
- 1抛弃Java 改用 Kotlin 的六个月,你不知道的小秘密。_kotlin和java哪个好
- 2「 自动化测试 」面试题..
- 3PDF Squeezer 3 for Mac(PDF简易压缩工具)_pdf sq mac
- 4[Python人工智能] 十九.Keras搭建循环神经网络分类案例及RNN原理详解_rnn网络python keras
- 5抖音视频列表数据采集与内容分析:洞察用户喜好与趋势_抖音用户数据预测
- 6Unity学习记录:制作双屏垃圾分类小游戏_unity 双屏幕
- 7springboot集成邮件功能
- 8控制状态流程图中的消息活动
- 9java商城二手手机管理系统(springboot+mysql源码+文档)
- 10告别单一密码,多因素身份认证带你进入安全新纪元!
01- 从零开始完整实现-循环神经网络RNN_从0搭建rnn
赞
踩
一 简介
使用 pytorch 搭建循环神经网络RNN,循环神经网络(Recurrent Neural Network,RNN)是一类用于 处理序列数据的神经网络架构。与传统神经网络不同,RNN 具有内部循环结构,可以在处理序列数据时保持状态信息。这使得 RNN 在自然语言处理、时间序列预测、语音识别等许多领域中非常有用。
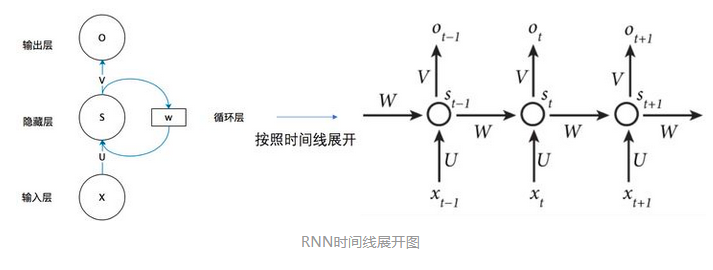
参考链接:循环神经网络(Recurrent Neural Network)
1.1 导包
- # 导包
- %matplotlib inline
-
- import math
- import torch
- from torch import nn
- from torch.nn import functional as F
- import dltools
1.2 加载数据
1.2.1 加载模块
- # Defined in file: ./chapter_recurrent-neural-networks/language-models-and-dataset.md
- def load_data_time_machine(batch_size, num_steps, use_random_iter=False,
- max_tokens=10000):
- """Return the iterator and the vocabulary of the time machine dataset."""
- data_iter = SeqDataLoader(batch_size, num_steps, use_random_iter,
- max_tokens)
- return data_iter, data_iter.vocab
-
- # 加载 time, machine 数据
- batch_size, num_steps = 32, 35
- train_iter, vocab = dltools.load_data_time_machine(batch_size=batch_size, num_steps=num_steps)
load_data_time_machine 主要是用于加载时序数据。
该函数返回两个值:
- data_iter:这是一个序列数据迭代器,用于生成训练数据的批次。这个迭代器通常用于训练循环神经网络,将数据分成多个批次,每个批次包含多个序列,每个序列有固定的时间步数,是时序数据,每批次为两个列表,一个为X, 一个目标值y。
- data_iter_vocab:这是数据集的词汇表(vocabulary),包含数据集中所有可能的标记(例如,单词或字符)及其对应的索引。词汇表是很重要的,因为它将文本数据转换为模型可以理解的数字表示,正常应该是 28个字符和数值对应的字典。
1.2.2 数据加载方式,是否使用随机数据
- # Defined in file
- class SeqDataLoader:
- """An iterator to load sequence data."""
- def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
- if use_random_iter:
- self.data_iter_fn = dltools.seq_data_iter_random
- else:
- self.data_iter_fn = dltools.seq_data_iter_sequential
- self.corpus, self.vocab = dltools.load_corpus_time_machine(max_tokens)
- self.batch_size, self.num_steps = batch_size, num_steps
-
- def __iter__(self):
- return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
-
- def seq_data_iter_random(corpus, batch_size, num_steps):
- corpus = corpus[random.randint(0, num_steps - 1):]
- num_subseqs = (len(corpus) - 1) // num_steps
- initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
- random.shuffle(initial_indices)
-
- def data(pos):
- return corpus[pos:pos + num_steps]
-
- num_batches = num_subseqs // batch_size
- for i in range(0, batch_size * num_batches, batch_size):
- initial_indices_per_batch = initial_indices[i:i + batch_size]
- X = [data(j) for j in initial_indices_per_batch]
- Y = [data(j + 1) for j in initial_indices_per_batch]
- yield dltools.tensor(X), dltools.tensor(Y)
-
-
- def seq_data_iter_sequential(corpus, batch_size, num_steps):
- """Generate a minibatch of subsequences using sequential partitioning."""
