
- 1基于Labview的空气质量监测系统设计_STM32F103C8T6(程序+原理图+PCB)_labview stm32 nrf
- 2C++Yolov4目标检测实战_c++ yolo
- 3Conda复制已经存在的环境_conda环境复制
- 4企业微信机器人WorkTool使用文档
- 5二、张量 CP 分解_cp分解 张量补全 拟合度
- 6Spring Boot 中各种缓存的使用_replicateasynchronously
- 7Python pyserial 模块安装(pycharm中安装)[ModuleNotFoundError: No module named ‘serial‘ 报错解决方法]_no module named 'serial
- 8GPL开源软件能商用吗?_gpl3.0可以商用吗
- 9端到端TVM编译器(上)_tvm build
- 10一篇文章带你读懂批处理命令_批处理 进程筛选器
4个大语言模型训练中的典型开源数据集_语言模型 数据集
赞
踩
本文分享自华为云社区《浅谈如何处理大语言模型训练数据之三开源数据集介绍》,作者: 码上开花_Lancer。
随着最近这些年来基于统计机器学习的自然语言处理的算法的发展,以及信息检索研究的需求,特别是近年来深度学习和预训练语言模型的研究以及国内国外许多大模型的开源,研究人员们构建了多种大规模开源数据集,涵盖了网页、图片、论文、百科等多个领域。在构建大语言模型时,数据的质量和多样性对于提高模型的性能至关重要‘同时,为了推动大模型的语言的研究和应用,学术界和工业界也开放了多个针对大语言模型的开源数据集,本篇文章将介绍典型的开源数据集集合。
一、Pile
Pile 数据集[68] 是一个用于大语言模型训练的多样性大规模文本语料库,由22 个不同的高质量子集构成,包括现有的和新构建的,许多来自学术或专业来源。这些子集包括Common Crawl、Wikipedia、OpenWebText、ArXiv、PubMed 等。Pile 的特点是包含了大量多样化的文本,涵盖了不同领域和主题,从而提高了训练数据集的多样性和丰富性。Pile 数据集总计规模大小有825GB 英文文本,其数据类型组成如图1所示,所占面积大小表示数据在整个数据集中所占的规模。
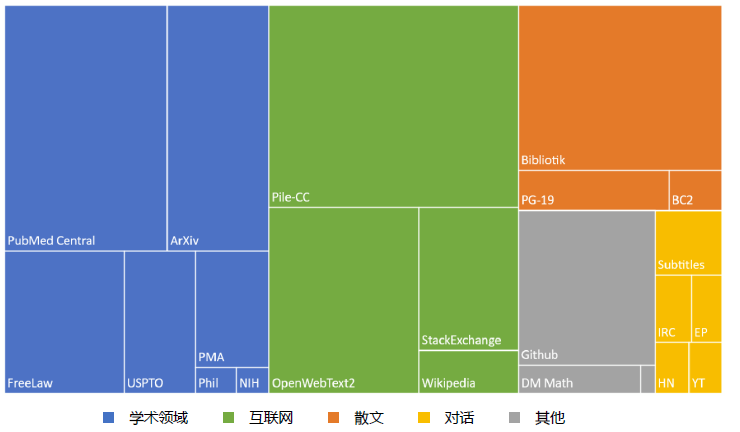
图1 Pile 数据集合组成
Pile 数据集合所包含的数据由如下22 个不同子集:
• Pile-CC 是基于Common Crawl 的数据集,在Web Archive 文件上使用jusText的方法进行提取,这比直接使用WET 文件,产生更高质量的输出。
• PubMed Central(PMC)是由美国国家生物技术信息中心(NCBI)运营的PubMed 生物医学在线资源库的一个子集,提供对近500 万份出版物的开放全文访问。
• Books3 是一个图书数据集,来自Shawn Presser 提供的Bibliotik。Bibliotik 由小说和非小说类书籍组成,几乎是图书数据集(BookCorpus2)数据量的十倍。
• OpenWebText2 (OWT2)是一个基于WebText 和OpenWebTextCorpus 的通用数据集。它包括从Reddit 提交到2020 年的最新内容、来自多种语言的内容、文档元数据、多个数据集版本和开源复制代码。
• ArXiv 是一个自1991 年开始运营的研究论文预印版本发布服务,论文主要集中在数学、计算机科学和物理领域。ArXiv 上的论文是用LaTeX 编写的,对于公式、符号、表格等内容的表示非常适合语言模型学习。
