
- 1JS表单验证(用正则表达式,用字符串验证)_在泛微表单上 用正则表达式进行判断
- 2web漏洞-xml外部实体注入(XXE)_xml external entity injection
- 3YOLOv3通道+层剪枝,参数压缩98%,砍掉48个层,提速2倍_通道剪枝yolov3
- 4100% 展示 MySQL 语句执行的神器-Optimizer Trace
- 5[图解]SysML和EA建模住宅安全系统-07 to be块定义图
- 6移动端YOLOv5压缩与蒸馏:高效且轻量级的物体检测方案
- 7【UE Niagara】制作星光飘落效果_unreal niagara 流星
- 8html修改value的值,javascript怎么改变input的值?
- 99个免费的AI辅助编程工具,智能自动编写和生成代码_辅助开发ai工具
- 10Excel + Python,飞速搞定数据分析与处理_从excel到python,数据分析
Kafka源码深度解析-序列5 -Producer -RecordAccumulator队列分析_kafka recordaccumulator
赞
踩
在Kafka源码分析-序列2中,我们提到了整个Producer client的架构图,如下所示:
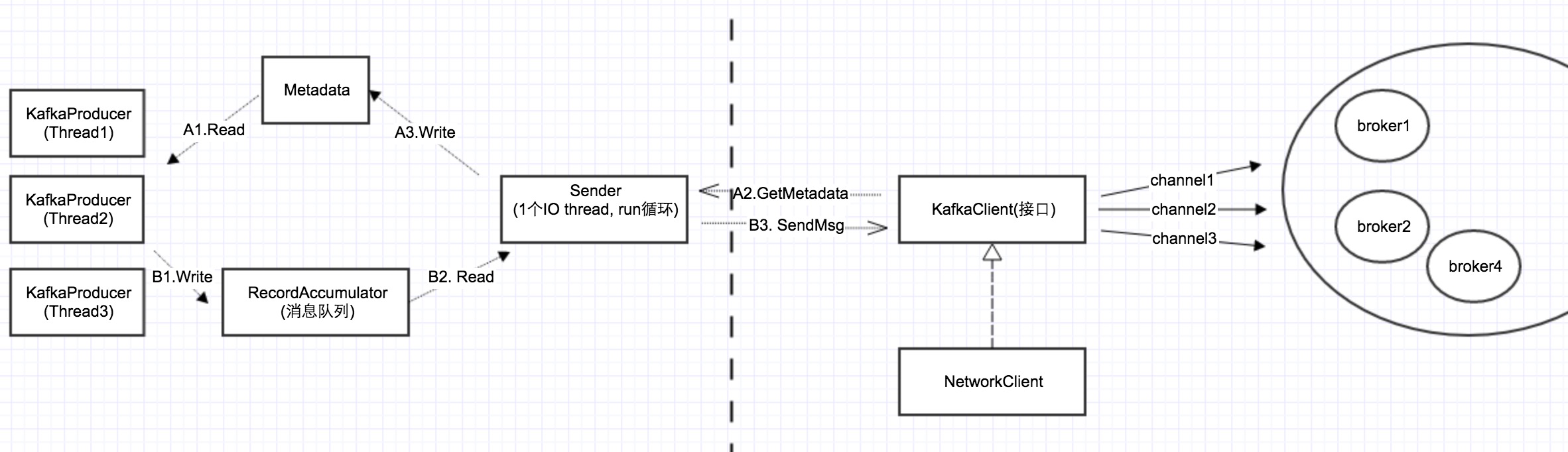
其它几个组件我们在前面都讲过了,今天讲述最后一个组件RecordAccumulator.
Batch发送
在以前的kafka client中,每条消息称为 “Message”,而在Java版client中,称之为”Record”,同时又因为有批量发送累积功能,所以称之为RecordAccumulator.
RecordAccumulator最大的一个特性就是batch消息,扔到队列中的多个消息,可能组成一个RecordBatch,然后由Sender一次性发送出去。
每个TopicPartition一个队列
下面是RecordAccumulator的内部结构,可以看到,每个TopicPartition对应一个消息队列,只有同一个TopicPartition的消息,才可能被batch。
public final class RecordAccumulator {
private final ConcurrentMap<TopicPartition, Deque<RecordBatch>> batches;
...
}
- 1
- 2
- 3
- 4
- 5
- 6
batch的策略
那什么时候,消息会被batch,什么时候不会呢?下面从KafkaProducer的send方法看起:
//KafkaProducer
public Future<RecordMetadata> send(ProducerRecord<K, V> record, Callback callback) {
try {
// first make sure the metadata for the topic is available
long waitedOnMetadataMs = waitOnMetadata(record.topic(), this.maxBlockTimeMs);
...
