
- 1openwrt rust环境安装_rust openwrt
- 2【数据结构(邓俊辉)学习笔记】向量06——位图
- 3【嵌入式AI开发】轻量化卷积神经网络Mnasnet(神经架构搜索)详解
- 4Python实现时间序列分析进行平稳性检验(ADF和KPSS)和差分去趋势(adfuller和kpss算法)项目实战_python adf检验
- 5【论文阅读】Image Super-Resolution with Non-Local Sparse Attention
- 6Django3+Vue3进行前后端开发环境搭建_vue3 django
- 7R语言使用git以及Rmarkdown_r安装git
- 8自然语言处理之准确率、召回率、F1理解_信息检索中,准确率和召回率分别考核什么?二者有什么制约关系?
- 9java面试(微服务)
- 10常见Linux操作系统SSH配置详解
从零开始 - 在Python中构建和训练生成对抗网络(GAN)模型
赞
踩
生成对抗网络(GANs)是一种强大的生成模型,可以合成新的逼真图像。通过完整的实现过程,读者将对GANs在幕后的工作原理有深刻的理解。本教程首先导入必要的库并加载将用于训练GAN的Fashion-MNIST数据集。然后,提供了构建GAN核心组件(生成器和判别器模型)的代码示例。接下来的部分解释了如何构建一个组合模型,该模型训练生成器以欺骗判别器,以及如何设计一个训练函数来优化对抗过程。
目录:
1. 导入库和下载数据集
2. 构建生成器模型
3. 构建判别器模型
4. 构建组合模型
5. 构建训练函数
6. 训练和观察结果
导入库和下载数据集
让我们首先导入本文中将使用的重要库:
- from __future__ import print_function, division
- from keras.datasets import fashion_mnist
- from keras.layers import Input, Dense, Reshape, Flatten, Dropout
- from keras.layers import BatchNormalization, Activation, ZeroPadding2D
- from keras.layers.advanced_activations import LeakyReLU
- from keras.layers.convolutional import UpSampling2D, Conv2D
- from keras.models import Sequential, Model
- from keras.optimizers import Adam
- import numpy as np
- import matplotlib.pyplot as plt
在本文中,您将在Fashion-MNIST数据集上训练DCGAN。Fashion-MNIST包含60,000个用于训练的灰度图像和一个包含10,000个图像的测试集。每个28×28的灰度图像与10个类别中的一个标签相关联。Fashion-MNIST旨在作为原始MNIST数据集的直接替代品,用于对比机器学习算法的性能。与三通道的彩色图像相比,灰度图像在一通道上训练卷积网络时需要更少的计算能力,这使您更容易在没有GPU的个人计算机上进行训练。

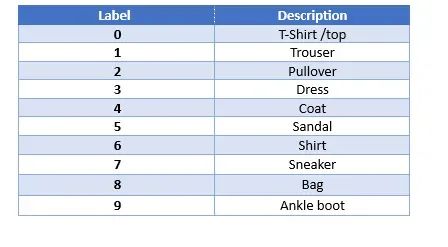
数据集分为10个时尚类别。类别标签如下:
您可以使用以下代码加载数据集:
- (training_data, _), (_, _) = fashion_mnist.load_data()
- X_train = training_data / 127.5 - 1.
- X_train = np.expand_dims(X_train, axis=3)
要可视化数据集中的图像,可以使用以下代码:
- def visualize_input(img, ax):
- ax.imshow(img, cmap='gray')
- width, height = img.shape
- thresh = img.max()/2.5
- for x in range(width):
- for y in range(height):
- ax.annotate(str(round(img[x][y],2)), xy=(y,x),
- horizontalalignment='center',
- verticalalignment='center',
- color='white' if img[x][y]<thresh else="" 'black')="" =""
- fig = plt.figure(figsize = (12,12))
- ax = fig.add_subplot(111)
- visualize_input(training_data[3343], ax)We also use batch normalization and a ReLU activation.
- For each of these layers, the general scheme is convolution ⇒ batch normalization
- ⇒ ReLU. We keep stacking up layers like this until we get the final transposed
- convolution layer with shape 28 × 28 × 1:


2. 构建生成器模型
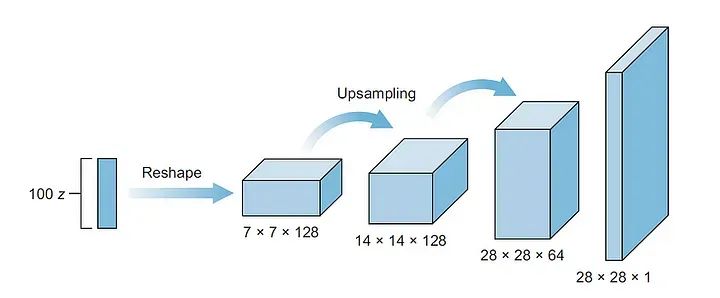
正如我们在前面的文章中所探讨的,GANs由两个主要组件组成,即生成器和判别器。在这一部分中,我们将构建生成器模型,其输入将是一个噪声向量(z)。生成器的架构如下图所示。
第一层是一个全连接层,然后被重新塑造成深而窄的层,在原始的DCGAN论文中,作者将输入重新塑造为4×4×1024。在这里,我们将使用7×7×128。然后,我们使用上采样层将特征映射的维度从7×7加倍到14×14,然后再次加倍到28×28。在这个网络中,我们使用了三个卷积层。我们还将使用批归一化和ReLU激活。
对于每个层,通用方案是卷积 ⇒ 批归一化 ⇒ ReLU。我们不断地堆叠这样的层,直到得到最终的转置卷积层,形状为28×28×1。
以下是构建上述生成器模型的Keras代码:
- def build_generator():
-
-
- generator = Sequential()
-
-
- generator.add(Dense(6272, activation="relu", input_dim=100)) # Add dense layer
- generator.add(Reshape((7, 7, 128))) # reshape the image
- generator.add(UpSampling2D()) # Upsampling layer to double the size of the image
- generator.add(Conv2D(128, kernel_size=3, padding="same", activation="relu"))
- generator.add(BatchNormalization(momentum=0.8))
- generator.add(UpSampling2D())
-
-
- # convolutional + batch normalization layers
- generator.add(Conv2D(64, kernel_size=3, padding="same", activation="relu"))
- generator.add(BatchNormalization(momentum=0.8))
-
-
- # convolutional layer with filters = 1
- generator.add(Conv2D(1, kernel_size=3, padding="same", activation="relu"))
- generator.summary() # prints the model summary
-
-
- """
- We don't add upsampling here because the image size of 28 × 28 is
- equal to the image size in the MNIST dataset.
- You can adjust this for your own problem.
- """
- noise = Input(shape=(100,))
- fake_image = generator(noise)
-
-
- # Returns a model that takes the noise vector as an input and outputs the fake image
- return Model(inputs=noise, outputs=fake_image)
3. 构建判别器模型
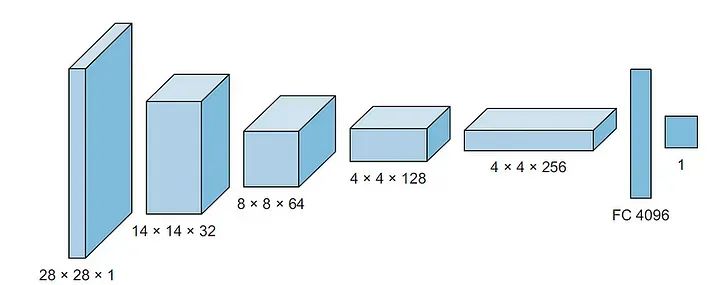
GANs的第二个主要组件是判别器。判别器只是一个传统的卷积分类器。判别器的输入是28×28×1的图像。我们希望有一些卷积层,然后是输出的全连接层。
与之前一样,我们希望得到一个Sigmoid输出,并且我们需要返回logits。对于卷积层的深度,我们可以从第一层开始使用32或64个过滤器,然后在添加层时将深度加倍。在这个实现中,我们将从64层开始,然后是128,然后是256。对于降采样,我们不使用池化层。相反,我们只使用步幅卷积层进行降采样,类似于Radford等人的实现。
我们还使用批归一化和dropout来优化训练。对于四个卷积层的每一层,通用方案是卷积 ⇒ 批归一化 ⇒ 泄漏的ReLU。
现在,让我们构建build_discriminator函数:
- def build_discriminator():
- discriminator = Sequential()
- discriminator.add(Conv2D(32, kernel_size=3, strides=2, input_shape=(28,28,1), padding="same"))
- discriminator.add(LeakyReLU(alpha=0.2))
- discriminator.add(Dropout(0.25))
-
- discriminator.add(Conv2D(64, kernel_size=3, strides=2,padding="same"))
- discriminator.add(ZeroPadding2D(padding=((0,1),(0,1))))
- discriminator.add(BatchNormalization(momentum=0.8))
-
- discriminator.add(LeakyReLU(alpha=0.2))
- discriminator.add(Dropout(0.25))
-
- discriminator.add(Conv2D(128, kernel_size=3, strides=2, padding="same"))
