
- 1error: RPC failed; curl 56 GnuTLS recv error (-110): The TLS connection was non-properly terminated.
- 2OpenAI Function calling_system prompt user prompt
- 3启明智显分享|国产RISC-V@480MHz“邮票孔”工业级HMI核心板,高品质低成本,仅34.9元!
- 4队列的顺序存储和链式存储_队列是一种先进先出的顺序存储结构,它指的是顺序存储结构吗
- 5自然语言处理中的语言模型与预训练技术的总结_xlnet全称
- 6物联网数据处理技术课程设计——基于python实现的智能图书馆借阅管理系统(OpenCV+MySQL)_图书管理系统python
- 7怎么用Markdown在github上写书,并用pages展示
- 8MBTI 热度爆火的需求分析
- 9Jenkins自动打包并部署到远程服务器_jenkins部署到远程服务器
- 10Apache SeaTunnel k8s 集群模式 Zeta 引擎部署指南
Pandas 2.2 中文官方教程和指南(二十·二)
赞
踩
通过组进行迭代
有了 GroupBy 对象,通过分组数据进行迭代非常自然,类似于itertools.groupby()的操作:
In [74]: grouped = df.groupby('A') In [75]: for name, group in grouped: ....: print(name) ....: print(group) ....: bar A B C D 1 bar one 0.254161 1.511763 3 bar three 0.215897 -0.990582 5 bar two -0.077118 1.211526 foo A B C D 0 foo one -0.575247 1.346061 2 foo two -1.143704 1.627081 4 foo two 1.193555 -0.441652 6 foo one -0.408530 0.268520 7 foo three -0.862495 0.024580

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
在按多个键分组的情况下,组名将是一个元组:
In [76]: for name, group in df.groupby(['A', 'B']): ....: print(name) ....: print(group) ....: ('bar', 'one') A B C D 1 bar one 0.254161 1.511763 ('bar', 'three') A B C D 3 bar three 0.215897 -0.990582 ('bar', 'two') A B C D 5 bar two -0.077118 1.211526 ('foo', 'one') A B C D 0 foo one -0.575247 1.346061 6 foo one -0.408530 0.268520 ('foo', 'three') A B C D 7 foo three -0.862495 0.02458 ('foo', 'two') A B C D 2 foo two -1.143704 1.627081 4 foo two 1.193555 -0.441652
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
参见通过组进行迭代。
选择一个组
可以使用DataFrameGroupBy.get_group()选择单个组:
In [77]: grouped.get_group("bar")
Out[77]:
A B C D
1 bar one 0.254161 1.511763
3 bar three 0.215897 -0.990582
5 bar two -0.077118 1.211526
- 1
- 2
- 3
- 4
- 5
- 6
或者对于在多列上分组的对象:
In [78]: df.groupby(["A", "B"]).get_group(("bar", "one"))
Out[78]:
A B C D
1 bar one 0.254161 1.511763
- 1
- 2
- 3
- 4
聚合
聚合是 GroupBy 操作,它减少了分组对象的维度。聚合的结果是每列在组中的一个标量值,或者至少被视为这样。例如,产生值组中每列的总和。
In [79]: animals = pd.DataFrame( ....: { ....: "kind": ["cat", "dog", "cat", "dog"], ....: "height": [9.1, 6.0, 9.5, 34.0], ....: "weight": [7.9, 7.5, 9.9, 198.0], ....: } ....: ) ....: In [80]: animals Out[80]: kind height weight 0 cat 9.1 7.9 1 dog 6.0 7.5 2 cat 9.5 9.9 3 dog 34.0 198.0 In [81]: animals.groupby("kind").sum() Out[81]: height weight kind cat 18.6 17.8 dog 40.0 205.5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
在结果中,默认情况下组的键出现在索引中。可以通过传递as_index=False来将其包含在列中。
In [82]: animals.groupby("kind", as_index=False).sum()
Out[82]:
kind height weight
0 cat 18.6 17.8
1 dog 40.0 205.5
- 1
- 2
- 3
- 4
- 5
内置聚合方法
许多常见的聚合操作内置在 GroupBy 对象中作为方法。在下面列出的方法中,带有*的方法没有高效的、GroupBy 特定的实现。
| 方法 | 描述 |
|---|---|
any() | 计算组中任何值是否为真 |
all() | 计算组中所有值是否为真 |
count() | 计算组中非 NA 值的数量 |
cov() * | 计算组的协方差 |
first() | 计算每个组中首次出现的值 |
idxmax() | 计算每个组中最大值的索引 |
idxmin() | 计算每个组中最小值的索引 |
last() | 计算每个组中最后出现的值 |
max() | 计算每个组中的最大值 |
mean() | 计算每个组的平均值 |
median() | 计算每个组的中位数 |
min() | 计算每个组中的最小值 |
nunique() | 计算每个组中唯一值的数量 |
prod() | 计算每个组中值的乘积 |
quantile() | 计算每个组中值的给定分位数 |
sem() | 计算每个组中值的平均标准误差 |
size() | 计算每个组中的值的数量 |
skew() * | 计算每个组中值的偏度 |
std() | 计算每个组中值的标准偏差 |
sum() | 计算每个组中值的总和 |
var() | 计算每个组中值的方差 |
一些示例:
In [83]: df.groupby("A")[["C", "D"]].max() Out[83]: C D A bar 0.254161 1.511763 foo 1.193555 1.627081 In [84]: df.groupby(["A", "B"]).mean() Out[84]: C D A B bar one 0.254161 1.511763 three 0.215897 -0.990582 two -0.077118 1.211526 foo one -0.491888 0.807291 three -0.862495 0.024580 two 0.024925 0.592714
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
另一个聚合示例是计算每个组的大小。这包含在 GroupBy 中作为size方法。它返回一个 Series,其索引由组名组成,值是每个组的大小。
In [85]: grouped = df.groupby(["A", "B"])
In [86]: grouped.size()
Out[86]:
A B
bar one 1
three 1
two 1
foo one 2
three 1
two 2
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
DataFrameGroupBy.describe() 方法本身不是一个减少器,但可以方便地生成关于每个组的摘要统计信息的集合。
In [87]: grouped.describe()
Out[87]:
C ... D
count mean std ... 50% 75% max
A B ...
bar one 1.0 0.254161 NaN ... 1.511763 1.511763 1.511763
three 1.0 0.215897 NaN ... -0.990582 -0.990582 -0.990582
two 1.0 -0.077118 NaN ... 1.211526 1.211526 1.211526
foo one 2.0 -0.491888 0.117887 ... 0.807291 1.076676 1.346061
three 1.0 -0.862495 NaN ... 0.024580 0.024580 0.024580
two 2.0 0.024925 1.652692 ... 0.592714 1.109898 1.627081
[6 rows x 16 columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
另一个聚合示例是计算每个组的唯一值的数量。这类似于DataFrameGroupBy.value_counts()函数,只是它只计算唯一值的数量。
In [88]: ll = [['foo', 1], ['foo', 2], ['foo', 2], ['bar', 1], ['bar', 1]] In [89]: df4 = pd.DataFrame(ll, columns=["A", "B"]) In [90]: df4 Out[90]: A B 0 foo 1 1 foo 2 2 foo 2 3 bar 1 4 bar 1 In [91]: df4.groupby("A")["B"].nunique() Out[91]: A bar 1 foo 2 Name: B, dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
注意
聚合函数不会在as_index=True(默认情况下)时将聚合的组作为命名列返回。分组的列将是返回对象的索引。
传递as_index=False 将返回聚合的组作为命名列,无论它们在输入中是命名的索引还是列。### aggregate() 方法
注意
aggregate() 方法可以接受许多不同类型的输入。本节详细介绍了使用字符串别名进行各种 GroupBy 方法的聚合;其他输入在下面的各节中详细说明。
pandas 实现的任何减少方法都可以作为字符串传递给aggregate()。鼓励用户使用简写agg。它将操作,就好像调用了相应的方法一样。
In [92]: grouped = df.groupby("A") In [93]: grouped[["C", "D"]].aggregate("sum") Out[93]: C D A bar 0.392940 1.732707 foo -1.796421 2.824590 In [94]: grouped = df.groupby(["A", "B"]) In [95]: grouped.agg("sum") Out[95]: C D A B bar one 0.254161 1.511763 three 0.215897 -0.990582 two -0.077118 1.211526 foo one -0.983776 1.614581 three -0.862495 0.024580 two 0.049851 1.185429
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
聚合的结果将具有组名作为新索引。在多个键的情况下,默认情况下结果是 MultiIndex。如上所述,可以通过使用as_index选项来更改这一点:
In [96]: grouped = df.groupby(["A", "B"], as_index=False) In [97]: grouped.agg("sum") Out[97]: A B C D 0 bar one 0.254161 1.511763 1 bar three 0.215897 -0.990582 2 bar two -0.077118 1.211526 3 foo one -0.983776 1.614581 4 foo three -0.862495 0.024580 5 foo two 0.049851 1.185429 In [98]: df.groupby("A", as_index=False)[["C", "D"]].agg("sum") Out[98]: A C D 0 bar 0.392940 1.732707 1 foo -1.796421 2.824590
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
请注意,您可以使用DataFrame.reset_index() DataFrame 函数来实现与列名存储在结果MultiIndex中相同的结果,尽管这将产生额外的副本。
In [99]: df.groupby(["A", "B"]).agg("sum").reset_index() Out[99]: A B C D 0 bar one 0.254161 1.511763 1 bar three 0.215897 -0.990582 2 bar two -0.077118 1.211526 3 foo one -0.983776 1.614581 4 foo three -0.862495 0.024580 5 foo two 0.049851 1.185429 ```### 使用用户定义函数进行聚合 用户还可以为自定义聚合提供自己的用户定义函数(UDFs)。 警告 在使用 UDF 进行聚合时,UDF 不应该改变提供的`Series`。有关更多信息,请参阅使用用户定义函数(UDF)方法进行变异。 注意 使用 UDF 进行聚合通常比在 GroupBy 上使用 pandas 内置方法性能较差。考虑将复杂操作拆分为一系列利用内置方法的操作链。 ```py In [100]: animals Out[100]: kind height weight 0 cat 9.1 7.9 1 dog 6.0 7.5 2 cat 9.5 9.9 3 dog 34.0 198.0 In [101]: animals.groupby("kind")[["height"]].agg(lambda x: set(x)) Out[101]: height kind cat {9.1, 9.5} dog {34.0, 6.0}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
结果 dtype 将反映聚合函数的 dtype。如果不同组的结果具有不同的 dtype,则将以与DataFrame构造相同的方式确定公共 dtype。
In [102]: animals.groupby("kind")[["height"]].agg(lambda x: x.astype(int).sum()) Out[102]: height kind cat 18 dog 40 ```### 一次应用多个函数 在分组的`Series`上,您可以将函数列表或字典传递给`SeriesGroupBy.agg()`,输出一个 DataFrame: ```py In [103]: grouped = df.groupby("A") In [104]: grouped["C"].agg(["sum", "mean", "std"]) Out[104]: sum mean std A bar 0.392940 0.130980 0.181231 foo -1.796421 -0.359284 0.912265
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
在分组的DataFrame上,您可以将函数列表传递给DataFrameGroupBy.agg(),以对每列进行聚合,从而产生具有分层列索引的聚合结果:
In [105]: grouped[["C", "D"]].agg(["sum", "mean", "std"])
Out[105]:
C D
sum mean std sum mean std
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果聚合以函数本身命名。如果需要重命名,则可以像这样为Series添加一个链接操作:
In [106]: (
.....: grouped["C"]
.....: .agg(["sum", "mean", "std"])
.....: .rename(columns={"sum": "foo", "mean": "bar", "std": "baz"})
.....: )
.....:
Out[106]:
foo bar baz