- # Start with a random offset to partition a sequence
- offset = random.randint(0, num_steps)
- num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
- Xs = dltools.tensor(corpus[offset:offset + num_tokens])
- Ys = dltools.tensor(corpus[offset + 1:offset + 1 + num_tokens])
- Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
- num_batches = Xs.shape[1] // num_steps
- for i in range(0, num_steps * num_batches, num_steps):
- X = Xs[:, i:i + num_steps]
- Y = Ys[:, i:i + num_steps]
- yield X, Y

这段代码定义了一个名为 SeDataLoader 的Python类,它是用于加载序列数据的迭代器。以下是该类的主要属性和功能解释:
- batch_size:表示每个批次(batch)中的序列数量。
- num_steps:表示每个序列的时间步数或长度。
- use_random_iter:一个布尔值,表示是否使用随机迭代器。如果设置为
True,则会随机选择数据作为训练样本;如果设置为False,则会按照固定的顺序选择数据作为训练样本。 - max_tokens:用于限制数据集中的最大标记数量。通常,用于限制词汇表的大小。
seq_data_iter_sequential 的函数,用于生成序列数据的小批量(minibatch),该函数用于顺序分割数据集。
以下是该函数的主要步骤和功能解释:
corpus: 输入的序列数据,通常是一个包含整数标记的列表或数组。batch_size: 每个小批量中的序列数量。num_steps: 每个序列的时间步数或长度。
函数开始时,它会随机选择一个偏移量 offset,该偏移量用于从数据集中分割序列。这个偏移量的目的是为了增加数据的随机性,以更好地训练模型。
1.2.3 实际加载模块
- def load_corpus_time_machine(max_tokens=-1):
- """Return token indices and the vocabulary of the time machine dataset."""
- lines = read_time_machine()
- tokens = tokenize(lines, 'char')
- vocab = Vocab(tokens)
- # Since each text line in the time machine dataset is not necessarily a
- # sentence or a paragraph, flatten all the text lines into a single list
- corpus = [vocab[token] for line in tokens for token in line]
- if max_tokens > 0:
- corpus = corpus[:max_tokens]
- return corpus, vocab
-
- def read_time_machine():
- with open('./article.txt', 'r') as f:
- lines = f.readlines()
- return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
1.2.4 查看加载 完成效果
- for x, y in train_iter:
- print('x: ', x)
- print('y: ', y)
- break

- # 输入数据,打算输入 one_hot编码
- vocab.token_to_idx

- # 输入数据,我们是打算输入 one_hot 编码的数据
- # pytorch 提供了快速进行one_hot 编码的工具
- from torch.nn import functional as F
- F.one_hot(torch.tensor([0, 2]), num_classes=len(vocab))

二 初始化模型
2.1 初始化参数
- # 初始化模型参数
- def get_params(vocab_size, num_hiddens, device):
- num_inputs = num_outputs = vocab_size
-
- # 内部函数
- def normal(shape):
- return torch.randn(size=shape, device=device) * 0.01
-
- # 隐藏层的参数
- W_xh = normal((num_inputs, num_hiddens))
- W_hh = normal((num_hiddens, num_hiddens))
- b_h = torch.zeros(num_hiddens, device=device)
-
- # 输出层参数
- W_hq = normal((num_hiddens, num_outputs))
- b_q = torch.zeros(num_outputs, device=device)
-
- # nn.parameter(w_xh) 默认可以求导
