
- 1实现SpringMVC底层机制(三)
- 2NLP学习笔记(一)_prompt tokens
- 3数据结构:手撕图解双向循环链表_哨兵位的概念
- 4ElasticSearch设置密码Windows_windows elasticsearch 设置密码
- 5应用限流常用方案及项目实战
- 6AttributeError: partially initialized module ‘xxxx‘ has no attribute ‘xxxx‘ (most likely due to a .._partially initialized module 'warnings' has no att
- 7H5如何做页面下拉刷新和上拉加载_h5上滑刷新
- 8Codeforces Round 870 (Div. 2)题解(5/6)_piifog
- 9【机器学习】总结了九种机器学习集成分类算法(原理+代码)
- 10php mysql类_php数据库功能类-mysql类
爬虫框架 Scrapy 详解
赞
踩
一、Scrapy 基础知识
Scrapy 是适用于 Python 的一个快速、高层次的屏幕抓取和 web 抓取框架,用于抓取 web 站点并从页面中提取结构化的数据。Scrapy 用途广泛,可以用于数据挖掘、监测和自动化测试。
Scrapy 是一个框架,可以根据需求进行定制。它也提供了多种类型爬虫的基类,如 BaseSpider、sitemap 爬虫等,最新版本又提供了 web2.0 爬虫的支持。
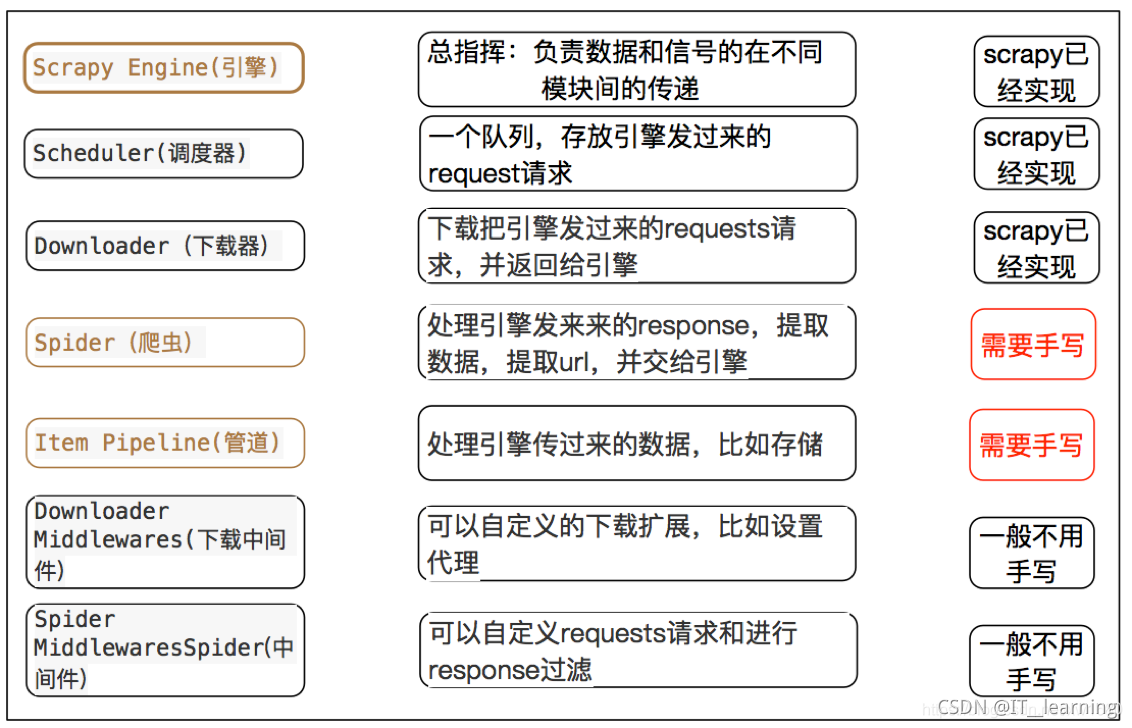
1、Scrapy 基本模块
(1) 调度器(Scheduler)
调度器,说白了把它假设成为一个
URL(抓取网页的网址或者说是链接)的优先队列,由它来决定下一个要抓取的网址是什么,同时去除重复的网址(不做无用功)。用户可以自己的需求定制调度器。(2) 下载器(Downloader)
