
- 1分布式与一致性协议之PBFT算法_pbft算法应用场景有哪些?
- 2python基础测试含答案_python测试基础
- 3准「AI 时代」下,如何衡量程序员的工作效率和生产力?_程序员相关的ai考核指标
- 4RocketMQ —消费重试_rocketmq消费重试
- 5添加数据(sql)_添加sql
- 6【分布式】大模型分布式训练入门与实践 - 04_大模型分布式微调 nccl
- 7如何在 PyCharm 中集成 GitLab?_pycharm上gitlab插件
- 8最新版的配音软件--- tts-vue 软件 下载安装成功过程
- 9Flink流计算常用算子大全_flink算子有哪些
- 10android studio设置jdk版本项目设置和全局设置
使用预先训练的扩散模型进行图像合成_预训练的扩散模型
赞
踩
动动发财的小手,点个赞吧!
文本到图像的扩散模型在生成符合自然语言描述提示的逼真图像方面取得了惊人的性能。开源预训练模型(例如稳定扩散)的发布有助于这些技术的民主化。预先训练的扩散模型允许任何人创建令人惊叹的图像,而不需要大量的计算能力或长时间的训练过程。
尽管文本引导图像生成提供了一定程度的控制,但获得具有预定构图的图像通常很棘手,即使有大量提示也是如此。事实上,标准的文本到图像扩散模型几乎无法控制生成图像中描绘的各种元素。
在这篇文章[1]中,我将解释基于论文 MultiDiffusion: Fusing Diffusion Paths for Controlled Image Generation 的最新技术。该技术使得可以在将元素放置在由文本引导的扩散模型生成的图像中时获得更大的控制。论文中提出的方法更通用,并且允许其他应用,例如生成全景图像,但我将在这里限制为使用基于区域的文本提示的图像合成的情况。这种方法的主要优点是它可以与开箱即用的预训练扩散模型一起使用,而不需要昂贵的重新训练或微调。
为了用代码补充这篇文章,我准备了一个简单的 Colab 笔记本和一个 GitHub 存储库,其中包含我用来生成本文中图像的代码实现。该代码基于 Hugging Face 扩散器库中包含的稳定扩散管道,但它仅实现了其功能所需的部分,以使其更简单、更易于阅读。
Diffusion 模型
在本节中,我将回顾有关扩散模型的一些基本事实。扩散模型是生成模型,通过反转将数据分布映射到各向同性高斯分布的扩散过程来生成新数据。更具体地说,给定图像,扩散过程由一系列步骤组成,每个步骤都向该图像添加少量高斯噪声。在无限步数的限制下,噪声图像将与从各向同性高斯分布采样的纯噪声无法区分。
扩散模型的目标是通过在给定步骤 t 的噪声图像的扩散过程中尝试猜测步骤 t-1 的噪声图像来反转该过程。例如,这可以通过训练神经网络来预测在该步骤中添加的噪声并从噪声图像中减去它来完成。
一旦我们训练了这样的模型,我们就可以通过从各向同性高斯分布中采样噪声来生成新图像,并使用该模型通过逐渐消除噪声来反转扩散过程。

文本到图像的扩散模型反转扩散过程,试图到达与文本提示的描述相对应的图像。这通常由神经网络完成,该神经网络在每个步骤 t 预测步骤 t-1 的噪声图像,该图像不仅以步骤 t 的噪声图像为条件,而且还以描述其尝试重建的图像的文本提示为条件。
许多图像扩散模型(包括稳定扩散)不在原始图像空间中运行,而是在较小的学习潜在空间中运行。通过这种方式,可以以最小的质量损失减少所需的计算资源。潜在空间通常是通过变分自动编码器学习的。潜在空间中的扩散过程与以前完全相同,允许从高斯噪声生成新的潜在向量。由此,可以使用变分自动编码器的解码器获得新生成的图像。
使用多重扩散进行图像合成
现在让我们来解释如何使用 MultiDiffusion 方法获得可控的图像合成。目标是通过预先训练的文本到图像扩散模型更好地控制图像中生成的元素。更具体地说,给定图像的一般描述(例如,封面图像中的客厅),我们希望通过文本提示指定的一系列元素出现在特定位置(例如,中心的红色沙发,左边是室内植物,右上角是一幅画)。这可以通过提供一组描述所需元素的文本提示和一组基于区域的二进制掩码来指定必须在其中描述元素的位置来实现。例如,下图包含封面图像中图像元素的边界框。

