
- 1yolo v5显示中文标签乱码解决_yolo检测标签乱码与只显示编号
- 2JAVA项目【仿牛客网面试总结】【分章节】_仿牛客网面试笔记
- 3使用Qt Creator进行代码分析_qt 代码分析
- 4Unknown host ‘dl.google.com‘. You may need to adjust the proxy settings in
- 5def __init__(self)和def __init__(self, 参数1,参数2,···,参数n)的用法详解
- 6vue中如何使用富文本详细讲解_vue 富文本
- 7高中毕业从汽修转行自学Python,月薪翻了三倍,我有一份转行秘籍分享给你_高中毕业自学python
- 8python类型转换方法_Numpy数据类型转换astype,dtype的方法
- 9Java关键字大冒险:深入浅出地理解Java的精髓
- 10啥移动硬盘格式能更好兼容Windows和Mac系统 NTFS格式苹果电脑不能修改 paragon ntfs for mac激活码_mac os 和windows系统都能用的硬盘格式
五集群环境搭建-使用root用户_root账户管理其他节点名称
赞
踩
文章目录
- 一、关于用户、同步传输文件问题
- 二、所有CentOS的/etc/hosts文件统一配置
- 三、修改/etc/hostname文件(配置主机名)
- 四、配置网络(NAT或者桥接模式)
- 五、所有CentOS关闭防火墙
- 六、所有CentOS的环境变量统一配置
- 七、配置ssh免密
- 八、JDK
- 九、配置zookeeper-3.4.13集群
- 十、配置hadoop-2.9.2集群
- 十一、Hadoop HA 与 Yarn HA
- 1.开启zookeeper集群并初始化HA在zookeeper中的状态
- 2.集群开启成功后在CentOS001中初始化状态
- 3.CentOS001、CentOS002启动journalnode
- 4.对CentOS001进行格式化并启动
- 5.在CentOS002上同步CentOS001的元数据信息并启动
- 6.在CentOS002、CentOS003、CentOS004上启动datanode
- 7.CentOS001、CentOS002启动 DFSZK Failover Controller,先启动的namenode节点为 active
- 8.查看namenode激活状态
- 9.在CentOS中开启yarn
- 10.查看yarn服务状态
- 十二、Spark-2.3.3 HA
- 十三、配置Hive-2.3.4服务端与客户端
- 十四、配置Sqoop
- 十五、Flume安装
- 十六、kafka-2.1.1集群配置
- 十七、配置Hbase-1.4.10集群
一、关于用户、同步传输文件问题
1.关于用户的问题:
所有操作使用root账户完成,实际生产环境不推荐!
2.关于同步传输文件或目录的问题:
CentOS之间同步文件命令:
scp /本机目录名/本机文件路径 对方用户名@对方主机名:/对方目录名/
#例如:
#sudo scp /opt/software/hadoop-2.9.2/etc/hadoop/core-site.xml root@centos002:/opt/software/hadoop-2.9.2/etc/hadoop/
#将core-site.xml文件传到对方/opt/software/etc/hadoop/目录下
#sudo scp /opt/software/hadoop-2.9.2/etc/hadoop/* root@centos002:/opt/software/hadoop-2.9.2/etc/hadoop/
#将/opt/software/hadoop-2.9.2/etc/hadoop/目录下所有文件传送到对方/opt/software/hadoop-2.9.2/etc/hadoop/目录下
- 1
- 2
- 3
- 4
- 5
- 6
CentOS之间同步目录命令:
scp -r /本机目录路径 对方用户名@对方主机名:/对方目录名/
#例如:
#sudo scp -r /opt/software/zookeeper-3.4.13 root@centos002:/opt/software/
#sudo scp -r /opt/software/zookeeper-3.4.13 root@centos003:/opt/software/
#sudo scp -r /opt/software/zookeeper-3.4.13 root@centos004:/opt/software/
#本机zookeeper-3.4.13目录及其内所有文件都会完整的复制到对方/opt/software/目录下
- 1
- 2
- 3
- 4
- 5
- 6
二、所有CentOS的/etc/hosts文件统一配置
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.15.131 centos001
192.168.15.132 centos002
192.168.15.133 centos003
192.168.15.134 centos004
- 1
- 2
- 3
- 4
- 5
- 6
- 7
三、修改/etc/hostname文件(配置主机名)
vim /etc/hostname
- 1
四、配置网络(NAT或者桥接模式)
修改/etc/sysconfig/network-scripts/ifcfg-ens33文件(配置固定IP地址)
vim /etc/sysconfig/network-scripts/ifcfg-ens33
- 1
五、所有CentOS关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
- 1
- 2
六、所有CentOS的环境变量统一配置
配置环境变量
vim /etc/profile
- 1