下载器,是所有组件中负担最大的,它用于高速地下载网络上的资源。Scrapy 的下载器代码不会太复杂,但
效率高,主要的原因是 Scrapy 下载器是建立在 twisted 这个高效的异步模型上的(其实整个框架都在建立在这个模型上的)。(3) 爬虫(Spider)
爬虫,是用户最关心的部份。
用户定制自己的爬虫(通过定制正则表达式等语法),用于从特定的网页中提取自己需要的信息,即所谓的实体(Item)。例如使用 Xpath 提取感兴趣的信息。
用户也可以从中提取出链接,让Scrapy继续抓取下一个页面。(4) 实体管道(Item Pipeline)
实体管道,用于接收网络爬虫传过来的数据,以便做进一步处理。例如
验证实体的有效性、清除不需要的信息、存入数据库(持久化实体)、存入文本文件等。(5) Scrapy引擎(Scrapy Engine)
Scrapy 引擎是整个框架的核心,用来处理整个系统的数据流,触发各种事件。它用来
控制调试器、下载器、爬虫。实际上,引擎相当于计算机的CPU,它控制着整个流程。(6) 中间件
整个 Scrapy 框架有很多中间件,如下载器中间件、网络爬虫中间件等,这些中间件相当于过滤器,夹在不同部分之间截获数据流,并进行特殊的加工处理。
2、Scrapy 工作流程
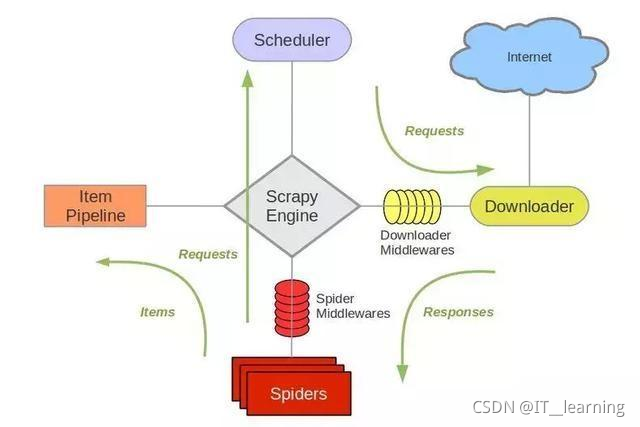
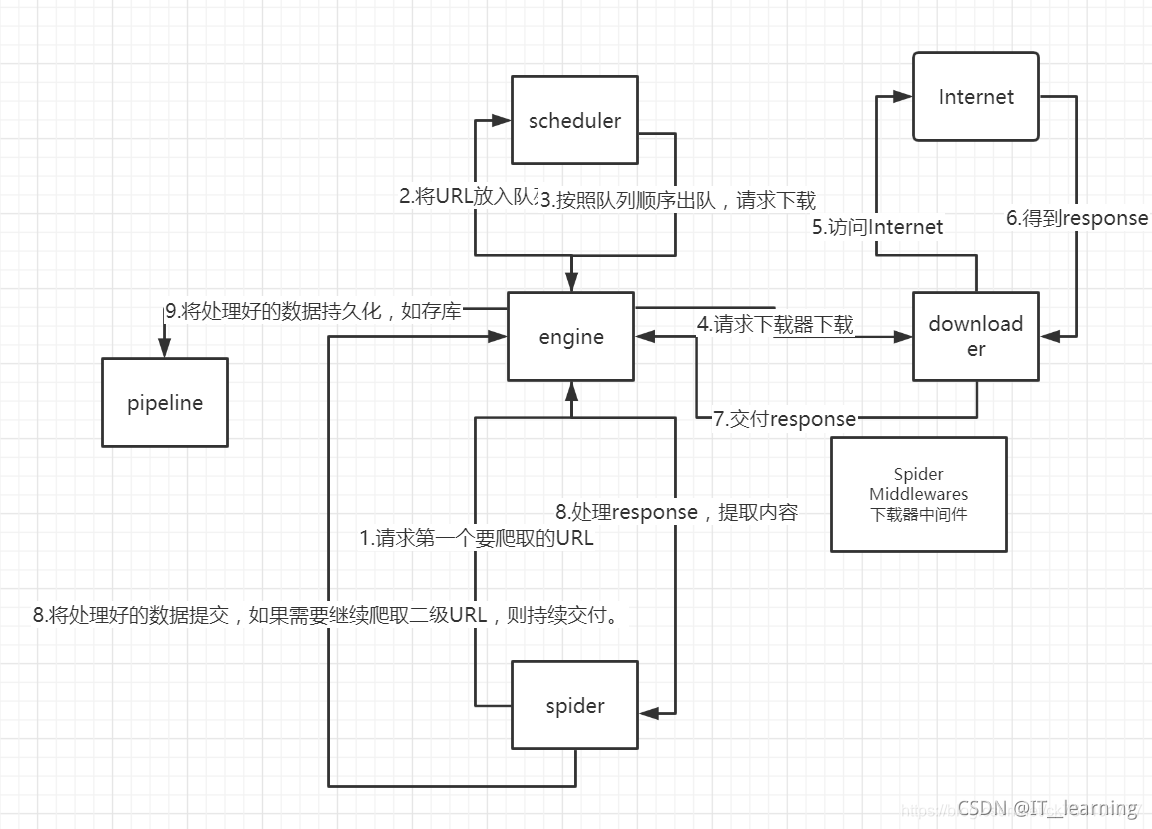
流程如下:
1)爬虫中起始的 URL 构造成 Requests 对象 爬虫中间件 引擎 调度器;
2)调度器把 Requests 引擎 下载中间件 下载器;
3)下载器发送请求,获取 Responses 响应 下载中间件 引擎 爬虫中间件 爬虫;
4)爬虫提取 URL 地址,组装成 Requests 对象 爬虫中间件 引擎 调度器,重复步骤2;
5)爬虫提取数据 引擎 管道处理和保存数据;
每个模块的具体作用:
3、Scrapy 依赖的 python 包
Scrapy 是用纯python编写的,它依赖于几个关键的python包(以及其他包):
(1)lxml:一个高效的XML和HTML解析器
(2)parsel :一个写在lxml上面的html/xml数据提取库,
(3)w3lib :用于处理URL和网页编码的多用途帮助程序
(4)twisted:异步网络框架
(5)cryptography 和 pyOpenSSL :处理各种网络级安全需求
4、XPath
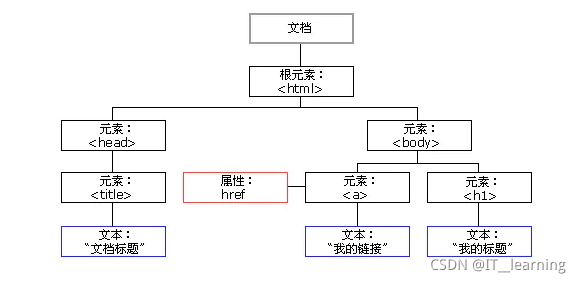
写爬虫最重要的是解析网页的内容,这个部分就介绍下通过 XPath 来解析网页,提取内容。
(1)HTML 节点和属性
(2)XPath 常用规则
● nodename选取此节点的所有子节点
● /从当前节点选取直接子节点
● //从当前节点选取子孙节点
● .选取当前节点
● …选取当前节点的父节点
● @选取属性
二、Scrapy 框架安装
1、Scrapy 安装
(1)Anaconda Python
conda install scrapy
- 1
(2)windows 标准 Python 开发环境
pip install scrapy
- 1
(3)ubuntu 标准 Python 开发环境
pip install scrapy # 或 pip3 install scrapy
- 1
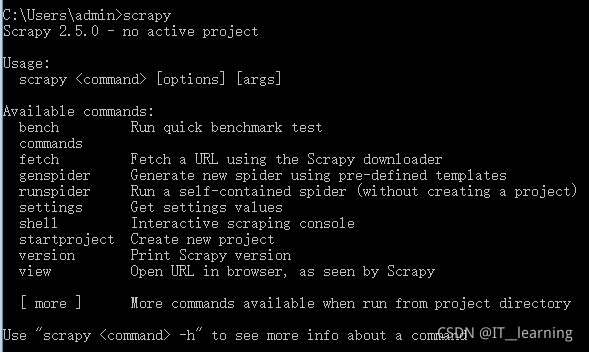
验证安装成功:
输入下面的语句,如果未抛出异常,说明 Scrapy 已经安装成功。
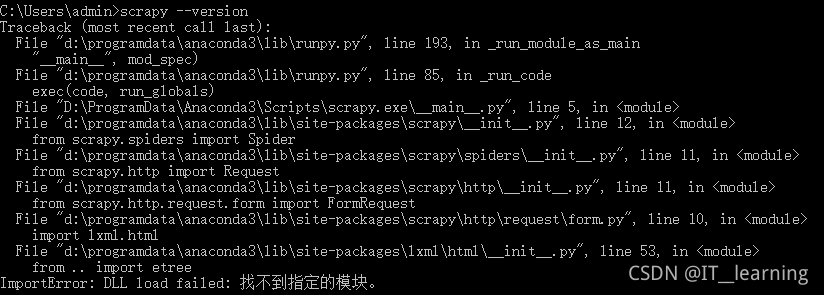
Windows 安装验证中遇到的问题:(1)ImportError: DLL load failed: 找不到指定的模块。
解决方法:lxml 版本与 Scrapy 版本不匹配,更新 lxml 版本pip install lxml --upgrade