- discriminator.add(BatchNormalization(momentum=0.8))
- discriminator.add(LeakyReLU(alpha=0.2))
- discriminator.add(Dropout(0.25))
-
- discriminator.add(Conv2D(256, kernel_size=3, strides=1, padding="same"))
- discriminator.add(BatchNormalization(momentum=0.8))
- discriminator.add(LeakyReLU(alpha=0.2))
- discriminator.add(Dropout(0.25))
-
- discriminator.add(Flatten())
- discriminator.add(Dense(1, activation='sigmoid'))
-
- img = Input(shape=(28,28,1))
- probability = discriminator(img)
-
- return Model(inputs=img, outputs=probability)
4. 构建组合模型
正如本系列的第二篇文章中所解释的,为了训练生成器,我们需要构建一个包含生成器和判别器的组合网络。组合模型以噪声信号(z)作为输入,并将判别器的预测输出作为虚假或真实输出。
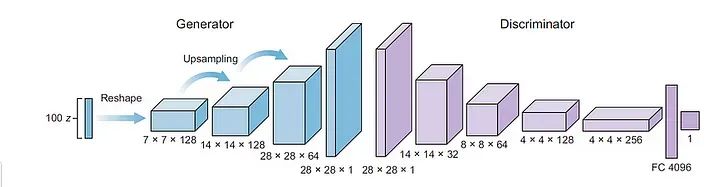
重要的是要记住,我们希望在组合模型中禁用判别器的训练,正如本系列的第二篇文章中所解释的那样。在训练生成器时,我们不希望判别器更新权重,但我们仍然希望将判别器模型包含在生成器训练中。因此,我们创建一个包含两个模型的组合网络,但在组合网络中冻结判别器模型的权重:
- optimizer = Adam(learning_rate=0.0002, beta_1=0.5)
- discriminator = build_discriminator()
- discriminator.compile(loss='binary_crossentropy', optimizer=optimizer, metrics=['accuracy'])
- discriminator.trainable = False
-
-
- # Build the generator
- generator = build_generator()
- z = Input(shape=(100,))
- img = generator(z)
- valid = discriminator(img)
- combined = Model(inputs=z, outputs=valid)
- combined.compile(loss='binary_crossentropy', optimizer=optimizer)
5. 构建训练函数
为了训练GAN模型,我们训练两个网络:判别器和我们在前面部分创建的组合网络。让我们构建train函数,该函数接受以下参数:
epoch
batch size 大小
save_interval,以指定多久保存一次结果
我们还将创建另一个函数`plot_generated_images()` 来绘制生成的图像。
- def plot_generated_images(epoch, generator, examples=100, dim=(10, 10),figsize=(10, 10)):
- noise = np.random.normal(0, 1, size=[examples, latent_dim])
- generated_images = generator.predict(noise)
- generated_images = generated_images.reshape(examples, 28, 28)
-
- plt.figure(figsize=figsize)
- for i in range(generated_images.shape[0]):
- plt.subplot(dim[0], dim[1], i+1)
- plt.imshow(generated_images[i], interpolation='nearest', cmap='gray_r')
- plt.axis('off')
-
- plt.tight_layout()
- plt.savefig('gan_generated_image_epoch_%d.png' % epoch
最后,让我们为训练GAN模型定义重要的变量和参数:
6. 训练和观察结果
此时,代码实现已经完成,我们准备开始DCGAN的训练。要训练模型,请运行以下代码行:
train(epochs=1000, batch_size=32, save_interval=50)这将在1,000个epochs上运行训练,并每50个epochs保存一次图像。当运行`train()` 函数时,训练进度将如下所示:
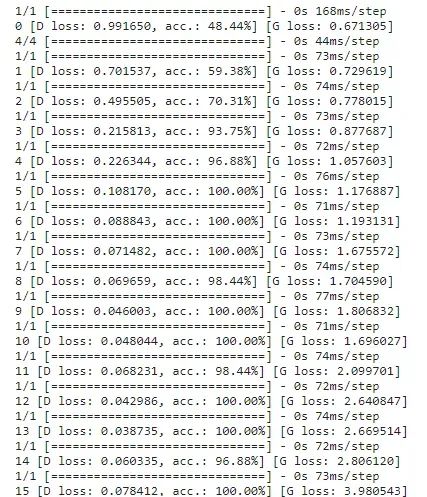
如下图所示,在epoch = 0时,图像只是随机噪声,没有明确的模式或有意义的数据。到了第50个epoch,图案已经开始形成。

在训练过程的后期,到了第1,000个epoch,您可以看到清晰的形状,可能能够猜测输入到GAN模型的训练数据的类型。

再快进到第10,000个epoch,您会发现生成器已经非常擅长重新创建训练数据集中不存在的新图像。

· END ·
HAPPY LIFE

本文仅供学习交流使用,如有侵权请联系作者删除

