
- 1利用autoconf和automake来自动生成MakeFile_yum autoconf automake make
- 2大话前端:深入理解XSS攻击及其防御策略
- 3企业微信自定义应用 企业可信IP配置 企业可信ip怎么设置_配置企业可信ip前,请先 设置可信域名 或 设置接收消息服务器url
- 46d姿态估计综述_6d位姿是什么
- 5【Test 19】 数据结构 快速排序详解!
- 6使用ajax实现用户名存在校验,使用AJAX完成用户名是否存在异步校验
- 7如何在微软官网上下载旧版本的visual studio_微软官网下载旧版
- 8超越实体机?深度评测揭示ToDesk云电脑、无影云、青椒云真实性能
- 9Web开发:django+前端+数据库(6)— Mysql_mysql web开发
- 10yolov5yolo.py逐行代码解读_yolov5代码逐行解释
Transformer详细解读与预测实例记录_transformer预测
赞
踩
Transformer详细解读与预测实例记录
1、位置编码

之后细化:
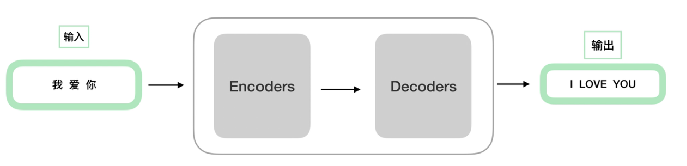

注意:encoder结构完全相同,但其参数不完全相同;decoder也是一样,不过decoder和encoder也是不相同的。

transformer模型结构如下图:

可以对应上图看。
接下来是encoder部分的详细说明:

1)输入部分:
Embedding部分:

说明:这里的每一个字定义为一个512维度的字向量。
2)位置编码部分:

从RNN说起,RNN所有的timesteps都共享一套参数。
因为transformer所有的输入都是一起的,不会像RNN输入一个处理一个,所以其需要位置编码(我的理解就是确定位置关系)。

在偶数位置使用sin,在奇数位置使用cos。

得到位置编码之后,把字向量的512维度向量与之相加,得到最终的512维度的向量作为transformer的输入向量。

为什么会消失呢
可见文章:https://zhuanlan.zhihu.com/p/57732839/
2、多头注意力机制
1)基本注意力机制

这样我们会更加关注婴儿。
公式如下:
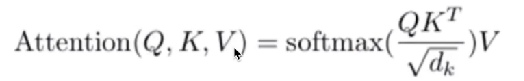

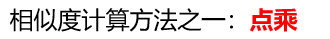
注:点乘结果越大,相似度越大。


注意:上图中 a1+a2+a3+a4=1 ,因为相似度相加是唯一的。
2)transformer中的注意力


为什么除以根号dk,因为qk相乘值很大,经过softmax后容易造成梯度消失,为了保持方差控制为1。
第三步和第四步是将分数除以8(8是论文中使用的键向量的维数64的平方根,这会让梯度更稳定。这里也可以使用其它值,8只是默认值),然后通过softmax传递结果。softmax的作用是使所有单词的分数归一化,得到的分数都是正值且和为1。


就是多了几套参数QKV,相当于把原始数据划分成了不同的空间。



整体如下图:

3、残差和LayerNorm


1)残差

残差就相当于是把原始的输入X与经过F(X)后的结果再相加。


所以它网络的深度可以很深,因为缓解了梯度消失。
2)LayerNorm

(BatchNormalization)



** BN缺点:**


当batch_size为10,9个长度为5,1个长度为20的时候,前5个单词的均值和方差可以用10个样本算出来,但是第10个样本的第6个单词到第20个样本前9个里面没有,只有一个所以bach_size很小的时候效果很差。


4、前馈神经网络


输入序列的每个单词都经过自编码过程。然后,他们各自通过前向传播神经网络——完全相同的网络,而每个向量都分别通过它。
5、Decoder


为什么需要mask?

如果没有mask:


2 encoder和decoder怎么交互的呢?

编码器通过处理输入序列开启工作。顶端编码器的输出之后会变转化为一个包含向量K(键向量)和V(值向量)的注意力向量集 。这些向量将被每个解码器用于自身的“编码-解码注意力层”,而这些层可以帮助解码器关注输入序列哪些位置合适:


在完成编码阶段后,则开始解码阶段。解码阶段的每个步骤都会输出一个输出序列(在这个例子里,是英语翻译的句子)的元素。
接下来的步骤重复了这个过程,直到到达一个特殊的终止符号,它表示transformer的解码器已经完成了它的输出。每个步骤的输出在下一个时间步被提供给底端解码器,并且就像编码器之前做的那样,这些解码器会输出它们的解码结果 。另外,就像我们对编码器的输入所做的那样,我们会嵌入并添加位置编码给那些解码器,来表示每个单词的位置。
而那些解码器中的自注意力层表现的模式与编码器不同:在解码器中,自注意力层只被允许处理输出序列中更靠前的那些位置。在softmax步骤前,它会把后面的位置给隐去(把它们设为-inf)。
这个“编码-解码注意力层”工作方式基本就像多头自注意力层一样,只不过它是通过在它下面的层来创造查询矩阵,并且从编码器的输出中取得键/值矩阵。


