后端
- 9推荐一本Vue开发的书籍_vue书籍
- 10Consul etcd zookeeper euerka比较
Linux 内核源代码情景分析 chap2 存储管理(二)_内核源代码情景分析 页保护
赞
踩
几个重要的数据结构和函数
1. 物理地址管理
1.1 pgd_t, pmd_t, pte_t
页面目录PGD, 中间目录PMD 和 页面表PT 分别是由 pgd_t, pmd_t, pte_t 构成的数组, 下面给出他们的定义:
==================== include/asm-i386/page.h 36 50 ====================
36 /*
37 * These are used to make use of C type-checking..
38 */
39 #if CONFIG_X86_PAE
40 typedef struct { unsigned long pte_low, pte_high; } pte_t;
41 typedef struct { unsigned long long pmd; } pmd_t;
42 typedef struct { unsigned long long pgd; } pgd_t;
43 #define pte_val(x) ((x).pte_low | ((unsigned long long)(x).pte_high << 32))
44 #else
45 typedef struct { unsigned long pte_low; } pte_t;
46 typedef struct { unsigned long pmd; } pmd_t;
47 typedef struct { unsigned long pgd; } pgd_t;
48 #define pte_val(x) ((x).pte_low)
49 #endif
50 #define PTE_MASK PAGE_MASK
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
根据定义, 我们知道pgd_t, pmd_t, pte_t 实际上就是长整数。
我们知道, 物理页面都是跟4K 字节的边界对齐的, 因而, 物理页面起始的高 20 bit 可以看成是物理页面的序号, 余下的 低 12 bit 可以用来表征页面的状态信息和访问权限, 就像 PGD 中所做的那样。然而, 内核中并没有在 pte_t 中定义有关的位段, 而是在page.h 中另行定义了一个用来说明页面保护的结构 pgprot_t
typedef struct { unsigned long pgprot; } pgprot_t;- 1
这个结构的值与i386 MMU 的页面表项的低12bit 相对应, 表征所映射页面的当前的状态和访问权限。
实际操作中,pgprot 数值小于 0x1000, 而pte 中数值大于 0x1000, 通过 __mk_pte 宏 可以得到实际用于页面表中的表项:
==================== include/asm-i386/pgtable-2level.h 61 61 ====================
61 #define __mk_pte(page_nr,pgprot) __pte(((page_nr) << PAGE_SHIFT) | pgprot_val(pgprot))
==================== include/asm-i386/page.h 56 58 ====================
56 #define pgprot_val(x) ((x).pgprot)
58 #define __pte(x) ((pte_t) { (x) } )- 1
- 2
- 3
- 4
- 5
- 6
1.2 mem_map
在内核中有一个全局的指针 mem_map, 他指向一个page 数据结构的数组。而每个page 结构代表了一个物理页面, 整个的这个 page 数组代表了系统中的全部的物理页面。
也就是说, 页面表项的高20 bit 对应了一个物理页面的编号, 通过这个编号, 我们可以在这个mem_map 所对应的page 数组中找到相应的 代表这个物理页面的 page 数据结构, 而通过在这个高 20 bit 数据后面添加 12 个 0 之后, 就可以得到物理页面的起始地址了。
1.3 pgprot 中的P标志位
在映射过程中, MMU 首先检查的是 P 标志位, (就是表项中最低位), 他标志着 所映射的物理页面是否在内存中。只有 P 为 1, 才完成映射, 否则会产生缺页异常。
1.4 pte_page, virt_to_page
内核中使用 pte_page 从页面表项获取物理页面结构地址,
用 virt_to_page 从虚拟地址找到相应物理页面的page 结构
==================== include/asm-i386/pgtable-2level.h 59 59 ====================
59 #define pte_page(x) (mem_map+((unsigned long)(((x).pte_low >> PAGE_SHIFT))))
==================== include/asm-i386/page.h 117 117 ====================
117 #define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))- 1
- 2
- 3
- 4
- 5
1.5 物理页面的page 结构(mem_map_t)
==================== include/linux/mm.h 126 148 ====================
126 /*
127 * Try to keep the most commonly accessed fields in single cache lines
128 * here (16 bytes or greater). This ordering should be particularly
129 * beneficial on 32-bit processors.
130 *
131 * The first line is data used in page cache lookup, the second line
132 * is used for linear searches (eg. clock algorithm scans).