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对于分组的DataFrame,您可以以类似的方式重命名:
In [107]: (
.....: grouped[["C", "D"]].agg(["sum", "mean", "std"]).rename(
.....: columns={"sum": "foo", "mean": "bar", "std": "baz"}
.....: )
.....: )
.....:
Out[107]:
C D
foo bar baz foo bar baz
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意
通常情况下,输出列名应该是唯一的,但是 pandas 允许您将相同的函数(或两个具有相同名称的函数)应用于同一列。
In [108]: grouped["C"].agg(["sum", "sum"])
Out[108]:
sum sum
A
bar 0.392940 0.392940
foo -1.796421 -1.796421
- 1
- 2
- 3
- 4
- 5
- 6
pandas 还允许您提供多个 lambda。在这种情况下,pandas 将破坏(无名)lambda 函数的名称,对每个后续 lambda 添加_<i>。
In [109]: grouped["C"].agg([lambda x: x.max() - x.min(), lambda x: x.median() - x.mean()]) Out[109]: <lambda_0> <lambda_1> A bar 0.331279 0.084917 foo 2.337259 -0.215962 ```### 命名聚合 为了支持*控制输出列名的特定列聚合*,pandas 在`DataFrameGroupBy.agg()` 和`SeriesGroupBy.agg()` 中接受特殊语法,称为“命名聚合”,其中 + 关键字是*输出*列名 + 值是元组,其第一个元素是要选择的列,第二个元素是要应用于该列的聚合。pandas 提供了带有字段`['column', 'aggfunc']`的`NamedAgg` 命名元组,以使参数更清晰。通常,聚合可以是可调用的或字符串别名。 ```py In [110]: animals Out[110]: kind height weight 0 cat 9.1 7.9 1 dog 6.0 7.5 2 cat 9.5 9.9 3 dog 34.0 198.0 In [111]: animals.groupby("kind").agg( .....: min_height=pd.NamedAgg(column="height", aggfunc="min"), .....: max_height=pd.NamedAgg(column="height", aggfunc="max"), .....: average_weight=pd.NamedAgg(column="weight", aggfunc="mean"), .....: ) .....: Out[111]: min_height max_height average_weight kind cat 9.1 9.5 8.90 dog 6.0 34.0 102.75
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
NamedAgg 只是一个namedtuple。也允许使用普通元组。
In [112]: animals.groupby("kind").agg(
.....: min_height=("height", "min"),
.....: max_height=("height", "max"),
.....: average_weight=("weight", "mean"),
.....: )
.....:
Out[112]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果您想要的列名不是有效的 Python 关键字,请构建一个字典并解压关键字参数
In [113]: animals.groupby("kind").agg(
.....: **{
.....: "total weight": pd.NamedAgg(column="weight", aggfunc="sum")
.....: }
.....: )
.....:
Out[113]:
total weight
kind
cat 17.8
dog 205.5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在使用命名聚合时,额外的关键字参数不会传递给聚合函数;只有(column, aggfunc)对作为**kwargs传递。如果您的聚合函数需要额外的参数,可以使用functools.partial()部分应用它们。
命名聚合对于 Series 分组聚合也是有效的。在这种情况下,没有列选择,因此值只是函数。
In [114]: animals.groupby("kind").height.agg(
.....: min_height="min",
.....: max_height="max",
.....: )
.....:
Out[114]:
min_height max_height
kind
cat 9.1 9.5
dog 6.0 34.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对 DataFrame 列应用不同的函数
通过将字典传递给aggregate,您可以对 DataFrame 的列应用不同的聚合:
In [115]: grouped.agg({"C": "sum", "D": lambda x: np.std(x, ddof=1)})
Out[115]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
函数名称也可以是字符串。为了使字符串有效,必须在 GroupBy 上实现它:
In [116]: grouped.agg({"C": "sum", "D": "std"})
Out[116]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
内置聚合方法
许多常见的聚合在 GroupBy 对象中作为方法内置。在下面列出的方法中,带有*的方法 没有 高效的、GroupBy 特定的实现。
| 方法 | 描述 |
|---|---|
any() | 计算组中任何值是否为真 |
all() | 计算组中所有值是否为真 |
count() | 计算组中非 NA 值的数量 |
cov() * | 计算组的协方差 |
first() | 计算每个组中首次出现的值 |
idxmax() | 计算每个组中最大值的索引 |
idxmin() | 计算每个组中最小值的索引 |
last() | 计算每个组中最后出现的值 |
max() | 计算每个组中的最大值 |
mean() | 计算每个组的均值 |
median() | 计算每个组的中位数 |
min() | 计算每个组中的最小值 |
nunique() | 计算每个组中唯一值的数量 |
prod() | 计算每个组中值的乘积 |
quantile() | 计算每个组中值的给定分位数 |
sem() | 计算每个组中值的均值标准误差 |
size() | 计算每个组中值的数量 |
skew() * | 计算每个组中值的偏度 |
std() | 计算每个组中值的标准差 |
sum() | 计算每个组中值的总和 |
var() | 计算每个组中值的方差 |
一些示例:
In [83]: df.groupby("A")[["C", "D"]].max() Out[83]: C D A bar 0.254161 1.511763 foo 1.193555 1.627081 In [84]: df.groupby(["A", "B"]).mean() Out[84]: C D A B bar one 0.254161 1.511763 three 0.215897 -0.990582 two -0.077118 1.211526 foo one -0.491888 0.807291 three -0.862495 0.024580 two 0.024925 0.592714
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
另一个聚合示例是计算每个组的大小。这包含在 GroupBy 中作为size方法。它返回一个 Series,其索引由组名组成,值是每个组的大小。
In [85]: grouped = df.groupby(["A", "B"])
In [86]: grouped.size()
Out[86]:
A B
bar one 1
three 1
two 1
foo one 2
three 1
two 2
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
虽然DataFrameGroupBy.describe()方法本身不是一个缩减器,但它可以用于方便地生成关于每个组的摘要统计信息的集合。
In [87]: grouped.describe()
Out[87]:
C ... D
count mean std ... 50% 75% max
A B ...
bar one 1.0 0.254161 NaN ... 1.511763 1.511763 1.511763
three 1.0 0.215897 NaN ... -0.990582 -0.990582 -0.990582
two 1.0 -0.077118 NaN ... 1.211526 1.211526 1.211526
foo one 2.0 -0.491888 0.117887 ... 0.807291 1.076676 1.346061
three 1.0 -0.862495 NaN ... 0.024580 0.024580 0.024580
two 2.0 0.024925 1.652692 ... 0.592714 1.109898 1.627081
[6 rows x 16 columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
另一个聚合示例是计算每个组的唯一值的数量。这类似于DataFrameGroupBy.value_counts()函数,只是它只计算唯一值的数量。
In [88]: ll = [['foo', 1], ['foo', 2], ['foo', 2], ['bar', 1], ['bar', 1]] In [89]: df4 = pd.DataFrame(ll, columns=["A", "B"]) In [90]: df4 Out[90]: A B 0 foo 1 1 foo 2 2 foo 2 3 bar 1 4 bar 1 In [91]: df4.groupby("A")["B"].nunique() Out[91]: A bar 1 foo 2 Name: B, dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
注意
当as_index=True时,默认情况下,聚合函数不会将你正在聚合的组作为命名列返回。分组的列将是返回对象的索引。
传递as_index=False 将返回你正在聚合的组作为命名列,无论它们在输入中是命名的索引还是列。
aggregate() 方法
注意
aggregate()方法可以接受许多不同类型的输入。本节详细介绍了使用字符串别名进行各种 GroupBy 方法的详细信息;其他输入在下面的各节中详细说明。
任何 pandas 实现的缩减方法都可以作为字符串传递给aggregate()。鼓励用户使用简写agg。它将操作,就好像调用了相应的方法一样。
In [92]: grouped = df.groupby("A") In [93]: grouped[["C", "D"]].aggregate("sum") Out[93]: C D A bar 0.392940 1.732707 foo -1.796421 2.824590 In [94]: grouped = df.groupby(["A", "B"]) In [95]: grouped.agg("sum") Out[95]: C D A B bar one 0.254161 1.511763 three 0.215897 -0.990582 two -0.077118 1.211526 foo one -0.983776 1.614581 three -0.862495 0.024580 two 0.049851 1.185429
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
聚合的结果将以组名作为新索引。在多个键的情况下,默认情况下结果是 MultiIndex。如上所述,这可以通过使用as_index选项来更改:
In [96]: grouped = df.groupby(["A", "B"], as_index=False) In [97]: grouped.agg("sum") Out[97]: A B C D 0 bar one 0.254161 1.511763 1 bar three 0.215897 -0.990582 2 bar two -0.077118 1.211526 3 foo one -0.983776 1.614581 4 foo three -0.862495 0.024580 5 foo two 0.049851 1.185429 In [98]: df.groupby("A", as_index=False)[["C", "D"]].agg("sum") Out[98]: A C D 0 bar 0.392940 1.732707 1 foo -1.796421 2.824590
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
请注意,您可以使用DataFrame.reset_index() DataFrame 函数来实现与列名相同的结果,因为列名存储在生成的MultiIndex中,尽管这将产生额外的副本。
In [99]: df.groupby(["A", "B"]).agg("sum").reset_index()
Out[99]:
A B C D
0 bar one 0.254161 1.511763
1 bar three 0.215897 -0.990582
2 bar two -0.077118 1.211526
3 foo one -0.983776 1.614581
4 foo three -0.862495 0.024580
5 foo two 0.049851 1.185429
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
使用用户定义函数进行聚合
用户还可以为自定义聚合提供自己的用户定义函数(UDFs)。
警告
在使用 UDF 进行聚合时,UDF 不应更改提供的Series。有关更多信息,请参阅使用用户定义函数(UDF)方法进行变异。
注意
使用 UDF 进行聚合通常比在 GroupBy 上使用 pandas 内置方法性能更低。考虑将复杂操作分解为一系列利用内置方法的操作。
In [100]: animals
Out[100]:
kind height weight
0 cat 9.1 7.9
1 dog 6.0 7.5
2 cat 9.5 9.9
3 dog 34.0 198.0
In [101]: animals.groupby("kind")[["height"]].agg(lambda x: set(x))
Out[101]:
height
kind
cat {9.1, 9.5}
dog {34.0, 6.0}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
结果的 dtype 将反映聚合函数的 dtype。如果不同组的结果具有不同的 dtype,则将以与DataFrame构造相同的方式确定公共 dtype。
In [102]: animals.groupby("kind")[["height"]].agg(lambda x: x.astype(int).sum())
Out[102]:
height
kind
cat 18
dog 40
- 1
- 2
- 3
- 4
- 5
- 6
一次应用多个函数
在分组的Series上,您可以将函数列表或字典传递给SeriesGroupBy.agg(),输出一个 DataFrame:
In [103]: grouped = df.groupby("A")
In [104]: grouped["C"].agg(["sum", "mean", "std"])
Out[104]:
sum mean std
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
在分组的DataFrame上,您可以将函数列表传递给DataFrameGroupBy.agg()以聚合每列,这将产生一个具有分层列索引的聚合结果:
In [105]: grouped[["C", "D"]].agg(["sum", "mean", "std"])
Out[105]:
C D
sum mean std sum mean std
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果的聚合以函数本身命名。如果需要重命名,则可以为Series添加一个链接操作,如下所示:
In [106]: (
.....: grouped["C"]
.....: .agg(["sum", "mean", "std"])