- 1
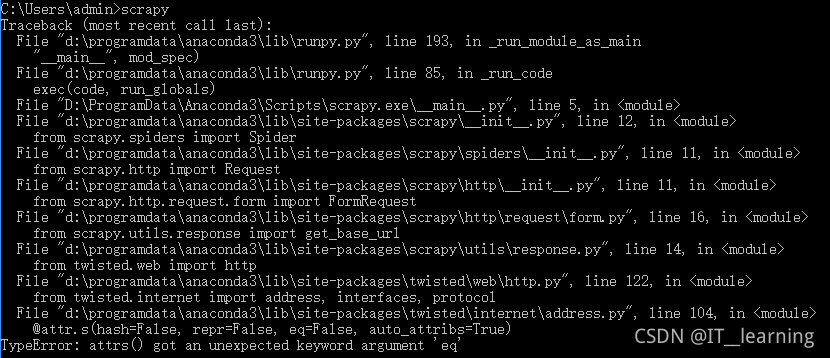
(2)TypeError: attrs() got an unexpected keyword argument ‘eq’
解决方法:attrs 的版本不够,更新 attrs 版本pip install attrs --upgrade
- 1
2、Scrapy Shell
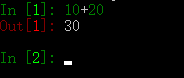
Scrapy 提供了一个 Shell 相当于 Python 的 REPL 环境,可以用这个 Scrapy Shell 测试 Scrapy 代码。在 Windows 中打开黑窗口,执行 scrapy shell 命令,就会进入 Scrapy Shell。

Scrapy Shell 和 Python 的 REPL 环境差不多,也可以执行任何的 Python 代码,只是又多了对 Scrapy 的支持,例如,在 Scrapy Shell 中输入 10 + 20,然后回车,会输出 30,如下图所示:
(1)使用 Scrapy Shell 抓取网页
启动 Chrome 浏览器,进入 淘宝首页 然后在页面右键菜单中单击 检查 命令,在弹出的调试窗口中选择第一个 Elements 标签页,最后单击 Elements 左侧黑色箭头的按钮,将鼠标放到淘宝首页的导航条聚划算上,如下图所示。
这时,Elements 标签页中的 HTML 代码会自动定位到包含 聚划算 的标签上,然后在右键菜单中单击如下图所示的 Copy Copy Xpath命令,就会复制当前标签的 Xpath。
很明显,包含 聚划算 文本的是一个 a 标签,复制的 a 标签的 Xpath 如下:
/html/body/div[3]/div/ul[1]/li[2]/a
- 1
在 Scrapy Shell 中启动淘宝首页。
scrapy shell ht


