
- 1人工智能在模拟空战中击落人类飞行员
- 2猿创征文|我的Python成长之路_python作文
- 3GPT-4完全破解版:用最新官方API微调,想干啥就干啥,网友怕了_gpi4
- 4基于单片机的危险气体远程检测报警系统设计
- 5CentOS7安装MySQL5.7过程以及常用需要修改操作,安装mysqlclient,安装mysql-devel报错问题以及卸载MySQL_docker centos7 mysql client dev
- 6学习笔记之——3DGS-SLAM系列代码解读_gs slam
- 7C#基础学习笔记_c#笔记
- 8期末考试查分,基于青果高校教务系统的一个自动python脚本代码。_大学期末查排名代码
- 9Tomcat 浅度解析_tomcat分析
- 10【Latex】添加删除线,高亮文本_latex 删除线
Spark相关知识点(期末复习集锦)_spark惰性机制名词解释
赞
踩
嗨喽,最近小伙伴们快要期末考试了吧,下面是我对《Spark零基础实战》的总结,希望能帮助到你们。
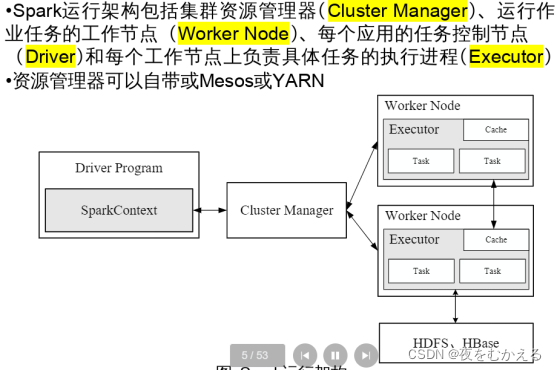
一、Spark简介
Spark,拥有hadoop MR所具有的优点,但不同于MR的是job中监测结果可以保存在内存中,从而不再需要读写HDFS,因此spark能够更好的适用于数据挖掘与机器学习等需要迭代的m r的算法。
1.Spark,使用scala语言实现,这是一种面向对象函数式编程语言,能够像操作本地集合对象一样轻松的操作分布式数据集
Spark,适用于多种分布式平台,如批处理,迭代算法,交互式查询流处理等
Spark,提供了丰富的接口,除了基于scala python Java和SQL等API外还内建了丰富的程序库
Spark,可以运行在hadoop集群中使用多种数据源
2.Spark 特点
①运行速度快,易用性好,通用性强和随处运行等特点
运行速度快:Spark,拥有DAG执行引擎,支持在内存中对数据进行迭代计算,通过DAG调度程序查询优化器和物理执行引擎,实现了批处理和流数据处理的高性能
易用性好:支持scala JAVA python等语言进行编写,还支持Sql查询
通用性强:Spark生态圈包含了丰富的组件,提供一站式解决平台
随处可运行:Spark具有很强的适应性,能够使用多种资源管理器来调度job
②什么是DAG?
DAG中文译名,有向无环图,DAG Scheduler 会根据RDD的transformation动作,将DAG分为不同的stage,每个stage中分为多个task,这些task可以并行运行。
Spark DAG解决了什么问题?
