
- 1Stable diffusion报Torch is not able to use GPU; add --skip-torch-cuda-test to COMMANDLINE_ARGS variab_runtimeerror: torch is not able to use gpu; add --
- 2【C语言】八道经典指针笔试题(详解)_c语言指针例题及解析
- 3硬件越跑越快,软件越陷越慢
- 4can 常见面试题_can总线面试问题
- 5【Java前端技术栈】ES6-ECMAScript6.0
- 6LLM之RAG理论(四)| RAG高级数据索引技术
- 7解决pip超时的问题_pip-23.2.1-py3-none-any.whl
- 8python:threading.Thread类的使用详解_python-threading
- 9远程连接ECS服务器提示了Connection refused,怎么办?_远程桌面connection refused
- 10debian10安装x ui失败_debian 10x-ui安装命令
《C陷阱与缺陷》笔记
赞
踩
变量的定义位置
先上一段看来比较正常的代码:
#include<stdio.h>#include<stdlib.h>int main(void){ printf("Tim\n"); int a = 10; printf("a = %d\n",a); system("pause"); return 0;}由于我的环境是VisualStudio2013,所以上述程序可以完美执行,并且是编译0警告通过,但是在VisualStudio2008的环境下这样写是完全错误的,C89规定,在任何执行语句之前,在块的开头声明所有局部变量。但是在C99以及C++中则没有这个限制,即在首次使用之前,可在块的任何位置都可以声明变量。例如下面的写法对于C89标准才是正确的:
#include<stdio.h>#include<stdlib.h>int main(void){ printf("sssssssss\n"); { int a = 10; printf("a = %d\n", a); } system("pause"); return 0;}当然为了达到更好兼容性,建议都把局部变量写在代码块的开始位置!!
define与typedef
1、函数式宏定义的参数没有类型,预处理器只负责做形式上的替换,而不做参数类型检查,所以危险性高;但因为省去了函数的调用,返回,释放,所以效率比自定义函数高;
2、调用真正函数的代码和调用函数式宏定义的代码编译生成的指令不同。
如果MAX是个普通函数,那么它的函数体return a > b ? a : b; 要编译生成指令,代码中出现的每次调用也要编译生成传参指令和call指令。而如果MAX是个函数式宏定义,这个宏定义本身倒不必编译生成指令,但是代码中出现的每次调用编译生成的指令都相当于一个函数体,而不是简单的几条传参指令和call指令。所以,使用函数式宏定义编译生成的目标文件会比较大。
3、在执行复杂功能时,如递归,函数式宏定义往往会导致较低的代码执行效率。
尽管函数式宏定义和普通函数相比有很多缺点,但只要小心使用还是会显著提高代码的执行效率,毕竟省去了分配和释放栈帧、传参、传返回值等一系列工作,因此那些简短并且被频繁调用的函数经常用函数式宏定义来代替实现。
①define定义符号
②定义比较长的关键字
#define reg register③用更加形象的的符号替代另一种实现
#define do_forever for( ; ; )④在写switch语句的时候自动把break加上
#define CASE break;case⑤打印日志
#define DEBUG_PRINT >printf(“file:%s\tline:%d\tdate:%s\ttime:%s\n”,FILE,_LINE__,DATE,TIME)使用宏时候的提示:所有对于数值表达式求值得宏定义都应该用这种方式加上括号,避免在使用宏的时候由于参数中的操作符之间不可预料的相互作用。
define 替换
在程序中扩展#define定义符号和宏时,需要涉及几个步骤。
在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们首先被替换。
