
- 1直接拿来用!最火的Android开源项目(三)(完结篇)_求android 简单项目所有完整源代码,要能够直接导入adt中使用的
- 2西红柿叶病害检测(yolov8模型,从图像、视频和摄像头三种路径识别检测,包含登陆页面、注册页面和检测页面)
- 3数据结构与算法导论---通讯录的实现_数据结构与算法实训通讯录代码总结
- 4vivo刷入鸿蒙,vivo鸿蒙系统刷机包
- 5非技术面试题_java非技术面试题
- 6100天精通Go语言(精品VIP版)专栏简介
- 7区块链的前世今生:走向高可靠企业应用
- 8动态规划之背包问题(java)全面总结_java 背包问题解析
- 9如何解决由于动态数据导致el-select下拉组件无法回显数据的问题_el-select动态添加的options如何回显
- 10玩转Mysql 五(MySQL索引)
使用tkinter制作一个仿数据库查询工具系统_python制作mysql数据库搜索工具
赞
踩
使用tkinter制作一个仿数据库查询工具系统
前言:
最近在使用可视化窗口操作数据库,读取数据信息。使用过程非常有感觉,而又想到python里面也有可视化的模块可供使用,这里就简单的运用tkinter设计一款数据库查询系统,并做一些自定义按键的设置。
/ 操作平台、模块及数据库
-
windows 10
-
python 3.7
-
numpy 1.22.2
-
pandas 1.4.1
-
PyYAML 6.0
-
sqlalchemy 1.3.13
-
mysql-connector 8.0.28
-
mysql 8.0.18
/ 简介
对于python还不够了解,tkinter也只是略有熟悉,设计过程中有部分难点,通过网上查找资料能一一解决,暂时设计出一个可以简单使用的查询系统,设计过程中暂时只运用到Mysql数据库,后续如学习使用其他数据库会整理相关代码以补充系统的数据库支持,数据展示部分设计来源pandastable模块,系统对该模块的代码有大量的删减,仅保留需求部分代码,如需学习可自行安装(pip install pandastable)调试使用。
系统主窗口页面:
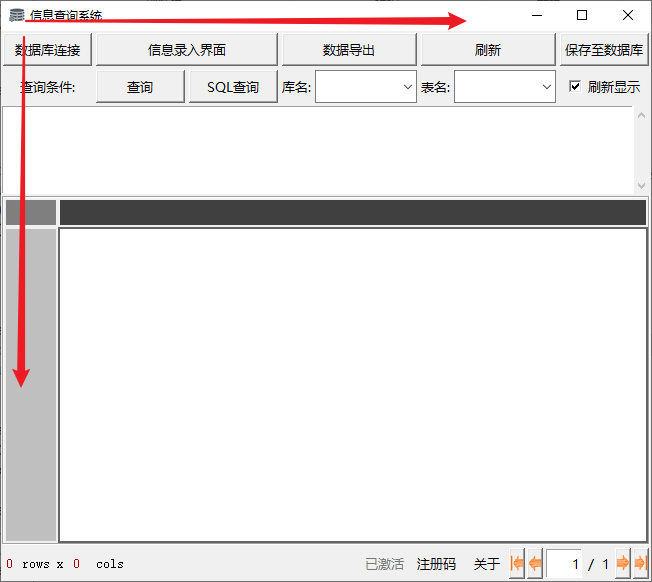
/ UI界面代码设置
听说有利用拖拽的方式完成框架设置,没有留心太多,干脆直接用代码硬砸,整个框架设计也简单,三个主体部分,每个主体内部再划分区域设置其他部件。
即:
-
主体部件一:
各类实体按键和复选框,文本数据框,见主窗口页面内上半部分。
-
主体部件二:
查询数据显示区域,见中间部分
-
主体部件三:
数据框显示附加显示及翻页按键,见页面最下层部分
功能键设置:
from tkinter import * from tkinter.scrolledtext import ScrolledText from tkinter.ttk import Combobox # 定义窗口 root = Tk() # 窗口大小 w = 600 h = 300 # 窗口居中 ws, hs = root.maxsize() x = (ws - w) // 2 y = (hs - h) // 2 root.geometry(f'{w}x{h}+{x}+{y}') # 设置按键 text = '按键' button = Button(root, text=text) # button.bind(func=function) button.grid(row=0, column=0) # 设置复选框 combobox = Combobox(root) combobox.grid(row=1, column=0) # chk.bind("<<ComboboxSelected>>", function) # 复选框事件绑定 # 设置标签 text = '标签' label = Label(root, text=text) label.grid(row=2, column=0) # 滚动文本框设置 text = '滚动文本框' s_txt = ScrolledText(root) s_txt.insert(INSERT, text) s_txt.grid(row=3, column=0) # 输入框设置 text = '输入框设置' textvariable = StringVar() entry = Entry(root, textvariable=textvariable) textvariable.set(text) entry.grid(row=4, column=0) # 窗口显示 root.mainloop()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
该工具系统通过上述几种部件设置组合而成,部分按键会开启子窗口,可以通过实例化或继承tk.Toplevel顶级窗口部件设置。
class SubFrame(tk.Toplevel):
"""子窗口设置"""
def __init__(self):
super().__init__(master)
- 1
- 2
- 3
- 4
- 5
这样就会使窗口呈现在屏幕上了,之后可以定义功能函数,绑定按键,通过按键交互数据库查询,数据筛选及文件导入导出。
/ 数据库连接
目前使用mysql数据库比较多,这里这是以mysql为例使用sqlalchemy连接数据库,前文也有提到过sqlalchemy的一些方法使用sqlalchemy模块获取数据库已有表的表名及字段名