• GitHub 是一个大型的开源代码库,对于语言模型完成代码生成、代码补全等任务具有非常重要的作用。
• Free Law 项目是一个在美国注册的非营利组织,为法律领域的学术研究提供访问和分析工具。CourtListener 是Free Law 项目的一部分,包含美国联邦和州法院的数百万法律意见,并提供批量下载服务。
• Stack Exchange 一个围绕用户提供问题和答案的网站集合。Stack Exchange Data Dump 包含了在Stack Exchange 网站集合中所有用户贡献的内容的匿名数据集。它是截止到2023 年9月为止公开可用的最大的问题-答案对数据集合之一,涵盖了广泛的主题,从编程到园艺再到艺术等等。
• USPTO Backgrounds 是美国专利商标局授权的专利背景部分的数据集,来源于其公布的批量档案。典型的专利背景展示了发明的一般背景,给出了技术领域的概述,并建立了问题空间的框架。USPTO 背景,包含了大量关 于应用主题的技术文章,面向非技术受众。
• Wikipedia (English) 是维基百科的英文部分。维基百科是一部由全球志愿者协作创建和维护的免费在线百科全书,旨在提供各种主题的知识。它是世界上最大的在线百科全书之一,可用于多种语言,包括英语、中文、西班牙 语、法语、德语等等。
• PubMed Abstracts 是由PubMed 的3000 万份出版物的摘要组成的数据集。PubMed 是由美国国家医学图书馆运营的生物医学文章在线存储库。PubMed 还包含了MEDLINE,它包含了1946 年至今的生物医学摘要。
• Project Gutenberg 是一个西方经典文学的数据集。这里使用的是PG-19,是由1919 年以前的Project Gutenberg 中的书籍组成,它们代表了与更现代的Book3 和BookCorpus 不同的风格。
• OpenSubtitles 是由英文电影和电视的字幕组成的数据集。字幕是对话的重要来源,并且可以增强模型对虚构格式的理解。也可能会对创造性写作任务(如剧本写作、演讲写作、交互式故事讲述等)有一定作用。
• OpenSubtitles 数据集是由英文电影和电视的字幕组成的集合。字幕是对话的重要来源,并且可以增强模型对虚构格式的理解。也可能会对创造性写作任务(如剧本写作、演讲写作、交互式故事讲述等)有一定作用。
• DeepMind Mathematics 数据集包含代数、算术、微积分、数论和概率等一系列数学问题组成,并且以自然语言提示的形式给出。大语言模型在数学任务上的表现较差,这可能部分是由于训练集中缺乏数学问题。因此,Pile 数据集中专门增加了数学问题数据集,期望增强通过Pile 数据集训练的语言模型的数学能力。
• BookCorpus2 数据集是原始BookCorpus的扩展版本,广泛应用于语言建模,甚至包括由“尚未发表”书籍。BookCorpus 与Project Gutenbergu 以及Books3 几乎没有重叠。
• Ubuntu IRC 数据集是从Freenode IRC 聊天服务器上所有与Ubuntu 相关的频道的公开聊天记录中提取的。聊天记录数据提供了语言模型建模人类交互的可能。
• EuroParl是一个多语言平行语料库,最初是为机器翻译任务构建。但也在自然语言处理的其他几个领域中得到了广泛应用。Pile 数据集中所使用的版本包括1996 年至2012年欧洲议会的21 种欧洲语言的议事录。
