
- 1Sunny-Ngrok实现内网穿透(免费域名)flask实现
- 2探索学术世界:学术页面(Academic Pages)深度解析
- 3第3章 开源大模型框架概览3.2 PyTorch与Hugging Face3.2.3 PyTorch在大模型中的应用_huggingface和pytorch的区别
- 4linux python安装opencv-python失败的解决办法 ERROR: Could not build wheels for opencv-python which use PEP 517_linux pip install opencv-python没反应
- 5聚类方法:DBSCAN算法研究(1)--DBSCAN原理、流程、参数设置、优缺点以及算法_dbscan聚类算法
- 6线上线下包搭建小程序/公众号/H5 支持二开!
- 7生活中常见的分辨率_常见分辨率
- 8java 千帆大模型 流式返回_大模型的流式输出 java怎么做
- 9shell脚本部署apache_666mpm
- 10Linux(Centos 7)环境下安装wget,并且更换阿里云镜像_centos7 离线安装wget
基于Python的全国主要城市天气数据可视化大屏系统_动态天气可视化案例
赞
踩
1 绪论
1.1 研究的目的与意义
近年来,气候变化引发全球范围内的关注。天气数据的采集和分析对于气候预测、生态环境保护等方面都起着至关重要的作用。同时,随着科技的不断发展,数据可视化已经成为了许多领域中不可或缺的一部分。基于此,本研究旨在通过Python语言编写一个全国主要城市天气数据可视化大屏,以更加直观形象地展现各地区天气变化趋势。
该系统的背景是当前社会对于天气信息的需求量日益增长。人们希望能够及时获取各地天气情况,以便做出相应的决策。然而,传统的气象局发布的图表往往难以满足这种需求。因此,本研究试图通过构建一个基于Python的数据可视化系统,使天气数据更加清晰明了,并且可以自由定制各类数据展示方式,以满足用户的个性化需求。
该系统的研究目的主要有以下几点:
1.提供实时并具有交互性的天气数据可视化界面,让用户随时随地了解各地区的天气情况。
2.提供多种数据展示方式,比如地图、折线图、雷达图等,以便用户可以根据自己的需求进行选择和定制。
3.实现对历史天气数据的查询和展示,让用户可以更好地了解各地天气变化趋势。
4.将系统应用于各个领域,如农业、城市规划、旅游等,为决策者提供重要的参考意见。
总之,本研究试图通过构建一个基于Python的全国主要城市天气数据可视化大屏,为用户提供更加清晰明了、直观形象的天气数据展示方式。希望该系统可以在各个领域中发挥重要作用,为社会的发展做出贡献。。
1.2 国内外研究现状
在国外,基于Python的全国主要城市天气数据可视化大屏的研究和应用已经比较成熟。以下是一些具有代表性的研究案例:
WeatherPy - Python实现的天气数据可视化工具。它可以通过API获取全球各地的实时天气数据,并利用Matplotlib库、Basemap库等进行数据可视化处理。
Climate Data Visualization - 该项目主要通过Python和D3.js技术实现对美国气象数据的可视化。它提供了丰富的图表类型,包括折线图、散点图、柱状图等,以便用户可以根据需要进行选择和定制。
NOAA Weather and Climate Toolkit - 这是一款由美国国家海洋和大气管理局开发的天气数据可视化软件。它支持多种数据格式和图表类型,并提供了一系列工具,帮助用户进行数据分析和处理。
以上这些研究案例都证明了基于Python的全国主要城市天气数据可视化大屏在国外已经得到广泛应用,并且取得了一定的研究成果。这对于我们国内相关领域的研究也提供了宝贵的借鉴和参考意义。
在国内,基于Python的全国主要城市天气数据可视化大屏的发展现状尚处于初级阶段。虽然近年来随着人工智能和数据可视化技术的不断发展,相关领域的研究和应用已经逐渐增多,但仍存在以下几个方面的问题:
数据来源不够完善。目前国内气象部门发布的天气数据种类较少,且更新速度不够快。这给基于Python的天气数据可视化系统的研究带来了一定的挑战。
技术水平和应用场景有待提升。相对于国外同类系统,国内的基于Python的天气数据可视化系统还存在技术水平较低、应用场景较为单一等问题。应用领域也主要局限于气象和生态环境等领域,具有较为明显的行业局限性。
缺乏标准规范。由于相关领域的研究和应用尚处于起步阶段,缺乏相应的标准规范和行业认证。这可能导致各类系统之间的数据格式、处理方法、图表类型等存在差异,进而降低数据的可比性和可信度。
总之,国内基于Python的全国主要城市天气数据可视化大屏的发展现状还需要进一步提升。未来,我们需要通过加强数据采集、提高技术水平、拓宽应用场景等方面的努力,推动该领域的不断发展,为社会和经济发展做出更多的贡献。
1.3 相关技术介绍
-
Requests爬虫库 requests库是Python中一个较为常用的HTTP请求库,它能够帮助用户实现网络数据爬取、API调用等功能。使用requests库可以轻松地向指定URL发送HTTP请求,并获取服务器响应的数据内容。该库提供了简便的API,易于学习和使用。在基于Python的全国主要城市天气数据可视化大屏系统中,requests库可以用来获取各个城市的天气数据以进行可视化处理。通过向天气相关API发送HTTP请求,获取返回的JSON格式的天气数据,然后将其解析并转换成Python对象,最终进行可视化展示。requests库支持多种请求方法和参数传递方式,并提供了丰富的异常处理机制,可以有效保证系统稳定性和安全性。
-
Echarts可视化工具 Echarts是一个基于JavaScript的可视化库,它具有高度的灵活性和可定制性,能够快速构建各种类型的数据可视化图表,如折线图、柱状图、散点图、地图等。在基于Python的全国主要城市天气数据可视化大屏系统中,Echarts可用于实现对天气数据的可视化处理和展示。通过将Python中获取到的天气数据转换成JSON格式,并传递给前端进行可视化展示,可以快速实现对多维复杂数据的可视化处理。Echarts支持多语言、响应式布局和动画效果,并提供了丰富的API和插件,使得用户可以自由设置样式、交互方式和数据内容,满足不同场景下的需求。Echarts已经成为了Web可视化开发中非常重要的一环,广泛应用于金融、物流、教育、医疗等领域,为用户提供了优秀的可视化体验和数据分析工具。
-
Flask框架
Flask是一种基于Python编写的Web应用程序框架,它具有轻量级、灵活性强、易于扩展等优点。在基于Python的全国主要城市天气数据可视化大屏系统中,可以使用Flask框架搭建Web服务器,实现前后端交互和数据传递。通过将获取到的天气数据进行处理和分析,在服务器端构建JSON格式的数据对象,并使用Flask提供的路由、模板、静态文件处理等功能,将数据对象传递给前端页面进行可视化展示。Flask框架还支持多种插件和扩展,如数据库操作、认证授权、缓存、邮件发送等,可以为系统提供更丰富的功能和良好的用户体验。Flask框架对于初学者来说也比较友好,易于学习和上手。因此,基于Python的全国主要城市天气数据可视化大屏系统中使用Flask框架能够有效地简化开发流程,提高开发效率,flask框架结构如图1-1所示。

