
- 1测试团队如何建设?_测试团队 建设
- 2一个git客户端配置多个git远程仓库账号_git 生成的密钥可以供多个远程库使用吗
- 3Python爬虫山西太原景点数据可视化和景点推荐系统 开题报告_山西旅游运营数据采集
- 4socket安装_socket库安装
- 5Kafka 客户端 Consumer 常用配置_kafka consumer常用配置
- 6matlab for Linux 安装_matlab for linux csdn
- 7从 0 搭建 Vite 3 + Vue 3 Js版 前端工程化项目_创建一个vue3+vite+js 的项目
- 8nginx负载均衡反向代理MySQL配置_反向代理mysql配置域名
- 9Python 机器学习 基础 之 处理文本数据 【处理文本数据/用字符串表示数据类型/将文本数据表示为词袋】的简单说明
- 10森说AI:从零开始应用paddlehub转换手写数字识别模型并完成部署:使用paddle2.xAPI简易实现手写数字识别模型_paddlehub 手写数字识别
打工人好用的大模型问答,还需要一款可靠的文档解析工具_有没有可以读取文档并作答的大模型
赞
踩
如果说三四年前,我们对AI的展望还停留在科幻片的话,现在,通向AI智能的路径已经初现端倪。各行各业的朋友们不约而同地嗅到了大模型带来的生产方式变革气息。
LLM宣布了AI时代的正式到来。
2022年11月30日,ChatGPT发布,向我们展示了技术的颠覆性潜力,生成式人工智能一夜爆火,ChatGPT月活用户在两月内突破1亿。23年,国内外科技大厂、初创企业纷纷入场,打造“AI”之年。
LLM的落地应用,正在迅速推动各领域工作方式的变革。我们不禁要问:AI会取代我们?还是让我们变得更高效?
埃森哲2023年的研究报告指出,所有行业中 40% 的工作时间都将得到大语言模型的协助。其主要原因在于,语言任务占到了企业人员工作总时长的 62%,让AI成为副手协同作战,将重塑打工人的工作方式,通过自动化技术大幅度提升生产力。
愿景在前,行则将至。当前,在咨询建议、内容创建等常用领域,已经有许多小伙伴开始尝试给自己配备一位“AI助手”了。在常规性知识问答之外,各个细分领域的专业性问答对打工人而言更加实用。合小研在阅读长篇幅论文、报告的时候,就经常需要大模型来完成一些综述、概括、辅助分析的工作,因此,我们非常关心一个问题:如果我提供一系列资料,目前大模型能为我反馈正确、精准的专业信息吗?
1 知识问答,大模型的表现怎么样?
在文档交互中,我们需要大模型实现的功能包括:根据文件完成知识问答,给出关联信息建议,以及提供专业性分析参考等。
多数企业的工作环境中,存在大量电子档、扫描档文件,而全人工阅读分析,往往会造成不必要的时间成本消耗。尤其在面对扫描或图片文档时,常规办公软件无法完成关键词检索,导致信息收集更为不便。
对话AI可以帮助我们解决这个问题吗?
最近,合小研以国内某自然语言大模型为例进行了简单的测试。该模型处于国内第一梯队水平,合小研的小伙伴们平时也经常在工作中使用。
1.1 企业年报
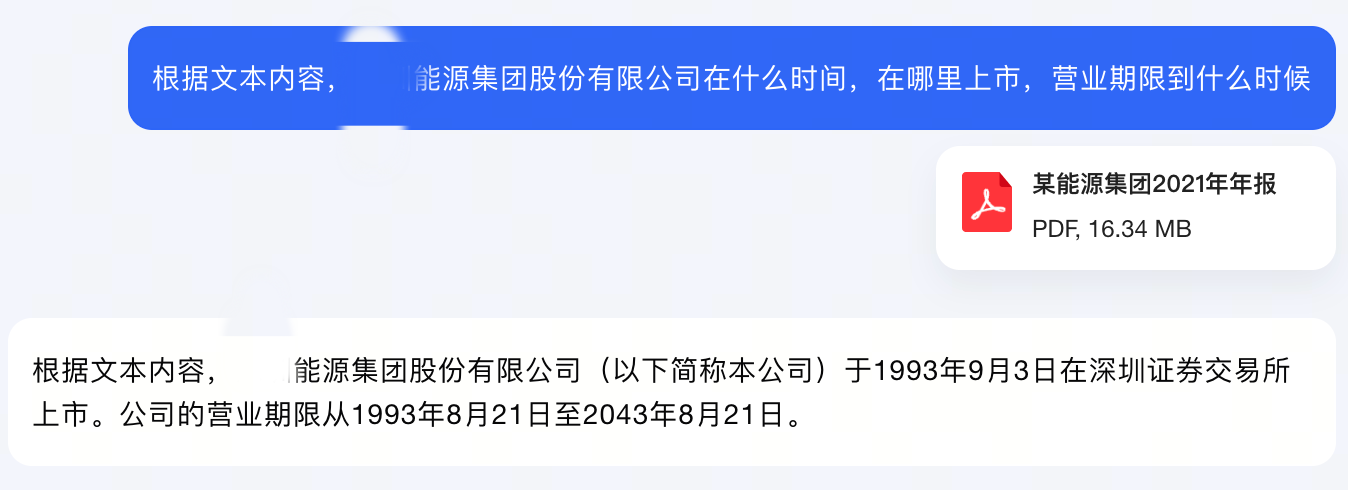
首先,合小研上传了一份长度100页的扫描版企业年报(部分),并提出问题:根据文本内容,该公司在什么时间,在哪里上市,营业期限到什么时候?
大模型给出了正确的回答。
继续追问一个问题:根据报告,企业与客户间的销售商品合同包含什么内容?
大模型同样给出了答案。与原文档进行比对,回答详细且全面。

