
- 1【SwiftUI】7.预览及其内部机制_swiftui 预览
- 2初探OpenGLES(三) - 使用GLSL加载图片_glcreateshader
- 3学习Android studio心得_使用android stdio做程序的体会和建议
- 4基于STM32单片机设计的红外测温仪(带人脸检测)_基于stm32的红外体温计设计
- 5KAN: Kolmogorov–Arnold Networks 文章理解
- 6基于微信小程序的校园跑腿系统的研究与实现,附源码_校园骑手微信小程序的设计与实现
- 7VMware Workstation Pro安装好macOS 10.13之后键盘无法输入,完全失灵。_虚拟机跑mac不能输入
- 8【sqlite】命令语法入门超详细介绍_sqlite .read
- 9Android10报错:error: libxxx (native:vendor) should not link to libxxx (native:platform)(一百一十七)_native vendor should not link
- 10git 克隆出问题remote: Access denied fatal: unable to access ‘<url>‘ The requested URL returned error: 403_git clone remote: [session-e84593b6] access denied
一篇文章搞懂MySQL的分库分表,从拆分场景、目标评估、拆分方案、不停机迁移、一致性补偿等方面详细阐述MySQL数据库的分库分表方案_mysql分库分表
赞
踩
导航:
目录
一、分库分表基本概念
只分表:
单表数据量大,读写出现瓶颈,这个表所在的库还可以支撑未来几年的增长。
只分库:
整个数据库读写出现性能瓶颈,例如数据库连接数被打满了(MySQL最大连接数默认150),或者并发量太大导致单个数据库已经无法满足日常的读写需求,就需要将整个库拆开。
分库分表:
单表数据量大,所在库也出现性能瓶颈,就要既分库又分表。
垂直拆分:
把字段分开。例如spu表的pic字段特别长,建议把这个pic字段拆到另一个表(同库b不同库。
水平拆分:
把记录分开。例如表数据量到达百万,我们拆成四张20万的表。
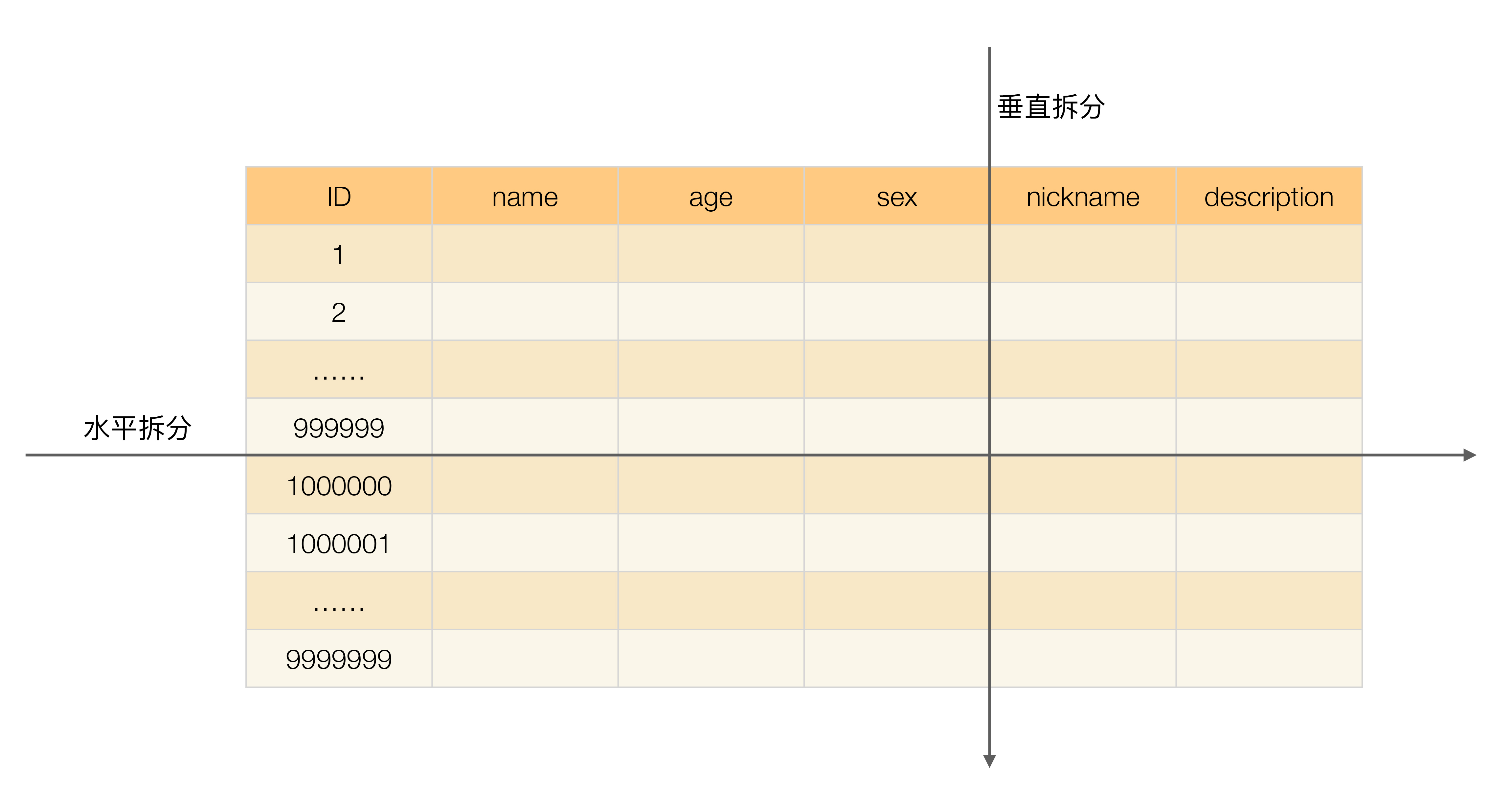
二、分库分表的场景和核心思想
一般情况下,单表数据量到达千万级别,就可以考虑分库分表了。
具体是否需要分库分表还是要看具体的业务场景,例如流水表、记录表,数据量非常容易到达千万级、亿万级,需要在设计数据库表的阶段就进行分表,还有一些表虽然数据量只有几百万,但字段非常多,而且有很多text、blog格式的字段,查询性能也会很慢,可以考虑分库分表。