.....: .rename(columns={"sum": "foo", "mean": "bar", "std": "baz"})
.....: )
.....:
Out[106]:
foo bar baz
A
bar 0.392940 0.130980 0.181231
foo -1.796421 -0.359284 0.912265
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对于分组的DataFrame,您可以以类似的方式重命名:
In [107]: (
.....: grouped[["C", "D"]].agg(["sum", "mean", "std"]).rename(
.....: columns={"sum": "foo", "mean": "bar", "std": "baz"}
.....: )
.....: )
.....:
Out[107]:
C D
foo bar baz foo bar baz
A
bar 0.392940 0.130980 0.181231 1.732707 0.577569 1.366330
foo -1.796421 -0.359284 0.912265 2.824590 0.564918 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意
一般来说,输出列名应该是唯一的,但 pandas 允许您将相同函数(或具有相同名称的两个函数)应用于同一列。
In [108]: grouped["C"].agg(["sum", "sum"])
Out[108]:
sum sum
A
bar 0.392940 0.392940
foo -1.796421 -1.796421
- 1
- 2
- 3
- 4
- 5
- 6
pandas 还允许您提供多个 lambda 函数。在这种情况下,pandas 将对(无名称)lambda 函数的名称进行修改,对每个后续 lambda 追加_<i>。
In [109]: grouped["C"].agg([lambda x: x.max() - x.min(), lambda x: x.median() - x.mean()])
Out[109]:
<lambda_0> <lambda_1>
A
bar 0.331279 0.084917
foo 2.337259 -0.215962
- 1
- 2
- 3
- 4
- 5
- 6
命名聚合
为了支持具有对输出列名称的控制的特定列聚合,pandas 接受在DataFrameGroupBy.agg()和SeriesGroupBy.agg()中的特殊语法,称为“命名聚合”,其中
-
关键字是输出列名
-
这些值是元组,第一个元素是要选择的列,第二个元素是要应用于该列的聚合。pandas 提供了
NamedAgg命名元组,字段为['column', 'aggfunc'],以便更清晰地了解参数是什么。通常,聚合可以是可调用的函数或字符串别名。
In [110]: animals Out[110]: kind height weight 0 cat 9.1 7.9 1 dog 6.0 7.5 2 cat 9.5 9.9 3 dog 34.0 198.0 In [111]: animals.groupby("kind").agg( .....: min_height=pd.NamedAgg(column="height", aggfunc="min"), .....: max_height=pd.NamedAgg(column="height", aggfunc="max"), .....: average_weight=pd.NamedAgg(column="weight", aggfunc="mean"), .....: ) .....: Out[111]: min_height max_height average_weight kind cat 9.1 9.5 8.90 dog 6.0 34.0 102.75
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
NamedAgg只是一个namedtuple。也允许使用普通元组。
In [112]: animals.groupby("kind").agg(
.....: min_height=("height", "min"),
.....: max_height=("height", "max"),
.....: average_weight=("weight", "mean"),
.....: )
.....:
Out[112]:
min_height max_height average_weight
kind
cat 9.1 9.5 8.90
dog 6.0 34.0 102.75
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
如果您想要的列名不是有效的 Python 关键字,请构造一个字典并展开关键字参数
In [113]: animals.groupby("kind").agg(
.....: **{
.....: "total weight": pd.NamedAgg(column="weight", aggfunc="sum")
.....: }
.....: )
.....:
Out[113]:
total weight
kind
cat 17.8
dog 205.5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在使用命名聚合时,额外的关键字参数不会传递给聚合函数;只有 (column, aggfunc) 对应的键值对应该作为 **kwargs 传递。如果您的聚合函数需要额外的参数,可以使用 functools.partial() 部分应用它们。
命名聚合对于 Series groupby 聚合也是有效的。在这种情况下,没有列选择,因此值只是函数。
In [114]: animals.groupby("kind").height.agg(
.....: min_height="min",
.....: max_height="max",
.....: )
.....:
Out[114]:
min_height max_height
kind
cat 9.1 9.5
dog 6.0 34.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
对 DataFrame 列应用不同函数
通过将字典传递给 aggregate,您可以对 DataFrame 的列应用��同的聚合:
In [115]: grouped.agg({"C": "sum", "D": lambda x: np.std(x, ddof=1)})
Out[115]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
函数名称也可以是字符串。为了使字符串有效,必须在 GroupBy 上实现它:
In [116]: grouped.agg({"C": "sum", "D": "std"})
Out[116]:
C D
A
bar 0.392940 1.366330
foo -1.796421 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
转换
转换是一个 GroupBy 操作,其结果与被分组的结果索引相同。常见示例包括 cumsum() 和 diff()。
In [117]: speeds Out[117]: class order max_speed falcon bird Falconiformes 389.0 parrot bird Psittaciformes 24.0 lion mammal Carnivora 80.2 monkey mammal Primates NaN leopard mammal Carnivora 58.0 In [118]: grouped = speeds.groupby("class")["max_speed"] In [119]: grouped.cumsum() Out[119]: falcon 389.0 parrot 413.0 lion 80.2 monkey NaN leopard 138.2 Name: max_speed, dtype: float64 In [120]: grouped.diff() Out[120]: falcon NaN parrot -365.0 lion NaN monkey NaN leopard NaN Name: max_speed, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
与聚合不同,用于拆分原始对象的分组不包含在结果中。
注意
由于转换不包括用于拆分结果的分组,因此在 DataFrame.groupby() 和 Series.groupby() 中的参数 as_index 和 sort 没有效果。
转换的常见用途是将结果添加回原始 DataFrame 中。
In [121]: result = speeds.copy()
In [122]: result["cumsum"] = grouped.cumsum()
In [123]: result["diff"] = grouped.diff()
In [124]: result
Out[124]:
class order max_speed cumsum diff
falcon bird Falconiformes 389.0 389.0 NaN
parrot bird Psittaciformes 24.0 413.0 -365.0
lion mammal Carnivora 80.2 80.2 NaN
monkey mammal Primates NaN NaN NaN
leopard mammal Carnivora 58.0 138.2 NaN
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
内置的转换方法
GroupBy 上的以下方法作为转换操作。
| 方法 | 描述 |
|---|---|
bfill() | 在每个组内填充 NA 值 |
cumcount() | 计算每个组内的累积计数 |
cummax() | 计算每个组内的累积最大值 |
cummin() | 计算每个组内的累积最小值 |
cumprod() | 计算每个组内的累积乘积 |
cumsum() | 计算每个组内的累积和 |
diff() | 计算每个组内相邻值之间的差异 |
ffill() | 在每个组内填充 NA 值 |
pct_change() | 计算每个组内相邻值之间的百分比变化 |
rank() | 计算每个组内每个值的排名 |
shift() | 在每个组内上下移动值 |
此外,将任何内置聚合方法作为字符串传递给transform()(请参阅下一节)将在组内广播结果,生成转换后的结果。如果聚合方法有高效的实现,这也将具有高性能。
transform() 方法
类似于聚合方法,transform() 方法可以接受字符串别名,指向前一节中内置的转换方法。它还可以接受��符串别名,指向内置的聚合方法。当提供聚合方法时,结果将在组内广播。
In [125]: speeds Out[125]: class order max_speed falcon bird Falconiformes 389.0 parrot bird Psittaciformes 24.0 lion mammal Carnivora 80.2 monkey mammal Primates NaN leopard mammal Carnivora 58.0 In [126]: grouped = speeds.groupby("class")[["max_speed"]] In [127]: grouped.transform("cumsum") Out[127]: max_speed falcon 389.0 parrot 413.0 lion 80.2 monkey NaN leopard 138.2 In [128]: grouped.transform("sum") Out[128]: max_speed falcon 413.0 parrot 413.0 lion 138.2 monkey 138.2 leopard 138.2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
除了字符串别名外,transform() 方法还可以接受用户定义的函数(UDFs)。UDF 必须:
-
返回的结果要么与组块的大小相同,要么可以广播到组块的大小(例如,标量,
grouped.transform(lambda x: x.iloc[-1]))。 -
在组块上逐列操作。使用 chunk.apply 将转换应用于第一个组块。
-
不要在组块上执行就地操作。组块应被视为不可变的,对组块的更改可能会产生意外结果。有关更多信息,请参见使用用户定义函数(UDF)方法进行变异。
-
(可选)一次性操作整个组块的所有列。如果支持此操作,将从第二块开始使用快速路径。
注意
通过提供 UDF 给transform进行转换通常比在 GroupBy 上使用内置方法性能更低。考虑将复杂操作分解为一系列利用内置方法的操作。
本节中的所有示例都可以通过调用内置方法而不是使用 UDFs 来提高性能。请参见下面的示例。
从版本 2.0.0 开始更改:当在分组的 DataFrame 上使用.transform并且转换函数返回一个 DataFrame 时,pandas 现在会将结果的索引与输入的索引对齐。您可以在转换函数内部调用.to_numpy()以避免对齐。
与聚合方法类似,结果的 dtype 将反映转换函数的 dtype。如果不同组的结果具有不同的 dtype,则将以与DataFrame构造相同的方式确定公共 dtype。
假设我们希望在每个组内标准化数据:
In [129]: index = pd.date_range("10/1/1999", periods=1100) In [130]: ts = pd.Series(np.random.normal(0.5, 2, 1100), index) In [131]: ts = ts.rolling(window=100, min_periods=100).mean().dropna() In [132]: ts.head() Out[132]: 2000-01-08 0.779333 2000-01-09 0.778852 2000-01-10 0.786476 2000-01-11 0.782797 2000-01-12 0.798110 Freq: D, dtype: float64 In [133]: ts.tail() Out[133]: 2002-09-30 0.660294 2002-10-01 0.631095 2002-10-02 0.673601 2002-10-03 0.709213 2002-10-04 0.719369 Freq: D, dtype: float64 In [134]: transformed = ts.groupby(lambda x: x.year).transform( .....: lambda x: (x - x.mean()) / x.std() .....: ) .....:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
我们期望结果现在在每个组内具有均值 0 和标准差 1(直到浮点误差),我们可以轻松检查:
# Original Data In [135]: grouped = ts.groupby(lambda x: x.year) In [136]: grouped.mean() Out[136]: 2000 0.442441 2001 0.526246 2002 0.459365 dtype: float64 In [137]: grouped.std() Out[137]: 2000 0.131752 2001 0.210945 2002 0.128753 dtype: float64 # Transformed Data In [138]: grouped_trans = transformed.groupby(lambda x: x.year) In [139]: grouped_trans.mean() Out[139]: 2000 -4.870756e-16 2001 -1.545187e-16 2002 4.136282e-16 dtype: float64 In [140]: grouped_trans.std() Out[140]: 2000 1.0 2001 1.0 2002 1.0 dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
我们还可以直观地比较原始数据集和转换后的数据集。
In [141]: compare = pd.DataFrame({"Original": ts, "Transformed": transformed})
In [142]: compare.plot()
Out[142]: <Axes: >
- 1
- 2
- 3
- 4
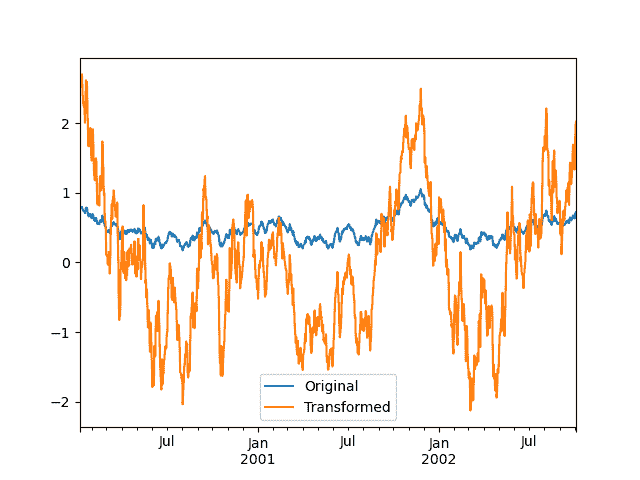
具有较低维度输出的转换函数将被广播以匹配输入数组的形状。
In [143]: ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min())
Out[143]:
2000-01-08 0.623893
2000-01-09 0.623893
2000-01-10 0.623893
2000-01-11 0.623893
2000-01-12 0.623893
...