可见,在年报等长文档信息提取方面,大模型能够为我们提供有效的分析辅助。
1.2 经济报告
我们来尝试一份包含数据与图表的经济报告。上传报告后,合小研提出问题:依据报告,美国CPI食品的1月官方值是多少?
大模型告诉我:根据您提供的文件内容,报告中并没有直接提供美国CPI食品的1月官方值。如果需要1月的具体数值,可能需要查阅其他官方数据发布渠道或等待官方数据的公布。

然而,如果进行人工检索,我们将在报告中获得如下表格,标明了CPI食品的1月官方值。

为什么大模型对这一信息读取失败?
1.3 期刊论文
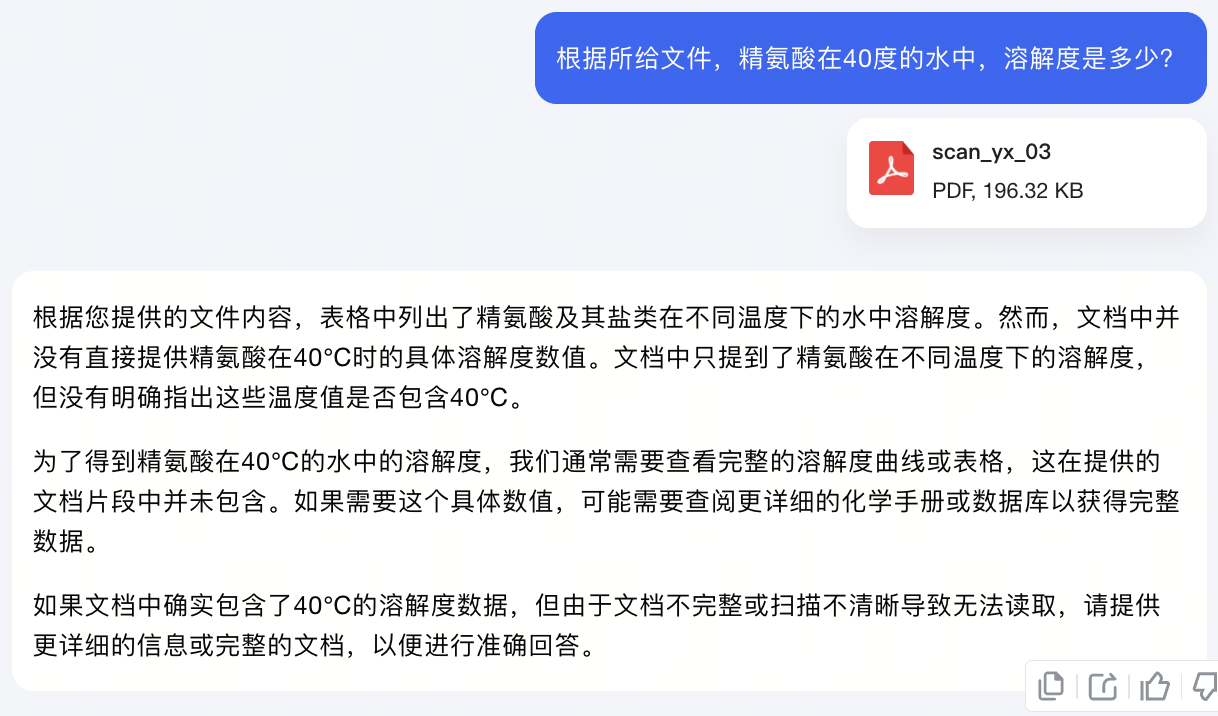
上传扫描版论文后,我们提出具体问题:根据所给文件,精氨酸在40度的水中,溶解度是多少?
大模型表示:文档中并没有直接提供精氨酸在40℃时的具体溶解度数值。同时,它补充道:如果文档中确实包含了40℃的溶解度数据,但由于文档不完整或扫描不清晰导致无法读取,请提供更详细的信息或完整的文档,以便进行准确回答。
但是,在人工阅读的情况下,我们可以看到清晰的有线表格,提供上述信息。

