
- 1RK3399linux交叉编辑器下载,ubuntu下交叉编译X264和FFMPEG到RK3399平台(编译器:aarch64-linux-gcc)...
- 2人工智能为什么可以准确回答问题而不依赖数据库呢?_机器人对答是数据库
- 3有哪些好用不火的软件?_实验楼怎么样csdn
- 4PolarDB 卷来卷去 云原生低延迟强一致性读 1 (SCC READ 译 )
- 5FLASH问题答疑
- 6基于GPT-3.5的AI机器人:源码与脚本详解大数据任务提交和执行_ai3.5在线机器人
- 7无人机摄影测量数据处理、三维建模及在土方量计算中的应用_像空点
- 8【gitlab部署】centos8安装gitlab(搭建属于自己的代码服务器)
- 9【MySQL精通之路】全文搜索-布尔型全文搜索
- 10物联网主干组网之全IP光网络_光传输组网原理
【数据结构初阶】复杂链表复制+带头双向循环链表+缓存级知识_数据结构 拷贝链表
赞
踩
我们下面的讲解顺序是先给大家将最后一道链表题,本题难度较大,所以在大家还没看困的基础下,我们先讲解一下这道题目。然后博主在详细得用图文方式给大家讲一下链表的另一经典结构:带头双向循环链表。最后我们利用一小段时间再给大家补充一下缓存级部分的知识,由于偏硬件,仅供了解即可。
OK,前言完毕,开始学习的脚步吧!!!
一、复杂链表复制

首先这道题我们应该如何去做呢?
我们从题中可以看出,其实有些问题我们是很好解决的,比如我开辟个结点出来,然后让这个结点中的value等于题目所给链表中的value,这个操作我们通过一个while循环就可以解决了,然后就是我们的next指针,这个也非常简单,因为我们每次只能开辟一个结点出来,所以我们需要while循环的方式来处理这种未知结点个数的情况。
补充知识点:已知循环次数用for循环,未知循环次数用while循环,我们后面的OJ题还是用while循环比较多
链接起来我们的copy结点其实也是比较简单的,我们先把copy结点连接到原链表上,然后再把copy结点拿下来尾插到一个新的链表上去。如图所示
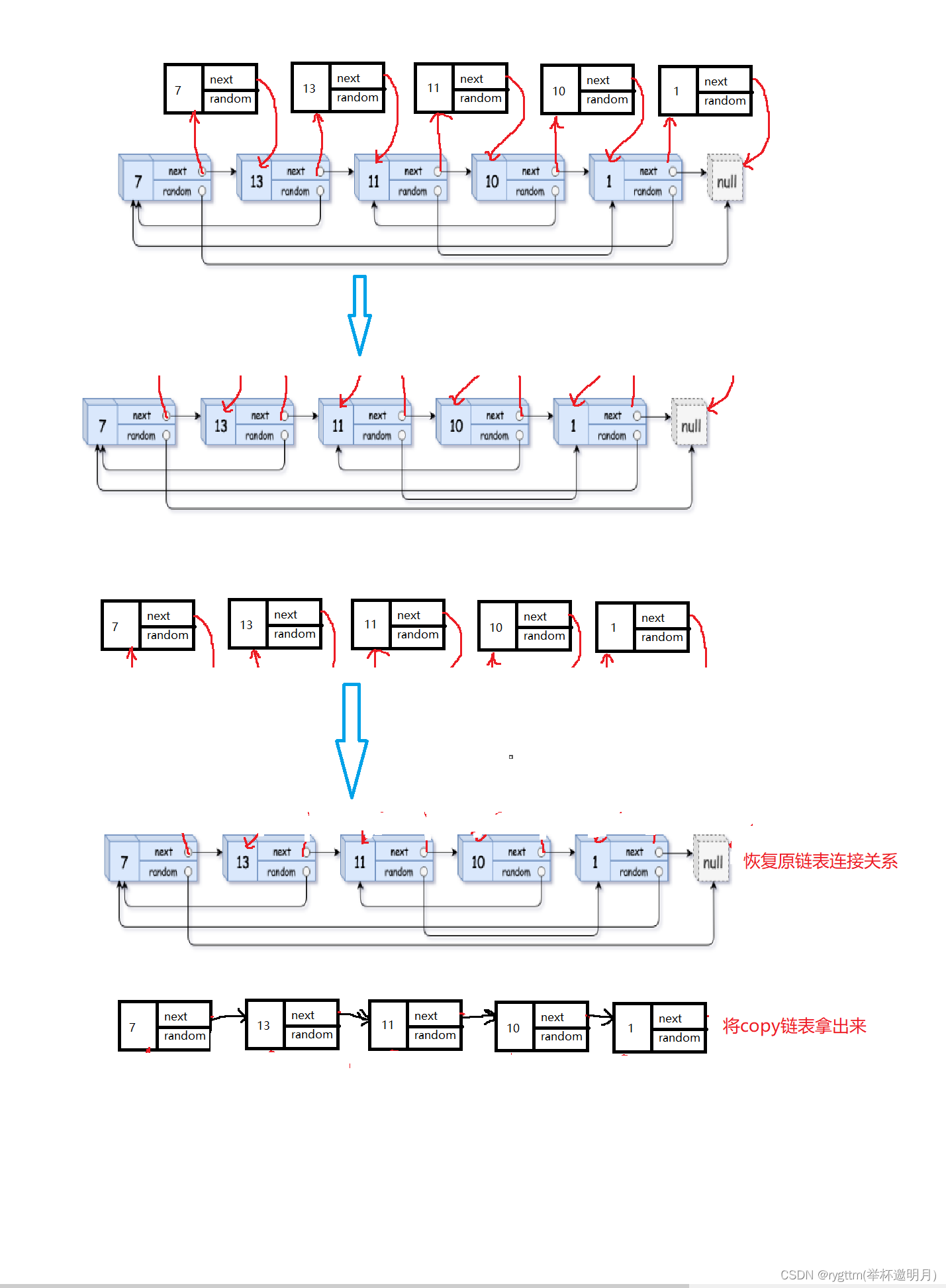
然后我们的copy工作已经完成一半了,但其实最主要的问题我们是比较难搞的,就是这个random指针,我们如何copy啊?
