
- 1【SpringCloud】Eurake注册中心与Ribbon负载均衡原理_springclound eureka 负载均衡
- 2【网站项目】木里风景文化管理平台
- 3PyQt5实现一个鼠标输入的涂鸦板_pyqt 画板
- 4SpringCloud:分布式缓存之Redis分片集群_springcloud里配置了redis集群,通过redis存取数据
- 5SQL server实例配置_新生福利 | Oracle11gR2 安装配置最佳实践(Linux)第四章
- 651单片机+ESP8266+Android APP实现局域网内控制LED灯_esp8266手机端app开发
- 7SPSS时间序列模型预测_spss时间序列预测
- 8SpringBoot 统一功能处理_springboot resttemplate参数统一处理
- 9【计算机毕业设计】056校园快递代取系统_基于ssm的高校快递代取系统经济可行性分析
- 10Anaconda创建Pytorch虚拟环境(排坑详细)_anaconda创建pytorch环境
数据治理——数据血缘简介_数据治理血缘关系
赞
踩
目录
前言
在当今信息爆炸的时代,企业面临着数据增长速度快,数据源复杂多样的挑战。数据血缘可以追溯数据的来源、操作和流向,帮助企业更好的把握数据的价值和风险。
一、什么是数据血缘
1.1 数据血缘的定义
数据血缘(Data Lineage)指的是在数据的产生,ETL处理,加工,融合,流转到最终消亡的过程。数据血缘记录了数据的产生、变化和传输过程,帮助了解数据的来源、流动路径和使用情况。
数据血缘可以以图谱的形式展示,通过节点和边表示数据对象和数据之间的关系。节点代表数据表、字段或文件,边表示数据之间的依赖关系、引用关系或转换关系。
在实际数据的运用中,从数据角度厘清数据的血缘关系,即弄清楚存储在什么数据库的什么表,对应的字段是什么以及字段的属性; 从业务角度厘清数据的血缘关系,即了解数据所属业务线,业务数据的产出逻辑,数据的使用逻辑以及业务线之间的关联关系。
1.2 数据血缘的特征
1.2.1 归属性
一般而言,特定的数据归属于特定的组织或者个人。
1.2.2 多源性
一个数据也可以是多个数据经过加工生成的,而且这种加工过程可以是多个。
1.2.3 可追溯性