133 */
134 typedef struct page {
135 struct list_head list;
136 struct address_space *mapping;
137 unsigned long index;
138 struct page *next_hash;
139 atomic_t count;
140 unsigned long flags; /* atomic flags, some possibly updated asynchronously */
141 struct list_head lru;
142 unsigned long age;
143 wait_queue_head_t wait;
144 struct page **pprev_hash;
145 struct buffer_head * buffers;
146 void *virtual; /* non-NULL if kmapped */
147 struct zone_struct *zone;
148 } mem_map_t;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
内核中通常使用 page 或者 map 来表示这个数据结构。
ps: 这个结构中的各个成分的次序是有讲究的, 目的是使得联系紧密的若干成分, 在执行被装入高速缓存的同一缓冲线中(16 字节)。
index 表明页面在文件中的序号, 或者去向。
上面提到了, mem_map 是内核中指向一个page结构的数组, 相当于一个物理页面的仓库。在系统初始化的时候, 被建立起来。 而这个仓库主要被划分为两个部分: ZONE_DMA 和 ZONE_NORMAL 。
1.6 ZONE_DMA
ZONE_DMA 管理区内的页面 主要是提供给 DMA 使用的。由于 DMA 交换不通过CPU 需要确保有一定的空间,以及有些外设的特殊要求, 或者 当DMA 所需要的缓冲区大小超过一个物理页面大小的时候, 要求这两个页面在物理上连续, (这是无法通过MMU 来保证的)。 基于这些原因, DMA 所用的物理地址需要单独划分一个区域。
1.7 管理区数据结构 zone_struct
==================== include/linux/mmzone.h 11 58 ====================
11 /*
12 * Free memory management - zoned buddy allocator.
13 */
14
15 #define MAX_ORDER 10
16
17 typedef struct free_area_struct {
18 struct list_head free_list;
19 unsigned int *map;
20 } free_area_t;
21
22 struct pglist_data;
23
24 typedef struct zone_struct {
25 /*
26 * Commonly accessed fields:
27 */
28 spinlock_t lock;
29 unsigned long offset;
30 unsigned long free_pages;
31 unsigned long inactive_clean_pages;
32 unsigned long inactive_dirty_pages;
33 unsigned long pages_min, pages_low, pages_high;
34
35 /*
36 * free areas of different sizes
37 */
38 struct list_head inactive_clean_list;
39 free_area_t free_area[MAX_ORDER];
40
41 /*
42 * rarely used fields:
43 */
44 char *name;
45 unsigned long size;
46 /*
47 * Discontig memory support fields.
48 */
49 struct pglist_data *zone_pgdat;
50 unsigned long zone_start_paddr;
51 unsigned long zone_start_mapnr;
52 struct page *zone_mem_map;
53 } zone_t;
54
55 #define ZONE_DMA 0
56 #define ZONE_NORMAL 1
57 #define ZONE_HIGHMEM 2
58 #define MAX_NR_ZONES 3- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