图1-1 flask框架图
2 需求分析
2.1 可行性分析
2.1.1 数据可行性
该系统的实现需要获取各个城市的天气数据,目前公开的气象数据已经可以满足需求。通过使用requests库向各类API发送HTTP请求,就能够快速获取到全国各地的天气数据,而且不同API提供的数据格式也较为统一。因此,在数据方面,该系统具有可行性。
2.1.2 技术可行性
该系统采用Python作为开发语言,并借助了多种技术和工具,如Echarts、Flask等。这些技术和工具都已经得到广泛应用和验证,具有成熟稳定的特点。同时,由于使用Python编写,系统具有较高的灵敏度和易于扩展的优点,可以适应不断变化的需求。因此,在技术方面,该系统亦具有可行性。
2.1.3 经济可行性
在经济方面,基于Python的全国主要城市天气数据可视化大屏系统所需成本较低。Python是一款免费开源的编程语言,众多的第三方库和工具也都是免费提供的。在服务器选择上,可以选择一些云计算服务商,如AWS、阿里云、腾讯云等,根据需求选择不同的套餐即可。同时,由于该系统可以应用于多种领域,如气象、旅游、城市规划等,因此具有较高的商业价值和市场前景。基于以上理由,在经济方面,该系统也具有可行性。
2.2 数据流图
在需求分析中,数据流图是对系统数据流程进行可视化呈现的一种方法。以下是该系统的数据流图如图2.1所示:

图2.1 数据流图
首先,需要从天气网站中获取全国主要城市的实时天气数据。使用requests库向API发送HTTP请求,获取返回的JSON格式数据,并将其保存到本地csv或者Excel文件中。因为获取到的原始天气数据可能存在多种类型、多个时间点的数据混合等情况。因此,需要对数据进行清洗、过滤和筛选,以便后续的可视化处理。比如,提取关键信息(如温度、湿度、风力等),将不同时间点的数据分离开来,进行缺失值处理等。接着,经过处理和筛选后,将数据转换成适合可视化展示的格式,如将数据转换为JSON格式,方便在前端页面中进行处理和呈现。最后,将处理和格式化后的数据传输给前端页面,使用Echarts库进行可视化处理。可以根据需求选择不同的图表类型(如折线图、柱状图、散点图、地图等),设置样式和交互方式,使得数据更加形象直观,易于理解和分析,天气网站数据页面如图2-2所示。

图2-2天气网站数据页面
在前端页面中,添加交互式元素(如下拉框、滑动条、复选框等),使得用户可以根据自己的需求选择不同的城市和时间点进行数据查看和分析。同时,在系统出现异常或错误时,还需要提供相应的反馈和提示,保证用户体验。
3 系统设计
3.1 系统体系结构
基于Python的全国主要城市天气数据可视化大屏系统的体系结构包括数据层、业务逻辑层和表示层三个部分。
数据层
数据层是整个系统的核心组成部分,用于存储和管理天气数据。其中包括各种天气API(如天气预报API、气象检测API等)和数据库(如MySQL、MongoDB等),通过这些数据源可以获取和存储天气数据。为了保证数据的质量和准确性,需要进行数据清洗、处理和筛选等操作,并将处理后的数据转换成JSON格式,以便传输到下一层。
业务逻辑层
业务逻辑层负责对数据进行处理和分析,并实现系统的各项功能。在该层中,使用Python编写程序,对数据进行清洗、排序、统计等操作,提取出关键信息,如温度、湿度、风力等,并将处理后的数据传递到表示层。同时,在该层中还需要实现系统的各项功能,如数据展示、图表生成等。
表示层
表示层是整个系统的前端部分,用于呈现数据和界面。在该层中,使用Echarts库实现数据的可视化处理,生成不同类型的图表,并将其显示在Web页面上。同时,使用Flask框架实现前后端交互和数据传输,为用户提供友好的操作界面。在表示层中还需要处理用户请求和反馈,保证系统的稳定性和安全性。
综上所述,基于Python的全国主要城市天气数据可视化大屏系统的体系结构包括数据层、业务逻辑层和表示层三个部分,各自承担着不同的职责和功能。数据层负责获取和管理天气数据,业务逻辑层负责对数据进行处理和分析,并实现系统的各项功能,表示层负责呈现数据和界面,并与用户进行交互。这些部分之间相互配合,形成一个完整的、高效稳定的系统,能够满足用户的需求。系统体系结构图如图3.1所示:

图3.1 系统体系结构图
3.2 系统功能模块设计
基于Python的全国主要城市天气数据可视化大屏系统的功能模块设计包括数据采集模块、数据清洗和处理模块,数据可视化模块等。
数据采集模块:该模块用于从天气网站中获取天气数据,并将其保存到本地Excel中。使用requests库向API发送请求,并对返回的JSON格式数据进行解析和处理,以便后续的清洗和分析操作。该模块需要实现以下功能:
1、根据城市名或城市编码获取指定城市的天气数据,包括日期、最高温度、最低温度、风力、风向、空气指数等;2、支持自动获取当前所在城市的天气数据;3、支持指定时间点获取历史天气数据;
数据清洗和处理模块:该模块用于对采集到的原始数据进行清洗、筛选和处理。通过对数据的分析和统计,提取出关键信息(如温度、湿度、风力等),并将不同时间点的数据分离开来,进行缺失值处理等。该模块需要实现以下功能:1、清洗和去重原始数据;2、筛选和提取关键信息;3、缺失值填充;4、数据转换为JSON格式。
数据可视化模块:该模块用于将经过清洗和处理后的数据进行可视化展示。使用Echarts库生成不同类型的图表,如折线图、柱状图、散点图、地图等,以便用户更加清晰明了地查看和分析数据。该模块需要实现以下功能:1、选择不同的图表类型和样式;2、根据用户需求,支持多种数据筛选和交互方式;3、生成动态和静态的图表;4、满足用户对数据分析和查询的需求。系统功能模块图如图3.2所示:

图3.2 系统功能模块图
3.3 数据存储设计
基于Python的全国主要城市天气数据可视化大屏系统的数据存储设计包括两种方式:本地Excel文件存储和JSON存储。采用本地Excel文件存储时,可以将获取到的原始数据以Excel文件格式保存到本地磁盘中;当采用JSON时,主要从存储的Excel文件读取并处理后,通过flask以JSON返回前端所产生的数据。
本系统的数据存储主要以Excel文件进行设计,并将数据就存在一个表:各主要城市天气信息表。包括日期、最高温度、最低温度、天气类型、风力风向、空气指数等字段。具体的字段设计如下:
| 字段名称 | 字段描述 | 字段类型 | 可空 |
|---|---|---|---|
| date | 日期 | 时间类型 | NOT |
| MaxTemp | 最高温度 | 字符串 | YES |
| MinTemp | 最低温度 | 字符串 | YES |
| Weather | 天气 | 字符串 | YES |
| Wind | 风力风向 | 字符串 | YES |
| zhishu | 空气指数 | 字符串 | YES |
4 系统实现
4.1 数据采集模块的实现
该功能主要实现了从2345天气网站抓取全国主要城市近5年天气数据,并将数据以CSV格式保存到本地文件中的功能,为进一步分析和利用天气数据提供了基础支撑。
首先,使用requests库获取天气信息页面的JSON数据,然后用BeautifulSoup库解析获得的内容。接着,根据获取到的各种信息(如日期、最高温度、最低温度、天气状况、风力等),将其存储到一个列表中,并使用csv库将列表写入CSV文件中。
具体步骤包括:
-
定义列名(date, MaxTemp, MinTemp, Weather, Wind, zhishu, city_id, year, month)并使用csv库创建CSV文件;
-
读取Excel文件中的城市代码;
-
针对每个城市、每年、每月生成URL,并爬取该URL所代表的天气数据;
-
解析获取的HTML内容,提取出所需的天气数据并存储到列表中,并使用csv库将该列表写入CSV文件中。据库中的功能。这为后续的数据分析和展示提供了重要的数据基础。系统采集模块主要代码和采集结果如图4-1和图4-2所示:

图4-1系统采集模块主要代码

图4.2 系统采集结果
4.2 数据清洗和处理模块的实现
该功能主要实现了读取Excel文件中的天气数据,对其进行初步整理和处理,然后根据不同的指数程度获取某一类数据,并返回一个包含多种数据格式(如滚动表、饼图、雷达等)的字典数据。
具体实现步骤包括:
首先定义函数read_urban(urban),通过传入城市名参数urban,使用pandas库中的read_excel()函数读取"城市近5年天气数据.xlsx"文件,然后对读取到的数据进行处理,包括将日期转换成“年-月”的格式,将摄氏度符号“°”去掉,将空气指数中的程度和等级分别提取出来,并存储到一个新的列zhishu1和zhishu_dj中。
然后定义函数get_data(urban, goods),通过传入城市名参数urban和指数程度参数goods,在read_urban()函数的基础上,进一步筛选出指定指数程度的数据,并按照日期正序排列。然后,从读取到的数据中提取日期、最高温度、最低温度和空气指数等信息,用于制作各种数据格式(如柱状图、饼图、雷达图、滚动表等)所需的数据。
最后在函数get_data()中,定义一个空字典dict_return,然后将需要的数据逐个添加到该字典中,并最终返回该字典。如get_data('北京', '严重'),即可获取城市为“北京”、指数程度为“严重”的天气数据。实现效果如图4.3所示:

图4.3 数据清洗和处理效果图
4.3 数据可视化模块的实现
首先后端创建一个名为app的Flask对象,并设置路由为“/query”,请求方法可以是GET或POST。然后定义一个名为query()的函数,用于处理用户查询请求。如果请求方法是POST,则通过request.form.get()获取HTML表单中提交的城市名和指数程度参数,并调用get_data()函数获取对应的天气数据字典dict_return;如果请求方法是GET,则默认返回城市为“北京”、指数程度为“严重”的天气数据字典dict_return。最后使用render_template()函数渲染HTML模板query.html,并将查询结果字典dict_return传递给该模板,最终将HTML页面返回给用户,数据就返回到前端页面,可以通过echart渲染成图表。
天气数据概况表: 这是滚动表的HTML页面进行交互式数据可视化展示。首先页面清空原有的滚动表数据,并从查询结果字典dict_return中获取新的滚动表数据Items。使用each()函数遍历Items数组,将每一行数据拼接成HTML格式的字符串str,并添加到滚动表的tbody元素中,最终实现滚动表的展示。
然后通过判断滚动表数据的行数是否大于10,来决定是否需要开启滚动效果。如果行数小于等于10,则不需要滚动;否则,将滚动表的tbody元素内容复制一份,并添加到原内容之后,然后设置.tbl-body元素的top属性为0,即让滚动表回到起始位置。再定义一个Marqueehq()函数,用于控制滚动表的滚动速度和方向(向上滚动),并使用setInterval()函数不停地调用该函数,以实现滚动效果。同时,当鼠标移入滚动表头部时,清除滚动效果;当鼠标移出时,重新开启滚动效果。实现效果如图4.4所示:

图4.4 天气数据概况表
最低温度变化折线图: 该折线图展示了不同时间节点最低温度变化情况。我们通过采集2345天气网站的天气数据,得到全国主要城市天气数据的最低温度,并使用Pandas进行数据清洗和预处理。然后,在ECharts图表中添加一个描述最低温度变化的折线,并通过设置文本样式和位置等属性使其更加突出和清晰。折线图的横轴表示时间,纵轴表示最低温度,并通过设置所有数据最小和最大突出显示为气泡,在右边纵轴设置可以拉动的控制轴,实现拖动交互功能。实现效果如图4.4所示:

图4.5 最低温度变化折线图
不同月份的平均指数折线图: 该折线图展示了不同月份平均空气指数变化情况。我们通过采集2345天气网站的天气数据,得到全国主要城市天气数据的空气指数,并使用Pandas进行数据清洗和预处理。然后,在ECharts图表中添加一个描述空气指数变化的折线,并通过设置文本样式和位置等属性使其更加突出和清晰。折线图的横轴表示时间,纵轴表示平均指数,并通过设置所有数据最小和最大突出显示为气泡。实现效果如图4.6所示:

图4.6 不同月份平均指数折线图
不同月份最高温度对比图: 该柱形图展示了不同时间节点最高温度变化情况。我们通过采集2345天气网站的天气数据,得到全国主要城市天气数据的最高温度,并使用Pandas进行数据清洗和预处理。然后,在ECharts图表中添加一个描述最高温度变化的折线,并通过设置文本样式和位置等属性使其更加突出和清晰。折线图的横轴表示时间,纵轴表示最高温度,在横纵轴设置可以拉动的控制轴,实现拖动交互功能。实现效果如图4.7所示:

图4.7 不同月份最高温度对比柱形图
不同年份平均指数比例饼图: 该饼图展示了不同年份平均指数数据情况。我们通过采集2345天气网站的天气数据,得到全国主要城市天气数据的空气指数,并使用Pandas进行数据清洗和预处理。然后,在ECharts图表中添加一个描述不同年份的平均指数数据,并通过设置文本样式和位置等属性使其更加突出和清晰。实现效果如图4.8所示:

图4.8 不同年份平均指数比例图
不同月份最高温度对比雷达图: 该表格展示了爬取到的电影相关信息。该雷达图展示了不同月份最高温度变化情况。我们通过采集2345天气网站的天气数据,得到全国主要城市天气数据的最高温度,并使用Pandas进行数据清洗和预处理。然后,在ECharts图表中添加一个描述不同月份的最高温度数据雷达图,并通过设置文本样式和位置等属性使其更加突出和清晰。实现效果如图4.9所示:
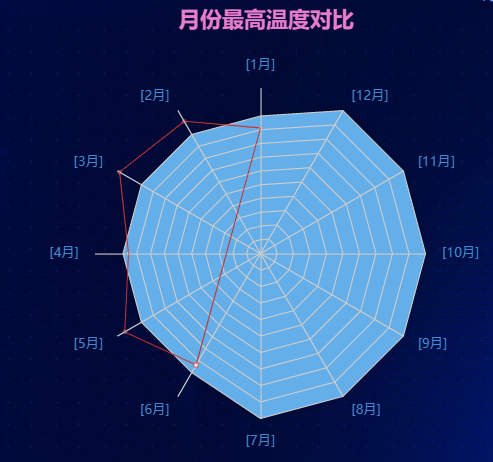
图4.9 不同月份最高温度对比雷达图
最后根据POST请求,通过request.form.get()获取HTML表单中提交的城市名和指数程度参数,并调用get_data()函数获取对应的天气数据字典dict_return;本数据大屏设置默认返回城市为“北京”、指数程度为“严重”的天气数据字典,可以在搜索框中搜索对应城市和空气质量程度实现搜索功能。总体实现效果如图4.9所示:
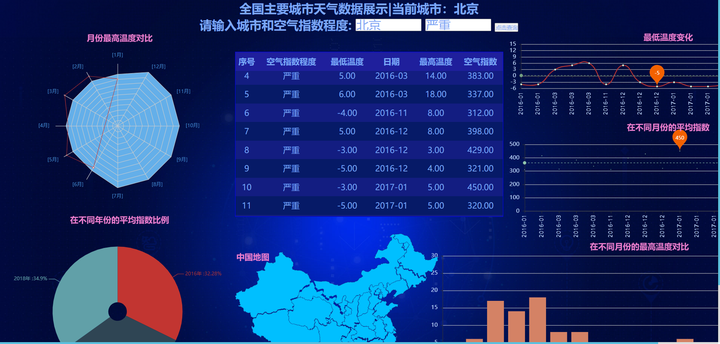
图4.9 可视化大屏图
5 系统测试
5.1 测试方法
基于Python的全国主要城市天气可视化大屏需要进行系统测试,以确保其功能的正确性、稳定性和性能。该系统的测试主要包括以下几个方面:
功能测试:对系统各项功能进行测试,如数据采集、清洗、分析、展示等方面。通过模拟不同情况下的用户操作,验证系统在不同场景下的响应和表现。
兼容性测试:测试系统在不同浏览器、操作系统等平台上的兼容性和稳定性,确保系统可以在各种环境下正常运行。
性能测试:测试系统的性能指标,如响应时间、处理速度等方面。通过模拟大量同时访问的用户,检验系统的并发性和压力承受能力。
5.2 功能测试
5.2.1 数据采集模块测试
数据采集测试。数据采集的数据是否正常采集成功,是否能存储到表中。
下面是数据采集模块测试的测试用例表:
| 测试用例 | 测试功能 | 测试内容 | 预期结果 |
|---|---|---|---|
| 001 | 数据采集测试 | 尝试采集天气网站数据 | 成功采集数据 |
5.2.2 数据清洗和处理测试
数据清洗和存储测试。数据清洗的数据是否正常清洗成功,是否能显示处理结果。下面是数据清洗与处理模块测试的测试用例表:
| 序号 | 输入 | 预期结果 | 实际结果 | 测试结果 |
|---|---|---|---|---|
| 002 | 运行数据清洗和处理程序 | 清洗成功,并显示在控制栏中 | 清洗成功 | 通过 |
5.2.3 数据可视化测试
数据可视化测试。数据可视化是否正常显示数据和图表。如下表所示:
| 序号 | 输入 | 预期结果 | 实际结果 | 测试结果 |
|---|---|---|---|---|
| 1 | 城市搜索功能测试:输入页面参数,点击搜索 | 生成对应城市可视化大屏 | 可视化成功 | 通过 |
| 2 | 不同月份平均指数折线图测试:拉动控制轴 | 折线图 | 可视化成功 | 通过 |
| 3 | 最高温度变化折线图测试:拉动控制轴 | 生成温度折线图 | 可视化成功 | 通过 |
6 结论
随着互联网和大数据技术的不断发展,数据可视化成为了一种重要的信息展示手段。基于Python的全国主要城市天气可视化大屏正是利用了数据可视化的优势,将各个城市的天气情况以图表、地图等形式进行直观展示,从而让用户更加便捷、清晰地了解到各地的气温、降雨、风力等信息。