export JAVA_HOME=/opt/software/java/jdk1.8.0_211/ export PATH=$PATH:$JAVA_HOME/bin export HADOOP_HOME=/opt/software/hadoop-2.9.2/ export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin export ZOOKEEPER_HOME=/opt/software/zookeeper-3.4.13 export PATH=$PATH:$ZOOKEEPER_HOME/bin export HIVE_HOME=/opt/software/hive-2.3.4 export PATH=$PATH:$HIVE_HOME/bin export PYSPARK_PYTHON=/usr/bin/python3.6 export SPARK_HOME=/opt/software/spark-2.3.3 export PATH=$PATH:$SPARK_HOME/bin export KAFKA_HOME=/opt/software/kafka-2.1.1 export PATH=$PATH:$KAFKA_HOME/bin export HBASE_HOME=/opt/software/hbase-1.4.10 export PATH=$PATH:$HBASE_HOME/bin #export JAVA_LIBRARY_PATH=/opt/software/hadoop-2.9.2/lib/native

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
每台CentOS更新配置
source /etc/profile
- 1
都配置完后重启虚拟机
七、配置ssh免密
每台CentOS都要使用root用户执行一遍(前提:每台机器都在线且可ping通)
ssh-keygen -t rsa
ssh-copy-id centos001
ssh-copy-id centos002
ssh-copy-id centos003
ssh-copy-id centos004
- 1
- 2
- 3
- 4
- 5
八、JDK
本次所有CentOS都使用jdk1.8.0_211
九、配置zookeeper-3.4.13集群
1.配置conf/zoo.cfg
复制模版文件zoo_sample.cfg为zoo.cfg并修改内容为:
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/opt/software/zookeeper-3.4.13/data dataLogDir=/opt/software/zookeeper-3.4.13/datalog # the port at which the clients will connect clientPort=2181 server.1=centos001:2888:3888 server.2=centos002:2888:3888 server.3=centos003:2888:3888 server.4=centos004:2888:3888
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2.创建所需目录以及myid文件
mkdir /opt/software/zookeeper-3.4.13/data
mkdir /opt/software/zookeeper-3.4.13/datalog
vim /opt/software/zookeeper-3.4.13/data/myid
- 1
- 2
- 3
将myid文件的内容设置为1
3.将zookeeper-3.4.13目录及其内所有文件发送到其他CentOS
scp -r /opt/software/zookeeper-3.4.13 root@centos002:/opt/software/
scp -r /opt/software/zookeeper-3.4.13 root@centos003:/opt/software/
scp -r /opt/software/zookeeper-3.4.13 root@centos004:/opt/software/
- 1
- 2
- 3
4.依次修改myid文件
修改CentOS002、CentOS003、CentOS004的myid内容为2、3、4
vim /opt/software/zookeeper-3.4.13/data/myid
- 1
5.开启zookeeper集群
每台CentOS执行如下命令:
zkServer.sh start
- 1
查看是否开启成功:
zkServer.sh status
jps
- 1
- 2
每台CentOS出现Mode: follower或Mode: leader且jps存在QuorumPeerMain进程即zookeeper集群开启成功
十、配置hadoop-2.9.2集群
1.配置core-site.xml
<configuration> <!-- 把多个 NameNode 的地址组装成一个集群 mycluster --> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <!-- 指定 hadoop 运行时产生文件的存储目录 --> <property> <name>hadoop.tmp.dir</name> <value>/opt/software/hadoop-2.9.2/data</value> </property> <!-- 指定 zkfc 要连接的 zkServer 地址 --> <property> <name>ha.zookeeper.quorum</name> <value>centos001:2181,centos002:2181,centos003:2181,centos004:2181</value> </property> <property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
2.配置hdfs-site.xml
