
- 1前后端分离部署(基于vue)_导入别人的前后端分离项目为什么会出现eplise
- 2关于requests.exceptions.ProxyError:报错的解决办法_requests.exceptions.proxyerror: httpconnectionpool
- 3华为机试 108 题(C 语言解答)_华为机考 c卷
- 4UNIX高级编程【深入浅出】第四章文件和目录(上)
- 5操作无法完成错误0x00000bc4的修复方法,以及出现0x00000bc4的原因
- 6【Linux】CentOS 7图形化界面——安装配置全流程_centos7安装图形化界面
- 7python如何base64_python base64
- 8服务器部署测试环境回顾与改进建议
- 9python绘制棋盘_python3 turtle 画围棋棋盘
- 10解决selenium报错导致程序异常终止_selenium timeoutexception: message:
车牌识别数据集CCPD介绍_ccpd车牌数据集
赞
踩
转载自:https://blog.csdn.net/yang_daxia/article/details/88234138
这是一个用于车牌识别的大型国内的数据集,由中科大的科研人员构建出来的。发表在ECCV2018论文Towards End-to-End License Plate Detection and Recognition: A Large Dataset and Baseline
https://github.com/detectRecog/CCPD
该数据集在合肥市的停车场采集得来的,采集时间早上7:30到晚上10:00.涉及多种复杂环境。
一共包含超多25万张图片,每种图片大小720x1160x3。一共包含9项。每项占比如下图:

各项意义如下:
| CCPD- | 数量/k | 描述 |
| Base | 200 | 正常车牌 |
| FN | 20 | 距离摄像头相当的远或者相当近 |
| DB | 20 | 光线暗或者比较亮 |
| Rotate | 10 | 水平倾斜20-25°,垂直倾斜-10-10° |
| Tilt | 10 | 水平倾斜15-45°,垂直倾斜15-45° |
| Weather | 10 | 在雨天,雪天,或者雾天 |
| Blur | 5 | 由于相机抖动造成的模糊 |
| Challenge | 10 | 其他的比较有挑战性的车牌 |
| NP | 5 | 没有车牌的新车 |
数据标注:文件名就是数据标注.
如:025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg
由分隔符'-'分为几个部分:
1)025为区域,
2)95_113 对应两个角度, 水平95°, 竖直113°
3)154&383_386&473对应边界框坐标:左上(154, 383), 右下(386, 473)
4)386&473_177&454_154&383_363&402对应四个角点坐标
5)0_0_22_27_27_33_16为车牌号码 映射关系如下: 第一个为省份0 对应省份字典皖, 后面的为字母和文字, 查看ads字典.如0为A, 22为Y.....
-
provinces = [
"皖",
"沪",
"津",
"渝",
"冀",
"晋",
"蒙",
"辽",
"吉",
"黑",
"苏",
"浙",
"京",
"闽",
"赣",
"鲁",
"豫",
"鄂",
"湘",
"粤",
"桂",
"琼",
"川",
"贵",
"云",
"藏",
"陕",
"甘",
"青",
"宁",
"新",
"警",
"学",
"O"]
-
-
ads = [
'A',
'B',
'C',
'D',
'E',
'F',
'G',
'H',
'J',
'K',
'L',
'M',
'N',
'P',
'Q',
'R',
'S',
'T',
'U',
'V',
'W',
'X',
-
'Y',
'Z',
'0',
'1',
'2',
'3',
'4',
'5',
'6',
'7',
'8',
'9',
'O']
- 1
6)37亮度
7)15模糊度
所以根据文件名即可获得所有标注信息.
模型:

10层卷积提取特征,经过三个全连接层到边界框:此为检测部分,
提取1,3,5层的特征用于ROI池化,因为底层特征有益于提高语义分割的质量,高层特征受益不大,且花费更多的时间。然后经过ROI池化,resize后 拼接在一起,输入到车牌号码识别器。目标函数如下:
roi池化参考:https://blog.csdn.net/auto1993/article/details/78514071
smoothL1损失为了防止预测值和label相差过大,梯度爆炸:https://blog.csdn.net/weixin_35653315/article/details/54571681
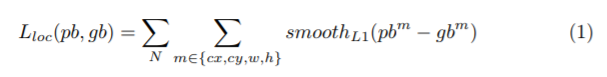
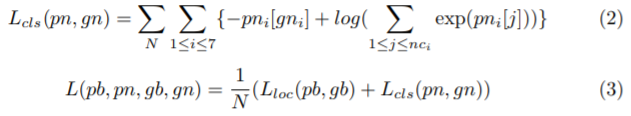
=================================================================================================
发现老的ccpd的标注有很多不正确,最近ccpd更新了数据以及标注.
数据量 ccpd_base: 200k
ccpd_challenge : 50k 相对增加40k
ccpd_blur:20.6k
ccpd_db:10k 相对较少10k
ccpd_fn:20.9k
ccpd_weather :10k
ccpd_rotate:10k
ccpd:tilt:30k 相对增加20k
所以总体增加50k
同时增加了数据量,为了和论文对比还是使用原始的数据量把, 可以更新标注
base 有5万5千多张重复的车牌号码, 所以不能用车牌号码校对, 但是md5值不唯一,所以可以用这个来校对
ccpd子集之间有重复图片, 但是单个子集没有重复的, 这样就可以一个一个子集校对
使用车牌号码也无法校对, 因为有同一个车牌号码, 不同角度的车.
所以目前的结论为base可以根据MD5校对, 其他子集无法校对.

