
- 1黑马程序员——Java基础---String类和StringBuffer
- 2[图解]SysML和EA建模住宅安全系统-01_sysml和ea区别
- 3力扣 1888. 使二进制字符串字符交替的最少反转次数(前缀和+滑动窗口)_现有一个二进制串,你可以进行任意次操作,每次操作选择相邻的三个位置,将其翻转。
- 4最详细的 K8S 学习笔记总结
- 5八、SpringCloud-RabbitMQ + Spring AMQP 消息队列_rabbitmq 版本控制
- 6Linux repo包安装Nginx
- 7手把手教如何用Linux下IIO设备(附代码)
- 8哈希表&位图&topk&一致性哈希算法_布隆过滤器 topk
- 92005-2020年A股数据挖掘:谁是最大的牛股?【附Python分析源码】
- 10OpenCV 图像处理一(阈值处理、形态学操作【连通性,腐蚀和膨胀,开闭运算,礼帽和黑帽,内核】)_我在vscode学opencv 图像处理一
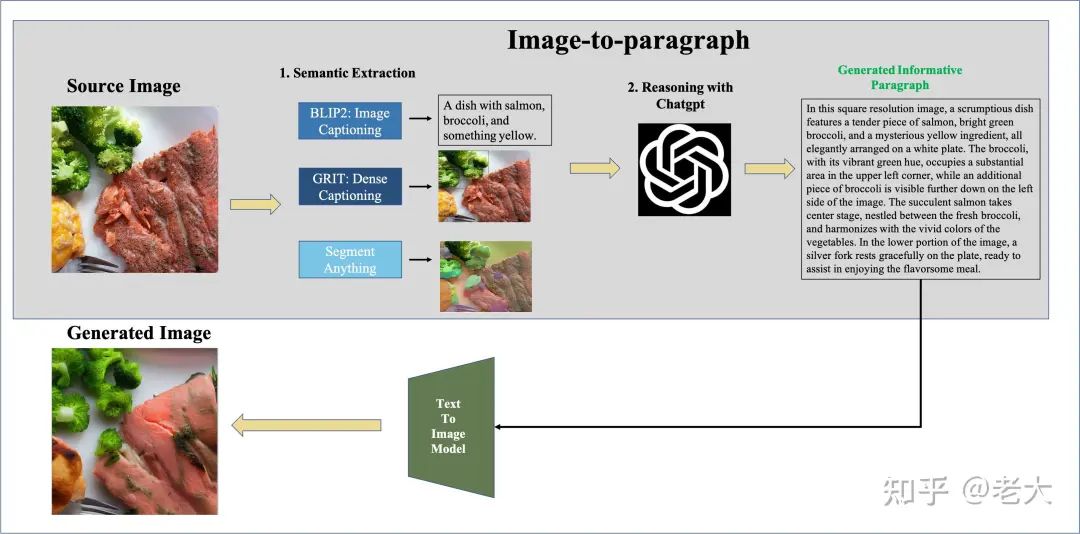
Image2Paragraph=BLIP-2+SAM+ChatGPT,把图片变文本段落! 8G显存即可Run!
赞
踩
作者:老大 https://zhuanlan.zhihu.com/p/621503837
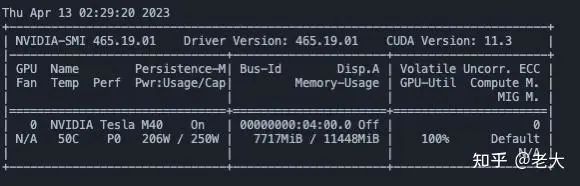
8G GPU显存即可以运行
代码链接(已开源): h
https://github.com/showlab/Image2Paragraph
动机:
怎么把图片表示成高质量文本一直是个热门的问题。传统的思路Show,and Tell 等 Image Caption和Dense Caption 等都是依赖大量的人工标注。首先依靠诸如亚马逊AMT( 亚非拉大兄弟们)等标注平台给每张图一人写一段描述。其中添加了一系列规则,诸如名词数目,颜色等等。通常用一句简短的话来描述一张图。
然而,这种朴素的标记思路造成了严重的One-to-many问题。如一张图对应很多文本。由于图片和文本之间信息的不对称性,在这类数据上训练的结果很容易陷入平凡解。(Pretrain中也经常遇到的问题)
而LLM(大语言模型)尤其是ChatGPT展现出来的逻辑能力让人望尘莫及。我们惊讶发现, 把Bounding Box 和 Object信息给到GPT4, GPT4很自然的能推理出物体之间的位置关系,甚至想像出物体之间的联系。
因此一个很自然的想法就是, 用GPT4对每张图生成高信息量的段落,From One-to-many to one-to-one
做法:
低阶语义抽取:
Image Caption, Dense Caption, Object Detection, Segement Anything 等等统一当成视觉理解组件。
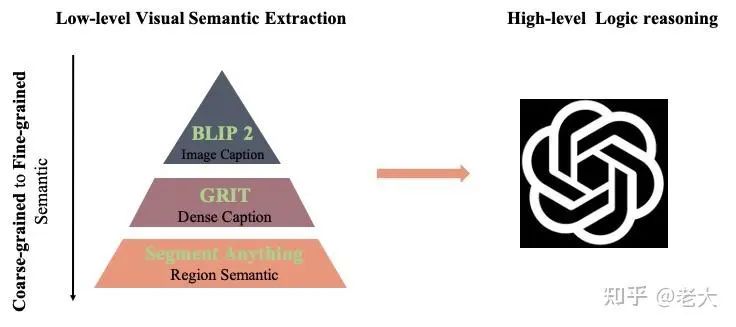
如图所示,首先用BLIP2 得到一张图的Coars-grained Caption信息。再用 GRIT得到Dense Caption信息,最终用Segment Anything 去得到Fine- grained Region-level Semantic.