数据的血缘关系体现了数据的生命周期,体现了数据从产生到消亡的整个过程,具备可追溯性。
1.2.4 层次性
数据的血缘关系是有层次的。对数据进行分类,归纳,总结等描述信息又会形成新的数据,不同程度的描述信息形成了数据的层次。
1.3 数字血缘关系图例
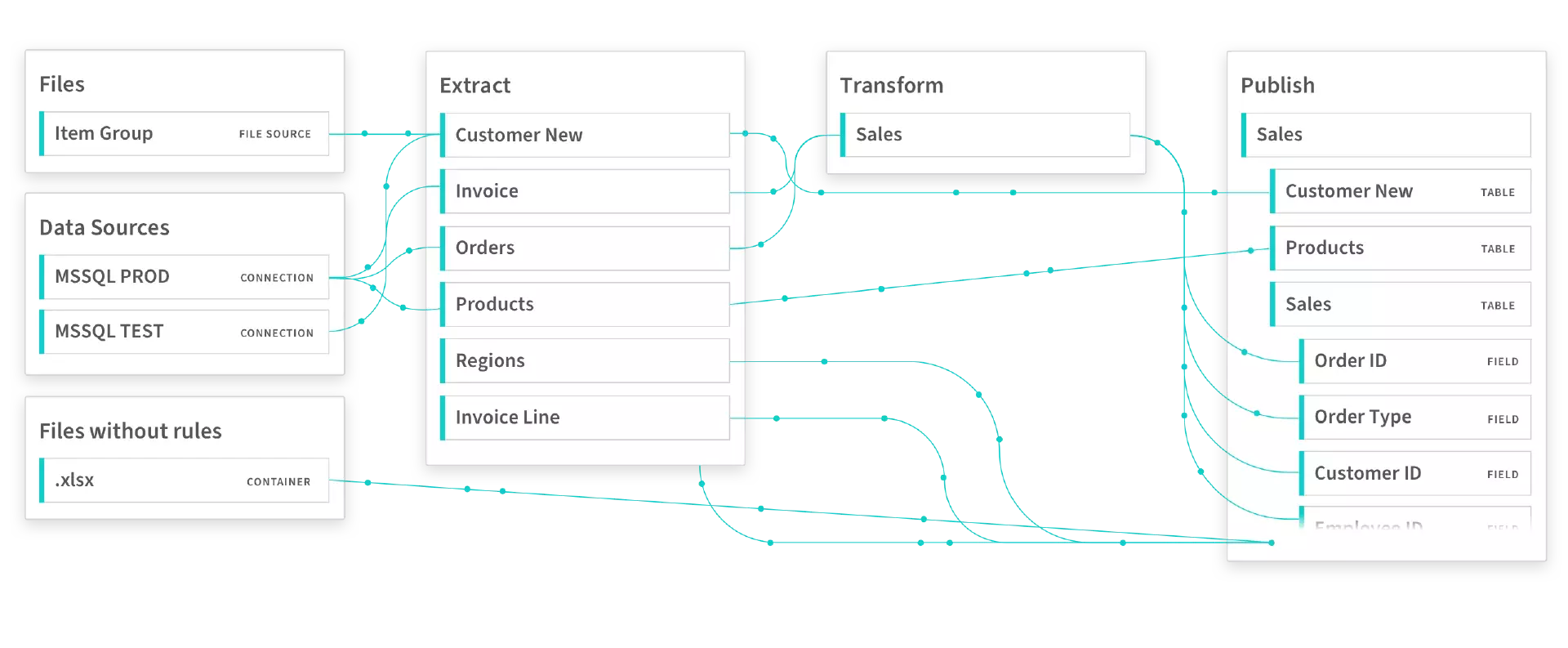
二、数据血缘的用途
数据血缘不仅帮助企业了解数据是从何处来的,还可以追踪数据的操作和流向,提供更全面的数据上下文。
2.1 优化数据资产管理成本
在资产领域,数据血缘的应用主要用于资产热度的计算。资产热度是指某个资产被频繁消费和广泛引用的程度,它可以作为资产权威性的证明。为了计算资产热度,在血缘平台中,引入了类似于网页排名算法PageRank的概念,通过分析资产的下游血缘依赖情况,为每个资产定义了一个热度值。较高的热度值代表着更直接信任和更可靠地数据资产。
此外随着业务地发展数据不断增长,只增不减的任务和数据表会不断加大数据资源的投入和管理成本。很多时候,企业不是不愿意做数据治理,而是缺少数据治理的依据,贸然下线数据库可能带来业务地重大影响,不如一直维持现状。
构建全面准确的全链路数据血缘视图,就可以找出数据的上下游应用方,做好沟通和信息同步。对于长期没有调用的服务,可以及时做下线处理,节省数据成本。
2.2 提升数据问题排查效率
数据从生产到赋能业务应用,会经过很多的处理环节,业务端报表或数据应用服务异常时,需要第一时间定位问题,排查修复。 基于数据关系,加以血缘的可视化的展现形式,可以直观地监测数据的生产链路,以及各个环节的异常情况。
数据血缘在影响分析和归因分析数据开发中发挥着重要作用。影响分析是事前的分析过程,当对某张表的资产进行变更时,上游的资产负责人需要通过血缘查看资产的下游,以判断变更的影响。可以根据对修改兼容性或某条链路的重要程度进行相应的通知操作,以避免导致严重的生产事故。
归因分析则是事后分析,当某个任务产生的表出现问题时,可以通过查询血缘的上级逐级寻找引发问题等的根本原因。对于离线数仓等情况,通过血缘的回溯找出受影响的下游任务,重新运行受影响的输出数据分区,减少不必要的资源浪费。
2.3 数据治理