• YouTube Subtitles 数据集是从YouTube 上人工生成的字幕中收集的文本平行语料库。该数据集除了提供了多语言数据之外,还是教育内容、流行文化和自然对话的来源。
• PhilPapers 数据集由University of Western Ontario 数字哲学中心(Center for Digital Philosophy)维护的国际数据库中的哲学出版物组成。它涵盖了广泛的抽象、概念性的话语,其文本写作质量也非常高。
• NIH Grant Abstracts: ExPORTER 数据集包含1985 年至今,所有获得美国NIH 资助的项目申请摘要,是非常高质量的科学写作实例。
• Hacker News 数据集是由初创企业孵化器和投资基金Y Combinator 运营的链接聚合器。其目标是希望用户提交“任何满足一个人的知识好奇心的内容”,但文章往往聚焦于计算机科学和创业主题。其中包含了一些小众话题的高质量对话和辩论。
• Enron Emails 数据集是由文献 提出的,用于电子邮件使用模式研究的数据集。该数据集的加入可以帮助语言模型建模电子邮件通信的特性。
Pile 中不同数据子集所占比例以及在训练时的采样权重有很大不同,对于高质量的数据会给于更高的采样权重。比如Pile-CC 数据集包含227.12GB 数据,整个训练周期中采样1 轮,但是Wikipedia (en) 数据集虽然仅有6.38G 数据,但是整个训练周期中采样3 轮。具体的采样权重和采样轮数可以参考文献。
二、ROOTS
Responsible Open-science Open-collaboration Text Sources(ROOTS)数据集合 是BigScience项目在训练具有1760 亿参数的BLOOM 大语言模型所使用的数据集合。该数据集合包含46 种自然语言和13 种编程语言,总计59 种语言,整个数据集的大小约1.6TB。ROOTS 数据集合中各语言所占比例如图2.1所示。图中左侧是以语言家族的字节数为单位表示的自然语言占比树状图。其中欧亚大陆语言占据了绝大部分(1321.89 GB)。橙色矩形对应是的印度尼西亚语(18GB),是巴布尼西亚大区唯一的代表。而绿色矩形对应于0.4GB 的非洲语言。图中右侧是以文件数量为单位的编程语言分布的华夫饼图(Waffle Plot),一个正方形大约对应3 万个文件。
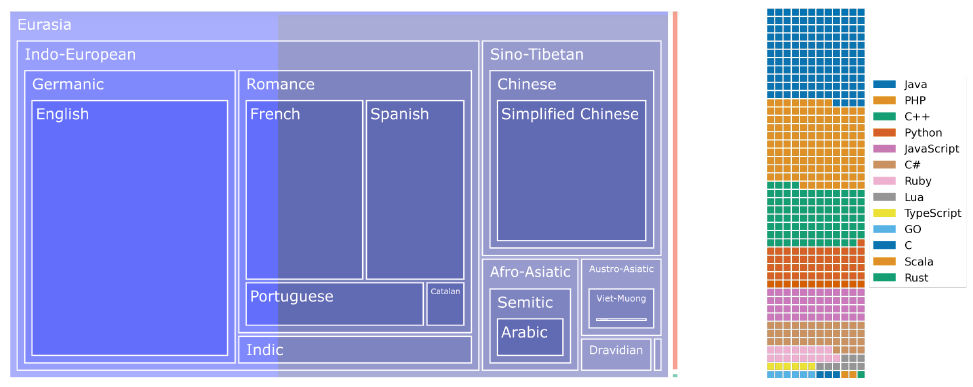
图2.1 ROOTS 数据集合中各语言所占比例
ROOTS 数据主要来源于四个方面:公开语料、虚拟抓取、GitHub 代码、网页数据。在公开语料方面,BigScience Data Sourcing 工作组目标是收集尽可能多的收集各类型数据,包括自然语言处理数据集以及各类型文档数据集合。为此,还设计了BigScience Catalogue用于管理和分享大型科学数据集,以及Masader repository 用于收集阿拉伯语言和文化资源的开放数据存储库。在收集原始数据集的基础上,进一步从语言和统一表示方面对收集的文档进行规范化处理。识别数据集所属语言并分类存储,并将所有数据都按照统一的文本和元数据结构进行表示。由于数据种类繁多,ROOTS 数据集并没有公开其所包含数据集合情况。