2002-09-30 0.558275
2002-10-01 0.558275
2002-10-02 0.558275
2002-10-03 0.558275
2002-10-04 0.558275
Freq: D, Length: 1001, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
另一个常见的数据转换是用组均值替换缺失数据。
In [144]: cols = ["A", "B", "C"] In [145]: values = np.random.randn(1000, 3) In [146]: values[np.random.randint(0, 1000, 100), 0] = np.nan In [147]: values[np.random.randint(0, 1000, 50), 1] = np.nan In [148]: values[np.random.randint(0, 1000, 200), 2] = np.nan In [149]: data_df = pd.DataFrame(values, columns=cols) In [150]: data_df Out[150]: A B C 0 1.539708 -1.166480 0.533026 1 1.302092 -0.505754 NaN 2 -0.371983 1.104803 -0.651520 3 -1.309622 1.118697 -1.161657 4 -1.924296 0.396437 0.812436 .. ... ... ... 995 -0.093110 0.683847 -0.774753 996 -0.185043 1.438572 NaN 997 -0.394469 -0.642343 0.011374 998 -1.174126 1.857148 NaN 999 0.234564 0.517098 0.393534 [1000 rows x 3 columns] In [151]: countries = np.array(["US", "UK", "GR", "JP"]) In [152]: key = countries[np.random.randint(0, 4, 1000)] In [153]: grouped = data_df.groupby(key) # Non-NA count in each group In [154]: grouped.count() Out[154]: A B C GR 209 217 189 JP 240 255 217 UK 216 231 193 US 239 250 217 In [155]: transformed = grouped.transform(lambda x: x.fillna(x.mean()))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
我们可以验证转换后数据中组均值未发生变化,并且转换后数据不包含 NA 值。
In [156]: grouped_trans = transformed.groupby(key) In [157]: grouped.mean() # original group means Out[157]: A B C GR -0.098371 -0.015420 0.068053 JP 0.069025 0.023100 -0.077324 UK 0.034069 -0.052580 -0.116525 US 0.058664 -0.020399 0.028603 In [158]: grouped_trans.mean() # transformation did not change group means Out[158]: A B C GR -0.098371 -0.015420 0.068053 JP 0.069025 0.023100 -0.077324 UK 0.034069 -0.052580 -0.116525 US 0.058664 -0.020399 0.028603 In [159]: grouped.count() # original has some missing data points Out[159]: A B C GR 209 217 189 JP 240 255 217 UK 216 231 193 US 239 250 217 In [160]: grouped_trans.count() # counts after transformation Out[160]: A B C GR 228 228 228 JP 267 267 267 UK 247 247 247 US 258 258 258 In [161]: grouped_trans.size() # Verify non-NA count equals group size Out[161]: GR 228 JP 267 UK 247 US 258 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
如上面的注释中所述,本节中的每个示例都可以使用内置方法更有效地计算。在下面的代码中,使用 UDF 的低效方法被注释掉,更快的替代方法出现在下面。
# result = ts.groupby(lambda x: x.year).transform( # lambda x: (x - x.mean()) / x.std() # ) In [162]: grouped = ts.groupby(lambda x: x.year) In [163]: result = (ts - grouped.transform("mean")) / grouped.transform("std") # result = ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min()) In [164]: grouped = ts.groupby(lambda x: x.year) In [165]: result = grouped.transform("max") - grouped.transform("min") # grouped = data_df.groupby(key) # result = grouped.transform(lambda x: x.fillna(x.mean())) In [166]: grouped = data_df.groupby(key) In [167]: result = data_df.fillna(grouped.transform("mean")) ```### 窗口和重新采样操作 可以将`resample()`、`expanding()`和`rolling()`作为 groupby 的方法使用。 下面的示例将在列 B 的样本上应用`rolling()`方法,基于列 A 的分组。 ```py In [168]: df_re = pd.DataFrame({"A": [1] * 10 + [5] * 10, "B": np.arange(20)}) In [169]: df_re Out[169]: A B 0 1 0 1 1 1 2 1 2 3 1 3 4 1 4 .. .. .. 15 5 15 16 5 16 17 5 17 18 5 18 19 5 19 [20 rows x 2 columns] In [170]: df_re.groupby("A").rolling(4).B.mean() Out[170]: A 1 0 NaN 1 NaN 2 NaN 3 1.5 4 2.5 ... 5 15 13.5 16 14.5 17 15.5 18 16.5 19 17.5 Name: B, Length: 20, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
expanding()方法将为每个特定组的所有成员累积给定操作(示例中为sum())。
In [171]: df_re.groupby("A").expanding().sum() Out[171]: B A 1 0 0.0 1 1.0 2 3.0 3 6.0 4 10.0 ... ... 5 15 75.0 16 91.0 17 108.0 18 126.0 19 145.0 [20 rows x 1 columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
假设你想要使用resample()方法在数据框的每个组中获得每日频率,并希望使用ffill()方法完成缺失值。
In [172]: df_re = pd.DataFrame( .....: { .....: "date": pd.date_range(start="2016-01-01", periods=4, freq="W"), .....: "group": [1, 1, 2, 2], .....: "val": [5, 6, 7, 8], .....: } .....: ).set_index("date") .....: In [173]: df_re Out[173]: group val date 2016-01-03 1 5 2016-01-10 1 6 2016-01-17 2 7 2016-01-24 2 8 In [174]: df_re.groupby("group").resample("1D", include_groups=False).ffill() Out[174]: val group date 1 2016-01-03 5 2016-01-04 5 2016-01-05 5 2016-01-06 5 2016-01-07 5 ... ... 2 2016-01-20 7 2016-01-21 7 2016-01-22 7 2016-01-23 7 2016-01-24 8 [16 rows x 1 columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
内置转换方法
下面的 GroupBy 方法作为转换操作。
| 方法 | 描述 |
|---|---|
bfill() | 在每个组内部填充 NA 值 |
cumcount() | 计算每个组内的累计计数 |
cummax() | 计算每个组内的累积最大值 |
cummin() | 计算每个组内的累积最小值 |
cumprod() | 计算每个组内的累积乘积 |
cumsum() | 计算每个组内的累积和 |
diff() | 计算每个组内相邻值之间的差异 |
ffill() | 在每个组内前向填充 NA 值 |
pct_change() | 计算每个组内相邻值之间的百分比变化 |
rank() | 计算每个组内每个值的排名 |
shift() | 在每个组内上下移动值 |
此外,将任何内置聚合方法作为字符串传递给transform()(请参见下一节)将在组中广播结果,产生一个转换后的结果。如果聚合方法有高效的实现,这也将是高性能的。
transform() 方法
与聚合方法类似,transform() 方法可以接受前一节中内置转换方法的字符串别名。它还可以接受内置聚合方法的字符串别名。当提供聚合方法时,结果将在组中广播。
In [125]: speeds Out[125]: class order max_speed falcon bird Falconiformes 389.0 parrot bird Psittaciformes 24.0 lion mammal Carnivora 80.2 monkey mammal Primates NaN leopard mammal Carnivora 58.0 In [126]: grouped = speeds.groupby("class")[["max_speed"]] In [127]: grouped.transform("cumsum") Out[127]: max_speed falcon 389.0 parrot 413.0 lion 80.2 monkey NaN leopard 138.2 In [128]: grouped.transform("sum") Out[128]: max_speed falcon 413.0 parrot 413.0 lion 138.2 monkey 138.2 leopard 138.2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
除了字符串别名外,transform() 方法还可以接受用户定义函数(UDFs)。UDF 必须:
-
返回一个与组块大小相同或可广播到组块大小的结果(例如,一个标量,
grouped.transform(lambda x: x.iloc[-1]))。 -
逐列在组块上操作。使用 chunk.apply 将转换应用于第一个组块。
-
不要对组块进行原地操作。组块应被视为不可变的,对组块的更改可能会产生意想不到的结果。有关更多信息,请参阅使用用户定义函数(UDF)方法进行变异。
-
(可选)一次操作整个组块的所有列。如果支持此操作,将从第二块开始使用快速路径。
注意
通过向transform提供 UDF 进行转换通常不如在 GroupBy 上使用内置方法高效。考虑将复杂操作分解为一系列利用内置方法的操作链。
本节中的所有示例都可以通过调用内置方法而不是使用 UDFs 来提高性能。请参见下面的示例。
从版本 2.0.0 开始更改:当在分组的 DataFrame 上使用.transform并且转换函数返回一个 DataFrame 时,pandas 现在会将结果的索引与输入的索引对齐。您可以在转换函数中调用.to_numpy()以避免对齐。
与聚合方法类似,结果的数据类型将反映转换函数的数据类型。如果不同组的结果具有不同的数据类型,则将以与 DataFrame 构造相同的方式确定公共数据类型。
假设我们希望在每个组内标准化数据:
In [129]: index = pd.date_range("10/1/1999", periods=1100) In [130]: ts = pd.Series(np.random.normal(0.5, 2, 1100), index) In [131]: ts = ts.rolling(window=100, min_periods=100).mean().dropna() In [132]: ts.head() Out[132]: 2000-01-08 0.779333 2000-01-09 0.778852 2000-01-10 0.786476 2000-01-11 0.782797 2000-01-12 0.798110 Freq: D, dtype: float64 In [133]: ts.tail() Out[133]: 2002-09-30 0.660294 2002-10-01 0.631095 2002-10-02 0.673601 2002-10-03 0.709213 2002-10-04 0.719369 Freq: D, dtype: float64 In [134]: transformed = ts.groupby(lambda x: x.year).transform( .....: lambda x: (x - x.mean()) / x.std() .....: ) .....:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
我们期望结果现在在每个组内具有均值为 0 和标准差为 1(直到浮点误差为止),我们可以轻松检查:
# Original Data In [135]: grouped = ts.groupby(lambda x: x.year) In [136]: grouped.mean() Out[136]: 2000 0.442441 2001 0.526246 2002 0.459365 dtype: float64 In [137]: grouped.std() Out[137]: 2000 0.131752 2001 0.210945 2002 0.128753 dtype: float64 # Transformed Data In [138]: grouped_trans = transformed.groupby(lambda x: x.year) In [139]: grouped_trans.mean() Out[139]: 2000 -4.870756e-16 2001 -1.545187e-16 2002 4.136282e-16 dtype: float64 In [140]: grouped_trans.std() Out[140]: 2000 1.0 2001 1.0 2002 1.0 dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
我们还可以直观地比较原始数据集和转换后的数据集。
In [141]: compare = pd.DataFrame({"Original": ts, "Transformed": transformed})
In [142]: compare.plot()
Out[142]: <Axes: >
- 1
- 2
- 3
- 4
具有较低维度输出的转换函数将被广播以匹配输入数组的形状。
In [143]: ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min())
Out[143]:
2000-01-08 0.623893
2000-01-09 0.623893
2000-01-10 0.623893
2000-01-11 0.623893
2000-01-12 0.623893
...
2002-09-30 0.558275
2002-10-01 0.558275
2002-10-02 0.558275
2002-10-03 0.558275
2002-10-04 0.558275
Freq: D, Length: 1001, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
另一个常见的数据转换是用组平均值替换缺失数据。
In [144]: cols = ["A", "B", "C"] In [145]: values = np.random.randn(1000, 3) In [146]: values[np.random.randint(0, 1000, 100), 0] = np.nan In [147]: values[np.random.randint(0, 1000, 50), 1] = np.nan In [148]: values[np.random.randint(0, 1000, 200), 2] = np.nan In [149]: data_df = pd.DataFrame(values, columns=cols) In [150]: data_df Out[150]: A B C 0 1.539708 -1.166480 0.533026 1 1.302092 -0.505754 NaN 2 -0.371983 1.104803 -0.651520 3 -1.309622 1.118697 -1.161657 4 -1.924296 0.396437 0.812436 .. ... ... ... 995 -0.093110 0.683847 -0.774753 996 -0.185043 1.438572 NaN 997 -0.394469 -0.642343 0.011374 998 -1.174126 1.857148 NaN 999 0.234564 0.517098 0.393534 [1000 rows x 3 columns] In [151]: countries = np.array(["US", "UK", "GR", "JP"]) In [152]: key = countries[np.random.randint(0, 4, 1000)] In [153]: grouped = data_df.groupby(key) # Non-NA count in each group In [154]: grouped.count() Out[154]: A B C GR 209 217 189 JP 240 255 217 UK 216 231 193 US 239 250 217 In [155]: transformed = grouped.transform(lambda x: x.fillna(x.mean()))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
我们可以验证转换后的数据中组平均值未发生变化,并且转换后的数据不包含任何 NAs。
In [156]: grouped_trans = transformed.groupby(key) In [157]: grouped.mean() # original group means Out[157]: A B C GR -0.098371 -0.015420 0.068053 JP 0.069025 0.023100 -0.077324 UK 0.034069 -0.052580 -0.116525 US 0.058664 -0.020399 0.028603 In [158]: grouped_trans.mean() # transformation did not change group means Out[158]: A B C GR -0.098371 -0.015420 0.068053 JP 0.069025 0.023100 -0.077324 UK 0.034069 -0.052580 -0.116525 US 0.058664 -0.020399 0.028603 In [159]: grouped.count() # original has some missing data points Out[159]: A B C GR 209 217 189 JP 240 255 217 UK 216 231 193 US 239 250 217 In [160]: grouped_trans.count() # counts after transformation Out[160]: A B C GR 228 228 228 JP 267 267 267 UK 247 247 247 US 258 258 258 In [161]: grouped_trans.size() # Verify non-NA count equals group size Out[161]: GR 228 JP 267 UK 247 US 258 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