但其实这个问题也是比较简单的,从我们最开始copy结点后的链接方式,是可以看出一点猫腻的
是什么猫腻呢?由于我们copy结点后,将其链接到原链表的每个结点后面了,这个位置的关系我们其实可以好好利用一下。
我们其实也可以观察到,其实我们想要处理第一个结点的random的话,我们是想要找到在这些copy的结点里面,我们的第一个结点的random应该指向谁,通过图像我们可以看出,我们可以通过原链表中结点的random的next找到copy结点中的random,
这是为什么呢?其实也很好理解,由于我们的每个结点后面的copy结点和他的value值是一模一样的,就相当于原链表的random的后面跟了个影子,我们如果想要链接copy链表中的random的话,通过他的真正结点的random的next就可以找到random应该链接的结点了。
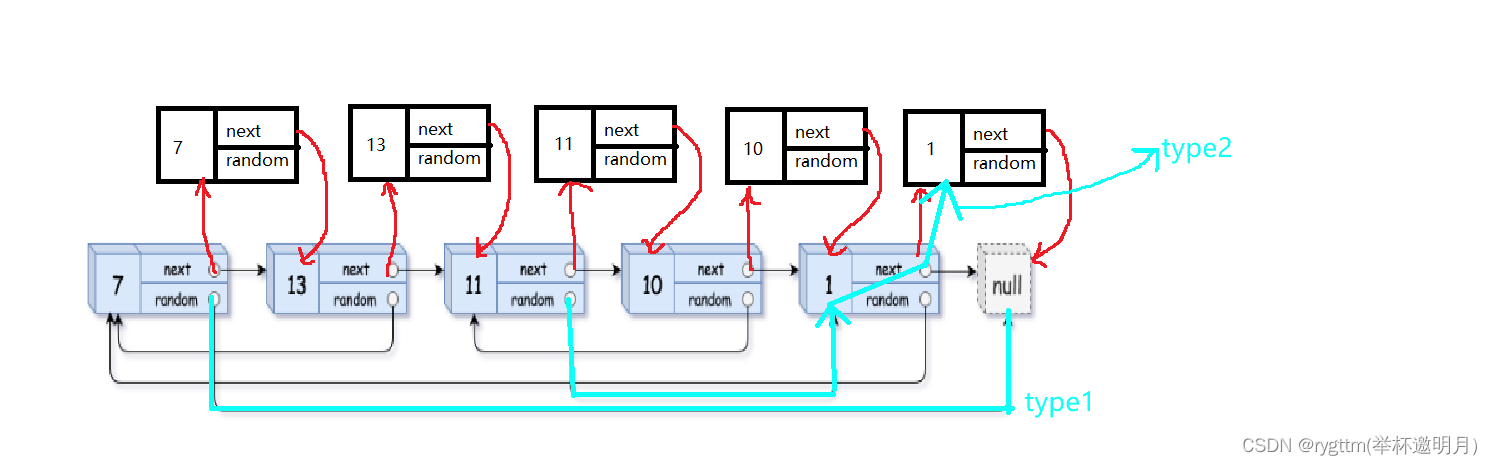
在找到这样的关系之后,我们将copy链表中的所有指针指向都画出来,然后再去思考下一步怎么做。
再得到上图所示得链接关系之后,我们其实可以发现,现在我们只要将copy链表拿下来,将其链接成一个链表,然后把这个新链表得头结点的地址返回就可以了。
那我们怎么样把上面链表中的copy结点拿下来呢?这不就回到了我们的链表OJ题了么?还记不记得我们上篇博客中的第一道链表OJ题,删除链表中值为value的元素,我们当时不就是使用尾插法将我们不想要的结点给过滤出去了。
那个题和现在这个步骤的处理思想不也是一致的吗?我们现在是想把原链表中的结点过滤出去,自然也使用尾插法了,又回到老样子了,害害害!