在这个管理区结构 zone_t 中 存在一组空闲区间队列 free_area_t, 这是因为, 我们常常需要按块来分配物理空间中的连续的页面。 于是有了 1, 2, 4, 8 , 16 。。。。等大小的块结构。
offset 表明分区在mem_map 中的起始页面编号。
1.8 NUMA
传统计算机结构中, 整个物理空间都是均匀一致的, cpu 访问这个空间中的任何一个地址所需要的时间都是相同的, 我们将它称为是 UMA (均质存储结构)。
然而, 这种情况是理想的,现实中一般都是 NUMA 结构。
为了支持 NUMA 结构, 管理区不在作为最高的机构,
他设置了多个存储节点, 对每个存储节点, 采用类似 UMA 时候的管理方式, ie, 在管理区结构 zone_struct 以及 page 结构数组的上方 多了一层代表着存储节点的 pglist_data 数据结构。
==================== include/linux/mmzone.h 79 90 ====================
79 typedef struct pglist_data {
80 zone_t node_zones[MAX_NR_ZONES];
81 zonelist_t node_zonelists[NR_GFPINDEX];
82 struct page *node_mem_map;
83 unsigned long *valid_addr_bitmap;
84 struct bootmem_data *bdata;
85 unsigned long node_start_paddr;
86 unsigned long node_start_mapnr;
87 unsigned long node_size;
88 int node_id;
89 struct pglist_data *node_next;
90 } pg_data_t;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
若干存储节点的pglist_data数据结构通过指针 node_next 形成了一个单链队列。
node_zones 表征节点的管理区, node_mem_map 表征指向 page 的结构数组。
相应的 zone_t 结构中也有一个指针 zone_pgdat 指向所属节点的pglist_data 结构。
==================== include/linux/mmzone.h 71 74 ====================
71 typedef struct zonelist_struct {
72 zone_t * zones [MAX_NR_ZONES+1]; // NULL delimited
73 int gfp_mask;
74 } zonelist_t;- 1
- 2
- 3
- 4
- 5
这个 zonelist_t 结构用 zones 数组 来表征不同页面的分配策略。
1.9 小结
物理空间的管理方面, 顶层的是 存储节点, 下方是管理区 和 page 数组。 我们可以这么去理解, 原先的UMA 结构在现在的模型中仅仅只是 NUMA 结构下方的一个存储节点而已。
我们拿到一个物理地址, 先得到他所在的存储节点位置 pglist_data, 继而 从这个结构中可以得到node_mem_map 就是我们所需要的 page 数组了, 通过 pte 表项的前 20 bit 可以定位得到这个 page 了。
2. 虚拟空间管理
2.1 虚拟空间的特殊性
虚拟空间管理和物理空间不同, 他没有一个总的物理页面的大仓库, 而是以进程为基础, 每个进程都有各自的虚拟存储空间(用户空间)。
物理空间管理, 我们主要是从 供 的角度管理, 而虚拟空间的管理, 更多的是从需求的角度来切入了。
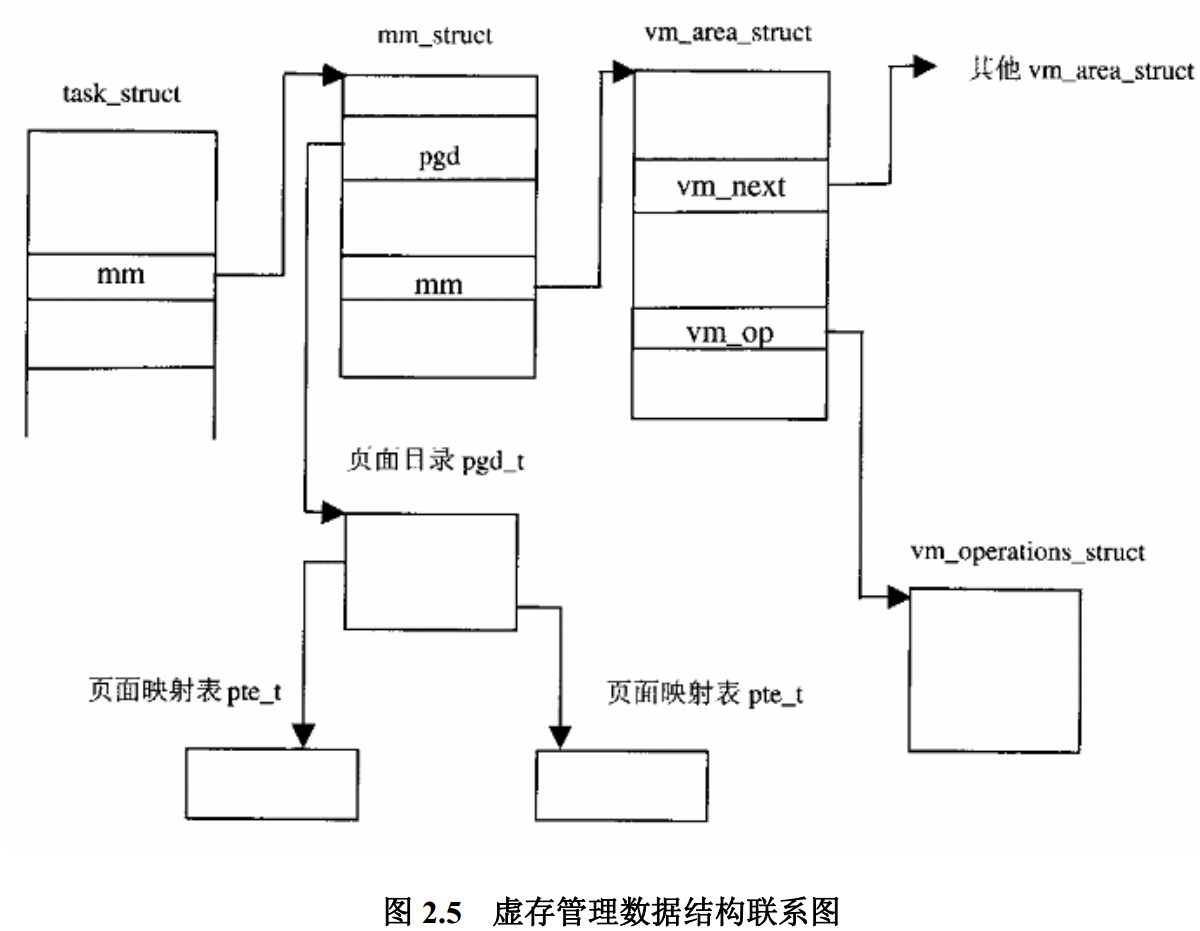
2.2 vm_area_struct
这是一个对虚存区间抽象的一个重要的数据结构, 每一个离散的虚存空间都有一个 vma 与之相对应:
==================== include/linux/mm.h 35 69 ====================
35 /*
36 * This struct defines a memory VMM memory area. There is one of these
37 * per VM-area/task. A VM area is any part of the process virtual memory
38 * space that has a special rule for the page-fault handlers (ie a shared
39 * library, the executable area etc).