最终的线性变换和Softmax层:
解码组件最后会输出一个实数向量。我们如何把浮点数变成一个单词?这便是线性变换层要做的工作,它之后就是Softmax层。
线性变换层是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。
不妨假设我们的模型从训练集中学习一万个不同的英语单词(我们模型的“输出词表”)。因此对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
接下来的Softmax 层便会把那些分数变成概率(都为正数、上限1.0)。概率最高的单元格被选中,并且它对应的单词被作为这个时间步的输出。

这张图片从底部以解码器组件产生的输出向量开始。之后它会转化出一个输出单词。
6、实例记录
时序数据单步预测


import torch
import torch.nn as nn
import numpy as np
import time
import math
from matplotlib import pyplot
torch.manual_seed(0)
np.random.seed(0)
import warnings
warnings.filterwarnings('ignore')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
#pe.requires_grad = False
self.register_buffer('pe', pe)
def forward(self, x):
return x + self.pe[:x.size(0), :]
class TransAm(nn.Module):
def __init__(self,feature_size=250,num_layers=1,dropout=0.1):
super(TransAm, self).__init__()
self.model_type = 'Transformer'
self.src_mask = None
self.pos_encoder = PositionalEncoding(feature_size)
self.encoder_layer = nn.TransformerEncoderLayer(d_model=feature_size, nhead=10, dropout=dropout)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=num_layers)
self.decoder = nn.Linear(feature_size,1)
self.init_weights()
def init_weights(self):
initrange = 0.1
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
def forward(self,src):
if self.src_mask is None or self.src_mask.size(0) != len(src):
device = src.device
mask = self._generate_square_subsequent_mask(len(src)).to(device)
self.src_mask = mask
src = self.pos_encoder(src)
output = self.transformer_encoder(src,self.src_mask)#, self.src_mask)
output = self.decoder(output)
return output
def _generate_square_subsequent_mask(self, sz):
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
def get_batch(source, i,batch_size):
seq_len = min(batch_size, len(source) - 1 - i)
data = source[i:i+seq_len]
input = torch.stack(torch.stack([item[0] for item in data]).chunk(input_window,1)) # 1 is feature size
target = torch.stack(torch.stack([item[1] for item in data]).chunk(input_window,1))
return input, target
def train(train_data):
model.train() # Turn on the train mode \o/
total_loss = 0.
start_time = time.time()
for batch, i in enumerate(range(0, len(train_data) - 1, batch_size)):
data, targets = get_batch(train_data, i,batch_size)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, targets)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 0.7)
optimizer.step()
total_loss += loss.item()
log_interval = int(len(train_data) / batch_size / 5)
if batch % log_interval == 0 and batch > 0:
cur_loss = total_loss / log_interval
elapsed = time.time() - start_time
print('| epoch {:3d} | {:5d}/{:5d} batches | '
'lr {:02.6f} | {:5.2f} ms | '
'loss {:5.5f} | ppl {:8.2f}'.format(
epoch, batch, len(train_data) // batch_size, scheduler.get_lr()[0],
elapsed * 1000 / log_interval,
cur_loss, math.exp(cur_loss)))
total_loss = 0
start_time = time.time()
def plot_and_loss(eval_model, data_source,epoch):
eval_model.eval()
total_loss = 0.
test_result = torch.Tensor(0)
truth = torch.Tensor(0)
with torch.no_grad():
for i in range(0, len(data_source) - 1):
data, target = get_batch(data_source, i,1)
output = eval_model(data)
total_loss += criterion(output, target).item()
test_result = torch.cat((test_result, output[-1].view(-1).cpu()), 0)
truth = torch.cat((truth, target[-1].view(-1).cpu()), 0)
#test_result = test_result.cpu().numpy() -> no need to detach stuff..
len(test_result)
pyplot.plot(test_result,color="red")
pyplot.plot(truth[:500],color="blue")
pyplot.plot(test_result-truth,color="green")
pyplot.grid(True, which='both')
pyplot.axhline(y=0, color='k')
pyplot.savefig('graph/transformer-epoch%d.png'%epoch)
pyplot.close()
return total_loss / i
# predict the next n steps based on the input data
def predict_future(eval_model, data_source,steps):
eval_model.eval()
total_loss = 0.
test_result = torch.Tensor(0)
truth = torch.Tensor(0)
data, _ = get_batch(data_source, 0,1)
with torch.no_grad():
for i in range(0, steps):
output = eval_model(data[-input_window:])
data = torch.cat((data, output[-1:]))
data = data.cpu().view(-1)
# I used this plot to visualize if the model pics up any long therm struccture within the data.
pyplot.plot(data,color="red")
pyplot.plot(data[:input_window],color="blue")
pyplot.grid(True, which='both')
pyplot.axhline(y=0, color='k')