如上面的注释中所提到的,本节中的每个示例都可以使用内置方法更有效地计算。在下面的代码中,使用 UDF 的低效方法被注释掉,更快的替代方法出现在下面。
# result = ts.groupby(lambda x: x.year).transform( # lambda x: (x - x.mean()) / x.std() # ) In [162]: grouped = ts.groupby(lambda x: x.year) In [163]: result = (ts - grouped.transform("mean")) / grouped.transform("std") # result = ts.groupby(lambda x: x.year).transform(lambda x: x.max() - x.min()) In [164]: grouped = ts.groupby(lambda x: x.year) In [165]: result = grouped.transform("max") - grouped.transform("min") # grouped = data_df.groupby(key) # result = grouped.transform(lambda x: x.fillna(x.mean())) In [166]: grouped = data_df.groupby(key) In [167]: result = data_df.fillna(grouped.transform("mean"))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
窗口和重采样操作
可以使用 resample()、expanding() 和 rolling() 作为 groupby 的方法。
下面的示例将在列 B 的样本上应用 rolling() 方法,基于列 A 的分组。
In [168]: df_re = pd.DataFrame({"A": [1] * 10 + [5] * 10, "B": np.arange(20)}) In [169]: df_re Out[169]: A B 0 1 0 1 1 1 2 1 2 3 1 3 4 1 4 .. .. .. 15 5 15 16 5 16 17 5 17 18 5 18 19 5 19 [20 rows x 2 columns] In [170]: df_re.groupby("A").rolling(4).B.mean() Out[170]: A 1 0 NaN 1 NaN 2 NaN 3 1.5 4 2.5 ... 5 15 13.5 16 14.5 17 15.5 18 16.5 19 17.5 Name: B, Length: 20, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
expanding() 方法将为每个特定组的所有成员累积给定操作(在示例中为 sum())。
In [171]: df_re.groupby("A").expanding().sum() Out[171]: B A 1 0 0.0 1 1.0 2 3.0 3 6.0 4 10.0 ... ... 5 15 75.0 16 91.0 17 108.0 18 126.0 19 145.0 [20 rows x 1 columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
假设您想要在数据框的每个组中使用 resample() 方法获得每日频率,并希望使用 ffill() 方法填充缺失值。
In [172]: df_re = pd.DataFrame( .....: { .....: "date": pd.date_range(start="2016-01-01", periods=4, freq="W"), .....: "group": [1, 1, 2, 2], .....: "val": [5, 6, 7, 8], .....: } .....: ).set_index("date") .....: In [173]: df_re Out[173]: group val date 2016-01-03 1 5 2016-01-10 1 6 2016-01-17 2 7 2016-01-24 2 8 In [174]: df_re.groupby("group").resample("1D", include_groups=False).ffill() Out[174]: val group date 1 2016-01-03 5 2016-01-04 5 2016-01-05 5 2016-01-06 5 2016-01-07 5 ... ... 2 2016-01-20 7 2016-01-21 7 2016-01-22 7 2016-01-23 7 2016-01-24 8 [16 rows x 1 columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
过滤
过滤是一个 GroupBy 操作,它对原始分组对象进行子集化。它可以过滤掉整个组、部分组或两者。过滤返回调用对象的过滤版本,包括提供时的分组列。在以下示例中,class 包含在结果中。
In [175]: speeds
Out[175]:
class order max_speed
falcon bird Falconiformes 389.0
parrot bird Psittaciformes 24.0
lion mammal Carnivora 80.2
monkey mammal Primates NaN
leopard mammal Carnivora 58.0
In [176]: speeds.groupby("class").nth(1)
Out[176]:
class order max_speed
parrot bird Psittaciformes 24.0
monkey mammal Primates NaN
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注意
与聚合不同,过滤不会将组键添加到结果的索引中。因此,传递 as_index=False 或 sort=True 不会影响这些方法。
过滤将尊重对 GroupBy 对象列的子集。
In [177]: speeds.groupby("class")[["order", "max_speed"]].nth(1)
Out[177]:
order max_speed
parrot Psittaciformes 24.0
monkey Primates NaN
- 1
- 2
- 3
- 4
- 5
内置过滤器
GroupBy 上的以下方法作为过滤器。所有这些方法都有一个高效的、特定于 GroupBy 的实现。
| 方法 | 描述 |
|---|---|
head() | 选择每个组的前几行 |
nth() | 选择每个组的第 n 行 |
tail() | 选择每个组的底部行 |
用户还可以在布尔索引中使用转换来构建组内的复杂过滤。例如,假设我们有产品和其体积的组,并且希望将数据子集限制为每个组中总体积不超过 90%的最大产品。
In [178]: product_volumes = pd.DataFrame( .....: { .....: "group": list("xxxxyyy"), .....: "product": list("abcdefg"), .....: "volume": [10, 30, 20, 15, 40, 10, 20], .....: } .....: ) .....: In [179]: product_volumes Out[179]: group product volume 0 x a 10 1 x b 30 2 x c 20 3 x d 15 4 y e 40 5 y f 10 6 y g 20 # Sort by volume to select the largest products first In [180]: product_volumes = product_volumes.sort_values("volume", ascending=False) In [181]: grouped = product_volumes.groupby("group")["volume"] In [182]: cumpct = grouped.cumsum() / grouped.transform("sum") In [183]: cumpct Out[183]: 4 0.571429 1 0.400000 2 0.666667 6 0.857143 3 0.866667 0 1.000000 5 1.000000 Name: volume, dtype: float64 In [184]: significant_products = product_volumes[cumpct <= 0.9] In [185]: significant_products.sort_values(["group", "product"]) Out[185]: group product volume 1 x b 30 2 x c 20 3 x d 15 4 y e 40 6 y g 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
filter方法
注意
通过向filter提供用户定义函数(UDF)进行过滤通常不如使用 GroupBy 上的内置方法高效。考虑将复杂操作分解为一系列利用内置方法的操作链。
filter方法接受一个用户定义函数(UDF),当应用于整个组时,返回True或False。然后,filter方法的结果是 UDF 返回True的组的子集。
假设我们只想获取属于组总和大于 2 的元素。
In [186]: sf = pd.Series([1, 1, 2, 3, 3, 3])
In [187]: sf.groupby(sf).filter(lambda x: x.sum() > 2)
Out[187]:
3 3
4 3
5 3
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
另一个有用的操作是过滤出只有几个成员的组中的元素。
In [188]: dff = pd.DataFrame({"A": np.arange(8), "B": list("aabbbbcc")})
In [189]: dff.groupby("B").filter(lambda x: len(x) > 2)
Out[189]:
A B
2 2 b
3 3 b
4 4 b
5 5 b
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
或者,我们可以返回一个类似索引对象,其中未通过过滤器的组填充为 NaN。
In [190]: dff.groupby("B").filter(lambda x: len(x) > 2, dropna=False)
Out[190]:
A B
0 NaN NaN
1 NaN NaN
2 2.0 b
3 3.0 b
4 4.0 b
5 5.0 b
6 NaN NaN
7 NaN NaN
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对于具有多列的数据框,过滤器应明确指定列作为过滤条件。
In [191]: dff["C"] = np.arange(8)
In [192]: dff.groupby("B").filter(lambda x: len(x["C"]) > 2)
Out[192]:
A B C
2 2 b 2
3 3 b 3
4 4 b 4
5 5 b 5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
内置过滤
GroupBy 上的以下方法充当过滤器。所有这些方法都有高效的、GroupBy 特定的实现。
| 方法 | 描述 |
|---|---|
head() | 选择每个组的顶部行 |
nth() | 选择每个组的第 n 行 |
tail() | 选择每个组的底部行 |
用户还可以在布尔索引中使用转换来构建组内的复杂过滤。例如,假设我们有产品和其体积的组,并且希望将数据子集限制为每个组中总体积不超过 90%的最大产品。
In [178]: product_volumes = pd.DataFrame( .....: { .....: "group": list("xxxxyyy"), .....: "product": list("abcdefg"), .....: "volume": [10, 30, 20, 15, 40, 10, 20], .....: } .....: ) .....: In [179]: product_volumes Out[179]: group product volume 0 x a 10 1 x b 30 2 x c 20 3 x d 15 4 y e 40 5 y f 10 6 y g 20 # Sort by volume to select the largest products first In [180]: product_volumes = product_volumes.sort_values("volume", ascending=False) In [181]: grouped = product_volumes.groupby("group")["volume"] In [182]: cumpct = grouped.cumsum() / grouped.transform("sum") In [183]: cumpct Out[183]: 4 0.571429 1 0.400000 2 0.666667 6 0.857143 3 0.866667 0 1.000000 5 1.000000 Name: volume, dtype: float64 In [184]: significant_products = product_volumes[cumpct <= 0.9] In [185]: significant_products.sort_values(["group", "product"]) Out[185]: group product volume 1 x b 30 2 x c 20 3 x d 15 4 y e 40 6 y g 20
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
filter方法
注意
通过向filter提供用户定义函数(UDF)进行过滤通常不如使用 GroupBy 上的内置方法高效。考虑将复杂操作分解为一系列利用内置方法的操作链。
filter方法接受一个用户定义函数(UDF),当应用于整个组时,返回True或False。filter方法的结果是 UDF 返回True的组的子集。
假设我们只想获取属于组总和大于 2 的元素。
In [186]: sf = pd.Series([1, 1, 2, 3, 3, 3])
In [187]: sf.groupby(sf).filter(lambda x: x.sum() > 2)
Out[187]:
3 3
4 3
5 3
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
另一个有用的操作是过滤出仅属于几个成员组的元素。
In [188]: dff = pd.DataFrame({"A": np.arange(8), "B": list("aabbbbcc")})
In [189]: dff.groupby("B").filter(lambda x: len(x) > 2)
Out[189]:
A B
2 2 b
3 3 b
4 4 b
5 5 b
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
或者,与其删除违规组,我们可以返回一个类似索引的对象,其中未通过筛选器的组将填充为 NaN。
In [190]: dff.groupby("B").filter(lambda x: len(x) > 2, dropna=False)
Out[190]:
A B
0 NaN NaN
1 NaN NaN
2 2.0 b
3 3.0 b
4 4.0 b
5 5.0 b
6 NaN NaN
7 NaN NaN
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
对于具有多列的 DataFrame,筛选器应明确指定列作为筛选条件。
In [191]: dff["C"] = np.arange(8)
In [192]: dff.groupby("B").filter(lambda x: len(x["C"]) > 2)
Out[192]:
A B C
2 2 b 2
3 3 b 3
4 4 b 4
5 5 b 5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
灵活的apply
对于分组数据的某些操作可能不适合聚合、转换或筛选类别。对于这些情况,可以使用apply函数。
警告
apply必须尝试从结果推断它应该作为规约器、转换器或过滤器进行操作,具体取决于传递给它的内容。因此,分组列可能包含在输出中,也可能不包含在输出中。虽然它试图智能猜测如何行事,但有时可能猜错。
注意
本节中的所有示例都可以使用其他 pandas 功能更可靠、更高效地计算。
In [193]: df Out[193]: A B C D 0 foo one -0.575247 1.346061 1 bar one 0.254161 1.511763 2 foo two -1.143704 1.627081 3 bar three 0.215897 -0.990582 4 foo two 1.193555 -0.441652 5 bar two -0.077118 1.211526 6 foo one -0.408530 0.268520 7 foo three -0.862495 0.024580 In [194]: grouped = df.groupby("A") # could also just call .describe() In [195]: grouped["C"].apply(lambda x: x.describe()) Out[195]: A bar count 3.000000 mean 0.130980 std 0.181231 min -0.077118 25% 0.069390 ... foo min -1.143704 25% -0.862495 50% -0.575247 75% -0.408530 max 1.193555 Name: C, Length: 16, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
返回结果的维度也可能会改变:
In [196]: grouped = df.groupby('A')['C'] In [197]: def f(group): .....: return pd.DataFrame({'original': group, .....: 'demeaned': group - group.mean()}) .....: In [198]: grouped.apply(f) Out[198]: original demeaned A bar 1 0.254161 0.123181 3 0.215897 0.084917 5 -0.077118 -0.208098 foo 0 -0.575247 -0.215962 2 -1.143704 -0.784420 4 1.193555 1.552839 6 -0.408530 -0.049245 7 -0.862495 -0.503211
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
对于 Series 上的apply可以操作来自应用函数的返回值,该返回值本身是一个 series,并且可能将结果上转换为 DataFrame:
In [199]: def f(x): .....: return pd.Series([x, x ** 2], index=["x", "x²"]) .....: In [200]: s = pd.Series(np.random.rand(5)) In [201]: s Out[201]: 0 0.582898 1 0.098352 2 0.001438 3 0.009420 4 0.815826 dtype: float64 In [202]: s.apply(f) Out[202]: x x² 0 0.582898 0.339770 1 0.098352 0.009673 2 0.001438 0.000002 3 0.009420 0.000089 4 0.815826 0.665572