在治理领域中,血缘关系可以应用于链路状态追踪和数仓治理两个典型场景。首先是链路状态追踪,当重要营销活动来临时,需要提前确定需要重点保障的任务,并通过血缘关系梳理出链路的核心部分。然后可以针对这些核心链路进行重点治理和保障措施。
其次是数仓治理。在数仓建设过程中,血缘关系可以辅助日常工作,特别是在规范化治理方面。数仓的规范化治理包括清理分层不合理的引用关系,或者规范化整体数仓分层结构,尤其处理存在冗余表的情况。例如,如果两个表来自同一个上游表但位于不同层级,那么需要清理这些冗余表。这种场景下,血缘关系可以成为一个典型的辅助治理工具。
通过应用血缘关系,可以更好地理解数据的流动和影响,从而在治理过程中做出更准确的决策和优化措施。
注:如果数仓中存在不合理的引用关系或冗余表,可能会导致以下问题:
- 数据重复和冗余:冗余表会导致数据在数仓中存在重复存储,占用额外的存储空间。这将增加数据维护的复杂性,并且可能导致数据不一致性的问题。
- 数据不一致性问题:如果不同层级的表之间存在引用关系,但引用关系不合理,可能导致数据的一致性问题。例如更新底层表时,上层表没有相应变化,导致数据不一致。
- 查询效率低下:冗余表会增加查询的复杂性,并且查询可能需要涉及多个表的联合操作。这将导致查询性能下降,同时增加查询的开销和难度。
- 数据流混乱:分层不合理的引用关系会导致数据的流程变得混乱,不易于理解和管理。降低的数仓的可维护性和可扩展性。
为了解决上述问题,数仓治理通常需要对数据血缘进行分析,以追溯数据的来源和流向,识别冗余表和不合理的引用关系,并进行相应的清理和规范化操作。
三、数据血缘的方案和开源框架
当前数据血缘的整体解决方案主要分为三步完成数据血缘的开发:
3.1 定义数据血缘的数据结构
1)任务血缘数据结构,表示数据血缘中任务节点的数据结构;
2)字段血缘数据结构,表示数据血缘中任务节点的数据结构;
3)血缘关系图,定义任务节点和资产节点的关系结构图谱;
3.2 获取数据血缘信息存储到血缘数据库中
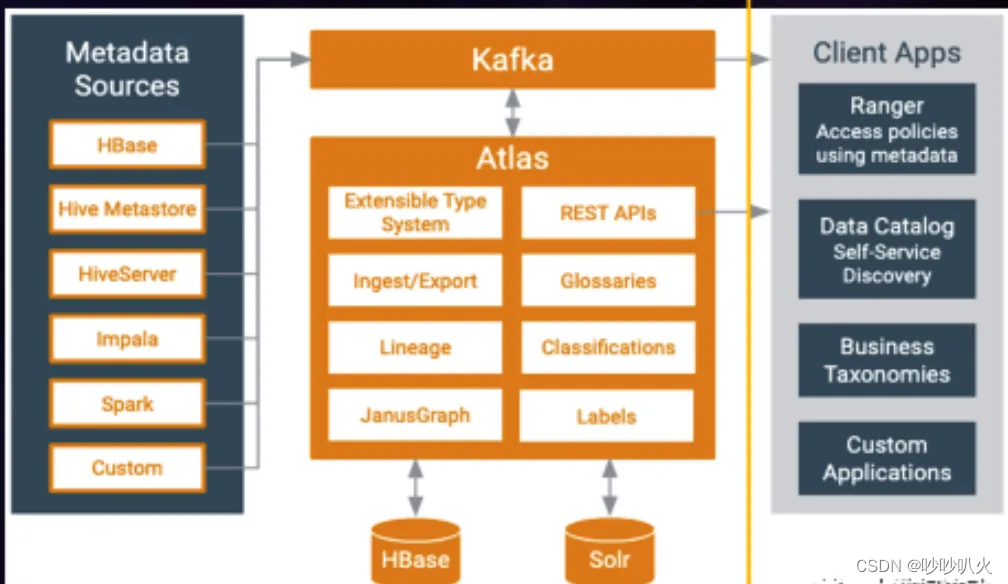
例如开源的数据血缘工具工具Atlas,Atlas通过插件(Hook)的方式在服务段注入捕获代码,并将元数据提交至kafka。Atlas服务从Kafka中消费元数据信息,并将元数据写入到 JanusGraph和 Solr两个系统。Atlas通过RestAPI 方式向其他第三方服务提供元数据查询和检索的服务。同时Atlas支持Flink引擎的Hook服务代码的注入,缺点是获取的数据血缘信息不全面。