替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值替换。
最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上述处理过程。
注意:
宏参数和#define 定义中可以出现其他#define定义的变量。但是对于宏,不能出现递归。
当预处理器搜索#define定义的符号的时候,字符串常量的内容并不被搜索。
“#”与”##”
使用”#”把宏参数变成对应的字符串
#define PRINT(FORMAT, VALUE)\ printf("the value of "#VALUE" is "FORMAT"\n", VALUE) int main(void){ //这里只有当字符串作为宏参数的时候才可以把字符串放在字符串中 PRINT("%d", 5 + 10); system("pause"); return 0; }“##”可以把位于它两边的符号合成一个符号。
它允许宏定义从分离的文本片段创建标识符。
注意:这样的连接必须产生一个合法的标识符。否则其结果就是未定义的。
接下来说说宏与函数
宏通常被应用于执行简单的运算。比如在两个数中找出较大的一个:
#define GET_MAX(a,b) a>b?a:b用于调用函数和从函数返回的代码可能比实际执行这个小型计算工作所需要的时间更多。所以宏比函数在程序的规模和速度方面更胜一筹。
更为重要的是函数的参数必须声明为特定的类型。所以函数只能在类型合适的表达式上使用。反之这个宏怎可以适用于整形、长整型、浮点型等可以用于来比较的类型。宏是类型无关的
和函数相比宏的缺点
每次使用宏的时候,一份宏定义的代码将插入到程序中。除非宏比较短,否则可能大幅度增加程序的长度。
宏是没法调试的。
宏由于类型无关,也就不够严谨。
宏可能会带来运算符优先级的问题,导致程容易出现错
宏的其他注意事项:宏可以传类型,但是函数不行
#define _CRT_SECURE_NO_WARNINGS #include<stdio.h> #include<stdlib.h> #define MALLOC(num, type)\ (type *)malloc(num * sizeof(type)) int main(void) { int* p = MALLOC(3, int); system("pause"); return 0; }带副作用的宏参数
#define MAX(a,b) ((a)>(b)?(a):(b))int main(int argc,char** argv){ int a = 5; int b = 8; int z = MAX(a++,b++); printf("a=%d b=%d z=%d\n",a,b,z);}上例就说明了带副作用的宏参数的危害
有时不把宏写成全部大写,是为了让别人把它当做函数理解
函数和宏的对比
| 属性 | #defien宏 | 函数 |
| :———-: | :———————————————————– | :———————————————————– |
| 代码长度 | 每次使用时,宏代码都被插入到程序中,除了非常短的宏之外,程序的长度将大幅度增长 | 函数代码只会出现在同一个地方,每次使用这个函数时都会调用这段代码 |
| 执行速度 | 更快 | 存在函数弹栈、压栈的开销 |
| 操作符优先级 | 宏参数的求值实在所有周围表达式的上下文环境里,除非它们加上括号,否侧邻近操作符的优先级可能会产生不可预料的后果 | 函数参数只在函数调用时求值一次,它的结果值将传递给函数,表达式的求值很容易预测 |
| 参数求值 | 参数每次用于宏定义时, 它们都将重新求值,具有副作用的参数可能会产生不可预料的结果 | 参数在函数调用前只求值一次,在函数中多次使用参数并不会带至多种求值过程,参数的副作用并不会造成任何的问题 |
| 参数类型 | 宏与类型无关,只要对参数的操作是合法的,它可以适用于任何参数类型 | 函数参数与类型有关,如果参数的类型不同,就需要使用不同的函数,即使它们的逻辑任务是相同的 |
| 调试 | 宏在预处理阶段就已经替换,所以无法执行调试 | 函数是可以调试的 |
| 其他 | 宏不具备函数的性质,不能递归 | 函数可以递归 |
