
热门标签
热门文章
- 1jQuery.print.js去掉不显示页眉页脚网址标题当前时间_jqprint去掉页眉页脚
- 2python问题unindent does not match any outer indentation level在pycharm平台的解决方法
- 3Web站点,应用,应用服务器_站点应用是什么
- 4FastDFS 设计理念、文件上传、下载、同步、删除和断点续传原理_fastdfs支持断点续传
- 5SQLServer 创建全文索引(两种方法)_sqlserver 全文索引
- 6linux7开启端口22,Linux centos7如何开放端口
- 7MYSQL每日一用:SELECT 语句中比对(between and \ like \ left)
- 8PyCharm之安装插件_pycharm form disk
- 9Redis与MySQL双写一致性_双写:双写是指同时将数据写入mysql和redis。这种方法可以保证数据的一致性,
- 10fastdfs连接超时报错解决方案_fastdfs pooledconnectionfactory连接错误
当前位置: article > 正文
机器学习中为什么需要梯度下降?梯度下降算法缺点?_【机器学习-回归】梯度下降(SGD/BGD/MBGD)...
作者:花生_TL007 | 2024-02-18 03:21:36
赞
踩
为什么调查报告使用梯度下降
上一节讲完线性回归的模型思路与损失函数,我们的目的当然是求解参数
那么下面如何操作可以寻找到这个最值点呢?答:梯度下降。
梯度下降法目的是寻找极值点,其本质可以类比为一个下山的过程。假设这样一个场景:一个人被困在山上,需要找到山谷。但由于视野等原因,下山的路径就无法确定,他必须利用自己周围的信息去找到下山的路径。这个时候,他就可以利用梯度下降算法来帮助自己下山。具体来说就是,以他当前的所处的位置为基准,朝着山的高度下降的地方走,然后不断调整方向。同理,如果我们的目标是上山,也就是爬到山顶,那么此时应该是朝着最陡峭的方向往上走。然后每走一段距离,都反复采用同一个方法,最后就能成功的抵达山谷。

鉴于此思想,可以得到由梯度下降的基本公式:
这里
结合前一篇文章线性回归(附链接):
不愿露名的笨马:【机器学习-回归】线性回归zhuanlan.zhihu.com
由于最终模型有形式:
且损失函数为:
则结合(1)式,可通过对
还有最后一个问题,根据怎样的样本确认梯度更新呢?这样就引出了以下三个概念:
- 随机梯度下降 (Stochastic Gradient Descent,SGD):每次迭代使用一个样本对梯度更新。
- 批量梯度下降(Batch Gradient Descent,BGD):每次迭代时使用全部样本进行梯度更新。
- 小批量梯度下降(Mini-Batch Gradient Descent,MBGD):每次迭代时使用若干样本进行梯度更新。
可以看出,MBGD可以看做SGD与BGD的折中办法,这里我们对比SGD与BGD的算法与优缺点。
随机梯度(SGD)
单样本损失函数:
对损失函数求偏导:
参数更新:
优势
- 由于每次迭代所选取的样本少,在每轮迭代中,只随机优化某一条训练数据上的损失函数,使得每轮参数更新速度大大加快。
劣势
- 同样由于每次迭代选取的样本少,梯度更新方向无法顾及到其余样本,因而准确性较低。
- 同样的原因,容易收敛到局部最优解而非全局最优解(即使损失函数为凸)。
- 难以并行。
批量梯度(BGD)
全体样本损失函数:
对损失函数求偏导:
参数更新:
优势
- 每次迭代对全部样本计算,利用矩阵,可以并行计算。
- 损失函数为凸时,可以得到全局最优解。
劣势
- 训练速度慢。
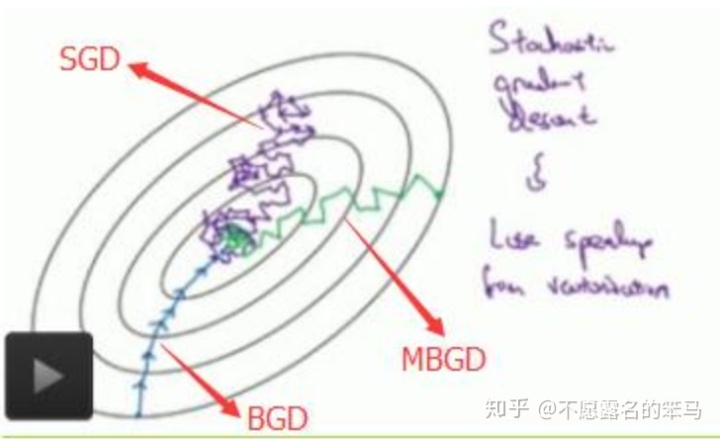
最后附一张SGD、BGD与MBGD之间的对照图。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/花生_TL007/article/detail/104214
推荐阅读
相关标签