pyplot.savefig('graph/transformer-future%d.png'%steps)
pyplot.close()
def evaluate(eval_model, data_source):
eval_model.eval() # Turn on the evaluation mode
total_loss = 0.
eval_batch_size = 1000
with torch.no_grad():
for i in range(0, len(data_source) - 1, eval_batch_size):
data, targets = get_batch(data_source, i,eval_batch_size)
output = eval_model(data)
total_loss += len(data[0])* criterion(output, targets).cpu().item()
return total_loss / len(data_source)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
input_window = 100 # number of input steps
output_window = 1 # number of prediction steps, in this model its fixed to one
batch_size = 10
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# if window is 100 and prediction step is 1
# in -> [0..99]
# target -> [1..100]
def create_inout_sequences(input_data, tw):
inout_seq = []
L = len(input_data)
for i in range(L-tw):
train_seq = input_data[i:i+tw]
train_label = input_data[i+output_window:i+tw+output_window]
inout_seq.append((train_seq ,train_label))
return torch.FloatTensor(inout_seq)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
def get_data():
# construct a littel toy dataset
time = np.arange(0, 200, 0.1)
print("输入数据time:")
print(time.shape)
amplitude = np.sin(time) + np.sin(time*0.05) +np.sin(time*0.12) *np.random.normal(-0.2, 0.2, len(time))
print("输入数据amplitude1:")
print(amplitude.shape)
#loading weather data from a file
#from pandas import read_csv
#series = read_csv('daily-min-temperatures.csv', header=0, index_col=0, parse_dates=True, squeeze=True)
# looks like normalizing input values curtial for the model
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1, 1))
#amplitude = scaler.fit_transform(series.to_numpy().reshape(-1, 1)).reshape(-1)
amplitude = scaler.fit_transform(amplitude.reshape(-1, 1)).reshape(-1)
print("输入数据amplitude2:")
print(amplitude.shape)
# sampels = 2600
sampels = 1200
train_data = amplitude[:sampels]
test_data = amplitude[sampels:]
test_data2 = amplitude[sampels:]
print("输入数据train_data1:")
print(train_data.shape)
print("输入数据test_data1:")
print(test_data.shape)
# convert our train data into a pytorch train tensor
#train_tensor = torch.FloatTensor(train_data).view(-1)
# todo: add comment..
train_sequence = create_inout_sequences(train_data,input_window)
train_sequence = train_sequence[:-output_window] #todo: fix hack? -> din't think this through, looks like the last n sequences are to short, so I just remove them. Hackety Hack..
#test_data = torch.FloatTensor(test_data).view(-1)
test_data = create_inout_sequences(test_data,input_window)
test_data = test_data[:-output_window] #todo: fix hack?
print("输入数据train_sequence:")
print(train_sequence.shape)
print("输入数据test_data2:")
print(test_data.shape)
return train_sequence.to(device),test_data.to(device),test_data2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
model = TransAm().to(device)
criterion = nn.MSELoss()
lr = 0.005
#optimizer = torch.optim.SGD(model.parameters(), lr=lr)
optimizer = torch.optim.AdamW(model.parameters(), lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, 1.0, gamma=0.95)
best_val_loss = float("inf")
epochs = 30 # The number of epochs
best_model = None
for epoch in range(1, epochs + 1):
epoch_start_time = time.time()
train(train_data)
if(epoch % 10 is 0):
val_loss = plot_and_loss(model, val_data,epoch)
predict_future(model, val_data,200)
else:
val_loss = evaluate(model, val_data)
print('-' * 89)
print('| end of epoch {:3d} | time: {:5.2f}s | valid loss {:5.5f} | valid ppl {:8.2f}'.format(epoch, (time.time() - epoch_start_time),
val_loss, math.exp(val_loss)))
print('-' * 89)
# if val_loss < best_val_loss:
# best_val_loss = val_loss
# best_model = model
scheduler.step()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
结果如下图:
蓝色是真实数据,红色是预测数据,绿色是差值。



预测未来结果:

时序数据多步预测
input_window = 100
output_window = 5
batch_size = 10 # batch size
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
calculate_loss_over_all_values = False
- 1
- 2
- 3
- 4
- 5
修改output_window即可。
注:以上为个人学习笔记,仅供学习参考,转载需授权,非商业转载请注明出处,如有错误或补充欢迎指出!
【参考】https://www.bilibili.com/video/BV1Di4y1c7Zm?p=3&spm_id_from=pageDriver
【参考】https://zhuanlan.zhihu.com/p/54356280
【参考】https://zhuanlan.zhihu.com/p/57732839/
【参考】https://blog.csdn.net/m0_60413136/article/details/120297473