<configuration> <!-- NameNode 数据存储目录 --> <property> <name>dfs.namenode.name.dir</name> <value>file://${hadoop.tmp.dir}/name</value> </property> <!-- DataNode 数据存储目录 --> <property> <name>dfs.datanode.data.dir</name> <value>file://${hadoop.tmp.dir}/data</value> </property> <!-- JournalNode 数据存储目录 --> <property> <name>dfs.journalnode.edits.dir</name> <value>${hadoop.tmp.dir}/jn</value> </property> <!-- 完全分布式集群名称 --> <property> <name>dfs.nameservices</name> <value>mycluster</value> </property> <!-- 集群中 NameNode 节点都有哪些 --> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value> </property> <!-- NameNode 的 RPC 通信地址 --> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>centos001:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>centos002:8020</value> </property> <!-- NameNode 的 http 通信地址 --> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>centos001:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>centos002:9870</value> </property> <!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 --> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://centos001:8485;centos002:8485/mycluster</value> </property> <!-- 访问代理类:client 用于确定哪个 NameNode 为 Active --> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 --> <property> <name>dfs.ha.fencing.methods</name> <value>sshfence</value> </property> <!-- 使用隔离机制时需要 ssh 秘钥登录--> <property> <name>dfs.ha.fencing.ssh.private-key-files</name> <value>/root/.ssh/id_rsa</value> </property> <!-- 启用 nn 故障自动转移 --> <property> <name>dfs.ha.automatic-failover.enabled</name> <value>true</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
3.配置yarn-site.xml
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 启用 resourcemanager ha --> <property> <name>yarn.resourcemanager.ha.enabled</name> <value>true</value> </property> <!-- 声明两台 resourcemanager 的地址 --> <property> <name>yarn.resourcemanager.cluster-id</name> <value>cluster-yarn1</value> </property> <!--指定 resourcemanager 的逻辑列表--> <property> <name>yarn.resourcemanager.ha.rm-ids</name> <value>rm1,rm2</value> </property> <!-- ========== rm1 的配置 ========== --> <!-- 指定 rm1 的主机名 --> <property> <name>yarn.resourcemanager.hostname.rm1</name> <value>centos003</value> </property> <!-- 指定 rm1 的 web 端地址 --> <property> <name>yarn.resourcemanager.webapp.address.rm1</name> <value>centos003:8088</value> </property> <!-- 指定 rm1 的内部通信地址 --> <property> <name>yarn.resourcemanager.address.rm1</name> <value>centos003:8032</value> </property> <!-- 指定 AM 向 rm1 申请资源的地址 --> <property> <name>yarn.resourcemanager.scheduler.address.rm1</name> <value>centos003:8030</value> </property> <!-- 指定供 NM 连接的地址 --> <property> <name>yarn.resourcemanager.resource-tracker.address.rm1</name> <value>centos003:8031</value> </property> <!-- ========== rm2 的配置 ========== --> <!-- 指定 rm2 的主机名 --> <property> <name>yarn.resourcemanager.hostname.rm2</name> <value>centos004</value> </property> <property> <name>yarn.resourcemanager.webapp.address.rm2</name> <value>centos004:8088</value> </property> <property> <name>yarn.resourcemanager.address.rm2</name> <value>centos004:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address.rm2</name> <value>centos004:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address.rm2</name> <value>centos004:8031</value> </property> <!