- # 把参数都设置 requires_gard = True
- params = [W_xh, W_hh, b_h, W_hq, b_q]
- for param in params:
- param.requires_grad_(True)
- return params
初始化一个循环神经网络(RNN)模型的参数的函数 get_params。这个函数会返回一个包含模型参数的列表,这些参数包括隐藏层的权重和偏置,以及输出层的权重和偏置。
以下是该函数的主要部分和功能解释:
vocab_size: 词汇表的大小,通常对应于模型的输入和输出的标记数量。num_hiddens: 隐藏层中的神经元数量,这是一个超参数。device: 指定模型参数所在的计算设备,通常是 GPU 或 CPU。
函数首先计算了 num_inputs 和 num_outputs,它们的值都等于 vocab_size,因为这个 RNN 模型的输入和输出的标记数量是相同的。
接下来,函数定义了一个内部函数 normal(shape),这个函数用于生成一个指定形状的张量,其值是从标准正态分布(均值为0,标准差为1)中随机采样的,然后乘以0.01。这是一种常用的初始化权重的方法。
然后,函数创建了以下参数:
W_xh:输入到隐藏层的权重矩阵,形状为(num_inputs, num_hiddens)。W_hh:隐藏层到隐藏层的权重矩阵,形状为(num_hiddens, num_hiddens)。b_h:隐藏层的偏置,形状为(num_hiddens,)。W_hq:隐藏层到输出层的权重矩阵,形状为(num_hiddens, num_outputs)。b_q:输出层的偏置,形状为(num_outputs,)。
这些参数的形状和初始化值都是基于 vocab_size 和 num_hiddens 来计算的。权重矩阵是随机初始化的,偏置是初始化为零的。
最后,函数将这些参数放入一个列表 params 中,并将它们的 requires_grad 属性设置为 True,这表示这些参数需要计算梯度,以便在模型训练过程中进行 反向传播和参数更新。
总之,get_params 函数的作用是根据指定的超参数和词汇表大小初始化一个循环神经网络模型的参数,并返回这些参数的列表。这些参数将在模型的训练过程中不断更新以适应训练数据。
2.2 初始化隐藏状态
- # 初始化时返回隐藏状态
- def init_rnn_state(batch_size, num_hiddens, device):
- # 返回元组
- return (torch.zeros((batch_size, num_hiddens), device=device),)
主要功能是初始化循环神经网络(RNN)的隐藏状态,并将其返回。以下是该函数的详细解释:
batch_size: 批量数据的大小,即每个小批量中的样本数量。num_hiddens: 隐藏层中的神经元数量,即 RNN 的隐藏单元数量。device: 指定初始化的张量所在的计算设备,通常为 GPU 或 CPU。
函数返回一个包含隐藏状态的元组,其中元组中的唯一元素是一个张量,表示初始化的隐藏状态。在这个元组中,张量的形状是 (batch_size, num_hiddens),它全是零。这个张量用来表示 RNN 模型的初始隐藏状态。
在训练 RNN 模型时,通常需要初始化隐藏状态,然后在每个时间步骤中更新隐藏状态。这个函数就是用来生成初始隐藏状态的,以便将其传递给 RNN 模型的第一个时间步骤。在模型的后续时间步骤中,将使用前一个时间步骤的隐藏状态来更新当前时间步骤的隐藏状态。
2.3 RNN主体结构
- # rnn主体结构
- def rnn(inputs, state, params):
- # inputs的形状: 时间步数量,批次大小,词表大小
- W_xh, W_hh, b_h, W_hq, b_q = params
- H, = state
- outputs = []
- # X的shape:【批次大小, 词表大小】
- for X in inputs:
- # 一般在循环神经网络中,激活函数使用tanh比较多
- H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h)
- Y = torch.mm(H, W_hq) + b_q
- outputs.append(Y)
- return torch.cat(outputs, dim=0), (H,)
定义了一个 RNN(循环神经网络)的主体结构,包括 前向传播 的过程。以下是该函数的详细解释:
-
inputs: 输入数据,其形状为(时间步数量,批次大小,词表大小),其中:时间步数量表示 RNN 模型将处理多少个时间步骤的数据。批次大小表示每个时间步骤有多少个样本。词表大小表示每个时间步骤中输入的特征的维度,通常用于表示词嵌入或特征向量。
-
state: 初始隐藏状态,是一个元组,其中唯一的元素是一个张量H,表示隐藏状态的形状为(批次大小,隐藏单元数量)。 -
params: 包含模型参数的列表,其中包括了权重和偏置参数。
函数的主要逻辑是循环遍历输入数据中的每个时间步骤,对于每个时间步骤,执行以下操作:
- 使用输入
X,以及当前的隐藏状态H,通过矩阵乘法和激活函数(tanh)计算新的隐藏状态H。 - 使用新的隐藏状态
H,通过矩阵乘法和偏置项,计算输出Y。
这个过程将在每个时间步骤中重复执行,每次都使用前一个时间步骤的隐藏状态作为当前时间步骤的输入,以此来模拟序列数据中的依赖关系。最终,所有时间步骤的输出将被连接成一个张量,并作为函数的返回值,同时最后一个时间步骤的隐藏状态也被返回。
这个函数的输出包括两部分:
torch.cat(outputs, dim=0):将所有时间步骤的输出连接成一个张量,维度为(时间步数量 * 批次大小, 词表大小)。这个张量包含了每个时间步骤的输出。(H,):最后一个时间步骤的隐藏状态,以元组形式返回,表示形状为(批次大小,隐藏单元数量)。
总之,这个函数实现了 RNN 模型的前向传播过程,将输入数据序列转换为输出序列,并保持隐藏状态以便在后续时间步骤中使用。
2.3.1 torch.cat
torch.cat 是 PyTorch 中用于进行张量拼接(concatenation)的函数。它允许你在指定的维度上将多个张量拼接在一起,从而创建一个新的张量。
2.3.2 torch.mm
torch.mm 是 PyTorch 中的矩阵乘法运算函数。它用于计算两个二维张量(矩阵)的矩阵乘法。具体来说,torch.mm 计算两个矩阵的内积。
三 包装成类
- # 包装成类
- class RNNModelScratch:
- def __init__(self, vocab_size, num_hiddens, device, get_params, init_state, forward_fn):
- self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
- self.params = get_params(vocab_size, num_hiddens, device)
- self.init_state, self.forward_fn = init_state, forward_fn
-
- def __call__(self, X, state):
- X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
- return self.forward_fn(X, state, self.params)
-
- def begin_state(self, batch_size, device):
- return self.init_state(batch_size, self.num_hiddens, device)
定义了一个基本的循环神经网络 (RNN) 模型类 RNNModelScratch,用于基于 PyTorch 构建一个简单的循环神经网络模型。下面是对代码的逐行解释:
-
class RNNModelScratch::这是一个 Python 类的定义,用于创建一个 RNN 模型的实例。 -
def __init__(self, vocab_size, num_hiddens, device, get_params, init_state, forward_fn)::这是类的构造函数__init__,用于初始化 RNN 模型的参数和配置。它接受以下参数:vocab_size:词汇表的大小,用于定义输入数据的维度(词表大小)。num_hiddens:隐藏层的大小,定义了 RNN 模型中隐藏状态的维度。device:指定模型在哪个计算设备上运行,如 CPU 或 GPU。get_params:一个函数,用于初始化模型的参数。init_state:一个函数,用于初始化 RNN 的隐藏状态。forward_fn:一个函数,用于定义 RNN 的前向传播过程。
-
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens:这一行将传入构造函数的参数存储在类的成员变量中,以便在整个类中使用。 -
self.params = get_params(vocab_size, num_hiddens, device):这一行调用传入的get_params函数来初始化模型的参数,并将其存储在self.params中。 -
self.init_state, self.forward_fn = init_state, forward_fn:这一行将传入的init_state和forward_fn函数存储在类的成员变量中,以便在模型中使用。 -
def __call__(self, X, state)::这是类的特殊方法__call__,它允许将类的实例像函数一样调用。这个方法用于定义如何进行前向传播。X:输入数据,通常是一个批量的序列数据。state:RNN 的隐藏状态。
-
X = F.one_hot(X.T, self.vocab_size).type(torch.float32):这一行将输入数据X转换成 one-hot 编码,以便输入到模型中。F.one_hot是 PyTorch 中的函数,它将整数序列转换成 one-hot 编码的张量。 -
return self.forward_fn(X, state, self.params):这一行调用传入的forward_fn函数,进行模型的前向传播,计算输出。 -
def begin_state(self, batch_size, device)::这个方法用于初始化 RNN 的隐藏状态,以便在训练时使用。batch_size:批量大小,定义了每个批次的样本数量。device:指定计算设备。
这个类的目的是创建一个简单的 RNN 模型,其中包括模型参数的初始化、前向传播方法的定义和隐藏状态的初始化。这个类可以用于构建和训练一个基本的循环神经网络模型。
3.1 device 的定义
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'- device = dltools.try_gpu()
-
- def try_gpu(i=0):
- """Return gpu(i) if exists, otherwise return cpu()."""