但是提供了Corpus Map 以及Corpus Description 工具,可以方便地查询各类数据集占比和数据情况。如图2.2所示,ROOTS 数据集中中文数据主要由WuDao Corpora 和OSCAR 组成。在虚拟抓取方面,由于很多语言的现有公开数据集合较少,因此这些语言的网页信息是十分重要的资源补充。在ROOTS 数据集中,采用CommonCrawl 网页镜像,选取了614 个域名,从这些域名下的网页中提取文本内容补充到数据集中,以提升语言的多样性。在GitHub 代码方面,针对程序语言,ROOTS 数据集采用了与AlphaCode相同的方法从BigQuery 公开数据集中选取文件长度在100 到20 万字符之间,字母符号占比在15%至65%,最大行数在20 至1000 行之间代码。大语言模型训练中,网页数据对于数据的多样性和数据量支撑都起到了重要的作用,ROOTS 数据集合中包含了从OSCAR 21.09 版本,对应的是Common Crawl 2021 年2 月的快照,占整体ROOTS 数据集规模的38%
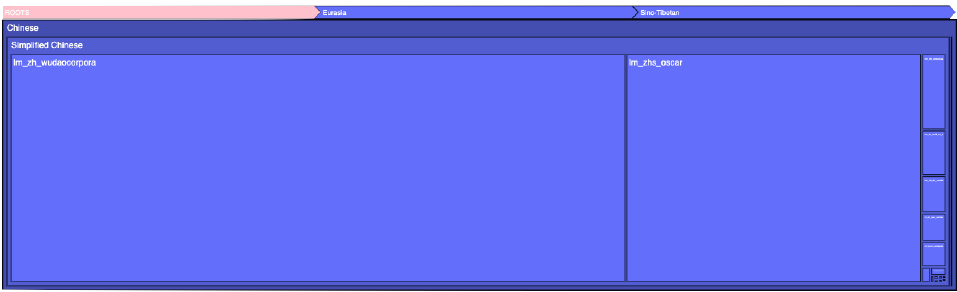
图2.2 ROOTS 数据集合中中文数据集种类以及所占比例
在数据准备完成后,还要进行清洗、过滤、去重以及隐私信息删除等工作,ROOTS 数据集处理流程如图3.1所示。整个处理工作并非完全依赖自动计算,而是人工与自动相结合的方法。针对数据中存在的一些非自然语言的文本,例如预处理错误、SEO 页面或垃圾邮件(包括色情垃圾邮件),ROOTS 数据集在构建时进行一定的处理。首先定义了一套质量指标,其中高质量的文本被定义为“由人类撰写,面向人类”(written by humans for humans),不区分内容(希望内容选择依据专业人员选择的来源)或语法正确性的先验判断。所使用的指标包括字母重复度、单词重复度、特殊字符、困惑度等。完整的指标列表可以参考文献。这些指标根据每个来源的不同,进行了两种主要的调整:针对每种语言单独选择参数,如阈值等;人工浏览每个数据来源,以确定哪些指标最可能识别出非自然语言。针对冗余信息,采用SimHash 算法,计算文档的向量表示,并根据文档向量表示之间的海明距离(Hamming distance)是否超过阈值进行过滤。在此基础上又使用后缀数组(Suffix Array),将包含6000 个以上字符重复的文档删除。通过上述方法共发现21.67%的冗余信息。个人信息数据(包括:邮件、电话、地址等)则使用正则表示方法进行了过滤。
三、 RefinedWeb
RefinedWeb[64] 是由位于阿布扎比的技术创新研究院(Technology Innovation Institute, TII) 在开发Falcon 大语言模型时同步开源的大语言模型预训练集合。其主要由从CommonCrawl 数据集过滤的高质量数据组成。CommonCrawl 数据集包含自2008 年以来爬取的数万亿个网页,由原始网页数据、提取的元数据和文本提取结果组成,总数据量超过1PB。CommonCrawl 数据集以WARC (Web ARChive)格式或者WET 格式进行存储。WARC 是一种用于存档Web 内容的国际标准格式,它包含了原始网页内容、HTTP 响应头、URL 信息和其他元数据。WET 文件只包含抽取出的纯文本内容。
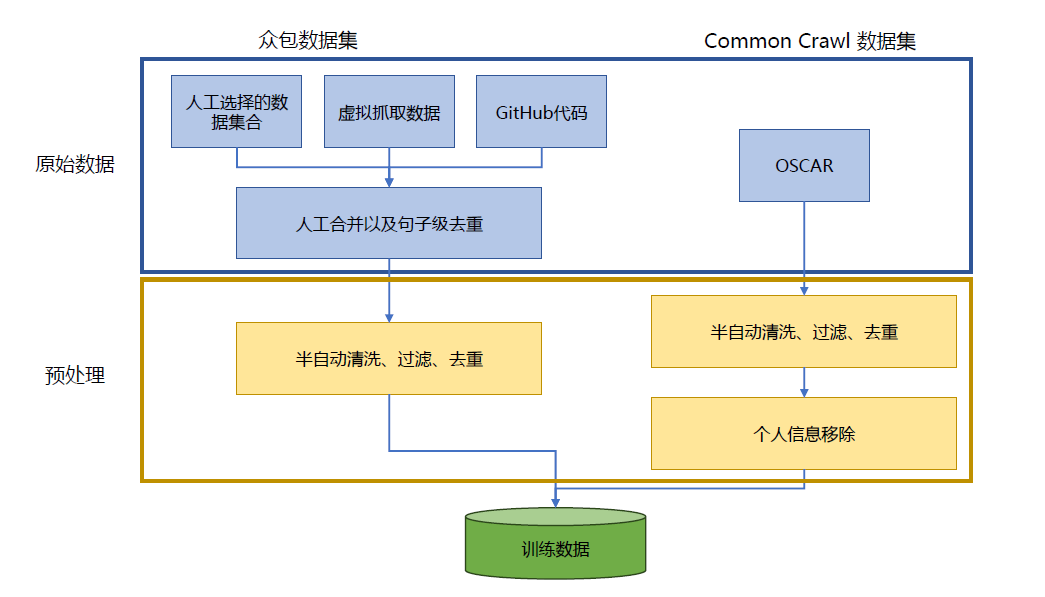
图3.1 ROOTS 数据集处理流程
文献 中给出了RefinedWeb 中CommonCrawl 数据集处理流程和数据过滤百分比,如图3.2所示。图中灰色部分是与前一个阶段相对应的移除率,阴影部分表示总体上的保留率。在文档准备阶段,移除率以文档数量的百分比进行衡量,过滤阶段和重复去除阶段使用词元(Token)为单位进行衡量。整个处理流程分类三个阶段:文档准备、过滤和去重。经过上述多个步骤之后,仅保留了大约11.67% 的数据。RefinedWeb 一共包含5 万亿个词元(5000G Token),开源公开部分6 千亿个词元(600G Token)。