-- 指定 zookeeper 集群的地址 --> <property> <name>yarn.resourcemanager.zk-address</name> <value>centos001:2181,centos002:2181,centos003:2181,centos004:2181</value> </property> <!-- 启用自动恢复 --> <property> <name>yarn.resourcemanager.recovery.enabled</name> <value>true</value> </property> <!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 --> <property> <name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLAS SPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>false</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
4.配置slaves
centos002
centos003
centos004
- 1
- 2
- 3
5.配置hadoop-env.sh
添加如下代码(最好是填JDK的绝对路径):
export JAVA_HOME=/opt/software/java/jdk1.8.0_211
- 1
6.将hadoop-2.9.2分发到其他CentOS
scp -r /opt/software/hadoop-2.9.2 root@centos002:/opt/software/
scp -r /opt/software/hadoop-2.9.2 root@centos003:/opt/software/
scp -r /opt/software/hadoop-2.9.2 root@centos004:/opt/software/
- 1
- 2
- 3
十一、Hadoop HA 与 Yarn HA
1.开启zookeeper集群并初始化HA在zookeeper中的状态
每台CentOS执行(如果已开启zk集群请忽略):
zkServer.sh start
- 1
2.集群开启成功后在CentOS001中初始化状态
hdfs zkfc -formatZK
- 1
3.CentOS001、CentOS002启动journalnode
hadoop-daemon.sh start journalnode
- 1
4.对CentOS001进行格式化并启动
hdfs namenode -format
hadoop-daemon.sh start namenode
- 1
- 2
5.在CentOS002上同步CentOS001的元数据信息并启动
hdfs namenode -bootstrapStandby
hadoop-daemon.sh start namenode
- 1
- 2
6.在CentOS002、CentOS003、CentOS004上启动datanode
hadoop-daemon.sh start datanode
- 1
7.CentOS001、CentOS002启动 DFSZK Failover Controller,先启动的namenode节点为 active
hadoop-daemon.sh start zkfc
- 1
8.查看namenode激活状态
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
- 1
- 2
9.在CentOS中开启yarn
start-yarn.sh
- 1
10.查看yarn服务状态
yarn rmadmin -getServiceState rm1
yarn rmadmin -getServiceState rm2
- 1
- 2
十二、Spark-2.3.3 HA
1.配置好spark-2.3.3/conf/slaves文件
centos003
centos004
- 1
- 2
2.配置spark-env.sh
## 设置JAVA目录 JAVA_HOME=/opt/software/java/jdk1.8.0_211/ ## HADOOP软件配置文件目录,读取HDFS上文件和运行YARN集群 HADOOP_CONF_DIR=/opt/software/hadoop-2.9.2/etc/hadoop YARN_CONF_DIR=/opt/software/hadoop-2.9.2/etc/hadoop ## 指定spark老大Master的IP和提交任务的通信端口 # 告知Spark的master运行在哪个机器上 #export SPARK_MASTER_HOST=master SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=centos001:2181,centos002:2181,centos003:2181,centos004:2181 -Dspark.deploy.zookeeper.dir=/spark-ha" # spark.deploy.recoveryMode 指定HA模式 基于Zookeeper实现 # 指定Zookeeper的连接地址 # 指定在Zookeeper中注册临时节点的路径 # 告知sparkmaster的通讯端口 export SPARK_MASTER_PORT=7077 # 告知spark master的 webui端口 SPARK_MASTER_WEBUI_PORT=8080 # worker cpu可用核数 SPARK_WORKER_CORES=1 # worker可用内存 SPARK_WORKER_MEMORY=1g # worker的工作通讯地址 SPARK_WORKER_PORT=7078 # worker的 webui地址 SPARK_WORKER_WEBUI_PORT=8081 ## 设置历史服务器 # 配置的意思是 将spark程序运行的历史日志 存到hdfs的/sparklog文件夹中 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://centos001:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
在HDFS上创建程序运行历史记录存放的文件夹:
hdfs dfs -mkdir /sparklog
hdfs dfs -chmod 777 /sparklog
- 1
- 2
3.配置spark-defaults.conf文件
# 开启spark的日期记录功能
spark.eventLog.enabled true
# # 设置spark日志记录的路径
spark.eventLog.dir hdfs://centos001:8020/sparklog/
# # 设置spark日志是否启动压缩
spark.eventLog.compress true
- 1
- 2
- 3
- 4
- 5
- 6
4.配置log4j.properties 文件(可选)
# Set everything to be logged to the console log4j.rootCategory=WARN, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n # Set the default spark-shell log level to WARN. When running the spark-shell, the # log level for this class is used to overwrite the root logger's log level, so that # the user can have different defaults for the shell and regular Spark apps. log4j.logger.org.apache.spark.repl.Main=WARN # Settings to quiet third party logs that are too verbose log4j.logger.org.spark_project.jetty=WARN log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
5.分发spark-2.3.3到其他CentOS
sudo scp -r /opt/software/spark-2.3.3 root@centos002:/opt/software/
#需要输入对方root用户的密码
sudo scp -r /opt/software/spark-2.3.3 root@centos003:/opt/software/
sudo scp -r /opt/software/spark-2.3.3 root@centos004:/opt/software/
- 1
- 2
- 3
- 4
6.CentOS001启动Spark集群(前提:所有CentOS环境变量设置完成)
./sbin/start-all.sh
- 1
7.在CentOS002上启动备用Master进程
./sbin/start-master.sh
- 1
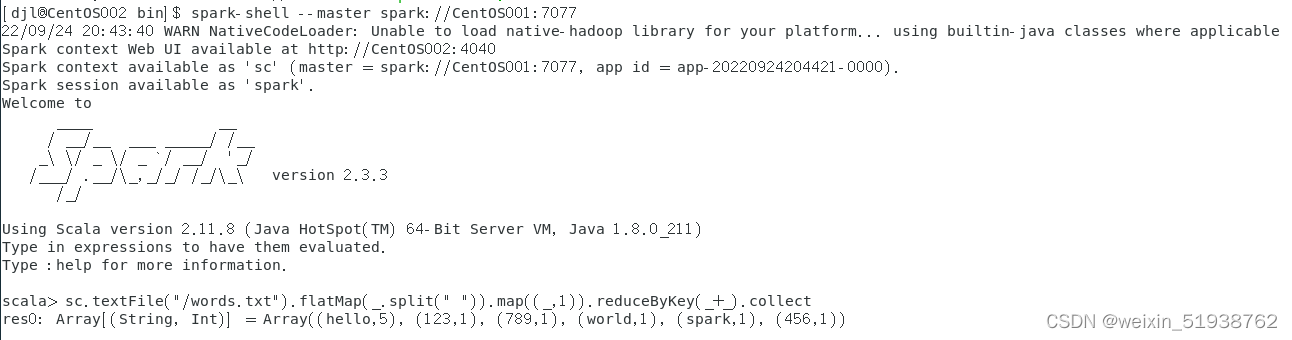
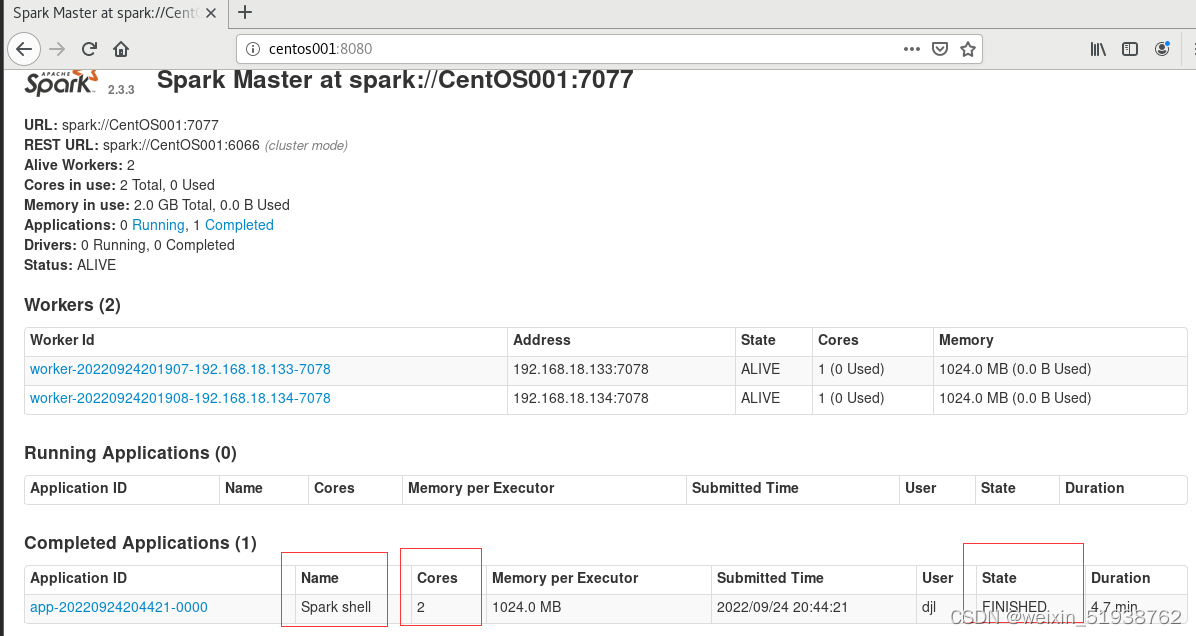
8.查看集群是否启动成功
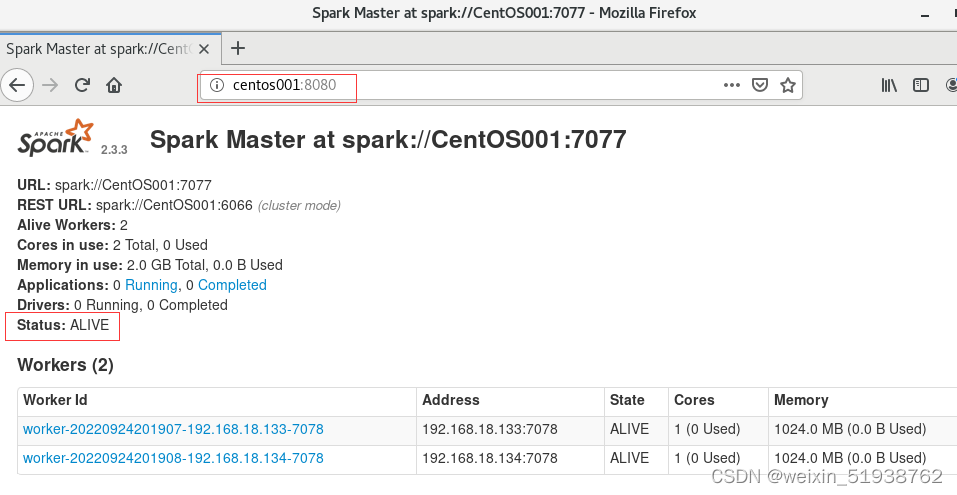
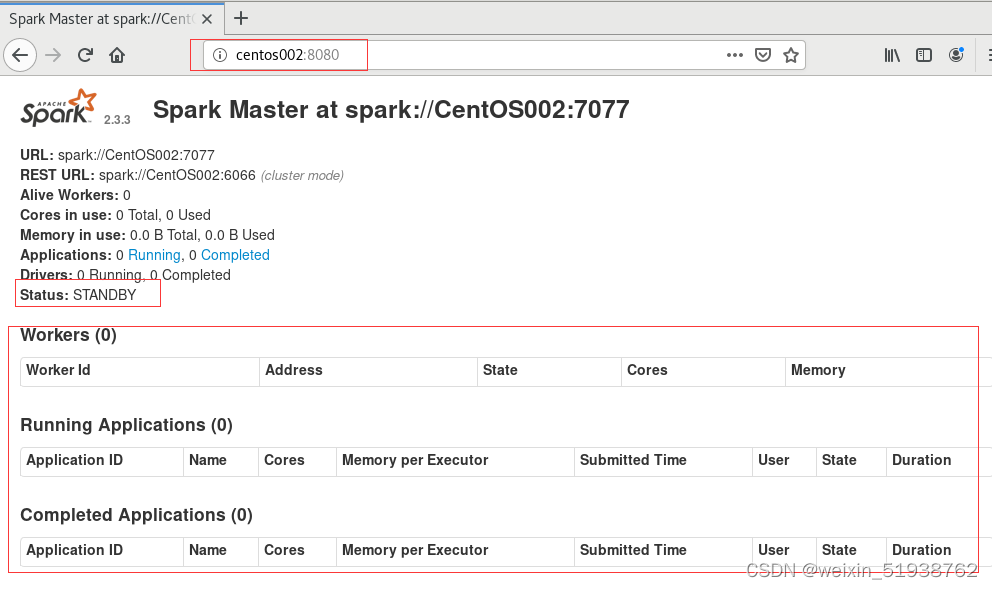
以上:CentOS001显示ACTIVE状态,CentOS002显示STANDBY状态。说明Spark-2.3.3 HA 搭建成功。
十三、配置Hive-2.3.4服务端与客户端
1.CentOS001安装mysql作为hive的元数据存储
(1)下载MySQL的Yum Repository
wget https://repo.mysql.com/mysql57-community-release-el7-11.noarch.rpm
- 1
(2)安装MySQL官方的Yum Repository
rpm -ivh mysql57-community-release-el7-11.noarch.rpm
- 1
(3)查看可安装的MySQL版本
yum repolist all |grep mysql
- 1
(4)安装Mysql
yum install -y mysql-community-server --nogpgcheck
- 1
(5)启动mysql
systemctl start mysqld
systemctl status mysqld
- 1
- 2
(6)修改登录密码
修改密码策略
vim /etc/my.cnf
- 1
末尾加两行:
validate_password_policy=Low
validate_password_length=6
- 1
- 2
重启mysqld服务
systemctl restart mysqld
- 1
获取临时密码
grep 'temporary password' /var/log/mysqld.log
- 1
使用临时密码登录
mysql -uroot -p
- 1
修改Mysql的root账户的密码
set password = "123456";
- 1
查询mysql中创建的库
show databases;
- 1
(7)在MySQL中创建Hive所需用户和数据库并授权
创建hive元数据库“hive”
create database hive;
- 1
创建用户hive(mysql中为hive专用的user名:hive,密码为:123456)
create user 'hive' identified by '123456';
- 1
将数据库hive的所有权限授权于用户hive
Grant all privileges on hive.* to hive identified by '123456';flush privileges;