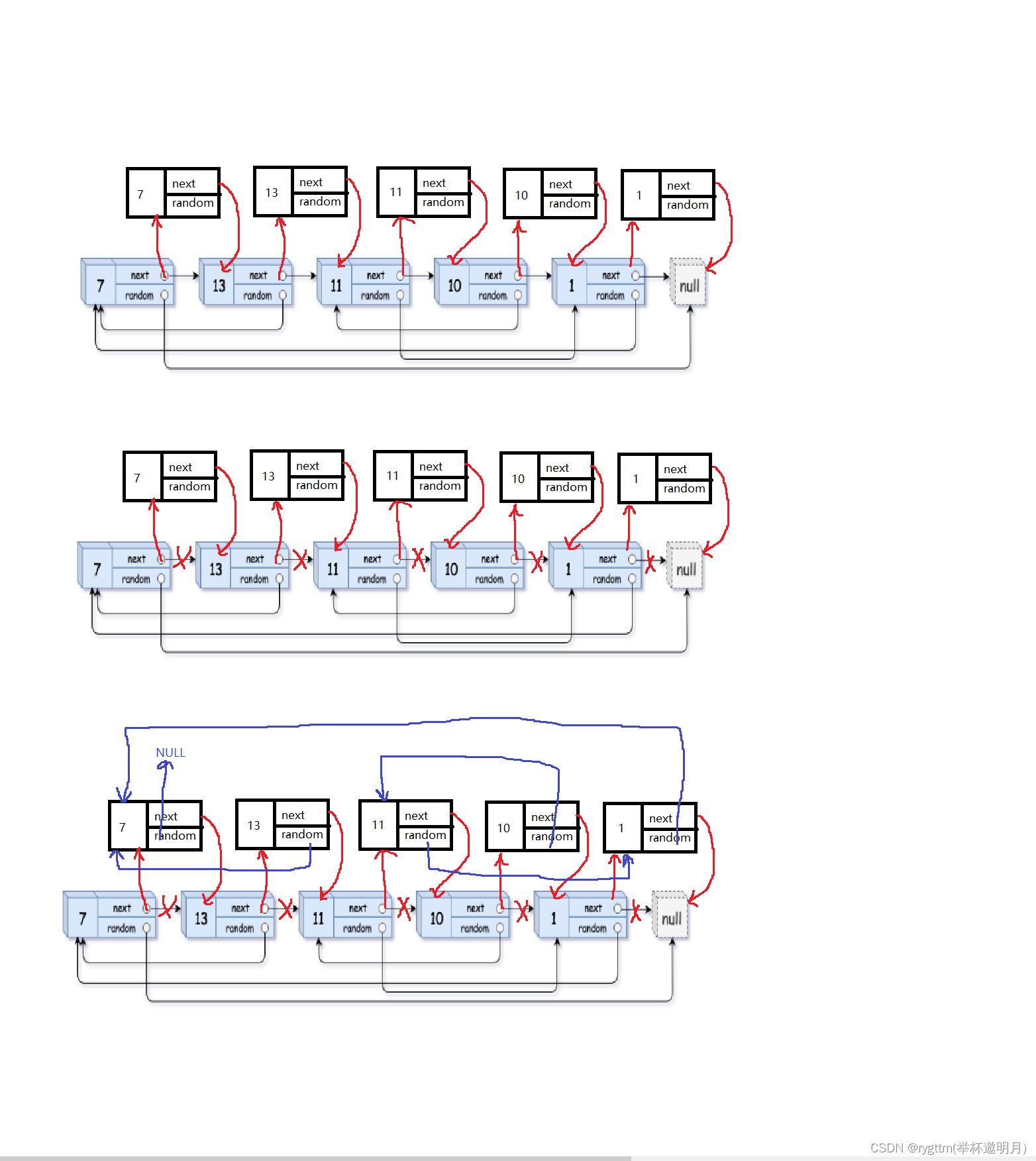
尾插法的应用我们回顾一下,为了不让我们的newhead多次向后移动和代码的命名风格良好,我们这里定义两个变量,一个指向我们的copy链表的头,一个随着我们的尾插结点个数的增多向后挪动的newtail指针,通过这两个指针,我们就可以完美解决尾插法这一步骤了。
下面是尾插法的使用形式,我们将其抽离出来,给大家看一下如何实现。 需要注意的是,不要忘记随着尾插的移动我们的newtail也得往后移动,否则谁来访问尾结点的next呢? struct Node*newhead=NULL,*newtail=NULL; cur=head; while(cur) { struct Node*copyHead=cur->next; struct Node*next=copyHead->next; cur->next=next; if(newhead==NULL) { newhead=newtail=copyHead; } else { newtail->next=copyHead; newtail=copyHead; } cur=next; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
struct Node* copyRandomList(struct Node* head) { //1.拷贝结点,链接到原链表结点后面 //2.处理我们拷贝结点的random指针 //3.将我们的拷贝结点链接成一个新的链表,再将原链表恢复 struct Node*cur=head; while(cur) { struct Node*next=cur->next; struct Node*newnode=(struct Node*)malloc(sizeof(struct Node)); newnode->val=cur->val; cur->next=newnode; newnode->next=next; cur=next; } cur=head; while(cur) { struct Node*copyHead=cur->next; struct Node*next=copyHead->next; if(cur->random==NULL) { copyHead->random=NULL; } else { copyHead->random=cur->random->next; } cur=next; } //我们利用尾插将拷贝结点链接到新链表上去。 struct Node*newhead=NULL,*newtail=NULL; cur=head; while(cur) { struct Node*copyHead=cur->next; struct Node*next=copyHead->next; cur->next=next; if(newhead==NULL) { newhead=newtail=copyHead; } else { newtail->next=copyHead; newtail=copyHead; } cur=next; } return newhead; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