浮点数与其他数字的比较
C语言中浮点数同0不能直接用==比较,只能看浮点数与0值的误差,原因如下:float是浮点数,存的是近似值,当用来表示0的时候,有可能计算结果是0,但是由于精度问题,实际上存储的是一个和0很接近的值,而==做判断的话只要不是完全相等就返回假,所以用==判断float有可能出错。
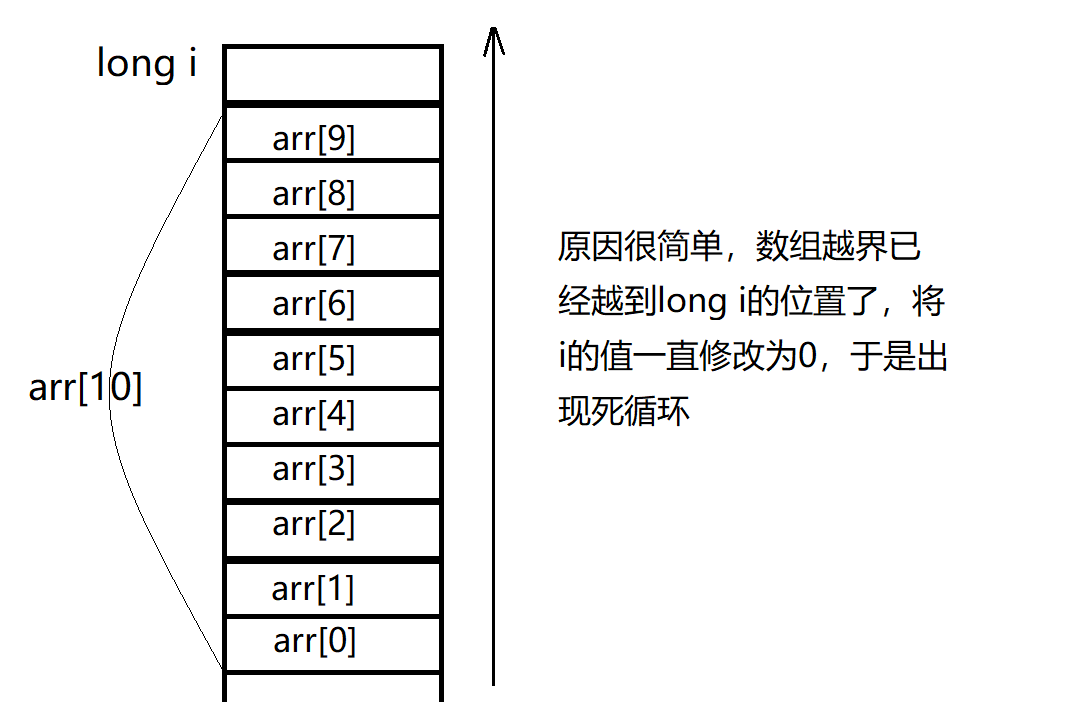
数组越界问题
下面一段程序:
#define _CRT_SECURE_NO_WARNINGS#include<stdio.h>#include<stdlib.h>int main(void){ long i; long arr[10]; for (i = 0; i <= 12; i++){ arr[i] = 0; printf("hehe\n"); } system("pause"); return 0;}看起来只是一个数组越界访问的问题,但是会引起死循环,
字符究竟是什么样的整数
我们需要把一个字符值转换为一个较大的整数的时候,这个问题才变得重要起来。而在其他情况下,结果都是已经定义:多余的位将简单的被“丢弃”丢弃编译器在将char类型为int类型的时候,需要做出选择:应该将字符作为有符号整数还是应该是无符号整数处理?如果是前一种情况,编译器在将char类型的数扩展到int类型时,应该同时赋值符号位,如果是后一种情况,编译器只需要在多余的位上用0填充即可。
如果说一个字符的最高位是1,编译器是将该字符当成是有符号数还是当做无符号数呢?这个选择非常重要,它决定着一个8字符的取值范围是从-128到127还是从0到255.而这一点,又会反过来影响到程序员岁哈希表或者转换表的设计方式。
如果编程者最关注的一个高位是1 的字符其数值究竟是正还是负,可将字符声明为无符号字符(unsigned char)。这样无论什么编译器将该字符转换为整数的时候只需要多余的位填充为0即可,而如果声明为一般的字符变量,那么有些编译器上可能会作为有符号处理,而另一些编译器又会作为无符号数处理。
与此相关的一个常见错误认识是:如果c是一个字符变量,使用(unsigned )c就可以得到与c等价的一个无符号整数,但是这是会失败的,因为将字符c转化为无符号整数时,c将首先被转化为一个int型整数,因此可能会得到一个非预期的结果。
下面说说正确的方式:使用(unsigned char) c ,因为一个unsigned char 类型的字符在转化为无符号整数时无需首先转化为int型整数,而是直接进行转换。
接下来再说说getchar()函数,先看下面一段代码:
#include<stdio.h>int main(void){ char c; while ((c = getchar()) != EOF){ putchar(c); } return 0;}这个程序表面上是把标准输入复制到标准输出,实则不然,原因是c被声明为char类型,而getchar()的返回值是int类型,这意味着c可能无法容纳下所有可能的字符,特别是可能无法容纳EOF,但是还好在VS下的EOF是-1
使用char类型的变量去接收返回值为int型的结果,最终会有3种可能:
1、某些合法的字符被截断后使得c的取值与EOF相同,这样的话程序将在赋值文件的过程中就终止;
2、c根本不可能取到EOF这个值,那么程序将陷入死循环;
3、程序会正常工作,但完全是因为巧合,尽管getchar()的返回值赋值给c的时候会发生截断,尽管while语句中比较运算符的操作数不是getchar()的返回值,而是截断后的值c。然而令人惊讶的是许多编译器对上述表达式的实现并不正确。这些编译器确实对getchar()的返回值做了截断处理,并把低端字节部分赋值给了变量c。但是它们在表达式中并不是比较c与EOF的值,而是比较getchar()函数的返回值与EOF,如果编译器采用的是红色字段的方法,那么程序完全可以正常运行!


- 本文作者: Tim
- 本文链接: https://zouchanglin.cn/2018/04/29/2592080764.html
- 版权声明: 本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 许可协议。转载请注明出处!

