
- 1IDEA运行第一个Java简单程序(新建项目到运行类)_idea java
- 2洞态IAST的部署及使用(以Tomcat为例)_洞态iast本地部署
- 3国风AI绘画平台Trik;「一个女孩的一生」走红;音视频转文字的精准处理指南;神经网络原理动画 | ShowMeAI日报
- 4自然语言处理--NLTK 停用词表_nltk导入中文停用词
- 5低不成高不就的现状?小伙用Python爬取百万招聘,找到满意工作_找工作低不成高不就
- 6爬虫项目实战:利用爬虫模板爬取豆瓣图书Top250_爬虫从模块查找书籍
- 7Caused by: org.springframework.amqp.AmqpException: No method found for class [B
- 8ORA-00257: 归档程序错误
- 9PowerDesigner16.5快速生成数据库详细设计文档_powerdesigner 生成数据库设计文档
- 10vue判断滚动条是否触底(触底增加数据)_vue-seamless-scroll 通过高度判断
4、深潜KafkaProducer —— RecordAccumulator精析
赞
踩
通过上一课时的介绍我们了解到,业务线程使用 KafkaProducer.send() 方法发送 message 的时候,会先将其写入RecordAccumulator 中进行缓冲,当 RecordAccumulator 中缓存的 message 达到一定阈值的时候,会由 IO 线程批量形成请求,发送到 kafka 集群。本课时我们就重点来看一下 RecordAccumulator 这个缓冲区的结构。
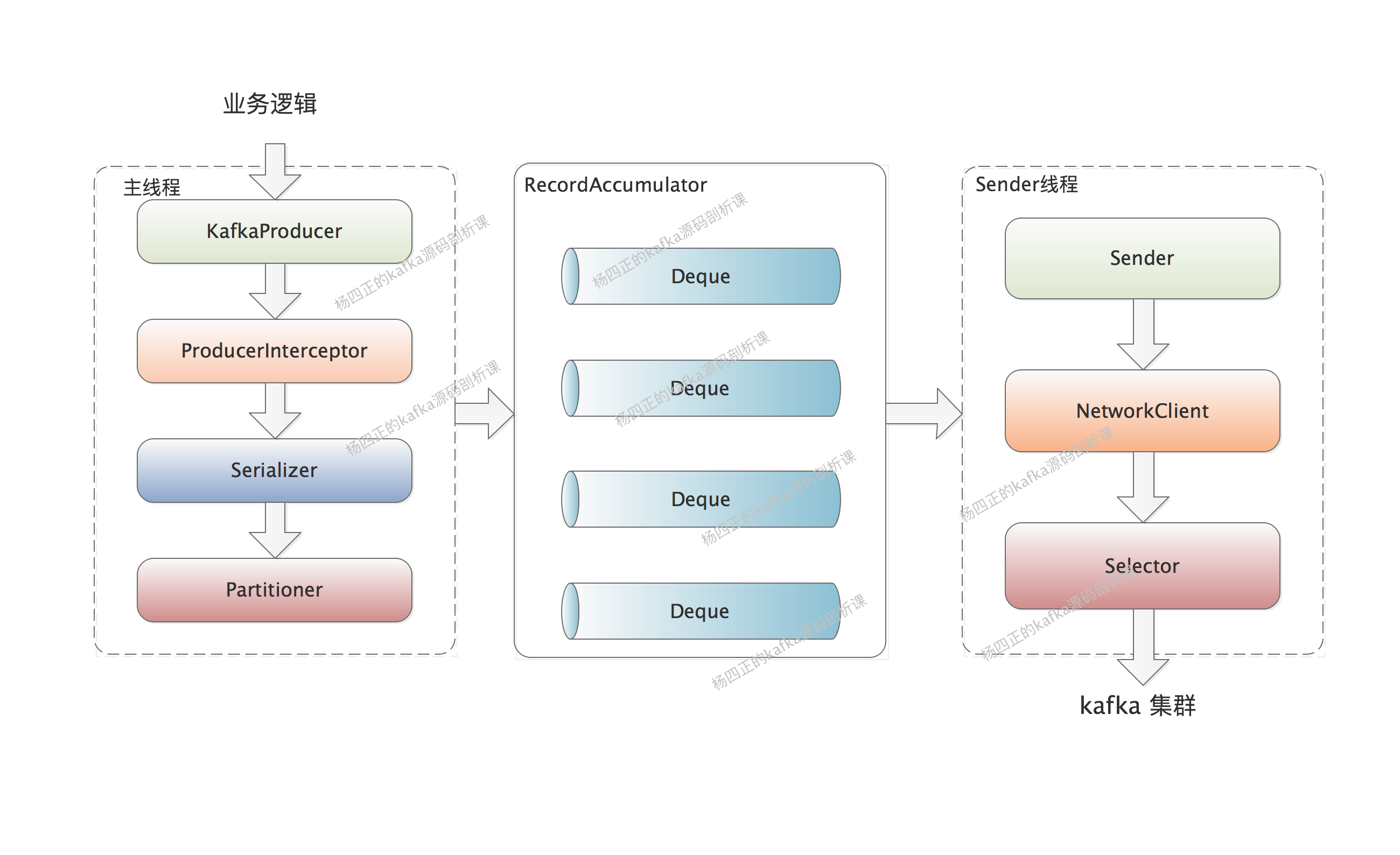
首先,我们从上图中可以看出,RecordAccumulator 会由业务线程写入、Sender 线程读取,这是一个非常明显的生产者-消费者模式,所以我们需要保证 RecordAccumulator 是线程安全的。
RecordAccumulator 中维护了一个 ConcurrentMap<TopicPartition, Deque<ProducerBatch>> 类型的集合,其中的 Key 是 TopicPartition 用来表示目标 partition,Value 是 ArrayDeque<ProducerBatch> 队列,用来缓冲发往目标 partition 的消息。 这里的 ArrayDeque 并不是线程安全的集合,后面我们会看到加锁的相关操作。
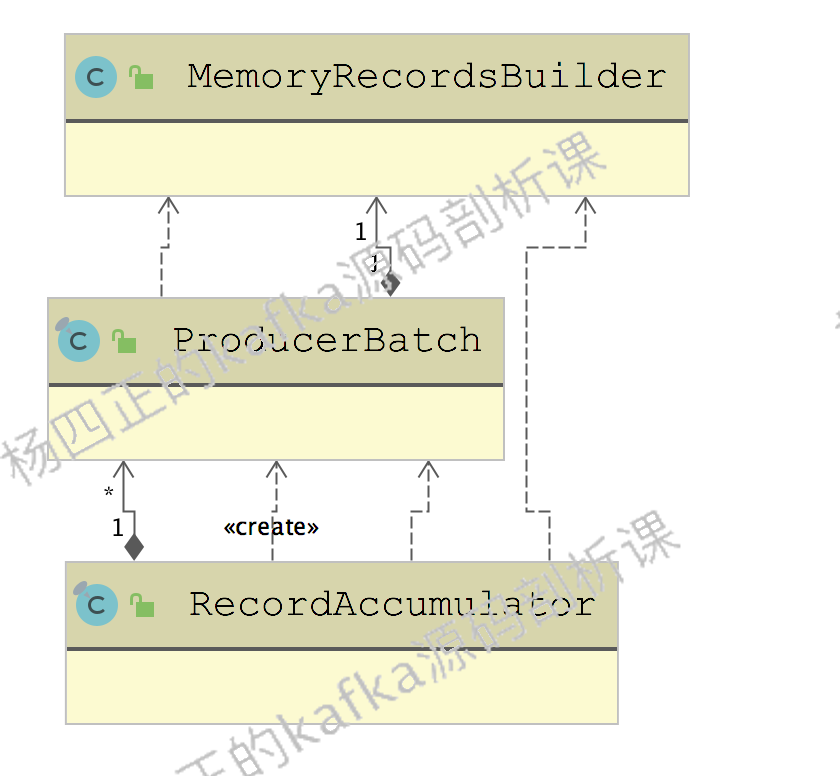
在每个 ProducerBatch 中都维护了一个 MemoryRecordsBuilder 对象,MemoryRecordsBuilder 才是真正存储 message 的地方。RecordAccumulator 、ProducerBatch、MemoryRecordsBuilder 这三个核心类的关系如下图所示:
message 格式
既然我们准备深入 KafkaProducer 进行分析,那我们就需要了解 message 在 kafka 内部的格式,而不是简单知道 message 是个 KV。kafka 目前的 message 的格式有三个版本:
- V0:kafka0.10 版本之前
- V1:kafka 0.10 ~ 0.11 版本
- V2:kafka 0.11.0 之后的版本
V0 版本
在使用 V0 版本的 message 时,message 在 RecordAccumulator 中只是简单的堆积,并没有进行聚合,每个 message 都有独立的元信息,如下图所示:
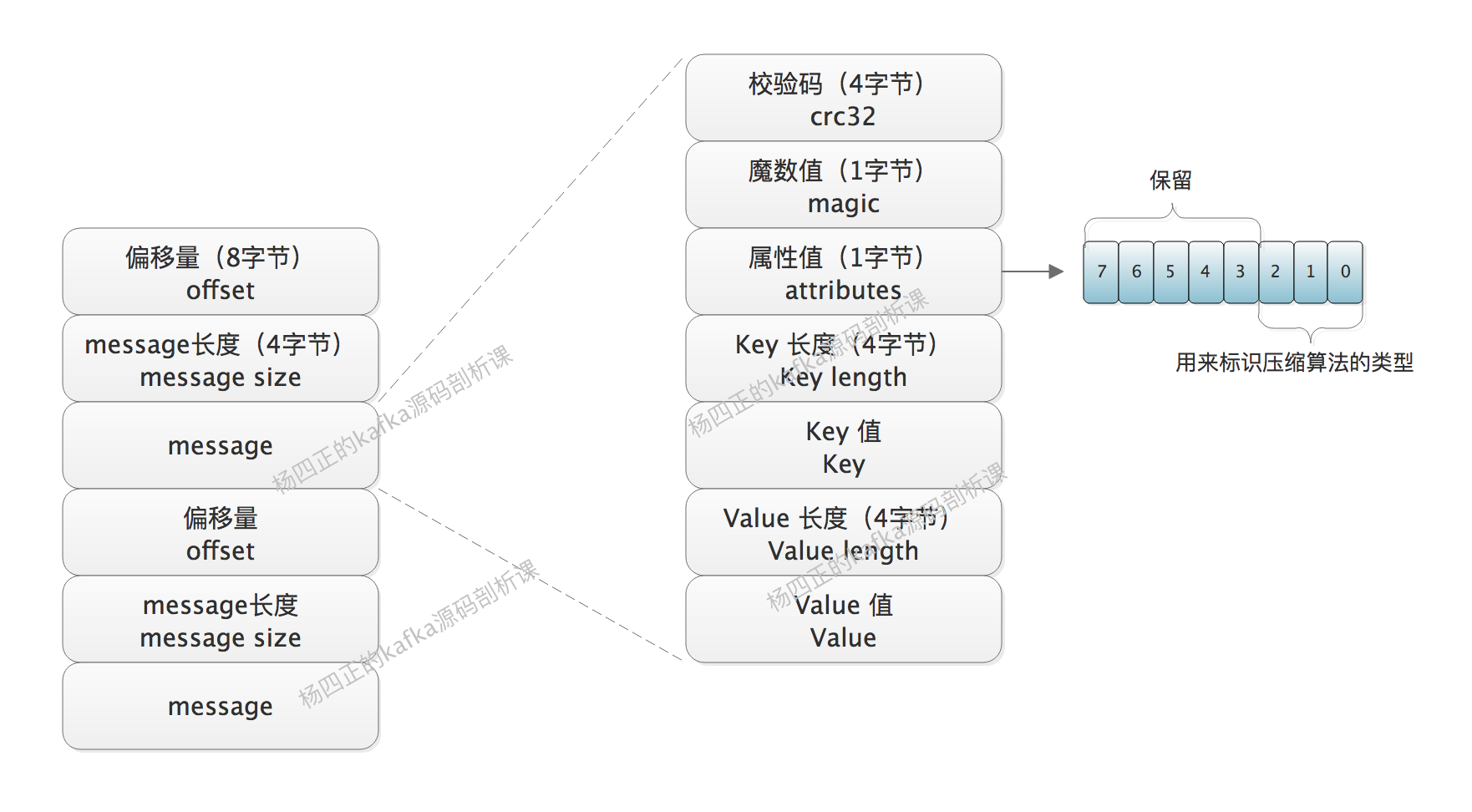
其中唯一要说明就是 attributes 部分,其中的低 3 位用来标识当前使用的压缩算法,高 5 位没有使用。
V1 版本
V1 版本 与 V0 版本的格式基本类似,就是多了一个 timestamp 字段,具体结构如下:
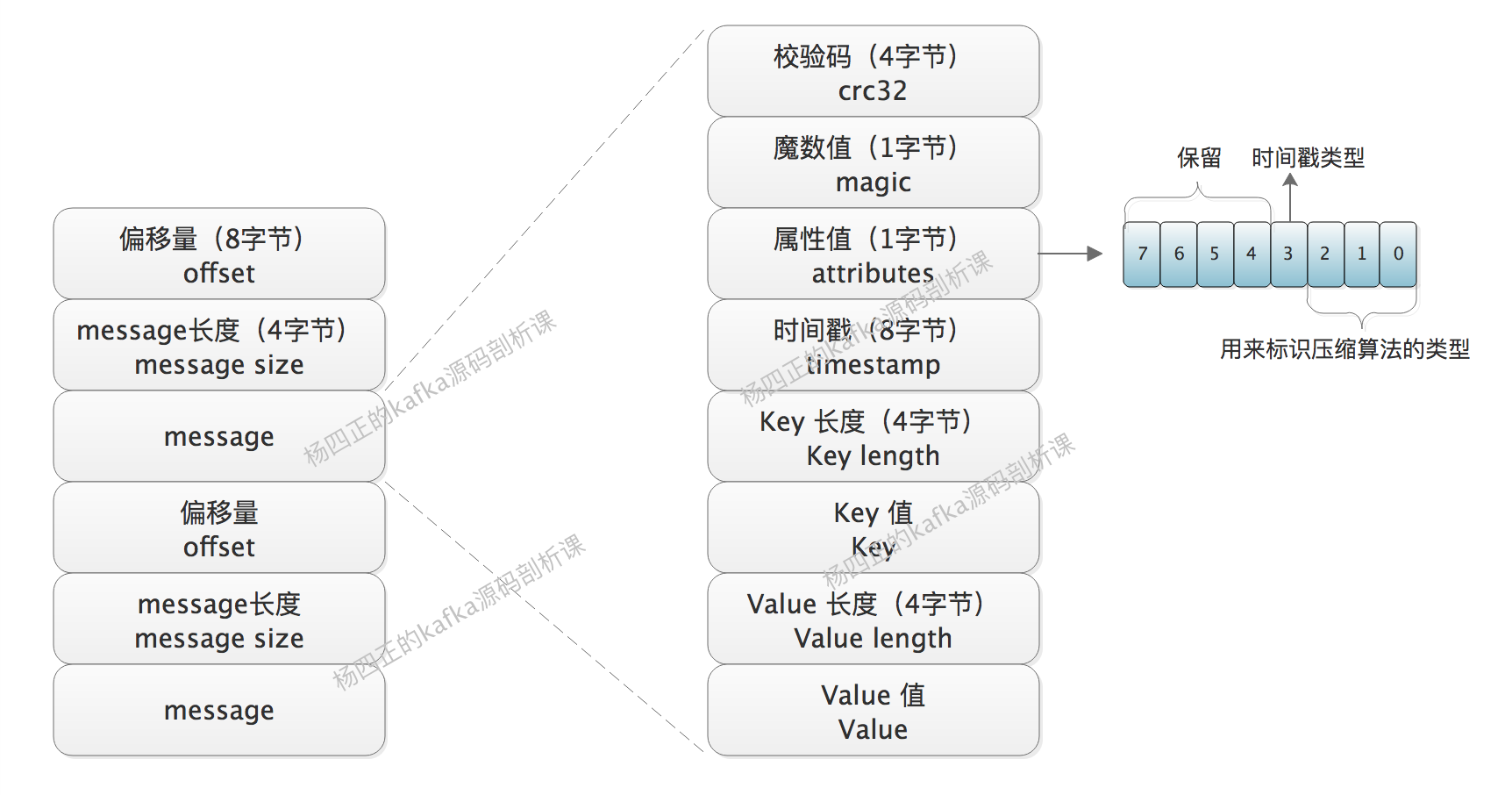
其中 attributes 部分的低 3 位依旧用来标识当前使用的压缩算法,第 4 位用来标识时间戳的类型。
在 V1 版本中引入 timestamp 主要是为了接口下面几个问题:
- 更准确的日志保留策略。在前面我们已经简单描述过了根据 message 存在时间的保留策略,在使用 V0 版本的时候,kafka broker 会直接根据磁盘上的 segment 文件的最后修改时间来判断是否执行删除操作,但是这种方案比较大的弊端就是如果发生 replica 迁移或是 replica 扩容,新增加 replica 中的 segment 文件就都是新创建的,其中包含的旧 message 就不会被删除。
- 更准确的日志切分策略。在前面我们已经提到过 segment 文件会定时、定量进行切分,在 V0 版本使用 segment 创建时间进行切分的话,也会存在上述同样的问题,导致出现单个大文件,也可能因为没有 message 写入,切分出很小的 segment 文件。
V1 版本中的压缩
对于常见压缩算法来说,压缩内容越多,压缩效果比例越高。但是单条 message 的长度一般都不会特别长,如果要让我们来解决这个矛盾的话,就是将多条 message 放到一起再压缩。kafka 也确实是这么干的,在 V1 版本中,kafka 使用了 wrapper message 的方式来提高压缩效率。简单理解,wrapper message 也是一条 message,但是其中的 value 值则是多条普通 message 组成的 message 集合,这些内部的普通 message 也称为 inner message。如下图所示:
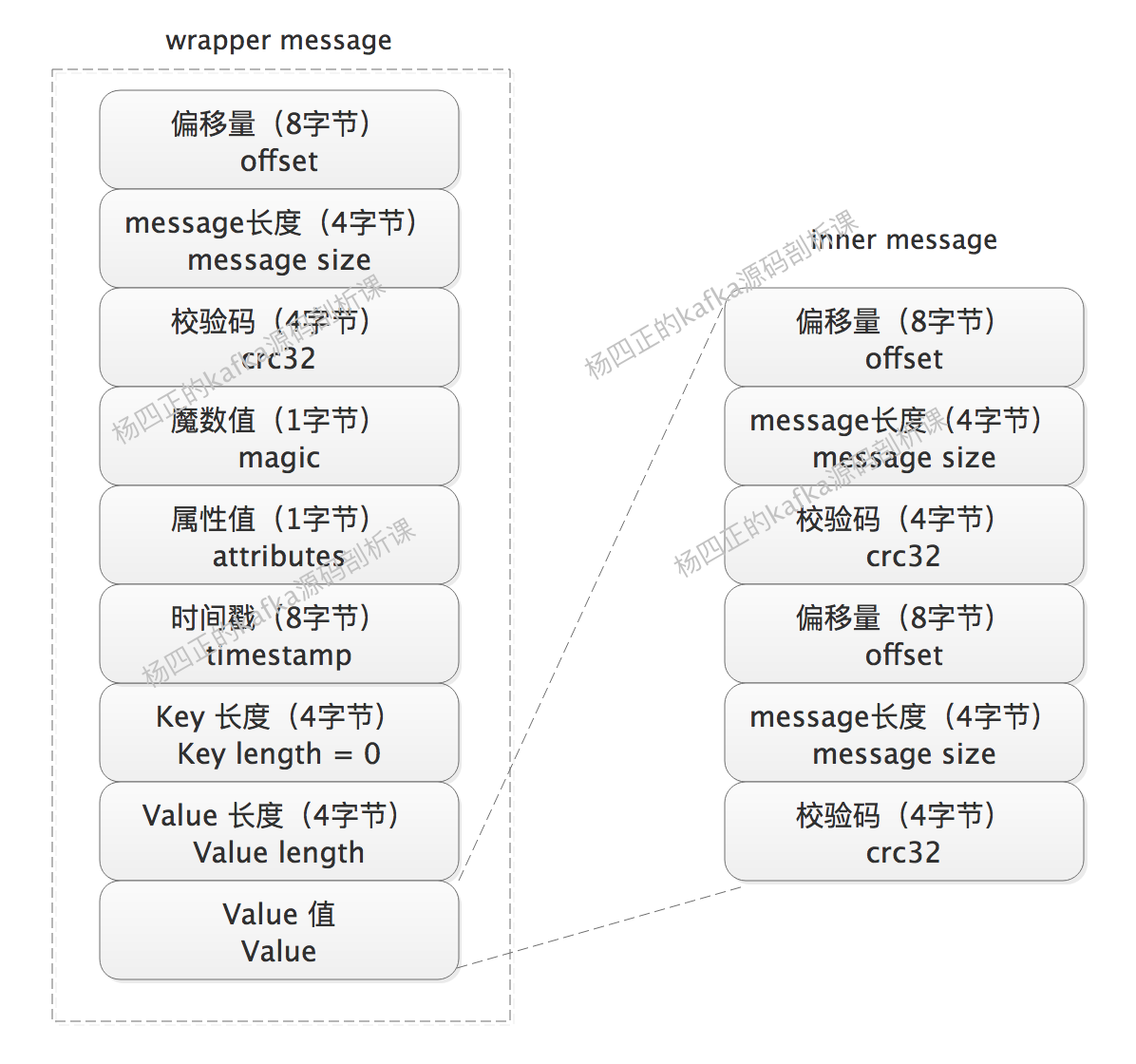
为了进一步降低 message 的无效负载,kafka 只在 wrapper message 中记录完整的 offset 值,inner message 中的 offset 只是相对于 wrapper message offset 的一个偏移量,如下图所示:
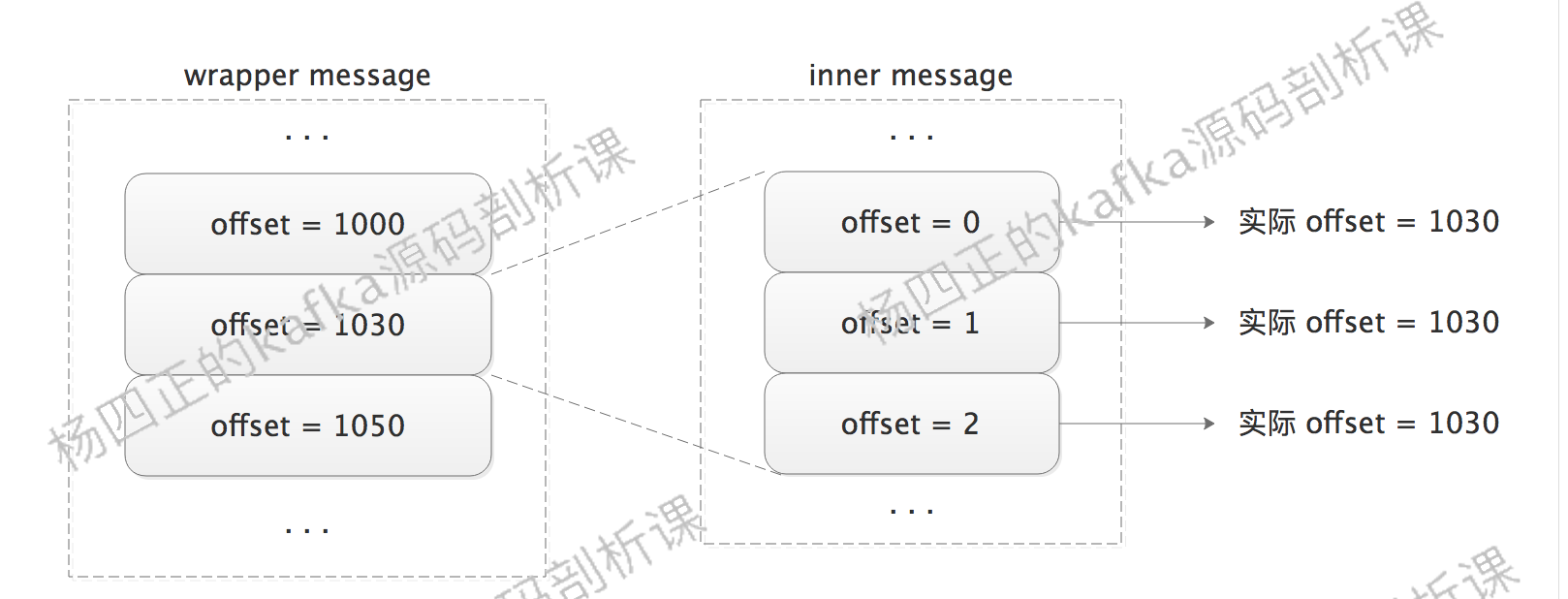
当 wrapper message 发送到 kafka broker 之后,broker 无需进行解压缩,直接存储即可,当 consumer 拉取 message 的时候,也是原封不动的进行传递,真正的解压缩在 consumer 完成,这样就可以节省 broker 解压缩和重新压缩的资源。
再谈 V1 版本中的时间戳
V1 版本 message 中的 timestamp 类型由 attributes 中的第 4 位标识,有 CreateTime 和 LogAppendTime 两种类型:
- CreateTime:timestamp 字段中记录的是 producer 生产这条 message 的时间戳
- LogAppendTime:timestamp 字段中记录的是 broker 将该 message 写入 segment 文件的时间戳。
在 producer 生成 message 的时候,message 中的时间戳是 CreateTime,wrapper message 中的 timestamp 是所有 inner message timestamp 的最大值。
当 message 传递到 broker 的时候,broker 会按照自身的 log.message.timestamp.type 配置(或 topic 的 message.timestamp.type 配置)(默认值为CreateTime)修改 wrapper message 的时间戳。如果 broker 使用的是 CreateTime,我们还可以设置 max.message.time.difference.ms 参数,当 message 中的时间戳与 broker 本地时间之差大于该配置值时,broker 会拒绝写入这条 message。
如果 broker 或是 topic 使用 LogAppendTime,那么会将 broker 本地时间直接设置到 message 的 timestamp 字段中,并将 attributes 中的 timestamp type 位修改为 1。如果是压缩 message,只会修改 wrapper message 中的 timestamp 和 timestamp type,不会修改 inner message,这是为了避免解压缩和重新压缩。也就是说,broker 只关心 wrapper message 的时间戳,忽略 inner message 的时间戳。