再说一下,写代码中具体的几个细节,防止大家实现不出来这道题
细节1: 我们是不清楚题目给我们提供的结点个数的,所以我们无法确切的使用malloc,开辟出来与题目所给链表结点相同的结点个数,这时就需要我们的while循环登场了,while循环就是专门用来处理未知循环次数的循环的,通过一个条件来控制我们的循环次数
细节2: 当我们尾插时,其实需要那么一个current指针来随着我们的链表长度增加,使其始终指向我们链表的尾结点,所以在实现抽离新链表时使用尾插,不要忘记将newtail向后移动,否则你会一直将newtail后面的结点改个不停,不断的进行赋值操作,而不是将我们的结点给链接起来,让其变成一个新的copy链表。
细节3: 我们在解决copy结点的random指向时,其实存在一个不易察觉的问题,如果我不说,感觉大家很容易踩坑,这个坑就是那个分支语句的操作。
我们试想一下,如果我们通过实现random那个逻辑去走一下的话,是无法处理原链表结点random指向NULL这样的情况的,因为我们如果通过random->next的话,其实是对空指针访问,这样就会造成访问权限冲突的问题,所以我们需要将这样的一种特殊情况单独抽离出来,单独对其进行判断。如果原结点的random指向NULL,我们让copy的random也指向NULL就好了。
The essential detail: 我们在插入copy结点,改变random,改变next这些操作中,我其实定义了很多的变量,可能有人会觉得,我不定义那么多变量也OK啊,完全可以实现和你一样的功能,但我们要明白一个点,我们的代码不仅仅是写给自己看的,可能有那么一天,你会重新回头来看自己的代码,你希望你回头看的时候,是一下就明白自己写的是什么,还是希望你抓狂的思考,不知道random的next的next是谁好啊。
所以我么们应该多定义几个变量,不要怕占用空间嘛,这几个小小的变量能占用多少空间啊,如果为了节省空间少定义变量的话,真是太得不偿失了,如果面试官看到你的代码,半天看不明白,你觉得他是什么想法,你的命名风格还乱,你觉得它又是什么想法?
所以少年,好好写代码,写的既清晰又能看懂那才是好代码,不是你的代码越少,省略的越多,读起来晦涩难懂就是高级代码,根本不是这样子的。
二、带头双向循环链表的实现
2.1 简单介绍一哈
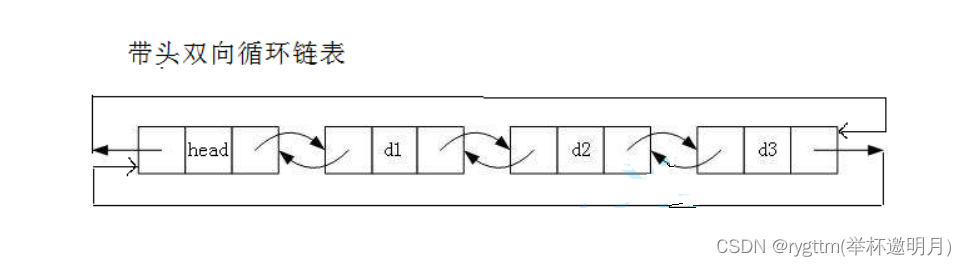
我们的带头双向循环链表和无头单向非循环链表是链表结构中最经典的两个结构,实现起来和结构复杂度分别是top1,什么意思呢?