文档准备阶段主要是进行URL 过滤、文本抽取和语言识别三个任务。URL 过滤(URL Filtering)主要针对欺诈和成人网站(例如,主要包含色情、暴力、赌博等内容的网站)。使用基于规则的过滤方法:
(1)包含460 万黑名单域名(Blocklist);
(2)根据严重程度加权的词汇列表对URL 评分。文本提取(Text Extraction)主要目标是仅提取页面的主要内容,同时去除菜单、标题、页脚、广告等内容。RefinedWeb 构建过程中使用trafilatura 工具集[125],并通过正则表达式进行了部分后处理。语言识别(Language Identification)阶段使用CCNet 提出的fastText 语言分类器。该分类器使用字符n-gram 做为特征,并在Wikipedia 上进行训练,支持176 种语言识别。如图3.2所示,CommonCrawl 数据集中非英语数据占比超过50%,在经过语言识别后,过滤掉了所有非英语数据。
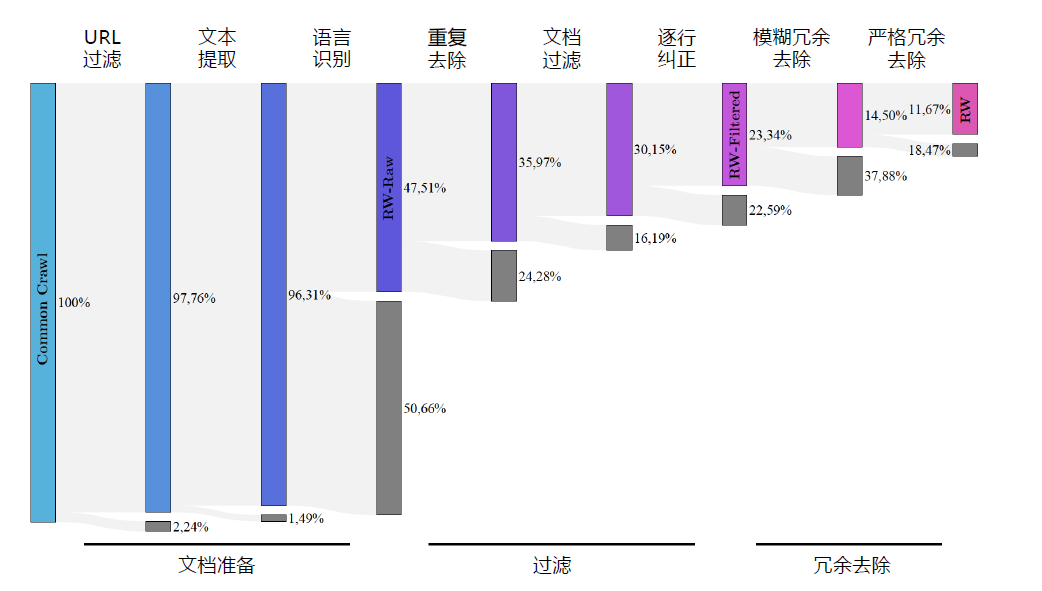
图3.2 RefinedWeb 中CommonCrawl 数据集过滤流程和数据过滤百分比
通过文档准备阶段得到的数据集合称为RW-RAW。
过滤阶段主要包含重复去除和文档过滤和逐行纠正三个任务。重复去除(Repetition Removal)主要目标是删除具有过多行、段落或n-gram 重复的文档。这些文档主要是由于爬取错误或者低质重复网页。这些内容会严重影响模型性能,使得模型产生病态行为(pathological behavior),因此需要尽可能在早期阶段去除[93]。文档过滤(Document-wise Filtering)目标是删除由机器生成的垃圾信息,这些页面主要由关键词列表、样板文本或特殊字符序列组成。采用了文献[85] 中所提出的启发式质量过滤算法,通过整体长度、符号与单词比率以及其他标准来剔除离群值,以确保文档是实际的自然语言。逐行纠正(Line-wise Corrections)目标是过滤文档中的不适合语言模型训练的行(例如,社交媒体计数器、导航按钮等)。使用基于规则的方法进行逐行纠正过滤,如果删除超过5%,则完全删除该文档。经过过滤阶段,仅有23% 的原始数据得以保留,所得到的数据集合称为RW-FILTERED。
冗余去除阶段包含模糊冗余去除、严格冗余去除以及URL 冗余去除三个任务。模糊冗余去除(Fuzzy Deduplication)目标是删除内容相似的文档。使用了MinHash 算法,快速估算两个文档间相似度。利用该算法可以有效过滤重叠度高的文档。RefinedWeb 数据集构建时,使用的是5-gram并分成20 个桶,每个桶采用450 个Hash 函数。严格冗余去除(Exact Deduplication)目标是删除连续相同的序列字符串。使用后缀数组(suffix array)进行严格逐个词元间的对比,并删除超过50个以上的连续相同词元序列。URL 冗余去除(URL Deduplication)目标是删除具有相同URL 的文档。CommonCrawl 数据中存在一定量的具有重复URL 的文档,而且这些文档的内容绝大部分情况是完全相同的。RefinedWeb 数据集构建时,将CommonCrawl 数据不同部分之间相同的URL 进行了去除。该阶段处理完成后的数据集称为REFINEDWEB,仅有保留了原始数据的11.67%。