当 message 被拉去到 consumer 的时候,consumer 只会根据 timestampe type 的值进行处理。如果 wrapper message 为 CreateTime,则 consumer 使用 inner message 的 timestamp 作为 CreateTime;如果 wrapper message 为 LogAppendTime ,则 consumer 使用 wrapper message 作为所有 inner message 的 LogAppendTime,忽略 inner message 的 timestamp 值。
最后,message 中的 timestamp 也是时间戳索引的重要基础,这个我们后面介绍 broker 的时候,详细介绍。
V2 版本
在 kafka 0.11 版本之后,开始使用 V2 版本的 message 格式,同时也兼容 V0、V1 版本的 message,当然,使用旧版本的 message 也就无法使用 kafka 中的一些新特性。
V2 版本的 message 格式参考了 Protocol Buffer 的一些特性,引入了Varints(变长整型)和 ZigZag 编码,其中,Varints 是使用一个或多个字节来序列化整数的一种方法,数值越小,占用的字节数就越少,说白了,还是为了减少 message 的体积。ZigZag 编码是为了解决 Varints 对负数编码效率低的问题,ZigZag 会将有符号整数映射为无符号整数,从而提高 Varints 对绝对值较小的负数的编码效率 ,如下图所示:
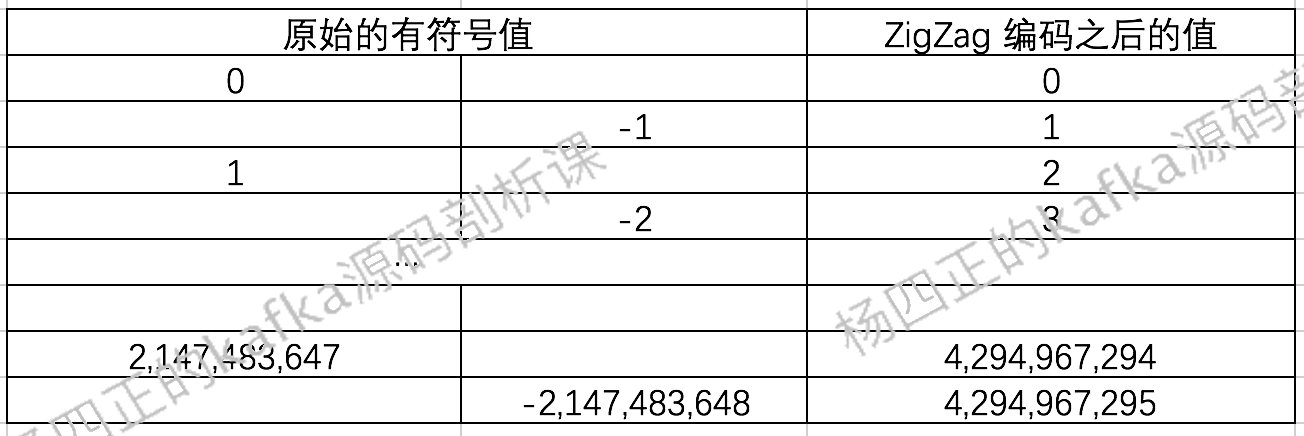
了解了 V2 版本格式的理论基础之后,我们来看 V2 中message 的格式(也被称为 Record):
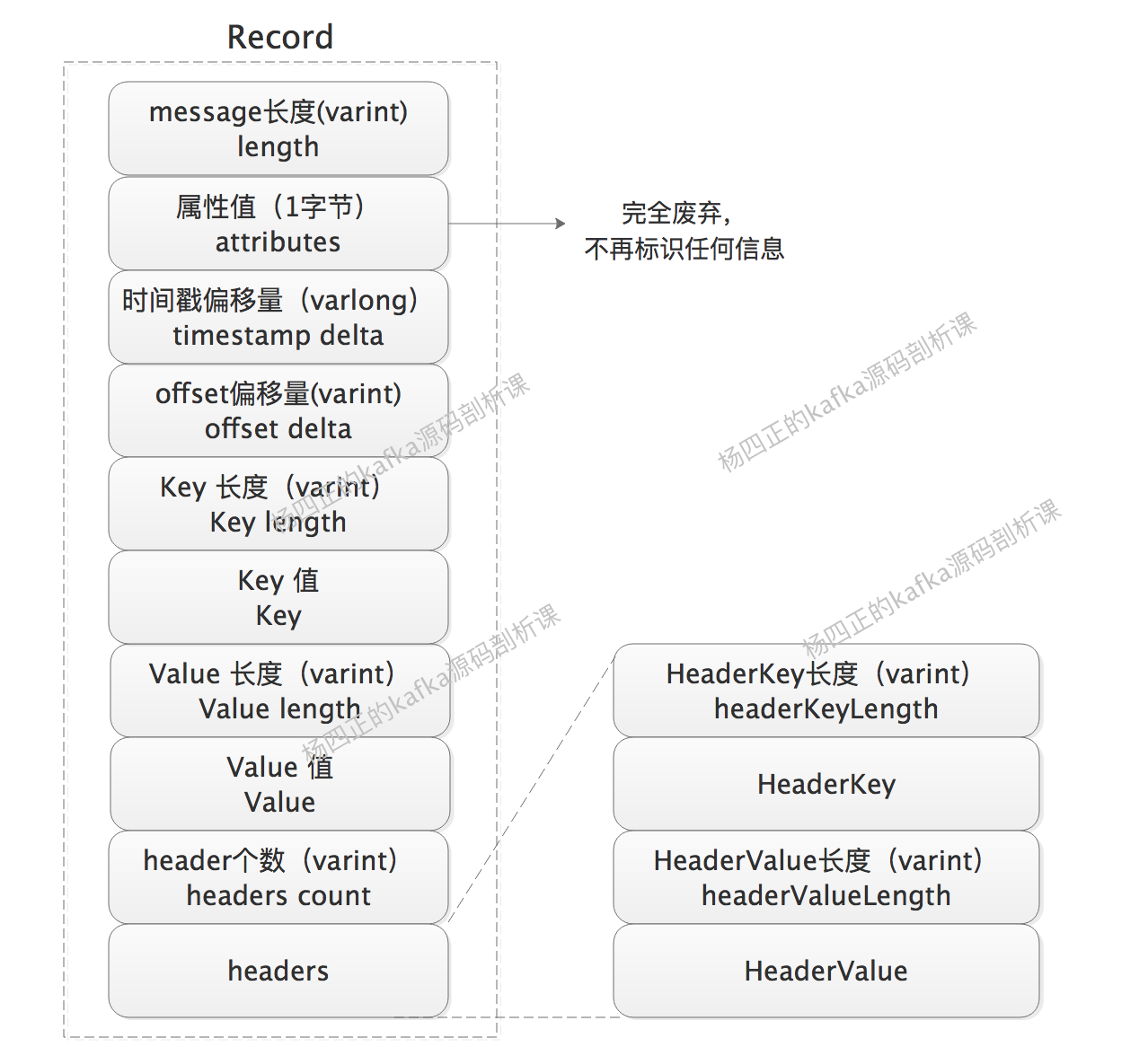
其中需要关注的是,所有标识长度的字段都是 varint(或 varlong),也就是变长字段,timestamp 和 offset 都是 delta 值,也就是偏移量。另外,就是 attribute 字段中的所有位都废弃了,并添加 header 扩展。
除了基础的 Record 格式之外,V2 版本中还定义了一个 Record Batch 的结构,同学们可以对比 V1 版本格式,Record 是内层结构,Record Batch 是外层结构,如下图所示:
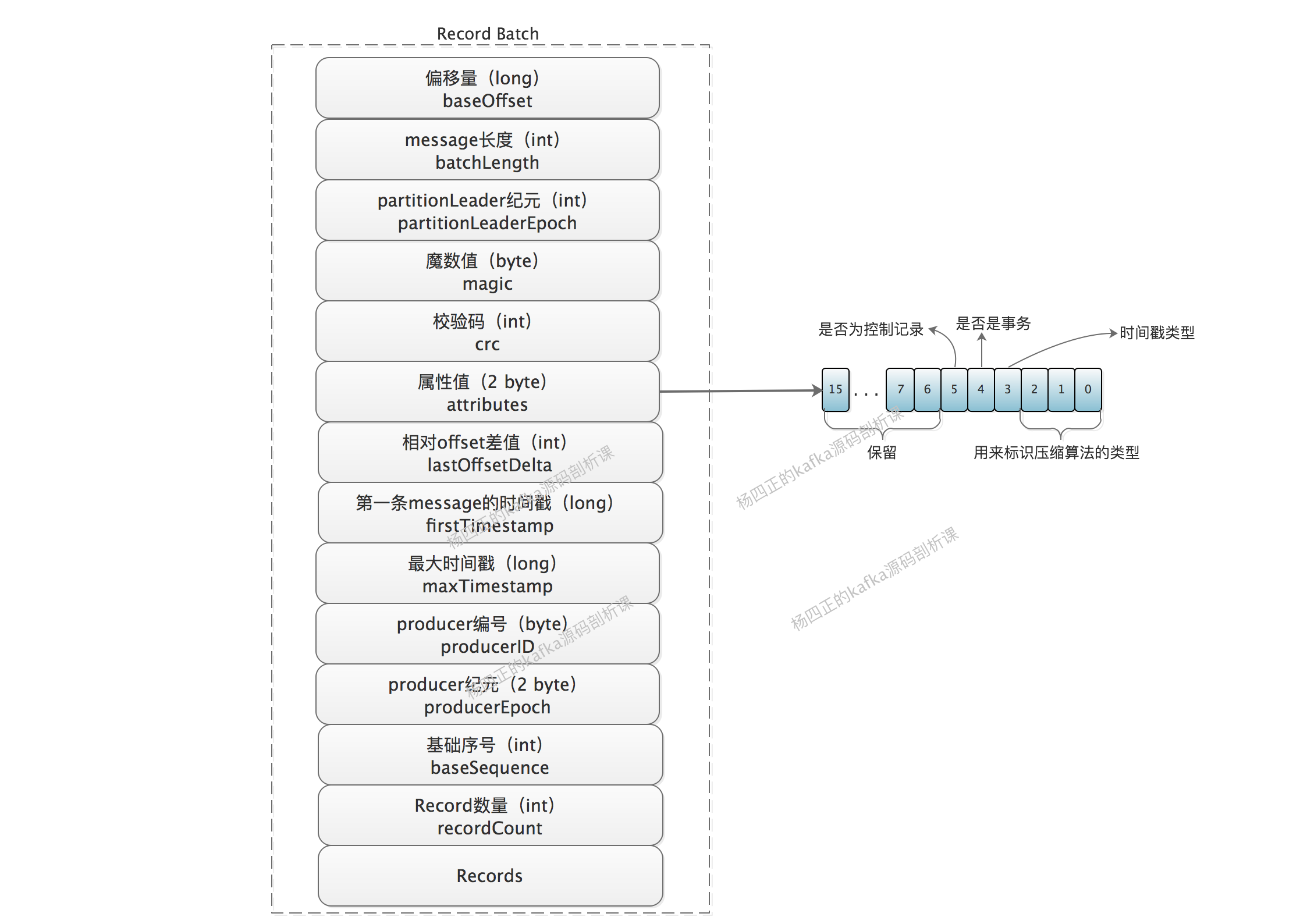
Record Batch 中包含的字段非常多,我们一个个来看:
- baseOffset:当前 RecordBatch 的起始位移,Record 中的 offset delta 与该 baseOffset 相加才能得到真正的 offset 值。当 RecordBatch 还在 producer 端的时候,offset 是 producer 分配的一个值,不是 partition 分配的,别搞混了。
- batchLength:RecordBatch 的总长度。
- partitionLeaderEpoch:用于标记目标 partition 中 leader replica 的纪元信息,后面介绍具体实现时会再次看到该值的相关实现。
- magic:V2 版本中的魔数值 2。
- crc 校验码:参与校验的部分是从属性值到 RecordBatch 末尾的全部数据,partitionLeaderEpoch 不在 CRC 里面是因为每次 broker 收到 RecordBatch 的时候,都会赋值 partitionLeaderEpoch,如果包含在 CRC 里面会导致需要重新计算CRC。这个实现后面会说。
- attributes:从 V1 版本中的 8 位扩展到 16 位,0~2 位表示压缩类型,第 3 位表示时间戳类型,第 4 位表示是否是事务型记录。所谓“事务”是Kafka的新功能,开启事务之后,只有在事务提交之后,事务型 consumer 才可以看到记录。5表示是否是 Control Record,这类记录总是单条出现,被包含在一个 control record batch 里面,它可以用于标记“事务是否已经提交”、“事务是否已经中止” 等,它只会在 broker 内处理,不会被传输给 consumer 和 producer,即对客户端是透明的。
- lastOffsetDelta:RecordBatch 最后一个 Record 的相对位移,用于 broker 确认 RecordBatch 中 Records 的组装正确性。
- firstTimestamp:RecordBatch 第一条 Record 的时间戳。
- maxTimestamp:RecordBatch 中最大的时间戳,一般情况下是最后一条消息的时间戳,用于 broker 确认RecordBatch 中 Records 的组装正确性。
- producer id:生产者编号,用于支持幂等性(Exactly Once 语义),参考KIP-98 - Exactly Once Delivery and Transactional Messaging。
- producer epoch:生产者纪元,用于支持幂等性(Exactly Once 语义)。
- base sequence:基础序号,用于支持幂等性(Exactly Once 语义),用于校验是否是重复 Record。
- records count:Record 的数量。
通过分析 V2 版本的消息格式我们知道,kafka message 不仅提供了类似事务、幂等等新功能,还对空间占用提供了足够的优化,总体提升很大
MemoryRecordsBuilder
了解了 kafka message 格式的演变之后,我们回到 KafkaProducer 的代码。
每个 MemoryRecordsBuilder 底层依赖一个 ByteBuffer 完成 message 的存储,我们后面会深入介绍 KafkaProducer 对 ByteBuffer 的管理。在 MemoryRecordsBuilder 中会将 ByteBuffer 封装成 ByteBufferOutputStream,ByteBufferOutputStream 实现了 OutputStream,这样我们就可以按照流的方式写入数据了。同时,ByteBufferOutputStream 提供了自动扩容底层 ByteBuffer 的能力。
还有一个需要关注的是 compressionType 字段,它用来指定当前 MemoryRecordsBuilder 使用哪种压缩算法来压缩 ByteBuffer 中的数据,kafka 目前已支持的压缩算法有:GZIP、SNAPPY、LZ4、ZSTD 四种,注意:只有 kafka V2 版本协议支持 ZSTD 压缩算法。
1 2 3 4 5 6 7 8 9 10 11 | public MemoryRecordsBuilder(ByteBuffer buffer,...) { // 省略其他参数
// 将MemoryRecordsBuilder关联的ByteBuffer封装成ByteBufferOutputStream流
this(new ByteBufferOutputStream(buffer), ...);
}
public MemoryRecordsBuilder(ByteBufferOutputStream bufferStream,...) { // 省略其他参数
// 省略其他字段的初始化
this.bufferStream = bufferStream;
// 在bufferStream流外层套一层压缩流,然后再套一层DataOutputStream流
this.appendStream = new DataOutputStream(compressionType.wrapForOutput(this.bufferStream, magic));
}
|
这样,我们得到的 appendStream 就如下图所示:
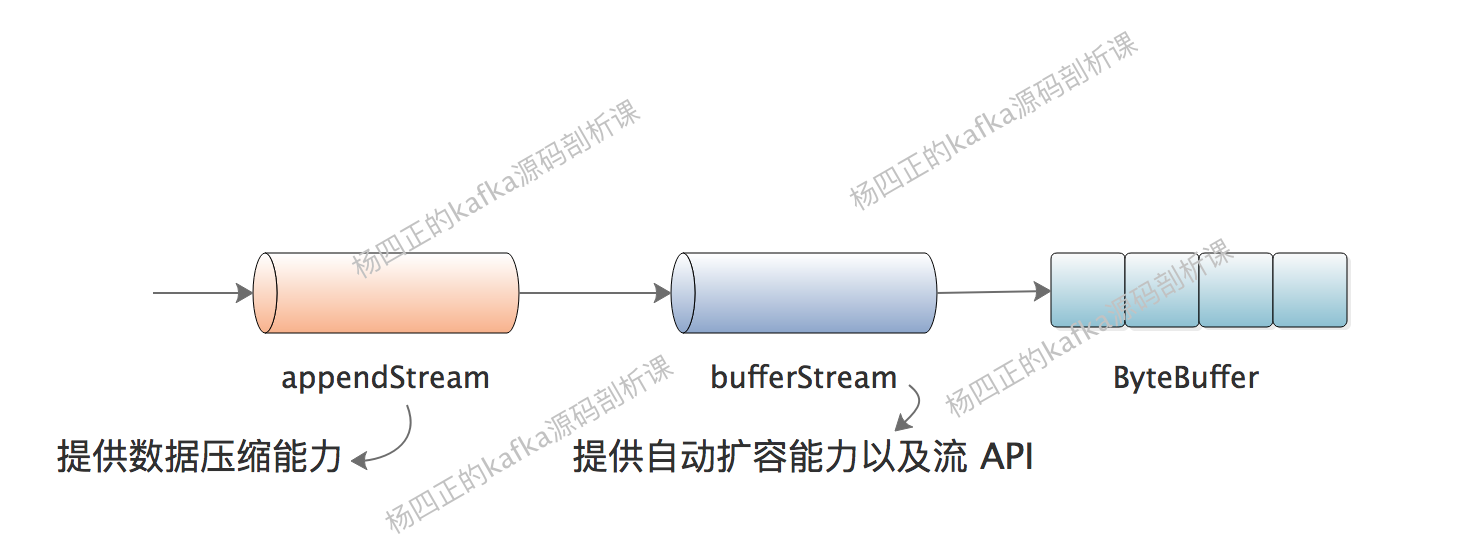
了解了 MemoryRecordsBuilder 底层的存储方式之后,我们来看 MemoryRecordsBuilder 的核心方法。首先是 appendWithOffset() 方法,逻辑并不复杂,需要明确的是 ProducerBatch 对标的 V2 中的 RecordBatch,我们写入的数据对标 V2 中的 Record:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | public Long append(long timestamp, ByteBuffer key, ByteBuffer value, Header[] headers) {
return appendWithOffset(nextSequentialOffset(), timestamp, key, value, headers);