- if torch.cuda.device_count() >= i + 1:
- return torch.device(f'cuda:{i}')
- return torch.device('cpu')
四 调用定义好的 RNN
- # 使用该类
- num_hiddens = 512
- net = RNNModelScratch(len(vocab), num_hiddens, dltools.try_gpu(), get_params, init_rnn_state, rnn)
- state = net.begin_state(X.shape[0], dltools.try_gpu())
- Y, new_state = net(X.to(dltools.try_gpu()), state)
4.1 查看定义效果
Y.shape![]()
new_state
vocab.__getitem__('a') # 输出为 4 4.2 使用模型进行预测
- # 预测
- def predict(prefix, num_preds, net, vocab, device):
- state = net.begin_state(batch_size=1, device=device)
- outputs = [vocab[prefix[0]]]
- get_input = lambda: torch.tensor([outputs[-1]], device = device).reshape((1, 1))
- # 预热
- for y in prefix[1:]:
- _, state = net(get_input(), state)
- outputs.append(vocab[y])
-
- # 真正的预测
- for _ in range(num_preds):
- y, state = net(get_input(), state)
- outputs.append(int(y.argmax(dim=1).reshape(1)))
- return ''.join([vocab.idx_to_token[i] for i in outputs])
定义了一个用于生成文本序列预测的函数 predict,它的功能是使用训练好的循环神经网络模型生成预测文本。下面是对代码的逐行解释:
-
def predict(prefix, num_preds, net, vocab, device)::这是一个函数定义,用于生成文本序列的预测。prefix:一个字符串列表,表示预测的起始前缀。num_preds:指定生成的预测文本的长度。net:训练好的循环神经网络模型。vocab:词汇表,用于将模型的输出转换成文本。device:指定计算设备,如 CPU 或 GPU。
-
state = net.begin_state(batch_size=1, device=device):这一行初始化 RNN 模型的隐藏状态。net.begin_state方法返回一个元组,包含 RNN 模型的隐藏状态。这里batch_size设为 1,表示每次生成一个字符。 -
outputs = [vocab[prefix[0]]]:初始化outputs列表,用于存储预测的字符。 -
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1)):这一行定义了一个 lambda 函数get_input,用于获取模型的输入。它将outputs列表的最后一个字符转换成 PyTorch 张量,并调整形状以符合模型的输入要求。 -
预热阶段:在这个阶段,模型接受前缀
prefix作为输入,并通过模型进行预热。预热的目的是 将模型的隐藏状态初始化为前缀 的状态,以便后续的生成过程。以下代码循环遍历前缀字符,并在每个时间步上运行模型,更新隐藏状态和输出。 -
真正的预测阶段:在这个阶段,模型开始生成预测文本。模型接受前一个时间步的输出作为当前时间步的输入,并运行模型,以此生成新的字符。以下代码循环生成预测字符,并将其添加到
outputs列表中: -
return ''.join([vocab.idx_to_token[i] for i in outputs]):最后,将模型生成的字符列表转换回字符串,并返回生成的预测文本。
总的来说,这个函数使用训练好的循环神经网络模型,根据给定的前缀生成文本序列的预测。在预测过程中,模型根据前一个时间步的输出来生成下一个字符,逐步生成整个文本序列。
4.3 梯度裁剪
- # 梯度裁剪
- def grad_clipping(net, theta):
- if isinstance(net, nn.Module):
- params = [p for p in net.parameters() if p.requires_grad]
- else:
- params = net.params
-
- norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
- if norm > theta:
- for param in params:
- param.grad[:] *= theta / norm
实现了梯度裁剪的功能,用于防止梯度爆炸问题。下面是对代码的逐行解释:
-
def grad_clipping(net, theta)::这是一个函数定义,用于执行梯度裁剪。net:可以是一个 PyTorch 模型(nn.Module类的子类)或者一个自定义模型对象。theta:裁剪的阈值,当梯度的 L2 范数大于该阈值时进行裁剪。
-
if isinstance(net, nn.Module)::这一行检查net是否是 PyTorch 的nn.Module类的子类,用于判断传入的模型类型。 -
params = [p for p in net.parameters() if p.requires_grad]:如果net是nn.Module类的子类,那么这一行将获取模型中所有需要梯度更新的参数。net.parameters()返回模型的所有参数,p.requires_grad表示参数是否需要梯度。如果
net不是nn.Module类的子类,那么这一行将尝试获取自定义模型对象中的参数列表,前提是这个自定义模型对象具有名为params的属性。 -
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params)):计算所有参数梯度的 L2 范数,这个范数表示了所有参数梯度的总体大小。具体来说,这里使用了两次求和。首先,对于每个参数p,计算p.grad ** 2,然后使用torch.sum对其进行求和。接着,使用sum对所有参数的 L2 范数进行求和。 -
