
- 1探索3D科研绘图:从学术图表入门到精通_3d科研绘图从入门到精通
- 2Matlab通信仿真系列——带限信道的信号传输_信号经过信道通信的matlab
- 3XCode 15.3 编译私有库 报错问题_xcode15.3 报错“phasescriptexecution failed with a no
- 4详解分布式共识(一致性)算法Raft_raft 共识总称
- 5阿里云生活物联网平台中Android Demo运行_阿里云生活物联网app开源
- 6区块链浏览器_aelf区块链浏览器概述及使用说明
- 7DOS命令集
- 8多元线性回归算法python实现(非常经典)_import numpy as np import matplotlib.pyplot as plt
- 9探秘DeBERTa:微软开源的预训练语言模型
- 10IntelliJ IDEA License Server 安装使用 Mac篇
【论文笔记】GPT-1:Improving Language Understanding by Generative Pre-Training
赞
踩
Abstract
核心思想: generative pre-training + discriminative fine-tuning
1 Introduction
为了获取更多annotation,利用linguistic info从unlabeled data中学习,这很有价值,减轻了对NLP中监督学习的依赖,毕竟许多domains缺乏annotated resources,并且用无监督学习学习到好的表示可以为监督学习提供一个很大的改进——pre-trained word embeddings有着光明前景,能广泛使用。
但是从unlabeled text中学习有2个挑战,这些不确定性使得开发有效的半监督学习approaches变得困难:
- 不清楚要使用哪种optimization objectives在学习到用于迁移的表示中最有用;
- 哪种方式来transfer这些learned representations to the target task还没达成共识,具体方式有:
a combination of making task-specific changes to the model architecture
using intricate learning schemes
adding auxiliary(辅助的) learning objectives
这篇论文中,使用了半监督的方法:使用a combination of unsupervised pre-training and supervised fine-tuning.
目标是: learn a universal representation,它只需要一点adaptation就可以迁移到许多task上.
训练数据: a large corpus of unlabeled text + several datasets with manually annotated training examples(target tasks),两者不需要in the same domain
训练程序:1. 使用未标记数据上的语言模型对象去学习神经网络模型的初始参数;2. 使用相应的监督目标对这些参数进行调整,以适应目标任务。
模型结构:Transformer.
迁移过程中:使用从traversal-style approaches方法派生的特定于任务的输入自适应方法,该方法将结构化文本输入处理为单个连续序列。
2 相关工作
Semi-supervised learning: 在:sequence labeling, text classification上都有使用。但是以前的方式能捕获word-level or phrase-level statistic,以前的研究者还学到了word embeddings,现在的approaches要捕获higher-level semantics,比如 character-level, phrase-level or sentence-level embeddings.
Unsupervised pre-training:Unsupervised pre-training is a special case of semi-supervised learning where the goal is to 找到一个好的初始点 instead of modifying the supervised learning objective. 曾经pre-traning方法是一 regularization scheme,使得在深度NN中得到更好的泛化。现在被用于许多task:image classification, speech recognition, entity disambiguation and MT.
还有一些Unsupervised pre-training方式如ELMo是在训练一个supervised model钟把pre-trained得到的hidden representations作为一个auxiliary features 用于target task,这就会涉及到新参数需要change。
Auxiliary training objectives:Adding auxiliary unsupervised training objectives is an alternative form of semi-supervised learning. 早期工作用到了许多辅助NLPtasks比如:POS tagging, chunking, named entity recognition, language modeling来提高semantic role labeling. 现在,会添加auxiliary language modeling objective到目标任务中。
3 Framework
3.1 Unsupervised pre-training 无监督预训练
使用语言模型最大化下面的式子,k是上下文窗口大小,θ是语言模型参数,我们使用一个神经网络来模拟条件概率P。
使用multi-layer Transformer decoder作为语言模型。这是transformer的一个变体。将transformer decoder中Encoder-Decoder Attention层去掉作为模型的主体,然后将decoder的输出经过一个softmax层,来产生目标词的输出分布。

3.2 Supervised fine-tuning 有监督微调
在这一步我们调整我们预训练语言模型的参数θ以适应特殊的任务。

此外我们发现将一些语言模型的损失加和特殊任务的损失一起进去微调有两点好处:
- 提升监督模型的泛化性
- 加速收敛
总之,在fine-tuning期间需要添加的参数只要Wy,然后需要embeddings for 定界符(delimiter)tokens.(如下图)
3.3 Task-specific input transformations
其他任务需要structured inputs, 比如:1. ordered sentence pairs, 2. triplets of documents, questions and answers.