Spark引入DAG在内存中进行计算,并可以优化计算,比如减少shuffle数据的过程
3.Spark的计算模型
Spark的基本计算单元是RDD[弹性分布式数据集,是spark中最基本的数据抽象,它代表一个不可变(只读),可分区里面的元素可并行计算的集合]
RDD具有数据流模型的特点,自动容错,感知性调度和可伸缩性。
①弹性
存储的弹性,RDD数据可以在内存和磁盘之间进行自由切换
可靠性的弹性,RDD在丢失数据时能够自动恢复RDD在计算过程中会出现失败的情况,以后会进行一定次数的重试(四次)
并行度的弹性,RDD数据分区可以改变,进而增加并行计算的力度
②分布式,RDD的数据是分布式存储的,也就是说spark集群每个节点上只存储了RDD的部分数据
③数据集,是一个数据集(RDD是一个数据容器,跟array和list相似)
4.Rdd之间有两种不同类型的依赖关系,窄依赖和宽依赖
5.Spark与MR区别
spark个借鉴了MR的基础上发展而来,继承了MR分布式并行计算的优点,并改进了MR明显的缺陷
1)Spark把中间数据放到内存中,迭代运算效率高
2)Spark容错性高
3)Spark更加通用(Hadooo只提供了map和reduce两种操作,spark提供的数据集操作类型很多,分为transformations和actions,两大类。)
6.Spark streaming是spark提供的,对实时数据进行流式计算的组件
Spark submit/Spark Shell 批处理
Spark SQL 查询

7.Spark Core是spark框架最核心的部分.实现了spark的基本功能包括,任务调度,内存管理,错误恢复与存储系统交互模块
8.Rdd执行过程
Stage:作业调度的基本单位
1)Rdd读入外部数据源进行创建。
2)Rdd经过一系列的转换(transformation)操作,每次都会产生不同的rdd,供给下一个转换操作使用。
3)最后一个rdd,经过动作操作进行转换并输出到外部数据源
这一系列处理被称为lineage(血缘关系),即DAG拓扑排序的结果
9.RDD优点
惰性调用,管道化,避免同步等待,不需要保存中间结果,每次操作变得简单
10.RDD特性
1)高效的容错性
现有的容错机制,数据复制或者记录日志
Rdd:血缘关系,重新计算丢失分区,无需回滚系统,重算过程。在不同节点之间并行,只记录粒度的操作
2)中间结果持久化内存数据在内存中的多个rdd操作之间进行传递,避免了不必要的读写磁盘开销
3)存放的数据可以是JAVA对象,避免了不必要的对象序列化和反序列化
11.Rdd之间的依赖关系:
阶段的划分的依据-窄依赖和宽依赖
1)窄依赖表现为一个父的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区。(一对一,或者,多对一)
2)宽依赖者表现为存在一个父Rdd的一个分区,对应一个子Rdd的多个分区(一对多)
宽依赖无法优化
//重点
窄依赖的函数map filter union mapPartitions
宽依赖的函数groupByKey, partitionBy
12.RDD计算过程
1) 创建RDD对象
2)SparkContext负责计算rdd之间的依赖关系,构建dag .
3)DAGScheduler负责把dag图分解成多个stage,每个stage包含了多个task,每个task会被TaskScheduler分发给WorkNode上的executor.
13.Spark运行模式
一、单机模式:
本地模式:spark单机运行,一般用开发测试
二、伪分布式模式
Standalone模式:构建一个由master+slave构成的spark集群,spark运行在集群中
//master,client和worker节点
//如果是用spark-shell交互式工具提交job 在master上运行
//如果使用spark-submit提交 在本地client上运行
三、分布式模式
Spark on yarn模式:spark客户端直接连到yarn.不需要额外构建spark集群
Spark on mesos模式:spark客户端直接连接到mesos,不需要额外构建spark集群
⭐⭐
Spark On YARN模式的搭建比较简单,仅需要在YARN集群的一个节点上安装Spark即可,该节点可作为提交Spark应用程序到YARN集群的客户端。
Spark本身的Master节点和Worker节点不需要启动。
Spark on yarn模式有client和cluster两种模式,主要区别在于:
Driver程序的运行节点不同。
client:Driver程序运行在客户端,适用于交互、调试,希望立即看到运行的输出结果。
Cluster:Driver程序运行在由RM(ResourceManager)启动的AM(AplicationMaster) 上, 适用于生产环境。
14.Spark on yarn 运行原理以及搭建过程
YARN-Cluster(yarn-Standalone)和YARN-Client模式的区别本质上就是application master进程的区别
Yarn- cluster模式下,driver运行在application master中,他负责向yarn申请资源并监督作业的运行情况,当用户提交了作业之后,就可以关掉client.作业会继续在yarn上运行,因而yarn-cluster模式不适合运行交互类型的作业。