}
private long nextSequentialOffset() {
// 这里的baseOffset是RecordBatch中的baseOffset,lastOffset用来记录当前写入Record的offset值,后面会用lastOffset-baseOffset计算offset delta。每次有新Record写入的时候,都会递增lastOffset
return lastOffset == null ? baseOffset : lastOffset + 1;
}
private Long appendWithOffset(long offset, boolean isControlRecord, long timestamp, ByteBuffer key, ByteBuffer value, Header[] headers) {
if (isControlRecord != this.isControlBatch) // 检查isControl标志是否一致
throw new IllegalArgumentException("...");
if (lastOffset != null && offset <= this.lastOffset) // 保证offset递增
throw new IllegalArgumentException("...");
if (timestamp < 0 && timestamp != RecordBatch.NO_TIMESTAMP) // 检查时间戳
throw new IllegalArgumentException("...");
// 检查:只有V2版本message才能有header
if (magic < RecordBatch.MAGIC_VALUE_V2 && headers != null && headers.length > 0)
throw new IllegalArgumentException("...");
if (this.firstTimestamp == null) // 更新firstTimestamp
this.firstTimestamp = timestamp;
if (magic > RecordBatch.MAGIC_VALUE_V1) { // 针对V2的写入
appendDefaultRecord(offset, timestamp, key, value, headers);
return null;
} else { // 针对V0、V1的写入
return appendLegacyRecord(offset, timestamp, key, value, magic);
}
}
|
appendDefaultRecord() 方法中会计算 Record 中的 offsetDelta、timestampDelta,然后完成 Record 写入,最后更新RecordBatch 的元数据,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 | private void appendDefaultRecord(long offset, long timestamp, ByteBuffer key, ByteBuffer value,
Header[] headers) throws IOException {
ensureOpenForRecordAppend(); // 检查appendStream状态
// 计算offsetDelta
int offsetDelta = (int) (offset - this.baseOffset);
// 计算timestampDelta
long timestampDelta = timestamp - this.firstTimestamp;
// 这里使用的DefaultRecord是一个工具类,其writeTo()方法会按照V2 Record的格式向appendStream流中
int sizeInBytes = DefaultRecord.writeTo(appendStream, offsetDelta, timestampDelta, key, value, headers);
// 修改RecordBatch中的元信息,例如,Record数量(numRecords)
recordWritten(offset, timestamp, sizeInBytes);
}
|
MemoryRecordsBuilder 中另一个需要关注的方法是 hasRoomFor() 方法,它主要用来估计当前 MemoryRecordsBuilder 是否还有空间来容纳此次写入的 Record,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | public boolean hasRoomFor(long timestamp, ByteBuffer key, ByteBuffer value, Header[] headers) {
// 检查两个状态,一个是appendStream流状态,另一个是当前已经写入的预估字节数是否以及超过了writeLimit字段指定的写入上限,这里的writeLimit字段用来记录MemoryRecordsBuilder能够写入的字节数上限值
if (isFull())
return false;
// 每个RecordBatch至少可以写入一个Record,此时要是一个Record都没有,则可以继续写入
if (numRecords == 0)
return true;
final int recordSize;
if (magic < RecordBatch.MAGIC_VALUE_V2) { // V0、V1版本的判断
recordSize = Records.LOG_OVERHEAD + LegacyRecord.recordSize(magic, key, value);
} else {
// 估算此次写入的Record大小
int nextOffsetDelta = lastOffset == null ? 0 : (int) (lastOffset - baseOffset + 1);
long timestampDelta = firstTimestamp == null ? 0 : timestamp - firstTimestamp;
recordSize = DefaultRecord.sizeInBytes(nextOffsetDelta, timestampDelta, key, value, headers);
}
// 已写入字节数+此次写入Record的字节数不能超过writeLimit
return this.writeLimit >= estimatedBytesWritten() + recordSize;
}
|
ProducerBatch
接下来我们向上走一层,来看 ProducerBatch 的实现,其中最核心方法是 tryAppend() 方法,核心步骤如下:
- 通过 MemoryRecordsBuilder的hasRoomFor() 方法检查当前 ProducerBatch 是否还有足够的空间来存储此次待写入的 Record。
- 调用 MemoryRecordsBuilder.append() 方法将 Record 追加到底层的 ByteBuffer 中。
- 创建 FutureRecordMetadata 对象,FutureRecordMetadata 继承了 Future 接口,对应此次 Record 的发送。
- 将 FutureRecordMetadata 对象以及 Record 关联的 Callback 回调封装成Thunk 对象,记录到 thunks (List类型)中。
下面是 ProducerBatch.tryAppend() 方法的具体实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | public FutureRecordMetadata tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, long now) {
// 检查MemoryRecordsBuilder是否还有空间继续写入
if (!recordsBuilder.hasRoomFor(timestamp, key, value, headers)) {
return null; // 没有空间写入的话,则返回null
} else {
// 调用append()方法写入Record
Long checksum = this.recordsBuilder.append(timestamp, key, value, headers);