# 数据库连接部分 from sqlalchemy import create_engine, inspect, MetaData, and_ from sqlalchemy.orm import sessionmaker # 定义一个数据库连接的类 class MysqlCON: def __init__(self, ip, port, root, pwd): super().__init__() self.root = root self.pwd = pwd self.ip = ip self.port = port # 实例化session self.session = sessionmaker()() self.metadata = MetaData() # 使用mysql+mysqlconnector作为连接器 self.mysql_dburl = f'mysql+mysqlconnector://{root}:{pwd}@{ip}:{port}' def connect_mysql(self): """连接数据库,返回数据库下的各个库名""" mysql_db = create_engine(self.mysql_dburl, pool_recycle=7200) try: # 通过映射关系,返回数据库结构 insp = inspect(mysql_db) except Exception as e: return str(e) self.session = sessionmaker(mysql_db)() self.metadata = MetaData(mysql_db) return insp.get_schema_names()_names() def get_tables(self, schema): """传入数据库名,返回该数据库下的所有数据表名""" if not self.metadata.is_bound(): return self.metadata.clear() self.metadata.reflect(schema=schema) self.table_dict = {i.name: i for i in self.metadata.tables.values()} return list(self.table_dict.keys()) ......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
关于数据库连接的详细代码可向作者索取。
/ 数据导入导出
通过读取数据库数据,可以简单的使用数据导出按键将数据导出,如需从数据文件中添加数据可以通过信息录入界面进入子窗口,导入所选数据文件,读取及保存模块均基于pandas实现,支持类型包含:xls, xlsx, pickle, csv, json, html, feather。
class ... def save(self, filename): """保存数据至文件夹中""" ftype = Path(filename).suffix if ftype == '.pkl' or ftype == '.pickle': self.df.to_pickle(filename) elif '.xls' in ftype: self.df.to_excel(filename) elif ftype == '.csv': self.df.to_csv(filename) elif ftype == '.json': self.df.to_json(filename) elif ftype == '.html': self.df.to_html(filename) elif ftype == '.feather': self.df.to_feather(filename) else: self.df.to_csv(filename) return def load(self, filename, filetype=None): """从文件夹中读取数据文件""" if filetype == '.pkl' or filetype == '.pickle': self.df = pd.read_pickle(filename) elif '.xls' in filetype: self.df = pd.read_excel(filename, sheet_name=0) elif filetype == '.csv': self.df = pd.read_csv(filename) elif filetype == '.json': self.df = pd.read_json(filename) elif filetype == '.html': self.df = pd.read_html(filename) elif filetype == '.feather': self.df = pd.read_feather(filename) # print (len(self.df)) elif filetype in self.filetype_read.keys(): self.df = eval(f'pd.{self.filetype_read.get(filetype)}({filename})') else: messagebox.showwarning("该文件暂不支持读取", "该文件暂不支持读取") return
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
数据展示将会随数据表的选择和导入窗口的变化而变化,注意到在界面右上部分有刷新显示的复选按键,如取消勾选,则任何操作不会影响数据展示部分的数据显示。
/ 数据查询
该系统支持pandas.filter和SQL查询方式,前者是对已显示在数据框内数据进行筛选,后者是通过sql语句查询数据库后再返回至数据展示窗口,更新数据显示,两者实现逻辑略有不同。
- 普通查询方式,即使用第一种方式查询:
如有pandas使用经验,可按自己习惯编写,建议按下述方式在查询文本框编写查询方式:
以:(列名 判断方式 判断条件)构造查询语句,建议每个条件都用括号()分隔开,用&和|连接,分别代表”并且,或者“,示例:(A == 1) & (B == ‘apple’),会筛选出当A列等于1并且B列等于’apple’的数据。
- SQL查询
如有sql查询使用经验,可在下方查询文本框编写sql查询语句,点击SQL查询按键,会从数据库按照sql语句查询相应数据,并呈现在展示框处,目前仅支持查询操作。
可在界面下方的关于获取系统的版本信息及使用简要方法。
软件获取方式:
该系统采用软件免费试用,如需激活可联系作者免费激活永久使用,源码付费的形式分享。
软件下载链接可转:
或者
/ 总结
本篇介绍设计的仿数据库查询系统,以及部分功能的代码实现,总体功能上肯定不如现有的数据查询软件完善,界面也没有很美观,但只要敢尝试,有什么事情是做不成的呢,这里也没有什么高深的技术,一步一步尝试,就可以走到终点。
晓看天色暮看云,哪还有什么不值当的,欢喜处处。
于二零二二年四月十一日作