就是我们的无头单向非循环链表结构看起来简单,实现起来还是相对复杂的,因为我们总是得根据链表中结点的个数来分情况讨论我们的接口具体如何实现,而且由于其结构的缺点,也让我们不少的结构实现起来较为繁琐。
但下面讲解的这个链表其实就是结构看起来较为复杂,但在我们实现接口功能的时候,其结构的优势还是给我们带来非常大的好处的。并且在实际应用层面,我们的带头双向循环链表是非常实用的。
但我们不能不学单链表啊,正因为其有结构上的缺陷,才更容易被面试官拿来考察我们,所以我们要好好学这两个经典的不能再经典的结构,后者就是已经不能再优化的结构了,没有之一。
2.2 结构的定义+链表初始化
typedef int LTDataType;
typedef struct ListNode
{
LTDataType data;
struct ListNode* next;
struct ListNode* prev;
}LTNode;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
因为我们的链表是双向且循环的,所以我们的结点需要两个指针,我们给出的结构体定义应该是有data next prev等类型的数据,包含两个指针和一个变量(存数据)。
LTNode* ListInit()//我们这里的phead是plist的拷贝值
{
//哨兵卫头结点
LTNode*phead = (LTNode*)malloc(sizeof(LTNode));
//我们刚开始初始化时,让phead的next和prev都指向他自己
phead->next = phead;
phead->prev = phead;
return phead;//我们这里不再实用二级指针处理,用返回值的方式将拷贝值带出函数接口
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
由于我们的链表是带有哨兵卫的头结点的,所以我们在初始化时,要开辟一个专属于哨兵卫结点的空间,让我们的plist指针指向这个结点,后续将我们的数据链接到哨兵卫后面就好了。
当然,由于链表此时只有一个哨兵卫结点,所以我们的prev和next指针都是指向它自己的,这个应该是比较好理解的吧。
另外这里再讲一下我们这个接口返回类型的设计,可以看到我们后面的大部分接口都是void型的,这里却用了一个指针类型,其原因就是我们想改变头结点地址,也就是开辟一个结点空间将这个空间的地址给到我们的plist,我们可以通过二级指针和返回值带出接口这两种方式来解决这个问题,但为了保证接口函数的参数一致性,我们采用返回值的方式来处理。
2.3 开辟结点空间+头插+尾插+头删+尾删+链表打印
LTNode* BuyListNode(LTDataType x)
{
LTNode* newnode = (LTNode*)malloc(sizeof(LTNode));
newnode->data = x;
newnode->next = NULL;
newnode->prev = NULL;
return newnode;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由于我们在头插,尾插,pos之前位置插入等接口里面总是要进行结点空间的开辟,所以我们将这一功能单独抽离出来,让其形成一个接口,在我们后续操作数据的接口中直接对其进行调用即可,又方便又省事的,还能防止我们的代码出现冗余的情况。
void ListPushFront(LTNode* phead, LTDataType x) { assert(phead); /*LTNode* newnode = BuyListNode(x); LTNode* next = phead->next; newnode->next = next; newnode->prev = phead; phead->next = newnode; next->prev = newnode;*/ //如果是空链表,我们的逻辑依然没有问题 ListInsert(phead->next, x); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
头插就是在我们哨兵卫结点的后面插入一个结点,此接口的实现在链接层面其实是需要4行代码的,也就是四个步骤。我们可以想一下,如果我们上来就讲结点头插到哨兵卫结点的后面,那是不是就破坏了哨兵卫和它原来后面那个结点的关系了,这样我们就找不到那个结点了,所以我们实用bext指针存一下哨兵卫后面结点的地址。
接下来的操作就简单了,我们只要将涉及到的四个指针的连接关系改一下就好了。
关键地方在于定义一个指针存一下head后面的结点地址,不过这个关键地方我们在单链表实现的时候,就已经见过这种操作并且将其实现,所以还是很简单的。