// 更新maxRecordSize和lastAppendTime
this.maxRecordSize = Math.max(this.maxRecordSize, AbstractRecords.estimateSizeInBytesUpperBound(magic(),
recordsBuilder.compressionType(), key, value, headers));
this.lastAppendTime = now;
// 创建FutureRecordMetadata对象
FutureRecordMetadata future = new FutureRecordMetadata(this.produceFuture,
this.recordCount,timestamp, checksum,
key == null ? -1 : key.length,
value == null ? -1 : value.length, Time.SYSTEM);
// 将Callback和FutureRecordMetadata记录到thunks中
thunks.add(new Thunk(callback, future));
this.recordCount++; // 更新recordCount字段
return future; // 返回FutureRecordMetadata
}
}
|
除了 MemoryRecordsBuilder 之外,ProducerBatch 中还记录了很多其他关键信息:

这里我们先来关注 ProduceRequestResult 这个类,其中维护了一个 CountDownLatch 对象(count 值为 1),实现了类似于Future的功能。当 ProducerBatch 形成的请求被 broker 端响应(正常响应、超时、异常响应)或是 KafkaProducer 关闭的时候,都会调用 ProduceRequestResult.done() 方法,该方法就会调用 CountDownLatch 对象的 countDown() 方法唤醒阻塞在 CountDownLatch 对象的 await() 方法的线程。这些线程后续可以通过 ProduceRequestResult 的 error 字段来判断此次请求是成功还是失败。
在 ProduceRequestResult 中还有一个 baseOffset 字段,用来记录 broker 端为关联 ProducerBatch 中第一条 Record 分配的 offset 值,这样,每个 Record 的真实 offset 就可以根据自身在 ProducerBatch 的位置计算出来了(Record 的真实 offset = ProduceRequestResult.baseOffset + relativeOffset)。
接下来看 FutureRecordMetadata,它实现了 JDK 中的 Future 接口,表示一个 Record 的状态。FutureRecordMetadata 中除了维护一个关联的 ProduceRequestResult 对象之外,还维护了一个 relativeOffset 字段,relativeOffset 用来记录对应 Record 在 ProducerBatch 中的偏移量。
在 FutureRecordMetadata 中,有两个值得注意的方法,一个是 get() 方法,其中会依赖ProduceRequestResult中的CountDown来实现阻塞等待,并调用 value() 方法返回 RecordMetadata 对象:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | public RecordMetadata get(long timeout, TimeUnit unit) throws InterruptedException, ExecutionException, TimeoutException {
// 计算超时时间
long now = time.milliseconds();
long timeoutMillis = unit.toMillis(timeout);
long deadline = Long.MAX_VALUE - timeoutMillis < now ? Long.MAX_VALUE : now + timeoutMillis;
// 依赖ProduceRequestResult中的CountDown来实现阻塞等待
boolean occurred = this.result.await(timeout, unit);
if (!occurred)
throw new TimeoutException("Timeout after waiting for " + timeoutMillis + " ms.");
if (nextRecordMetadata != null) // 可以先忽略nextRecordMetadata,后面介绍split的时候,再深入介绍
return nextRecordMetadata.get(deadline - time.milliseconds(), TimeUnit.MILLISECONDS);
// 调用value()方法返回RecordMetadata对象
return valueOrError();
}
|
另一个是 value() 方法,其中会将 partition信息、baseOffset、relativeOffset、时间戳(LogAppendTime或CreateTime)等信息封装成 RecordMetadata 对象返回:
1 2 3 4 5 6 7 8 | RecordMetadata value() {
if (nextRecordMetadata != null) // 先忽略nextRecordMetadata
return nextRecordMetadata.value();
// 将partition信息、baseOffset、relativeOffset、时间戳(LogAppendTime或CreateTime)等信息封装成RecordMetadata对象返回
return new RecordMetadata(result.topicPartition(), this.result.baseOffset(),
this.relativeOffset, timestamp(), this.checksum,
this.serializedKeySize, this.serializedValueSize);
}
|
最后来看 ProducerBatch 中的 thunks 集合,其中的每个 Thunk 对象对应一个 Record 对象,在 Thunk 对象中记录了对应 Record 关联的 Callback 对象以及关联的 FutureRecordMetadata 对象。
了解了 ProducerBatch 写入数据的相关内容之后,我们回到 ProducerBatch 来关注其 done() 方法。当 KafkaProducer 收到 ProducerBatch 对应的正常响应、或超时、或关闭生产者时,都会调用 ProducerBatch 的 done()方法。在 done() 方法中,ProducerBatch 首先会更新 finalState 状态,然后调用 completeFutureAndFireCallbacks() 方法触发各个 Record 的 Callback 回调,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | public boolean done(long baseOffset, long logAppendTime, RuntimeException exception) {
// 根据exception字段决定此次ProducerBatch发送的最终状态
final FinalState tryFinalState = (exception == null) ? FinalState.SUCCEEDED : FinalState.FAILED;
// CAS操作更新finalState状态,只有第一次更新的时候,才会触发completeFutureAndFireCallbacks()方法
if (this.finalState.compareAndSet(null, tryFinalState)) {
completeFutureAndFireCallbacks(baseOffset, logAppendTime, exception);
return true;
}