此外,文献还对三个阶段所产生的数据用于训练10 亿和30 亿模型的效果通过使用零样本泛化能力进行评测。发现REFINEDWEB 的效果远好于RW-RAW 和RW-FILTERED。这也在一定程度上说明高质量数据集对于语言模型具有重要的影响。
四、SlimPajama
SlimPajama是由CerebrasAI 公司针对RedPajama 进行清洗和去重后得到的开源数据集合。原始RedPajama 包含1.21 万亿词元(1.21T Token),经过处理后的SlimPajama 数据集包含6270 亿词元(627B Token)。SlimPajama 还开源了用于对数据集进行端到端预处理的脚本。RedPajama 是由TOGETHER 联合多家公司发起的开源大语言模型项目,试图严格按照LLaMA 模型论文中的方法构造大语言模型训练所需数据。虽然RedPajama 数据质量较好,但是CerebrasAI 的研究人员发现RedPajama 数据集还是存在两个问题:
1)一些语料中缺少数据文件;
2)数据集中包含大量重复数据。
为此,CerebrasAI 的研究人员开始针对RedPajama 数据集开展进一步的处理。SlimPajama 的整体处理过程如图3.17所示。整体处理包括多个阶段:NFC 正规化、清理、去重、文档交错、文档重排、训练集和保留集拆分,以及训练集与保留集中相似数据去重等步骤。所有步骤都假定整个数据集无法全部装载到内存中,并分布在多个进程中进行处理。使用64 个CPU,大约花费60 多个小时就是完成1.21 万亿词元处理。在整个处理过程中所需要内存峰值为1.4TB。
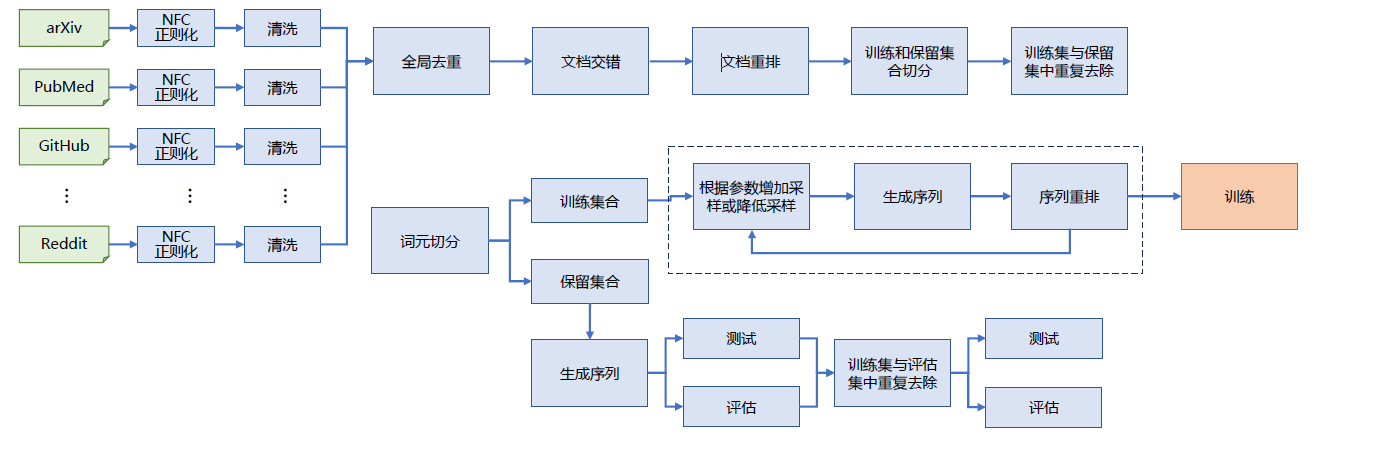
图4.1 SlimPajama 数据集处理过程
SlimPajama 处理详细流程如下:
(1) NFC 正则化(NFC Normalization):目标是去除非Unicode 字符,SlimPajama 遵循GPT-2 的规范,采用NFC(Normalization Form C)正则化方法。NFC 正则化的命令示例如下:
- python preprocessing/normalize_text.py \
-
- --data_dir <prefix_path>/RedPajama/arxiv/ \
-
- --target_dir <prefix_path>/RedPajama_norm/arxiv/
(2) 过滤短文档(Filter Short Documents):RedPajama 的源文件中有1.86% 包含了下载错误或长度较非常短的内容,这些内容对于模型训练没有作用。在去除标点、空格、换行和制表符后,过滤了长度少于200 个字符的文档。查找需要过滤的文档的命令示例如下:
- python preprocessing/filter.py \
-
- <prefix_path>/RedPajama_norm/<dataset_name>/ \
-
- <prefix_path>/RedPajama_filtered.pickle <n_docs> \
-
- <dataset_name> <threshold>
(3) 去重(Deduplication):为了对数据集进行全局去重(包括语料库内和语料库间的去重),SlimPajama 使用了datasketch 库,并进行了一定的优化以减少内存消耗并增加并行性。采用了生产者-消费者模式,可以将运行时占主导地位的I/O 操作进行有效的并行。整个去重过程包括多个阶段:构建MinHashLSH 索引、在索引中进行查询以定位重复项、构建图表示以确定重复连通域,最后过滤每个成分中的重复项。