至于为什么贴的接口实现代码被屏蔽掉,我们这里留一个彩蛋,后面揭晓
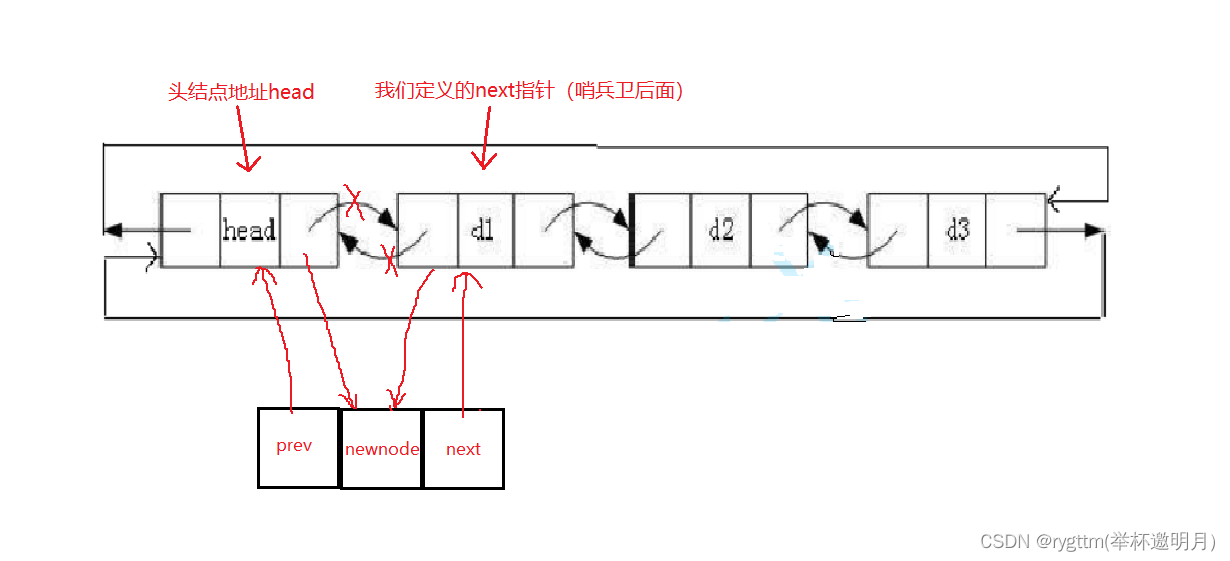
void ListPushBack(LTNode* phead, LTDataType x) { //因为我们不存在改变哨兵卫结点地址的操作,所以这里不需要使用二级指针。 //如果在单链表种你确定你不更改头结点地址的话,那你也不需要使用二级指针了,但可惜你一定会更改的,所以你必须使用二级指针 //你不会改变plist的话,那你也就不需要二级指针 //我们之前实现单链表的代码中,如果你不想使用二级指针,那么你其实可以通过返回值的方式将我们的头结点拷贝值带出函数的, //但这么做其实是非常奇怪的,你调用pushback一下,还得用plist接收一下,这太奇怪了 assert(phead);//链表一定是不为空的,因为有哨兵卫的头结点存在,就算你把结点删完了,也不能为空 //LTNode* tail = phead->prev; //LTNode* newnode = BuyListNode(x); //newnode->data = x; phead tail newnode -位置关系 先将tail和newnode链接起来 //tail->next = newnode; //newnode->prev = tail; 再将newnode和phead连接起来 //phead->prev = newnode; //newnode->next = phead; //这样链表结构下的尾插,我们根本不用考虑当链表为空和链表不为空这样的情况 //我们现有的逻辑结构就可以同时涵盖这两种情况的处理了 ListInsert(phead, x); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
尾插也是很简单的,尾其实就是在phead的prev位置,所以我们还是老套路,四句代码搞定尾插。
就是改变一下指针的指向关系而已,还是很简单的。
void ListPopFront(LTNode* phead)
{
assert(phead);
assert(phead->next != phead);//链表为空,不要再删了
//LTNode* next = phead->next;
//LTNode* nextNext = next->next;//不要觉得少了几个变量,你的代码就高级了,多定义点,理解起来干净利落
//phead->next = nextNext;
//nextNext->prev = phead;
//free(next);
ListErase(phead->next);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们注意一下,在free掉首结点空间之前,应该通过指针存储地址的方式,将我们的链接关系改好,然后再free掉首结点的空间。
void ListPopBack(LTNode* phead) { assert(phead); assert(phead->next!=phead);//链表就剩一个头结点了,不能删了 /*phead->prev = phead->prev->prev; free(phead->prev->next); phead->prev->next = phead;*/ //也可以这样写,多定义几个变量 /*LTNode* tail = phead->prev; LTNode* tailPrev = tail->prev; phead->prev = tailPrev; tailPrev->next = phead; free(tail);*/ ListErase(phead->prev); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
道理都一样,四句代码搞定尾删,不讲了,
void ListPrint(LTNode* phead)
{
assert(phead);
LTNode* cur = phead->next;
while (cur != phead)
{
printf("%d ", cur->data);
cur = cur->next;
}
printf("\n");
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
打印的话,我们只要遍历整个链表的结点,将每个结点的data打印出来就好了。
2.4 结点查找+pos之前插入+pos位置删除
LTNode* ListFind(LTNode* phead, LTDataType x)
{