// done()方法可能被调用一次或是两次,如果是SUCCEED状态切换成其他的失败状态,直接会抛出异常
if (this.finalState.get() != FinalState.SUCCEEDED) {
// 省略日志输出代码
} else {
throw new IllegalStateException("...");
}
return false;
}
|
在 completeFutureAndFireCallbacks() 方法中,会遍历 thunks 集合触发每个 Record 的 Callback,更新 ProduceRequestResult 中的 baseOffset、logAppendTime、error字段,并调用其 done() 方法释放阻塞在其上的线程,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | private void completeFutureAndFireCallbacks(long baseOffset, long logAppendTime, RuntimeException exception) {
// 更新ProduceRequestResult中的baseOffset、logAppendTime、error字段
produceFuture.set(baseOffset, logAppendTime, exception);
// 遍历thunks集合,触发每个Record的Callback回调
for (Thunk thunk : thunks) { // 省略try/catch代码块
if (exception == null) {
RecordMetadata metadata = thunk.future.value();
if (thunk.callback != null)
thunk.callback.onCompletion(metadata, null);
} else {
if (thunk.callback != null)
thunk.callback.onCompletion(null, exception);
}
}
// 调用底层CountDownLatch.countDown()方法,释放阻塞在其上的线程
produceFuture.done();
}
|
BufferPool
前面提到,MemoryRecordsBuilder 底层使用 ByteBuffer 来存储写入的 Record 数据,但是创建 ByteBuffer 对象本身是一种比较消耗资源的行为,所以 KafkaProducer 使用 BufferPool 来实现 ByteBuffer 的统一管理。BufferPool 说白了就是一个 ByteBuffer 的资源池,当需要 ByteBuffer 的时候,我们就从其中获取,当使用完成之后,就将 ByteBuffer 归还到 BufferPool 中。
BufferPool 是一个比较简单的资源池实现,它只会针对特定大小(poolableSize 字段)的 ByteBuffer 进行管理,对于其他大小的 ByteBuffer 选择视而不见(Netty 里面 Buffer 池更加复杂,之后介绍 Netty 源码的时候会详细说)。
一般情况下,我们会调整 ProducerBatch 的大小(batch.size 配置(指定 Record 个数)* 单个 Record 的预估大小),使每个 ProducerBatch 可以缓存多条 Record。但当出现一条 Record 的字节数大于整个 ProducerBatch 的意外情况时,就不会尝试从 BufferPool 申请 ByteBuffer,而是直接新分配 ByteBuffer 对象,待其被使用完后直接丢弃由GC回收。
下面来看一下 BufferPool 的核心字段:

BufferPool 分配 ByteBuffer 的核心逻辑位于 allocate() 方法中,逻辑并不复杂,直接上代码和注释:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 | public ByteBuffer allocate(int size, long maxTimeToBlockMs) throws InterruptedException {
if (size > this.totalMemory) // 首先检查目标ByteBuffer的大小是否大于了
throw new IllegalArgumentException("...");
ByteBuffer buffer = null;
this.lock.lock(); // 加锁
// 检查当前BufferPool的状态,如果当前BufferPool处于关闭状态,则直接抛出异常(略)
try {
// 目标大小恰好为poolableSize,且free列表为空的话,直接复用free列表中的ByteBuffer
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();
// 计算free列表中的ByteBuffer总空间
int freeListSize = freeSize() * this.poolableSize;
// 当前BufferPool能够释放出目标大小的空间,则直接通过freeUp()方法进行分配
if (this.nonPooledAvailableMemory + freeListSize >= size) {
freeUp(size);
this.nonPooledAvailableMemory -= size;
} else {
int accumulated = 0;
// 如果当前BufferPool空间不足以提供目标空间,则需要阻塞当前线程
Condition moreMemory = this.lock.newCondition();
try {
// 计算当前线程最大阻塞时长
long remainingTimeToBlockNs = TimeUnit.MILLISECONDS.toNanos(maxTimeToBlockMs);
this.waiters.addLast(moreMemory);
while (accumulated < size) { // 循环等待分配成功
long startWaitNs = time.nanoseconds();
long timeNs;
boolean waitingTimeElapsed;
try {
// 当前线程阻塞等待,返回结果为false则表示阻塞超时
waitingTimeElapsed = !moreMemory.await(remainingTimeToBlockNs, TimeUnit.NANOSECONDS);
} finally {
long endWaitNs = time.nanoseconds();
timeNs = Math.max(0L, endWaitNs - startWaitNs);
}
// 检查当前BufferPool的状态,如果当前BufferPool处于关闭状态,则直接抛出异常(略)
if (waitingTimeElapsed) {
// 指定时长内依旧没有获取到目标大小的空间,则抛出异常
throw new BufferExhaustedException("...");
}
remainingTimeToBlockNs -= timeNs;
// 目标大小是poolableSize大小的ByteBuffer,且free中出现了空闲的ByteBuffer
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
buffer = this.free.pollFirst();
accumulated = size;
} else {
// 先分配一部分空间,并继续等待空闲空间
freeUp(size - accumulated);
int got = (int) Math.min(size - accumulated, this.nonPooledAvailableMemory);
this.nonPooledAvailableMemory -= got;
accumulated += got;
}
}
accumulated = 0;
} finally {
// 如果上面的while循环不是正常结束的,则accumulated不为0,这里会归还
this.nonPooledAvailableMemory += accumulated;
this.waiters.remove(moreMemory);
}
}
} finally {
// 当前BufferPool要是还存在空闲空间,则唤醒下一个等待线程来尝试分配ByteBuffer
try {