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
类似于 aggregate() 方法,结果 dtype 将反映应用函数的 dtype。如果不同组的结果具有不同的 dtype,则将以与DataFrame构造相同的方式确定通用 dtype。
使用group_keys控制分组列的放置
要控制是否在索引中包含分组列,可以使用默认为True的group_keys参数。对比
In [203]: df.groupby("A", group_keys=True).apply(lambda x: x, include_groups=False)
Out[203]:
B C D
A
bar 1 one 0.254161 1.511763
3 three 0.215897 -0.990582
5 two -0.077118 1.211526
foo 0 one -0.575247 1.346061
2 two -1.143704 1.627081
4 two 1.193555 -0.441652
6 one -0.408530 0.268520
7 three -0.862495 0.024580
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用
In [204]: df.groupby("A", group_keys=False).apply(lambda x: x, include_groups=False)
Out[204]:
B C D
0 one -0.575247 1.346061
1 one 0.254161 1.511763
2 two -1.143704 1.627081
3 three 0.215897 -0.990582
4 two 1.193555 -0.441652
5 two -0.077118 1.211526
6 one -0.408530 0.268520
7 three -0.862495 0.024580
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
使用group_keys控制分组列的放置
要控制是否在索引中包含分组列,可以使用默认为True的group_keys参数。对比
In [203]: df.groupby("A", group_keys=True).apply(lambda x: x, include_groups=False)
Out[203]:
B C D
A
bar 1 one 0.254161 1.511763
3 three 0.215897 -0.990582
5 two -0.077118 1.211526
foo 0 one -0.575247 1.346061
2 two -1.143704 1.627081
4 two 1.193555 -0.441652
6 one -0.408530 0.268520
7 three -0.862495 0.024580
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
使用
In [204]: df.groupby("A", group_keys=False).apply(lambda x: x, include_groups=False)
Out[204]:
B C D
0 one -0.575247 1.346061
1 one 0.254161 1.511763
2 two -1.143704 1.627081
3 three 0.215897 -0.990582
4 two 1.193555 -0.441652
5 two -0.077118 1.211526
6 one -0.408530 0.268520
7 three -0.862495 0.024580
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
Numba 加速例程
自版本 1.1 新增。
如果 Numba 安装为可选依赖项,则transform和aggregate方法支持engine='numba'和engine_kwargs参数。请参阅 使用 Numba 提升性能 了解参数的一般用法和性能考虑。
函数签名必须以values, index 完全开头,因为属于每个组的数据将被传递给values,分组索引将被传递给index。
警告
当使用engine='numba'时,内部不会有“回退”行为。分组数据和分组索引将作为 NumPy 数组传递给 JITed 用户定义的函数,不会尝试任何替代执行。
其他有用的功能
排除非数值列
再次考虑我们一直在看的示例 DataFrame:
In [205]: df
Out[205]:
A B C D
0 foo one -0.575247 1.346061
1 bar one 0.254161 1.511763
2 foo two -1.143704 1.627081
3 bar three 0.215897 -0.990582
4 foo two 1.193555 -0.441652
5 bar two -0.077118 1.211526
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
假设我们希望按A列分组计算标准差。有一个小问题,即我们不关心列B中的数据,因为它不是数值型的。您可以通过指定numeric_only=True来避免非数值列:
In [206]: df.groupby("A").std(numeric_only=True)
Out[206]:
C D
A
bar 0.181231 1.366330
foo 0.912265 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
请注意,df.groupby('A').colname.std().比df.groupby('A').std().colname更有效。因此,如果聚合函数的结果只需要在一列(这里是colname)上,可以在应用聚合函数之前对其进行过滤。
In [207]: from decimal import Decimal In [208]: df_dec = pd.DataFrame( .....: { .....: "id": [1, 2, 1, 2], .....: "int_column": [1, 2, 3, 4], .....: "dec_column": [ .....: Decimal("0.50"), .....: Decimal("0.15"), .....: Decimal("0.25"), .....: Decimal("0.40"), .....: ], .....: } .....: ) .....: In [209]: df_dec.groupby(["id"])[["dec_column"]].sum() Out[209]: dec_column id 1 0.75 2 0.55
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
处理(未)观察到的分类值
当使用Categorical分组器(作为单个分组器或作为多个分组器的一部分)时,observed关键字控制是否返回所有可能的分组器值的笛卡尔积(observed=False)或仅返回观察到的分组器值(observed=True)。
显示所有值:
In [210]: pd.Series([1, 1, 1]).groupby(
.....: pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=False
.....: ).count()
.....:
Out[210]:
a 3
b 0
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
仅显示观察值:
In [211]: pd.Series([1, 1, 1]).groupby(
.....: pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=True
.....: ).count()
.....:
Out[211]:
a 3
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
分组的返回 dtype 将始终包括所有被分组的类别。
In [212]: s = ( .....: pd.Series([1, 1, 1]) .....: .groupby(pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=True) .....: .count() .....: ) .....: In [213]: s.index.dtype Out[213]: CategoricalDtype(categories=['a', 'b'], ordered=False, categories_dtype=object) ```### NA 组处理 通过`NA`,我们指的是任何`NA`值,包括`NA`、`NaN`、`NaT`和`None`。如果在分组键中存在任何`NA`值,默认情况下这些值将被排除。换句话说,任何“`NA`组”将被删除。您可以通过指定`dropna=False`来包含 NA 组。 ```py In [214]: df = pd.DataFrame({"key": [1.0, 1.0, np.nan, 2.0, np.nan], "A": [1, 2, 3, 4, 5]}) In [215]: df Out[215]: key A 0 1.0 1 1 1.0 2 2 NaN 3 3 2.0 4 4 NaN 5 In [216]: df.groupby("key", dropna=True).sum() Out[216]: A key 1.0 3 2.0 4 In [217]: df.groupby("key", dropna=False).sum() Out[217]: A key 1.0 3 2.0 4 NaN 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
使用有序因子进行分组
以 pandas 的Categorical类的实例表示的分类变量可以用作分组键。如果是这样,级别的顺序将被保留。当observed=False和sort=False时,任何未观察到的类别将按顺序排在结果的末尾。
In [218]: days = pd.Categorical( .....: values=["Wed", "Mon", "Thu", "Mon", "Wed", "Sat"], .....: categories=["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"], .....: ) .....: In [219]: data = pd.DataFrame( .....: { .....: "day": days, .....: "workers": [3, 4, 1, 4, 2, 2], .....: } .....: ) .....: In [220]: data Out[220]: day workers 0 Wed 3 1 Mon 4 2 Thu 1 3 Mon 4 4 Wed 2 5 Sat 2 In [221]: data.groupby("day", observed=False, sort=True).sum() Out[221]: workers day Mon 8 Tue 0 Wed 5 Thu 1 Fri 0 Sat 2 Sun 0 In [222]: data.groupby("day", observed=False, sort=False).sum() Out[222]: workers day Wed 5 Mon 8 Thu 1 Sat 2 Tue 0 Fri 0 Sun 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
使用分组器规范进行分组
您可能需要指定更多数据以正确分组。您可以使用pd.Grouper提供此本地控制。
In [223]: import datetime In [224]: df = pd.DataFrame( .....: { .....: "Branch": "A A A A A A A B".split(), .....: "Buyer": "Carl Mark Carl Carl Joe Joe Joe Carl".split(), .....: "Quantity": [1, 3, 5, 1, 8, 1, 9, 3], .....: "Date": [ .....: datetime.datetime(2013, 1, 1, 13, 0), .....: datetime.datetime(2013, 1, 1, 13, 5), .....: datetime.datetime(2013, 10, 1, 20, 0), .....: datetime.datetime(2013, 10, 2, 10, 0), .....: datetime.datetime(2013, 10, 1, 20, 0), .....: datetime.datetime(2013, 10, 2, 10, 0), .....: datetime.datetime(2013, 12, 2, 12, 0), .....: datetime.datetime(2013, 12, 2, 14, 0), .....: ], .....: } .....: ) .....: In [225]: df Out[225]: Branch Buyer Quantity Date 0 A Carl 1 2013-01-01 13:00:00 1 A Mark 3 2013-01-01 13:05:00 2 A Carl 5 2013-10-01 20:00:00 3 A Carl 1 2013-10-02 10:00:00 4 A Joe 8 2013-10-01 20:00:00 5 A Joe 1 2013-10-02 10:00:00 6 A Joe 9 2013-12-02 12:00:00 7 B Carl 3 2013-12-02 14:00:00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
使用所需频率按特定列分组。这类似于重新取样。
In [226]: df.groupby([pd.Grouper(freq="1ME", key="Date"), "Buyer"])[["Quantity"]].sum()
Out[226]:
Quantity
Date Buyer
2013-01-31 Carl 1
Mark 3
2013-10-31 Carl 6
Joe 9
2013-12-31 Carl 3
Joe 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
当指定freq时,pd.Grouper返回的对象将是pandas.api.typing.TimeGrouper的实例。当存在具有相同名称的列和索引时,您可以使用key按列分组,使用level按索引分组。
In [227]: df = df.set_index("Date") In [228]: df["Date"] = df.index + pd.offsets.MonthEnd(2) In [229]: df.groupby([pd.Grouper(freq="6ME", key="Date"), "Buyer"])[["Quantity"]].sum() Out[229]: Quantity Date Buyer 2013-02-28 Carl 1 Mark 3 2014-02-28 Carl 9 Joe 18 In [230]: df.groupby([pd.Grouper(freq="6ME", level="Date"), "Buyer"])[["Quantity"]].sum() Out[230]: Quantity Date Buyer 2013-01-31 Carl 1 Mark 3 2014-01-31 Carl 9 Joe 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
获取每个组的前几行
就像对 DataFrame 或 Series 调用 head 和 tail 一样,你可以在 groupby 上调用它们:
In [231]: df = pd.DataFrame([[1, 2], [1, 4], [5, 6]], columns=["A", "B"]) In [232]: df Out[232]: A B 0 1 2 1 1 4 2 5 6 In [233]: g = df.groupby("A") In [234]: g.head(1) Out[234]: A B 0 1 2 2 5 6 In [235]: g.tail(1) Out[235]: A B 1 1 4 2 5 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这显示每个组的前 n 行或最后 n 行。
获取每个组的第 n 行
要从每个组中选择第 n 个项目,请使用 DataFrameGroupBy.nth() 或 SeriesGroupBy.nth()。提供的参数可以是任何整数、整数列表、切片或切片列表;请参见下面的示例。当组的第 n 个元素不存在时,不 会引发错误;相反,不会返回相应的行。
一般来说,此操作作为过滤器。在某些情况下,它还会返回每个组的一行,因此也是一种缩减。但是,由于一般情况下它可以返回零个或多个组的行,因此 pandas 在所有情况下都将其视为过滤器。
In [236]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], columns=["A", "B"]) In [237]: g = df.groupby("A") In [238]: g.nth(0) Out[238]: A B 0 1 NaN 2 5 6.0 In [239]: g.nth(-1) Out[239]: A B 1 1 4.0 2 5 6.0 In [240]: g.nth(1) Out[240]: A B 1 1 4.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
如果组的第 n 个元素不存在,则结果中不包括相应的行。特别是,如果指定的 n 大于任何组,结果将是一个空的 DataFrame。
In [241]: g.nth(5)
Out[241]:
Empty DataFrame
Columns: [A, B]
Index: []
- 1
- 2
- 3
- 4
- 5
如果要选择第 n 个非空项目,请使用 dropna kwarg。对于 DataFrame,这应该是 'any' 或 'all',就像您传递给 dropna 一样:
# nth(0) is the same as g.first() In [242]: g.nth(0, dropna="any") Out[242]: A B 1 1 4.0 2 5 6.0 In [243]: g.first() Out[243]: B A 1 4.0 5 6.0 # nth(-1) is the same as g.last() In [244]: g.nth(-1, dropna="any") Out[244]: A B 1 1 4.0 2 5 6.0 In [245]: g.last() Out[245]: B A 1 4.0 5 6.0 In [246]: g.B.nth(0, dropna="all") Out[246]: 1 4.0 2 6.0 Name: B, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
您还可以通过将多个 nth 值指定为整数列表来从每个组中选择多行。
In [247]: business_dates = pd.date_range(start="4/1/2014", end="6/30/2014", freq="B") In [248]: df = pd.DataFrame(1, index=business_dates, columns=["a", "b"]) # get the first, 4th, and last date index for each month In [249]: df.groupby([df.index.year, df.index.month]).nth([0, 3, -1]) Out[249]: a b 2014-04-01 1 1 2014-04-04 1 1 2014-04-30 1 1 2014-05-01 1 1 2014-05-06 1 1 2014-05-30 1 1 2014-06-02 1 1 2014-06-05 1 1 2014-06-30 1 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
您还可以使用切片或切片列表。