该系统使用Python编程语言和多个开源工具库(如Pandas、ECharts等),实现了对全国主要城市的天气数据进行采集、清洗、分析和可视化的功能。其中,通过Pandas库实现对天气API接口返回的JSON格式数据进行解析和转换;通过ECharts库实现绘制各类图表,如折线图、饼图、散点图等;实现JavaScript交互式图表的呈现和展示。
总体而言,该系统在保证数据质量和可靠性的前提下,通过采用多样化的数据可视化方式,让用户可以更加深入地了解到各城市之间的气象差异和变化趋势。同时,该系统还支持按照不同的时间尺度(如日、周、月等)进行数据筛选和展示,为用户提供更加灵活和定制化的数据需求。
未来,基于Python的全国主要城市天气可视化大屏还可以进一步完善和优化。例如,可以增加更多样化、更具实用性的图表类型,如热力图、雷达图等;另外,可以将该系统与其他相关的应用或平台进行集成和联动,以满足用户更广泛、更深入的数据分析和决策需求。此外,该系统还可以结合机器学习和人工智能等技术,实现对天气预测、风险评估等方面的更加精准和高效的支持。相信随着技术的不断更新和完善,该系统在未来会有更加广泛和深远的应用和发展前景。
参考文献
-
邹云涛, 聂绍齐, 宋超, 等. 基于互联网数据挖掘技术的电影票房预测方法[J]. 计算机工程与设计, 2017, 38(3): 809-813.
-
杨凤临. 基于Python的电影数据采集及分析[J]. 科技资讯, 2020 (9): 81-82.
-
赵晓雪, 龚峥, 张斌, 等. 基于Python的大数据采集系统研究[J]. 计算机应用与软件, 2018, 35(11): 172-175.
-
Wang, W., Chen, J., & Li, X. (2015). Data Visualization of Movie Box Office Revenues by R Language. In Proceedings of the 2015 International Conference on Culture, Education and Economic Development of Modern Society (pp. 15-18).
-
Meyer, D. (2015). Web scraping with Python: collecting more data from the modern web. " O'Reilly Media, Inc.".
-
Zhang, Z., & Zhu, H. (2018). Research on Data Analysis of Box Office Based on WeChat Intelligent Service Platform. In 2018 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC) (pp. 1550-1553). IEEE.
-
林俊杰, 吴荣才. Python在数据清洗中的应用[J]. 大众科技, 2019 (11): 173-174.
-
李方圆, 陈俊桥, 焦枝铎. 基于Flask和Echarts的Web可视化技术研究[J]. 计算机工程与设计, 2017, 38(1): 129-132.
-
苏航, 王建军, 郭正军. 基于Flask框架的Web开发技术研究[J]. 计算机与数字工程, 2020, 48(2): 284-287.
-
李小斌, 马宏伟, 窦文春. 基于Echarts的数据可视化技术[J]. 电脑与智能, 2018 (2): 59-61.