if (!(this.nonPooledAvailableMemory == 0 && this.free.isEmpty()) && !this.waiters.isEmpty())
this.waiters.peekFirst().signal();
} finally {
lock.unlock(); // 解锁
}
}
if (buffer == null)
// 分配成功但无法复用free列表中的ByteBuffer(可能目标大小不是poolableSize大小,或是free列表本身是空的)
return safeAllocateByteBuffer(size);
else
return buffer; // 直接复用free大小的ByteBuffer
}
// 这里简单看一下freeUp()方法,这里会不断从free列表中释放空闲的ByteBuffer来补充nonPooledAvailableMemory
private void freeUp(int size) {
while (!this.free.isEmpty() && this.nonPooledAvailableMemory < size)
this.nonPooledAvailableMemory += this.free.pollLast().capacity();
}
|
从 BufferPool 中分配出来的 ByteBuffer 在使用之后,会调用 deallocate() 方法来释放,具体实现如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | public void deallocate(ByteBuffer buffer, int size) {
lock.lock(); // 加锁
try {
// 如果待释放的ByteBuffer大小为poolableSize,则直接放入free列表中
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
// 如果不是poolableSize大小,则由 JVM GC来回收ByteBuffer并增加nonPooledAvailableMemory
this.nonPooledAvailableMemory += size;
}
// 唤醒waiters中的第一个阻塞线程
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock(); // 释放锁
}
}
|
RecordAccumulator
分析完 MemoryRecordsBuilder、ProducerBatch 以及 BufferPool 与写入相关的方法之后,我们再来看 RecordAccumulator 的实现。
分析一个类的时候,还是要先看其数据结构,然后再来看其行为(方法)。RecordAccumulator 中的关键字段如下:

在前面分析 KafkaProducer.doSend() 方法发送 message 的时候,直接调用了 RecordsAccumulator.append() 方法,这也是调用 ProducerBatch.tryAppend() 方法将消息追加到底层 MemoryRecordsBuilder 的地方。下面我们就来看 RecordAccumulator.append() 方法的核心逻辑:
- 在 batches 集合中查找目标 partition 对应的 ArrayDeque 集合,如果查找失败,则创建新的ArrayDeque,并添加到 batches 集合中。
- 对步骤 1 中拿到的 ArrayDeque 集合进行加锁。这里使用 synchronized 代码块进行加锁。
- 执行 tryAppend() 方法,尝试向 ArrayDeque 中的最后一个 ProducerBatch 写入 Record。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | private RecordAppendResult tryAppend(long timestamp, byte[] key, byte[] value, Header[] headers, Callback callback, Deque<ProducerBatch> deque, long nowMs) {
// 获取ArrayDeque<ProducerBatch>集合中最后一个ProducerBatch对象
ProducerBatch last = deque.peekLast();
if (last != null) {
// 尝试将消息写入last这个ProducerBatch对象
FutureRecordMetadata future = last.tryAppend(timestamp, key, value, headers, callback, nowMs);
if (future == null)
// 写入失败,则关闭last指向的ProducerBatch对象,同时返回null表示写入失败
last.closeForRecordAppends();
else
// 写入成功,则返回RecordAppendResult对象
return new RecordAppendResult(future, deque.size() > 1 || last.isFull(), false, false);
}
return null;
}
|
- synchronized 块执行结束,自动释放锁。
- 如果步骤 3 中的追加操作成功,则返回 RecordAppendResult。
- 如果步骤 3 中的追加 Record 失败,则可能是因为当前使用的 ProducerBatch 已经被填满了。这里会判断abortOnNewBatch 参数是否为 true,如果是的话,会立即返回 RecordAppendResult 结果(其中的 abortForNewBatch 字段设置为 true),返回的 RecordAppendResult 中如果 abortForNewBatch 为true,会再触发一次 RecordAccumulator.append()方法。
- 如果 abortForNewBatch 参数不为 true,则会开始从 BufferPool 中分配新的 ByteBuffer,并封装成新的 ProducerBatch 对象。
- 再次对 ArrayDeque 加锁,并尝试将 Record 追加到新建的 ProducerBatch 中,同时将新建的ProducerBatch追加到对应的 Deque 尾部。
- 将新建的 ProducerBatch 添加到 incomplete集合中。synchronized块结束,自动解锁。
- 返回 RecordAppendResult,RecordAppendResult 会中 batchIsFull 字段和 newBatchCreated 字段会作为唤醒Sender 线程的条件。KafkaProducer.doSend() 方法中唤醒 Sender 线程的代码片段如下:
1 2 3 4 | if (result.batchIsFull || result.newBatchCreated) {
// 当此次写入填满一个ProducerBatch或是有新ProducerBatch创建的时候,会唤醒Sender线程来进行发送
this.sender.wakeup();
}
|
下面来看 RecordAccumulator.append() 方法的具体实现:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 | public RecordAppendResult append(TopicPartition tp, long timestamp,
byte[] key, byte[] value, Header[] headers, Callback callback,
long maxTimeToBlock, boolean abortOnNewBatch, long nowMs) throws InterruptedException {
// 统计正在向RecordAccumulator中写入的Record数量
appendsInProgress.incrementAndGet();
ByteBuffer buffer = null;
if (headers == null) headers = Record.EMPTY_HEADERS;
try {
// 在 batches 集合中查找目标 partition 对应的 ArrayDeque<ProducerBatch> 集合,
// 如果查找失败,则创建新的ArrayDeque<ProducerBatch>,并添加到 batches 集合中。