- 1
使用hive用户登录验证,存在hive数据库即成功
mysql -uhive -p123456
show databases;
- 1
- 2
2.CentOS002安装hive-2.3.4
(1)配置hive-env.sh
解压hive-2.3.4到CentOS002并将JDBC驱动复制到hive-2.3.4/lib目录下
cp mysql-connector-java-5.1.48/mysql-connector-java-5.1.48.jar /opt/software/hive-2.3.4/lib/
- 1
修改hive-env.sh文件内容如下
HADOOP_HOME=/opt/software/hadoop-2.9.2
export HIVE_CONF_DIR=/opt/software/hive-2.3.4/conf
export HIVE_AUX_JARS_PATH=/opt/software/hive-2.3.4/lib
- 1
- 2
- 3
(2)创建hive-default.xml但不修改
cp hive-default.xml.template hive-default.xml
- 1
(3)修改hive-site.xml
hive-site.xml修改如下
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://centos001:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
(4)初始化Hive Metastore
schematool -initSchema -dbType mysql
- 1
(5)验证Hive
启动hadoop集群
start-dfs.sh
start-yarn.sh
jps
- 1
- 2
- 3
进入hive
hive
- 1

(6)将hive-2.3.4同步到CentOS003
scp -r /opt/software/hive-2.3.4 root@centos003:/opt/software/
- 1
3.hive服务端配置(metastore + hiveserver2)
(1)配置hive-site.xml文件
在CentOS002中的hive-site.xml中的配置如下:
<configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://centos001:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>hive</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property> <property> <name>hive.metastore.uris</name> <value>thrift://centos002:9083</value> </property> </configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
连接流程:
客户端(beeline)–>hiveserver2–>metastore–>mysql
客户端(hive)–>metastore–>mysql
hiveserver2开启时如果没有配置metastore的连接地址那么会自己开启一个metastore,开启后的metastore根据hive-site.xml配置文件连接到mysql。
(2)开启metastore服务与hiveserver2服务
在CentOS002上后台启动metastore服务与hiveserver2服务:
nohup hive --service metastore &
nohup hive --service hiveserver2 &
- 1
- 2
4.hive客户端配置
在CentOS003的hive-site.xml中的配置如下:
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://centos002:9083</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
(1)使用hive客户端连接到CentOS002的Metastore服务
hive
- 1

(2)使用beeline连接到CentOS002的hiveserver2服务
进入beeline
/opt/software/hive-2.3.4/bin/beeline
- 1
输入连接命令:
!connect jdbc:hive2://centos002:10000
- 1
连接成功:
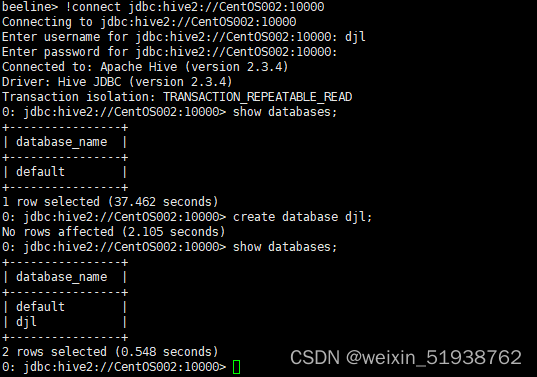
十四、配置Sqoop
在CentOS003上解压好sqoop1.4.7后
1.配置sqoop-env.sh
mv sqoop-env-template.sh sqoop-env.sh
vim sqoop-env.sh
- 1
- 2
export HADOOP_COMMON_HOME=/opt/software/hadoop-2.9.2
export HADOOP_MAPRED_HOME=/opt/software/hadoop-2.9.2
export HIVE_HOME=/opt/software/hive-2.3.4
export ZOOKEEPER_HOME=/opt/software/zookeeper-3.4.13
export ZOOCFGDIR=/opt/software/zookeeper-3.4.13
export HBASE_HOME=/opt/software/hbase-1.4.10
#export ACCUMULO_HOME=/opt/software/data/data/accumulo
#export HCAT_HOME=/opt/software/data/servers/hbase/logs/hcat-logs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.拷贝JDBC驱动
下载mysql-connector-java-5.1.48解压后将mysql-connector-java-5.1.48.jar拷贝到sqoop的lib目录下:
cp mysql-connector-java-5.1.48/mysql-connector-java-5.1.48.jar /opt/software/sqoop-1.4.7/lib/
- 1
或者从hive的lib目录下复制一份到sqoop的lib目录下:
cp /opt/software/hive-2.3.4/lib/mysql-connector-java-5.1.48.jar /opt/software/sqoop-1.4.7/lib/
- 1
3.测试Sqoop连接mysql
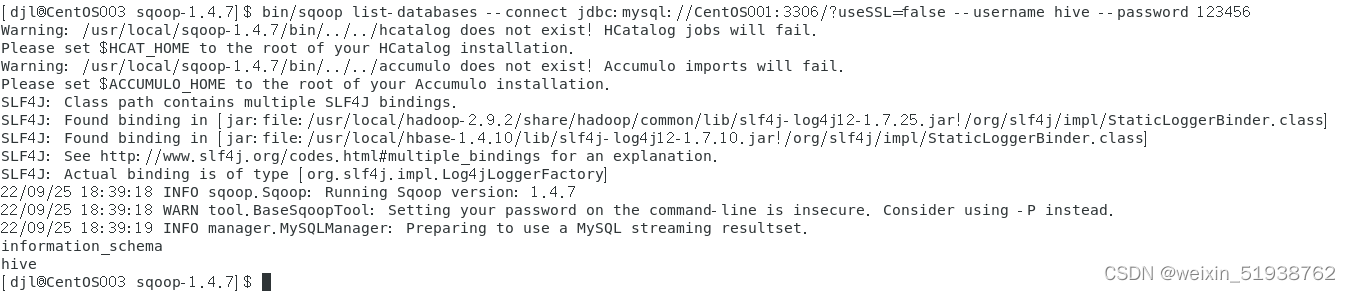
使用具有远程登录权限的用户登录mysql:
bin/sqoop list-databases --connect jdbc:mysql://centos001:3306/useSSL=false --username hive --password 123456
- 1
4.mysql导入数据到HDFS
sqoop import --connect jdbc:mysql://centos001:3306/hive?useSSL=false --username hive --password 123456 --table DBS -m 1
- 1
import
从非大数据集群(RDBMS)向大数据集群(HDFS,HIVE,HBASE)中传输数据,叫做:导入
–connect jdbc:mysql://centos001:3306/hive?useSSL=false
–username hive
–password 123456
#对远程mysql中的hive数据库进行连接
–table DBS
#导出mysql中hive数据库下的DBS表
-m 1
#指定map数量为1
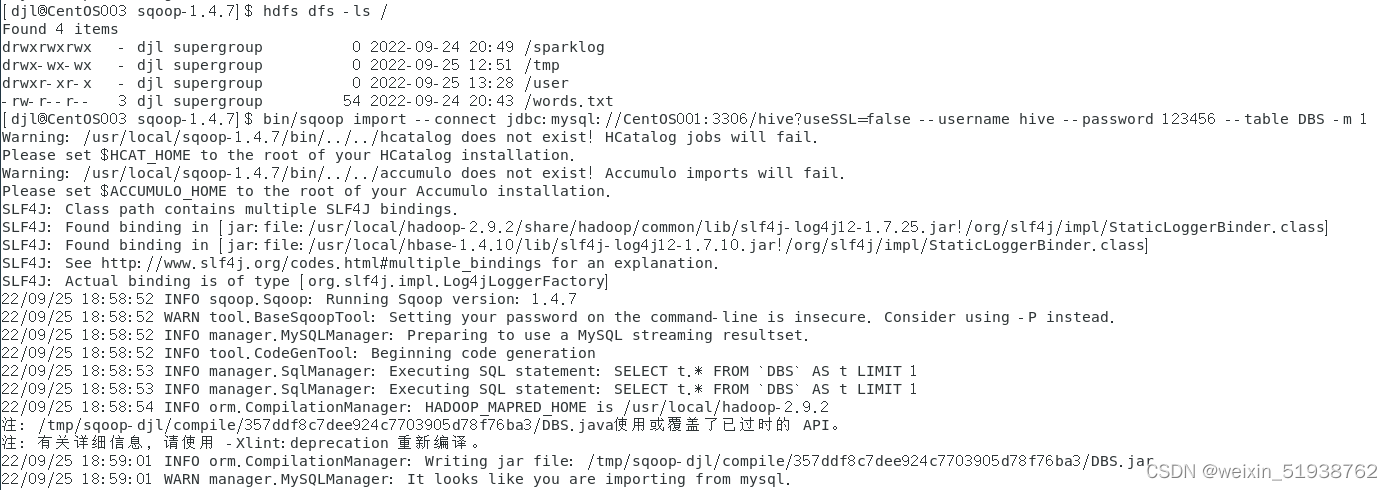
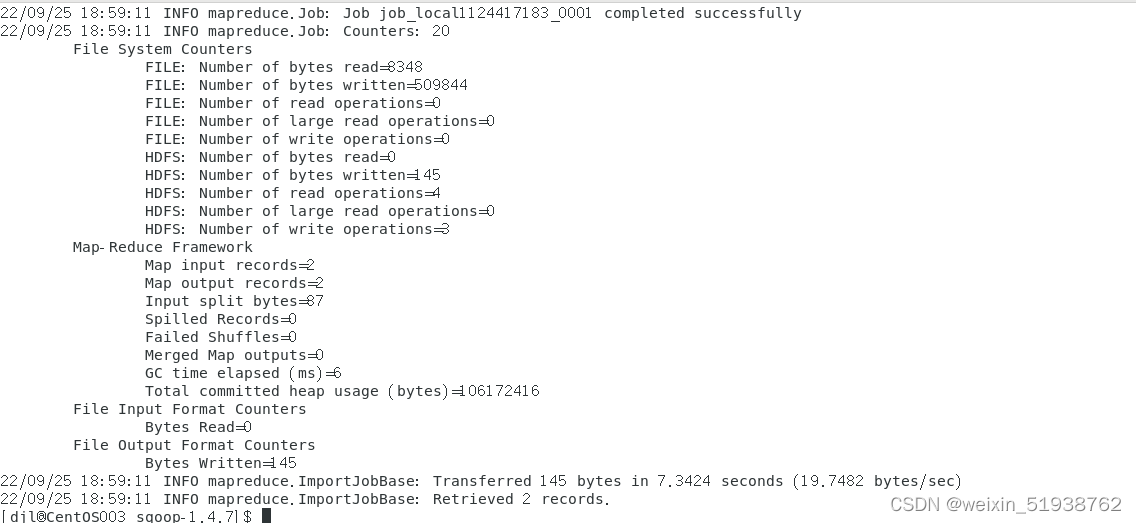
默认导出到hdfs的 “/user/用户名/mysql中导出的表名” 目录下:

十五、Flume安装
1.在CentOS3下安装Flume-1.9.0
上传至虚拟机,并解压
sudo tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/software/
- 1
重命名
sudo mv /opt/software/apache-flume-1.9.0-bin.tar.gz /opt/software/flume-1.9.0
- 1
查看flume版本
flume-ng version
- 1
2.操作待定
测试:
监控一个目录,将数据打印出来
# 首先先给agent起一个名字 叫a1 # 分别给source channel sink取名字 a1.sources = r1 a1.channels = c1 a1.sinks = k1 # 分别对source、channel、sink进行配置 # 配置source # 将source的类型指定为 spooldir 用于监听一个目录下文件的变化 # 因为每个组件可能会出现相同的属性名称,所以在对每个组件进行配置的时候 # 需要加上 agent的名字.sources.组件的名字.属性 = 属性值 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /opt/software/data/ a1.sources.r1.fileSuffix = .ok a1.sources.r1.fileHeader = true # 给r1这个souces配置一个拦截器并取名为 i1 a1.sources.r1.interceptors = i1 # 将拦截器i1的类型设置为timestamp 会将处理数据的时间以毫秒的格式插入event的header中 # a1.sources.r1.interceptors.i1.type = timestamp # 将拦截器i1的类型设置为regex_filter 会根据正则表达式过滤数据 a1.sources.r1.interceptors.i1.type = regex_filter # 配置正则表达式 a1.sources.r1.interceptors.i1.regex = \\d{3,6} # excludeEvents = true 表示将匹配到的过滤,未匹配到的放行 a1.sources.r1.interceptors.i1.excludeEvents = true # 配置sink # 使用logger作为sink组件,可以将收集到数据直接打印到控制台 a1.sinks.k1.type = logger # 配置channel # 将channel的类型设置为memory,表示将event缓存在内存中 a1.channels.c1.type = memory # 组装 # 将sources的channels属性指定为c1 a1.sources.r1.channels = c1 # 将sinks的channel属性指定为c1 a1.sinks.k1.channel = c1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
启动agent
flume-ng agent -n a1 -f ./spoolingtest.conf -Dflume.root.logger=DEBUG,console
- 1
新建/usr/local/data目录
mkdir /opt/software/data
- 1
在/usr/local/data目录下新建文件,输入内容,观察flume进程打印的日志
vim /opt/software/data/789.txt
- 1
十六、kafka-2.1.1集群配置
1.在CentOS001上修改server.properties配置文件
cd /opt/software/kafka-2.1.1/config/
vim server.properties
- 1
- 2