In [250]: df.groupby([df.index.year, df.index.month]).nth[1:] Out[250]: a b 2014-04-02 1 1 2014-04-03 1 1 2014-04-04 1 1 2014-04-07 1 1 2014-04-08 1 1 ... .. .. 2014-06-24 1 1 2014-06-25 1 1 2014-06-26 1 1 2014-06-27 1 1 2014-06-30 1 1 [62 rows x 2 columns] In [251]: df.groupby([df.index.year, df.index.month]).nth[1:, :-1] Out[251]: a b 2014-04-01 1 1 2014-04-02 1 1 2014-04-03 1 1 2014-04-04 1 1 2014-04-07 1 1 ... .. .. 2014-06-24 1 1 2014-06-25 1 1 2014-06-26 1 1 2014-06-27 1 1 2014-06-30 1 1 [65 rows x 2 columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
枚举组项目
要查看每行在其组内出现的顺序,使用 cumcount 方法:
In [252]: dfg = pd.DataFrame(list("aaabba"), columns=["A"]) In [253]: dfg Out[253]: A 0 a 1 a 2 a 3 b 4 b 5 a In [254]: dfg.groupby("A").cumcount() Out[254]: 0 0 1 1 2 2 3 0 4 1 5 3 dtype: int64 In [255]: dfg.groupby("A").cumcount(ascending=False) Out[255]: 0 3 1 2 2 1 3 1 4 0 5 0 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
枚举分组
要查看组的顺序(而不是由 cumcount 给出的组内行的顺序),可以使用 DataFrameGroupBy.ngroup()。
请注意,给定给组的数字与在迭代 groupby 对象时看到组的顺序相匹配,而不是它们首次观察到的顺序。
In [256]: dfg = pd.DataFrame(list("aaabba"), columns=["A"]) In [257]: dfg Out[257]: A 0 a 1 a 2 a 3 b 4 b 5 a In [258]: dfg.groupby("A").ngroup() Out[258]: 0 0 1 0 2 0 3 1 4 1 5 0 dtype: int64 In [259]: dfg.groupby("A").ngroup(ascending=False) Out[259]: 0 1 1 1 2 1 3 0 4 0 5 1 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
绘图
Groupby 也适用于一些绘图方法。在这种情况下,假设我们怀疑第一列的值在“B”组中平均高出 3 倍。
In [260]: np.random.seed(1234)
In [261]: df = pd.DataFrame(np.random.randn(50, 2))
In [262]: df["g"] = np.random.choice(["A", "B"], size=50)
In [263]: df.loc[df["g"] == "B", 1] += 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们可以通过箱线图轻松可视化这一点:
In [264]: df.groupby("g").boxplot()
Out[264]:
A Axes(0.1,0.15;0.363636x0.75)
B Axes(0.536364,0.15;0.363636x0.75)
dtype: object
- 1
- 2
- 3
- 4
- 5
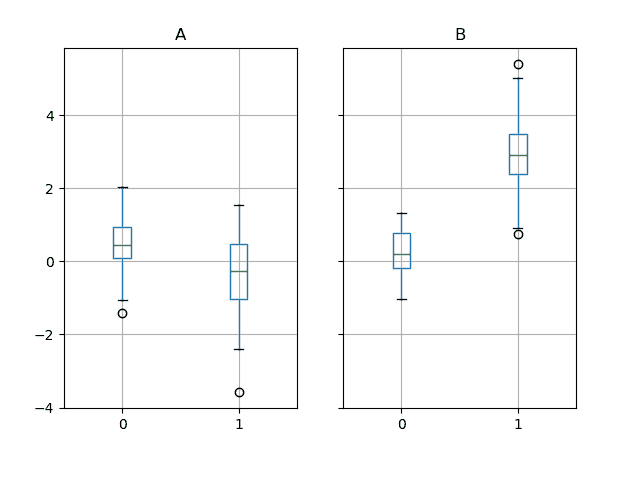
调用 boxplot 的结果是一个字典,其键是我们分组列 g 的值(“A” 和 “B”)。结果字典的值可以通过 boxplot 的 return_type 关键字进行控制。更多信息请参见可视化文档。
警告
由于历史原因,df.groupby("g").boxplot() 与 df.boxplot(by="g") 不等效。请参见这里进行解释。
管道函数调用
与 DataFrame 和 Series 提供的功能类似,可以使用 pipe 方法将接受 GroupBy 对象的函数链接在一起,以提供更清晰、更可读的语法。要阅读有关 .pipe 的一般信息,请参阅此处。
当您需要重用 GroupBy 对象时,组合 .groupby 和 .pipe 通常很有用。
例如,假设有一个 DataFrame,其中包含商店、产品、收入和销售数量的列。我们想要对每个商店和每个产品进行分组计算价格(即收入/数量)。我们可以通过多步操作来实现这一点,但是以管道的方式表达可以使代码更易读。首先设置数据:
In [265]: n = 1000 In [266]: df = pd.DataFrame( .....: { .....: "Store": np.random.choice(["Store_1", "Store_2"], n), .....: "Product": np.random.choice(["Product_1", "Product_2"], n), .....: "Revenue": (np.random.random(n) * 50 + 10).round(2), .....: "Quantity": np.random.randint(1, 10, size=n), .....: } .....: ) .....: In [267]: df.head(2) Out[267]: Store Product Revenue Quantity 0 Store_2 Product_1 26.12 1 1 Store_2 Product_1 28.86 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
现在我们找到了每个商店/产品的价格。
In [268]: (
.....: df.groupby(["Store", "Product"])
.....: .pipe(lambda grp: grp.Revenue.sum() / grp.Quantity.sum())
.....: .unstack()
.....: .round(2)
.....: )
.....:
Out[268]:
Product Product_1 Product_2
Store
Store_1 6.82 7.05
Store_2 6.30 6.64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
当您希望将分组对象传递给某个任意函数时,管道也可以很有表现力,例如:
In [269]: def mean(groupby):
.....: return groupby.mean()
.....:
In [270]: df.groupby(["Store", "Product"]).pipe(mean)
Out[270]:
Revenue Quantity
Store Product
Store_1 Product_1 34.622727 5.075758
Product_2 35.482815 5.029630
Store_2 Product_1 32.972837 5.237589
Product_2 34.684360 5.224000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
在这里,mean 接受一个 GroupBy 对象,并分别为每个商店/产品组合找到 Revenue 和 Quantity 列的均值。mean 函数可以是接受 GroupBy 对象的任何函数;.pipe 将把 GroupBy 对象作为参数传递给您指定的函数。
排除非数值列
再次考虑我们一直在查看的示例 DataFrame:
In [205]: df
Out[205]:
A B C D
0 foo one -0.575247 1.346061
1 bar one 0.254161 1.511763
2 foo two -1.143704 1.627081
3 bar three 0.215897 -0.990582
4 foo two 1.193555 -0.441652
5 bar two -0.077118 1.211526
6 foo one -0.408530 0.268520
7 foo three -0.862495 0.024580
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
假设我们希望按列 A 进行分组计算标准差。有一个轻微的问题,即我们不关心列 B 中的数据,因为它不是数值数据。您可以通过指定 numeric_only=True 来避免非数值列:
In [206]: df.groupby("A").std(numeric_only=True)
Out[206]:
C D
A
bar 0.181231 1.366330
foo 0.912265 0.884785
- 1
- 2
- 3
- 4
- 5
- 6
请注意,df.groupby('A').colname.std(). 比 df.groupby('A').std().colname 更高效。因此,如果聚合函数的结果仅需要在一列(此处为 colname)上(在应用聚合函数之前)进行过滤,那么它可能比较好。
In [207]: from decimal import Decimal In [208]: df_dec = pd.DataFrame( .....: { .....: "id": [1, 2, 1, 2], .....: "int_column": [1, 2, 3, 4], .....: "dec_column": [ .....: Decimal("0.50"), .....: Decimal("0.15"), .....: Decimal("0.25"), .....: Decimal("0.40"), .....: ], .....: } .....: ) .....: In [209]: df_dec.groupby(["id"])[["dec_column"]].sum() Out[209]: dec_column id 1 0.75 2 0.55
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
处理(未)观察到的分类值
当使用 Categorical 分组器(作为单个分组器或作为多个分组器的一部分)时,observed 关键字控制是否返回所有可能分组器值的笛卡尔积(observed=False),或仅返回观察到的分组器值(observed=True)。
显示所有值:
In [210]: pd.Series([1, 1, 1]).groupby(
.....: pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=False
.....: ).count()
.....:
Out[210]:
a 3
b 0
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
仅显示观察到的值:
In [211]: pd.Series([1, 1, 1]).groupby(
.....: pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=True
.....: ).count()
.....:
Out[211]:
a 3
dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
分组的返回 dtype 将始终包括所有分组的类别。
In [212]: s = (
.....: pd.Series([1, 1, 1])
.....: .groupby(pd.Categorical(["a", "a", "a"], categories=["a", "b"]), observed=True)
.....: .count()
.....: )
.....:
In [213]: s.index.dtype
Out[213]: CategoricalDtype(categories=['a', 'b'], ordered=False, categories_dtype=object)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
NA 组处理
通过 NA,我们指的是任何 NA 值,包括 NA、NaN、NaT 和 None。如果在分组键中有任何 NA 值,默认情况下这些值将被排除。换句话说,任何“NA 组”都将被删除。您可以通过指定 dropna=False 来包含 NA 组。
In [214]: df = pd.DataFrame({"key": [1.0, 1.0, np.nan, 2.0, np.nan], "A": [1, 2, 3, 4, 5]}) In [215]: df Out[215]: key A 0 1.0 1 1 1.0 2 2 NaN 3 3 2.0 4 4 NaN 5 In [216]: df.groupby("key", dropna=True).sum() Out[216]: A key 1.0 3 2.0 4 In [217]: df.groupby("key", dropna=False).sum() Out[217]: A key 1.0 3 2.0 4 NaN 8
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
使用有序因子分组
表示为 pandas 的 Categorical 类实例的分类变量可以用作分组键。如果是这样,则将保留级别的顺序。当 observed=False 和 sort=False 时,任何未观察到的类别将以相应顺序的结果的末尾。
In [218]: days = pd.Categorical( .....: values=["Wed", "Mon", "Thu", "Mon", "Wed", "Sat"], .....: categories=["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"], .....: ) .....: In [219]: data = pd.DataFrame( .....: { .....: "day": days, .....: "workers": [3, 4, 1, 4, 2, 2], .....: } .....: ) .....: In [220]: data Out[220]: day workers 0 Wed 3 1 Mon 4 2 Thu 1 3 Mon 4 4 Wed 2 5 Sat 2 In [221]: data.groupby("day", observed=False, sort=True).sum() Out[221]: workers day Mon 8 Tue 0 Wed 5 Thu 1 Fri 0 Sat 2 Sun 0 In [222]: data.groupby("day", observed=False, sort=False).sum() Out[222]: workers day Wed 5 Mon 8 Thu 1 Sat 2 Tue 0 Fri 0 Sun 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
使用分组器规范进行分组
你可能需要指定更多数据以正确分组。您可以使用pd.Grouper来提供这种局部控制。
In [223]: import datetime In [224]: df = pd.DataFrame( .....: { .....: "Branch": "A A A A A A A B".split(), .....: "Buyer": "Carl Mark Carl Carl Joe Joe Joe Carl".split(), .....: "Quantity": [1, 3, 5, 1, 8, 1, 9, 3], .....: "Date": [ .....: datetime.datetime(2013, 1, 1, 13, 0), .....: datetime.datetime(2013, 1, 1, 13, 5), .....: datetime.datetime(2013, 10, 1, 20, 0), .....: datetime.datetime(2013, 10, 2, 10, 0), .....: datetime.datetime(2013, 10, 1, 20, 0), .....: datetime.datetime(2013, 10, 2, 10, 0), .....: datetime.datetime(2013, 12, 2, 12, 0), .....: datetime.datetime(2013, 12, 2, 14, 0), .....: ], .....: } .....: ) .....: In [225]: df Out[225]: Branch Buyer Quantity Date 0 A Carl 1 2013-01-01 13:00:00 1 A Mark 3 2013-01-01 13:05:00 2 A Carl 5 2013-10-01 20:00:00 3 A Carl 1 2013-10-02 10:00:00 4 A Joe 8 2013-10-01 20:00:00 5 A Joe 1 2013-10-02 10:00:00 6 A Joe 9 2013-12-02 12:00:00 7 B Carl 3 2013-12-02 14:00:00
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
按照特定列和所需的频率进行分组。这类似于重采样。
In [226]: df.groupby([pd.Grouper(freq="1ME", key="Date"), "Buyer"])[["Quantity"]].sum()
Out[226]:
Quantity
Date Buyer
2013-01-31 Carl 1
Mark 3
2013-10-31 Carl 6
Joe 9
2013-12-31 Carl 3
Joe 9
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
当指定了freq时,pd.Grouper返回的对象将是pandas.api.typing.TimeGrouper的实例。当列和索引具有相同的名称时,您可以使用key按列进行分组,并使用level按索引进行分组。
In [227]: df = df.set_index("Date") In [228]: df["Date"] = df.index + pd.offsets.MonthEnd(2) In [229]: df.groupby([pd.Grouper(freq="6ME", key="Date"), "Buyer"])[["Quantity"]].sum() Out[229]: Quantity Date Buyer 2013-02-28 Carl 1 Mark 3 2014-02-28 Carl 9 Joe 18 In [230]: df.groupby([pd.Grouper(freq="6ME", level="Date"), "Buyer"])[["Quantity"]].sum() Out[230]: Quantity Date Buyer 2013-01-31 Carl 1 Mark 3 2014-01-31 Carl 9 Joe 18
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
获取每个组的第一行
就像对 DataFrame 或 Series 一样,您可以在 groupby 上调用 head 和 tail:
In [231]: df = pd.DataFrame([[1, 2], [1, 4], [5, 6]], columns=["A", "B"]) In [232]: df Out[232]: A B 0 1 2 1 1 4 2 5 6 In [233]: g = df.groupby("A") In [234]: g.head(1) Out[234]: A B 0 1 2 2 5 6 In [235]: g.tail(1) Out[235]: A B 1 1 4 2 5 6
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
这显示了每个组的前 n 行或最后 n 行。
获取每个组的第 n 行
要从每个组中选择第 n 个项目,请使用DataFrameGroupBy.nth()或SeriesGroupBy.nth()。提供的参数可以是任何整数、整数列表、切片或切片列表;请参阅下面的示例。如果组的第 n 个元素不存在,则不会引发错误;而是不返回相应的行。
一般来说,这个操作 acts as a filtration。在某些情况下,它还会返回每个组的一行,使其也成为一个减少。但是,因为一般来说它可以返回零个或多个每组的行,所以 pandas 在所有情况下都将其视为过滤器。
In [236]: df = pd.DataFrame([[1, np.nan], [1, 4], [5, 6]], columns=["A", "B"]) In [237]: g = df.groupby("A") In [238]: g.nth(0) Out[238]: A B 0 1 NaN 2 5 6.0 In [239]: g.nth(-1) Out[239]: A B 1 1 4.0 2 5 6.0 In [240]: g.nth(1) Out[240]: A B 1 1 4.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