高阶推理:
把金字塔视觉语义给到ChatGPT,让ChatGPT去推理物体之间的关系和物体的物质信息等,最终生成一个高质量Unique的文本段落。
可视化:
最后对生成的段落,放进Control Net生成一张重构的图。
实验:
最后是一些运行结果:
对生成的段落用ControlNet生成新图片。



Region-level Semantic:
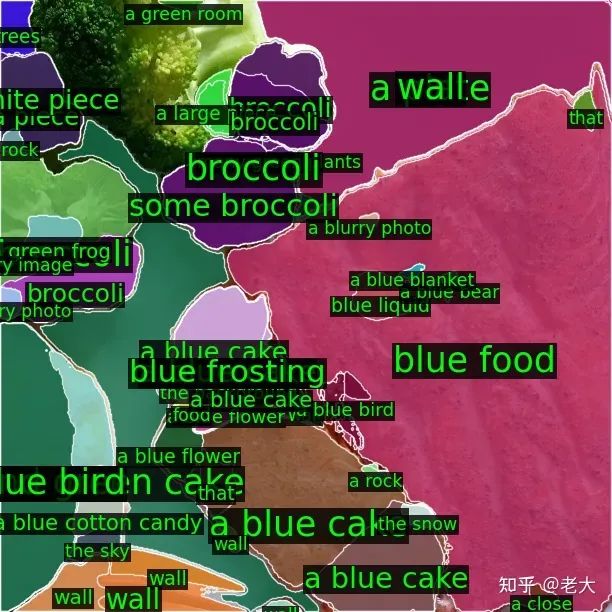
最后有意思的是:
当我们把图片变成文本之后。不需要训练的情况下,检索效果竟然好与在COCO上 Train的结果。
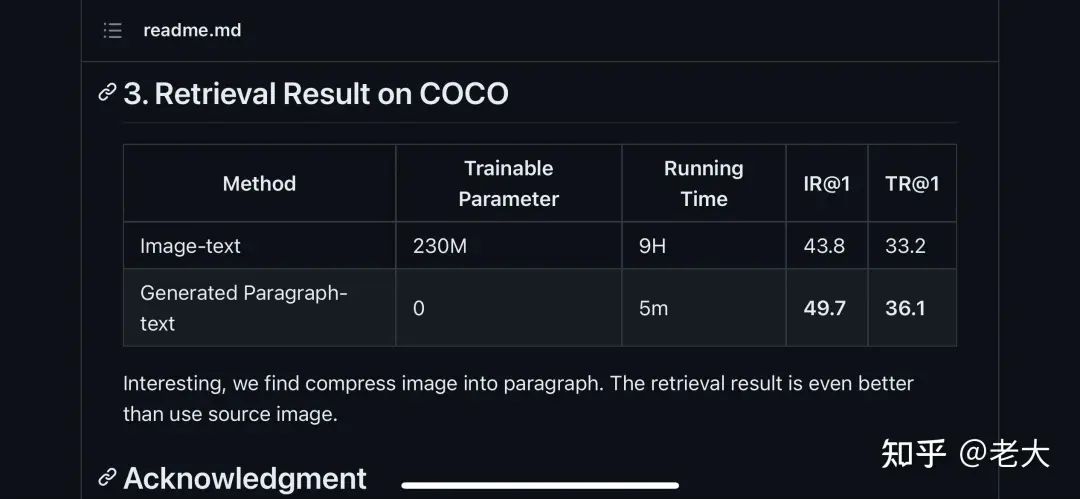
一些呼之欲出的问题即将到来:
现有Vision- language Pretrain需不需要新的 Data collection 范式?
现有的Image- Text 数据集尤其是Caption数据需不需要Refine?
参考:
Show,And Tell. GRIT. ChatGPT. Segment Anything. ControlNet. Blip2.
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻

点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!