RecordAccumulator.RecordAppendResult result = accumulator.append(tp, serializedKey, serializedValue, callback, remainingWaitMs); //核心函数:把消息放入队列
if (result.batchIsFull || result.newBatchCreated) {
log.trace("Waking up the sender since topic {} partition {} is either full or getting a new batch", record.topic(), partition);
this.sender.wakeup();
}
return result.future;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
从上面代码可以看到,batch逻辑,都在accumulator.append函数里面:
public RecordAppendResult append(TopicPartition tp, byte[] key, byte[] value, Callback callback, long maxTimeToBlock) throws InterruptedException {
appendsInProgress.incrementAndGet();
try {
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
Deque<RecordBatch> dq = dequeFor(tp); //找到该topicPartiton对应的消息队列
synchronized (dq) {
RecordBatch last = dq.peekLast(); //拿出队列的最后1个元素
if (last != null) {
FutureRecordMetadata future = last.tryAppend(key, value, callback, time.milliseconds()); //最后一个元素, 即RecordBatch不为空,把该Record加入该RecordBatch
if (future != null)
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
int size = Math.max(this.batchSize, Records.LOG_OVERHEAD + Record.recordSize(key, value));
log.trace("Allocating a new {} byte message buffer for topic {} partition {}", size, tp.topic(), tp.partition());
ByteBuffer buffer = free.allocate(size, maxTimeToBlock);
synchronized (dq) {
// Need to check if producer is closed again after grabbing the dequeue lock.
if (closed)
throw new IllegalStateException("Cannot send after the producer is closed.");
RecordBatch last = dq.peekLast();
if (last != null) {
FutureRecordMetadata future = last.tryAppend(key, value, callback, time.milliseconds());
if (future != null) {
// Somebody else found us a batch, return the one we waited for! Hopefully this doesn't happen often...
free.deallocate(buffer);
return new RecordAppendResult(future, dq.size() > 1 || last.records.isFull(), false);
}
}
//队列里面没有RecordBatch,建一个新的,然后把Record放进去
MemoryRecords records = MemoryRecords.emptyRecords(buffer, compression, this.batchSize);
RecordBatch batch = new RecordBatch(tp, records, time.milliseconds());
FutureRecordMetadata future = Utils.notNull(batch.tryAppend(key, value, callback, time.milliseconds()));
dq.addLast(batch);
incomplete.add(batch);
return new RecordAppendResult(future, dq.size() > 1 || batch.records.isFull(), true);
}
} finally {
appendsInProgress.decrementAndGet();
}
}
private Deque<RecordBatch> dequeFor(TopicPartition tp) {
Deque<RecordBatch> d = this.batches.get(tp);
if (d != null)
return d;
d = new ArrayDeque<>();
Deque<RecordBatch> previous = this.batches.putIfAbsent(tp, d);
if (previous == null)
return d;
else
return previous;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
从上面代码我们可以看出Batch的策略:
1。如果是同步发送,每次去队列取,RecordBatch都会为空。这个时候,消息就不会batch,一个Record形成一个RecordBatch
2。Producer 入队速率 < Sender出队速率 && lingerMs = 0 ,消息也不会被batch
3。Producer 入队速率 > Sender出对速率, 消息会被batch
4。lingerMs > 0,这个时候Sender会等待,直到lingerMs > 0 或者 队列满了,或者超过了一个RecordBatch的最大值,就会发送。这个逻辑在RecordAccumulator的ready函数里面。
public ReadyCheckResult ready(Cluster cluster, long nowMs) {
Set<Node> readyNodes = new HashSet<Node>();
long nextReadyCheckDelayMs = Long.MAX_VALUE;
boolean unknownLeadersExist = false;
boolean exhausted = this.free.queued() > 0;
for (Map.Entry<TopicPartition, Deque<RecordBatch>> entry : this.batches.entrySet()) {
TopicPartition part = entry.getKey();
Deque<RecordBatch> deque = entry.getValue();
Node leader = cluster.leaderFor(part);
if (leader == null) {
unknownLeadersExist = true;
} else if (!readyNodes.contains(leader)) {
synchronized (deque) {
RecordBatch batch = deque.peekFirst();
if (batch != null) {
boolean backingOff = batch.attempts > 0 && batch.lastAttemptMs + retryBackoffMs > nowMs;
long waitedTimeMs = nowMs - batch.lastAttemptMs;
long timeToWaitMs = backingOff ? retryBackoffMs : lingerMs;
long timeLeftMs = Math.max(timeToWaitMs - waitedTimeMs, 0);
boolean full = deque.size() > 1 || batch.records.isFull();
boolean expired = waitedTimeMs >= timeToWaitMs;
boolean sendable = full || expired || exhausted || closed || flushInProgress(); //关键的一句话
if (sendable && !backingOff) {
readyNodes.add(leader);
} else {
nextReadyCheckDelayMs = Math.min(timeLeftMs, nextReadyCheckDelayMs);
}
}
}
}
}
return new ReadyCheckResult(readyNodes, nextReadyCheckDelayMs, unknownLeadersExist);
}- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
为什么是Deque?
在上面我们看到,消息队列用的是一个“双端队列“,而不是普通的队列。
一端生产,一端消费,用一个普通的队列不就可以吗,为什么要“双端“呢?
这其实是为了处理“发送失败,重试“的问题:当消息发送失败,要重发的时候,需要把消息优先放入队列头部重新发送,这就需要用到双端队列,在头部,而不是尾部加入。
当然,即使如此,该消息发出去的顺序,还是和Producer放进去的顺序不一致了。