if norm > theta::判断梯度的 L2 范数是否大于指定的阈值theta,如果是,则执行下面的梯度裁剪操作。 -
for param in params::遍历需要梯度更新的参数列表。 -
param.grad[:] *= theta / norm:对每个参数的梯度进行裁剪操作。具体地,将参数的梯度按比例缩放,使其满足 L2 范数不超过阈值theta。这里使用param.grad[:]来直接修改参数的梯度,将其乘以缩放因子theta / norm。
总的来说,这段代码用于梯度裁剪,可以应用于任何 PyTorch 模型或自定义模型。它通过计算所有参数的梯度的 L2 范数,并将其与指定的阈值进行比较,如果超过阈值,则对梯度进行按比例的缩放,以确保梯度不会爆炸。这有助于提高模型的训练稳定性。
五 训练
- # 训练
- def train_epoch(net, train_iter, loss, updater, device, use_random_iter):
- state, timer = None, dltools.Timer()
- metric = dltools.Accumulator(2)
- for X, Y in train_iter:
- if state is None or use_random_iter:
- state = net.begin_state(batch_size=X.shape[0], device=device)
- else:
- if isinstance(net, nn.Module) and not isinstance(state, tuple):
- state.detach_()
- else:
- for s in state:
- s.detach_()
- y = Y.T.reshape(-1)
- X, y = X.to(device), y.to(device)
- y_hat, state = net(X, state)
- l = loss(y_hat, y.long()).mean()
- if isinstance(updater, torch.optim.Optimizer):
- updater.zero_grad()
- l.backward()
- grad_clippling(net, 1)
- updater.step()
- else:
- l.backward()
- grad_clipping(net, 1)
- updater(batch_size=1)
- metric.add(l * y.numel(), y.numel()) # !!!! l 不是1
- # 返回困惑度和每个字符平均训练时间
- return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
训练循环神经网络(RNN)模型的训练循环的一部分。以下是对代码的逐行解释:
-
train_epoch(net, train_iter, loss, updater, device, use_random_iter)::这是一个函数定义,用于执行一个训练周期。net:RNN 模型。train_iter:训练数据迭代器,用于生成训练数据批次。loss:损失函数,用于计算模型的损失。updater:参数更新器,可以是 PyTorch 优化器(例如torch.optim.SGD)或者一个自定义的参数更新函数。device:训练设备,通常是 GPU。use_random_iter:一个布尔值,表示是否使用随机迭代器。
-
state, timer = None, dltools.Timer():初始化state为None,timer用于计时。 -
metric = dltools.Accumulator(2):创建一个累加器metric,用于累积损失和样本数,初始化为 2 个元素的列表。 -
for X, Y in train_iter::遍历训练数据迭代器,获取训练数据批次X和标签Y。 -
if state is None or use_random_iter::检查state是否为None或者use_random_iter为真。如果是,表示需要重新初始化 RNN 的隐藏状态。 -
state = net.begin_state(batch_size=X.shape[0], device=device):调用net.begin_state方法来初始化 RNN 模型的隐藏状态,其中包括batch_size(批次大小)和device(设备)参数。 -
y = Y.T.reshape(-1):将标签Y进行转置并展平,以便与模型输出y_hat进行损失计算。 -
X, y = X.to(device), y.to(device):将输入数据X和标签y移动到指定的计算设备上,通常是 GPU。 -
y_hat, state = net(X, state):使用 RNN 模型前向传播,计算模型输出y_hat和更新的隐藏状态state。 -
l = loss(y_hat, y.long()).mean():计算损失l,这里假设loss是一个能够接受模型输出y_hat和整数类型的标签y的损失函数。然后,对损失进行均值计算。 -
if isinstance(updater, torch.optim.Optimizer)::检查updater是否是 PyTorch 的优化器,如果是,则表示使用了内置的优化器。 -
updater.zero_grad():如果使用 PyTorch 优化器,将梯度清零。 -
l.backward():反向传播,计算梯度。 -
grad_clippling(net, 1):调用grad_clippling函数,对梯度进行梯度裁剪操作,防止梯度爆炸。 -
updater.step():如果使用 PyTorch 优化器,执行参数更新步骤。 -
else::如果不使用 PyTorch 优化器,表示使用自定义的参数更新函数。 -
grad_clipping(net, 1):对梯度进行梯度裁剪操作,防止梯度爆炸。 -
updater(batch_size=1):执行参数更新操作,传递参数batch_size=1给更新器。 -
metric.add(l * y.numel(), y.numel()):将损失l乘以当前批次的样本数y.numel()加入到累加器metric中,以便后续计算损失的平均值。 -
返回困惑度(Perplexity)和每个字符
5.1 时间记录
- class Timer:
- """Record multiple running times."""