Deque<ProducerBatch> dq = getOrCreateDeque(tp);
synchronized (dq) { // 对ArrayDeque<ProducerBatch>加锁
// 如果追加操作成功,则返回RecordAppendResult
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null) // 追加成功,则返回的appendResult不为null
return appendResult;
}
// 如果追加Record失败,则可能是因为当前使用的ProducerBatch已经被填满了,这里会根据abortOnNewBatch参数,
// 决定是否立即返回RecordAppendResult结果,返回的RecordAppendResult中如果abortForNewBatch为true,
// 会再触发一次append()方法
if (abortOnNewBatch) {
return new RecordAppendResult(null, false, false, true);
}
byte maxUsableMagic = apiVersions.maxUsableProduceMagic();
int size = Math.max(this.batchSize, AbstractRecords.estimateSizeInBytesUpperBound(maxUsableMagic, compression, key, value, headers));
// 从BufferPool中分配ByteBuffer
buffer = free.allocate(size, maxTimeToBlock);
nowMs = time.milliseconds();
synchronized (dq) { // 再次对ArrayDeque<ProducerBatch>加锁
if (closed)
throw new KafkaException("Producer closed while send in progress");
// 再次尝试tryAppend()方法追加Record
RecordAppendResult appendResult = tryAppend(timestamp, key, value, headers, callback, dq, nowMs);
if (appendResult != null) {
return appendResult;
}
// 将ByteBuffer封装成MemoryRecordsBuilder
MemoryRecordsBuilder recordsBuilder = recordsBuilder(buffer, maxUsableMagic);
// 创建ProducerBatch对象
ProducerBatch batch = new ProducerBatch(tp, recordsBuilder, nowMs);
// 通过tryAppend()方法将Record追加到ProducerBatch中
FutureRecordMetadata future = Objects.requireNonNull(batch.tryAppend(timestamp, key, value, headers,
callback, nowMs));
// 将ProducerBatch添加到ArrayDeque<ProducerBatch>中
dq.addLast(batch);
// 将ProducerBatch添加到IncompleteBatches中
incomplete.add(batch);
buffer = null; // 置空buffer
return new RecordAppendResult(future, dq.size() > 1 || batch.isFull(), true, false);
}
} finally {
if (buffer != null) // 如果buffer不为空,则表示写入过程中出现异常,这里会释放ByteBuffer
free.deallocate(buffer);
// 当前Record已经写入完成,递减appendsInProgress
appendsInProgress.decrementAndGet();
}
}
|
这里我们清晰的看到,对 ArrayDeque 进行加锁的代码,ArrayDeque 本身是非线程安全的集合,加锁处理可以理解,但是为什么分两次加锁呢?这主要是因为在向 BufferPool 申请新 ByteBuffer 的时候,可能会导致阻塞。我们假设在一个 synchronized 块中完成上面所有追加操作,线程A发送的 Record 比较大,需要向 BufferPool 申请新空间,而此时 BufferPool 空间不足,线程A 就会阻塞在 BufferPool 上等待,此时它依然持有对应 ArrayDeque 的锁;线程B 发送的 Record 较小,而此时的 ArrayDeque 最后一个 ProducerBatch 剩余空间正好足够写入该 Record,但是由于线程A 未释放Deque的锁,所以也需要一起等待,这就造成线程 B 不必要阻塞,降低了吞吐量。这里本质其实是通过减少锁的持有时间来进行的优化。
除了两次 ArrayDeque 加锁操作,我们还看到第二次加锁后重试,这主要是为了防止多个线程并发从 BufferPool 申请空间后,造成内部碎片。这种场景如下图所示,线程 A 发现最后一个 ProducerBatch 空间不足,申请空间并创建一个新ProducerBatch 对象添加到 ArrayDeque 的尾部,然后线程 B 与线程 A 并发执行,也将新创建一个 ProducerBatch 添加到ArrayDeque 尾部。从上面 tryAppend() 方法的逻辑中我们可以看到,后续的写入只会在 ArrayDeque 尾部的 ProducerBatch 上进行,这样就会导致下图中的 ProducerBatch3 不再被写入,从而出现内部碎片:
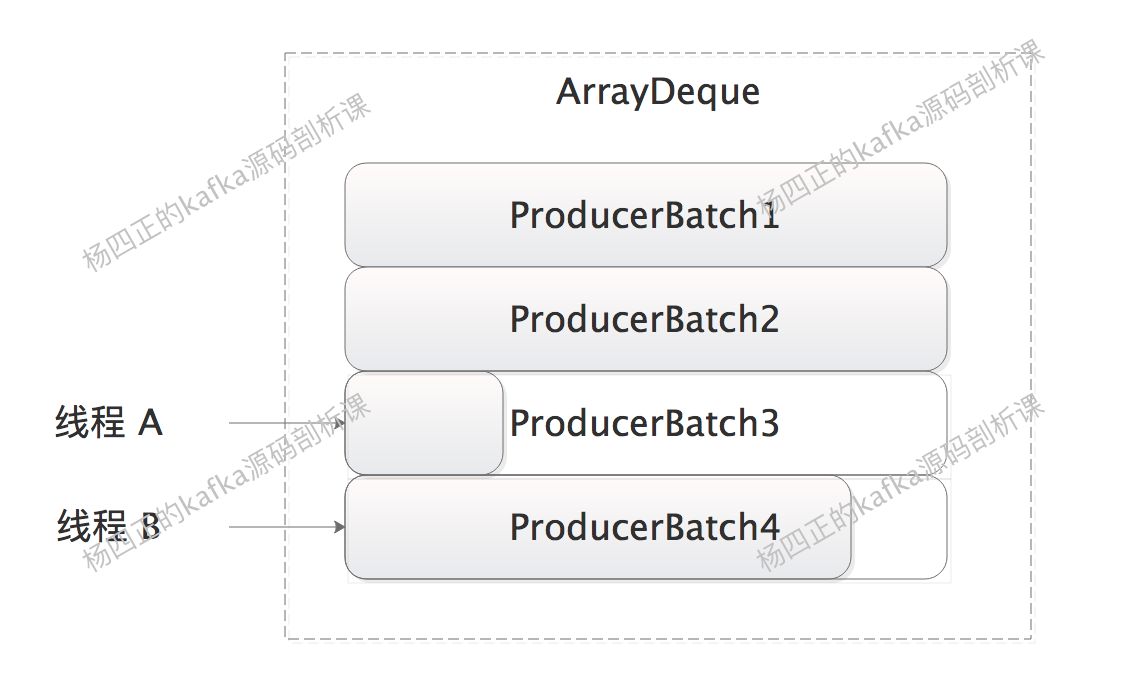
了解了 RecordAccumulator 对 Record 写入的支持之后,我们再来看 RecordAccumulator.ready()方法,它是 Sender 线程发送 Record 到 kafka broker 之前被调用的,该方法会根据集群元数据,获取能够接收待发送 Record 的节点集合,具体筛选条件如下:
- batchs 集合中的 ArrayDeque 中有多个 RecordBatch 或是第一个 RecordBatch 是否满了。
- 等待时间是否足够长。这主要是两个方面,如果有重试的话,需要超过 retryBackoffMs 的退避时长;如果没有重试的话,需要超过 linger.ms 配置指定的等待时长(linger.ms 默认是 0)。
- 是否有其他线程在等待 BufferPool 释放空间。
- 是否有线程调用了 flush() 方法,正在等待 flush 操作完成。
下面来看是 ready 方法的代码,它会遍历batches集合中每个分区,首先查找目标 partition 的 leader replica 所在的Node,只有知道 Node 信息,KafkaProducer 才知道往哪里发。然后针对每个 ArrayDeque 进行处理,如果满足上述四个条件,则将对应的 Node 信息记录到 readyNodes 集合中。最后,ready() 方法返回的是 ReadyCheckResult 对象,其中记录了满足发送条件的 Node 集合、在遍历过程中找不到 leader replica 的 topic 以及下次调用 ready() 方法进行检查的时间间隔。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | public ReadyCheckResult ready(Cluster cluster, long nowMs) {
// 用来记录可以向哪些Node节点发送数据
Set<Node> readyNodes = new HashSet<>();
// 记录下次需要调用ready()方法的时间间隔
long nextReadyCheckDelayMs = Long.MAX_VALUE;
// 记录Cluster元数据中找不到leader replica的topic
Set<String> unknownLeaderTopics = new HashSet<>();
// 是否有线程在阻塞等待BufferPool释放空间
boolean exhausted = this.free.queued() > 0;