//链表的结点访问需要进行链表结点的遍历,而顺序表的元素访问支持下标访问,我们无需遍历元素,通过下标就可快速找到对应元素
assert(phead);
LTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
在结点查找方面,其实就能体现出来链表与顺序表相比的缺陷。我们的顺序表通过你传的下标便可以直接访问到对应的元素,但链表的结构是无法这么做的,因为它不支持随机访问,这也是链表比较大的一个缺陷,这个缺陷也导致了很多的算法无法在链表这种结构下实行。
话说回来,我们的查找其实需要将我们的链表整体都遍历一遍,比较其中是否有结点等于我们的x,如果等于我们返回这个结点的地址,如果遍历结束之后还是找不到data与x相等的结点,我们就返回一个NULL
//pos位置之前插入 void ListInsert(LTNode* pos, LTDataType x)//真牛逼呢,卧槽,这接口太强了,我靠 //这个接口很大的一个优势在于,当pos位置=phead时就是尾插,当pos位置=phead下一个结点就是头插 { assert(pos); LTNode* posPrev = pos->prev; LTNode* newnode = BuyListNode(x); //位置关系 posPrev newnode pos posPrev->next = newnode; newnode->prev = posPrev; newnode->next = pos; pos->prev = newnode; //我们定义了一个指针,就省去了不少脑力判断的麻烦,如果没有指针,我们还不能上来就改变pos和newnode的关系, //因为这样很可能导致我们无法找到pos前面的结点位置了,所以,大兄弟,多定义几个变量吧,又不是定义变量跟你要钱呢。 }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
首先我们还是开辟一个newnode的空间,目的是将其插入到我们的pos地址前,在使用这个接口时,建议配合ListFind使用,一个负责找出x结点的地址,一个负责在x结点前插入数据,当然也可以配合ListErase一起使用,用于删除某位置的结点。
我们用一个指针记录一下pos前一个结点的地址,然后再4行代码,改变指针连接方向,将我们的newnode插入到pos位置的前面。简单吧!和单链表的实现相比,确实要容易一些。
//pos位置删除
void ListErase(LTNode* pos)
{
assert(pos);
LTNode* posPrev = pos->prev;
LTNode* posNext = pos->next;
posPrev->next = posNext;
posNext->prev = posPrev;
free(pos);
pos = NULL;//这句代码没什么意义,因为置空的是pos地址的拷贝值,对形参的修改并不会影响函数外面的实参。
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
要想删除pos位置的结点,我们应该需要两个指针来保存pos前后两个结点的地址,然后使这两个结点互相连接起来,最后将pos位置的空间free掉,这样就完成哦我们的pos位置删除的接口了。
值得注意的是,释放空间之后,将指针置为空是一个好习惯,也是一种好的代码风格,我们应该提倡,这样做可以防止他人误用掉我们释放空间后的地址,调试时更容易观察出问题。
因为我们的free不会讲指针自动置为空的,所以我们要手动置为NULL。
揭晓彩蛋:我们的尾插尾删头插头删等接口的功能其实完全可以用ListInsert和ListErase来代替,因为头插就是在pos=phead->next->next位置插入,尾插就是在pos=phead位置插入,头删就是在pos=phead->next位置删除,尾删就是在pos=phead->prev位置删除。(这里的等号不是赋值啊,就是单纯的相等,别理解错了,友友们)
2.5 链表空间释放
void ListDestroy(LTNode* phead)
{
LTNode* cur = phead;
while (cur != phead)
{
LTNode* next = cur->next;
free(cur);
cur = next;
}
free(phead);
phead = NULL;//这句代码是没有任何意义的,因为我们置空的是头结点地址的拷贝值,对函数外面真正的形参完全不起任何作用。
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这里的释放又面对了一个多次重复的问题,就是释放cur空间之后,找不到cur后面的结点了,所以还是老样子,定义一个next指针存放cur后面结点的地址。