再一次,大模型无法找到相应的关键信息,并给出准确答案。
在实际工作场景中,我们需要识别的文件是多样、复杂的,其中既有清晰且便于机器读取的纯文字电子文件,也可能包含大量形式的图表,或来源时期不一的纸质扫描档、模糊或扭曲页面。当我们使用大模型作为工作助手,准确且稳定的输出是不可或缺的要素,当前的内容生成,显然需要进一步提升。
2 大模型回答不理想,原因何在?
在简短的测试里,我们考察了大模型对企业年报、经济报告以及期刊论文三份类型文件的问答效果,其中两项回答并不理想,无法为我们提供准确的内容。
发现这个问题后,合小研咨询了合合团队中的产品研发小伙伴们,试图推测可能的问题成因。
产品同学秒回合小研:用我们的文档解析工具把PDF转成Markdown格式了,你再发给大模型试试。
将转化后的经济报告发送给大模型,我们再次提出相同的问题。
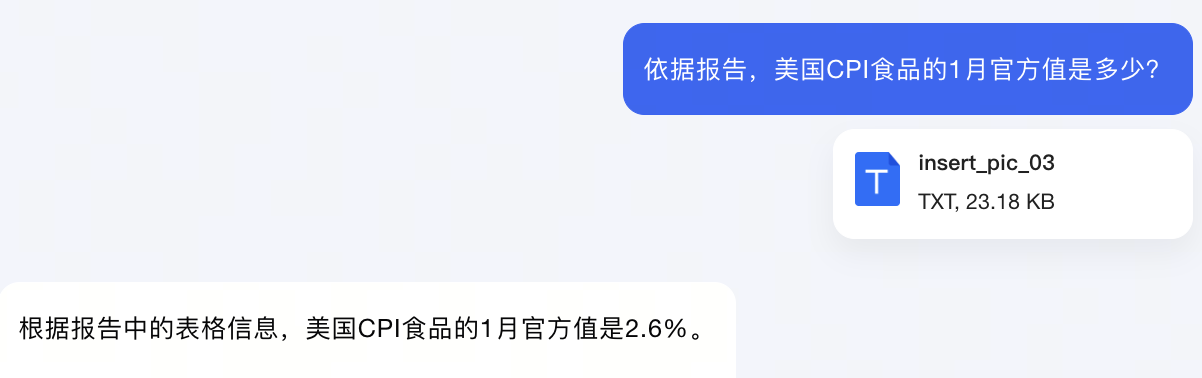
这一次,大模型清晰地给出了正确答案。