// 下面遍历batches集合,对其中每个partition的leader replica所在的Node都进行判断
for (Map.Entry<TopicPartition, Deque<ProducerBatch>> entry : this.batches.entrySet()) {
Deque<ProducerBatch> deque = entry.getValue();
synchronized (deque) {
ProducerBatch batch = deque.peekFirst();
if (batch != null) {
TopicPartition part = entry.getKey();
// 查找目标partition的leader replica所在的节点
Node leader = cluster.leaderFor(part);
if (leader == null) {
// leader replica找不到,会认为是异常情况,不能发送消息
unknownLeaderTopics.add(part.topic());
} else if (!readyNodes.contains(leader) && !isMuted(part)) {
boolean full = deque.size() > 1 || batch.isFull();
long waitedTimeMs = batch.waitedTimeMs(nowMs);
boolean backingOff = batch.attempts() > 0 && waitedTimeMs < retryBackoffMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
boolean expired = waitedTimeMs >= timeToWaitMs;
// 检查上述五个条件,找到此次发送涉及到的Node
boolean sendable = full || expired || exhausted || closed || flushInProgress();
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
// 记录下次需要调用ready()方法检查的时间间隔
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeaderTopics);
}
|
调用 RecordAccumulator.ready() 方法得到的 readyNodes 集合后,此集合还要经过 NetworkClient 的过滤(在介绍Sender线程的时候再详细介绍)之后,才能得到最终能够发送消息的 Node 集合。
之后,Sender 线程会调用 RecordAccumulator.drain() 方法会根据上述 Node 集合获取要发送的 ProducerBatch,返回Map<Integer, List>集合,其中的 Key 是目标 Node 的 Id,Value 是此次待发送的 ProducerBatch 集合。在调用KafkaProducer的上层业务逻辑中,则是按照TopicPartition的方式产生数据,它只关心发送到哪个TopicPartition,并不关心这些TopicPartition在哪个Node节点上。在网络IO层面,生产者是面向Node节点发送消息数据,它只建立到Node的连接并发送数据,并不关心这些数据属于哪个TopicPartition。drain( )方法的核心功能是将 TopicPartition -> ProducerBatch 集合的映射关系,转换成了 Node -> ProducerBatch 集合的映射。下面是 drain() 方法的核心代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | public Map<Integer, List<ProducerBatch>> drain(Cluster cluster, Set<Node> nodes, int maxSize, long now) {
if (nodes.isEmpty())
return Collections.emptyMap();
// 转换后的结果,Key是目标Node的Id,Value是发送到目标Node的ProducerBatch集合
Map<Integer, List<ProducerBatch>> batches = new HashMap<>();
for (Node node : nodes) {
// 获取目标Node的ProducerBatch集合
List<ProducerBatch> ready = drainBatchesForOneNode(cluster, node, maxSize, now);
batches.put(node.id(), ready);
}
return batches;
}
private List<ProducerBatch> drainBatchesForOneNode(Cluster cluster, Node node, int maxSize, long now) {
int size = 0;
// 获取当前Node上的partition集合
List<PartitionInfo> parts = cluster.partitionsForNode(node.id());
// 记录发往目标Node的ProducerBatch集合
List<ProducerBatch> ready = new ArrayList<>();
// drainIndex是batches的下标,记录上次发送停止时的位置,下次继续从此位置开始发送。如果始终从
// 索引0的队列开始发送,可能会出现一直只发送前几个partition的消息的情况,造成其他partition饥饿。
int start = drainIndex = drainIndex % parts.size();
do {
// 获取partition的元数据
PartitionInfo part = parts.get(drainIndex);
TopicPartition tp = new TopicPartition(part.topic(), part.partition());
this.drainIndex = (this.drainIndex + 1) % parts.size();
// 检查目标partition对应的ArrayDeque是否为空(略)
synchronized (deque) {
// 获取ArrayDeque中第一个ProducerBatch对象
ProducerBatch first = deque.peekFirst();
if (first == null)
continue;
// 重试操作的话,需要检查是否已经等待了足够的退避时间(略)
if (size + first.estimatedSizeInBytes() > maxSize && !ready.isEmpty()) {
// 此次请求要发送的数据量已满,结束循环
break;
} else {
if (shouldStopDrainBatchesForPartition(first, tp))
break;
// 获取ArrayDeque中第一个ProducerBatch
ProducerBatch batch = deque.pollFirst();
// 事务相关的处理(略)
// 关闭底层输出流,将ProducerBatch设置成只读状态
batch.close();
size += batch.records().sizeInBytes();
// 将ProducerBatch记录到ready集合中
ready.add(batch);
// 修改ProducerBatch的drainedMs标记
batch.drained(now);
}
}
} while (start != drainIndex);
return ready;
}
|
总结
本课时首先介绍了 kafka 中 message 格式的演变,详细分析了 V0、V1、V2 三个版本 message 的格式变迁。
然后介绍了 KafkaProducer 中 RecordAccumulator 相关的核心内容,它是业务线程和 Sender 线程之间数据的中转站,主要涉及到了 MemoryRecordsBuilder、ProducerBatch、BufferPool 等底层组件,以及 RecordAccumulator 的核心方法。
下一课时,我们将开始介绍 KafkaProducer 中 Sender 线程相关的内容。
本课时的文章和视频讲解,还会放到:
-
微信公众号:

-
B 站搜索:杨四正