- def __init__(self):
- self.times = []
- self.start()
-
- def start(self):
- """Start the timer."""
- self.tik = time.time()
-
- def stop(self):
- """Stop the timer and record the time in a list."""
- self.times.append(time.time() - self.tik)
- return self.times[-1]
-
- def avg(self):
- """Return the average time."""
- return sum(self.times) / len(self.times)
-
- def sum(self):
- """Return the sum of time."""
- return sum(self.times)
-
- def cumsum(self):
- """Return the accumulated time."""
- return np.array(self.times).cumsum().tolist()
5.2 累加器
- class Accumulator:
- """For accumulating sums over `n` variables."""
- def __init__(self, n):
- self.data = [0.0] * n
-
- def add(self, *args):
- self.data = [a + float(b) for a, b in zip(self.data, args)]
-
- def reset(self):
- self.data = [0.0] * len(self.data)
-
- def __getitem__(self, idx):
- return self.data[idx]
累加器(Accumulator)类,用于累加 n 个变量的和。以下是该类的方法和属性:
-
__init__(self, n):类的构造函数,接受一个参数n,表示需要累加的变量的数量。在初始化时,会创建一个长度为n的列表self.data,用于存储累加的结果,初始值都设置为0.0。 -
add(self, *args):这个方法用于将传递给它的参数累加到self.data中。它接受任意数量的参数,并将每个参数的值与self.data中对应位置的值相加。这个方法的主要作用是将多个变量的值累加到self.data中。 -
reset(self):这个方法用于重置累加器,将self.data中所有的值都设置为0.0。这在开始新的累加计算时非常有用。 -
__getitem__(self, idx):这个方法用于通过索引idx获取累加器中对应位置的值。它返回self.data中索引为idx的值。
这个累加器的主要作用是方便地对多个变量进行累加操作,并且可以随时重置累加器的值。这在一些统计或累积计算中非常有用。通过不断调用 add 方法,可以将多个变量的值累加到累加器中,然后通过 __getitem__ 方法获取累加的结果。如果需要重新开始累加计算,可以调用 reset 方法将累加器的值重置为初始状态。
六 训练代码组合
- # 组合到一起
- def train(net, train_iter, vocab, lr, num_epochs, device, use_random_iter=False):
- loss = nn.CrossEntropyLoss()
- animator = dltools.Animator(xlabel='epoch', ylabel='perlexity', legend=['train'], xlim=[10, num_epochs])
-
- # 初始化
- if isinstance(net, nn.Module):
- updater = torch.optim.SGD(net.parameters(), lr)
- else:
- updater = lambda batch_size: dltools.sgd(net.params, lr, batch_size)
-
- pred = lambda prefix: predict(prefix, 50, net, vocab, device)
- # train and forecast
- for epoch in range(num_epochs):
- ppl, speed = train_epoch(net, train_iter, loss, updater, device, use_random_iter)
-
- if (epoch + 1) % 10 == 0:
- print(pred('time traveller'))
- animator.add(epoch + 1, [ppl])
- print(f'困惑度{ppl:.1f}, {speed: .1f} 词元/秒{str(device)}')
- print(pred('time traveller'))
- print(pred('traveller'))
定义了一个训练循环,用于训练循环神经网络(RNN)模型。以下是该代码的主要步骤和功能:
-
导入所需的库,包括 PyTorch 模块和自定义的 dltools 模块。
-
定义了一个损失函数
loss,使用交叉熵损失函数(nn.CrossEntropyLoss())。交叉熵常用于文本分类问题中。 -
创建了一个用于可视化训练过程的
animator对象。这个对象可以用来绘制训练过程中的损失曲线。 -