Yarn-client模式下,application master仅仅向yarn请求executor ,client会和请求的container通信来调度他们工作,也就是说client不能离开

二、Scala语言
1.Scala简介
1)Scala运行JAVA虚拟机JVM之上,并且兼容现有的JAVA程序
2)scala是纯粹的面向对象的语言
3)scala也是一门函数式语言
4)声明值和变量
val:不可变,类似java的final
var:可变的,即可以再次给赋值
any:变量类型,类似java的object
5)标识符:区分大小写
6)不能使用关键字作为变量
7)Scala类似JAVA支持单行或多行注释
8)Unit表示无值,和其他语言中的void等同,用作不返回任何结果的方法的结果类型,unit只有一个实例值写成()
9)Any,所有其他类的超类
Nothing.,任何其他类型的子类型
10)数据类型转换
name.toDouble
name.doubuleValue
Integer.valueof(name)
String.V alueOf(name)
11)Scala的变量可以有三个不同的范围,具体取决于他们被使用的位置
①字段,字段是属于对象的变量(var或者val)
②方法参数,方法参数是在调用该方法时用的方法中的值的变量(val)
③局部变量,局部变量是在方法中声明的变量(var或者val)
2.函数与方法
1)Scala方法是类的一部分,而函数是一个对象可以赋值给一个变量。
换句话来说,类中定义的函数即是方法
2)方法转换为函数:
用下划线“_”进行转换,语法:方法名_
3)函数参数
3.Scala集合
1)数组 2)List序列 3)元组 4)set集合 5)Map映射
Scala 的集合有三大类:
序列 Seq(有序的, Linear Seq) 集 Set 映射 Map【key->value】
我们一般可以根据集合所在的包名进行区分:
scala.collection.immutable
scala.collection.mutable
scala 默认采用不可变集合,对于几乎所有的集合类,Scala 都同时提供了可变(mutable)和不可变(immutable) 的版本。可变数组
4.基本语法
1)不可变数组
var/val 变量名 = new Array[元素类型](数组长度)
var/val 变量名 = Array(元素 1,元素 2,......)
可变数组
var/val 变量名 = new ArrayBuffer[元素类型](数组长度)
var/val 变量名 = ArrayBuffer(元素 1,元素 2,......)
2)列表(List)是 Scala 中最重要的, 也是最常用的一种数据结构。
特点是: 有序, 可重复。
不可变list
val/var 变量名 = List(元素 1, 元素 2, 元素 3...)
可变list
val/var 变量名 = ListBuffer[数据类型]()
val/var 变量名 = ListBuffer(元素 1,元素 2,元素 3...)
toList 将可变列表(ListBuffer)转换为不可变列表(List)
toArray 将可变列表(ListBuffer)转换为数组
3)与列表一样,元组也是不可变的,但与列表不同的是元组可以包含不同类型的元素。
元组的长度和元素都是不可变的
val/var 元组名= (元素 1,元素 2,元素 3...)
val/var 元组名 = 元素1->元素2 只能用于两个元素
4)映射就是 Map,由键值对(key, value)组成的集合。任何值都可以根据键来进行检索。键在映射中是唯一的,但值不一定是唯一的。映射也称为哈希表。
特点: 键具有唯一性, 但是值可以重复.
Map 也分为不可变 Map 和可变 Map。
val/var map = Map(键->值, 键->值, 键->值...)
val/var map = Map((键, 值), (键, 值), (键, 值), (键, 值)...)
与不可变一样,可变需要导包
5.类和对象
scala中有一个简洁的初始化成员变量的方法,用“_”来初始化成员变量(就是相当于空值)int:0 String :null
6.构造器
当创建对象的时候,会自动调用类的构造器,之前使用的都是默认构造器
主构造器,辅助构造器
语法
Class 类名 (var /val 参数名: String = a,var/val参数名:参数类型=b){
//构造代码块
}
在主构造器的参数中,没有被任何关键字修饰的参数,会被标注为private[this]
把除了主构造器之外的构造器称为辅助构造器
def this(参数名:类型,参数名:类型){
//调用主构造器
//构造器代码
}
7.伴生对象
定义:一个class和object具有同样的名字。这个object称为伴生对象,这个class称为伴生类
特点:
伴生对象必须和伴生类一样的名字
伴生对象和伴生类在同一个scala源文件中
伴生对象和伴生类可以互相访问private属性
如果某个成员权限设置为private[this],表示只能在当前类中访问。伴生对象也不可以访问。
8.在Scala中,创建对象,实现免new动作
通过伴生对象的apply方法实现
Object 伴生对象名字{
def apply(参数名:参数类型,参数名:参数类型)=new 类(....)