在期刊论文案例中,有线表格中细节信息同样得到了正确提取。
产品同学表示:这说明就是文档解析环节出的问题,之前大模型没能从你给的文件里识别到需要的信息。我们的解析工具把图片格式、各类表格都精准识别,转化成机器可读格式,大模型就能给出正确答复了。
我们了解到,业界实践中,目前的问答产品落地存在几大挑战:
第一,文档识别失败率高。面对复杂版面,无法正确解析,获取标题、分块文本、图表等。在这种情况下,大模型常表现为细节信息提供答案失败或回答错误。
第二,逻辑结构解析不完整。段落语义划分错误,导致回答不全面或总结性偏差。
第三,召回效果差。可能由于训练数据不平衡,影响模型检索召回能力。
而面对前两种问题,稳定准确的文档解析工具将大大提升大模型的应答能力,优化用户体验。
3 专业文档解析工具,有效增强大模型的问题解决能力
专业的文档解析是如何实现的?为什么它对大模型如此重要呢?
针对这些问题,我们需要理解PDF解析与大模型的阅读方式。
目前,主流专业产品采用的路线结合了PDF提取技术与OCR识别技术。其中,PDF提取技术主要用于处理PDF格式的文档,通过直接解析PDF文件的结构来提取文本和其他内容;其优点是处理速度快,适合于结构简单的PDF文档,但在处理复杂布局或包含大量图表、图片的文档时,准确率可能较低。OCR(Optical Character Recognition)技术通过扫描文档图像,识别其中的文字信息。这种技术适用于各种格式的文档,特别是扫描的纸质文档或图像格式的电子文档。OCR技术可以处理复杂布局的文档,但处理速度相对较慢,且对图像质量有一定要求。
合合信息的文档解析工具在此基础上对文件进行阅读顺序还原,支持多种格式的输出,在信息识别这一环节提供给大模型最“舒适”的序列文字。
文档解析是文档问答类大模型产品不可或缺的底层工具,并对产品质量有着重要的影响。在上文的测试中,大模型读取失败的信息分别来自文档中以图片格式存在的数据,与扫描档有线表格,同样也是文档解析环节中的难点。
由此可知,大模型应用场景下,一款好用的PDF解析工具,至少需要具备三个特性:速度快、精度高、兼容性好。在文档解析这一专精领域,合合信息凭借先发优势,积累了丰富的版式识别能力,能够实现元素检测准确,阅读顺序还原准确与高效的快速识别。
美国管理学家劳伦斯·彼得提出的木桶理论在AI纪元仍然适用。一款用户体验良好的大模型问答产品,需要全面的技术底座,方能成为改革工作模式、推广落地场景的利器。如何打造真正适用、实用,让打工人觉得好用的产品,也是合小研的小伙伴们,以及更多AI从业者不断思考探索的问题。理想产品的打造,要从每一个技术难关的攻克开始,而专业的文档解析工具,正是我们的突破点之一。
4 如何试用文档解析工具
合合信息文档解析产品已经上架到TextIn平台,任何开发者都可以注册账号并开通使用。
访问链接:https://www.textin.com/market/detail/pdf_to_markdown

点击【免费体验】,即可在线试用,如下图所示:

如果想试试用代码调用,也可以访问对应的接口文档内容:
https://www.textin.com/document/pdf_to_markdown
平台提供了一个Playground,帮开发者们预先调试接口。
点击页面中【API调试】按钮,即可进入调试页面。
在这里可以简单配置一些接口参数,发起调用后,右侧就会出现调用结果。
如果想用python调用,既可以参考平台上的通用示例代码,也可添加本文最后的二维码,获取更全面的demo代码。
文档解析产品目前正处于内测阶段。正式产品通常有1000页的免费试用额度,在内测期间,平台给每位开发者提供每周7000页的额度福利,关注公众号《合研社》即可领取。欢迎大家与我们团队多多交流,提出意见或建议。

