
热门标签
热门文章
- 1MySQL复习题_仅修改数据表中的字段名称时,通常使用alter table…modify实现
- 2NVIDIA推出IsaacNovaOrin加快自主移动机器人的发展_nova orin
- 3微信小程序——点击tabbar里的按钮跳转到另一个tabbar中的内容_按一个键到下一个标注简化小程序
- 4服务器硬盘数据备份到nas,这么设置USBCopy数据就能轻松备份至NAS
- 5已解决redis.clients.jedis.exceptions.JedisAskDataException异常的正确解决方法,亲测有效!!!_redis.clients.jedis.exceptions.jedisdataexception:
- 6植物大战僵尸杂交版破解C++实现
- 7Vivado中信号被优化掉,无法使用探针_vivado 设备设计和探针不匹配
- 8服务器上paddleOCR的bug记录_paddleocr集成tablestructure
- 903 pytest fixture(夹具)_testfixure测试夹具
- 10CorelDRAW2024绿色版汉化补丁器_coreldraw2020绿色便携版
当前位置: article > 正文
如何使用大型语言模型与任何 PDF 和图像文件聊天 — 使用代码 构建可以回答有关任何文件的问题的人工智能助手的完整指南_利用大语言模型对pdf解析
作者:不正经 | 2024-06-08 02:45:36
赞
踩
利用大语言模型对pdf解析
介绍
PDF 和图像文件中蕴藏着如此多有价值的信息。幸运的是,我们拥有强大的大脑,能够处理这些文件以查找特定信息,这实际上很棒。
但是,我们中有多少人内心深处不希望有一个工具可以回答有关给定文档的任何问题?
项目的一般工作流程
清楚地了解正在构建的系统的主要组件总是有好处的。那么让我们开始吧。
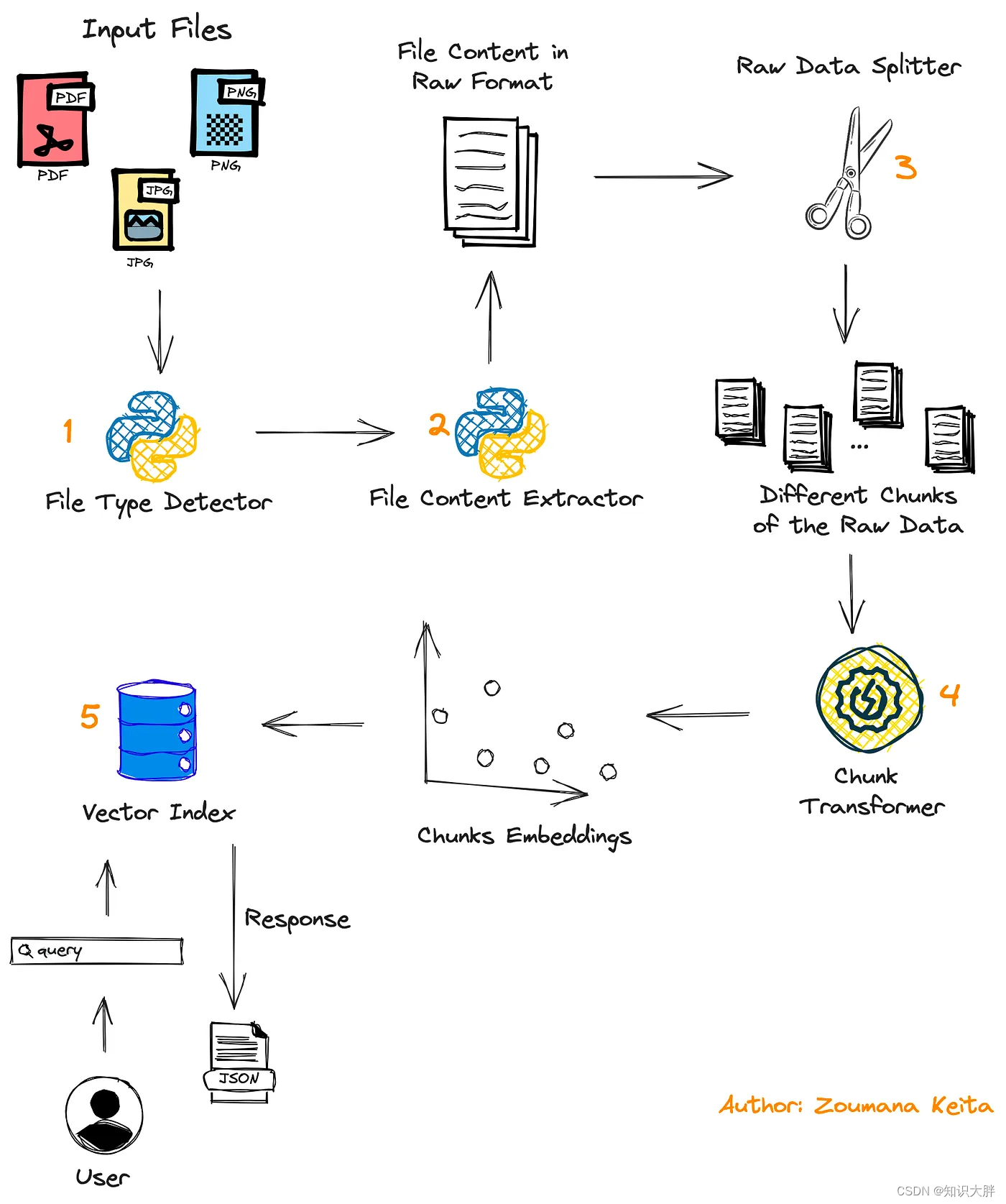
首先,用户提交要处理的文档,该文档可以是PDF或图像格式。
第二个模块用于检测文件的格式,以便应用相关内容提取功能。
然后使用该模块将文档的内容分成多个块Data Splitter。
Chunk Transformer这些块最终在存储到向量存储中之前使用 转换为嵌入。
在该过程结束时,用户的查询用于查找包含该查询答案的相关块,并将结果作为 JSON 返回给用户。
1. 检测文档类型
对于每个输入文档,根据其类型(无论是PDF、 还是image.
这可以通过辅助函数与内置 Python 模块中的函数detect_document_type相结合来实现。guess
def detect_document_type(document_path):
guess_file = guess(document_path)
file_type = ""
image_types = ['jpg', 'jpeg', 'png', 'gif']
if(guess_f- 1
- 2
- 3
- 4
- 5
- 6
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/688117
推荐阅读
相关标签