| 数据量增长情况 | 数据表类型 | 优化核心思想 |
|---|---|---|
| 数据量为千万级,是一个相对稳定的数据量 | 状态表 | 能不拆就不拆读需求水平扩展 |
| 数据量为千万级,可能达到亿级或者更高 | 流水表 | 业务拆分,面向分布式存储设计 |
| 数据量为千万级,可能达到亿级或者更高 | 流水表 | 设计数据统计需求存储的分布式扩展 |
| 数据量为千万级,不应该有这么多的数据 | 配置表 | 小而简,避免大一统 |
三、分库分表具体步骤
3.1 分库分表的原则:能不分就不分
1.优先MySQL调优,能不分就不分。
数据量能稳定在千万级,近几年不会到达亿级,其实是不用着急拆的,先尝试MySQL调优,优化读写性能。只有在MySQL调优已经无法解决慢查询问题时,才可以考虑分库分表。
MySQL调优:
2.分片数量尽量少。
分片尽量均匀分布在多个 DataHost 上,因为一个查询 SQL 跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量。
3.不要一个事务里跨越多个分片查询
尽量不要在一个事务中的 SQL 跨越多个分片,分布式事务一直是个不好处理的问题。
3.2 目标评估
评估需要拆分成几个库、几个表。
举例:
当前20亿,5年后评估为100亿。分几个表? 分几个库?解答:一个合理的答案,1024个表,16个库按1024个表算,拆分完单表200万,5年后为1000万.1024个表*200w≈100亿
3.3 表拆分
3.3.1 业务层面拆分
3.3.1.1 混合业务拆分
混合业务拆分:将混合业务拆分为独立业务。
业务场景举例:
-
电商网站:一个典型的混合业务,包含用户信息、订单信息、商品信息等。可以将用户信息、订单信息和商品信息分别拆分到不同的库或表中,以减少数据冗余并提高访问效率。
-
社交媒体平台:包含用户信息、好友关系、动态信息等。可以将用户信息和好友关系分离存储,以便更好地支持好友关系的查询和更新。
-
在线游戏:涉及角色信息、道具信息、战斗日志等。可以将角色信息和道具信息拆分到不同的表中,以提升查询效率,并将战斗日志存储到日志数据库中,以减轻主数据库的负载。
-
物流系统:包含订单信息、配送信息、运输信息等。可以将订单信息、配送信息和运输信息分别拆分到不同的表中,以便更好地支持订单的查询和跟踪。
3.3.1.2 冷热分离
冷热分离:将常用的“热”数据和不常使用的“冷”数据分开存储。即在处理数据时将数据库分成冷库和热库,冷库存放那些走到终态、不常使用的数据,热库存放还需要修改、经常使用的数据。
什么情况下可以使用冷热分离?