(a) MinHash 生成(MinHash Generation):为了计算每个文档的MinHash 对象,首先从每个文档中去除标点、连续空格、换行和制表符,并将其转换为小写。接下来,构建了13-gram 的列表,这些n-gram 作为特征用于创建文档签名,并添加到MinHashLSH 索引中。MinHash 生成的命令示例如下:
- python dedup/to_hash.py <dataset_name> \
-
- <prefix_path>/RedPajama_norm/<dataset_name>/\
-
- <prefix_path>/RedPajama_minhash/<dataset_name>/ \
-
- <n_docs> <iter> <index_start> <index_end> \
-
- -w <ngram_size> -k <buffer_size>
(b) 重复对生成(Duplicate Pairs Generation):使用Jaccard 相似度计算文档之间相似度,设置阈值为0.8 来确定一对文档是否应被视为重复。SlimPajama 的实现使用了–range 和–bands 参数,可在给定Jaccard 阈值的情况下使用datasketch/lsh.py 进行计算。重复对生成的命令示例如下:
- python dedup/generate_duplicate_pairs.py \
-
- --input_dir <prefix_path>/RedPajama_minhash/ \
-
- --out_file <prefix_path>/redpj_duplicates/duplicate_pairs.txt \
-
- --range <range> --bands <bands> --processes <n_processes>
(c) 重复图构建以及连通域查找(Duplicate Graph Construction & Search for Connected Components):确定了重复的文档对之后,需要找到包含彼此重复文档的连通域。例如根据以下文档对:(A, B)、(A, C)、(A, E),可以形成一个(A, B, C, E) 的组,并仅保留该组中的一个文档。可以使用如下命令构建重复图:
- python dedup/generate_connected_components.py \
-
- --input_dir <prefix_path>/redpj_duplicates \
-
- --out_file <prefix_path>/redpj_duplicates/connected_components.pickle
(d) 生成最终重复列表(Generate Final List of Duplicates):根据连通域构建创建一个查找表,以便稍后过滤出重复项。以下是生成重复项列表的命令示例:
- python preprocessing/shuffle_holdout.py pass1 \
-
- --input_dir <prefix_path>/RedPajama_norm/ \
-
- --duplicates <prefix_path>/redpj_duplicates/duplicates.pickle \
-
