
- 1使用 Vue.js 和 Python 构建 DevOps 应用程序
- 2Docker安全最佳实践_docker安全端口配置
- 3数据库系统(二)数据库关系代数 | 选择 投影 笛卡尔积 自然连接 外连接等_投影选择笛卡尔积自然连接
- 4西蒙斯告诉你何为传奇人生 James Simons_吉姆 西蒙斯
- 5CSDN 博客等级获取及介绍_csdn等级升级
- 6csdn专用必杀技----谷歌浏览器插件_csdn谷歌插件
- 7导致Oracle裁员的原因有哪些?
- 8Java智能语音电销机器人 可私有化部署 自带小程序系统_java开发智能外呼机器人系统
- 9Hadoop 3.0磁盘均衡器(diskbalancer)新功能及使用介绍
- 10Mac电脑M1芯片Python环境搭建_mac m1 python 安装 依赖
pandas dataframe 的几种过滤数据的方法_pandas dataframe 过滤
赞
踩
pandas dataframe简介
Pandas是一个用于数据科学的开源Python库。这个库在整个数据科学行业被广泛使用。它是一个快速和非常强大的python工具来执行数据分析。Pandas为我们提供了读取、过滤、检查、操作、分析和绘制数据的命令。它使用内置函数加载以各种文件格式存储的数据,如csv, json, text等,作为pandas数据框架结构。
pandas dataframe是一种和excel一样的表格结构。它是一种二维数据结构,由行和列形式的数据组成。此库用于对数据进行分组、聚合、清理和过滤。它允许我们创建原始数据集的子集。
在使用它之前,首先要通过命令
pip3 install pandas来安装pandas。
使用时,就可以通过
import pandas as pd来引用pandas。
在进入具体的分析之前,准备数据如下:

方法一,选择某一列或者某几列数据
调用方法: df [ [‘‘column name 1', ‘'column name 2’’] ]
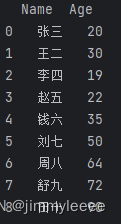
根据上述数据选择Name和Age列,示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choose_by_column = test_info[['Name','Age']]
- print(choose_by_column)
程序结果执行如下:
方法二,根据行的索引选取几行数据
调用方法:df [start_index : end_index]
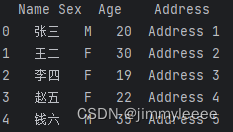
根据上述数据选择前5行数据,示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info[0:5]
- print(choosed_data)
打印结果如下:
方法三,根据行与列的索引选取数据
调用方法:df.iloc [row index range, column index range]
示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info.iloc[1:5, 0:2]
- print(choosed_data)
打印结果如下:

方法四,根据行列的索引选取具体某一列数据
调用方法:df.loc [row dataset index/labels, ‘column_name’]
示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info.loc[1:5, 'Name']
- print(choosed_data)
打印结果如下:

方法五,根据某一列的值符合条件来过滤
调用方法:df [ (df[‘‘column name'] ==’column value’ )]
选出大于40岁的数据,示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info[test_info['Age']>40]
- print(choosed_data)
打印结果如下:

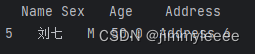
如果是多个条件,可以使用逻辑操作符 & 和 |, 例如,选择大于40又小于60的:
choosed_data = test_info[(test_info['Age']>40) & (test_info['Age']<60)]结果如下:
使用loc函数也可以实现同样的效果:
调用方法:df.loc[(column name 1 >= column value) & (column name 2 >= column value)]
示例代码:
choosed_data = test_info.loc[(test_info['Age']>40) & (test_info['Age']<60)]方法六,使用query方法
调用方法:df.query(column name >= column value )
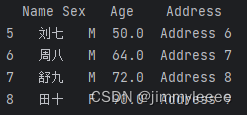
示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info.query('Age>40')
- print(choosed_data)
打印结果如下:
方法七,使用iat定位某一个具体的cell
调用方法: df.iat[row index, column index]
示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info.iat[5, 3]
- print(choosed_data)
打印结果如下:
![]()
方法八,根据列表条件选择
调用方法:df [ df[column name].isin([column value 1, column value 2])]
选择年龄是10的倍数的人,示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info[test_info['Age'].isin([10,20,30,40,50,60,70,80,90,100])]
- print(choosed_data)
打印结果如下:
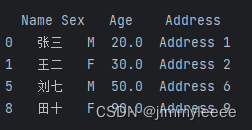
跟方法五一样,也可以通过df.loc[]实现同样的效果,这里就不举例了。
方法九,根据字符串的值匹配进行过滤
调用方法:df = df[ df[column name].str.contains('characters$')]
示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info[test_info['Address'].str.contains('Address')]
- print(choosed_data)
打印结果如下:

如果出现错误 “ValueError: Cannot mask with non-boolean array containing NA / NaN values”,说明这一列有空值,可以先将空值使用DataFrame.fillna处理之后,再调用。
方法十,空值的过滤
调用方法:df.isnull()
示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info.isnull()
- print(choosed_data)
打印结果如下:

可以根据打印结果知道哪一行的那一列的数据是空的。
接着就可以使用df.dropna(inplace=True)将空值删除。
示例代码如下:
- data_file = "F:\\1.xlsx"
- test_info = pd.read_excel(data_file)
- choosed_data = test_info.isnull()
- test_info.dropna(inplace=True)
- print(test_info)
打印结果:

可以看到最后一行的含有空值的行已经被删除了。