- 数据走到终态后只有读没有写的需求。例如订单完结后基本只会读不会改。
- 用户能接受新旧数据分开查询。比如有些电商网站默认只让查询3个月内的订单,如果要查询3个月前的订单,还需要访问其他的页面。
业务场景举例:
-
邮件系统:邮件系统中最近邮件是用户经常访问和修改的,三个月前的邮件或已归档的邮件不经常访问的。可以将用户的收件箱、发件箱里最近三个月的邮件放在一个库里(热库),之前的邮件或者已读的邮件放在另一个库里(冷酷)。
-
日志系统:在大型应用中,日志数据是非常庞大的,但并不是所有日志都需要经常查询或分析。可以将最近一段时间的活动日志存放在热库中,而将过去的历史日志存放在冷库中,以减轻热库的负载和优化查询性能。
-
社交媒体平台:社交媒体平台上的用户数据量通常很大,但是只有少部分用户是活跃的,并且只有少量用户的数据会频繁访问和更新,如果所有用户都放在同一个库里,势必会影响活跃用户的查询效率。可以将活跃用户的个人信息、好友关系等存放在热库中,而将不活跃用户的数据存放在冷库中,以提升热库的性能和减少冷库的存储成本。
-
电商平台:电商平台上的商品数据也可以进行冷热分离。热库中存放热门商品的基本信息和库存等,以支持频繁的查询和更新操作,而将不活跃或下架的商品信息存放在冷库中,以减少热库的负载和优化查询性能。
-
客服工单:在我们日常操作时,经常能看到查询历史工单时会有个“近三个月工单”的选项,实际业务场景中,用户基本只会关注近三个月工单,而且这些工单也会经常需要进行修改、删除的操作,而对很早期的历史订单基本就没有修改、删除的需求,只有少量的查询需求。
3.3.2 数据层面拆分
-
按日期拆分:这种使用方式比较普遍,尤其是按照日期维度的拆分,其实在程序层面的改动很小,但是扩展性方面的收益很大。
- 日维度拆分,如test_20191021
- 月维度拆分,如test_201910
- 年维度拆分,如test_2019
-
按主键范围拆分:例如【1,200w】主键在一个表,【200w,400w】主键在一个表。优点是单表数据量可控。缺点是流量无法分摊,写操作集中在最后面的表。
-
中间表映射:表随意拆分,引入中间表记录查询的字段值,以及它对应的数据在哪个表里。优点是灵活。确定是引入中间表让流程变复杂。
-
hash切分:sharding_key%N。优点是数据分片均匀,流量分摊。缺点是扩容需要迁移数据,跨节点查询问题。
-
按分区拆分:hash,range等方式。不建议,因为数据其实难以实现水平扩展。
3.4 分表字段(sharding_key)选择
选择最佳的分表字段是一个需要仔细考虑的问题。最佳的分表字段应该是能够让数据分布均匀、频繁查询的字段以及不可变的字段。通过选择最佳的分表字段,可以提高系统的性能和查询效率。
常用字段:
-
主键ID:频繁查询并且唯一,非常适合作分表字段。例如,在用户表中,用户ID作为分表字段是一个不错的选择,因为用户ID是唯一的,而且在查询用户信息时经常会用到。
-
时间字段:如果业务需要按时间范围查询数据,那么选择时间字段作为分表字段是合理的。例如,在日志表中,可以选择时间戳字段作为分表字段,以便按天、按月或按年分割数据,方便查询和维护。
-
