- 1大模型LLM(2):开源 LLMOps平台dify。_llmops开源平台
- 2【linux 使用ollama部署运行本地大模型完整的教程,openai接口, llama2例子】_ollama linux
- 3Monkey测试:Monkey的简单使用
- 4Java核心技术 卷1_斯维斯方法有两个参数 分别是什么类型的类型和什么类型的对象
- 5使用vscode调试带-m参数的python代码_vscode -m
- 6Hbase的安装与配置_hbase配置
- 7Java入门基础教程-字面量、变量、关键字与标识符
- 8AIGC行业现状和未来发展趋势
- 9Java编程学习入门、Java语言学习、Java入门必看
- 10【GitHub项目推荐--开箱即用的直播聊天系统,高颜值,支持二次开发】【转载】_开源直播平台 github
中康数字科技:基于大模型的医学文本信息处理与抽取_中文实体抽取模型 大模型
赞
踩
在医疗行为开展的过程中,存在辨明药品禁忌症、了解不良反应、明确配伍禁忌和调整用药方式等实际需求,市面现有产品的功能较为单一、应用范围窄、数据更新慢无法满足业务需求,例如:药店场景SKU管理(Stock Keeping Unit,库存保有单位)要求数据标准化且更新频率高;在处方流转中,医院、药房、药店有审方需求。广州中康数字科技有限公司将这些需求转化为基于自然语言处理的药品说明书自动结构化问题,使用飞桨PaddleNLP解决数据处理问题,并形成药品知识图谱,衍生出合理用药提示、不良反应监测、推荐用药等应用。
中康科技通过探索海量文本与图像知识结构化处理、分析药品信息结构,并结合人工智能技术,形成药品知识图谱,并以此为基础进一步研究构建泛医行业应用。使用ERNIE-UIE和ERNIE-Health进行药品说明书的信息抽取和知识图谱构建,并嵌入到中康数字科技自研的医学垂直领域标注平台Sinotation中进行自动化标注和自主学习,提升标注效率和标准质量。本项目还实现自动化抽取药品说明书数据并对齐到医学标准术语库,包括SNOMED CT、UMLS 等,扩展图谱内容,形成药品知识图谱,衍生出合理用药提示服务、不良反应监测、用药推荐助手、药品说明书结构化等应用,填补了客户需求空白,解决人工效率低下问题。
系统上线后,提升了信息抽取的准确性,医学知识图谱的F1值从0.86上升到0.90左右。基于ERNIE-Health预训练模型效果提升2~3个点,基于ERNIE-Health模型初始化医学语料预测训练,可提升1~2 个点。
3月28日晚8:30,中康科技资深算法工程师梁锐老师将作客飞桨直播间,分享基于大模型的医学文本信息处理与抽取产业落地经验。
01 技术方案
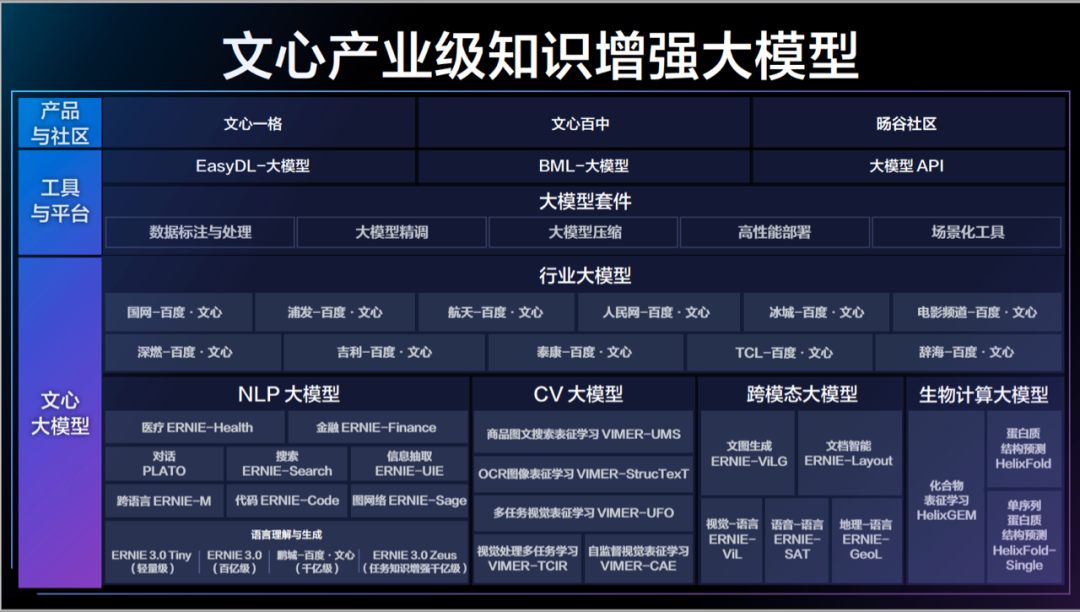