如果组的第 n 个元素不存在,则结果中不包括相应的行。特别地,如果指定的n大于任何组,结果将是一个空的 DataFrame。
In [241]: g.nth(5)
Out[241]:
Empty DataFrame
Columns: [A, B]
Index: []
- 1
- 2
- 3
- 4
- 5
如果要选择第 n 个非空项目,请使用dropna kwarg。对于 DataFrame,这应该是'any'或'all',就像您要传递给 dropna 的一样:
# nth(0) is the same as g.first() In [242]: g.nth(0, dropna="any") Out[242]: A B 1 1 4.0 2 5 6.0 In [243]: g.first() Out[243]: B A 1 4.0 5 6.0 # nth(-1) is the same as g.last() In [244]: g.nth(-1, dropna="any") Out[244]: A B 1 1 4.0 2 5 6.0 In [245]: g.last() Out[245]: B A 1 4.0 5 6.0 In [246]: g.B.nth(0, dropna="all") Out[246]: 1 4.0 2 6.0 Name: B, dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
您还可以通过指定多个 nth 值作为整数列表来从每个组中选择多个行。
In [247]: business_dates = pd.date_range(start="4/1/2014", end="6/30/2014", freq="B") In [248]: df = pd.DataFrame(1, index=business_dates, columns=["a", "b"]) # get the first, 4th, and last date index for each month In [249]: df.groupby([df.index.year, df.index.month]).nth([0, 3, -1]) Out[249]: a b 2014-04-01 1 1 2014-04-04 1 1 2014-04-30 1 1 2014-05-01 1 1 2014-05-06 1 1 2014-05-30 1 1 2014-06-02 1 1 2014-06-05 1 1 2014-06-30 1 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
您还可以使用切片或切片列表。
In [250]: df.groupby([df.index.year, df.index.month]).nth[1:] Out[250]: a b 2014-04-02 1 1 2014-04-03 1 1 2014-04-04 1 1 2014-04-07 1 1 2014-04-08 1 1 ... .. .. 2014-06-24 1 1 2014-06-25 1 1 2014-06-26 1 1 2014-06-27 1 1 2014-06-30 1 1 [62 rows x 2 columns] In [251]: df.groupby([df.index.year, df.index.month]).nth[1:, :-1] Out[251]: a b 2014-04-01 1 1 2014-04-02 1 1 2014-04-03 1 1 2014-04-04 1 1 2014-04-07 1 1 ... .. .. 2014-06-24 1 1 2014-06-25 1 1 2014-06-26 1 1 2014-06-27 1 1 2014-06-30 1 1 [65 rows x 2 columns]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
枚举组项目
要查看每行出现在其组内的顺序,请使用cumcount方法:
In [252]: dfg = pd.DataFrame(list("aaabba"), columns=["A"]) In [253]: dfg Out[253]: A 0 a 1 a 2 a 3 b 4 b 5 a In [254]: dfg.groupby("A").cumcount() Out[254]: 0 0 1 1 2 2 3 0 4 1 5 3 dtype: int64 In [255]: dfg.groupby("A").cumcount(ascending=False) Out[255]: 0 3 1 2 2 1 3 1 4 0 5 0 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
枚举组
要查看组的排序顺序(而不是由cumcount给出的组内行的顺序),可以使用DataFrameGroupBy.ngroup()。
请注意,给定组的数字与在迭代 groupby 对象时看到组的顺序相匹配,而不是它们首次观察到的顺序。
In [256]: dfg = pd.DataFrame(list("aaabba"), columns=["A"]) In [257]: dfg Out[257]: A 0 a 1 a 2 a 3 b 4 b 5 a In [258]: dfg.groupby("A").ngroup() Out[258]: 0 0 1 0 2 0 3 1 4 1 5 0 dtype: int64 In [259]: dfg.groupby("A").ngroup(ascending=False) Out[259]: 0 1 1 1 2 1 3 0 4 0 5 1 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
绘图
Groupby 也适用于一些绘图方法。在这种情况下,假设我们怀疑列 1 中的值在组“B”中平均高出 3 倍。
In [260]: np.random.seed(1234)
In [261]: df = pd.DataFrame(np.random.randn(50, 2))
In [262]: df["g"] = np.random.choice(["A", "B"], size=50)
In [263]: df.loc[df["g"] == "B", 1] += 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
我们可以用箱线图轻松可视化这个过程:
In [264]: df.groupby("g").boxplot()
Out[264]:
A Axes(0.1,0.15;0.363636x0.75)
B Axes(0.536364,0.15;0.363636x0.75)
dtype: object
- 1
- 2
- 3
- 4
- 5
调用 boxplot 的结果是一个字典,其键是我们的分组列 g 的值(“A” 和 “B”)。结果字典的值可以通过 boxplot 的 return_type 关键字控制。有关更多信息,请参阅可视化文档。
警告
由于历史原因,df.groupby("g").boxplot() 不等同于 df.boxplot(by="g")。请参见此处进行解释。
管道函数调用
与 DataFrame 和 Series 提供的功能类似,接受 GroupBy 对象的函数可以使用 pipe 方法链接在一起,以实现更清晰、更易读的语法。要了解一般术语中的 .pipe,请参阅此处。
当您需要重用 GroupBy 对象时,结合 .groupby 和 .pipe 通常很有用。
例如,想象一下有一个 DataFrame,其中包含商店、产品、收入和销售数量的列。我们希望对每个店铺和每个产品进行分组计算价格(即收入/数量)。我们可以通过多步操作来完成此操作,但是以管道的方式表达可以使代码更易读。首先我们设置数据:
In [265]: n = 1000 In [266]: df = pd.DataFrame( .....: { .....: "Store": np.random.choice(["Store_1", "Store_2"], n), .....: "Product": np.random.choice(["Product_1", "Product_2"], n), .....: "Revenue": (np.random.random(n) * 50 + 10).round(2), .....: "Quantity": np.random.randint(1, 10, size=n), .....: } .....: ) .....: In [267]: df.head(2) Out[267]: Store Product Revenue Quantity 0 Store_2 Product_1 26.12 1 1 Store_2 Product_1 28.86 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
我们现在找到了每个店铺/产品的价格。
In [268]: (
.....: df.groupby(["Store", "Product"])
.....: .pipe(lambda grp: grp.Revenue.sum() / grp.Quantity.sum())
.....: .unstack()
.....: .round(2)
.....: )
.....:
Out[268]:
Product Product_1 Product_2
Store
Store_1 6.82 7.05
Store_2 6.30 6.64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
当您想要将分组对象传递给某个任意函数时,管道也可以很表达式,例如:
In [269]: def mean(groupby):
.....: return groupby.mean()
.....:
In [270]: df.groupby(["Store", "Product"]).pipe(mean)
Out[270]:
Revenue Quantity
Store Product
Store_1 Product_1 34.622727 5.075758
Product_2 35.482815 5.029630
Store_2 Product_1 32.972837 5.237589
Product_2 34.684360 5.224000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里 mean 接受一个 GroupBy 对象,并分别为每个 Store-Product 组合找到 Revenue 和 Quantity 列的均值。mean 函数可以是任何接受 GroupBy 对象的函数;.pipe 将把 GroupBy 对象作为参数传递到您指定的函数中。
示例
多列因子化
通过使用 DataFrameGroupBy.ngroup(),我们可以提取有关组的信息,方式类似于 factorize()(在重塑 API 中进一步描述),但它自然适用于不同类型和不同来源的多列。在处理中,当组行之间的关系比它们的内容更重要时,或者作为仅接受整数编码的算法的输入时,这可能是一个中间的类别步骤。 (有关 pandas 对完整分类数据的支持的更多信息,请参见分类介绍和 API 文档。)
In [271]: dfg = pd.DataFrame({"A": [1, 1, 2, 3, 2], "B": list("aaaba")}) In [272]: dfg Out[272]: A B 0 1 a 1 1 a 2 2 a 3 3 b 4 2 a In [273]: dfg.groupby(["A", "B"]).ngroup() Out[273]: 0 0 1 0 2 1 3 2 4 1 dtype: int64 In [274]: dfg.groupby(["A", [0, 0, 0, 1, 1]]).ngroup() Out[274]: 0 0 1 0 2 1 3 3 4 2 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
按索引器分组以“重新采样”数据
重新采样会从已经存在的观察数据或生成数据的模型中产生新的假设样本(重新采样)。这些新样本与预先存在的样本类似。
为了使重采样适用于非日期时间索引,可以使用以下过程。
在以下示例中,df.index // 5 返回一个整数数组,用于确定哪些内容被选中进行分组操作。
注意
下面的示例显示了如何通过将样本合并为较少的样本来进行降采样。在这里,通过使用df.index // 5,我们将样本聚合到箱中。通过应用**std()**函数,我们将许多样本中包含的信息聚合成一小部分值,即它们的标准差,从而减少样本数量。
In [275]: df = pd.DataFrame(np.random.randn(10, 2)) In [276]: df Out[276]: 0 1 0 -0.793893 0.321153 1 0.342250 1.618906 2 -0.975807 1.918201 3 -0.810847 -1.405919 4 -1.977759 0.461659 5 0.730057 -1.316938 6 -0.751328 0.528290 7 -0.257759 -1.081009 8 0.505895 -1.701948 9 -1.006349 0.020208 In [277]: df.index // 5 Out[277]: Index([0, 0, 0, 0, 0, 1, 1, 1, 1, 1], dtype='int64') In [278]: df.groupby(df.index // 5).std() Out[278]: 0 1 0 0.823647 1.312912 1 0.760109 0.942941
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
返回一个 Series 以传播名称
分组 DataFrame 列,计算一组指标并返回一个命名 Series。Series 名称用作列索引的名称。这在与重塑操作(如堆叠)结合使用时特别有用,其中列索引名称将用作插入列的名称:
In [279]: df = pd.DataFrame( .....: { .....: "a": [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2], .....: "b": [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1], .....: "c": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0], .....: "d": [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1], .....: } .....: ) .....: In [280]: def compute_metrics(x): .....: result = {"b_sum": x["b"].sum(), "c_mean": x["c"].mean()} .....: return pd.Series(result, name="metrics") .....: In [281]: result = df.groupby("a").apply(compute_metrics, include_groups=False) In [282]: result Out[282]: metrics b_sum c_mean a 0 2.0 0.5 1 2.0 0.5 2 2.0 0.5 In [283]: result.stack(future_stack=True) Out[283]: a metrics 0 b_sum 2.0 c_mean 0.5 1 b_sum 2.0 c_mean 0.5 2 b_sum 2.0 c_mean 0.5 dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
多列因子化
通过使用DataFrameGroupBy.ngroup(),我们可以类似于factorize()(在重塑 API 中进一步描述)的方式提取关于组的信息,但这种方式自然地适用于混合类型和不同来源的多列。这在处理中间类别步骤时可能很有用,当组行之间的关系比它们的内容更重要时,或者作为仅接受整数编码的算法的输入。(有关 pandas 对完整分类数据的支持的更多信息,请参阅分类介绍和 API 文档。)
In [271]: dfg = pd.DataFrame({"A": [1, 1, 2, 3, 2], "B": list("aaaba")}) In [272]: dfg Out[272]: A B 0 1 a 1 1 a 2 2 a 3 3 b 4 2 a In [273]: dfg.groupby(["A", "B"]).ngroup() Out[273]: 0 0 1 0 2 1 3 2 4 1 dtype: int64 In [274]: dfg.groupby(["A", [0, 0, 0, 1, 1]]).ngroup() Out[274]: 0 0 1 0 2 1 3 3 4 2 dtype: int64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
按索引器对数据进行“重采样”分组
重采样从已有的观测数据或生成数据的模型中产生新的假设样本(重采样)。这些新样本与现有样本相似。
为了使重采样适用于非日期时间索引,可以使用以下过程。
在以下示例中,df.index // 5 返回一个整数数组,用于确定哪些内容被选中进行分组操作。
注意
下面的示例显示了如何通过将样本合并为较少的样本来进行降采样。在这里,通过使用df.index // 5,我们将样本聚合到箱中。通过应用**std()**函数,我们将许多样本中包含的信息聚合成一小部分值,即它们的标准差,从而减少样本数量。
In [275]: df = pd.DataFrame(np.random.randn(10, 2)) In [276]: df Out[276]: 0 1 0 -0.793893 0.321153 1 0.342250 1.618906 2 -0.975807 1.918201 3 -0.810847 -1.405919 4 -1.977759 0.461659 5 0.730057 -1.316938 6 -0.751328 0.528290 7 -0.257759 -1.081009 8 0.505895 -1.701948 9 -1.006349 0.020208 In [277]: df.index // 5 Out[277]: Index([0, 0, 0, 0, 0, 1, 1, 1, 1, 1], dtype='int64') In [278]: df.groupby(df.index // 5).std() Out[278]: 0 1 0 0.823647 1.312912 1 0.760109 0.942941
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
返回一个 Series 以传播名称
对 DataFrame 列进行分组,计算一组指标,并返回一个命名的 Series。Series 的名称将用作列索引的名称。这在与重塑操作(如堆叠)结合使用时特别有用,其中列索引名称将用作插入列的名称:
In [279]: df = pd.DataFrame( .....: { .....: "a": [0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2], .....: "b": [0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 1, 1], .....: "c": [1, 0, 1, 0, 1, 0, 1, 0, 1, 0, 1, 0], .....: "d": [0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1], .....: } .....: ) .....: In [280]: def compute_metrics(x): .....: result = {"b_sum": x["b"].sum(), "c_mean": x["c"].mean()} .....: return pd.Series(result, name="metrics") .....: In [281]: result = df.groupby("a").apply(compute_metrics, include_groups=False) In [282]: result Out[282]: metrics b_sum c_mean a 0 2.0 0.5 1 2.0 0.5 2 2.0 0.5 In [283]: result.stack(future_stack=True) Out[283]: a metrics 0 b_sum 2.0 c_mean 0.5 1 b_sum 2.0 c_mean 0.5 2 b_sum 2.0 c_mean 0.5 dtype: float64
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35