3.3 使用前端框架展示数据血缘图
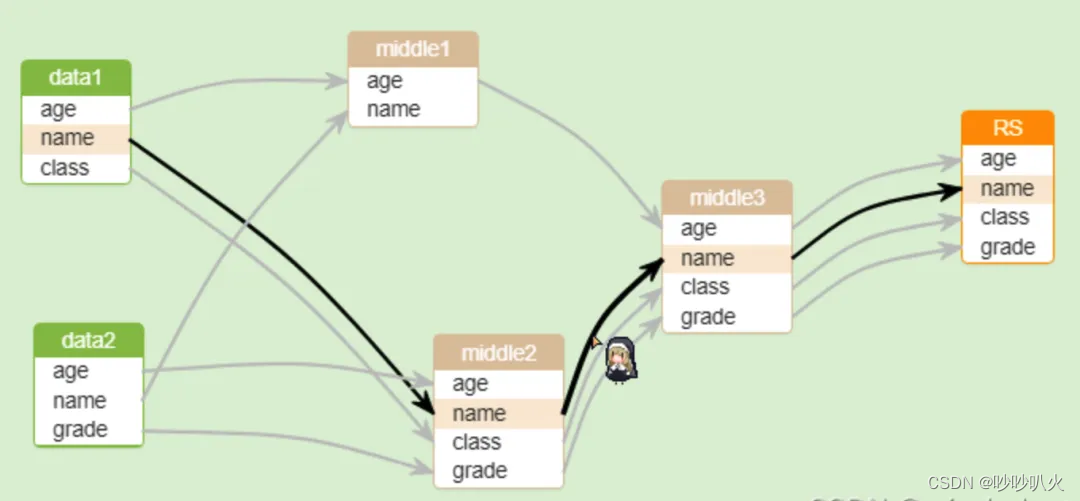
前端框架采用开源的框架有sqlflow、jsplumb、效果图如下:
1)jsplumb:
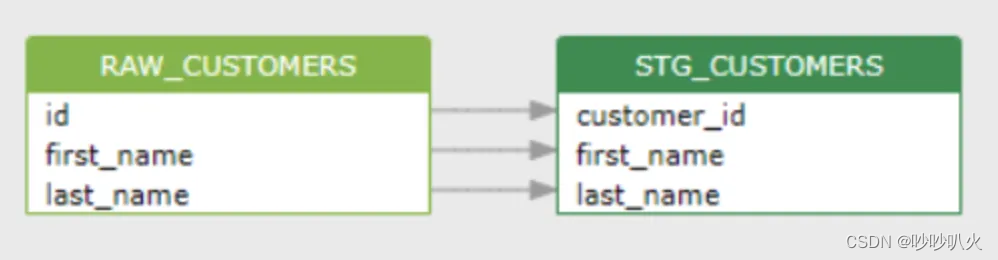
2)sqlflow:
DataHub也是数据血缘的开源框架,可以通过sqllineage 获取加工任务中的SQL代码,解析成血缘关系并存储到DataHub展示。sqllineage是一个用于解析SQL语句并提取其中的数据血缘信息的工具。它可以解析包括 Hive SQL、Spark SQL、Presto SQL 等在内的多种 SQL 方言,识别SQL 语句中的表、列、函数、关键字等元素,并分析它们之间的关系,从而构建数据血缘。通过 sqllineage,用户可以获得 SQL 语句的逻辑血缘信息,即了解 SQL 语句中哪些表和列被使用,以及它们之间的数据流向。DataHub支持的数据库类型如下:
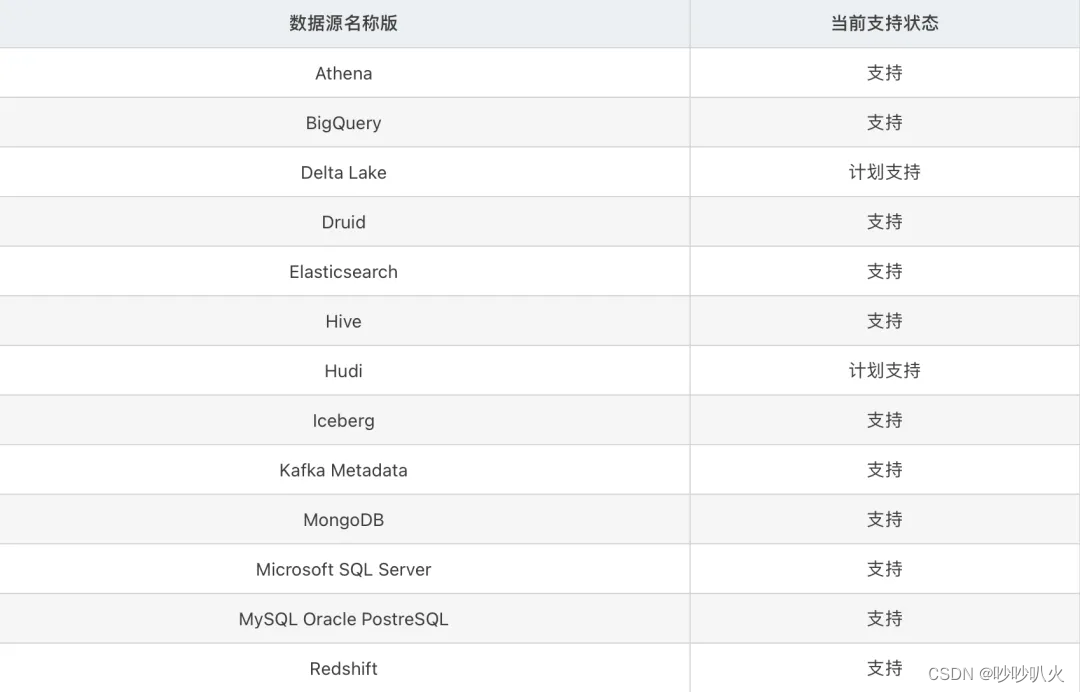
另外一个数据血缘开源框架是Amundsen,它有自己完整的元数据采集、存储、展示的整个框架,需要配合使用Apache Airflow作为数据生成器的编排引擎,从而获取血缘关系。Amundsende的模块主要分为以下4种类型:
1. 元数据服务
元数据服务处理来自前端服务以及其他微服务的元数据请求。默认情况下,持久层是Neo4j,但可以替换。
2. 搜索服务
搜索服务由ElasticSearch提供支持,处理来自前端服务的搜索请求。默认情况下,由ElasticSearch提供搜索引擎,但可以替换。
3. 前端服务
前端服务托管Amundsen的网络应用程序。
4. 数据生成器
数据生成器是一个通用的数据提取框架,可从各种来源提取元数据。在Lyft,使用Apache Airflow作为数据生成器的编排引擎。每个数据生成器job都将是DAG(有向无环图)中的单个任务。每种类型的数据资源都将有一个单独的DAG,因为它可能必须以不同的时间运行。