基于飞桨生态的药品知识图谱自动化构建是医学知识工厂的其中一个部分,目前说明书自动结构化的服务以及药品知识图谱及其衍生的应用已经上线。另外,基于医学指南的临床辅助决策工具也在投入使用当中。除此以外,针对门诊病历的文本结构化和专病数据库也在研发中,而关于临床研究文章的医学知识图谱也正在密锣紧鼓的规划中。
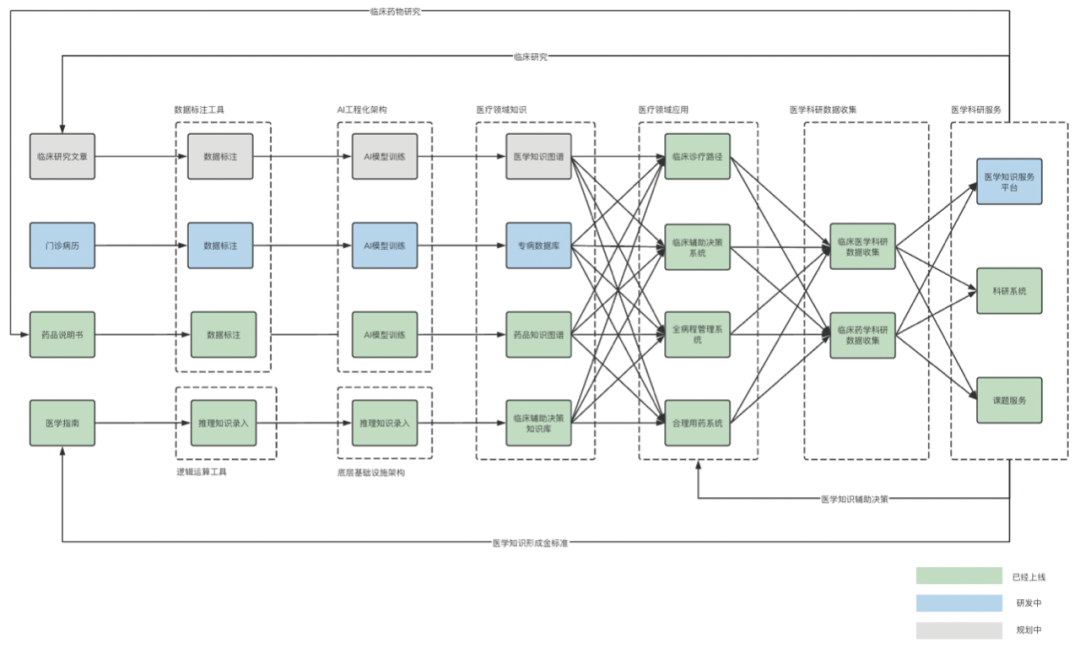
广州中康数字科技有限公司构建的医学知识工厂整体架构
02 技术亮点
Part-1 基于UIE抽取信息,提升数据标准质量
UIE基于Prompt + 预训练模型阅读理解抽取来统一信息抽取任务,它支持few-shot范式的训练,对于短文本抽取实体的情况,在标注少量数据情况下就可以达到不错的效果。例如:在药品说明书信息抽取时,医学专家们定义schema,并标注了约15 条数据,对于通用的实体取可以达到f1值达0.85 以上效果。
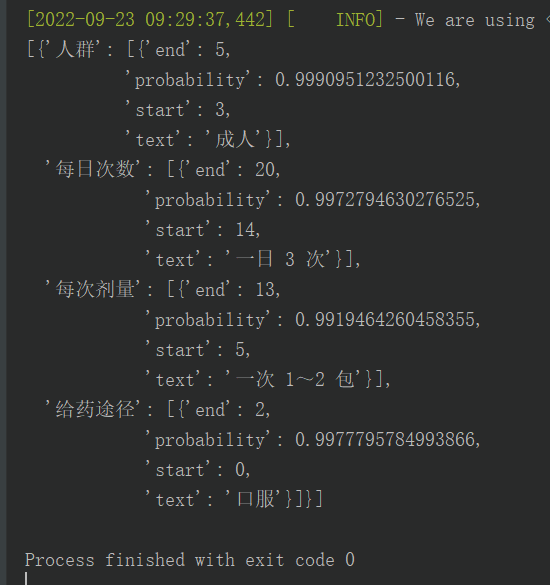
Part-2 基于ERNIE-Health进行Fine-tune,提升下游任务模型的准确率
使用医疗领域大模型ERNIE-Health,基于企业积累的医疗数据进行fine-tune。同时在训练过程中,还输入大量的医学术语进行多任务的对比学习,大大提升了医疗知识图谱的效果。
03 相关项目
- 通用信息抽取 UIE (Universal Information Extraction)
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/uie
- ERNIE-Health
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-health
- 使用医疗领域预训练模型Fine-tune 完成中文医疗语言理解任务
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-health/cblue
- Unified Structure Generation for Universal Information Extraction
https://arxiv.org/pdf/2203.12277.pdf
04 技术拓展——文心大模型
随着数据井喷、算法进步和算力突破,效果好、泛化能力强、通用性强的预训练大模型(以下简称“大模型”),成为人工智能发展的关键方向与人工智能产业应用的基础底座。文心大模型源于产业、服务于产业,是产业级知识增强大模型,涵盖基础大模型、任务大模型、行业大模型,大模型总量达36个,并构建了业界规模最大的产业大模型体系。文心大模型配套了丰富的工具与平台层,包括大模型开发套件、API 以及内置文心大模型能力的 EasyDL 和 BML 开发平台。 百度通过大模型与国产深度学习框架融合发展,打造了自主创新的 AI 底座,大幅降低了 AI 开发和应用的门槛,满足真实场景中的应用需求,真正发挥大模型驱动 AI 规模化应用的产业价值。