}
Val 对象名 = 伴生对象名(参数1,参数2....)
Scala中可以使用extends关键字来实现继承
A类:子类,派生类
B类:父类,超类,基类
9.子类中出现和父类一模一样的方法,称为方法重写.
1)scala代码中可以在子类中使用override来重写父类的成员,也可以使用super来引用父类的成员
2)可以使用override来重写一个val字段
3)父类用var修饰的变量,子类不能重写,这是因为在子类中重写父类的变量,编译器会将其视为新的变量,而不是原来的父类变量
10.类型判断
val trueorfalse:Boolean=对象.isInstanceOf[类型] //判断对象是否为指定类的对象
val 变量=对象.asInstanceOf[类型]
11.在scala中,样例类是一种特殊类,一般是用于保存数据的,类似于JAVA的pojo类,在并发编程以及spark flink这些框架中都会经常使用它
语法:
case class 样例类名([var/val]成员变量名1:类型1,成员变量名:类型2,成员变量名3:类型3){}
样例类中的默认方法
Apply()方法 toString()方法 Equals()方法 Copy()方法

用case修饰的单例对象就叫样例对象,而且它没有主构造器
case object样例对象名
1)当做枚举值时,用枚举就是一些固定值用来统一项目规范的。
2)作为没有任何参数的消息传递
12.Trait特征相当于java的接口,实际上它比接口还功能强大,与接口不同的是,它还可以定义属性和方法的实现。一般情况下,scala类只能继承单一父类,但如果是trait特征的话,就可以继承多个。从结果来看,就是实现了多重继承scala将多个类的相同特征从类中剥离出来,形成一个独立的语法结构,称之为trait特征特质。Scala采用特殊的关键字trait来声明特质,如果一个类符合某一个特征,那么就可以将特质混入到类中。
With+特质
extends+类
三、RDD创建
1.Rdd创建
1)从文件系统中加载数据创建rdd
sc.textFile(URL)
//分布式文件系统地址
//本地文件系统地址(json文件读取)
2)通过并行集合(数组,列表)创建rdd
sc.parallelize(array)
3)直接通过 makeRDD方法创建
(Scala 读取JSON格式数据时,JSON.parseFull(jsonString:String)函数,以一个JSON字符 串作为输入并进行解析,如果解析成功则返回一个 Some(map: Map[String, Any]),如果解析失败则返回None )
1.以下哪些方法可以用于生成一个RDD?