地理信息字段:如果业务需要按地区查询数据,那么选择地理信息字段作为分表字段是合适的。例如,在订单表中,可以选择订单地区字段作为分表字段,以便将订单数据按地区进行拆分,方便查询和扩展。
-
关联字段:如果业务需要频繁进行关联查询,那么选择订单号等关联字段作为分表字段。例如,在订单表中,可以选择订单号作为分表字段,因为订单号唯一且包含业务信息,并且日常查询、关联查询都是根据订单号查询的,很少根据id查询,方便查询和维护。
选择分表字段的原则:
1. 数据分布均匀
最佳的分表字段应该是能够让数据分布均匀的字段,这样可以避免某个表的数据过多,导致查询效率降低。在用户表中,如果以地区作为分表字段,可能会导致某些地区的数据过多,而某些地区的数据过少。
2. 频繁查询的字段
尽量选择查询频率最高的字段(例如主键id),然后根据表拆分方式选择字段。在一个订单表中,如果经常需要根据用户ID查询订单信息,那么以用户ID作为分表字段是一个不错的选择。
3. 不可变字段
最佳的分表字段还应该是不可变的字段,这样可以避免在数据迁移时出现问题。在一个商品表中,如果选择以商品名称作为分表字段,那么当商品名称发生变化时,就需要将数据移动到不同的表中,这样会增加系统的复杂度。
3.5 代码改造
修改代码里的查询、更新语句,以便让其适应分库分表后的情况。
查询语句改造:
-
单库查询改为跨库查询:对于需要查询的字段,需要明确指定查询的库和表,以避免查询到错误的数据。例如,原来的查询语句 “SELECT * FROM users WHERE id = 1” 可以修改为 “SELECT * FROM db.table_name WHERE id = 1”,其中 db 为目标数据库,table_name 为目标表。
-
单表查询改为跨表查询:例如投诉记录表根据哈希取余的方式分成10个表,如果id%1=0,则查0号表complaint_records_0。
3.6 数据迁移
最简单的就是停机迁移,复杂点的就是不停机迁移,要考虑增量同步和全量同步的问题。
3.6.1 增量同步
增量同步:老库迁移到新库期间,增删改命令的落库不能出错
- 同步双写:同步写新库和老库;
- 异步双写(推荐): 写老库,监听binlog异步同步到新库
- 中间件同步工具:通过一定的规则将数据同步到目标库表
3.6.2 全量同步
全量同步:老库到新库的数据迁移,要控制好迁移效率,解决增量数据的一致性。
- 定时任务查老库写新库
- 使用中间件迁移数据,例如Dbmate、Apache NiFi、Ladder、Phinx、Flyway、TiDB等。
3.7 数据一致性校验和补偿
假设采用异步双写方案,在迁移完成后,逐条对比新老库数据,一致则跳过,不一致则补偿:
- 新库存在,老库不存在:新库删除数据
- 新库不存在,老库存在:新库插入数据
- 新库存在、老库存在:比较所有字段,不一致则将新库更新为老库数据
3.8 灰度切读
灰度发布:指黑(旧版本)与白(新版本)之间,让一些用户继续用旧版本,一些用户开始用新版本,如果用户对新版本没什么意见,就逐步把所有用户迁移到新版本,实现平滑过渡发布。
原则:
- 有问题及时切回老库
- 灰度放量先慢后快,每次放量观察一段时间
- 支持灵活的规则:门店维度灰度、百 (万)分比灰度
3.9 停旧库、写新库
下线老库,用新库读写。