40 */
41 struct vm_area_struct {
42 struct mm_struct * vm_mm; /* VM area parameters */
43 unsigned long vm_start;
44 unsigned long vm_end;
45
46 /* linked list of VM areas per task, sorted by address */
47 struct vm_area_struct *vm_next;
48
49 pgprot_t vm_page_prot;
50 unsigned long vm_flags;
51
52 /* AVL tree of VM areas per task, sorted by address */
53 short vm_avl_height;
54 struct vm_area_struct * vm_avl_left;
55 struct vm_area_struct * vm_avl_right;
56
57 /* For areas with an address space and backing store,
58 * one of the address_space->i_mmap{,shared} lists,
59 * for shm areas, the list of attaches, otherwise unused.
60 */
61 struct vm_area_struct *vm_next_share;
62 struct vm_area_struct **vm_pprev_share;
63
64 struct vm_operations_struct * vm_ops;
65 unsigned long vm_pgoff; /* offset in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */
66 struct file * vm_file;
67 unsigned long vm_raend;
68 void * vm_private_data; /* was vm_pte (shared mem) */
69 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
内核中这个结构的变量名通常都是 vma
vm_start 和 vm_end 标记了一个虚存空间, vm_page_prot 和 vm_flags 表征这个虚存空间的权限等信息, 一个区间内的所有页面都应该有相同的访问权限和保护属性。
利用 vm_next 指针将同一个进程空间内所有的虚存地址的高低次序连接在一起。由于, 通常涉及到给定一个虚拟地址, 需要找出他所在的区间的操作, 如果仅仅只是链表的话, 效率不高, 于是这里还引入了AVL 树。
vm_avl_height, vm_avl_left, vm_avl_right 的三个成分就是用于 AVL 树, 表示本区间在 AVL 树中的相应位置的。
使用 vm_next_share, vm_pprev_share, vm_file 表征虚存空间与磁盘文件之间的关联。
vm_ops 指向一个 vm_operation_struct 数据结构的指针
==================== include/linux/mm.h 115 124 ====================
115 /*
116 * These are the virtual MM functions - opening of an area, closing and
117 * unmapping it (needed to keep files on disk up-to-date etc), pointer
118 * to the functions called when a no-page or a wp-page exception occurs.
119 */
120 struct vm_operations_struct {
121 void (*open)(struct vm_area_struct * area);
122 void (*close)(struct vm_area_struct * area);
123 struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int write_access);
124 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这个结构由3个函数指针构成, 分别用于虚存空间的打开, 关闭 和 建立映射。
2.3 vm_mm
==================== include/linux/sched.h 203 227 ====================
203 struct mm_struct {
204 struct vm_area_struct * mmap; /* list of VMAs */
205 struct vm_area_struct * mmap_avl; /* tree of VMAs */
206 struct vm_area_struct * mmap_cache; /* last find_vma result */
207 pgd_t * pgd;
208 atomic_t mm_users; /* How many users with user space? */
209 atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
210 int map_count; /* number of VMAs */
211 struct semaphore mmap_sem;
212 spinlock_t page_table_lock;
213
214 struct list_head mmlist; /* List of all active mm's */
215
216 unsigned long start_code, end_code, start_data, end_data;
217 unsigned long start_brk, brk, start_stack;
218 unsigned long arg_start, arg_end, env_start, env_end;
219 unsigned long rss, total_vm, locked_vm;
220 unsigned long def_flags;
221 unsigned long cpu_vm_mask;
222 unsigned long swap_cnt; /* number of pages to swap on next pass */
223 unsigned long swap_address;
224
225 /* Architecture-specific MM context */
226 mm_context_t context;
227 };- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
这是一个比vm_area_t 更高层次上使用的数据结构。每个进程只有一个 mm_struct 结构。, 在每个进程的进程 控制块, task_struct 结构中, 有一个指针指向该进程的 mm_struct 结构。
一个进程只有一个 mm_struct, 但是 一个 mm_struct 可以被多个进程共享, ex. vfork(), clone()
2.4 小结
ps:
mm_struct 结构和他下属的各个 vm_area_struct 只是表明了他对虚存空间的需求, page , zone_struct 等结构则说明了对页面的供应, 而 PGD, PMD, PT 等则是他们两者之间的桥梁
![【Linux】服务器时区 [ CST | UTC | GMT | RTC ]_linux上服务器时区](https://img-blog.csdnimg.cn/img_convert/7ca7738362d74dc0867c0c0ec139a490.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png)


