
- 1linux 操作系统root账号被锁定的两种解决方法_root账号被锁定了怎么办
- 2php github源码,PHP源码已迁移至GitHub
- 3Presto 中 lookUp Join的实现_presto getoutputcalls
- 4程序设计语言基础知识【软考】
- 5Git | Git基本命令
- 6链表刷题集
- 7FOREIGN KEY 约束_constraint `fk2ueej4xaluv4gr1ynq3l8ymqi` foreign k
- 8交换机与AI的连接:构建未来智能网络的关键路径_交换机对人工智能的意义有哪些
- 9python自然语言处理 第一章答案_python自然语言处理答案
- 10ACWING 799. 最长连续不重复子序列 (入门) (双指针算法)
大模型(LLM)推理加速之KV Cache技术_kv cache可以加速多少
赞
踩
前言
在学习Key-Value Cache(kv cache),读者需要熟悉Transformer架构,最好能够懂得分析transformer模型的参数量、计算量、中间激活、KV cache。本文不会再对Transformer架构做赘述。
KV cache原理
在如GPT等大模型的推理当中,一次推理只生成一个token,输出的token会与输入tokens拼接在一起,作为下一次推理的输入,每个token都需要依赖之前生成的token,这个重要的特性就是自回归性(autoregressive)。
然而随着推理的进行,输入的tokens会越变越长,导致推理FLOPs(计算量,如果读过前言中的那篇文章,可以知道推理的
F
L
O
P
s
=
2
∗
模型参数量
∗
t
o
k
e
n
数)
FLOPs = 2 * 模型参数量 * token数)
FLOPs=2∗模型参数量∗token数)随之增大。这会严重影响推理的速度。
由于在推理过程中,第
i
i
i次注意力的计算都会重复计算前
i
−
1
i-1
i−1个token的
K
K
K和
V
V
V值,故KV Cache的出发点就在这里,缓存当前轮可重复利用的
K
K
K和
V
V
V值,下一轮计算时直接读取缓存结果。
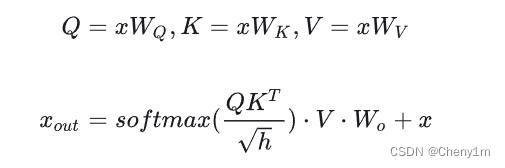
具体细节
- 原来的推理过程:假设输入是 [ b , s , h ] [b,s,h] [b,s,h](batchsize,seqencelen,hidden), K , Q , V K,Q,V K,Q,V矩阵是 [ h , h ] [h,h] [h,h],那么每次的计算结果就 [ b , s , h ] [b,s,h] [b,s,h]
- 使用KV cache: 每次输出不再 C o n c a t Concat Concat给之前的输出(因为每次计算依据缓存过之前token的 K , V K,V K,V值),所以输入是 [ b , 1 , h ] [b,1,h] [b,1,h],那么每次计算结果就是 [ b , 1 , h ] [b,1,h] [b,1,h],在此刻再与之前已经计算过的shape为 [ b , s − 1 , h ] [b,s-1,h] [b,s−1,h]的 K , V K,V K,V值分别进行 C o n c a t Concat Concat即可得到与原来推理过程相同的结果。但是每次没有重复计算前 i − 1 i-1 i−1个token的 K K K和 V V V值,减少了推理计算量,提升了推理速度。
更多
如果还有细节理解不到位的地方可以参考大模型推理性能优化之KV Cache解读