- --short_docs <prefix_path>/RedPajama_filtered.pickle\
-
- --out_dir <prefix_path>/SlimPajama/pass1
(4) 交错和重排(Interleave & Shuffle):大语言模型训练大都是在多源数据集上进行,需要使用指定的权重混合这些数据源。SlimPajama 数据集中默认从每个语料库中采样1 轮,但是可以通过preprocessing/datasets.py 中更新采样权重。除了混合数据源外,还要执行随机重排操作以避免任何顺序偏差。交错和重排的命令示例如下:
- python preprocessing/shuffle_holdout.py pass1 \
-
- --input_dir <prefix_path>/RedPajama_norm/ \
-
- --duplicates <prefix_path>/redpj_duplicates/duplicates.pickle \
-
- --short_docs <prefix_path>/RedPajama_filtered.pickle \
-
- --out_dir <prefix_path>/SlimPajama/pass1
(5) 训练和保留集合切分(Split Dataset into Train and Holdout):这一步主要是完成第二次随机重拍并创建了保留集。为了加快处理速度,将源数据分成块并行处理。以下是命令示例:
- for j in {1..20}
-
- do
-
- python preprocessing/shuffle_holdout.py pass2 "$((j-1))" "$j" "$j" \
-
- --input_dir <prefix_path>/SlimPajama/pass1 \
-
- --train_dir <prefix_path>/SlimPajama/train \
-
- --holdout_dir <prefix_path>/SlimPajama/holdout > $j.log 2>&1 &
-
- done
(6) 训练集与保留集中重复去除(Deduplicate Train against Holdout):最后一步是确保训练集和保留集之间没有重叠。为了去除训练集的污染,应用了SHA256 哈希算法来查找训练集和保留集之间的精确匹配项。然后,从训练集中过滤出这些精确匹配项。以下是命令示例:
- python dedup/dedup_train.py 1 \
-
- --src_dir <prefix_path>/SlimPajama/train \
-
- --tgt_dir <prefix_path>/SlimPajama/holdout \
-
- --out_dir <prefix_path>/SlimPajama/train_deduped
-
- for j in {2..20}
-
- do
-
- python dedup/dedup_train.py "$j" \
-
- --src_dir <prefix_path>/SlimPajama/train \
-
- --tgt_dir <prefix_path>/SlimPajama/holdout \
-
- --out_dir <prefix_path>/SlimPajama/train_deduped > $j.log 2>&1 &
-
- done

以上就是对四种开源数据集种类的介绍,以及开源数据集的处理流程和方法。