Atlas、DataHub和Amundsen是三个广泛使用的开源数据血缘和元数据管理工具。它们各自有不同的特点和优缺点。
3.4 开源数据血缘的区别
3.4.1 Apache Atlas
优点:
- 成熟稳定:Apache Atlas 是一款经过多年发展的成熟项目,有着稳定的功能和广泛的用户社区。
- 强大的血缘分析:Apache Atlas 提供了强大的血缘分析功能,可以跟踪数据在不同组件和系统之间的关系。
- 集成生态系统:Apache Atlas 可以与其他 Apache项目(如Ranger,Hadoop等)以及其他第三方工具集成,具有广泛的生态系统。
缺点:
- 复杂性:Apache Atlas作为一个功能强大的企业级元数据管理工具,它的配置和使用可能较为复杂。
- 缺乏实时支持:Apache Atlas并不擅长处理实时数据,对于需要实时血缘跟踪的场景可能不能提供最佳的支持。通过特殊处理可以和flink引擎结合产生血缘数据。
3.4.2 DataHub
优点:
- 实时数据集成:DataHub提供了实时数据集成的能力,可以自动发现和捕获数据源的变化。
- 与现有工具集成:DataHub可以与现有工具和系统集成,如Kafka、Hadoop和Kubernetes等。
- 可扩展:DataHub 使用分布式架构,可以水平扩展以处理大规模的数据元数据。
缺点:
- 社区相对较新:DataHub的开发社区相对较新,相比于Atlas 等老牌工具,可能缺乏一些成熟度和广泛性。
- 功能相对简单:与 Apache Atlas相比,DataHub的功能相对简单,可能不能满足所有复杂的元数据管理需求。
3.4.3 Amundsen
优点:
- 用户友好的界面:Amundsen提供了用户友好的用户界面,使得数据血缘和元数据管理更加直观和易用。
- 强调数据消费者:Amundsen强调数据消费者的使用体验,提供了交互式搜索和探索数据的功能。
- 可扩展和可定制:Amundsen的架构可以轻松地进行扩展和定制,以适应不同的业务场景。
缺点:
- 缺少某些高级功能:与 Apache Atlas相比,Amundsen在某些高级功能方面可能还有所欠缺,如安全性和遗留系统集成等。
- 需要根据实际需求和环境来选择适合的工具,这三个工具各自都有其适用的场景和优点。
参考文章:

