
- 121.分布式文档系统_Elasticsearch上机动手实战演练bulk批量增删改_bulk operation has failures
- 2Git:生成ssh,并设置ssh链接_git 生成ssh
- 3快速应用开发_快速应用开发(rad)
- 4MP-SPDZ-V0.3.2(二)模拟三方秘密分享(SS)求和_mp—spdz
- 5NLP(六十三)使用Baichuan-7b模型微调人物关系分类任务_firefly-baichuan-7b
- 6gvim自动补全设置_在gvim中编辑verilog怎么设置begin end的对齐或者打always自动补全
- 7安装PCL点云库官方文档至本地计算机_点云库pcl1.11官方文档
- 8处理el-table大数据卡顿的问题,包含tree型数据格式_el-table 100条数据缩放页面后卡顿
- 9【AI视野·今日CV 计算机视觉论文速览 第253期】Mon, 25 Sep 2023_lmc: large model collaboration with cross-assessme
- 10python--字典版学生成绩管理系统_python字典-学生成绩统计
一篇文章教会你如何搭建hive数据库
赞
踩
目录
(3)安装MySQL的mysql common、mysql libs、mysql client、mysql server软件包
(4)修改 MySQL 数据库配置,在/etc/my.cnf 文件中添加以下数据(在symbolic-links=0 配置信息的下方添加数据)
(启动后查看mysql的状态(一定是要running))编辑(6)查看mysqld自动提供给的随机密码
(8)添加 root 用户从本地和远程访问 MySQL 数据库表单的授权。
(3)通过 vi 编辑器修改 hive-site.xml 文件实现 Hive 连接 MySQL 数据库,并设定 Hive 临时文件存储路径。
一、hive的概念和由来

(此图为Apache Hive官网的截图,具体网址为Apache Hive)
(1)Hive的概念
Hive是基于Hadoop的数据仓库工具,可以用来对HDFS中存储的数据进行查询和分析。Hive能够将HDFS上结构化的数据文件映射为数据库表,并提供SQL查询功能,将SQL语句转变成MapReduce任务来执行。Hive通过简单的SQL语句实现快速调用MapReduce机制进行数据统计分析,因此不必专门开发MapReduce应用程序即可实现大数据分析。
Hive对存储在HDFS中的数据进行分析和管理,它可以将结构化的数据文件映射为一张数据库表,通过SQL查询分析需要的内容,查询Hive使用的SQL语句简称Hive SQL(HQL)。Hive的运行机制使不熟悉MapReduce的用户也能很方便地利用SQL语言对数据进行查询、汇总、分析。同时,Hive也允许熟悉MapReduce开发者们开发自定义的Mappers和Reducers来处理内建的Mappers和Reducers无法完成的复杂的分析工作。Hive还允许用户编写自己定义的函数UDF,用来在查询中使用。
(2)Hive的由来
Hive起源于Facebook(一个美国的社交服务网络)。Facebook有着大量的数据,而Hadoop是一个开源的MapReduce实现,可以轻松处理大量的数据。但是MapReduce程序对于Java程序员来说比较容易写,但是对于其他语言使用者来说不太方便。此时Facebook最早地开始研发Hive,它让对Hadoop使用SQL查询(实际上SQL后台转化为了MapReduce)成为可能,那些非Java程序员也可以更方便地使用。hive最早的目的也就是为了分析处理海量的日志。
二、Hive的优缺点


(图中Hive的缺点明显是可控性差和因为使用语句的有限(只使用到SQL语句,逻辑简单,所以表达能力有限)
三、Hive的组件架构
(1)Hive与hadoop的关系
Hive构建在Hadoop之上,HQL中对查询语句的解释、优化、生成查询计划是由Hive完成的。Hive读取的所有数据都是存储在Hadoop文件系统中。Hive查询计划被转化为MapReduce任务,在Hadoop中执行。
(2)Hive与数据库的异同
由于Hive采用了SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。MapReduce开发人员可以把自己写的Mapper和Reducer作为插件支持Hive做更复杂的数据分析。它与关系型数据库的SQL略有不同,但支持了绝大多数的语句(如DDL、DML)以及常见的聚合函数、连接查询、条件查询等操作。
Hive不适合用于联机(online)事务处理,也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。Hive的特点是可伸缩(在Hadoop 的集群上动态的添加设备),可扩展、容错、输入格式的松散耦合。Hive的入口是DRIVER,执行的SQL语句首先提交到DRIVER驱动,然后调用COMPILER解释驱动,最终解释成MapReduce任务执行,最后将结果返回。
四、基础环境准备和安装准备
Hive组件需要基于Hadoop系统进行安装。因此,在安装Hive组件前,需要确保Hadoop系统能够正常运行。内容是基于之前已部署完毕的Hadoop全分布系统(HDFS),在master节点上实现Hive组件安装。
(1)Hive组件的部署规划和软件包路径如下:
(1)当前环境中已安装Hadoop全分布系统。
(2)本地安装MySQL数据库(账号root,密码Password123$),编写者软件包在/opt/software/mysql-5.7.18路径下。
(3)MySQL端口号(3306)。
(4)MySQL的JDBC驱动包/opt/software/mysql-connector-java-5.1.47.jar,
在此基础上更新Hive元数据存储。
(5)Hive软件包/opt/software/apache-hive-2.0.0-bin.tar.gz。
(缺一不可)
(2)解压安装文件
(1)使用root用户,将Hive安装包
/opt/software/apache-hive-2.0.0-bin.tar.gz路解压到/usr/local/src路径下。
[root@master ~]# tar -zxvf /opt/software/apache-hive-2.0.0-bin.tar.gz -C /usr/local/src
(2)将解压后的apache-hive-2.0.0-bin文件夹更名为hive;
[root@master ~]# mv /usr/local/src/apache-hive-2.0.0-bin usr/local/src/hive
(3)修改hive目录归属用户和用户组为hadoop
[root@master ~]# chown -R hadoop:hadoop /usr/local/src/hive
四、设置Hive环境
(1)关闭防火墙
(1)关闭 Linux 系统防火墙,并将防火墙设定为系统开机并不自动启动。
# 关闭防火墙服务
[root@master ~]# systemctl stop firewalld
# 设置防火墙服务开机不启动
[root@master ~]# systemctl disable firewalld
(2)卸载 Linux 系统自带的 MariaDB。
# 查询已安装的 mariadb 软件包
[root@ master ~]# rpm -qa | grep mariadb
#卸载已经查询到的mariadb软件包
[root@master ~]# rpm -e --nodeps mariadb-libs-5.5.56-2.el7.x86_64(这是写者自身查到的包)
(3)安装MySQL的mysql common、mysql libs、mysql client、mysql server软件包
[root@master ~]# cd /opt/software/tools-software/
[root@master ~]# rpm -ivh mysql-community-common-5.7.18-1.el7.x86_64.rpm
[root@master ~]# rpm -ivh mysql-community-libs-5.7.18-1.el7.x86_64.rpm
[root@master ~]# rpm -ivh mysql-community-client-5.7.18-1.el7.x86_64.rpm
[root@master ~]# rpm -ivh mysql-community-server-5.7.18-1.el7.x86_64.rpm
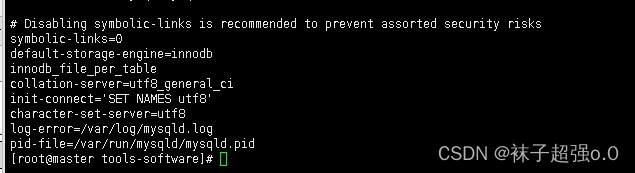
(4)修改 MySQL 数据库配置,在/etc/my.cnf 文件中添加以下数据(在symbolic-links=0 配置信息的下方添加数据)
default-storage-engine=innodb
innodb_file_per_table
collation-server=utf8_general_ci
init-connect='SET NAMES utf8'
character-set-server=utf8
(5)启动mysql数据库
[root@master ~]# systemctl start mysqld
(启动后查看mysql的状态(一定是要running)) (6)查看mysqld自动提供给的随机密码
(6)查看mysqld自动提供给的随机密码
[root@master ~]# cat /var/log/mysqld.log | grep password
(7)MySQL 数据库初始化。
(1)执行 mysql_secure_installation 命令初始化 MySQL 数据库,初始化过程中需要设定 数据库 root 用户登录密码,密码需符合安全规则,包括大小写字符、数字和特殊符号, 可设定密码为 Password123$。
在进行 MySQL 数据库初始化过程中会出现以下交互确认信息:
1)Change the password for root ? ((Press y|Y for Yes, any other key for No)表示是否更改 root 用户密码,在键盘输入 y 和回车。
2)Do you wish to continue with the password provided?(Press y|Y for Yes, any other key for No)表示是否使用设定的密码继续,在键盘输入 y 和回车。
3)Remove anonymous users? (Press y|Y for Yes, any other key for No)表示是 否删除匿名用户,在键盘输入 y 和回车。
4)Disallow root login remotely? (Press y|Y for Yes, any other key for No) 表示是否拒绝 root 用户远程登录,在键盘输入 n 和回车,表示允许 root 用户远程登录。
5)Remove test database and access to it? (Press y|Y for Yes, any other key for No)表示是否删除测试数据库,在键盘输入 y 和回车。
6)Reload privilege tables now? (Press y|Y for Yes, any other key for No) 表示是否重新加载授权表,在键盘输入 y 和回车。
(8)添加 root 用户从本地和远程访问 MySQL 数据库表单的授权。
[root@master ~]# mysql -uroot -p
Enter password: #输入自己设置好的密码,写者的密码为:Password123$
进入mysql界面后(mysql的界面为mysql>)
mysql> grant all privileges on *.* to root@'localhost' identified by 'Password123$'; # 添加 root 用户本地访问授权
mysql> grant all privileges on *.* to root@'%' identified by 'Password123$'; # 添加 root 用户远程访问授权
mysql> flush privileges; # 刷新授权
mysql> select user,host from mysql.user where user='root'; #查询root用户授权情况
五、配置Hive组件
(1)更改环境变量
# 在文件末尾追加以下配置内容
[root@master ~]# vi /etc/profile
# set hive environment
export HIVE_HOME=/usr/local/src/hive
export PATH=$PATH:$HIVE_HOME/bin

# 使环境变量配置生效
[root@master ~]# source /etc/profile
(2)修改 Hive 组件配置文件。
切换到 hadoop 用户执行以下对 Hive 组件的配置操作。 将/usr/local/src/hive/conf 文件夹下 hive-default.xml.template 文件,更名为 hive-site.xml。
[root@master ~]# su - hadoop
[hadoop@master ~]$ cp /usr/local/src/hive/conf/hive-default.xml.template /usr/local/src/hive/conf/hive-site.xml
(3)通过 vi 编辑器修改 hive-site.xml 文件实现 Hive 连接 MySQL 数据库,并设定 Hive 临时文件存储路径。
[hadoop@master ~]$ vi /usr/local/src/hive/conf/hive-site.xml
1)找出<name>javax.jdo.option.ConnectionURL</name>(此项为设置mysql数据库连接)
更改value值,改为<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&us eSSL=false</value>
2)找出<name>javax.jdo.option.ConnectionPassword</name>(此项为设置mysql数据库中root的密码)
更改value值,改为<value>Password123$</value>
3)找出<name>hive.metastore.schema.verification</name>(此项为验证元存储版本的一致性)
value值默认为false,如果有错,则更改为<value>false</value>
4)找出<name>javax.jdo.option.ConnectionDriverName</name>(配置数据库驱动)
更改value值,改为<value>com.mysql.jdbc.Driver</value>
5)找出<name>javax.jdo.option.ConnectionUserName</name>(配置数据库用户名 javax.jdo.option.ConnectionUserName 为 root)
更改value值,改为<value>root</value>
6)将<name>hive.querylog.location</name>
<name>hive.exec.local.scratchdir</name>
<name>hive.downloaded.resources.dir</name><name>hive.server2.logging.operation.log.location</name>这四个name的value值改为<value>/usr/local/src/hive/tmp</value>
7)在 Hive 安装目录中创建临时文件夹 tmp
[hadoop@master ~]$ mkdir /usr/local/src/hive/tmp
五、初始化元数据
1)将 MySQL 数据库驱动(/opt/software/mysql-connector-java-5.1.46.jar)拷贝到 Hive 安装目录的 lib 下;
[hadoop@master ~]$ cp /opt/software/mysql-connector-java-5.1.46.jar /usr/local/src/hive/lib/
2)重新启动 hadooop 即可
[hadoop@master lib]$ stop-all.sh
[hadoop@master lib]$ start-all.sh
3)初始化数据库
[hadoop@master ~]$schematool -initSchema -dbType mysql
4)启动 hive
[hadoop@master ~]$ hive




