
- 1GitHub之GitHub Actions的项目自动化持续集成和部署_github action 可持续集成 跨平台 c++库
- 2保姆级讲解 Samba服务器的配置与管理
- 3记录-element ui table表格数据更新问题_miniui 点击事件改变值内容
- 4java导出excel 【POI 3.17】POI 版本不匹配解决方法_cannot resolve org.apache.poi:poi-ooxml:3.17
- 5推荐几款Pycharm插件,大大提升开发效率!_pycharm代码补全插件
- 6RecyclerView的多布局实现_recyclerview多布局实现
- 7Linux安装ssh |Ubuntu安装ssh |Ubuntu配置ssh_sudo apt-get install openssh-server
- 8k8s:PVC 的使用_k8s查看pvc使用情况
- 9uniapp学习笔记——基于<uni-file-picker>组件和uni.uploadFile()方法实现图片上传
- 10React17+Hook+TS4+VSCode开发环境搭建(2021)_react hooks ts项目搭建
NLP-D22-cs224n&UNICORN&多层感知机&房价预测kaggle_kaggle波士顿房价预测多层感知机参数
赞
踩
–0519今天0430起床的,早上开始看cs224n,感觉老师好可爱!
现在开始读论文啦!
一、Unicorn
—0558感觉还是有创新的!但是一时间说不上来?可能是时间与关系在溯源图中的综合???先干饭!
–0621吃饭的时候看了cs224n,讲的很细。主要讲了word2vec,具体是如何去做word2vec这件事。
1、用中心词预测周围词
2、用两套向量,分别表示这个词作为中心词和作为周围词时的向量表示
3、优化目标:预测准确----》数学表达:P(预测的周围词|已知的中心词)=把所有词都当做中心词这样做一遍【两词之间的相似度/(字典中所有词和已知中心词的相似度求和)】
这里用两词之间的相似度近似其被预测的可能性,也就是认为,如果两词越相近,就越可能被预测出。
我们希望优化目标越大越好,通过一系列变换(加负号,除以整个字典大小),变成最小化问题,用梯度下降解决(看这意思,老师好像想开始讲梯度下降了,好细啊)
----0627继续读论文,今天读完background就去撸代码!
—0720看到不少专业词汇,好困,想趴一会。。。
—0746复习一下昨天框架的api,就去收拾宿舍了!
注意:
1、ReLU的大小写
2、normal是在torch.init中的
3\dropout的手撕和简洁实现
(1)简洁实现

(2)手撕
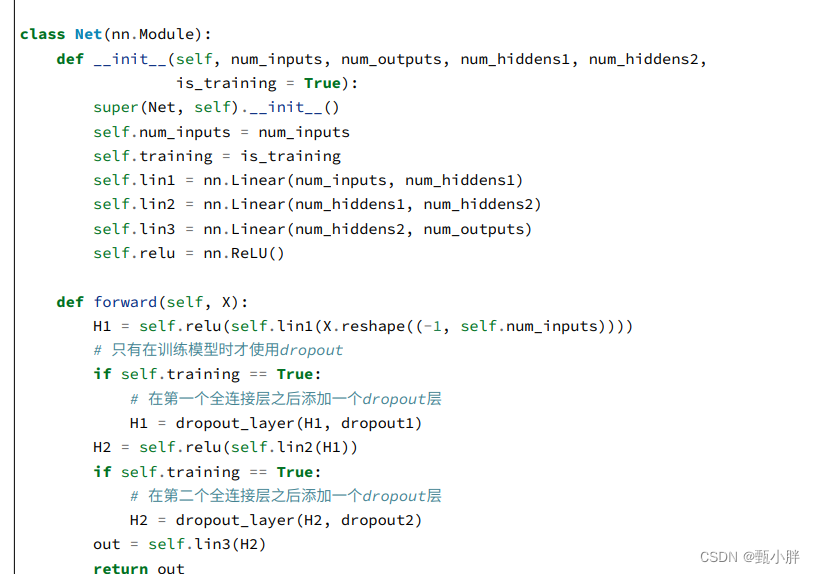
这里的简洁主要是说,在使用dropout上。
之所以手撕时没有直接使用nn.Sequential()是因为需要判断是在训练还是在测试,在测试时不用dropout,所以不能直接用sequential,需要加入判断逻辑,用继承nn.Module来更加灵活地定义网络。。
框架帮我们自动在dropout层(nn.Dropout)完成了对于训练和测试的判断,使我们直接能将其写在nn.Sequential中。
4\注意optim和init的位置
torch.optim.SGD()
nn.init.normal_
5\感觉正则化这块weight-decay和dropout理解的不是特别好,可以再去看下视频,至少解决两个一起用,效果会不会更好这个问题。
—1055去干饭!
—1507突发了很多事,现在才能回来学习。
中午吃饭的时候又看了下dropout,其实也是一种正则(约数w的),但是没有被证明啦。不过最先提出的时候是想着增加数据的扰动,在源头进行dropout已经被证明啦!
—1607不想学了,想去跑步了。。。
----1900感觉有惯性,还是回来做题看翻译了,放松不下来啊。
—1928今天很快,去看下翻译,应该还有时间敲pytorch
—2002看完翻译了鹅鹅鹅犹豫是休息一下还是看pytorch
—2019看了一小会cs224n,虽然能听懂,但还是想先看李宏毅老师的课程再来听这个,感觉理解会更深刻。
----2032确实不想刷视频了鹅鹅鹅去做核酸叭顺便看看沐沐。晚上有时间回来敲代码。
–2123回来了,继续写pytorch了!
1、slice使用
slice是切片对象
https://www.runoob.com/python/python-func-slice.html
2、pd.Series用法
—2229代码敲完了,感觉尽管是很简单的比赛,实际做起来都这么复杂,自己都不一定能写明白。明天看下剩下的小结部分,然后自己手撕一遍整个流程。
先去睡了!晚安