初始化模型参数更新器
updater。如果net是一个 PyTorch 模型(nn.Module类型),则使用随机梯度下降(SGD)优化器来更新模型参数。否则,使用自定义的梯度下降函数dltools.sgd来更新模型参数。 -
定义了一个函数
pred,用于生成给定前缀文本的预测结果。这个函数会调用predict函数来生成文本的预测。 -
进行训练循环,循环的次数为
num_epochs。在每个 epoch 中,调用train_epoch函数进行模型训练,并计算困惑度和训练速度。 -
如果当前 epoch 的序号(
epoch + 1)是 10 的倍数,就调用pred函数生成以 "time traveller" 为前缀的文本预测,并将困惑度添加到animator中以进行可视化。 -
输出当前 epoch 的困惑度、训练速度和设备信息。
-
最后,生成 "time traveller" 和 "traveller" 的文本预测并输出。
总的来说,这段代码实现了一个训练循环,用于训练 RNN 模型,并在训练过程中生成文本预测。同时,它还使用了自定义的 dltools 模块来管理训练过程和可视化。
6.1 实时画图工具
- class Animator:
- """For plotting data in animation."""
- def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
- ylim=None, xscale='linear', yscale='linear',
- fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
- figsize=(3.5, 2.5)):
- # Incrementally plot multiple lines
- if legend is None:
- legend = []
- dltools.use_svg_display()
- self.fig, self.axes = dltools.plt.subplots(nrows, ncols, figsize=figsize)
- if nrows * ncols == 1:
- self.axes = [self.axes,]
- # Use a lambda function to capture arguments
- self.config_axes = lambda: dltools.set_axes(self.axes[
- 0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
- self.X, self.Y, self.fmts = None, None, fmts
-
- def add(self, x, y):
- # Add multiple data points into the figure
- if not hasattr(y, "__len__"):
- y = [y]
- n = len(y)
- if not hasattr(x, "__len__"):
- x = [x] * n
- if not self.X:
- self.X = [[] for _ in range(n)]
- if not self.Y:
- self.Y = [[] for _ in range(n)]
- for i, (a, b) in enumerate(zip(x, y)):
- if a is not None and b is not None:
- self.X[i].append(a)
- self.Y[i].append(b)
- self.axes[0].cla()
- for x, y, fmt in zip(self.X, self.Y, self.fmts):
- self.axes[0].plot(x, y, fmt)
- self.config_axes()
- display.display(self.fig)
- display.clear_output(wait=True)
6.2 nn.CrossEntropyLoss
nn.CrossEntropyLoss() 是 PyTorch 中用于多类别分类问题的损失函数。在深度学习中,交叉熵损失函数通常用于衡量模型的输出与实际目标之间的差异,特别是在分类任务中。
具体来说,nn.CrossEntropyLoss() 针对多类别分类任务的损失计算如下:
假设有 C 个类别(类别的数量),对于每个样本,模型会输出一个包含 C 个元素的向量,每个元素代表该样本属于对应类别的概率得分。这个向量通常称为“logits”。
nn.CrossEntropyLoss()首先将模型的 logits 通过 softmax 函数转换为概率分布。softmax 函数将 logits 映射为一个概率分布,使得所有类别的概率之和为 1。- 接下来,它将实际的类别标签(ground truth)编码成一个 one-hot 向量,其中只有一个元素为 1,表示样本的真实类别。
- 最后,它计算模型输出的概率分布与实际类别的交叉熵,作为损失值。交叉熵越小,模型的预测越接近真实标签。
nn.CrossEntropyLoss() 的参数通常是模型的输出(logits)和实际的类别标签。在训练神经网络时,通过反向传播算法,优化器会调整模型的参数,使交叉熵损失最小化,从而提高模型的分类性能。
七 查看训练效果
- num_epochs, lr = 200, 0.01
- # 使用顺序抽样
- train(net, train_iter, vocab, lr, num_epochs, dltools.try_gpu())

good !