论文使用traversal-style approach 遍历式方法),在这里我们将结构化输入转换成预训练语言模型能够处理的有序序列(见下图)All transformations include adding randomly initialized start and end tokens (< s>, < e>).
Textual entailment :连接premise p和 hypothesis h,中间用delimiter token($)来连接
Similarity:对于相似度任务来说,两个被比较的句子没有固有的顺序。为了反映这一点,我们修改输入序列以包含两个可能的句子顺序(中间有一个分隔符),并分别处理每个序列,以生成两个序列表示hlm ,在送入线性输出层之前按元素宽度(element-wise)添加。
QA and Commonsense Reasoning:我们得到一个上下文文档Z、一个问题Q和一组可能的答案{Ak}。We concatenate the document context and question with each possible answer, adding a delimiter token in between to get [z; q; $; ak]. Each of these sequences are processed independently with our model and then normalized via a softmax layer to produce an output distribution over possible answers.
理解(参考)
- GPT模型其实质是一个语言模型,它的主体使用的是Transform的decoder部分,因为decoder在逐词翻译的时候会mask掉当前位置以后的词,所以它也是一个天生的语言模型。
- GPT堆叠了20层的decoder,而不包括encoder部分。因此在decoder中没有encoder-decoder attention的子层,但是仍然有self-attention layer子层,在该层会mask将来位置的词,这样可以使用它去做语言模型的任务:预测下一个词:
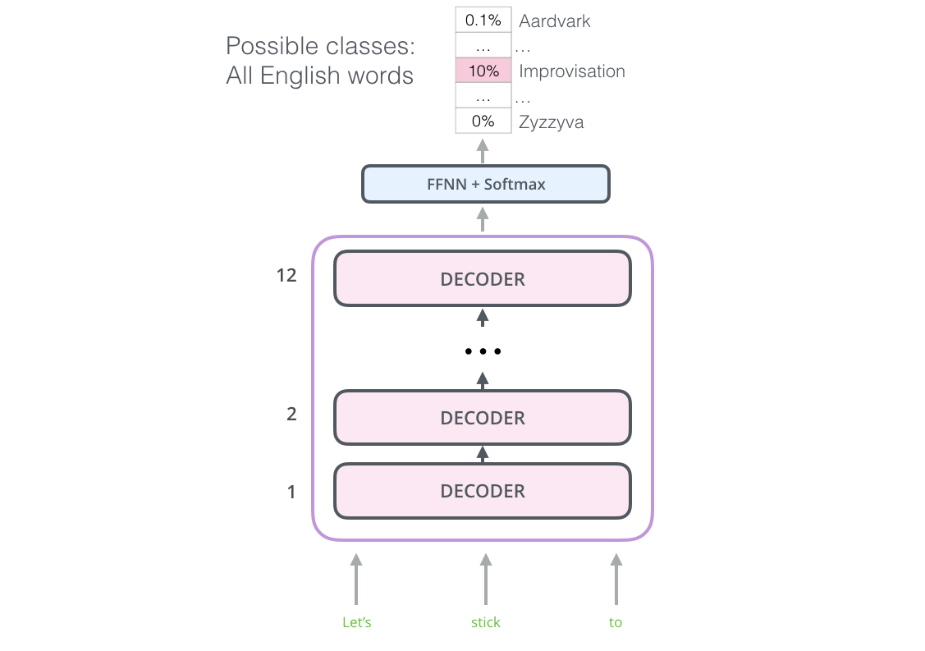
4 实验
4.1 Setup
datasets要text with long range dependencies ,这样work best with this approach.
it contains long stretches of contiguous text, which allows the generative model to learn to condition on long-range information.
4.2 Supervised fine-tuning
在QA上的:
RACE 数据集,This corpus has been shown to contain more reasoning type questions that other datasets like CNN [19] or SQuaD [47], providing the perfect evaluation for our model which is trained to handle long-range contexts.

5 Analysis
转移层数的影响(Impact of number of layers transferred):This indicates that each layer in the pre-trained model contains useful functionality for solving target tasks.

Zero-shot Behaviors:一个假设是,底层生成模型学习执行我们评估的许多任务,以提高其语言建模能力,并且transformer的更结构化的注意力记忆与LSTM相比有助于传递。
Ablation studies:
- 在fine-tuning期间没使用auxiliary LM objective:auxiliary objective有助于NLI, QQP,并且大数据集能从中受益
- Transformer与单层2048个unit的LSTM相比:提高了5.6 score
- 没有pre-trained,transformer直接训练在有监督的target tasks上:缺少预训练直接降低了14.8%