A、从分布式文件系统中加载数据创建RDD
B、通过并行集合(数组)创建RDD
C、直接通过makeRDD方法创建
D、通过对一个或多个已有RDD进行转换操作,产生新的RDD
2.Rdd操作
1.转换操作

Map和FlashMap的区别

2、行动操作

3.惰性机制
所谓的惰性机制,是指整个转换过程中只是记录了转换的轨迹,并不会真正的计算,只有遇到行动操作时才会触发从头到尾的真正计算。
RDD采用惰性机制
可以通过持久化缓存机制,避免这种重复计算的开销可以使用persist()方法,对一个RDD标记为持久化。之所以说标记为持久化,是因为出现persist()语句的地方并不会马上计算生成RDD,并把它持久化,而是要等到遇到第一个行动操作,触发真正计算以后,才会把计算结果进行持久化,持久化的RDD将会保留在计算节点的内存中后,被后面的行动操作重复使用。
4.Persist( )参数
Memory _only
表示将rdd作为反序列化的对象,存储于JVM中,如果内存不足,就要按照LRU原则替换缓存中的内容
Memory _and _disk表示,将rd d作为反序列化的对象,存储于JVM中,如果内存不足,超出的区域将会被存放在磁盘上。一般而言,使用cache()方法时会调用persist(memory_ only),可以使用unpersist()方法手动的把持久化RDD从缓存中移除
5.RDD通常很大,所以要进行分区
分区的作用:增加并行度 减少通信开销
6.RDD分区原则
Rdd分区的一个原则是指分区的个数尽量等于集群中CPU核心数目,当分区数等于核心数时,可以更好的利用集群中所有的CPU资源,实现最大程度的并行计算,从而提高程序的执行效率。
对于不同的spark部署模式而言,都可以采用spark .default .parallelism这个参数的值来配置默认的分区数目。
一般而言
本地模式:默认本地机器的CPU数目,若设置了local [N],则默认为N
Apache Mesos:默认的分区数为8
Standalone或yarn:在"集群中CPU核心数目总和"和“2”中取较大值作为默认值
AMP Lab大数据分析负载分为三大类型:批量数据处理,交互式查询,实时流处理
7.Spark SQL
1)Spark SQL是Apache Spark的用于处理结构化数据的模块
2)Spark SQL的性能优化
内存列存储,字节码生成技术 scala代码优化
8.Spark SQL提供了一种特殊的RDD,叫做SchemaRDD(存放row对象的RDD),每个row对象代表一行记录。SchemaRDD还包含记录的结构信息(数据字段)。SchemaRDD看起来和普通的RDD很像,但是内部SchemaRDD可以利用结构信息更加高效的存储数据。
在spark2.0中DataFrame和DataSet都是基于SchemaRDD优化而来的
9.从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代 Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载、转 换、处理等功能。
10.Spark SQL 提供了两种主要的编程抽象,类似 Spark Core 中的 RDD。
四、问答题以及重要编程
1. DataFrame 2. DataSet
Spark Sql的特点
1. Integrated( 易 整 合 )
无缝的整合了 SQL 查询和 Spark 编程。
2. Hive Integration( 集 成 Hive)
在已有的仓库上直接运行 SQL 或者 HiveQL
3.Standard Connectivity( 标 准 的 连 接 方 式 )
通过 JDBC 或者 ODBC 来连接。
什么是DataFrame
与 RDD 类似,DataFrame 也是一个分布式数据容器。
然而 DataFrame 更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即 schema。
什么是DataSet
1. 是 DataFrame API 的一个扩展,是 SparkSQL 最新的数据抽象(1.6 新增)。
2. 用户友好的 API 风格,既具有类型安全检查,也具有 DataFrame 的查询优化特性。
3. Dataset 支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提高了效率。
4. 样例类被用来在 DataSet 中定义数据的结构信息,样例类中每个属性的名称直接映射到 DataSet 中的字 段名称。
5. DataFrame 是 DataSet 的特例, DataFrame=DataSet[Row],所以可以通过 as 方法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些的类型一样,所有的表结构信息都用 Row 来表示。
6. DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person].
SparkSession 内部封装了 SparkContext,所以计算实际上是由 SparkContext 完成的。
学习DataFrame进行编程
有了 SparkSession 之后,通过 SparkSession 有 3 种方式来创建 DataFrame:
Ø 通过 Spark 的数据源创建;
Ø 通过已知的 RDD 来创建;
Ø 通过查询一个 Hive 表来创建。
在 Spark 中,DataFrame 是一种强类型的数据结构,它由行和列组成。每一列都有一个名称和一个数据类型。
Rdd和DataFrame的交互
从 RDD 到 DataFrame
1、通过样例类进行转换
2.通过Schema进行转换
package com.qst.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* RDD 转换 DataFrame
* 1. 通过样例类进行转换
* 2.通过 Schema 进行转换
*/
object SparkSQLDemo03 {
// 样例类
case class Person(id: Int, name: String, age: Int)
def main(args: Array[String]): Unit = {
// 准备工作:创建 SparkSession
val spark =
SparkSession.builder().appName(this.getClass.getName).master("local[*]").getO
rCreate()
val sc = spark.sparkContext
sc.setLogLevel("WARN")
// 1. 通过样例类进行转换
val linesRDD = sc.textFile("file/person.txt")
// 1.1. RDD[String] 变为 RDD[Person]
val personRDD: RDD[Person] = linesRDD.map(x => {
val arr = x.split(",")
Person(arr(0).toInt, arr(1), arr(2).toInt)
})
import spark.implicits._ // 隐式转换
// 1.2. RDD+样例类 => DataFrame
val personDF: DataFrame = personRDD.toDF()
val personDS: Dataset[Person] = personRDD.toDS()
personDF.show()
personDS.show()
println("--------------------------------------------------------")
// 2. 通过 Schema 进行转换
// 2.1 定义一个 Schema,创建 StructType 类型
val schema = StructType(
List(StructField("id", IntegerType, false),
StructField("name", StringType, false),
StructField("age", IntegerType, false))
)
// 2.2 映射出来一个 RDD[Row],因为 DataFrame 其实就是 Dataset[Row]
val rddRow: RDD[Row] = linesRDD.map(line => {
val arr = line.split(",")
Row(arr(0).toInt, arr(1), arr(2).toInt)
})
// 2.3 通过 schema+rddRow=> DataFrame
val pDF: DataFrame = spark.createDataFrame(rddRow, schema)
pDF.show()
// 关闭
spark.stop()
}
}
从 DataFrame 到 RDD
直接调用 DataFrame 的 rdd 方法就完成了从转换
val rdd = pDF.rdd
println(rdd)
println(rdd.collect())
// 关闭
spark.stop()
}
}
DataSet 和 RDD 类似, 但是 DataSet 没有使用 Java 序列化,而是使用一种专门的编码器去序列化对象, 然后在网络上处理或者传输。
DataSet 是具有强类型的数据集合,需要提供对应的类型信息。
在后期的 Spark 版本中,DataSet 会逐步取代 RDD 和 DataFrame 成为唯一的 API 接口。
三者的共性
1. RDD、DataFrame、Dataset 全都是 Spark 平台下的分布式弹性数据集, 为处理超大型数据提供便利
2. 三者都有惰性机制,在进行创建、转换,如 map 方法时,不会立即执行, 只有在遇到 Action 如 foreach 时,三者才会开始遍历运算。
3. 三者都会根据 Spark 的内存情况自动缓存运算,不用担心会内存溢出。
4. 三者都有 partition 的概念
5. 三者有许多共同的函数,如 map, filter,排序等
6. 在对 DataFrame 和 Dataset 进行操作许多操作都需要这个包进行支持 import spark.implicits._
三者的区别
1.与 RDD 和 Dataset 不同,DataFrame 每一行的类型固定为 Row,每一列的值没法直接访问,只有通过 解析才能获取各个字段的值,
2. DataFrame 与 DataSet 均支持 SparkSQL 的操作,比如 select,groupby 之类,还能注册临时表/视窗, 进行 sql 语句操作;
3. Dataset 和 DataFrame 拥有完全相同的成员函数,区别只是每一行的数据类型不同。 DataFrame 其实就是 DataSet 的一个特例
4. DataFrame 也可以叫 Dataset[Row],每一行的类型是 Row,DataFrame 可以被看做是一组按照特定顺 序排列的 Row 对象集合,每个 Row 对象都对应一行数据记录,包含多个字段(