MultiDiffusion可控图像生成的核心思想是将针对不同指定提示的多个扩散过程组合在一起,以获得在预定区域中显示每个提示内容的连贯且平滑的图像。与每个提示关联的区域是通过与图像尺寸相同的二进制掩码指定的。如果必须在该位置描绘提示,则遮罩的像素设置为 1,否则设置为 0。
更具体地说,让我们用 t 表示在潜在空间中运行的扩散过程中的通用步骤。给定时间步 t 处的噪声潜在向量,模型将预测每个指定文本提示的噪声。从这些预测噪声中,我们通过在时间步 t 处从先前的潜在向量中删除每个预测噪声,获得时间步 t-1 处的一组潜在向量(每个提示一个)。为了获得扩散过程中下一个时间步骤的输入,我们需要将这些不同的向量组合在一起。这可以通过将每个潜在向量乘以相应的提示掩码,然后采用掩码加权的每像素平均值来完成。遵循此过程,在特定掩模指定的区域中,潜在向量将遵循相应局部提示引导的扩散过程的轨迹。在预测噪声之前,在每一步将潜在向量组合在一起,确保生成图像的全局内聚性以及不同屏蔽区域之间的平滑过渡。
MultiDiffusion 在扩散过程开始时引入了引导阶段,以更好地粘附紧密掩模。在这些初始步骤期间,对应于不同提示的去噪潜在向量不会组合在一起,而是与对应于恒定颜色背景的一些去噪潜在向量组合。这样,由于布局通常是在扩散过程的早期确定的,因此可以获得与指定蒙版的更好匹配,因为模型最初可以仅关注蒙版区域来描绘提示。
实例
在本节中,我将展示该方法的一些应用。我使用 HuggingFace 托管的预训练稳定扩散 2 模型来创建本文中的所有图像,包括封面图像。
如所讨论的,该方法的直接应用是获取包含在预定义位置中生成的元素的图像。


该方法允许指定要描述的单个元素的样式或一些其他属性。例如,这可用于在模糊背景上获得清晰的图像。


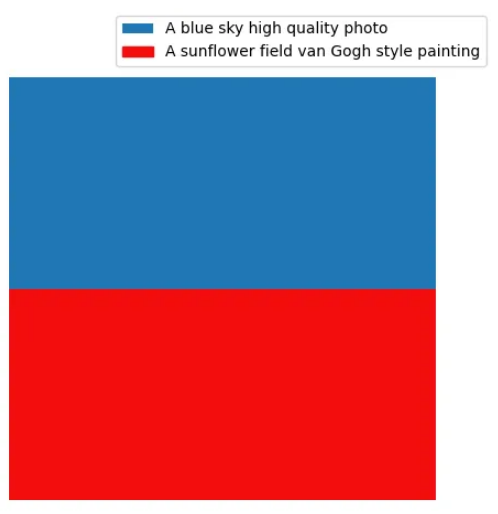
元素的风格也可以非常不同,从而产生令人惊叹的视觉效果。例如,下图是通过将高质量照片风格与梵高风格的绘画混合而获得的。

总结
在这篇文章中,我们探索了一种将不同扩散过程结合在一起的方法,以改善对文本条件扩散模型生成的图像的控制。此方法增强了对生成图像元素的位置的控制,并且还可以无缝组合以不同风格描绘的元素。
所述过程的主要优点之一是它可以与预先训练的文本到图像扩散模型一起使用,而不需要微调,这通常是一个昂贵的过程。另一个优点是,可控图像生成是通过二进制掩模获得的,与更复杂的条件相比,二进制掩模更容易指定和处理。
这项技术的主要缺点是,它需要在每个扩散步骤中为每个提示传递一个神经网络,以便预测相应的噪声。幸运的是,这些可以批量执行以减少推理时间开销,但代价是更大的 GPU 内存利用率。此外,有时一些提示(尤其是仅在图像的一小部分中指定的提示)被忽略,或者它们覆盖的区域比相应蒙版指定的区域更大。虽然可以通过引导步骤来缓解这种情况,但过多的引导步骤会显着降低图像的整体质量,因为可用于将元素协调在一起的步骤较少。
值得一提的是,组合不同扩散过程的想法并不限于本文中描述的内容,它还可以用于进一步的应用,例如全景图像生成,如论文 MultiDiffusion: Fusing Diffusion Paths for Controlled图像生成。
我希望您喜欢这篇文章,如果您想深入了解技术细节,您可以查看此 Colab 笔记本和 GitHub 存储库以及代码实现。
Reference
Source: https://towardsdatascience.com/image-composition-with-pre-trained-diffusion-models-772cd01b5022
本文由 mdnice 多平台发布