#broker 的全局唯一编号,不能重复,只能是数字。 broker.id=0 #处理网络请求的线程数量 num.network.threads=3 #用来处理磁盘 IO 的线程数量 num.io.threads=8 #发送套接字的缓冲区大小 socket.send.buffer.bytes=102400 #接收套接字的缓冲区大小 socket.receive.buffer.bytes=102400 #请求套接字的缓冲区大小 socket.request.max.bytes=104857600 #kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以 #配置多个磁盘路径,路径与路径之间可以用","分隔 log.dirs=/opt/software/kafka-2.1.1/datas #topic 在当前 broker 上的分区个数 num.partitions=1 #用来恢复和清理 data 下数据的线程数量 num.recovery.threads.per.data.dir=1 # 每个 topic 创建时的副本数,默认时 1 个副本 offsets.topic.replication.factor=2 #segment 文件保留的最长时间,超时将被删除 log.retention.hours=168 #每个 segment 文件的大小,默认最大 1G log.segment.bytes=1073741824 # 检查过期数据的时间,默认 5 分钟检查一次是否数据过期 log.retention.check.interval.ms=300000 #配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理) zookeeper.connect=centos001:2181,centos002:2181,centos003:2181,centos004:2181/kafka
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
2.在CentOS001上分发kafka-2.1.1给CentOS002与CentOS003
scp -r /opt/software/kafka-2.1.1 root@centos002:/opt/software/
scp -r /opt/software/kafka-2.1.1 root@centos002:/opt/software/
- 1
- 2
3.在CentOS002与CentOS003上修改配置文件kafka-2.1.1/config/server.properties
分别修改部分其中的配置为broker.id=1、broker.id=2
4.先启动zookeeper集群然后启动kafka集群
每台CentOS执行(已启动zk集群请忽略):
zkServer.sh start
- 1
zookeeper集群启动成功后
CentOS001、CentOS002、CentOS003执行:
bin/kafka-server-start.sh -daemon config/server.properties
- 1
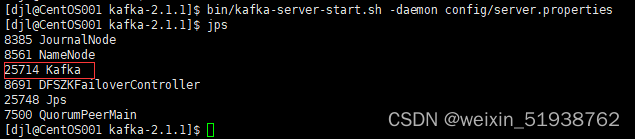
5.测试kafka集群
(1)CentOS001创建有一个副本分区test主题
bin/kafka-topics.sh --create --zookeeper centos001:2181/kafka --topic test --partitions 1 --replication-factor 1
- 1

(2)CentOS002启动消费端接收消息
bin/kafka-console-consumer.sh --bootstrap-server centos002:9092 --topic test
- 1

(3)CentOS003启动生产端发送消息到主题test
bin/kafka-console-producer.sh --broker-list centos003:9092 --topic test
- 1

最后CentOS002获取到消息就说明kafka集群部署成功了

十七、配置Hbase-1.4.10集群
1.配置hbase-env.sh文件
添加以下内容:
export HBASE_PID_DIR=/opt/software/hbase-1.4.10/pids
export HBASE_MANAGES_ZK=false
- 1
- 2
2.配置hbase-site.xml
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster:8020/hbase</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>centos001,centos002,centos003,centos004</value>
</property>
</configuration>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.配置regionservers
centos001
centos002
centos003
- 1
- 2
- 3
4.配置高可用HMaster节点
在conf/目录下创建backup-masters文件
vim conf/backup-masters
- 1
写入
centos004
- 1
5.将hbase发送到其他CentOS
scp -r /opt/software/hbase-1.4.10 root@centos002:/opt/software/
scp -r /opt/software/hbase-1.4.10 root@centos003:/opt/software/
scp -r /opt/software/hbase-1.4.10 root@centos004:/opt/software/
- 1
- 2
- 3
6.启动hbase集群
先开启hadoop集群以及zookeeper集群
然后再开启hbase集群
bin/start-hbase.sh
- 1
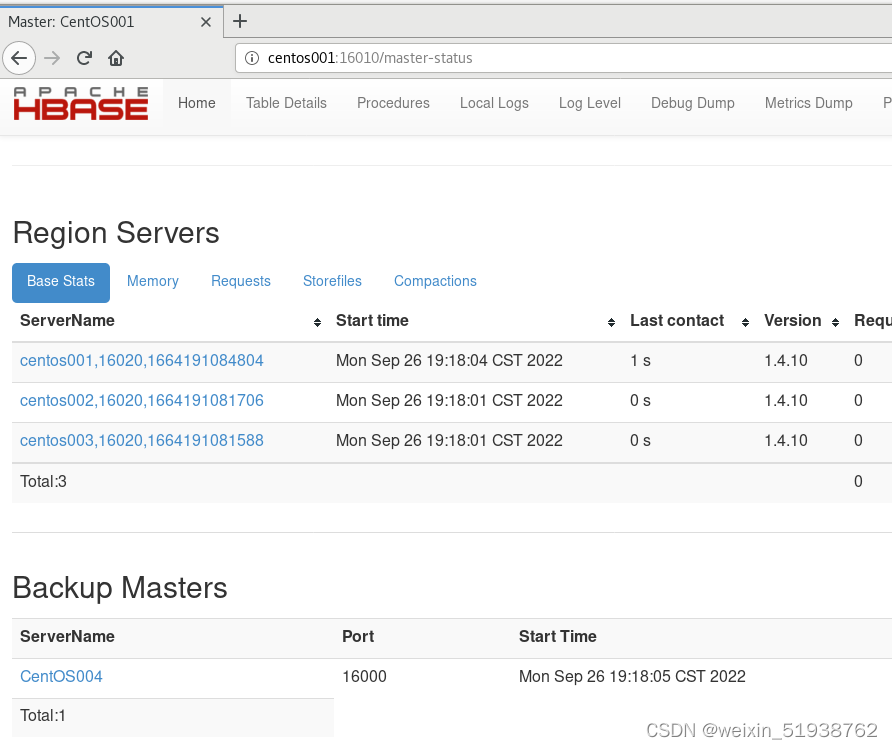
7.测试Hbase HA
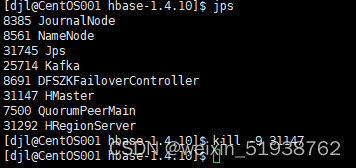
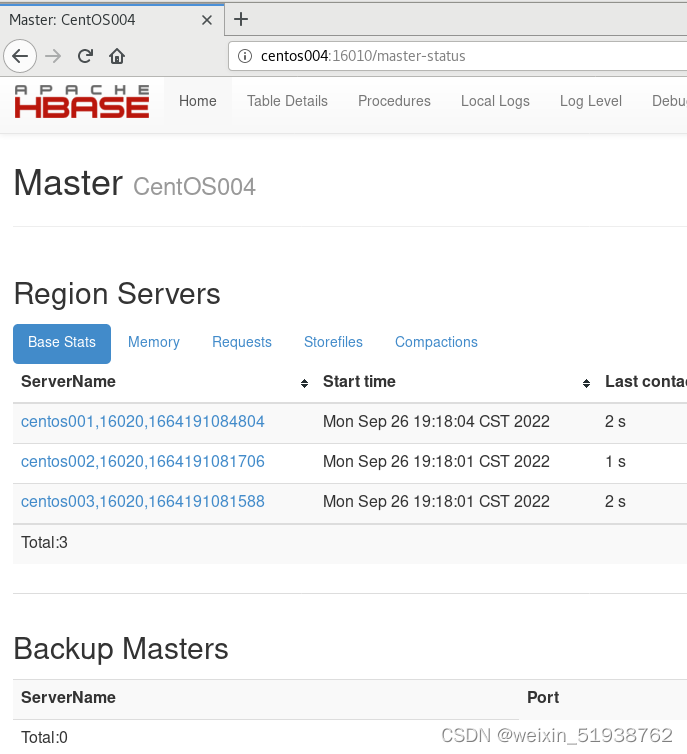

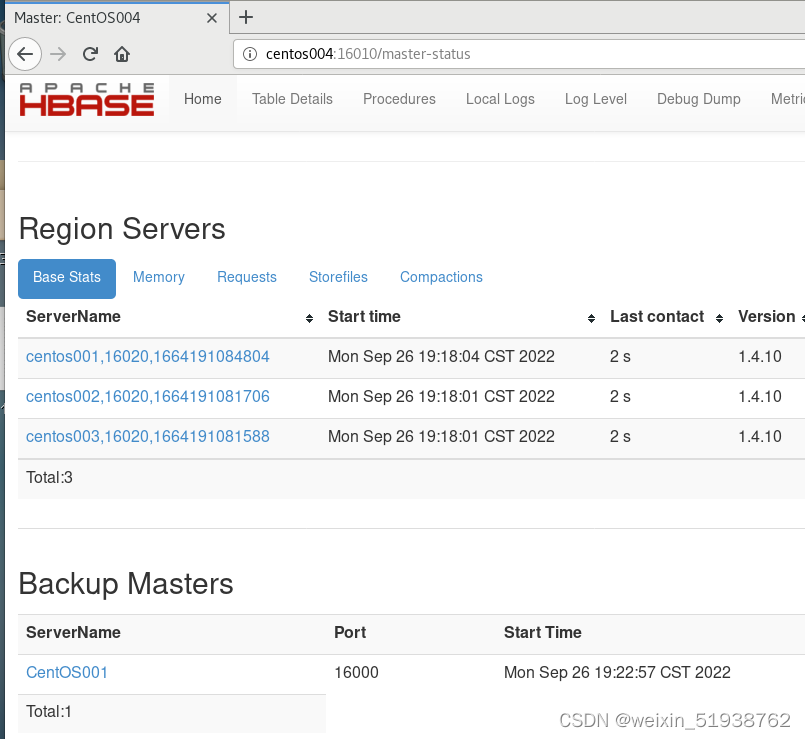
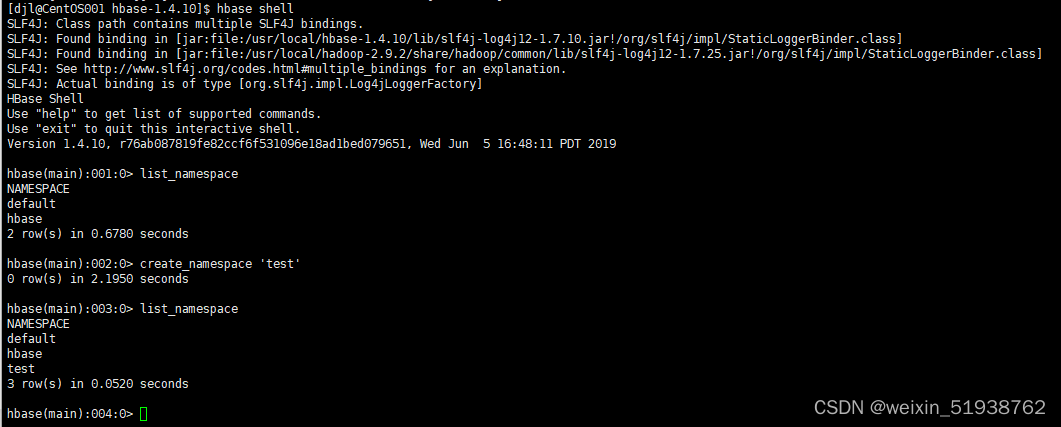
至此Hbase HA集群搭建成功!