column)。而 Dataset 是在 DataFrame 的基础上,为了提高类型安全性而引入的概念,它将每一行看做是一个特定类型的对象,而不是简单 的 Row 对象。因此,在 Dataset 中,每一行都是一个特定的 Case Class,行中的各个字段按照 Case Class 中 定义的类型来定义,这使得我们可以更加自由地获取每行的信息以及进行类型安全的操作。


Spark-shell本身就是一个driver,里面已经包含了main方法
Spark-shell命令及其常用的参数如下:
./bin/spark-shell--master<master-url>
Spark的运行模式取决于传递给spark context的master URL的值
Master URL可以是以下任意一种形式:
本地部署
1)local使用一个worker线程本地化运行spark(完全不并行)
2)local[*]使用逻辑CPU个数数量的线程来本地化运行spark
3) local[ k]使用k个worker线程本地化运行spark(理想情况下k应该根据运行机器的CPU核数设定
集群部署:
1)Spark ://host: port连接到指定的spark standalone master。默认端口是7077
yarn-client以客户端模式连接yarn集群,集群位置可在hadoop_ config_ dir环境变量中找到
yar n-cluster以集群模式连接yarn集群,集群位置可在haoop_ conf_ dir环境变量中找到。
2)mesos ://HOST:PORT连接到指定的mesos集群,默认接口是5050。
Spark中采用本地模式启动spark shell的命令,主要包含以下参数
master这个参数,表示当前的spark shell要连接哪个master,如果是local[*],就是使用本地模式启动spark-shell,其中中括号内的星号表示需要使用几个CPU,也就是启动几个线程模拟
spark集群
--jars:这个参数,用于把相关的jar包添加到CLASSPATH中,如果有多个jar包可以使用逗号分隔符连接它们。
./bin/spark - shell --master local[4]
./bin/spark - shell --master local[4] --jars code.jar
./bin/spark - shell --help
------------------------------------------------------------------------
类相关代码
- object AnimalExpDemo {
-
- // 1、定义动物父级抽象类
- abstract class Animal {
- var name: String = ""
- var age: Int = 0
- var sex: Boolean = true // true表示boy,false表示girl
-
- // 定义行为吃饭和跑步
- // 吃饭的方法需要子类根据具体吃的食物来实现
- def eat()
-
- // 跑步方法为公共的,所有动物都会跑步
- def run(): Unit = {
- println(s"Animal 姓名:$name 年龄:$age 性别:$sex is running")
- }
- }
-
- // 2、定义一个老虎的类继承Animal,实现吃饭eat方法,并且根据特有的行为定义捕食方法predation
- class Tiger extends Animal {
- // 重写吃饭的方法
- override def eat(): Unit = {
- println("Tiger 姓名:" + name + " 年龄:" + age + " 性别:" + sex + " 吃肉")
- }
-
- // 特有捕食行为predation
- def predation() = {
- println("Tiger 姓名:" + name + " 年龄:" + age + " 性别:" + sex + " 捕食猎物")
- }
- }
-
- // 3、定义兔子Rabbit类,重写eat方法,实现特有行为做窝makeNest
- class Rabbit(tname: String, tage: Int, tsex: Boolean) extends Animal {
- name = tname
- age = tage
- sex = tsex
-
- override def eat(): Unit = {
- println("Rabbit"
- + " 姓名:" + name
- + " 年龄:" + age
- + " 性别:" + sex
- + " 吃胡萝卜")
- }
-
- // 特殊行为方法做窝
- def makeNest(): Unit = {
- println("Rabbit 姓名:" + name + " 年龄:" + age + " 性别:" + sex + " 做一个小窝,给自己睡觉")
- }
- }
-
- def main(args: Array[String]): Unit = {
- // 创建老虎对象
- val t1: Animal = new Tiger
- t1.name = "老虎"
- t1.age = 3
- t1.sex = true
- // 调用老虎吃饭方法
- t1.eat()
- // 调用老虎奔跑方法
- t1.run()
- //t1.predation()
-
- println("_____________________________________________________")
- val r1: Animal = new Rabbit("兔子", 2, false)
- r1.eat()
- r1.run()
- //r1.makeNest()
-
- println("_____________________________________________________")
- // 4. 通过类型的判断来确定调用哪个方法,老虎的话调用老虎特有的方法,兔子调用特有的方法
- if (t1.isInstanceOf[Tiger]) {
- // 由于t1是Tiger类型的,则将其强制转换为Tiger
- val t2 = t1.asInstanceOf[Tiger]
- t2.predation()
- }
-
- if (r1.getClass == classOf[Rabbit]) {
- val r2 = r1.asInstanceOf[Rabbit]
- r2.makeNest()
- }
- }
- }