值得注意的是,我们这里对phead的置空操作不起作用,因为plist不会受到影响,所以在调用这个接口之后,我们应该手动讲plist置空,如下面的测试接口代码所示(应该叫测试文件)
void TestList3() { LTNode* plist = ListInit(); ListPushBack(plist, 1); ListPushBack(plist, 2); ListPushBack(plist, 3); ListPushBack(plist, 4); ListPrint(plist); ListPopBack(plist); ListPopFront(plist); ListPrint(plist); ListDestroy(plist); plist = NULL;//看这里 } int main() { //TestList1(); //TestList2(); TestList3(); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
三、顺序表和链表对比
顺序表和链表其实各有优势,很难说谁的结构更好,他们其实是相辅相成的一种结构
我们下面所谈的链表默认为带头双向循环链表
顺序表的优点:
(1)支持随机访问
(2)CPU高速缓存命中率高
顺序表的缺点:
(1)在中间位置对数据插入删除的时候效率低。每一次的时间复杂度都是O(N)。
(2)由于其所在空间为连续的物理地址空间,我们需要不停的对其扩容以便增加数据的存储,扩容就面临一次扩容多少的问题,为了避免频繁的扩容,我们采取按照倍数去扩容的原则,但这就会造成空间浪费的问题。
链表的优点:
(1)任意位置插入和删除数据效率低
(2)空间按需申请,不存在空间浪费的问题
链表的缺点:
(1)不支持随机访问(下标访问),这就会导致很多算法无法在这样的结构上实现,例如排序、二分查找
(2)CPU高速缓存命中率低
四、缓存级知识
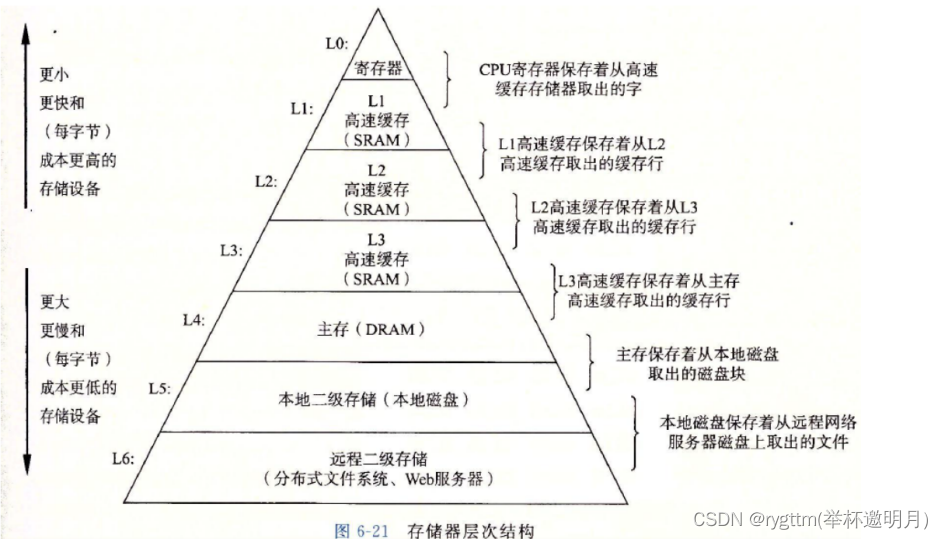
存储体系按照硬件来分的话,就是如下图所示的样子,大体可以分为带电存储和不带电存储两种存储方式,从主存向上的4个存储形式就是我们的带电存储方式,下面的远程二级存储和磁盘存储是我们的不带电存储形式。其中远程二级存储,例如:你存到百度网盘等信息内容交给百度后台进行存储。
1.
假设现在分别遍历顺序表和链表,我们的CPU就会去执行这个指令,而我们的顺序表存在哪里呢?
他们其实存在内存里面,从进程地址空间的角度来讲,他其实是存在堆区上的,他们的空间都是我们malloc出来的。
这里会涉及到虚拟内存和物理内存映射的知识,我们这里不要扯那么复杂,尽量讲简单一些。
2.
我们的CPU要执行指令,编译时CPU是不会直接向内存中读取数据的,会先将数据加载到三级缓存里面
L1 cache 寄存器
L2 cache
L3 cache
小的放到寄存器,大的放到缓存里面
比如访问存储1数据的内存位置0x00123400,先看这个地址在不在缓存中,在就直接访问,不在就先加载到高速缓存里面,然后再访问。
3.
根据就近原则,我们会先访问当前地址的附近地址,所以我们将地址附近的数据加载到缓存时,加载的是一片数据,将某个地址附近的
数据一起都加载到缓存里面,至于加载多少,这取决于内存。
假设不命中的情况下,CPU一次加载20byte到缓存(具体加载多大,取决于硬件体系)
4.
比如当我们访问arr[0]时,计算机会认为你极大概率访问arr[1]…等等,所以他会把arr[0]后面的数据一次性加载到缓存里面,大小可能是
20字节等等大小,计算机就这样设计的。
但链表与其相比就不一样了,我们链表的物理地址空间可不是一致的,如果运气好,我们一次性加载数据到缓存里面时,可能把后面结点
数据加载到缓存里面,但如果运气不好,就得重新将其加载到缓存里面,所以CPU高速缓存命中率较低,我们结点之间的地址还是相差较大的
,我们加载一片过去,大概率是一次性加载不到高速缓存里面的,所以我们需要多次命中,多次加载到缓存里面去。
如果多次未命中的话,其实又会带来另一个问题,缓存污染,我们的高速缓存空间其实是有限的,如果你多次加载的缓存是未命中有效数据
的,那我们的高速缓存会把缓存中你最近没有访问的空间换出去,把你加载的缓存放进来。因为我们的高速缓存空间大小是有限的。
所以有可能造成什么样的结果呢?当我们为了加载链表中的有效数据,我们加载了100多次,终于将我们的有效数据都加载到缓存里面去了,
但这个高速缓存中其实是存在许许多多没用的缓存的,至于是谁的空间,我们也不知道,反正这些不用的数据已经占用我们的告诉缓存了,
这就造成了缓存污染,把一堆没用的数据加载到我们的告诉缓存里面。
坑就坑在,链表的数据不仅不命中,一些对我们来说无用的数据还占用高速缓存,这就很智障好吧!

